
Survey on Videos Data Augmentation for Deep Learning Models



Abstract
:
1. Introduction
2. Methods Used and Overview of the Literature
- 1.
- An initial search was performed, resulting in a collection of 570 publications. The criteria used to select a paper were the following:
- (a)
- title, abstract or main text must contain the set of words (“video” “data augmentation”) or (“video” “synthetic” “data” “generation”) or (“video” “simulation” “data” “generation”)
- (b)
- papers must be published from 2012 to 2022;
- (c)
- papers must be written in English;
- (d)
- book chapters were excluded.
- 2.
- Duplicated entries and papers with the titles and abstracts not relevant with the topic were removed, resulting in a pruned set of 76 papers.
- 3.
- The full text of the remaining 76 paper was evaluated. Several of the papers applied standard image data augmentation strategies without focusing specifically on the problem of video data augmentation. For this reason, only 33 papers were finally selected.
- 4.
- The set of 33 papers was extended with two more papers which we felt had an impact on the survey. The final number of paper selected for the review is 35.
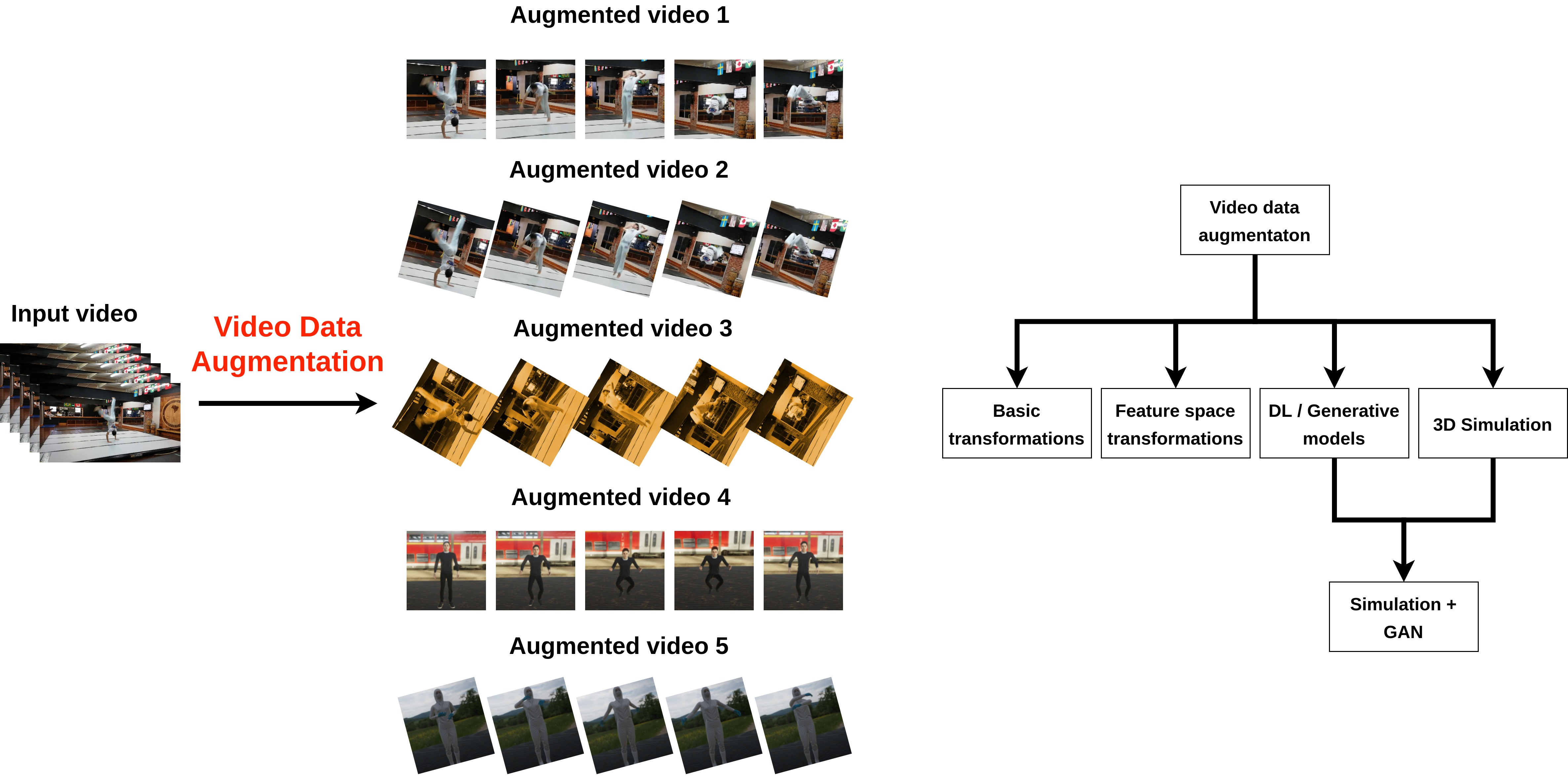
3. Review on Video Data Augmentation
3.1. Basic Transformations
3.2. Feature Space
3.3. Dl Models
3.4. Simulation
3.5. Solving the Reality Gap (Simulation + GAN)
4. Future Directions and Conclusions
4.1. From Static Image to Video Data Augmentation
4.2. Future Directions
4.3. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiao, L.; Zhao, J. A survey on the new generation of deep learning in image processing. IEEE Access 2019, 7, 172231–172263. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Guan, H.; Liu, M. Domain adaptation for medical image analysis: A survey. IEEE Trans. Biomed. Eng. 2021, 69, 1173–1185. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25, Available online: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 14 February 2022).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. Available online: https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf (accessed on 14 February 2022).
