
NextDet: Efficient Sparse-to-Dense Object Detection with Attentive Feature Aggregation


Abstract
:1. Introduction
- An efficient and a powerful object detector is being proposed which can be trained on a single GPU.
- The remainder of this paper has been partitioned as follows: Section 2 provides the reader a detailed information about object detection models in general and its related works. Section 3 defines the methodology of the proposed NextDet object detection network. Section 4 evaluates the NextDet object detector by benchmarking on different datasets and Section 5 concludes this paper.
2. Anatomy of Object Detectors and Related Works
- Input: Images
- Neck:
- Head:
3. NextDet
3.1. Backbone
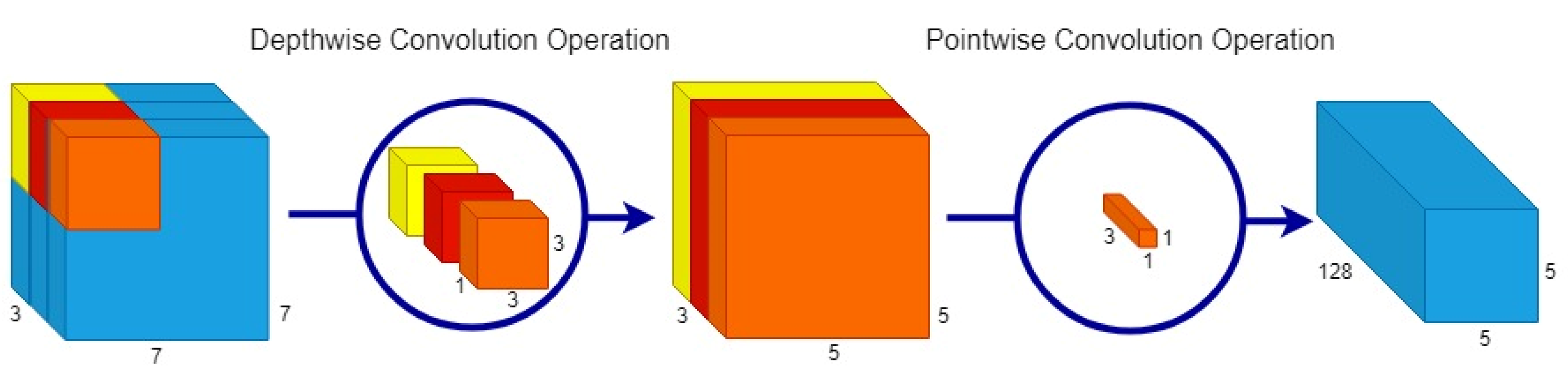
3.1.1. CondenseNeXt CNN
3.2. Neck
3.2.1. FPN and PAN
3.2.2. SPP
3.3. Head
3.4. Bounding Box Regression
4. Experimental Analysis
4.1. Datasets
4.1.1. Argoverse-HD
4.1.2. COCO
4.2. Model Evaluation Metrics
- Calculating the predicted bounding box and the ground-truth bounding box ratio: IoU defined in (7) is utilized to calculate this ratio of overlap. If the calculated IoU value is greater than a pre-determined threshold, it is determined that the object detector has detected the target object within an image successfully.
- Matching the ground-truth and predicted bounding box class labels: After it is determined that an object has been successfully detected in step 1, class label of the predicted bounding box is matched to the ground-truth bounding box accordingly.
4.3. Experiment Setup
- NVIDIA Tesla V100 PCIe 32 GB GPU
- Intel 6248 2.5 GHz 20-core CPU
- 1.92 TB solid-state drive
- 768 GB of RAM
- PyTorch 1.12.1
- Python 3.7.9
- CUDA 11.3
4.4. Experiment Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, Y.; Li, X.; Luo, H.; Yin, S.; Kaynak, O. Quo Vadis Artificial Intelligence? Discov. Artif. Intell. 2022, 2, 4. [Google Scholar] [CrossRef]
- Pang, Y.; Cao, J. Deep Learning in Object Detection. In Deep Learning in Object Detection and Recognition; Jiang, X., Hadid, A., Pang, Y., Granger, E., Feng, X., Eds.; Springer: Singapore, 2019; pp. 19–57. ISBN 978-981-10-5152-4. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kalgaonkar, P.; El-Sharkawy, M. CondenseNeXt: An Ultra-Efficient Deep Neural Network for Embedded Systems. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Virtual Conference, 27–30 January 2021; pp. 524–528. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Argoverse-HD. Available online: https://www.kaggle.com/datasets/mtlics/argoversehd (accessed on 23 September 2022).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 July 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kim, J.; Sung, J.-Y.; Park, S. Comparison of Faster-RCNN, YOLO, and SSD for Real-Time Vehicle Type Recognition. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics—Asia (ICCE-Asia), Seoul, Korea, 1–3 November 2020; pp. 1–4. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 346–361. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 404–419. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Huang, G.; Liu, S.; Maaten, L.V.D.; Weinberger, K.Q. CondenseNet: An Efficient DenseNet Using Learned Group Convolutions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2752–2761. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3 2019. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Du, X.; Lin, T.-Y.; Jin, P.; Ghiasi, G.; Tan, M.; Cui, Y.; Le, Q.V.; Song, X. SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- YOLOv5 Documentation. Available online: https://docs.ultralytics.com/ (accessed on 23 September 2022).
