
Machine Learning for Bankruptcy Prediction in the American Stock Market: Dataset and Benchmarks

 , ,
, ,  ,
, 

Abstract
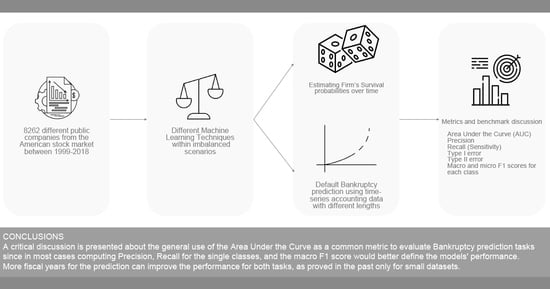
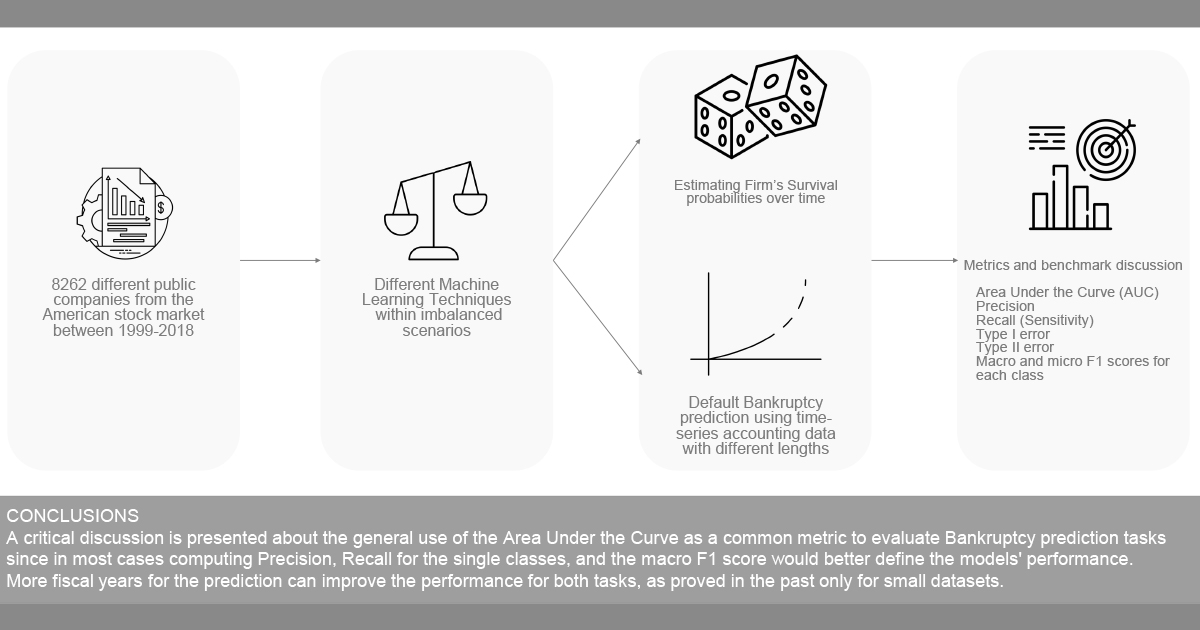
:
1. Introduction
- We collected a dataset for bankruptcy prediction considering 8262 different companies in the stock market in the time interval between 1999 and 2018. The dataset has been made public (https://github.com/sowide/bankruptcy_dataset, accessed on 14 August 2022) for the scientific community for further investigations as a benchmark and thus it can be easily enriched with data coming from other sources pertaining to the same companies. Our dataset faithfully followed the FAIR Data Principles [7]:
- (a)
- Findable: our data is indexed in a searchable resource and had a unique and persistent identifier.
- (b)
- Accessible: our data is understandable to humans and machines and it is deposited in a trusted repository.
- (c)
- Interoperable: we used a formal, accessible, shared, and broadly applicable language for knowledge representation.
- (d)
- Reusable: we provided accurate information on provenance and clear usage licenses.
- We investigated two different bankruptcy prediction tasks: The first task (T1) is the default prediction task which aims to predict the company status in the next year using time series of accounting data or just the last fiscal year available. The second task (T2) is the survival probability prediction task in which the model tries to predict the company status over k years in the future.
- In light of the results achieved, we critically discuss the most interesting metrics as proposed benchmarks for the future, such as: Area Under the Curve (AUC), precision, recall (sensitivity), type I error, type II error, and macro- and micro-F1 scores for each class.
2. Related Works
3. Dataset
- If the firm’s management files Chapter 11 of the Bankruptcy Code to “reorganize” its business: management continues to run the day-to-day business operations but all significant business decisions must be approved by a bankruptcy court.
- If the firm’s management files Chapter 7 of the Bankruptcy Code: the company stops all operations and goes completely out of business.
