
Forecasting the Risk Factor of Frontier Markets: A Novel Stacking Ensemble of Neural Network Approach

Abstract
:1. Introduction
2. Background and Literature Review
3. Materials and Methods
3.1. Dataset
3.2. Volatility Calculation
3.3. Performance Metrics
- RMSE: RMSE is a widely used error metric for performance calculation process. The RMSE can be calculated as follows:
- MAE: Unlike the RMSE, the changes in MAE are linear. This is because MAE does not square the error value in it; instead, the scores increase linearly. The MAE can be calculated as follows:
3.4. Methodology
3.4.1. Predictive Model: Random Forest
3.4.2. Predictive Model: AdaBoost
3.4.3. Predictive Model: Gradient Boosting
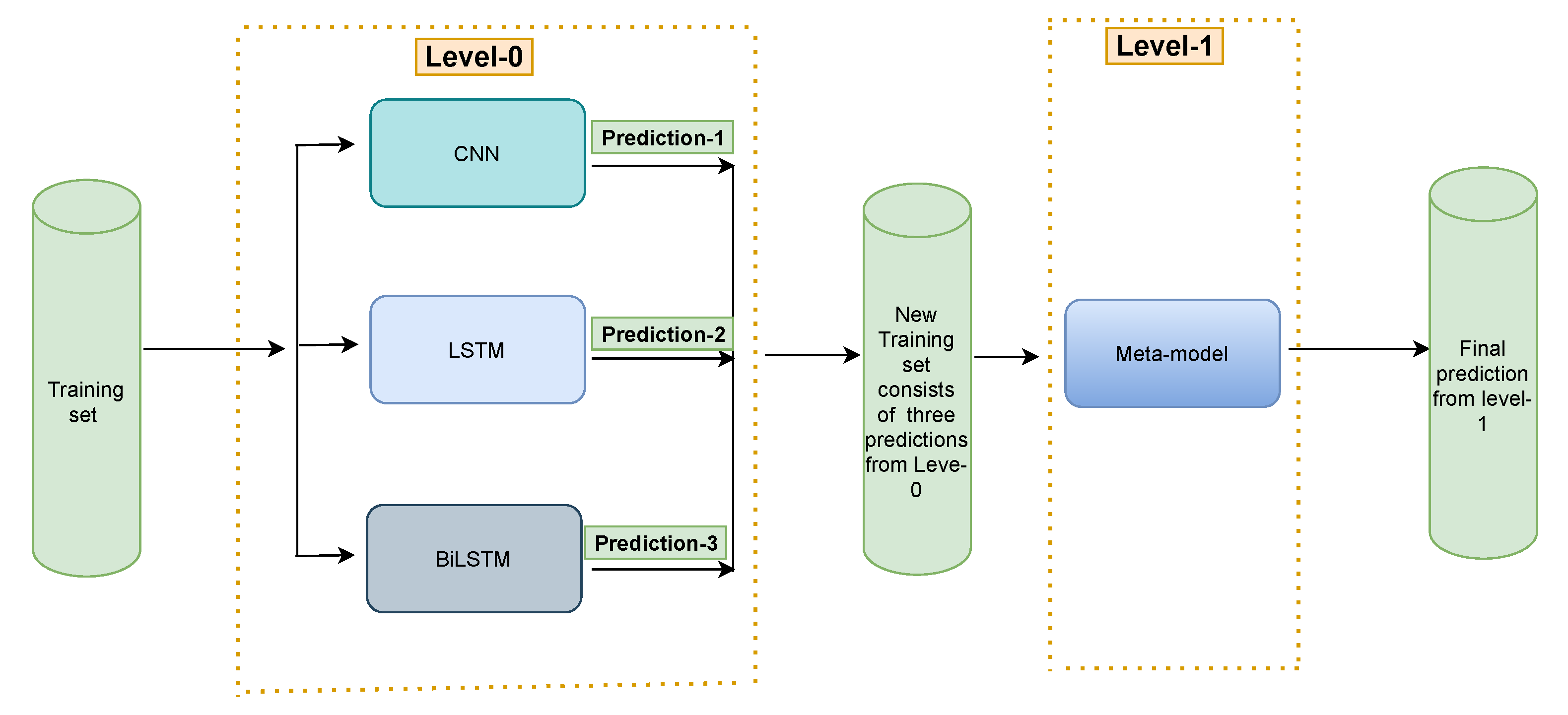
3.4.4. Predictive Model: ML Stacking Ensemble
3.4.5. Predictive Model: One Dimensional Convolutional Neural Network (1D-CNN)
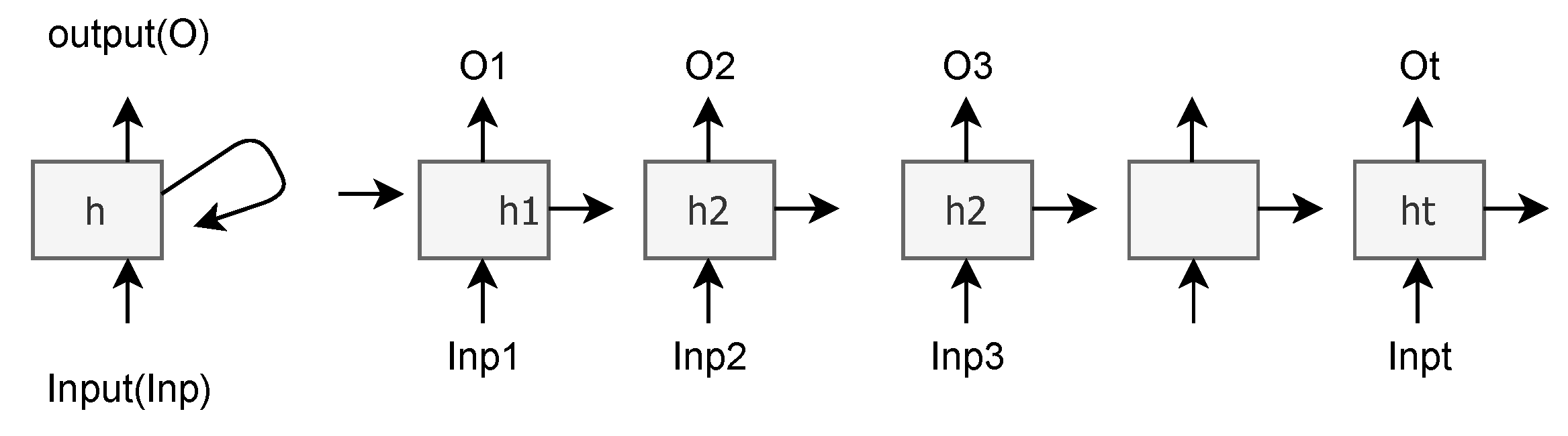
3.4.6. Predictive Model: Long Short-Term Memory (LSTM) Architecture
