A Bibliometric Overview of Twitter-Related Studies Indexed in Web of Science



Abstract
:1. Introduction
2. Literature Review
2.1. Twitter and Its Research Lines
2.2. Methodological Background
3. Methods
3.1. Data Collection and Preparation
3.2. Bibliometric Analysis Strategies
4. Results and Discussion
4.1. Performance Analysis
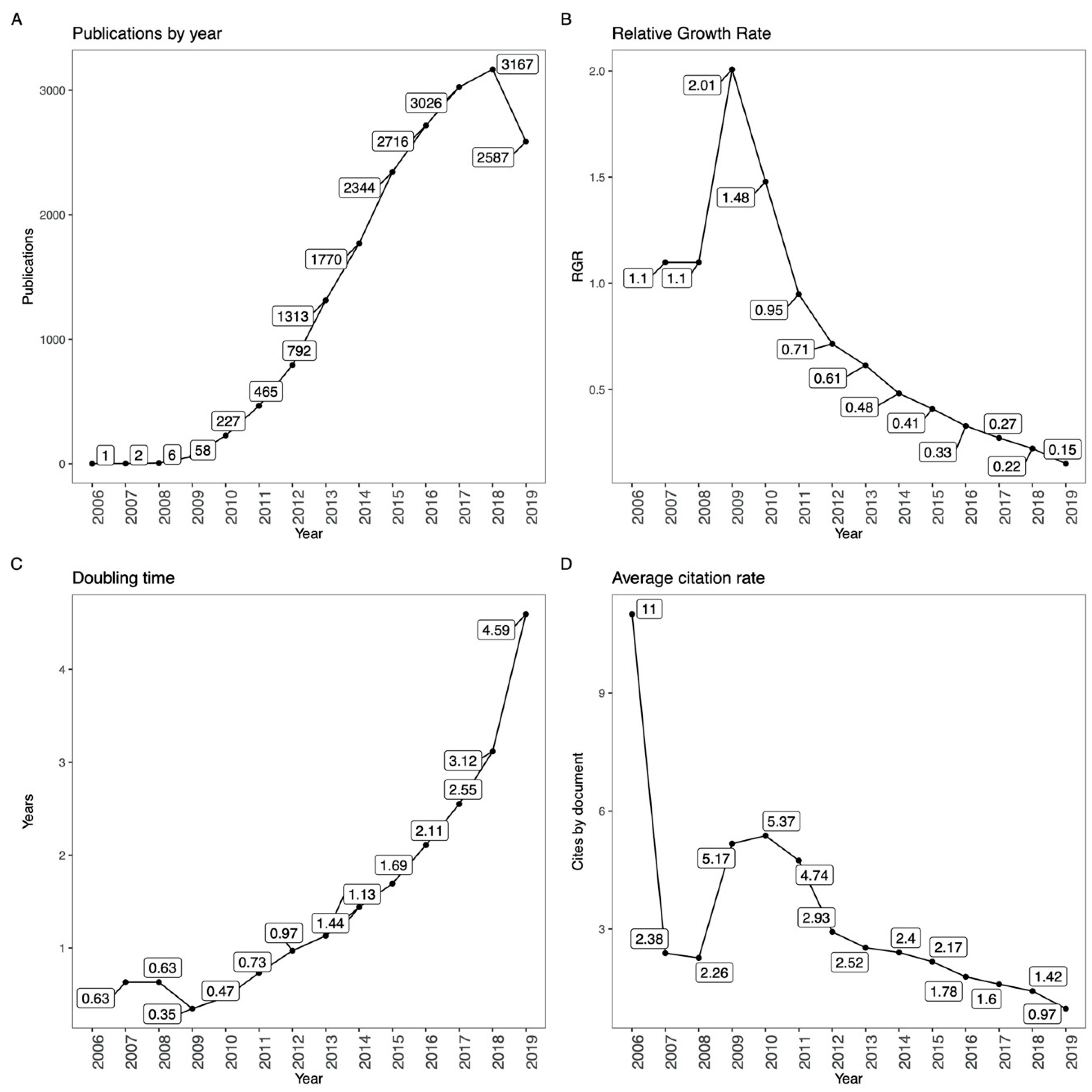
4.1.1. Annual Scientific Production
4.1.2. Most Relevant Sources
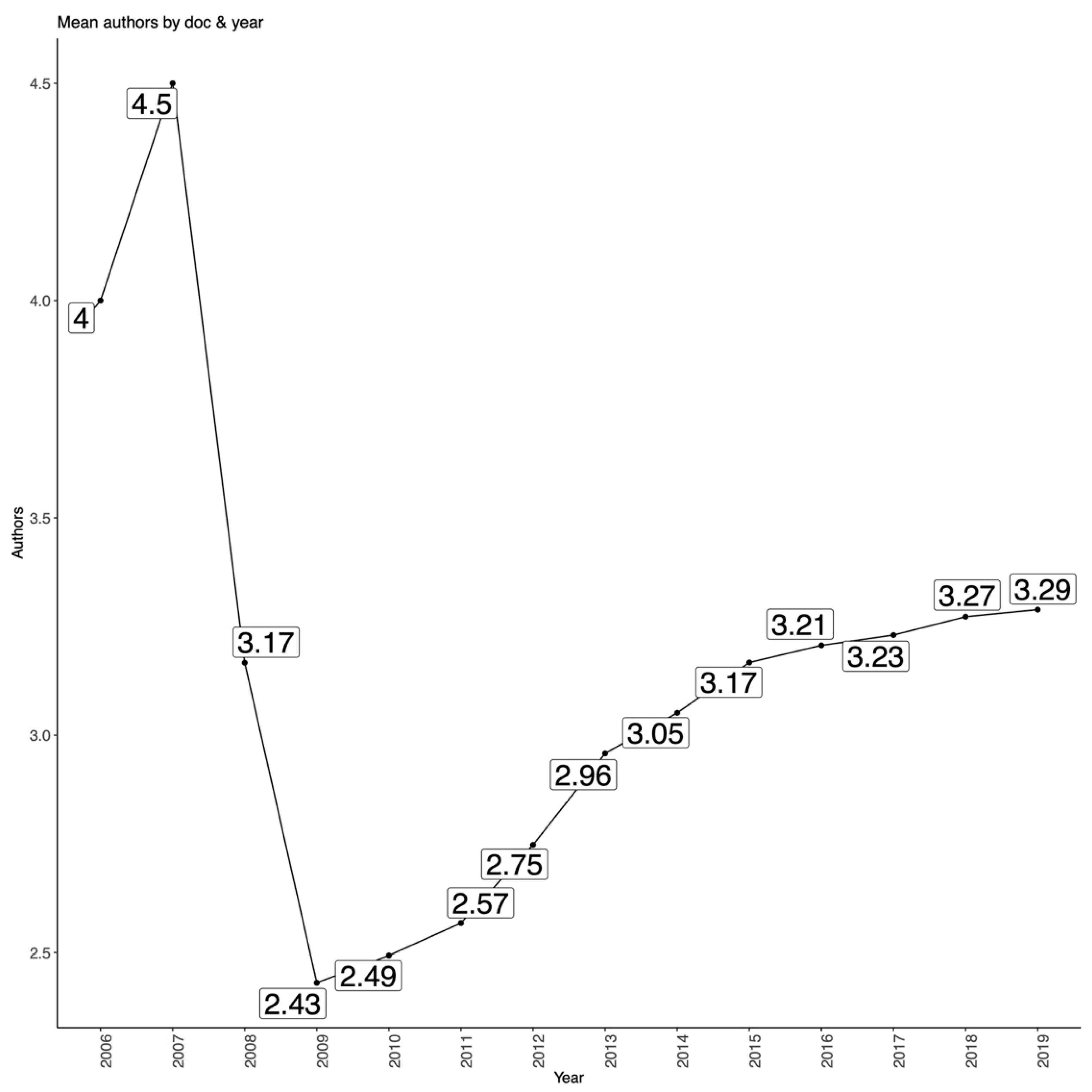
4.1.3. Author Statistics and Most Cited Publications
4.1.4. Most Relevant Keywords
4.2. Science Mapping
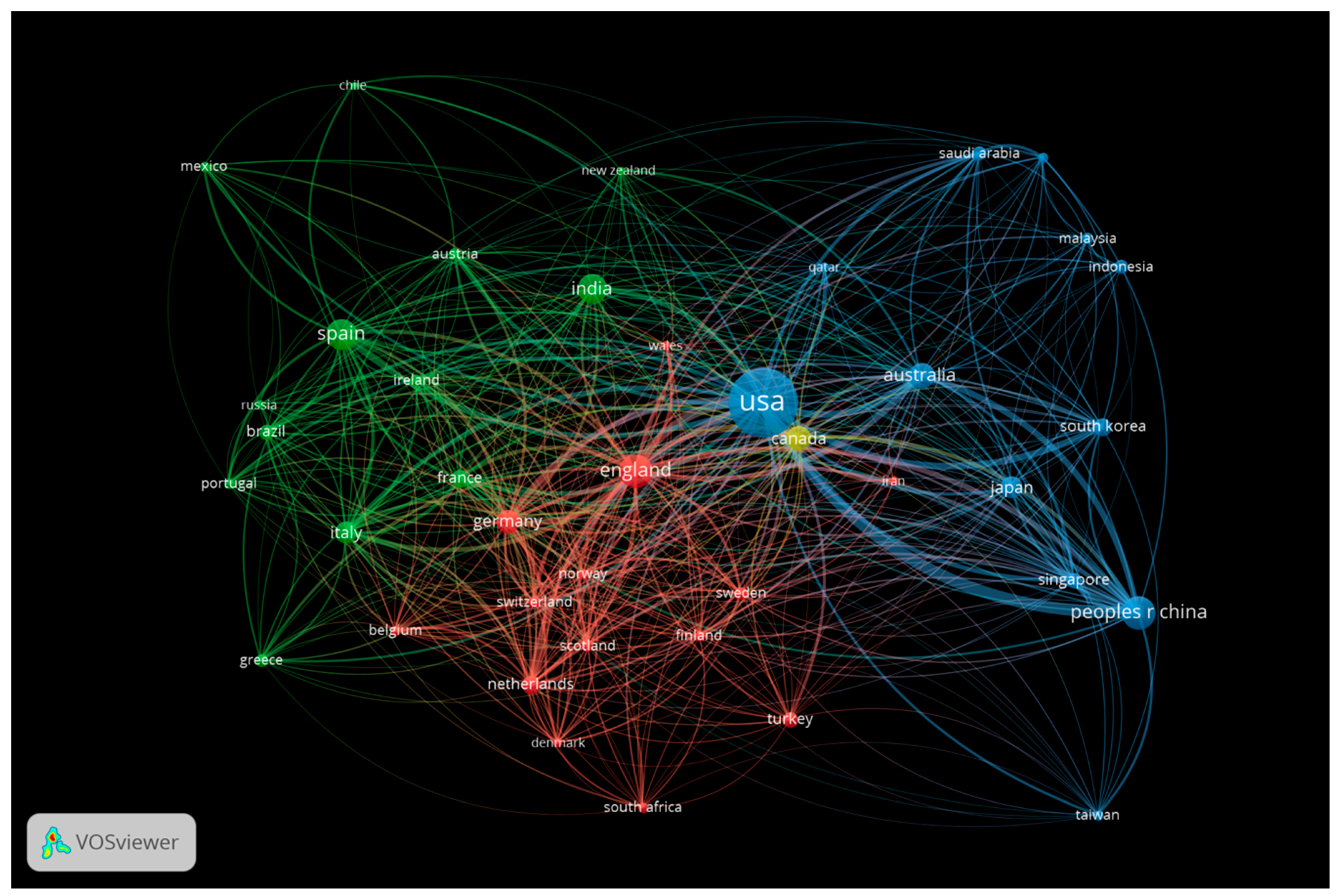
4.2.1. Country Collaboration Network
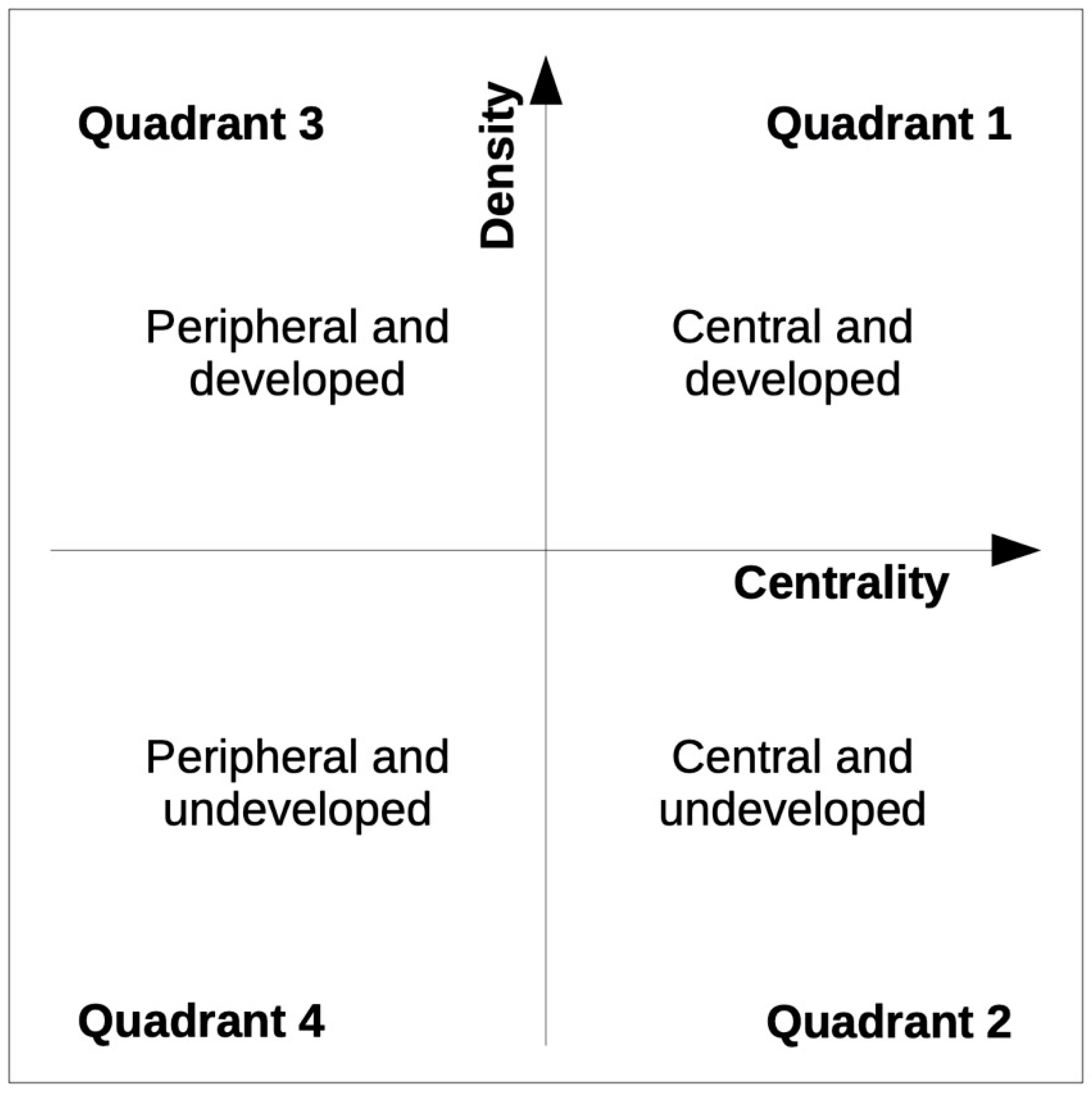
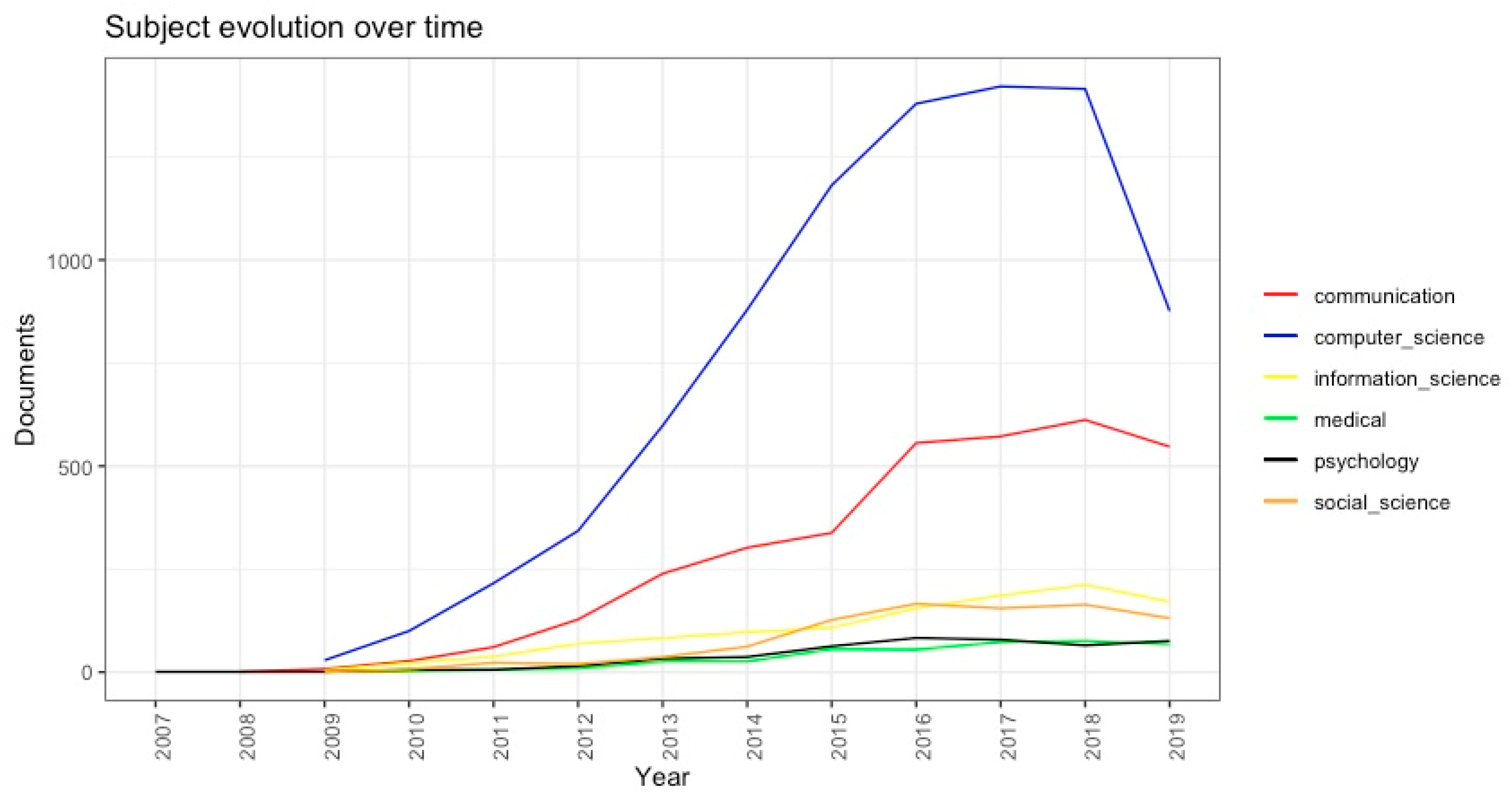
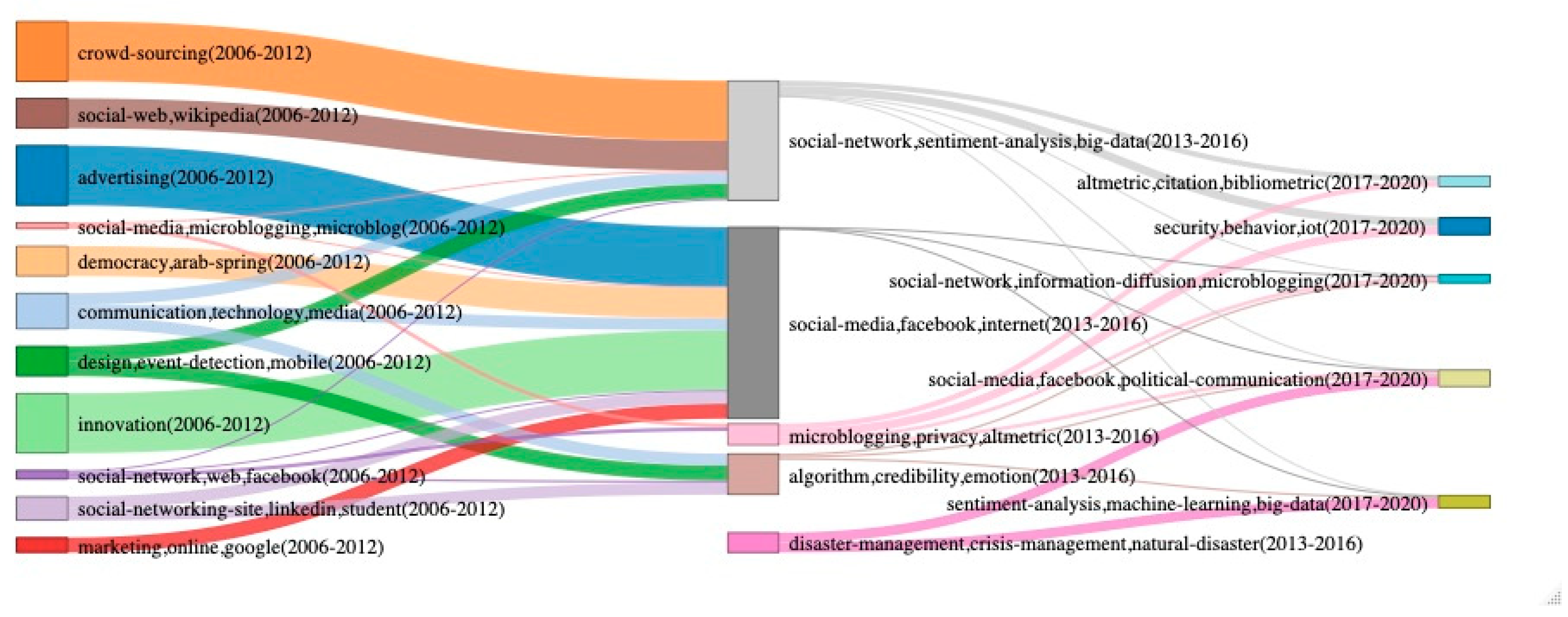
4.2.2. Thematic Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Twitter. Twitter Annual Report 2018; Twitter: San Francisco, CA, USA, 2018. [Google Scholar]
- Fiegerman, S. Twitter Now Losing Users in the U.S. Available online: https://money.cnn.com/2017/07/27/technology/business/twitter-earnings/index.html?iid (accessed on 27 July 2018).
- Haque, U. The Reason Twitter’s Losing Active Users. Available online: https://hbr.org/2016/02/the-reason-twitters-losing-active-users (accessed on 27 July 2018).
- Statista Twitter: Number of Active Users 2010–2018|Statista. Available online: https://www.statista.com/statistics/282087/number-of-monthly-active-twitter-users/ (accessed on 27 July 2018).
