
Automatic Detection of Sensitive Data Using Transformer- Based Classifiers




Abstract
:1. Introduction
- Personal data is all information relating to an identified or identifiable natural person, with particular reference to an identifier such as her/his name, identification number, location data, IP address, date and/or place of birth, or online identifier. These data items are usually relatively simple to retrieve using dictionaries or regular expressions, considering that they usually appear within well-established and easy-to-read data structures.
- Sensitive data, on the other hand, include personal data such as racial or ethnic origin, political opinions, religious or philosophical beliefs, trade union membership, data relating to one’s sexual life or sexual orientation, as well as data on present and future physical and mental health. This includes information on healthcare services regardless of the source, for example a doctor. These data types are hardly structured, and most frequently they are part of a document such as an email message, a review or a post. This makes it extremely difficult to know if a company is in possession of sensitive data, with the risk that they will not be properly protected.
2. General Data Protection Regulation
- Personal data: in the GDPR, article 4, paragraph 1:
Therefore, personal data involve any information that can lead to the identification of a natural person. The limits of this definition are still subject to debate: according to it, even a generic physical description of an individual, if too specific, could be treated as personal data. Direct information is the most common type of personal data, and it is easier to detect than its indirect counterpart.‘personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person; - Sensitive data: a special category of personal data that requires strict protection, as stated in the GDPR, article 9, paragraph 1:
The definition of sensitive data has been intentionally kept generic to include a broader group of information types.Processing of personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, or trade union membership, and the processing of genetic data, biometric data for the purpose of uniquely identifying a natural person, data concerning health or data concerning a natural person’s sex life or sexual orientation shall be prohibited. - Personal data relating to criminal convictions and offences: the processing of this personal data type must be kept under control of an official authority or authorised by Union or Member State laws providing for appropriate safeguards for the rights and freedoms of data subjects.
3. Background
3.1. Sensitive Data Discovery
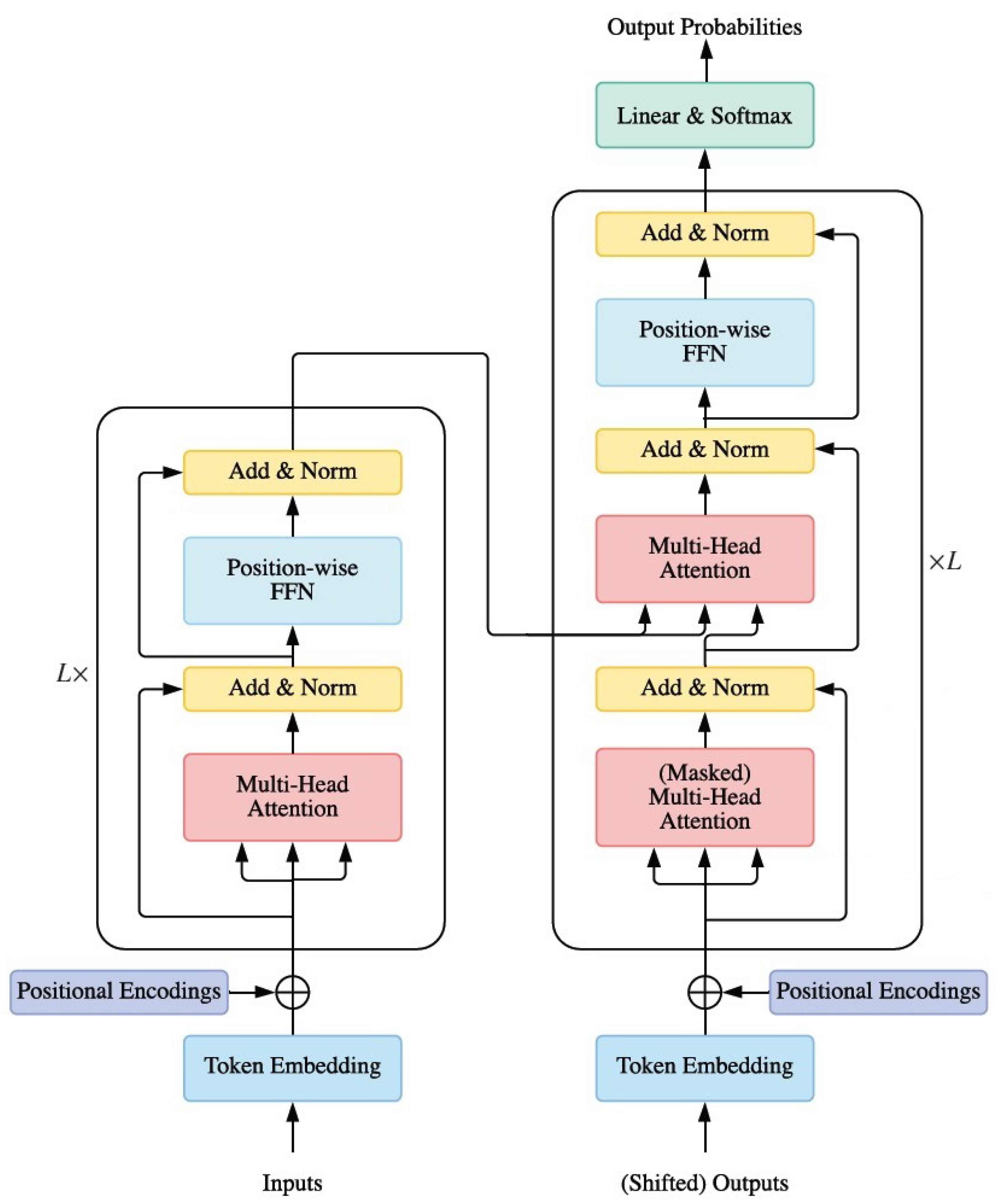
3.2. Transformers
- The matrix of queries , which contains the vector representation of a word within a sentence;
- The matrix of keys , which contains the vector representations of all words within a sentence;