4. Machine-Learning Models
4.1. Support Vector Machine
4.2. Random Forest
4.3. Boosting Algorithms
- AdaBoost [40]: This was the first boosting algorithm developed for classification and regression tasks. It fits a sequence of weak learners on different weighted training data. It gives incorrect predictions more weight in sub-sequence iterations and less weight to correct predictions. In this way, it forces the algorithm to “focus” on observations that are harder to predict. The final prediction comes from weighing the majority vote or sum.The algorithm begins by forecasting the original dataset and giving the same weight to each observation. If the prediction is incorrect, using the first “weak” learner, the algorithm will give a higher weight value to that observation. This procedure is iterated until the model reaches a predefined value of accuracy.AdaBoost is typically easy to use because it does not need complex parameters during its tuning procedures and it shows low sensitivity to overfitting. Moreover, it is able to learn from a small set of features learning incrementally new information. However, Adaboost is sensitive to noisy data and abnormal values.
- Gradient Boosting [41]: This algorithm uses a set of weak predictive models, typically decision trees. Gradient Boosting trains many models sequentially that are then composed using the additive modeling property. In each training epoch, a new learner is added to increase the accuracy of the previous one. Each model gradually minimizes the whole system loss function using the Gradient Descent algorithm.
- XGBoost (Extreme Gradient Boosting) [42]: XGBoost is an optimized distributed Gradient Boosting library designed to be highly efficient, flexible, and portable. XGBoost minimizes a regularized (L1 and L2) objective function that combines a convex loss function based on the difference between the predicted and target outputs and a penalty term for model complexity. The training proceeds by adding new trees that predict the residuals or errors of prior trees that are then combined with previous trees to make the final prediction (4).where and are the regularization parameters and residuals computed with the i-th tree, respectively, and is a function that is trained to predict residuals, using X for the i-th tree.is computed using the residuals, solving the following optimization problem:where L(Y, F(X)) is a differentiable loss function.
4.4. Logistic Regression
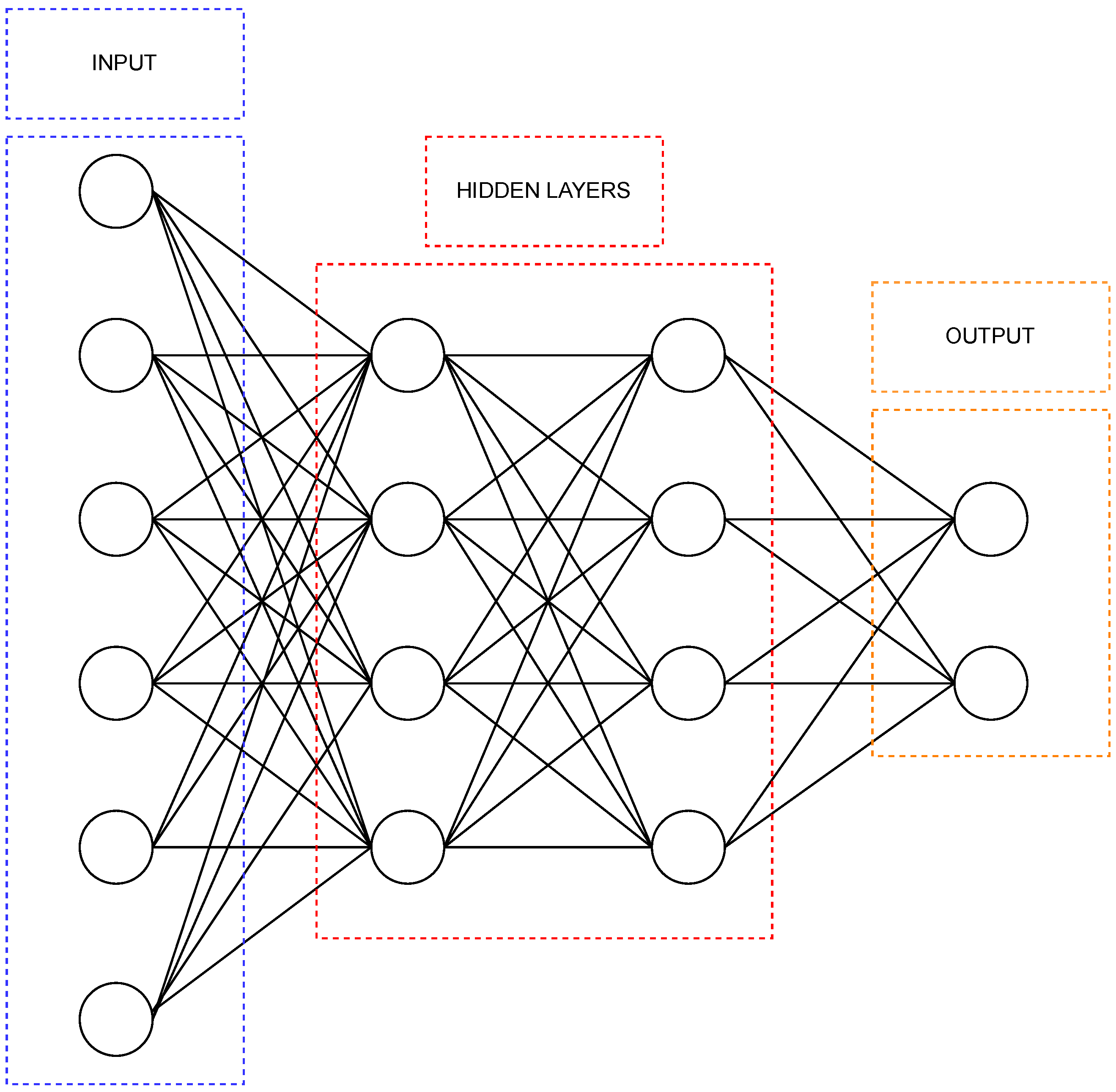
4.5. Artificial Neural Network
5. Metrics for Imbalanced Bankruptcy Prediction Tasks
- True positive (TP): The number of bankrupted companies that have been correctly predicted as such.