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Tremblay, J.; To, T.; Sundaralingam, B.; Xiang, Y.; Fox, D.; Birchfield, S. Deep object pose estimation for semantic robotic grasping of household objects. arXiv 2018, arXiv:1809.10790. [Google Scholar]
- Technologies, U. Unity Homepage. Available online: https://unity.com/ (accessed on 14 February 2022).
- Games, E. Unreal Engine Homepage. Available online: https://www.unrealengine.com/en-US/ (accessed on 14 February 2022).
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yue-Hei Ng, J.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.; Chandraker, M. Desire: Distant future prediction in dynamic scenes with interacting agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 336–345. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Khalifa, N.E.; Loey, M.; Mirjalili, S. A comprehensive survey of recent trends in deep learning for digital images augmentation. Artif. Intell. Rev. 2021, 1–27. Available online: https://link.springer.com/article/10.1007/s10462-021-10066-4 (accessed on 14 February 2022). [CrossRef] [PubMed]
- Wang, X.; Wang, K.; Lian, S. A survey on face data augmentation for the training of deep neural networks. Neural Comput. Appl. 2020, 32, 15503–15531. [Google Scholar] [CrossRef] [Green Version]
- Chlap, P.; Min, H.; Vandenberg, N.; Dowling, J.; Holloway, L.; Haworth, A. A review of medical image data augmentation techniques for deep learning applications. J. Med. Imaging Radiat. Oncol. 2021, 65, 545–563. [Google Scholar] [CrossRef] [PubMed]
- Naveed, H. Survey: Image mixing and deleting for data augmentation. arXiv 2021, arXiv:2106.07085. [Google Scholar]
- Scopus. Scopus Homepage. Available online: https://www.scopus.com/ (accessed on 14 February 2022).