- The matrix of values that are related to and, just like , are vector representations of all words within a sentence.
- Self-attention. In the Transformer encoder, we set Q = K = V = X in Equation (2), where X is the output of the previous layer.
- Masked Self-attention. In the Transformer decoder, self-attention is restricted so that queries at each position can only attend to all key-value pairs up to and including that position to enforce causality. To enable parallel training, this is typically obtained by applying a mask function to the non-normalized attention , where the positions that are not to be accessed are masked out by setting if . This kind of self-attention is often referred to as autoregressive or causal attention.
- Cross-attention. The queries are projected from the outputs of the previous decoder layer, whereas the keys and values are projected using the outputs of the encoder.
3.3. BERT
- BERT removes the unidirectional constraint by performing a Mask Language Model (MLM) task, which randomly masks some of the tokens from the input and tries to reconstruct (predict) the full original input. Unlike left-to-right language model pre-training, the objective of MLM enables the word representation to fuse the left and the right context, allowing one to pre-train a deep bidirectional Transformer. MLM is the key feature of BERT that has allowed it to outperform previous embedding methods.
- Many important tasks, such as Question Answering (QA) and Natural Language Inference (NLI), involve understanding the relationship between two sentences, denoted as 〈Sentence A, Sentence , which is not directly captured by language modeling. To train a model that understands sentence relationships, BERT is pre-trained on a binarized Next Sentence Prediction (NSP) task: when sentence pairs 〈SentenceA, Sentence are selected as pre-training examples, half of the time, B is the actual sentence following A, while, in the other cases, B is a random sentence taken from the sentence corpus. The model must then predict for each 〈Sentence A, Sentence pair whether Sentence B is the actual sentence following Sentence A.
- : it features 12 blocks of Transformers, a hidden layer with 768 neurons, 12 self-attention heads for a total size of the pre-trained model amounting to 110 million parameters.
- : it features 24 blocks of Transformers, a hidden layer with 1024 neurons, 16 self-attention heads for a total size of the pre-trained model amounting to 340 million parameters.
4. Problem Formulation
I’ve heard that John Doe had a heart attack last week and now he’s at the hospital.
- A sensitive topic, that is one of the topics described in the definition of sensitive data.
- Personal data that allow one to link the sensitive topic to a natural person.
5. Data Sets
- Politics: any argument related to the racial or ethnic origin of an individual, along with any political opinion or trade union membership.