- False negative (FN): The number of bankrupted companies that have been wrongly predicted as healthy firms.
- True negative (FN): The number of actually healthy companies that have been correctly predicted as such.
- False positive (FP): The number of healthy companies that have been wrongly predicted as bankrupted by the model.
- The macro- score: The macro- score is computed as the arithmetic mean of the score of all the classes.
- The micro- score: It is used to assess the quality of multi-label binary problems. It measures the score of the aggregated contributions of all classes.
6. Task T1: Default Prediction with Historical Time Series
- Five years is the general maximum number of years found in the literature to be useful.
- When increasing the WL considered, the most recent companies are excluded because they do not have available data. In general, considering more years leads to smaller training and test sets. This could introduce a statistical bias, causing the analysis to focus on only the more mature and stable companies that have existed for several years while ignoring the relatively newer, smaller companies that are riskier and have higher default rates. This could introduce a statistical bias forcing the analysis to consider only the more structured and stable companies that have existed for several years while ignoring the relatively new companies with smaller market capitalization and which are thus riskier and have a higher probability of default, particularly during periods of economic decline.
6.1. Models Comparison and Selection for Default Prediction
- For WL = 2, best average AUC = with Random Forest
- For WL = 3, best average AUC = with Random Forest and Gradient Boosting
- For WL = 4, best average AUC = with XGBoost
- For WL = 5, best average AUC = with Random Forest
6.2. Results for Default Prediction
7. Task T2: Survival Probability Task
Results for the Survival Probability Prediction
8. Results
8.1. The Most Suitable Metric
8.2. Best Model and Temporal Windows
- For the default prediction task (T1), the general performance increases when considering more than one year of accounting variables and this is true for both ANNs and Random Forest. Indeed, the 5-year temporal window exhibits the best results in terms of AUC. However, in light of the discussion about the metrics, the temporal window of three years achieves the best trade-off between AUC and macro- score using fewer variables.
- For the survival probability prediction task (T2), the best performance is achieved when trying to predict the company status three years in advance (LAW = 3) with an AUC = 0.87 with the ANN. It should be highlighted that ANN reached for LAW = 5 a considerable AUC = 0.86. However, all the models exhibit a really low precision on the bankruptcy class except for SVM and XGBoost. Indeed the best model in terms of macro- score is XGBoost (LAW = 5)
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Danilov, C.; Konstantin, A. Corporate Bankruptcy: Assessment, Analysis and Prediction of Financial Distress, Insolvency, and Failure. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2467580 (accessed on 14 August 2022).
- Ding, A.A.; Tian, S.; Yu, Y.; Guo, H. A class of discrete transformation survival models with application to default probability prediction. J. Am. Stat. Assoc. 2012, 107, 990–1003. [Google Scholar] [CrossRef]
- Prusak, B. Review of research into enterprise bankruptcy prediction in selected central and eastern European countries. Int. J. Financ. Stud. 2018, 6, 60. [Google Scholar] [CrossRef] [Green Version]
- Zięba, M.; Tomczak, S.K.; Tomczak, J.M. Ensemble boosted trees with synthetic features generation in application to bankruptcy prediction. Expert Syst. Appl. 2016, 58, 93–101. [Google Scholar] [CrossRef]
- Mai, F.; Tian, S.; Lee, C.; Ma, L. Deep learning models for bankruptcy prediction using textual disclosures. Eur. J. Oper. Res. 2019, 274, 743–758. [Google Scholar] [CrossRef]
- Adosoglou, G.; Park, S.; Lombardo, G.; Cagnoni, S.; Pardalos, P.M. Lazy Network: A Word Embedding-Based Temporal Financial Network to Avoid Economic Shocks in Asset Pricing Models. Complexity 2022, 2022, 9430919. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- Thakur, N.; Han, C.Y. A study of fall detection in assisted living: Identifying and improving the optimal machine learning method. J. Sens. Actuator Netw. 2021, 10, 39. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Chen, F.; Abualigah, L. Machine learning technologies for big data analytics. Electronics 2022, 11, 421. [Google Scholar] [CrossRef]
- Schönfeld, J.; Kuděj, M.; Smrčka, L. Financial health of enterprises introducing safeguard procedure based on bankruptcy models. J. Bus. Econ. Manag. 2018, 19, 692–705. [Google Scholar] [CrossRef] [Green Version]
- Moscatelli, M.; Parlapiano, F.; Narizzano, S.; Viggiano, G. Corporate default forecasting with machine learning. Expert Syst. Appl. 2020, 161, 113567. [Google Scholar] [CrossRef]
