
Multimodel Phishing URL Detection Using LSTM, Bidirectional LSTM, and GRU Models

 ,
,  ,
,
Abstract
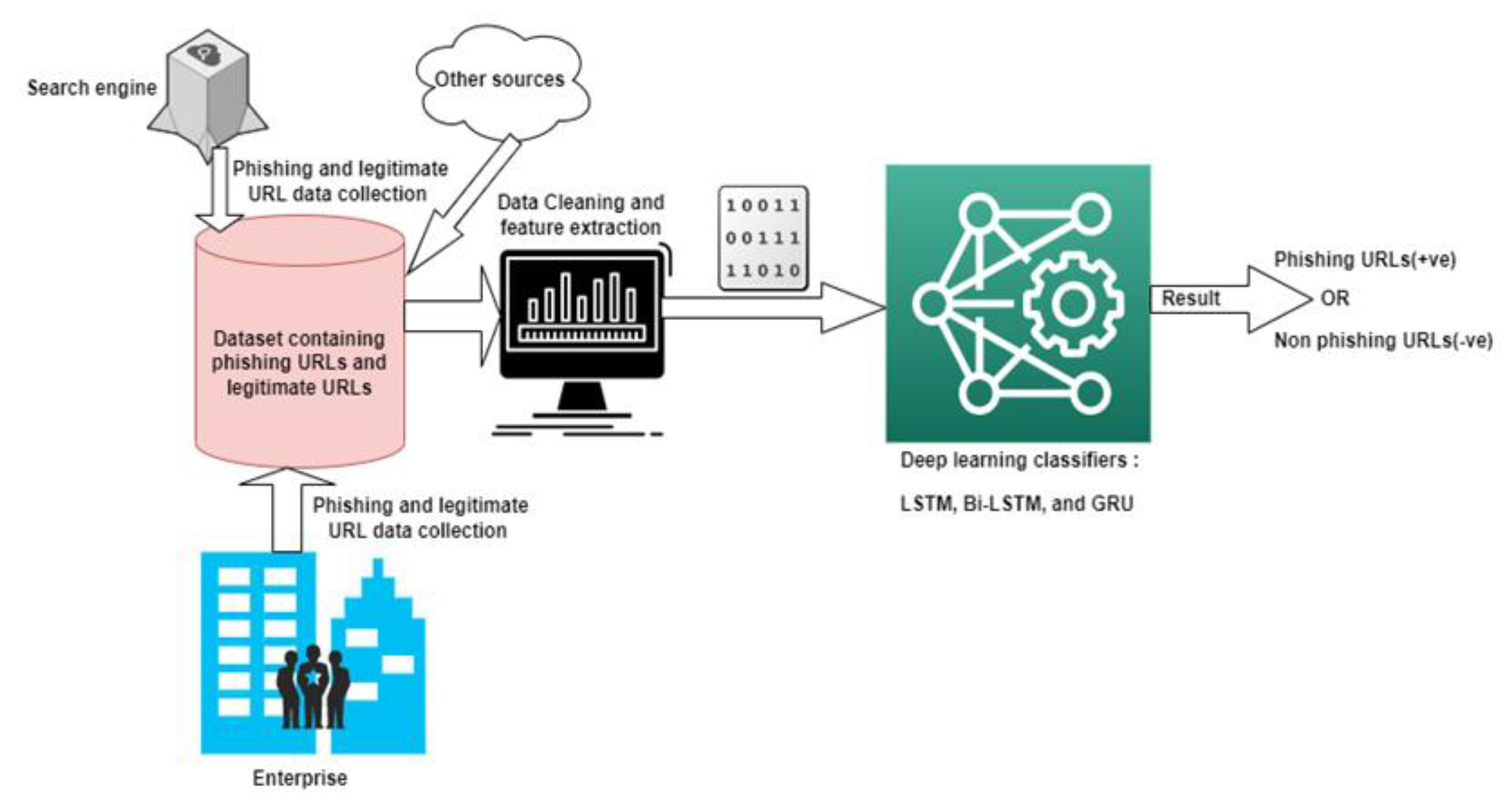
:1. Introduction
- In all web-based malicious activities, users are required to click a URL; using this URL’s information, we aim to develop a deep learning model that detects malicious URLs.
- The URL is padded as a step of sequences; therefore, instead of RNN, we have proposed LSTM-based architectures such as LSTM, Bi-LSTM, and gated recurrent units (GRU), as RNNs are subject to the vanishing gradient problem. However, with the ability to better understand the URL input, Bi-LSTM has an edge in terms of accuracy in detecting malicious URLs. The performance of the proposed models LSTM, Bi-LSTM, and GRU was analyzed using different metrics, such as precision, recall, F1 score, and accuracy.