- Health: any information related to physical and/or mental health.
- Religion: any topic related to religious or philosophical beliefs.
- Sexuality: any argument involving the sexual life or orientation of an individual.
5.1. Training Set
5.2. Test Set
6. Model Architectures
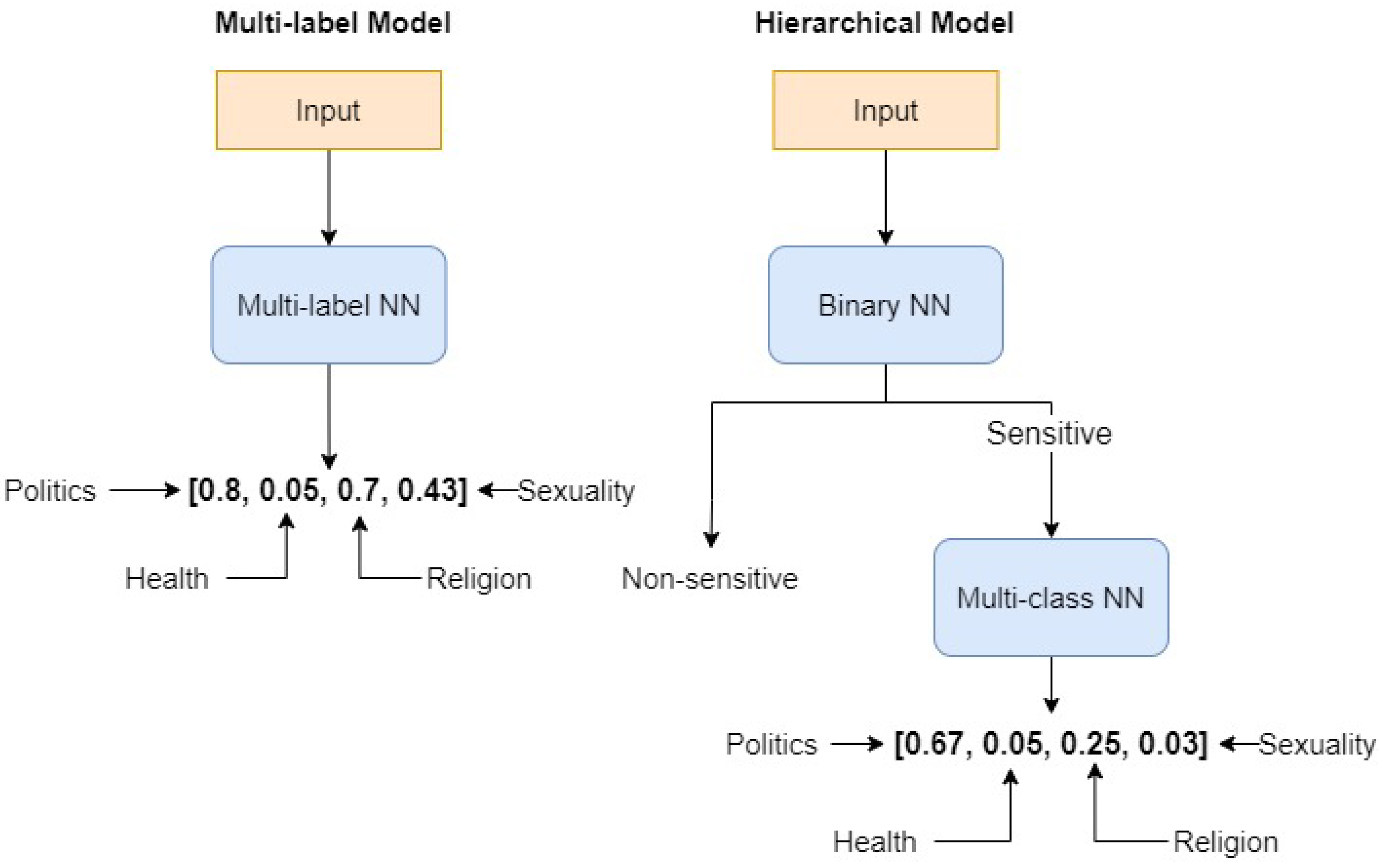
6.1. Flat Multi-Label Model
6.2. Hierarchical Model
- A binary classifier that determines whether a sentence contains sensitive topics.