- Danenas, P.; Garsva, G. Selection of Support Vector Machines based classifiers for credit risk domain. Expert Syst. Appl. 2015, 42, 3194–3204. [Google Scholar] [CrossRef]
- du Jardin, P. A two-stage classification technique for bankruptcy prediction. Eur. J. Oper. Res. 2016, 254, 236–252. [Google Scholar] [CrossRef]
- Tsai, C.F.; Hsu, Y.F.; Yen, D.C. A comparative study of classifier ensembles for bankruptcy prediction. Appl. Soft Comput. 2014, 24, 977–984. [Google Scholar] [CrossRef]
- Wang, G.; Ma, J.; Yang, S. An improved boosting based on feature selection for corporate bankruptcy prediction. Expert Syst. Appl. 2014, 41, 2353–2361. [Google Scholar] [CrossRef]
- Zhou, L.; Lai, K.K.; Yen, J. Bankruptcy prediction using SVM models with a new approach to combine features selection and parameter optimisation. Int. J. Syst. Sci. 2014, 45, 241–253. [Google Scholar] [CrossRef]
- Bottani, E.; Mordonini, M.; Franchi, B.; Pellegrino, M. Demand Forecasting for an Automotive Company with Neural Network and Ensemble Classifiers Approaches. In IFIP International Conference on Advances in Production Management Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 134–142. [Google Scholar]
- Geng, R.; Bose, I.; Chen, X. Prediction of financial distress: An empirical study of listed Chinese companies using data mining. Eur. J. Oper. Res. 2015, 241, 236–247. [Google Scholar] [CrossRef]
- Alfaro, E.; García, N.; Gámez, M.; Elizondo, D. Bankruptcy forecasting: An empirical comparison of AdaBoost and Neural Networks. Decis. Support Syst. 2008, 45, 110–122. [Google Scholar] [CrossRef]
- Bose, I.; Pal, R. Predicting the survival or failure of click-and-mortar corporations: A knowledge discovery approach. Eur. J. Oper. Res. 2006, 174, 959–982. [Google Scholar] [CrossRef]
- Tian, S.; Yu, Y.; Guo, H. Variable selection and corporate bankruptcy forecasts. J. Bank. Financ. 2015, 52, 89–100. [Google Scholar] [CrossRef]
- Wanke, P.; Barros, C.P.; Faria, J.R. Financial distress drivers in Brazilian banks: A dynamic slacks approach. Eur. J. Oper. Res. 2015, 240, 258–268. [Google Scholar] [CrossRef]
- Altman, E.I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Altman, E.I.; Hotchkiss, E.; Wang, W. Corporate Financial Distress, Restructuring, and Bankruptcy: Analyze Leveraged Finance, Distressed Debt, and Bankruptcy; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Kralicek, P. Fundamentals of Finance: Balance Sheets, Profit and Loss Accounts, Cash Flow, Calculation Bases, Financial Planning, Early Warning Systems; Ueberreuter: Berlin, Germany, 1991. [Google Scholar]
- Taffler, R.J.; Tisshaw, H. Going, going, gone–four factors which predict. Accountancy 1977, 88, 50–54. [Google Scholar]
- Ohlson, J.A. Financial ratios and the probabilistic prediction of bankruptcy. J. Account. Res. 1980, 18, 109–131. [Google Scholar] [CrossRef] [Green Version]
- Beaver, W.H. Financial ratios as predictors of failure. J. Account. Res. 1966, 4, 71–111. [Google Scholar] [CrossRef]
- Wang, G.; Ma, J.; Huang, L.; Xu, K. Two credit scoring models based on dual strategy ensemble trees. Knowl.-Based Syst. 2012, 26, 61–68. [Google Scholar] [CrossRef]
- Nanni, L.; Lumini, A. An experimental comparison of ensemble of classifiers for bankruptcy prediction and credit scoring. Expert Syst. Appl. 2009, 36, 3028–3033. [Google Scholar] [CrossRef]
- Kim, M.J.; Kang, D.K. Ensemble with Neural Networks for bankruptcy prediction. Expert Syst. Appl. 2010, 37, 3373–3379. [Google Scholar] [CrossRef]
- Wang, G.; Hao, J.; Ma, J.; Jiang, H. A comparative assessment of ensemble learning for credit scoring. Expert Syst. Appl. 2011, 38, 223–230. [Google Scholar] [CrossRef]
- Barboza, F.; Kimura, H.; Altman, E. Machine-learning models and bankruptcy prediction. Expert Syst. Appl. 2017, 83, 405–417. [Google Scholar] [CrossRef]
- Mossman, C.E.; Bell, G.G.; Swartz, L.M.; Turtle, H. An empirical comparison of bankruptcy models. Financ. Rev. 1998, 33, 35–54. [Google Scholar] [CrossRef]
- Duan, J.C.; Sun, J.; Wang, T. Multiperiod corporate default prediction—A forward intensity approach. J. Econom. 2012, 170, 191–209. [Google Scholar] [CrossRef]
- Kim, H.; Cho, H.; Ryu, D. Corporate default predictions using machine learning: Literature review. Sustainability 2020, 12, 6325. [Google Scholar] [CrossRef]
- Adosoglou, G.; Lombardo, G.; Pardalos, P.M. Neural Network embeddings on corporate annual filings for portfolio selection. Expert Syst. Appl. 2021, 164, 114053. [Google Scholar] [CrossRef]
- Campbell, J.Y.; Hilscher, J.; Szilagyi, J. In search of distress risk. J. Financ. 2008, 63, 2899–2939. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A Gradient Boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; He, T. Xgboost: Extreme Gradient Boosting. Available online: https://cran.microsoft.com/snapshot/2017-12-11/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 14 August 2022).