- Ahmed, W.; Bath, P.A.; Demartini, G. Chapter 4: Using Twitter as a Data Source: An Overview of Ethical, Legal, and Methodological Challenges; Emerald Publishing Limited: Bingley, UK, 2017; pp. 79–107. [Google Scholar]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a social network or a news media? In Proceedings of the 19th International Conference on World Wide Web—WWW ’10, Raleigh, CA, USA, 26–30 April 2010; ACM Press: New York, NY, USA, 2010; p. 591. [Google Scholar]
- Gupta, B.M.; Kumar, A.; Gupta, R.; Dhawan, S.M. A bibliometric assessment of Global Literature on “Twitter” during 2008–15. Int. J. Inf. Dissem. Technol. 2016, 6, 199–206. [Google Scholar]
- Yu, J.; Muñoz-Justicia, J. Free and Low-Cost Twitter Research Software Tools for Social Science. Soc. Sci. Comput. Rev. 2020. [Google Scholar] [CrossRef]
- Williams, S.A.; Terras, M.; Warwick, C. What do people study when they study Twitter? Classifying Twitter related academic papers. J. Doc. 2013, 69, 384–410. [Google Scholar] [CrossRef] [Green Version]
- Kang, B.; Lee, J.Y. A Bibliometric Analysis on Twitter Research. J. Korean Soc. Inf. Manag. 2014, 31, 293–311. [Google Scholar] [CrossRef] [Green Version]
- Peña-López, I.; Congosto, M.; Aragón, P. SpanishIndignadosand the evolution of the 15M movement on Twitter: Towards networked para-institutions. J. Span. Cult. Stud. 2014, 15, 189–216. [Google Scholar] [CrossRef]
- Isa, D.; Himelboim, I. A Social Networks Approach to Online Social Movement: Social Mediators and Mediated Content in #FreeAJStaff Twitter Network. Soc. Media Soc. 2018, 4, 4. [Google Scholar] [CrossRef] [Green Version]
