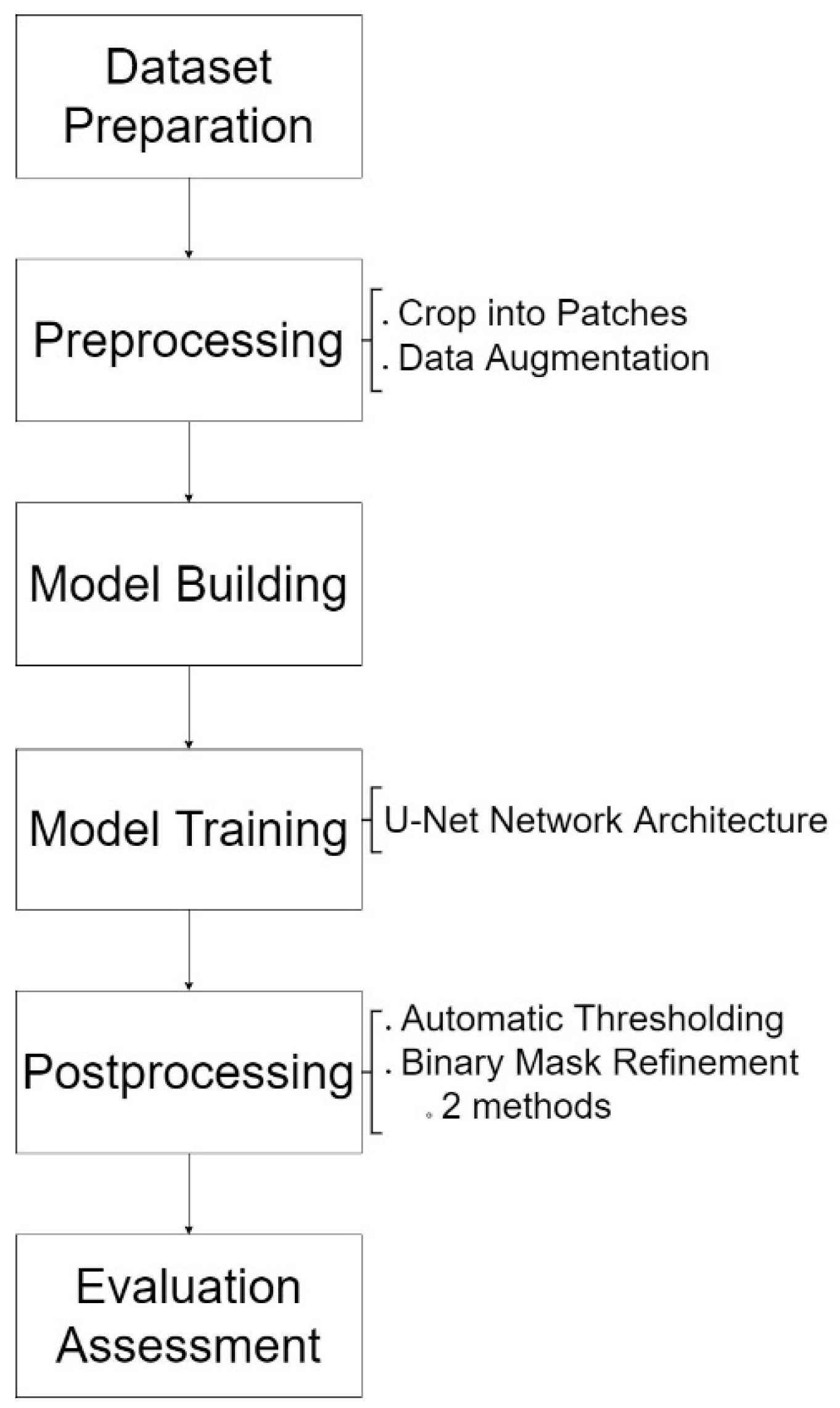
There has been a lot of research using various techniques to detect shadows as the importance of shadow detection in drone images has become more significant. Based on various research studies [
9,
10,
11], shadow detection methods in drone images can be divided into three categories, which are property-based methods, model-based methods, and machine learning methods.
2.2.1. Property-Based
Property-based methods mainly focus on detecting shadows based on shadow properties in images. Considering that shadow properties in images can be explored in different ways, property-based methods are then further classified into thresholding, invariant color model, and object segmentation. Thresholding is a simple image processing method that creates binary images by setting a pixel value threshold. The global thresholding and local thresholding [
12], bimodal histograms, and Otsu’s threshold [
13] are examples of approaches that are generally used due to the simplicity of the implementation. Unfortunately, there are a lot of weaknesses of these methods. Some thresholding methods apply various threshold values to different segments of the image [
12]. Moreover, implementation of the thresholding methods highly depends on prior knowledge of shadow properties. One of the shadow properties used is the significant changes in the red band of RGB components in the Optimized Shadow Index of the shadow region [
3].