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Total Firms | Bankrupt Firms | Year | Total Firms | Bankrupt Firms |
|---|---|---|---|---|---|
| 2000 | 5308 | 3 | 2010 | 3743 | 23 |
| 2001 | 5226 | 7 | 2011 | 3625 | 35 |
| 2002 | 4897 | 10 | 2012 | 3513 | 25 |
| 2003 | 4651 | 17 | 2013 | 3485 | 26 |
| 2004 | 4417 | 29 | 2014 | 3484 | 28 |
| 2005 | 4348 | 46 | 2015 | 3504 | 33 |
| 2006 | 4205 | 40 | 2016 | 3354 | 33 |
| 2007 | 4128 | 51 | 2017 | 3191 | 29 |
| 2008 | 4009 | 59 | 2018 | 3014 | 21 |
| 2009 | 3857 | 58 | 2019 | 2723 | 36 |
| Variable Name | Description | |
|---|---|---|
| X1 | Current assets | All the assets of a company that are expected to be sold or used as a result of standard business operations over the next year |
| X2 | Cost of goods sold | The total amount a company paid as a cost directly related to the sale of products |
| X3 | Depreciation and amortization | Depreciation refers to the loss of value of a tangible fixed asset over time (such as property. machinery, buildings, and plant). Amortization refers to the loss of value of intangible assets over time. |
| X4 | EBITDA | Earnings before interest, taxes, depreciation and amortization: Measure of a company’s overall financial performance alternative to the net income |
| X5 | Inventory | The accounting of items and raw materials that a company either uses in production or sells. |
| X6 | Net Income | The overall profitability of a company after all expenses and costs have been deducted from total revenue. |
| X7 | Total Receivables | The balance of money due to a firm for goods or services delivered or used but not yet paid for by customers. |
| X8 | Market value | The price of an asset in a marketplace. In our dataset it refers to the market capitalization since companies are publicly traded in the stock market |
| X9 | Net sales | The sum of a company’s gross sales minus its returns, allowances, and discounts. |
| X10 | Total assets | All the assets, or items of value, a business owns |
| X11 | Total Long term debt | A company’s loans and other liabilities that will not become due within one year of the balance sheet date |
| X12 | EBIT | Earnings before interest and taxes |
| X13 | Gross Profit | The profit a business makes after subtracting all the costs that are related to manufacturing and selling its products or services |
| X14 | Total Current Liabilities | It is the sum of accounts payable, accrued liabilities and taxes such as Bonds payable at the end of the year, salaries and commissions remaining |
| X15 | Retained Earnings | The amount of profit a company has left over after paying all its direct costs, indirect costs, income taxes and its dividends to shareholders |
| X16 | Total Revenue | The amount of income that a business has made from all sales before subtracting expenses. It may include interest and dividends from investments |
| X17 | Total Liabilities | The combined debts and obligations that the company owes to outside parties |
| X18 | Total Operating Expenses | The expense a business incurs through its normal business operations |
| LAW = 2 | LAW = 3 | LAW = 4 | LAW = 5 | WL = 1 | WL = 2 | WL = 3 | WL = 4 | WL = 5 | |