- Jacobson, J.; Mascaro, C. Movember: Twitter Conversations of a Hairy Social Movement. Soc. Media Soc. 2016, 2. [Google Scholar] [CrossRef]
- Aragón, P.; Kappler, K.E.; Kaltenbrunner, A.; Laniado, D.; Volkovich, Y. Communication dynamics in twitter during political campaigns: The case of the 2011 Spanish national election. Policy Internet 2013, 5, 183–206. [Google Scholar] [CrossRef]
- Ceron, A.; D’Adda, G. E-campaigning on Twitter: The effectiveness of distributive promises and negative campaign in the 2013 Italian election. New Media Soc. 2016, 18, 1935–1955. [Google Scholar] [CrossRef]
- Jaharudin, M.H. The 13th General Elections: Changes in Malaysian Political Culture and Barsian Nasional’s Crisis of Moral Legitimacy. Kaji Malays. 2014, 32, 149–169. [Google Scholar]
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Perez-Meana, H.M.; Portillo-Portillo, J.; Villalba, L.J.G.; Villalba, L.J.G. Using Twitter Data to Monitor Natural Disaster Social Dynamics: A Recurrent Neural Network Approach with Word Embeddings and Kernel Density Estimation. Sensors 2019, 19, 1746. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gutierrez, C.; Figuerias, P.; Oliveira, P.; Costa, R.; Jardim-Goncalves, R. Twitter mining for traffic events detection. In Proceedings of the 2015 Science and Information Conference, SAI, London, UK, 28–30 July 2015; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2015; pp. 371–378. [Google Scholar]