- Charalambous, C.; Bharath, A. A data augmentation methodology for training machine/deep learning gait recognition algorithms. In Proceedings of the British Machine Vision Conference 2016, BMVC 2016, York, UK, 19–22 September 2016; pp. 110.1–110.12. [Google Scholar]
- Wang, L.; Ge, L.; Li, R.; Fang, Y. Three-stream CNNs for action recognition. Pattern Recognit. Lett. 2017, 92, 33–40. [Google Scholar] [CrossRef]
- De Souza, C.; Gaidon, A.; Cabon, Y.; López, A. Procedural generation of videos to train deep action recognition networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2594–2604. [Google Scholar]
- Wang, W.; Shen, J.; Shao, L. Video Salient Object Detection via Fully Convolutional Networks. IEEE Trans. Image Process. 2018, 27, 38–49. [Google Scholar] [CrossRef] [Green Version]
- Griffith, E.; Mishra, C.; Ralph, J.; Maskell, S. A system for the generation of synthetic Wide Area Aerial surveillance imagery. Simul. Model. Pract. Theory 2018, 84, 286–308. [Google Scholar] [CrossRef] [Green Version]
- Lu, S.P.; You, J.; Ceulemans, B.; Wang, M.; Munteanu, A. Synthesis of Shaking Video Using Motion Capture Data and Dynamic 3D Scene Modeling. In Proceedings of the International Conference on Image Processing, ICIP, Athens, Greece, 7–10 October 2018; pp. 1438–1442. [Google Scholar]
- Dong, J.; Li, X.; Xu, C.; Yang, G.; Wang, X. Feature re-learning with data augmentation for content-based video recommendation. In Proceedings of the MM 2018—2018 ACM Multimedia Conference, Seoul, Korea, 22–26 October 2018; pp. 2058–2062. [Google Scholar]
- Angus, M.; Elbalkini, M.; Khan, S.; Harakeh, A.; Andrienko, O.; Reading, C.; Waslander, S.; Czarnecki, K. Unlimited Road-scene Synthetic Annotation (URSA) Dataset. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, ITSC, Maui, HI, USA, 4–7 November 2018; pp. 985–992. [Google Scholar]
- Aberman, K.; Shi, M.; Liao, J.; Liscbinski, D.; Chen, B.; Cohen-Or, D. Deep Video-Based Performance Cloning. Comput. Graph. Forum 2019, 38, 219–233. [Google Scholar] [CrossRef] [Green Version]
- Rimboux, A.; Dupre, R.; Daci, E.; Lagkas, T.; Sarigiannidis, P.; Remagnino, P.; Argyriou, V. Smart IoT cameras for crowd analysis based on augmentation for automatic pedestrian detection, simulation and annotation. In Proceedings of the 15th Annual International Conference on Distributed Computing in Sensor Systems, DCOSS 2019, Santorini Island, Greece, 29–31 May 2019; pp. 304–311. [Google Scholar]
- Fonder, M.; Van Droogenbroeck, M. Mid-air: A multi-modal dataset for extremely low altitude drone flights. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 553–562. [Google Scholar]
- Wu, D.; Chen, J.; Sharma, N.; Pan, S.; Long, G.; Blumenstein, M. Adversarial Action Data Augmentation for Similar Gesture Action Recognition. In Proceedings of the International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar]
- Sakkos, D.; Shum, H.; Ho, E. Illumination-based data augmentation for robust background subtraction. In Proceedings of the 2019 13th International Conference on Software, Knowledge, Information Management and Applications, SKIMA 2019, Island of Ulkulhas, Maldives, 26–28 August 2019. [Google Scholar]
- Li, J.; Yang, M.; Liu, Y.; Wang, Y.; Zheng, Q.; Wang, D. Dynamic hand gesture recognition using multi-direction 3D convolutional neural networks. Eng. Lett. 2019, 27, 490–500. [Google Scholar]
- Sakkos, D.; Ho, E.; Shum, H.; Elvin, G. Image editing-based data augmentation for illumination-insensitive background subtraction. J. Enterp. Inf. Manag. 2020. Available online: https://www.emerald.com/insight/content/doi/10.1108/JEIM-02-2020-0042/full/html (accessed on 14 February 2022). [CrossRef]
- Kwon, Y.; Petrangeli, S.; Kim, D.; Wang, H.; Park, E.; Swaminathan, V.; Fuchs, H. Rotationally-Temporally Consistent Novel View Synthesis of Human Performance Video. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 387–402. [Google Scholar]
- Chai, L.; Liu, Y.; Liu, W.; Han, G.; He, S. CrowdGAN: Identity-free Interactive Crowd Video Generation and Beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2020. Available online: https://www.computer.org/csdl/journal/tp/5555/01/09286483/1por0TYwZvG (accessed on 14 February 2022). [CrossRef]
