Drug Repurposing for Parkinson’s Disease by Integrating Knowledge Graph Completion Model and Knowledge Fusion of Medical Literature


Abstract
:1. Introduction
- we combine novel knowledge and accurate knowledge by integrating the literature-based knowledge graph with a local medical knowledge base;
- we apply relatively effective knowledge graph completion methods to predict the drug candidates for Parkinson’s disease and discover that ConvTransE get a better prediction results;
- we employ classic machine learning methods to repurpose the drug candidates against Parkinson’s disease and compare the results with the method only using literature-based knowledge graph to confirm the effectiveness of knowledge fusion.
2. Related Work
3. Materials and Methods
3.1. Data Sets
3.1.1. Literature Data
3.1.2. The Data in the Local Medical Knowledge Base
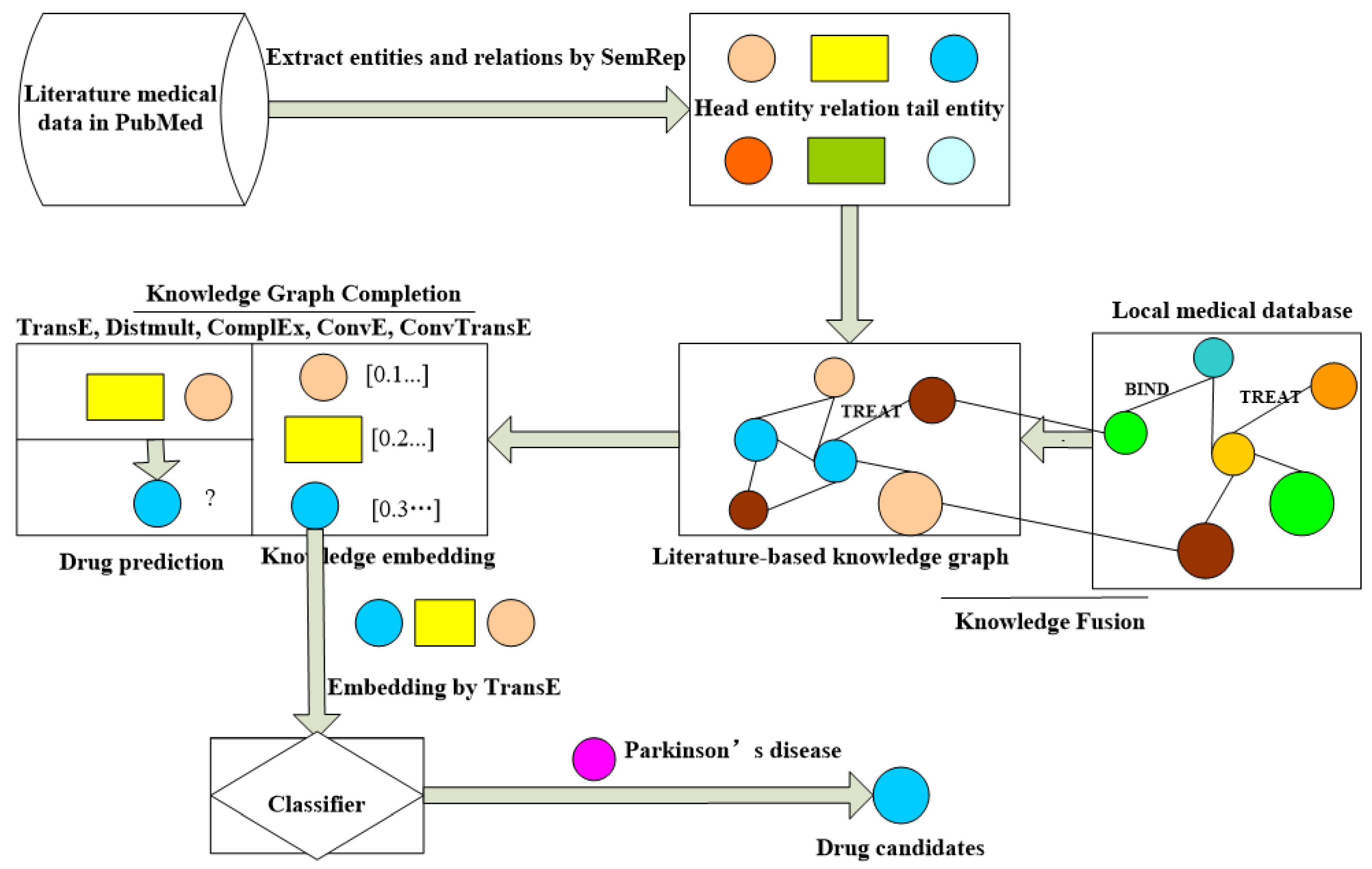
3.2. Method
- extracting and prerocessing medical data in the literature;
- constructing medical entities and their relationships into a literature-based knowledge graph and integrating it with local medical base;
- employing the knowledge graph completion methods to predict the drug candidates for Parkinson’s disease; and,
- using the machine learning methods to repurpose the drug candidates against Parkinson’s disease.
