A Classifier to Detect Informational vs. Non-Informational Heart Attack Tweets


 , ,
, ,  and
and
Abstract
:1. Introduction
- We generate and manually label around 7000 tweets in the heart attack domain into informational and non-informational;
- We compare the performance of several machine learning models (DNN, J48 decision trees, naïve Bayes, and SVM) in terms of accuracy, precision, recall and F1-score measures on the annotated dataset.
2. Related Work
2.1. Social Media in the Health Domain
2.2. Mining Social Media for Health Care and Diseases
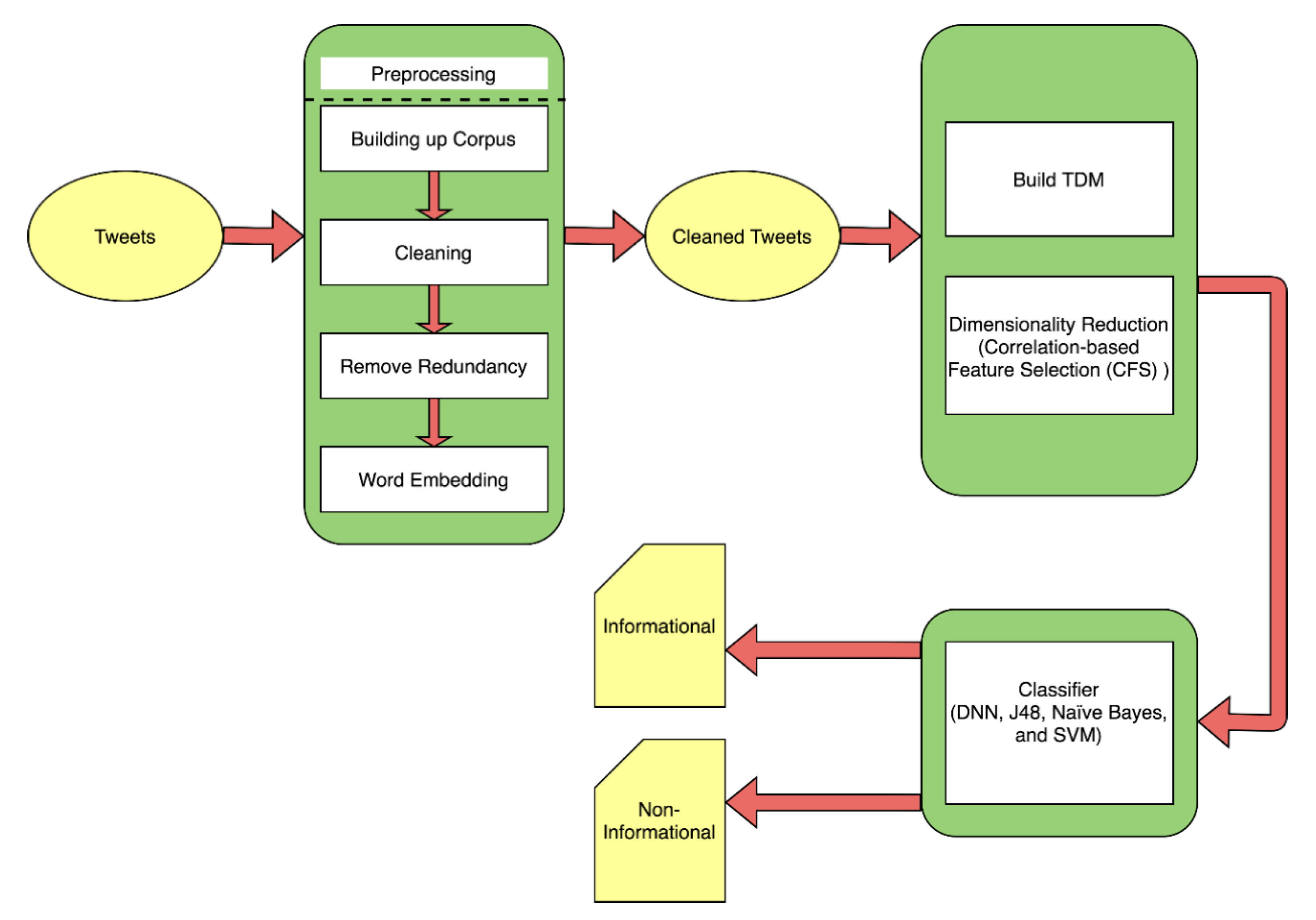
3. Methodology
3.1. Building Up the Corpus
3.2. Cleaning
- Removal of punctuations;
- Removal of retweet (RT);
- Removal of hashtags;
- Removal of stop-words;
- Removal of URLs;
- Stemming (Porter stemmer);
- Convert all letters to lower case.