- de Souza, C.; Gaidon, A.; Cabon, Y.; Murray, N.; López, A. Generating Human Action Videos by Coupling 3D Game Engines and Probabilistic Graphical Models. Int. J. Comput. Vis. 2020, 128, 1505–1536. [Google Scholar] [CrossRef] [Green Version]
- Namitha, K.; Narayanan, A.; Geetha, M. A Synthetic Video Dataset Generation Toolbox for Surveillance Video Synopsis Applications. In Proceedings of the 2020 IEEE International Conference on Communication and Signal Processing, ICCSP 2020, Nanjing, China, 10–12 January 2020; pp. 493–497. [Google Scholar]
- Isobe, T.; Han, J.; Zhuz, F.; Liy, Y.; Wang, S. Intra-Clip Aggregation for Video Person Re-Identification. In Proceedings of the International Conference on Image Processing, ICIP, Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2336–2340. [Google Scholar]
- Zhang, Y.; Jia, G.; Chen, L.; Zhang, M.; Yong, J. Self-Paced Video Data Augmentation by Generative Adversarial Networks with Insufficient Samples. In Proceedings of the MM 2020—28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1652–1660. [Google Scholar]
- Yun, S.; Oh, S.J.; Heo, B.; Han, D.; Kim, J. Videomix: Rethinking data augmentation for video classification. arXiv 2020, arXiv:2012.03457. [Google Scholar]
- Ye, Y.; Yang, K.; Xiang, K.; Wang, J.; Wang, K. Universal semantic segmentation for fisheye urban driving images. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 648–655. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Pixel-Wise Crowd Understanding via Synthetic Data. Int. J. Comput. Vis. 2021, 129, 225–245. [Google Scholar] [CrossRef]
- Hwang, H.; Jang, C.; Park, G.; Cho, J.; Kim, I. ElderSim: A Synthetic Data Generation Platform for Human Action Recognition in Eldercare Applications. arXiv 2020, arXiv:2010.14742. [Google Scholar] [CrossRef]
- Tsou, Y.Y.; Lee, Y.A.; Hsu, C.T. Multi-task Learning for Simultaneous Video Generation and Remote Photoplethysmography Estimation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Volume 12626, pp. 392–407. [Google Scholar]
- Wei, D.; Xu, X.; Shen, H.; Huang, K. GAC-GAN: A General Method for Appearance-Controllable Human Video Motion Transfer. IEEE Trans. Multimed. 2021, 23, 2457–2470. [Google Scholar] [CrossRef]
- Chen, Y.; Rong, F.; Duggal, S.; Wang, S.; Yan, X.; Manivasagam, S.; Xue, S.; Yumer, E.; Urtasun, R. GeoSim: Realistic Video Simulation via Geometry-Aware Composition for Self-Driving. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2021; pp. 7226–7236. [Google Scholar]
- Dong, J.; Wang, X.; Zhang, L.; Xu, C.; Yang, G.; Li, X. Feature Re-Learning with Data Augmentation for Video Relevance Prediction. IEEE Trans. Knowl. Data Eng. 2021, 33, 1946–1959. [Google Scholar] [CrossRef] [Green Version]
- Hu, L.; Huang, S.; Wang, S.; Liu, W.; Ning, J. Do We Really Need Frame-by-Frame Annotation Datasets for Object Tracking? In Proceedings of the MM 2021—29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 4949–4957. [Google Scholar]
- Kerim, A.; Celikcan, U.; Erdem, E.; Erdem, A. Using synthetic data for person tracking under adverse weather conditions. Image Vis. Comput. 2021, 111, 104187. [Google Scholar] [CrossRef]
- Varol, G.; Laptev, I.; Schmid, C.; Zisserman, A. Synthetic Humans for Action Recognition from Unseen Viewpoints. Int. J. Comput. Vis. 2021, 129, 2264–2287. [Google Scholar] [CrossRef]
- Hu, Y.T.; Wang, J.; Yeh, R.; Schwing, A. SAIL-VOS 3D: A synthetic dataset and baselines for object detection and 3d mesh reconstruction from video data. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 3359–3369. [Google Scholar]
- Bongini, F.; Berlincioni, L.; Bertini, M.; Del Bimbo, A. Partially Fake it Till you Make It: Mixing Real and Fake Thermal Images for Improved Object Detection. In Proceedings of the MM 2021—29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 5482–5490. [Google Scholar]
- Otberdout, N.; Daoudi, M.; Kacem, A.; Ballihi, L.; Berretti, S. Dynamic Facial Expression Generation on Hilbert Hypersphere with Conditional Wasserstein Generative Adversarial Nets. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 848–863. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Sadeghi, F.; Levine, S. Cad2rl: Real single-image flight without a single real image. arXiv 2016, arXiv:1611.04201. [Google Scholar]
- Blender. Blender Homepage. Available online: https://www.blender.org/ (accessed on 14 February 2022).