- The architecture and working steps of each proposed algorithm are demonstrated in detail, and a detailed comparative performance with other existing models is conducted.
- The proposed model can be used for real-time website detection.
2. Related Work
3. Proposed Models
3.1. Proposed Model I: Long Short-Term Memory (LSTM)
| Algorithm 1: Regular LSTM for phishing URL detection | ||
| Input | : | URL {….}, L = length of URL |
| Output | : | Phishing or legitimate (Y) |
| Step 1 | : | Begin |
| Step 2 | : | For t = 1 to L do |
| Step 3 | : | calculate the value of using Equation (1) |
| Step 4 | : | if = 0, then forget the information |
| Step 5 | : | else, the forget value is 1 keep the information |
| Step 6 | : | End if |
| Step 7 | : | Calculate an input gate value Equation (3) |
| Step 8 | : | Calculate the candidate key of another weight matrix in candidate memory cell Equation (4) |
| Step 9 | : | Calculate the cell state Equation (5) |
| Step 10 | : | Compute the value of the output cell state and multiply by tanh of C and store it in Equations (6) and (7) |
| Step 11 | : | return (, ) |
| Step 12 | : | End for |
| Step 13 | : | Y = SoftMax (,…) |
| Step 14 | : | End |
3.2. Proposed Model II: Bidirectional Long Short-Term Memory (Bi-LSTM)
| Algorithm 2: Bi-LSTM for phishing URL detection | ||
| Input | : | URL {….}, L = length of URL |
| Output | : | Phishing or legitimate (Y) |
| Step 1 | : | Begin |
| Step 2 | : | For t = 1 to L do Compute forward layer output sequence Equation (8) |
| Step 3 | : | End for |
| Step 4 | : | For t = L to 1 do Compute backward layer output sequence Equation (9) |
| Step 5 | : | End for |
| Step 6 | : | Obtain Y by merging and using sigmoid activation function |
| Step 7 | : | End |
3.3. Proposed Model III: Gated Recurrent Unit (GRU)-Based RNN
| Algorithm 3: GRU-based RNN for phishing URL detection | ||
| Input | : | URL {….}, L = length of URL |
| Output | : | Phishing or legitimate (Y) (Y = 0: Legitimate, Y = 1: Malicious) |
| Step 1 | : | Begin |
| Step 2 | : | For each URL do |
| Step 3 | : | and merge and pass through a sigmoid function and the result stored in , Equation (11). |
| Step 4 | : | (different biases and weights Equation (12) |
| Step 5 | : | and pass their output through a tanh function Equation (13) |
| Step 6 | : | from a vector containing all 1s and multiply it with the previous hidden state. |
| Step 7 | : | . |
| Step 8 | : | Equation (14) |
| Step 9 | : | End for |
| Step 10 | : | |
| Step 11 | : | End |
4. Experimental Work and Results
4.1. Dataset
4.2. Data Preprocessing
4.3. Result and Discussion
4.3.1. Performance Metrics
4.3.2. Evaluation of the Proposed Models
4.3.3. Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Warburton, D. Phishing Attacks Soar 220% During COVID-19 Peak as Cybercriminal Opportunism Intensifies. Available online: https://www.f5.com/company/news/features/phishing-attacks-soar-220--during-covid-19-peak-as-cybercriminal (accessed on 27 January 2022).
- Bitaab, M.; Cho, H.; Oest, A.; Zhang, P.; Sun, Z.; Pourmohamad, R.; Kim, D.; Bao, T.; Wang, R.; Shoshitaishvili, Y.; et al. Scam Pandemic: How Attackers Exploit Public Fear through Phishing. In Proceedings of the APWG Symposium on Electronic Crime Research (eCrime), Boston, MA, USA, 16–19 November 2020; pp. 1–10. [Google Scholar]
- Agrawal, P.; Mangal, D. A Novel Approach for Phishing URLs Detection. Int. J. Sci. Res. (IJSR) 2015, 5, 1117–1122. [Google Scholar] [CrossRef]
- Rekouche, K. Early phishing. arXiv 2011, arXiv:1106.4692. [Google Scholar]
- Gupta, B.B.; Arachchilage, N.A.G.; Psannis, K.E. Defending against phishing attacks: Taxonomy of methods, current issues and future directions. Telecommun. Syst. 2017, 67, 247–267. [Google Scholar] [CrossRef] [Green Version]
- Chung, J.; Koay, J.-Z.; Leau, Y.-B. A Review on Social Media Phishing: Factors and Countermeasures BT—Advances in Cyber Security. In Proceedings of the International Conference on Advances in Cyber Security, Penang, Malaysia, 8–9 December 2020; pp. 657–673. [Google Scholar]
- Dinler, Ö.B.; Şahin, C.B. Prediction of phishing web sites with deep learning using WEKA environment. Avrupa Bilim Teknol. Dergisi. 2021, 24, 35–41. [Google Scholar] [CrossRef]
- Carroll, F.; Adejobi, J.A.; Montasari, R. How Good Are We at Detecting a Phishing Attack? Investigating the Evolving Phishing Attack Email and Why It Continues to Successfully Deceive Society. SN Comput. Sci. 2022, 3, 170. [Google Scholar] [CrossRef]
- Sheng, S.; Wardman, B.; Warner, G.; Cranor, L.F.; Hong, J.; Zhang, C. An empirical analysis of phishing blacklists. In Proceedings of the 6th Conference on Email and Anti-Spam, Mountain View, CA, USA, 16–17 July 2009. [Google Scholar]