- Original Tweet: “My aunt had a heart attack in church today they thought she just passed out in the spirit Keep my family in your prayers tweeps.”
- After cleaning: “aunt church today thought pass spirit keep family prayer tweep”
3.3. Redundancy Removal
3.4. Word Embedding
3.5. Building TDM
3.6. Dimensionality Reduction
3.7. Classification
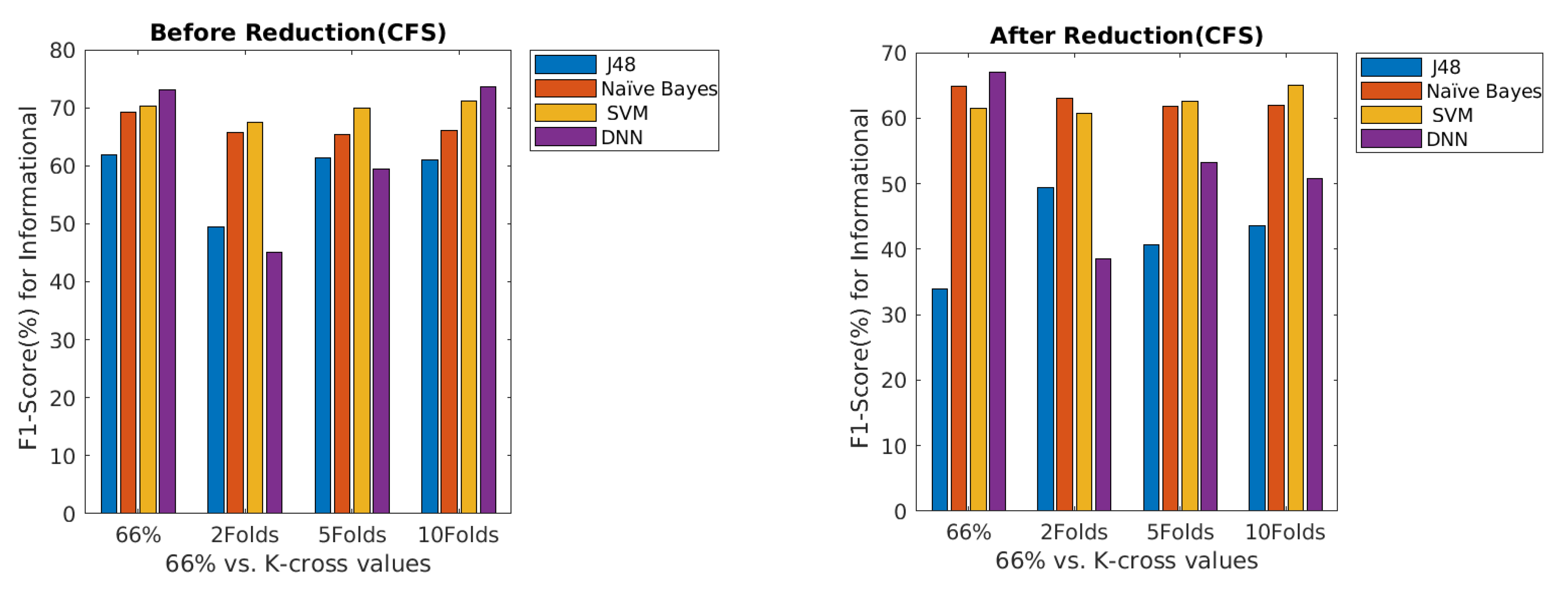
4. Results
5. Discussion and Study Limitation
- Twitter was the only platform used in our project, while there are many other platforms in social media such as Facebook and LinkedIn that can be utilized;
- The unbalanced dataset was a challenge where the percentage of non-informational tweets was higher than the informational tweets. This limitation can be solved by using adaptive learning techniques that avoid the dependency on manual labeling of tweets
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | |||||||
|---|---|---|---|---|---|---|---|---|
| 66% | 2-fold | 5-fold | 10-fold | 66% | 2-fold | 5-fold | 10-fold | |
| J48 | 63.3 | 62.6 | 61.1 | 61 | 60.5 | 40.8 | 61.6 | 61 |
| Naïve Bayes | 66.9 | 62.7 | 62 | 62.8 | 71.8 | 69 | 69.3 | 69.6 |
| SVM | 83.6 | 85.3 | 85.5 | 85.2 | 60.5 | 55.8 | 59.2 | 61.2 |
| DNN | 85 | 93.5 | 70.2 | 86.7 | 64 | 30.5 | 51.6 | 64.6 |
| Precision | Recall | |||||||
|---|---|---|---|---|---|---|---|---|
| 66% | 2-fold | 5-fold | 10-fold | 66% | 2-fold | 5-fold | 10-fold | |
| J48 | 95.5 | 93.2 | 95.4 | 95.3 | 95.8 | 95.1 | 95.3 | 95.3 |
| Naïve Bayes | 96.8 | 96.2 | 96.3 | 96.3 | 96.4 | 95.7 | 95.6 | 95.7 |
| SVM | 95.6 | 94.9 | 95.3 | 95.5 | 97.1 | 96.8 | 97 | 97.1 |
| DNN | 96 | 92.5 | 94.4 | 95.9 | 97 | 96 | 96.8 | 97.4 |
| Precision | Recall | |||||||
|---|---|---|---|---|---|---|---|---|
| 66% | 2-fold | 5-fold | 10-fold | 66% | 2-fold | 5-fold | 10-fold | |
| J48 | 82.5 | 62.1 | 69.4 | 65.6 | 21.4 | 41.1 | 28.8 | 32.6 |
| Naïve Bayes | 60.7 | 58.2 | 57.9 | 57.8 | 69.5 | 68.5 | 66.2 | 66.9 |
| SVM | 83.6 | 84.7 | 86.7 | 86.3 | 48.6 | 47.4 | 49 | 52.1 |
| DNN | 90 | 89 | 83.2 | 76.9 | 53 | 24.5 | 41 | 39.2 |
| Precision | Recall | |||||||
|---|---|---|---|---|---|---|---|---|
| 66% | 2-fold | 5-fold | 10-fold | 66% | 2-fold | 5-fold | 10-fold | |