- Wang, L.; Gan, J.Q. Prediction of the 2017 French Election Based on Twitter Data Analysis. In Proceedings of the 2017 9th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 27–29 September 2017. [Google Scholar]
- Bollen, J.; Mao, H.; Zeng, X.-J. Twitter mood predicts the stock market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Zimmer, M.; Proferes, N. A topology of Twitter research: Disciplines, methods, and ethics. Aslib J. Inf. Manag. 2014, 66, 250–261. [Google Scholar] [CrossRef]
- Weller, K. What do we get from Twitter—and What Not? A Close Look at Twitter Research in the Social Sciences. Knowl. Organ. 2014, 41, 238–248. [Google Scholar] [CrossRef]
- Williams, S.A.; Terras, M.; Warwick, C.; McGowan, B.; Pedrana, A. How Twitter Is Studied in the Medical Professions: A Classification of Twitter Papers Indexed in PubMed. Med. 2.0 2013, 2, e2. [Google Scholar] [CrossRef] [Green Version]
- Van Raan, A.F.J. The use of bibliometric analysis in research performance assessment and monitoring of interdisciplinary scientific developments. Tech. Theor. Prax 2003, 1, 20–29. [Google Scholar] [CrossRef]
- Broadus, R.N. Toward a definition of “bibliometrics”. Scientometrics 1987, 12, 373–379. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Inf. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Noyons, E.C.M.; Moed, H.F.; Luwel, M. Combining mapping and citation analysis for evaluative bibliometric purposes: A bibliometric study. J. Am. Soc. Inf. Sci. 1999, 50, 115–131. [Google Scholar] [CrossRef]
- van Raan, A.F.J. Measuring Science. In Handbook of Quantitative Science and Technology Research; Springer: Dordrecht, The Netherlands, 2005; pp. 19–50. [Google Scholar]