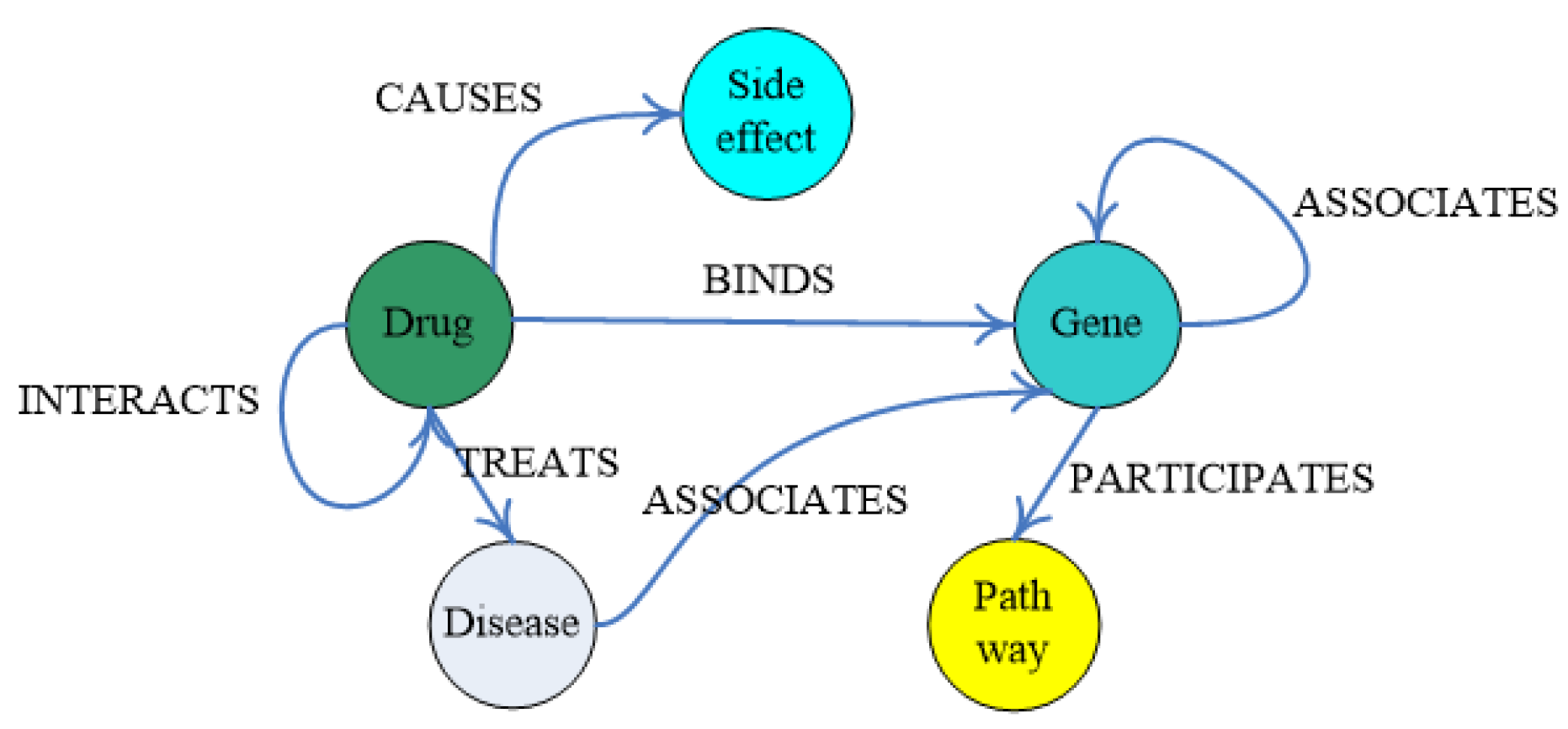
3.2.1. Preprocessing and Extraction of Medical Entities and Their Relationships
3.2.2. Construction and Fusion of the Medical Knowledge Graph
3.2.3. The Prediction of the Drug Candidate for Parkinson’s Disease by Knowledge Graph Completion Methods
3.2.4. The Prediction of the Drug Candidate for Parkinson’s Disease by Machine Learning Methods
4. Experiment
4.1. Experimental Setup
4.2. Evaluation Metrics
4.3. Experimental Results and Analysis
4.3.1. Comparison of Knowledge Graph Completion Models
4.3.2. Comparison of Machine Learning Methods
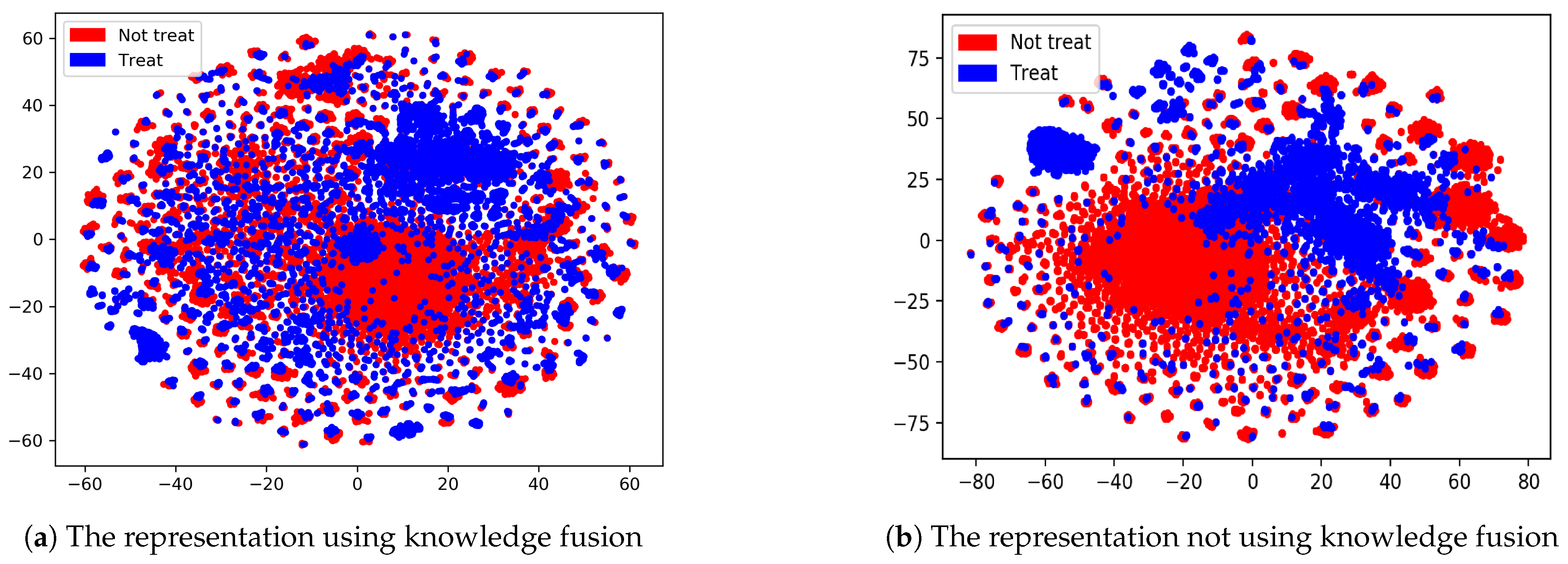
4.4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Armstrong, M.J.; Okun, M.S. Diagnosis and treatment of Parkinson disease: A review. JAMA 2020, 323, 548–560. [Google Scholar] [CrossRef] [PubMed]
- Reddy, D.H.; Misra, S.; Medhi, B. Advances in drug development for Parkinson’s disease: Present status. Pharmacology 2014, 93, 260–271. [Google Scholar] [CrossRef] [PubMed]
- Shameer, K.; Readhead, B.; Dudley, J.T. Computational and experimental advances in drug repositioning for accelerated therapeutic stratification. Curr. Top. Med. Chem. 2015, 15, 5–20. [Google Scholar] [CrossRef] [PubMed]
- Hubsher, G.; Haider, M.; Okun, M.S. Amantadine: The journey from fighting flu to treating Parkinson disease. Neurology 2012, 78, 1096–1099. [Google Scholar] [CrossRef]
- Xue, H.; Li, J.; Xie, H.; Wang, Y. Review of drug repositioning approaches and resources. Int. J. Biol. Sci. 2018, 14, 1232. [Google Scholar] [CrossRef] [Green Version]
- Ashburn, T.T.; Thor, K.B. Drug repositioning: Identifying and developing new uses for existing drugs. Nat. Rev. Drug Discov. 2004, 3, 673–683. [Google Scholar] [CrossRef]
- Sertkaya, A.; Birkenbach, A.; Berlind, A.; Eyraud, J. Examination of Clinical Trial Costs and Barriers for Drug Development: Report to the Assistant Secretary of Planning and Evaluation (ASPE); Department of Health and Human Services: Washington, DC, USA, 2014.