| J48 | 91.7 | 93.2 | 92 | 92.4 | 99.5 | 97 | 98.5 | 97.9 |
| Naïve Bayes | 96.5 | 96.1 | 95.9 | 96 | 94.9 | 94.1 | 94.2 | 94.1 |
| SVM | 94.4 | 94 | 94.2 | 94.5 | 98.9 | 99 | 99.1 | 99 |
| DNN | 95 | 92 | 93.2 | 93 | 99 | 100 | 98.6 | 98.9 |
References
- Shahare, F.F. Sentiment analysis for the news data based on the social media. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017; pp. 1365–1370. [Google Scholar]
- Stieglitz, S.; Mirbabaie, M.; Ross, B.; Neuberger, C. Social media analytics—Challenges in topic discovery, data collection, and data preparation. Int. J. Inf. Manag. 2018, 39, 156–168. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, J. Consumer health information seeking in social media: A literature review. Health Inf. Libr. J. 2017, 34, 268–283. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sidana, S.; Mishra, S.; Amer-Yahia, S.; Clausel, M.; Amini, M.-R. Health Monitoring on Social Media over Time. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 17–21 July 2016; pp. 849–852. [Google Scholar]
- Sarker, A.; Gonzalez, G. Data, tools and resources for mining social media drug chatter. In Proceedings of the Fifth Workshop on Building and Evaluating Resources for Biomedical Text Mining (BioTxtM2016), Osaka, Japan, 12 December 2016; pp. 99–107. [Google Scholar]
- Pershad, Y.; Hangge, P.; Albadawi, H.; Oklu, R. So-cial medicine: Twitter in healthcare. J. Clin. Med. 2018, 7, 121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kale, S.; Padmadas, V. Sentiment Analysis of Tweets Using Semantic Analysis. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 17–18 August 2017; pp. 1–3. [Google Scholar] [CrossRef]
- Harish, B.N.; Reena, K.; Kumar, S.; Zhong, J. How much do you care? Mining and Analysis of Tweets Pertaining to Health Issues. In SoutheastCon 2018; IEEE: New York, NY, USA, 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Bouazizi, M.; Ohtsuki, T. A Pattern-Based Approach for Multi-Class Sentiment Analysis in Twitter. IEEE Access 2017, 5, 20617–20639. [Google Scholar] [CrossRef]
- Heart Disease: Facts, Statistics, and You. Available online: https://www.healthline.com/health/heart-disease/statisticsn#1 (accessed on 31 July 2019).