- Van Raan, A.F.J. Measurement of Central Aspects of Scientific Research: Performance, Interdisciplinarity, Structure. Meas. Interdiscip. Res. Perspect. 2005, 3, 1–19. [Google Scholar] [CrossRef]
- Gutierrez-Salcedo, M.; Martínez, M.Á.; Moral-Munoz, J.A.; Herrera, F.; Cobo, M.J. Some bibliometric procedures for analyzing and evaluating research fields. Appl. Intell. 2017, 48, 1275–1287. [Google Scholar] [CrossRef]
- Börner, K.; Chen, C.; Boyack, K. Visualizing knowledge domains. Annu. Rev. Inf. Sci. Technol. 2005, 37, 179–255. [Google Scholar] [CrossRef]
- Callon, M.; Courtial, J.P.; Laville, F. Co-word analysis as a tool for describing the network of interactions between basic and technological research: The case of polymer chemsitry. Scientometrics 1991, 22, 155–205. [Google Scholar] [CrossRef]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. An approach for detecting, quantifying, and visualizing the evolution of a research field: A practical application to the Fuzzy Sets Theory field. J. Inf. 2011, 5, 146–166. [Google Scholar] [CrossRef]
- Cobo, M.J.; Herrera-Viedma, E.; Herrera, F.; López-Herrera, A. SciMAT: A new science mapping analysis software tool. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 1609–1630. [Google Scholar] [CrossRef]
- Leopold, E.; May, M.; Paaß, G. Data Mining and Text Mining for Science & Technology Research. In Handbook of Quantitative Science and Technology Research; Springer: Dordrecht, The Netherlands, 2004; pp. 187–213. [Google Scholar]