|---|---|---|---|---|---|---|---|---|---|
| Svm | 4.930e-32 | 0.0 | 0.0 | 4.930e-32 | 0.0 | 1.233e-32 | 0.0 | 0.0 | 0.0 |
| Ann | 0.009 | 0.0075 | 0.0089 | 0.0103 | 0.0076 | 0.0037 | 0.0026 | 0.0029 | 0.0022 |
| Logistic Regression | 1.233e-32 | 1.232e-32 | 6.145e-07 | 2.488e-07 | 1.233e-32 | 2.831e-05 | 5.612e-08 | 0.00019 | 2.427e-06 |
| AdaBoost | 6.416e-07 | 0.0 | 8.430e-07 | 4.930e-32 | 6.559e-06 | 1.233e-32 | 2.039e-07 | 1.233e-32 | 6.951e-06 |
| Random Forest | 8.301e-05 | 8.208e-05 | 6.273e-05 | 9.655e-05 | 8.076e-05 | 0.00012 | 7.139e-05 | 0.00011 | 9.349e-05 |
| Gradient Boosting | 2.887e-05 | 1.616e-05 | 4.583e-06 | 2.462e-05 | 3.135e-06 | 8.098e-07 | 1.801e-06 | 1.445e-06 | 2.860e-05 |
| XgBoost | 4.930e-32 | 0.0 | 0.0 | 1.233e-32 | 4.930e-32 | 1.233e-32 | 1.233e-32 | 4.930e-32 | 4.930e-32 |
| WL = 1 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 42 | 63 | 742 | 2498 | 0.585 | 0.759 | 0.478 | 22.901 | 60 | 0.4 | 0.054 | 0.771 | 0.975 |
| Ann | 80 | 25 | 609 | 2631 | 0.861 | 0.81 | 0.547 | 18.796 | 23.81 | 0.762 | 0.116 | 0.812 | 0.991 |
| Logistic Regression | 85 | 20 | 969 | 2271 | 0.755 | 0.704 | 0.484 | 29.907 | 19.048 | 0.81 | 0.081 | 0.701 | 0.991 |
| AdaBoost | 68 | 37 | 1072 | 2168 | 0.658 | 0.668 | 0.453 | 33.086 | 35.238 | 0.648 | 0.06 | 0.669 | 0.983 |
| Random Forest | 83 | 22 | 1158 | 2082 | 0.717 | 0.647 | 0.451 | 35.741 | 20.952 | 0.79 | 0.067 | 0.643 | 0.99 |
| Gradient Boosting | 85 | 20 | 945 | 2295 | 0.759 | 0.712 | 0.488 | 29.167 | 19.048 | 0.81 | 0.083 | 0.708 | 0.991 |
| XgBoost | 90 | 15 | 921 | 2319 | 0.786 | 0.72 | 0.497 | 28.426 | 14.286 | 0.857 | 0.089 | 0.716 | 0.994 |
| WL = 2 | |||||||||||||
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 50 | 53 | 701 | 2442 | 0.631 | 0.768 | 0.492 | 22.304 | 51.456 | 0.485 | 0.067 | 0.777 | 0.979 |
| Ann | 75 | 28 | 541 | 2602 | 0.857 | 0.825 | 0.555 | 17.213 | 27.184 | 0.728 | 0.122 | 0.828 | 0.989 |
| Logistic Regression | 85 | 18 | 1024 | 2119 | 0.75 | 0.679 | 0.471 | 32.58 | 17.476 | 0.825 | 0.077 | 0.674 | 0.992 |
| AdaBoost | 77 | 26 | 1077 | 2066 | 0.702 | 0.66 | 0.456 | 34.267 | 25.243 | 0.748 | 0.067 | 0.657 | 0.988 |
| Random Forest | 89 | 14 | 979 | 2164 | 0.776 | 0.694 | 0.483 | 31.149 | 13.592 | 0.864 | 0.083 | 0.689 | 0.994 |
| Gradient Boosting | 82 | 21 | 1070 | 2073 | 0.728 | 0.664 | 0.461 | 34.044 | 20.388 | 0.796 | 0.071 | 0.66 | 0.99 |
| XgBoost | 80 | 23 | 796 | 2347 | 0.762 | 0.748 | 0.507 | 25.326 | 22.33 | 0.777 | 0.091 | 0.747 | 0.99 |
| WL = 3 | |||||||||||||
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 43 | 58 | 628 | 2378 | 0.608 | 0.779 | 0.493 | 20.892 | 57.426 | 0.426 | 0.064 | 0.791 | 0.976 |
| Ann | 83 | 18 | 885 | 2121 | 0.85 | 0.709 | 0.49 | 29.441 | 17.822 | 0.822 | 0.086 | 0.706 | 0.992 |
| Logistic Regression | 81 | 20 | 1259 | 1747 | 0.692 | 0.588 | 0.422 | 41.883 | 19.802 | 0.802 | 0.06 | 0.581 | 0.989 |
| AdaBoost | 74 | 27 | 1168 | 1838 | 0.672 | 0.615 | 0.432 | 38.856 | 26.733 | 0.733 | 0.06 | 0.611 | 0.986 |
| Random Forest | 85 | 16 | 869 | 2137 | 0.776 | 0.715 | 0.495 | 28.909 | 15.842 | 0.842 | 0.089 | 0.711 | 0.993 |
| Gradient Boosting | 78 | 23 | 834 | 2172 | 0.747 | 0.724 | 0.495 | 27.745 | 22.772 | 0.772 | 0.086 | 0.723 | 0.99 |