- Gottlieb, A.; Stein, G.Y.; Ruppin, E.; Sharan, R. PREDICT: A method for inferring novel drug indications with application to personalized medicine. Mol. Syst. Biol. 2011, 7, 496. [Google Scholar] [CrossRef]
- Li, J.; Zhu, X.; Chen, J. Building Disease-Specific Drug-Protein Connectivity Maps from Molecular Interaction Networks and PubMed Abstracts. PLoS Comput. Biol. 2009, 5, 14. [Google Scholar] [CrossRef]
- Rastegar-Mojarad, M.; Elayavilli, R.K.; Li, D. A new method for prioritizing drug repositioning candidates extracted by literature-based discovery. In Proceedings of the 2015 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Washington, DC, USA, 9–12 November 2015. [Google Scholar]
- Wu, C.; Gudivada, R.C.; Aronow, B.J.; Jegga, A.G. Computational drug repositioning through heterogeneous network clustering. BMC Syst. Biol. 2013, 7, S6. [Google Scholar] [CrossRef] [Green Version]
- Napolitano, F.; Zhao, Y.; Moreira, V.M.; Tagliaferri, R.; Kere, J.; D’Amato, M.; Greco, D. Drug repositioning: A machine-learning approach through data integration. J. Cheminf. 2013, 5, 30. [Google Scholar] [CrossRef] [Green Version]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Galligher, B.; Eliassi-Rad, T. Collective classification in network data. AI Mag. 2008, 29, 93–106. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Yu, P.S.; Zhou, Z.H. Meta-path based multi-network collective link prediction. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’14), New York, NY, USA, 24–27 November 2014. [Google Scholar] [CrossRef] [Green Version]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2787–2795. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of the 33rd International Conference on International Conference on Machine Learning—Volume 48 (ICML’16), New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Zhu, Y.; Jung, W.; Wang, F.; Che, C. Drug repurposing against Parkinson’s disease by text mining the scientific literature. Libr. Hi Tech 2020, 38, 741–750. [Google Scholar] [CrossRef]
- Wishart, D.S.; Knox, C.; Guo, A.C.; Shrivastava, S.; Hassanali, M.; Stothard, P.; Chang, Z.; Woolsey, J. DrugBank: A comprehensive resource for in silico drug discovery and exploration. Nucleic Acids Res. 2006, 34, 668–672. [Google Scholar] [CrossRef] [PubMed]
- Thorn, C.F.; Klein, T.E.; Altman, R.B. PharmGKB: The pharmacogenomics knowledge base. Pharmacogenomics 2013, 311–320. [Google Scholar] [CrossRef] [Green Version]
- Kanehisa, M.; Furumichi, M.; Sato, Y.; Ishiguro-Watanabe, M.; Tanabe, M. KEGG: Integrating viruses and cellular organisms. Nucleic Acids Res. 2020. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, S.; Li, F.; Zhou, Y.; Zhang, Y.; Wang, Z.; Zhang, R.; Zhu, J.; Ren, Y.; Tan, Y.; et al. Therapeutic target database 2020: Enriched resource for facilitating research and early development of targeted therapeutics. Nucleic Acids Res. 2020, 48, 1031–1041. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M.; Campillos, M.; Letunic, I.; Jensen, L.J.; Bork, P. A side effect resource to capture phenotypic effects of drugs. Mol. Syst. Biol. 2010, 6, 343. [Google Scholar] [CrossRef]
- Rindflesch, T.C.; Fiszman, M. The interaction of domain knowledge and linguistic structure in natural language processing: Interpreting hypernymic propositions in biomedical text. J. Biomed. Inf. 2003, 36, 462–477. [Google Scholar] [CrossRef] [Green Version]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), Hilton New Orleans Riverside, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shang, C.; Tang, Y.; Huang, J.; Bi, J.; He, X.; Zhou, B. End-to-End Structure-Aware Convolutional Networks for Knowledge Base Completion. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-2019), Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar] [CrossRef] [Green Version]
- Byvatov, E.; Fechner, U.; Sadowski, J.; Schneider, G. Comparison of support vector machine and artificial neural network systems for drug/nondrug classification. J. Chem. Inf. Model. 2003, 43, 1882–1889. [Google Scholar] [CrossRef]