- Van Eck, N.J.; Waltman, L. How to normalize cooccurrence data? An analysis of some well-known similarity measures. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 1635–1651. [Google Scholar] [CrossRef] [Green Version]
- Van Eck, N.J.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2009, 84, 523–538. [Google Scholar] [CrossRef] [Green Version]
- Waltman, L.; Van Eck, N.J.; Noyons, E. A unified approach to mapping and clustering of bibliometric networks. J. Inf. 2010, 4, 629–635. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Chai, L. Three new bibliometric indicators/approaches derived from keyword analysis. Scientometrics 2018, 116, 721–750. [Google Scholar] [CrossRef]
- Waila, P.; Singh, V.K.; Singh, M.K. A Scientometric Analysis of Research in Recommender Systems. J. Sci. Res. 2016, 5, 71–84. [Google Scholar] [CrossRef] [Green Version]
- Sweileh, W.; Al-Jabi, S.W.; AbuTaha, A.S.; Zyoud, S.; Anayah, F.M.A.; Sawalha, A.F. Bibliometric analysis of worldwide scientific literature in mobile - health: 2006–2016. BMC Med. Inform. Decis. Mak. 2017, 17, 72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thelwall, M. Author gender differences in psychology citation impact 1996–2018. Int. J. Psychol. 2019, 12633. [Google Scholar] [CrossRef] [PubMed]
- Clarivate Analytics KeyWords Plus Generation, Creation, and Changes. Available online: https://support.clarivate.com/ScientificandAcademicResearch/s/article/KeyWords-Plus-generation-creation-and-changes?language=en_US (accessed on 12 May 2020).