| XgBoost | 77 | 24 | 816 | 2190 | 0.745 | 0.73 | 0.497 | 27.146 | 23.762 | 0.762 | 0.086 | 0.729 | 0.989 |
| WL = 4 | |||||||||||||
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 54 | 42 | 641 | 2183 | 0.668 | 0.766 | 0.501 | 22.698 | 43.75 | 0.563 | 0.078 | 0.773 | 0.981 |
| Ann | 80 | 16 | 711 | 2113 | 0.87 | 0.751 | 0.517 | 25.177 | 16.667 | 0.833 | 0.101 | 0.748 | 0.992 |
| Logistic Regression | 85 | 11 | 1373 | 1451 | 0.7 | 0.526 | 0.393 | 48.619 | 11.458 | 0.885 | 0.058 | 0.514 | 0.992 |
| AdaBoost | 71 | 25 | 888 | 1936 | 0.713 | 0.687 | 0.472 | 31.445 | 26.042 | 0.74 | 0.074 | 0.686 | 0.987 |
| Random Forest | 80 | 16 | 807 | 2017 | 0.774 | 0.718 | 0.497 | 28.576 | 16.667 | 0.833 | 0.09 | 0.714 | 0.992 |
| Gradient Boosting | 72 | 24 | 925 | 1899 | 0.711 | 0.675 | 0.466 | 32.755 | 25 | 0.75 | 0.072 | 0.672 | 0.988 |
| XgBoost | 78 | 18 | 771 | 2053 | 0.77 | 0.73 | 0.502 | 27.302 | 18.75 | 0.813 | 0.092 | 0.727 | 0.991 |
| WL = 5 | |||||||||||||
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 37 | 54 | 572 | 2072 | 0.595 | 0.771 | 0.487 | 21.634 | 59.341 | 0.407 | 0.061 | 0.784 | 0.975 |
| Ann | 85 | 6 | 1107 | 1537 | 0.893 | 0.593 | 0.433 | 41.868 | 6.593 | 0.934 | 0.071 | 0.581 | 0.996 |
| Logistic Regression | 82 | 9 | 1174 | 1470 | 0.729 | 0.567 | 0.417 | 44.402 | 9.89 | 0.901 | 0.065 | 0.556 | 0.994 |
| AdaBoost | 69 | 22 | 955 | 1689 | 0.699 | 0.643 | 0.45 | 36.12 | 24.176 | 0.758 | 0.067 | 0.639 | 0.987 |
| Random Forest | 75 | 16 | 651 | 1993 | 0.789 | 0.756 | 0.52 | 24.622 | 17.582 | 0.824 | 0.103 | 0.754 | 0.992 |
| Gradient Boosting | 72 | 19 | 759 | 1885 | 0.752 | 0.716 | 0.493 | 28.707 | 20.879 | 0.791 | 0.087 | 0.713 | 0.99 |
| XgBoost | 72 | 19 | 669 | 1975 | 0.769 | 0.748 | 0.512 | 25.303 | 20.879 | 0.791 | 0.097 | 0.747 | 0.99 |
| WL = 2 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 51 | 52 | 759 | 2384 | 0.627 | 0.75 | 0.483 | 24.149 | 50.485 | 0.495 | 0.063 | 0.759 | 0.979 |
| Ann | 74 | 29 | 842 | 2301 | 0.819 | 0.732 | 0.493 | 26.79 | 28.155 | 0.718 | 0.081 | 0.732 | 0.988 |
| Logistic Regression | 85 | 18 | 1082 | 2061 | 0.74 | 0.661 | 0.462 | 34.426 | 17.476 | 0.825 | 0.073 | 0.656 | 0.991 |
| AdaBoost | 83 | 20 | 1042 | 2101 | 0.737 | 0.673 | 0.467 | 33.153 | 19.417 | 0.806 | 0.074 | 0.668 | 0.991 |
| Random Forest | 78 | 25 | 853 | 2290 | 0.743 | 0.73 | 0.495 | 27.14 | 24.272 | 0.757 | 0.084 | 0.729 | 0.989 |
| Gradient Boosting | 81 | 22 | 1002 | 2141 | 0.734 | 0.685 | 0.472 | 31.88 | 21.359 | 0.786 | 0.075 | 0.681 | 0.99 |
| XgBoost | 79 | 24 | 946 | 2197 | 0.733 | 0.701 | 0.48 | 30.099 | 23.301 | 0.767 | 0.077 | 0.699 | 0.989 |
| WL = 3 | |||||||||||||
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 48 | 53 | 554 | 2452 | 0.645 | 0.805 | 0.513 | 18.43 | 52.475 | 0.475 | 0.08 | 0.816 | 0.979 |
| Ann | 83 | 18 | 779 | 2227 | 0.872 | 0.743 | 0.51 | 25.915 | 17.822 | 0.822 | 0.096 | 0.741 | 0.992 |
| Logistic Regression | 90 | 11 | 1136 | 1870 | 0.757 | 0.631 | 0.45 | 37.791 | 10.891 | 0.891 | 0.073 | 0.622 | 0.994 |
| AdaBoost | 87 | 14 | 872 | 2134 | 0.786 | 0.715 | 0.496 | 29.009 | 13.861 | 0.861 | 0.091 | 0.71 | 0.993 |