- Sridevi, M.; ArunKumar, B.R. Role of social media in health-care domain: An integrated review. Int. J. Eng. Res. Appl. 2017, 7, 49–54. [Google Scholar]
- Tripathi, M.; Singh, S.; Ghimire, S.; Shukla, S.; Kumar, S. Effect of social media on human health. Virol. Immunol. J. 2018, 2, 1–3. [Google Scholar]
- Perkins, J.M.; Subramanian, S.; Christakis, N.A. Social networks and health: A systematic review of sociocentric net-work studies in low-and middle-income countries. Soc. Sci. Med. 2015, 125, 60–78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paul, M.J.; Sarker, A.; Brownstein, J.S.; Nikfarjam, A.; Scotch, M.; Smith, K.L.; Gonzalez, G. Social media mining for public health monitoring and surveillance. In Proceedings of the Pacific Symposium on Biocomputing, Kohala Coast, HI, USA, 4–8 January 2016; pp. 468–479. [Google Scholar]
- Sutar, S.G. Intelligent data mining technique of social media for improving health care. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1356–1360. [Google Scholar]
- Kaushik, S.; Choudhury, A.; Mallik, K.; Moid, A.; Dutt, V.; Perner, P. Applying Data Mining to Healthcare: A Study of Social Network of Physicians and Patient Journeys. In Computer Vision; Perner, P., Ed.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9729, pp. 599–613. [Google Scholar]
- Lu, Y.; Wu, Y.; Liu, J.; Li, J.W.; Zhang, P. Un-derstanding health care social media use from different stakeholder perspectives: A content analysis of an on-line health community. J. Med. Internet Res. 2017, 19, e109. [Google Scholar] [CrossRef] [PubMed]
- Twitter Can Predict Rates of Coronary Heart Disease|Authentic Happiness. Available online: https://www.authentichappiness.sas.upenn.edu/news/twitter-can-predict-rates-coronary-heart-disease (accessed on 12 December 2020).
- Brown, N.J.L.; Coyne, J.C. Does Twitter language reliably predict heart disease? A commentary on Eichstaedt et al. (2015a). PeerJ 2018, 6, e5656. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naili, M.; Chaibi, A.H.; Ghezala, H.H.B. Com-parative study of word embedding methods in topic segmentation. Procedia Comput. Sci. 2017, 112, 340–349. [Google Scholar] [CrossRef]
- Document-Term Matrix. Available online: https://en.wikipedia.org/wiki/Document-term-matrix (accessed on 1 November 2020).
- Van der Maaten, L. An introduction to dimensionality reduction using matlab. Report 2007, 1201, 62. [Google Scholar]
- DLRL. Available online: https://dlib.vt.edu/index.html (accessed on 1 November 2020).
- Alsinglawi, B.; Alnajjar, F.; Mubin, O.; Novoa, M.; Alorjani, M.; Karajeh, O.; Darwish, O. Predicting Length of Stay for Cardiovascular Hospitalizations in the Intensive Care Unit: Machine Learning Approach. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 5442–5445. [Google Scholar] [CrossRef]
- Darwish, O.; Al-Fuqaha, A.; Brahim, G.B.; Jenhani, I.; Anan, M. Towards a streaming approach to the mitigation of covert timing channels. In Proceedings of the 2018 14th International Wireless Communications Mobile Computing Conference (IWCMC), Limassol, Cyprus, 25–29 June 2018; pp. 255–260. [Google Scholar]




| Testing Method | Before CFS Reduction | After CFS Reduction |
|---|---|---|
| 66% | 491.37 s | 2.96 s |
| 2-fold | 490.76 s | 2.47 s |
| 5-fold | 490.76 s | 2.44 s |
| 10-fold | 492.28 s | 2.45 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karajeh, O.; Darweesh, D.; Darwish, O.; Abu-El-Rub, N.; Alsinglawi, B.; Alsaedi, N. A Classifier to Detect Informational vs. Non-Informational Heart Attack Tweets. Future Internet 2021, 13, 19. https://doi.org/10.3390/fi13010019
Karajeh O, Darweesh D, Darwish O, Abu-El-Rub N, Alsinglawi B, Alsaedi N. A Classifier to Detect Informational vs. Non-Informational Heart Attack Tweets. Future Internet. 2021; 13(1):19. https://doi.org/10.3390/fi13010019
Chicago/Turabian StyleKarajeh, Ola, Dirar Darweesh, Omar Darwish, Noor Abu-El-Rub, Belal Alsinglawi, and Nasser Alsaedi. 2021. "A Classifier to Detect Informational vs. Non-Informational Heart Attack Tweets" Future Internet 13, no. 1: 19. https://doi.org/10.3390/fi13010019
APA StyleKarajeh, O., Darweesh, D., Darwish, O., Abu-El-Rub, N., Alsinglawi, B., & Alsaedi, N. (2021). A Classifier to Detect Informational vs. Non-Informational Heart Attack Tweets. Future Internet, 13(1), 19. https://doi.org/10.3390/fi13010019