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/file/07563a3fe3bbe7e3ba84431ad9d055af-Paper.pdf (accessed on 14 February 2022).
- Siam, M.; Valipour, S.; Jagersand, M.; Ray, N. Convolutional gated recurrent networks for video segmentation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3090–3094. [Google Scholar]
- To, T.; Tremblay, J.; McKay, D.; Yamaguchi, Y.; Leung, K.; Balanon, A.; Cheng, J.; Hodge, W.; Birchfield, S. NDDS: NVIDIA Deep Learning Dataset Synthesizer. 2018. Available online: https://github.com/NVIDIA/Dataset_Synthesizer (accessed on 14 February 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Application Area | Data Augmentation Method | Model Tested | Dataset |
|---|---|---|---|---|
| Charalambous et al., 2016 [25] | Gait recognition | Simulated avatars animated with mocap data | SVM | Self collected |
| Wang et al., 2017 [26] | Action recognition | Temporal cropping | Three-stream CNN | UCF101, HMDB51, Hollywood2, Youtube |
| De Souza et al., 2017 [27] | Action recognition | Simulated scene (Unity) | TSN | UCF-101, HMDB-51 |
| Wang et al., 2018 [28] | Salient regions detection | Optical flow warping | Encoder/Decoder CNNs | FBMS, DAVIS |
| Griffith et al., 2018 [29] | Aerial surveillance | simulated wide area aerial imagery | - | - |
| Lu et al., 2018 [30] | Synthesis of Shaking Videos | Dynamic 3D scene modeling | - | - |
| Dong et al., 2018 [31] | Video recommendation | Feature space | InceptionV3 | Hulu Challenge 2018 |
| Angus et al., 2018 [32] | Road-scene synthetic annotation | Simulated road scenes | FCN, SegNet | URSAS (generated by the authors), CityScapes, PFB, Synthia |
| Aberman et al., 2019 [33] | Video-based cloning | Double branches GAN | - | - |
| Rimboux et al., 2019 [34] | Pedestrian detection | Background subtraction + 3D synthetic models of persons | ResNet-101, RPN+ | Town Centre |
| Fonder et al., 2019 [35] | Drone video analysis | Simulated aerial scenes (Unreal Engine and AirSim) | - | - |
| Wu et al., 2019 [36] | Action recognition | GAN for dynamic image generation | 2D and 3D CNNs | UCF101, KTH |
| Sakkos et al., 2019 [37] | Background subtraction | Changes in illumination | Encoder/Decoder CNN | SABS |
| Li et al., 2019 [38] | Hand gesture recognition | Temporal cropping | mdCNN | VIVA |
| Sakkos et al., 2020 [39] | Background subtraction | Changes in illumination | Encoder/Decoder CNN | SABS |
| Kwon et al., 2020 [40] | Novel view synthesis of human performance videos | Two-tower siamese encoder/decoder | - | MVHA, PVHM, ShapeNet |
| Chai et al., 2020 [41] | Crowd video generation | CrowdGAN | MCNN, CSRNet, SANet, CAN | Mall and FDST |
| De Souza et al., 2020 [42] | Action recognition | Simulated scene (Unity) | TSN | UCF-101, HMDB-51 |
| Namitha et al., 2020 [43] | Video surveillance | Coloured boxes superposition | - | Sherbrooke, i-Lids, M-30, Car |