For the invariant color model methods, color information is exploited for shadow detection by using invariant properties of some color spaces, such as CIELAB [
14] and C1C2C3 [
15]. The drawback of these methods is that they depend mainly on the knowledge of the presence of shadow in different channels of color model. Proposing an object-oriented method, [
16] performed a Gaussian Mixture Model to refine soft shadow and added the result to another result from image segmentation. While it managed to recover incomplete shapes and holes in the detected shadow, the accuracy obtained was not higher than 90%, while a lot of shadow analysis needed to be performed, such as clustering analysis. Another object-oriented segmentation approach was performed by [
17], who used shadow features in the image segmentation step, followed by extraction of shadow regions using the statistical features of the images. They also used spatial information to avoid false shadow detection, but it still faced difficulty detecting small shadows.
2.2.3. Machine Learning
Shadow detection using machine learning, a technique where a model is built and fit into data to accomplish a task, is a method that has been preferred recently. This is mainly because machine learning techniques require less knowledge of shadow properties and offer more flexibility in detection compared to older techniques. Machine learning techniques can be divided into three more categories, which are unsupervised learning, supervised learning, and deep learning.
Unsupervised learning is popular due to its simplicity of implementation, and it does not require sample data to train the model, which saves a lot of time on data preparation. Shadow detection using unsupervised learning is often implemented by clustering technique, where the pixels of the images are grouped by their similarities, and a cluster that possibly represents shadow is selected. An algorithm that can be seen to be popular for performing shadow detection in aerial images is K-Means. Ref. [
20] used improved K-Means, which is K-Means-AP, to solve the drawbacks of traditional K-Means, where the random number of clusters produces a random result. Another implementation was by [
21], which compared the clustering results of two algorithms, K-means and Gaussian Mixture Model (GMM), after preprocessing the image using morphological operations. While using unsupervised learning guaranteed some benefits, the accuracy of the detection still needed improvement, as it was prone to noise [
21].
Compared to unsupervised learning, supervised learning requires training samples to build classifiers, which usually produce more accurate detection in classification. The famous model used in shadow detection based on supervised learning is the Support Vector Machine (SVM). SVM is used to generate an initial map containing the classification of shadow class and non-shadow class. Various enhancements were also included in SVM, such as the implementation of LSSVM to reduce cross validation error [
22] and adding Extended Random Walker to reduce the noisiness result of SVM [
23].
As the machine learning field has been widely discussed to solve problems in visual information processing, implementation of deep learning in shadow detection has been a growing discussion, considering there are still many weaknesses shown in traditional unsupervised and supervised learning. Much research has discussed the implementation of deep learning in shadow detection, specifically in trying different neural network architectures and adding enhanced modules to achieve state-of-the-art results. When using drone images, deep learning has always been a consideration, as they usually produce very high-resolution images with complicated shadow areas. In deep learning, shadow detection is considered a semantic segmentation task, where each pixel is assigned as either shadow or non-shadow. Few works related to shadow detection in aerial images implementing deep learning have been studied. One of them proposed DSSDNet, a network that chose a deeply supervised CNN as its network architecture with the implementation of DSPF to improve model performance [
10]. Alongside proposing a new model with enhancement, this work also aimed to solve shadow detection in aerial image problems related to insufficient training datasets by creating a publicly available dataset called AISD. The images were captured using drones flying at high altitudes; thus, many small shadowed regions cast by objects such as vehicles are not clearly noticeable and are not labeled. This contribution allows many researchers to propose and test state-of-the-art methods using this dataset, which widens the possibilities for different aspects of enhancement within this topic. One of the research projects which used the AISD dataset was by [
4], who proposed the Edge-aware Spatial Pyramid Fusion network (ESPFNet) for enhancing the detection of salient shadows. One of the main components in this network is the parallel spatial pyramid structure, which extracts multiscale features from the input image. The approach to aggregate the feature representation was similar to the pooling operation used in PSPNet [
24]. Instead of aiming to detect the most noticeable shadows only, [
9] proposed a shadow detection network based on a multiscale spatial attention mechanism (MSASDNet) to solve false detection in weak illumination regions and small shadow regions.
Another architecture that is widely used in various types of segmentation tasks is U-Net. It is an architecture that performs well with a small training dataset and was proven to improve image localization [
25]. For shadow detection in aerial images, [
26] considered non-local spatial contextual information, and proposed GSCA-UNet, a model composed of a U-shaped encoder and decoder, and a GSCA module for flexibility. Much other research in shadow detection also chose to build network architecture inspired by U-Net, such as [
27,
28,
29], which indicates that U-Net architecture is one of the popular architectures in this domain. For this reason, given a small number of images, U-Net architecture is applied in this project to produce acceptable shadow detection results.
In the study, some limitations are identified to be further discussed, which are an insufficient training dataset, along with the need to spend too much time on dataset preparation due to complex shadow regions [
10], unexpected noises in the resulting shadow masks [
26], and inefficiency of trial-and-error post-processing steps [
4]. Instead of using existing annotated datasets, such as AISD, which exclude the labeling of small shadowed regions, a new dataset is prepared for this study to focus on low altitude aerial images. Through this process, this study contributes a new annotated dataset with more of a variety of images and allows for more method comparisons in the future.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}