- Rao, R.S.; Vaishnavi, T.; Pais, A.R. CatchPhish: Detection of phishing websites by inspecting URLs. J. Ambient. Intell. Humaniz. Comput. 2019, 11, 813–825. [Google Scholar] [CrossRef]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minocha, S.; Singh, B. A novel phishing detection system using binary modified equilibrium optimizer for feature selection. Comput. Electr. Eng. 2022, 98, 107689. [Google Scholar] [CrossRef]
- Balogun, A.O.; Adewole, K.S.; Raheem, M.O.; Akande, O.N.; Usman-Hamza, F.E.; Mabayoje, M.A.; Akintola, A.G.; Asaju-Gbolagade, A.W.; Jimoh, M.K.; Jimoh, R.G.; et al. Improving the phishing website detection using empirical analysis of Function Tree and its variants. Heliyon 2021, 7, e07437. [Google Scholar] [CrossRef]
- Xiao, X.; Xiao, W.; Zhang, D.; Zhang, B.; Hu, G.; Li, Q.; Xia, S. Phishing websites detection via CNN and multi-head self-attention on imbalanced datasets. Comput. Secur. 2021, 108, 102372. [Google Scholar] [CrossRef]
- Li, T.; Kou, G.; Peng, Y. Improving malicious URLs detection via feature engineering: Linear and nonlinear space transformation methods. Inf. Syst. 2020, 91, 101494. [Google Scholar] [CrossRef]
- Abedin, N.F.; Bawm, R.; Sarwar, T.; Saifuddin, M.; Rahman, M.A.; Hossain, S. Phishing Attack Detection using Machine Learning Classification Techniques. In Proceedings of the 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi, India, 3–5 December 2020; pp. 1125–1130. [Google Scholar] [CrossRef]
- Haynes, K.; Shirazi, H.; Ray, I. Lightweight URL-based phishing detection using natural language processing transformers for mobile devices. Procedia Comput. Sci. 2021, 191, 127–134. [Google Scholar] [CrossRef]
- Feng, F.; Zhou, Q.; Shen, Z.; Yang, X.; Han, L.; Wang, J. The application of a novel neural network in the detection of phishing websites. J. Ambient Intell. Humaniz. Comput. 2018, 1–15. [Google Scholar] [CrossRef]
- Smadi, S.; Aslam, N.; Zhang, L. Detection of online phishing email using dynamic evolving neural network based on reinforcement learning. Decis. Support Syst. 2018, 107, 88–102. [Google Scholar] [CrossRef] [Green Version]
- Babagoli, M.; Aghababa, M.P.; Solouk, V. Heuristic nonlinear regression strategy for detecting phishing websites. Soft Comput. 2018, 23, 4315–4327. [Google Scholar] [CrossRef]
- Rao, R.S.; Pais, A.R. Detection of phishing websites using an efficient feature-based machine learning framework. Neural Comput. Appl. 2018, 31, 3851–3873. [Google Scholar] [CrossRef]
- Yasin, A.; Abuhasan, A. An Intelligent Classification Model for Phishing Email Detection. Int. J. Netw. Secur. Its Appl. 2016, 8, 55–72. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training Recurrent Neural Networks. In Proceedings of the 30th International Conference on International Conference on Machine Learning ICML, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Ilya, S.; Oriol, V.; Quoc, V.L. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2 (NIPS’14); MIT Press: Cambridge, MA, USA, 2014; pp. 3104–3112. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Le, X.H.; Ho, H.V.; Lee, G.; Jung, S. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef] [Green Version]
- Rahman, L.; Mohammed, N.; Al Azad, A.K. A new LSTM model by introducing biological cell state. In Proceedings of the 2016 3rd International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Dhaka, Bangladesh, 22–24 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N.; Mohamed, A. Hybrid Speech Recognition with Deep Bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Han, P.; Wang, W.; Shi, Q.; Yang, J. Real-time Short-Term Trajectory Prediction Based on GRU Neural Network. In Proceedings of the IEEE/AIAA 38th Digital Avionics Systems Conference (DASC), San Diego, CA, USA, 8–12 September 2019. [Google Scholar] [CrossRef]
- Irie, K.; Tüske, Z.; Alkhouli, T.; Schlüter, R.; Ney, H. LSTM, GRU, highway and a bit of attention: An empirical overview for language modeling in speech recognition. In Proceedings of the 17th Annual Conference of the International Speech Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 3519–3523. [Google Scholar] [CrossRef]
- Wright, R.E. Logistic regression. In Reading and Understanding Multivariate Statistics; Grimm, L.G., Yarnold, P.R., Eds.; American Psychological Association: Washington DC, USA, 1995; pp. 217–244. [Google Scholar]
- Rahman, M.M.; Watanobe, Y.; Nakamura, K. A bidirectional LSTM language model for code evaluation and repair. Symmetry. 2021, 13, 247. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K. Xgboost: Extreme Gradient Boosting. Available online: https://cran.microsoft.com/snapshot/2017-12-11/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 11 September 2022).