| Isobe et al., 2020 [44] | Person re-identification | Random cropping, flipping and erasing | Swallow network | ILIDSVID, PRID 2011, MARS |
| Paper | Application Area | Data Augmentation Method | Model Tested | Dataset |
|---|---|---|---|---|
| Zhang et al., 2020 [45] | Video data augmentation | WGAN for dynamic image generation | 2D and 3D CNNs | LS-HMDB4 |
| Yun et al., 2020 [46] | Action recognition | Image mixing | SlowFast-50 | Mini-Kinetics |
| Ye et al., 2020 [47] | Semantic segmentation | Simulated fisheye model | SwiftNet-18 | CityScapes |
| Wang et al., 2021 [48] | Crowd understanding | Simulation + GAN | Several CNNs | ShanghaiTech A/B, UCF-CC-50, UCF-QNRF, WorldExpo′10, CityScapes |
| Hwang et al., 2021 [49] | Action recognition | Simulated scene and avatar (Unreal Engine) | Glimpse, ST-GCN, VA-CNN | ETRI-Activity3D, NTU RGB+D 120 |
| Tsou et al., 2021 [50] | Photoplethysmography Estimation | Encoder/Decoder deep networks | rPPG network (3DCNN) | PURE, UBFC-RPPG |
| Wei et al., 2021 [51] | Human video motion transfer | GAN | - | Self collected, iPER dataset |
| Chen et al., 2021 [52] | Self driving | Video images + 3D car models | PSPNet, DeepLabv3 | UrbanData (Collected by the authors) |
| Dong et al., 2021 [53] | Video relevance prediction | Feature space | InceptionV3 | Hulu Challenge 2018 |
| Hu et al., 2021 [54] | Object detection | Background extraction and geometrical transformations | ResNet-18, ResNet-50 | LaSOT, GOT-10k, TrackingNet, OTB-100, UAV123 |
| Kerim et al., 2021 [55] | Person tracking | Simulated scene (NOVA engine) | DiMP, ATOM, KYS, PrDiM | PTAW172Real, PTAW217Synt (Collected and generated by the authors) |
| Varol et al., 2021 [56] | Action recognition | Synthetic 3D human avatars generation | 3D ResNet-50 | RGB+D Dataset |
| Hu et al., 2021 [57] | Object tracking | Simulated scene (GTAV) | Pixel2Mesh, Pix2Vox, MeshR-CNN, Video2Mesh | SAIL-VOS 3D (proposed synthetic dataset), Pix3D. |
| Bongini et al., 2021 [58] | Object detection | - | YOLOv3 | FLIR ADAS |
| Otberdout et al., 2022 [59] | Facial expression generation | MotionGAN and TextureGAN | LSTM | CASIA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cauli, N.; Reforgiato Recupero, D. Survey on Videos Data Augmentation for Deep Learning Models. Future Internet 2022, 14, 93. https://doi.org/10.3390/fi14030093
Cauli N, Reforgiato Recupero D. Survey on Videos Data Augmentation for Deep Learning Models. Future Internet. 2022; 14(3):93. https://doi.org/10.3390/fi14030093
Chicago/Turabian StyleCauli, Nino, and Diego Reforgiato Recupero. 2022. "Survey on Videos Data Augmentation for Deep Learning Models" Future Internet 14, no. 3: 93. https://doi.org/10.3390/fi14030093
APA StyleCauli, N., & Reforgiato Recupero, D. (2022). Survey on Videos Data Augmentation for Deep Learning Models. Future Internet, 14(3), 93. https://doi.org/10.3390/fi14030093