| Random Forest | 85 | 16 | 781 | 2225 | 0.791 | 0.743 | 0.512 | 25.981 | 15.842 | 0.842 | 0.098 | 0.74 | 0.993 |
| Gradient Boosting | 76 | 25 | 962 | 2044 | 0.716 | 0.682 | 0.469 | 32.003 | 24.752 | 0.752 | 0.073 | 0.68 | 0.988 |
| XgBoost | 83 | 18 | 841 | 2165 | 0.771 | 0.724 | 0.498 | 27.977 | 17.822 | 0.822 | 0.09 | 0.72 | 0.992 |
| WL = 4 | |||||||||||||
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 46 | 50 | 750 | 2074 | 0.607 | 0.726 | 0.471 | 26.558 | 52.083 | 0.479 | 0.058 | 0.734 | 0.976 |
| Ann | 69 | 27 | 705 | 2119 | 0.811 | 0.749 | 0.506 | 24.965 | 28.125 | 0.719 | 0.089 | 0.75 | 0.987 |
| Logistic Regression | 77 | 19 | 742 | 2082 | 0.77 | 0.739 | 0.507 | 26.275 | 19.792 | 0.802 | 0.094 | 0.737 | 0.991 |
| AdaBoost | 71 | 25 | 844 | 1980 | 0.72 | 0.702 | 0.48 | 29.887 | 26.042 | 0.74 | 0.078 | 0.701 | 0.988 |
| Random Forest | 81 | 15 | 770 | 2054 | 0.786 | 0.731 | 0.505 | 27.266 | 15.625 | 0.844 | 0.095 | 0.727 | 0.993 |
| Gradient Boosting | 79 | 17 | 880 | 1944 | 0.756 | 0.693 | 0.481 | 31.161 | 17.708 | 0.823 | 0.082 | 0.688 | 0.991 |
| XgBoost | 77 | 19 | 824 | 2000 | 0.755 | 0.711 | 0.49 | 29.178 | 19.792 | 0.802 | 0.085 | 0.708 | 0.991 |
| WL = 5 | |||||||||||||
| TP | FN | FP | TN | AUC Score | Micro-f1 | Macro-f1 | I Error | II Error | Rec Bankruptcy | Pr Bankruptcy | Rec Healthy | Pr Healthy | |
| Svm | 62 | 29 | 539 | 2105 | 0.739 | 0.792 | 0.53 | 20.386 | 31.868 | 0.681 | 0.103 | 0.796 | 0.986 |
| Ann | 85 | 6 | 1270 | 1374 | 0.862 | 0.533 | 0.4 | 48.033 | 6.593 | 0.934 | 0.063 | 0.52 | 0.996 |
| Logistic Regression | 78 | 13 | 849 | 1795 | 0.768 | 0.685 | 0.48 | 32.11 | 14.286 | 0.857 | 0.084 | 0.679 | 0.993 |
| AdaBoost | 74 | 17 | 953 | 1691 | 0.726 | 0.645 | 0.455 | 36.044 | 18.681 | 0.813 | 0.072 | 0.64 | 0.99 |
| Random Forest | 79 | 12 | 715 | 1929 | 0.799 | 0.734 | 0.51 | 27.042 | 13.187 | 0.868 | 0.099 | 0.73 | 0.994 |
| Gradient Boosting | 74 | 17 | 866 | 1778 | 0.743 | 0.677 | 0.472 | 32.753 | 18.681 | 0.813 | 0.079 | 0.672 | 0.991 |
| XgBoost | 73 | 18 | 610 | 2034 | 0.786 | 0.77 | 0.527 | 23.071 | 19.78 | 0.802 | 0.107 | 0.769 | 0.991 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lombardo, G.; Pellegrino, M.; Adosoglou, G.; Cagnoni, S.; Pardalos, P.M.; Poggi, A. Machine Learning for Bankruptcy Prediction in the American Stock Market: Dataset and Benchmarks. Future Internet 2022, 14, 244. https://doi.org/10.3390/fi14080244
Lombardo G, Pellegrino M, Adosoglou G, Cagnoni S, Pardalos PM, Poggi A. Machine Learning for Bankruptcy Prediction in the American Stock Market: Dataset and Benchmarks. Future Internet. 2022; 14(8):244. https://doi.org/10.3390/fi14080244
Chicago/Turabian StyleLombardo, Gianfranco, Mattia Pellegrino, George Adosoglou, Stefano Cagnoni, Panos M. Pardalos, and Agostino Poggi. 2022. "Machine Learning for Bankruptcy Prediction in the American Stock Market: Dataset and Benchmarks" Future Internet 14, no. 8: 244. https://doi.org/10.3390/fi14080244
APA StyleLombardo, G., Pellegrino, M., Adosoglou, G., Cagnoni, S., Pardalos, P. M., & Poggi, A. (2022). Machine Learning for Bankruptcy Prediction in the American Stock Market: Dataset and Benchmarks. Future Internet, 14(8), 244. https://doi.org/10.3390/fi14080244