- Kibriya, A.M.; Frank, E.; Pfahringer, B.; Holmes, G. Multinomial naive bayes for text categorization revisited. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Cairns, Australia, 4–6 December 2004; pp. 488–499. [Google Scholar]
- Kumar, S.; Sharma, A.; Reddy, B.K.; Sachan, S.; Jain, V.; Singh, J. An intelligent model based on integrated inverse document frequency and multinomial Naive Bayes for current affairs news categorization. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 1341–1355. [Google Scholar] [CrossRef]
- Peterson, L.E. K-Nearest Neighbor. Available online: http://scholarpedia.org/article/K-nearest_neighbor (accessed on 27 January 2022).
- Xu, H.; Zhang, L.; Li, P.; Zhu, F. Outlier detection algorithm based on k-nearest neighbors-local outlier factor. J. Algorithms Comput. Technol. 2022, 16, 17483026221078111. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | |||
|---|---|---|---|
| 0 (Legitimate) | 1 (Malicious) | ||
| Actual class | 0 (legitimate) | True negative (TN) | False positive (FP) |
| 1 (malicious) | False negative (FN) | True positive (TP) | |
| Model | Accuracy (%) |
|---|---|
| LSTM | 96.9 |
| Bi-LSTM | 99.0 |
| GRU | 97.5 |
| Algorithm | Class | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|---|
| LSTM | Legitimate | 0.99 | 0.96 | 0.97 | 0.97 |
| Malicious | 0.94 | 0.99 | 0.96 | ||
| Bi-LSTM | Legitimate | 0.99 | 0.99 | 0.99 | 0.99 |
| Malicious | 0.99 | 0.99 | 0.99 | ||
| GRU | Legitimate | 0.99 | 0.97 | 0.98 | 0.98 |
| Malicious | 0.95 | 0.99 | 0.97 | ||
| LR | Legitimate | 0.96 | 0.91 | 0.93 | 0.96 |
| Malicious | 0.96 | 0.99 | 0.98 | ||
| XGBOOST | Legitimate | 0.96 | 0.48 | 0.64 | 0.85 |
| Malicious | 0.83 | 0.99 | 0.90 | ||
| MNB | Legitimate | 0.94 | 0.91 | 0.93 | 0.957 |
| Malicious | 0.97 | 0.98 | 0.97 | ||
| KNN | Legitimate | 0.81 | 0.96 | 0.88 | 0.92 |
| Malicious | 0.98 | 0.91 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, S.S.; Awad, A.I.; Amare, L.A.; Erkihun, M.T.; Anas, M. Multimodel Phishing URL Detection Using LSTM, Bidirectional LSTM, and GRU Models. Future Internet 2022, 14, 340. https://doi.org/10.3390/fi14110340
Roy SS, Awad AI, Amare LA, Erkihun MT, Anas M. Multimodel Phishing URL Detection Using LSTM, Bidirectional LSTM, and GRU Models. Future Internet. 2022; 14(11):340. https://doi.org/10.3390/fi14110340
Chicago/Turabian StyleRoy, Sanjiban Sekhar, Ali Ismail Awad, Lamesgen Adugnaw Amare, Mabrie Tesfaye Erkihun, and Mohd Anas. 2022. "Multimodel Phishing URL Detection Using LSTM, Bidirectional LSTM, and GRU Models" Future Internet 14, no. 11: 340. https://doi.org/10.3390/fi14110340
APA StyleRoy, S. S., Awad, A. I., Amare, L. A., Erkihun, M. T., & Anas, M. (2022). Multimodel Phishing URL Detection Using LSTM, Bidirectional LSTM, and GRU Models. Future Internet, 14(11), 340. https://doi.org/10.3390/fi14110340