- Zhang, J.; Yu, Q.; Zheng, F.; Long, C.; Lu, Z.; Duan, Z. Comparing keywords plus of WOS and author keywords: A case study of patient adherence research. J. Assoc. Inf. Sci. Technol. 2015, 67, 967–972. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. BIBLIOMETRIC MAPPING OF THE COMPUTATIONAL INTELLIGENCE FIELD. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2007, 15, 625–645. [Google Scholar] [CrossRef]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, H.; Tang, M.; Luo, L.; Li, C.; Chiclana, F.; Zeng, X.-J. A Bibliometric Analysis and Visualization of Medical Big Data Research. Sustainability 2018, 10, 166. [Google Scholar] [CrossRef] [Green Version]
- Holmberg, K.; Thelwall, M. Disciplinary differences in Twitter scholarly communication. Scientometrics 2014, 101, 1027–1042. [Google Scholar] [CrossRef]
- Thelwall, M.; Haustein, S.; Larivière, V.; Sugimoto, C.R. Do Altmetrics Work? Twitter and Ten Other Social Web Services. PLoS ONE 2013, 8, e64841. [Google Scholar] [CrossRef]
- Buccafurri, F.; Lax, G.; Nicolazzo, S.; Nocera, A. Comparing Twitter and Facebook user behavior: Privacy and other aspects. Comput. Hum. Behav. 2015, 52, 87–95. [Google Scholar] [CrossRef]
- Lu, X.; Brelsford, C. Network Structure and Community Evolution on Twitter: Human Behavior Change in Response to the 2011 Japanese Earthquake and Tsunami. Sci. Rep. 2014, 4, 6773. [Google Scholar] [CrossRef]
- Chatfield, A.; Scholl, H.J.; Brajawidagda, U. Tsunami early warnings via Twitter in government: Net-savvy citizens’ co-production of time-critical public information services. Gov. Inf. Q. 2013, 30, 377–386. [Google Scholar] [CrossRef]
- Fung, I.C.-H.; Tse, Z.T.H.; Cheung, C.-N.; Miu, A.S.; Fu, K.-W. Ebola and the social media. Lancet 2014, 384, 2207. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G.; Nitti, M. The Social Internet of Things (SIoT)—When social networks meet the Internet of Things: Concept, architecture and network characterization. Comput. Netw. 2012, 56, 3594–3608. [Google Scholar] [CrossRef]
- Das, D.; Chidananda, H.T.; Sahoo, L. Personalized movie recommendation system using twitter data. In Progress in Computing, Analytics and Networking. Advances in Intelligent Systems and Computing; Pattnaik, P., Rautaray, S., Das, H., Nayak, J., Eds.; Springer: Singapore, 2018; Volume 710, pp. 339–347. [Google Scholar]
- Fausto, S.; Aventurier, P. Scientific Literature on Twitter as a Subject Research: Findings Based on Bibliometric Analysis; Handbook Twitter For Research 2015–2016; EMLYON Press: Lyon, France, 2016; p. 242. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Author | Year | Domain and Research Focus | Reference Pointer |
|---|---|---|---|---|
| A bibliometric analysis on Twitter Research | Kang, B.; Lee, J. Y. | 2014 | Bibliometric study. Argued that political issues are one of the core subjects in Twitter research. | [10] |
| Spanish Indignados and the evolution of the 15 M movement on Twitter: towards networked para-institutions | Pena-Lopez, I.; Congosto, M.; Aragon, P. | 2014 | Social dynamics. Using Twitter as a communication tool in regional social movements. | [11] |
| A social networks approach to online social movement: social mediators and mediated content in #FreeAJStaff Twitter network | Isa, D.; Himelboim, I. | 2018 | Social dynamics. Twitter as a mediator in news freedom online movements. | [12] |
| Movember: Twitter conversations of a hairy social movement | Jacobson, J.; Mascaro, C. | 2016 | Social dynamics. Twitter as a platform to engage individuals in social campaigns and sociotechnical social movements. | [13] |
| Communication dynamics in Twitter during political campaigns | Aragon, P.; Kappler, K. E. et al. | 2013 | Politics. Political elites use Twitter as a campaign platform in general elections | [14] |
| E-campaigning on Twitter: The effectiveness of distributive promises and negative campaign in the 2013 Italian election. | Ceron, A.; d’Adda, G. | 2016 | Politics. Using Twitter content to evaluate the impact of different electoral strategies in political elections | [15] |
| The 13th General Elections: Changes in Malaysian Political Culture And Barisan Nasional’s Crisis of Moral Legitimacy | Jaharudin, M.H. | 2014 | Politics. The role and importance that Twitter and other social media played in political elections. | [16] |