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Krizhevsky, A. Convolutional Deep Belief Networks on CIFAR-10. 2012; 9, Unpublished manuscript. [Google Scholar]
- Alkhouly, A.A.; Mohammed, A.; Hefny, H.A. Improving the Performance of Deep Neural Networks Using Two Proposed Activation Functions. IEEE Access 2021, 9, 82249–82271. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding Bag-of-Words Model: A Statistical Framework. Int. J. Mach. Learn. & Cyber. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Chang, M.-F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D Tracking and Forecasting With Rich Maps. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8740–8749. [Google Scholar]
- Padilla, R.; Passos, W.L.; Dias, T.L.B.; Netto, S.L.; da Silva, E.A.B. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Available online: https://proceedings.neurips.cc/paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf (accessed on 10 October 2022).
- Stewart, C.A.; Welch, V.; Plale, B.; Fox, G.; Pierce, M.; Sterling, T. Indiana University Pervasive Technology Institute. Available online: https://scholarworks.iu.edu/dspace/handle/2022/21675 (accessed on 10 October 2022).
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Number of Classes | Number of Images | Resolution | Class Overlap | |
|---|---|---|---|---|---|---|
| Train | Test | |||||
| Argoverse-HD | Road | 8 | 39,384 | 15,062 | 1200 × 1920 | True |
| COCO | Common | 80 1 | 118,287 | 5000 | Multi-scale | True |
| Architecture Name | Backbone | Mean Precision | mAP | AP50 | AP75 |
|---|---|---|---|---|---|
| NextDet | CondenseNeXt | 61.90% | 35.10% | 48.95% | 38.20% |
| NextDet + FPN | CondenseNeXt | 58.06% | 33.88% | 45.16% | 36.91% |
| NextDet-SAM | CondenseNeXt | 59.70% | 34.49% | 45.82% | 37.20% |
| ShuffDet + PAN | ShuffleNet | 58.31% | 30.30% | 42.21% | 32.95% |
| ShuffDet + FPN | ShuffleNet | 53.95% | 28.97% | 40.80% | 31.54% |
| Mob3Det + PAN | MobileNetv3 | 54.80% | 29.90% | 41.57% | 32.53% |
| Mob3Det + FPN | MobileNetv3 | 52.97% | 28.56% | 40.09% | 31.05% |
| Architecture Name | Backbone | Mean Precision | mAP | AP50 | AP75 |
|---|---|---|---|---|---|
| NextDet | CondenseNeXt | 66.80% | 58.00% | 81.63% | 63.73% |
| NextDet + FPN | CondenseNeXt | 64.86% | 56.76% | 79.65% | 61.87% |
| NextDet-SAM | CondenseNeXt | 65.36% | 57.14% | 80.41% | 62.27% |
| ShuffDet + PAN | ShuffleNet | 59.40% | 51.10% | 72.40% | 56.33% |
| ShuffDet + FPN | ShuffleNet | 57.51% | 50.78% | 71.02% | 55.00% |
| Mob3Det + PAN | MobileNetv3 | 54.50% | 50.60% | 70.95% | 54.69% |
| Mob3Det + FPN | MobileNetv3 | 53.83% | 50.12% | 70.18% | 54.23% |
| Light-Weight CNN | FLOPs 1 | Parameters | Top-1 Accuracy 2 |
|---|---|---|---|
| CondenseNeXt | 26.8 million | 0.16 million | 92.28% |
| ShuffleNet | 43.43 million | 0.25 million | 91.48% |
| MobileNetv3 | 36.34 million | 1.84 million | 88.93% |
| Architecture Name | Description |
|---|---|
| NextDet | The proposed NextDet architecture in this paper. |
| NextDet + FPN | NextDet architecture with FPN network only. |
| NextDet-SAM | NextDet architecture without spatial attention modules. |
| ShuffDet + PAN | NextDet architecture with ShuffleNet backbone and PAN network. |
| ShuffDet + FPN | NextDet architecture with ShuffleNet backbone and FPN network. |
| Mob3Det + PAN | NextDet architecture with MobileNetv3 backbone and PAN network. |
| Mob3Det + FPN | NextDet architecture with MobileNetv3 backbone and FPN network. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalgaonkar, P.; El-Sharkawy, M. NextDet: Efficient Sparse-to-Dense Object Detection with Attentive Feature Aggregation. Future Internet 2022, 14, 355. https://doi.org/10.3390/fi14120355
Kalgaonkar P, El-Sharkawy M. NextDet: Efficient Sparse-to-Dense Object Detection with Attentive Feature Aggregation. Future Internet. 2022; 14(12):355. https://doi.org/10.3390/fi14120355
Chicago/Turabian StyleKalgaonkar, Priyank, and Mohamed El-Sharkawy. 2022. "NextDet: Efficient Sparse-to-Dense Object Detection with Attentive Feature Aggregation" Future Internet 14, no. 12: 355. https://doi.org/10.3390/fi14120355
APA StyleKalgaonkar, P., & El-Sharkawy, M. (2022). NextDet: Efficient Sparse-to-Dense Object Detection with Attentive Feature Aggregation. Future Internet, 14(12), 355. https://doi.org/10.3390/fi14120355