- A multi-class classifier, activated only when the binary classifier detects a sensitive topic, that determines to which sensitive macro-category the sentence belongs.
6.3. Models’ Structure
- A pre-trained model that is fine-tuned over the training data set.
- A Dropout layer to prevent the BERT model from overfitting the training data.
- A Linear layer.
- The multi-label NN uses a sigmoid function, which is defined asThe sigmoid function is suited for multi-label models because the resulting outputs are independent of one another, thus allowing for the assignment of multiple labels (or no label at all) to the input data.
- The binary and the multi-class models both use a Softmax function, which is defined aswhere x is a vector of K real numbers. The Softmax function returns a probability distribution, which means that the outputs produced using this function are interrelated and add up to one, satisfying the formal requirements for representing probability distributions.
7. Training and Evaluation
8. Results
9. Conclusions
- In this project, we have applied a policy which determines that a document contains sensitive data if it meets both the following requirements:
- -
- It contains at least a sentence classified as containing a sensitive topic.
- -
- It refers to personal data, that is, any information that can point to a natural person.
According to our policy, these two elements do not necessarily need to be related with each other to consider the document sensitive. This made us focus mainly on the topic detection and classification task.This approach also allowed us to minimize false negatives, which is also a crucial requirement for the relevance of the negative effects such cases can have. Of course, it is not the most accurate strategy. Possible future research could study the development of a more accurate merging policy for the information that can be extracted from text within this context. Such a policy should take into account and analyze the relationships between sensitive topics and personal data more in depth. - Some of the sensitive topics, especially Politics and Sexuality, tend to change very rapidly due to the high social interest around them and to unpredictable events, such as the COVID-19 pandemic and the Ukrainian war, that make people’s general moods and beliefs change significantly and rapidly. Such events could lead to a decay in terms of the model’s ability to recognize the most up-to-date instances of sensitive topics. This could be likely to happen with the data set we have used, built from a single source (Reddit), despite considering many different sub-groups. It could be useful to analyze the model performance decay to apply proper continuous fine-tuning strategies.The topic of continual learning is, in fact, one of the hottest topics in machine learning.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GDPR | General Data Protection Regulation |
| EU | European Union |
| BERT | Bidirectional Encoder Representations from Transformers |
| NLP | Natural Language Processing |
| PTM | Pre-trained Model |
| FFN | Feed-Forward Network |
| ReLU | Rectified Linear Unit |
| HIT | Human Intelligence Task |
| RNN | Recurrent Neural Network |
References
- European Commission. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the Protection of Natural Persons with Regard to the Processing of Personal Data and on the Free Movement of Such Data, and Repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA Relevance); European Commission: Brussels, Belgium, 2016. [Google Scholar]
- Wachter, S. Normative challenges of identification in the Internet of Things: Privacy, profiling, discrimination, and the GDPR. Comput. Law Secur. Rev. 2018, 34, 436–449. [Google Scholar] [CrossRef]
- Mondschein, C.F.; Monda, C. The EU’s General Data Protection Regulation (GDPR) in a research context. In Fundamentals of Clinical Data Science; Springer: Cham, Switzerland, 2019; pp. 55–71. [Google Scholar]
- Kretschmer, M.; Pennekamp, J.; Wehrle, K. Cookie banners and privacy policies: Measuring the impact of the GDPR on the web. Acm Trans. Web (TWEB) 2021, 15, 1–42. [Google Scholar] [CrossRef]
- Bhaskar, R.; Laxman, S.; Smith, A.; Thakurta, A. Discovering frequent patterns in sensitive data. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 503–512. [Google Scholar]
- McSherry, F.; Talwar, K. Mechanism Design via Differential Privacy. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), Providence, RI, USA, 21–23 October 2007; pp. 94–103. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography; Halevi, S., Rabin, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Kužina, V.; Vušak, E.; Jović, A. Methods for Automatic Sensitive Data Detection in Large Datasets: A Review. In Proceedings of the 2021 44th International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 27 September–1 October 2021; pp. 187–192. [Google Scholar]
- Pattanayak, S.; Ludwig, S.A. Improving Data Privacy Using Fuzzy Logic and Autoencoder Neural Network. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Lafayette, LA, USA, 18–21 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Attaullah, H.; Anjum, A.; Kanwal, T.; Malik, S.U.R.; Asheralieva, A.; Malik, H.; Zoha, A.; Arshad, K.; Imran, M.A. F-classify: Fuzzy rule based classification method for privacy preservation of multiple sensitive attributes. Sensors 2021, 21, 4933. [Google Scholar] [CrossRef] [PubMed]
- Bucolo, M.; Fortuna, L.; La Rosa, M. Complex dynamics through fuzzy chains. IEEE Trans. Fuzzy Syst. 2004, 12, 289–295. [Google Scholar] [CrossRef]
- IBM Security Guardium Data Protection. Available online: https://www.ibm.com/products/ibm-guardium-data-protection (accessed on 27 July 2022).