| Using Twitter data to monitor natural disaster social dynamics: A recurrent neural network approach with word embeddings and kernel density estimation. | Hernandez-Suarez, A.; Sanchez-Perez, G; et al. | 2019 | Geographical information system and disaster management. Using Twitter data to monitor natural disasters and to evaluate the post-effect of such catastrophe | [17] |
| Twitter mining for traffic events detection. | Gutierrez, C.; Figuerias, P et al. | 2015 | Traffic and management. Twitter as a monitor to detect traffic events | [18] |
| Prediction of the 2017 French Election Based on Twitter Data Analysis | Wang, L.; Gan, J.Q. | 2017 | Politics. Using Twitter content to predict political event | [19] |
| Twitter mood predicts the stock market. | Bollen, J.; Mao, H.; Zeng, X. | 2001 | Economics. Using Twitter content to predict stock market | [20] |
| Rank | Sources | Subject | Articles |
|---|---|---|---|
| 1 | PLOS One | Multidisciplinary Sciences | 251 |
| 2 | International Conference on Advances in Social Networks Analysis and Mining1 | Computer Science, Computer Networks and Communications, Information Systems | 239 |
| 3 | Computers in Human Behavior | Psychology, Experimental; Psychology, Multidisciplinary | 176 |
| 4 | IEEE International Conference on Big Data2 | Computer Science, Software | 145 |
| 5 | Journal of Medical Internet Research | Health Care Sciences & Services; Medical Informatics | 142 |
| 6 | Information Communication& Society | Communication; Sociology | 141 |
| 7 | New Media & Society | Communication | 118 |
| 8 | Social Network Analysis and Mining | Computer Science; Information Systems | 118 |
| 9 | International Journal of Communication | Communication | 108 |
| 10 | Social Media + Society | Computer Science Applications, Communication, Cultural Studies | 107 |
| Rank | Most Productive Authors | Most Cited Publications | |||||
|---|---|---|---|---|---|---|---|
| Name | N. Articles | Corresponding Author | Year | Journal | Total Citation | Citation per Year | |
| 1 | Wang Y | 55 | Kaplan AM | 2010 | Bus Horizons | 4169 | 417 |
| 2 | Kim J | 45 | Boyd D | 2012 | Inform Commun Soc | 1624 | 203 |
| 3 | Kim Y | 44 | Bollen J | 2011 | J Comput Sci-Neth | 1414 | 157 |
| 4 | Zhang Y | 44 | Kietzmann JH | 2011 | Bus Horizons | 1248 | 139 |
| 5 | Liu H | 43 | Marwick AE | 2011 | New Media Soc | 1126 | 125 |
| 6 | Liu Y | 42 | Jansen BJ | 2009 | J Am Soc Inf Sci Tec | 828 | 75 |
| 7 | Wang D | 36 | Casler K | 2013 | Comput Hum Behav | 577 | 82 |
| 8 | Park HW | 35 | O’Keefe GS | 2011 | Pediatrics | 549 | 61 |
| 9 | Lee J | 34 | Chew C | 2010 | Plos One | 504 | 50 |
| 10 | Bruns A | 33 | Hanna R | 2011 | Bus Horizons | 492 | 55 |
| Rank | Author Keywords | Documents | Keyword Plus | Documents |
|---|---|---|---|---|
| 1 | Social media | 4699 | Social media | 1408 |
| 2 | Sentiment analysis | 1148 | Media | 776 |
| 3 | Social networks | 1015 | Communication | 680 |
| 4 | 753 | 672 | ||
| 5 | Machine learning | 508 | Internet | 613 |
| 6 | Big data | 482 | Impact | 540 |
| 7 | Social network | 428 | Online | 534 |
| 8 | Social network analysis | 390 | News | 444 |
| 9 | Internet | 353 | Networks | 412 |
| 10 | Text mining | 327 | Model | 405 |
| Country | Publications | SCP | MCP | MCP Ratio |
|---|---|---|---|---|
| USA | 5340 | 4626 | 714 | 13.37% |
| United Kingdom | 1300 | 997 | 303 | 23.31% |
| China | 1251 | 820 | 431 | 34.45% |
| Spain | 1098 | 934 | 164 | 14.94% |
| India | 1086 | 1001 | 85 | 7.83% |
| Australia | 707 | 523 | 184 | 26.03% |
| Canada | 620 | 448 | 172 | 27.74% |
| Japan | 610 | 547 | 63 | 10.33% |
| Germany | 518 | 372 | 146 | 28.19% |
| Italy | 510 | 381 | 129 | 25.29% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Muñoz-Justicia, J. A Bibliometric Overview of Twitter-Related Studies Indexed in Web of Science. Future Internet 2020, 12, 91. https://doi.org/10.3390/fi12050091
Yu J, Muñoz-Justicia J. A Bibliometric Overview of Twitter-Related Studies Indexed in Web of Science. Future Internet. 2020; 12(5):91. https://doi.org/10.3390/fi12050091
Chicago/Turabian StyleYu, Jingyuan, and Juan Muñoz-Justicia. 2020. "A Bibliometric Overview of Twitter-Related Studies Indexed in Web of Science" Future Internet 12, no. 5: 91. https://doi.org/10.3390/fi12050091
APA StyleYu, J., & Muñoz-Justicia, J. (2020). A Bibliometric Overview of Twitter-Related Studies Indexed in Web of Science. Future Internet, 12(5), 91. https://doi.org/10.3390/fi12050091