- Cao, D.-S.; Zhang, L.-X.; Tan, G.-S.; Xiang, Z.; Zeng, W.-B.; Xu, Q.-S.; Chen, A.F. Computational Prediction of Drug Target Interactions Using Chemical, Biological, and Network Features. Mol. Inform. 2014, 33, 669–681. [Google Scholar] [CrossRef] [PubMed]
- Van Der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Cai, R.; Zhang, Y.; Simmering, J.E.; Schultz, J.L.; Li, Y.; Fernandez-Carasa, I.; Consiglio, A.; Raya, A.; Polgreen, P.M.; Narayanan, N.S.; et al. Enhancing glycolysis attenuates Parkinson’s disease progression in models and clinical databases. J. Clin. Investig. 2019, 129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mullin, S.; Smith, L.; Lee, K.; D’Souza, G.; Woodgate, P.; Elflein, J.; Hällqvist, J.; Toffoli, M.; Streeter, A.; Hosking, J.; et al. Ambroxol for the treatment of patients with Parkinson disease with and without glucocerebrosidase gene mutations: A nonrandomized, noncontrolled trial. JAMA Neurol. 2020, 77, 427–434. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pagan, F.L.; Hebron, M.L.; Wilmarth, B.; Torres-Yaghi, Y.; Lawler, A.; Mundel, E.E.; Yusuf, N.; Starr, N.J.; Anjum, M.; Arellano, J.; et al. Nilotinib effects on safety, tolerability, and potential biomarkers in Parkinson disease: A phase 2 randomized clinical trial. JAMA Neurol. 2020, 77, 309–317. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Data Sets | Medical Literature Data | Knowledge Fusion Data |
|---|---|---|
| Entities | 12,497 | 12,497 |
| Relations | 43 | 43 |
| triples | 115,300 | 165,901 |
| Models | No Knowledge Fusion | Knowledge Fusion | ||||
|---|---|---|---|---|---|---|
| Hits@1 | Hits@3 | Hits@10 | Hits@1 | Hits@3 | Hits@10 | |
| TransE | 42.11% | 56.12% | 69.02% | 54.94% | 62.89% | 75.59% |
| DistMult | 28.99% | 49.74% | 67.80% | 36.64% | 55.08% | 70.78% |
| ComplEx | 23.35% | 45.92% | 66.58% | 37.03% | 51.95% | 68.44% |
| ConvE | 28.82% | 56.68% | 73.52% | 36.33% | 73.52% | 75.00% |
| ConvTransE | 50.95% | 67.97% | 86.71% | 51.72% | 71.56% | 87.27% |
| Models | Literature-Based Knowledge Graph | Fused Knowledge Graph | Results in Zhu et al. [18] | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Recall | Precision | F1-Score | Recall | Precision | F1-Score | Recall | Precision | F1-Score | |
| SVM | 98.78% | 96.42% | 97.58% | 100.00% | 96.90% | 98.42% | 98.72% | 94.14% | 96.38% |
| LogisticRegression | 97.55% | 93.07% | 95.26% | 99.92% | 93.48% | 96.59% | 93.97% | 91.42% | 92.68% |
| RandomForest | 96.56% | 93.48% | 95.00% | 97.12% | 94.91% | 96.00% | 83.41% | 93.01% | 87.95% |
| DecisionTree | 83.51% | 81.55% | 82.52% | 89.14% | 82.27% | 85.57% | 72.16% | 76.13% | 74.09% |
| UMLS ID | Drug Name | Source that Have Been Proved |
|---|---|---|
| C4754962 | Terazosin | Medical literature in the Journal of clinical investigation [30] |
| C1367795 | Ambroxol | Medical literature in JAMA neurology [31] |
| C1721377 | Nilotinib | Medical literature in JAMA neurology [32] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Che, C. Drug Repurposing for Parkinson’s Disease by Integrating Knowledge Graph Completion Model and Knowledge Fusion of Medical Literature. Future Internet 2021, 13, 14. https://doi.org/10.3390/fi13010014
Zhang X, Che C. Drug Repurposing for Parkinson’s Disease by Integrating Knowledge Graph Completion Model and Knowledge Fusion of Medical Literature. Future Internet. 2021; 13(1):14. https://doi.org/10.3390/fi13010014
Chicago/Turabian StyleZhang, Xiaolin, and Chao Che. 2021. "Drug Repurposing for Parkinson’s Disease by Integrating Knowledge Graph Completion Model and Knowledge Fusion of Medical Literature" Future Internet 13, no. 1: 14. https://doi.org/10.3390/fi13010014
APA StyleZhang, X., & Che, C. (2021). Drug Repurposing for Parkinson’s Disease by Integrating Knowledge Graph Completion Model and Knowledge Fusion of Medical Literature. Future Internet, 13(1), 14. https://doi.org/10.3390/fi13010014