- Azure Information Protection. Available online: https://azure.microsoft.com/solutions/information-protection/ (accessed on 27 July 2022).
- Rubrik. Available online: https://www.rubrik.com/ (accessed on 27 July 2022).
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. arXiv 2021, arXiv:2106.04554. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, L.; Kaiser, I. Attention is all you need. In Proceedings of the NIPS’16: Proceedings of the 30th International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Kaur, M.; Mohta, A. A Review of Deep Learning with Recurrent Neural Network. In Proceedings of the 2019 International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 27–29 November 2019; pp. 460–465. [Google Scholar] [CrossRef]
- Daniel Jurafsky, J.H.M. N-gram Language Models. Speech and Language Processing. 2021. Third edition draft. pp. 1–29. Available online: https://web.stanford.edu/~jurafsky/slp3/ed3book.pdf (accessed on 27 July 2022).
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 19–27. [Google Scholar]
- Angiani, G.; Cagnoni, S.; Chuzhikova, N.; Fornacciari, P.; Mordonini, M.; Tomaiuolo, M. Flat and Hierarchical Classifiers for Detecting Emotion in Tweets. In Proceedings of the AI*IA 2016 Advances in Artificial Intelligence: XVth International Conference of the Italian Association for Artificial Intelligence, Genova, Italy, 29 November–1 December 2016; Adorni, G., Cagnoni, S., Gori, M., Maratea, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 51–64. [Google Scholar]
- Tan, S.; Zhang, J. An empirical study of sentiment analysis for chinese documents. Expert Syst. Appl. 2008, 34, 2622–2629. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Politics | Health | Religion | Sexuality | |
|---|---|---|---|---|
| Sensitive topics | Ethnic origin Political beliefs Trade union membership | Genetic data Biometric data Health state | Religious beliefs Philosophical beliefs | Sexual life Sexual orientation |
| Subreddit | r/politics r/Libertarian r/ukpolitics r/Ethnicity r/union r/LabourUK r/socialism r/Conservative r/Labour r/Anarchism r/communism r/antiwork r/ConservativesOnly r/democrats r/DemocraticSocialism r/PoliticalCompass r/Republican r/PoliticsPeopleTwitter | r/Health r/healthcare r/mentalhealth r/medicalschool r/medicine r/Doctor r/biology r/Coronavirus r/nursing | r/religion r/Christianity r/Christian r/TrueChristian r/atheism r/islam r/philosophy r/Objectivism r/Buddhism r/askphilosophy r/PhilosophyofReligion r/Judaism r/Catholicism r/hinduism r/Izlam r/exmormon r/exmuslim | r/lgbt r/gay r/lesbian r/bisexual r/asktransgender r/transgender r/askgaybros r/actuallesbians r/ainbow r/LesbianActually r/gaybros r/LGBTeens r/queer r/sexuality r/sex r/relationships r/ldssexuality r/asexuality |
| Sensitive Topics | Generic Topics | Total | ||||
|---|---|---|---|---|---|---|
| Politics | Religion | Health | Sexuality | |||
| Samples | 6767 | 6073 | 6673 | 4048 | 23,978 | |
| Total | 23,561 | 23,978 | 47,539 | |||
| Sensitive Topics | Generic Topics | Total | ||||
|---|---|---|---|---|---|---|
| Politics | Religion | Health | Sexuality | |||
| Samples | 391 | 337 | 253 | 219 | 1200 | |
| Total | 1200 | 1200 | 2400 | |||
| Optimizer | Batch Size | Learning Rate | Dropout | ||
|---|---|---|---|---|---|
| Hierarchical | Binary | RMSprop | 32 | 1 × 10 | 0.3 |
| Multi-class | Adam | 32 | 1 × 10 | 0.5 | |
| Flat Multi-label | RMSprop | 16 | 1 × 10 | 0.3 |
| Precision | Recall | -Score | Runtime (s) | |
|---|---|---|---|---|
| Binary | 0.97 | 0.93 | 0.95 | 0.11 (±0.01) |
| Flat Multi-label | 0.96 | 0.92 | 0.94 | 0.12 (±0.01) |
| Precision | Recall | -Score | Runtime (s) | |
|---|---|---|---|---|
| Multi-class model | 0.94 | 0.94 | 0.94 | 0.11 (±0.01) |
| Health | 0.91 | 0.95 | 0.93 | |
| Politics | 0.96 | 0.92 | 0.94 | |
| Religion | 0.94 | 0.96 | 0.95 | |
| Sexuality | 0.94 | 0.93 | 0.93 | |
| Multi-label model | 0.95 | 0.87 | 0.91 | 0.12 (±0.01) |
| Health | 0.92 | 0.87 | 0.89 | |
| Politics | 1.00 | 0.81 | 0.90 | |
| Religion | 0.94 | 0.93 | 0.93 | |
| Sexuality | 0.94 | 0.89 | 0.91 |
| Text | Actual Class | Predicted Labels |
|---|---|---|
| I think they allow medical intervention in life and death cases, but I know someone who is a Christian Scientist and is not getting vaccinated. | Health | Health, Religion |
| Joe Biden literally said on national TV he would not trust a vaccine developed under the Trump administration. | Politics | Health, Politics |
| I wish people’s superstitious beliefs were not so often involved in politics, and I wish politicians did not feel the need to declare or pretend they are religious to gain support. | Religion | Politics, Religion |
| My family is not open to the idea of me being trans, but I already take antidepressants, so they aren not against me taking medication. | Sexuality | Health, Sexuality |
| Precision | Recall | -Score | Runtime (s) | |
|---|---|---|---|---|
| Hierarchical model | 0.92 | 0.93 | 0.92 | 0.13 (±0.01) |
| Other | 0.93 | 0.97 | 0.95 | |
| Health | 0.89 | 0.82 | 0.85 | |
| Politics | 0.93 | 0.86 | 0.89 | |
| Religion | 0.94 | 0.95 | 0.94 | |
| Sexuality | 0.91 | 0.86 | 0.89 | |
| Multi-label model | 0.91 | 0.91 | 0.91 | 0.12 (±0.01) |
| Other | 0.92 | 0.96 | 0.94 | |
| Health | 0.87 | 0.87 | 0.87 | |
| Politics | 0.94 | 0.81 | 0.87 | |
| Religion | 0.92 | 0.93 | 0.93 | |
| Sexuality | 0.90 | 0.89 | 0.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrolini, M.; Cagnoni, S.; Mordonini, M. Automatic Detection of Sensitive Data Using Transformer- Based Classifiers. Future Internet 2022, 14, 228. https://doi.org/10.3390/fi14080228
Petrolini M, Cagnoni S, Mordonini M. Automatic Detection of Sensitive Data Using Transformer- Based Classifiers. Future Internet. 2022; 14(8):228. https://doi.org/10.3390/fi14080228
Chicago/Turabian StylePetrolini, Michael, Stefano Cagnoni, and Monica Mordonini. 2022. "Automatic Detection of Sensitive Data Using Transformer- Based Classifiers" Future Internet 14, no. 8: 228. https://doi.org/10.3390/fi14080228
APA StylePetrolini, M., Cagnoni, S., & Mordonini, M. (2022). Automatic Detection of Sensitive Data Using Transformer- Based Classifiers. Future Internet, 14(8), 228. https://doi.org/10.3390/fi14080228