- A sigmoid layer called the “input gate layer” decides which values to update.
- A tanh layer creates a vector of new candidate values to add to the state.
- Combination of step 1 and 2 creates an update to the state.
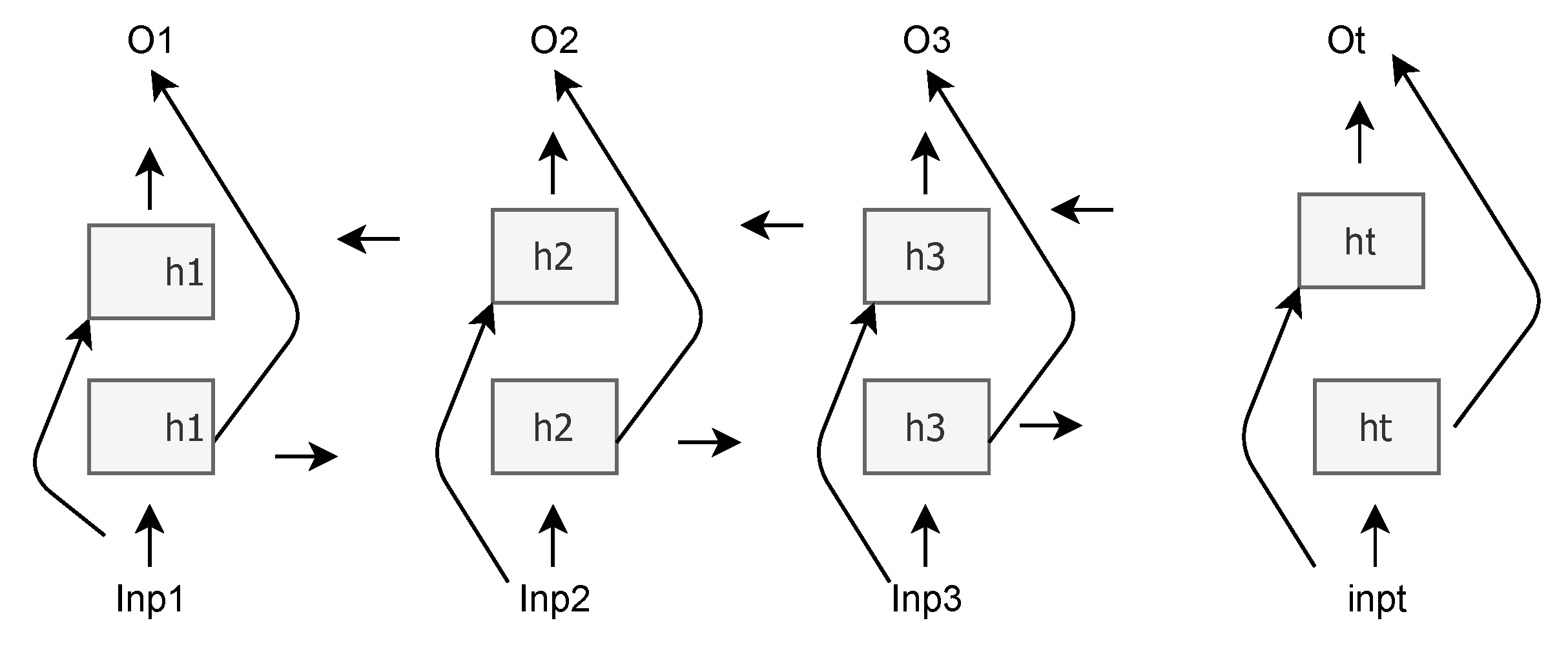
3.4.7. Predictive Model: BiLSTM Architecture
3.5. Proposed Model: Stacking Ensemble Neural Network Architecture
4. Result and Discussion
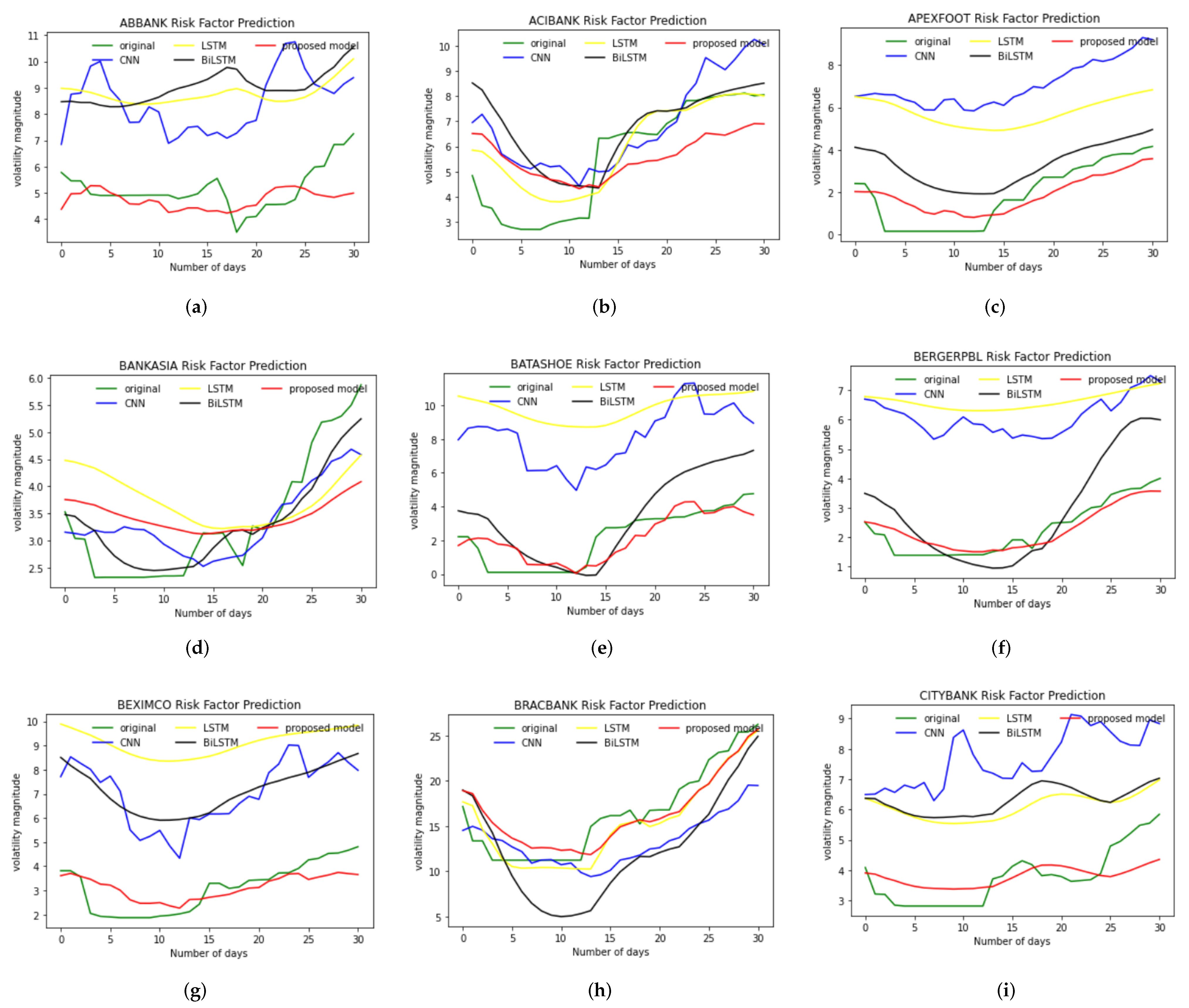
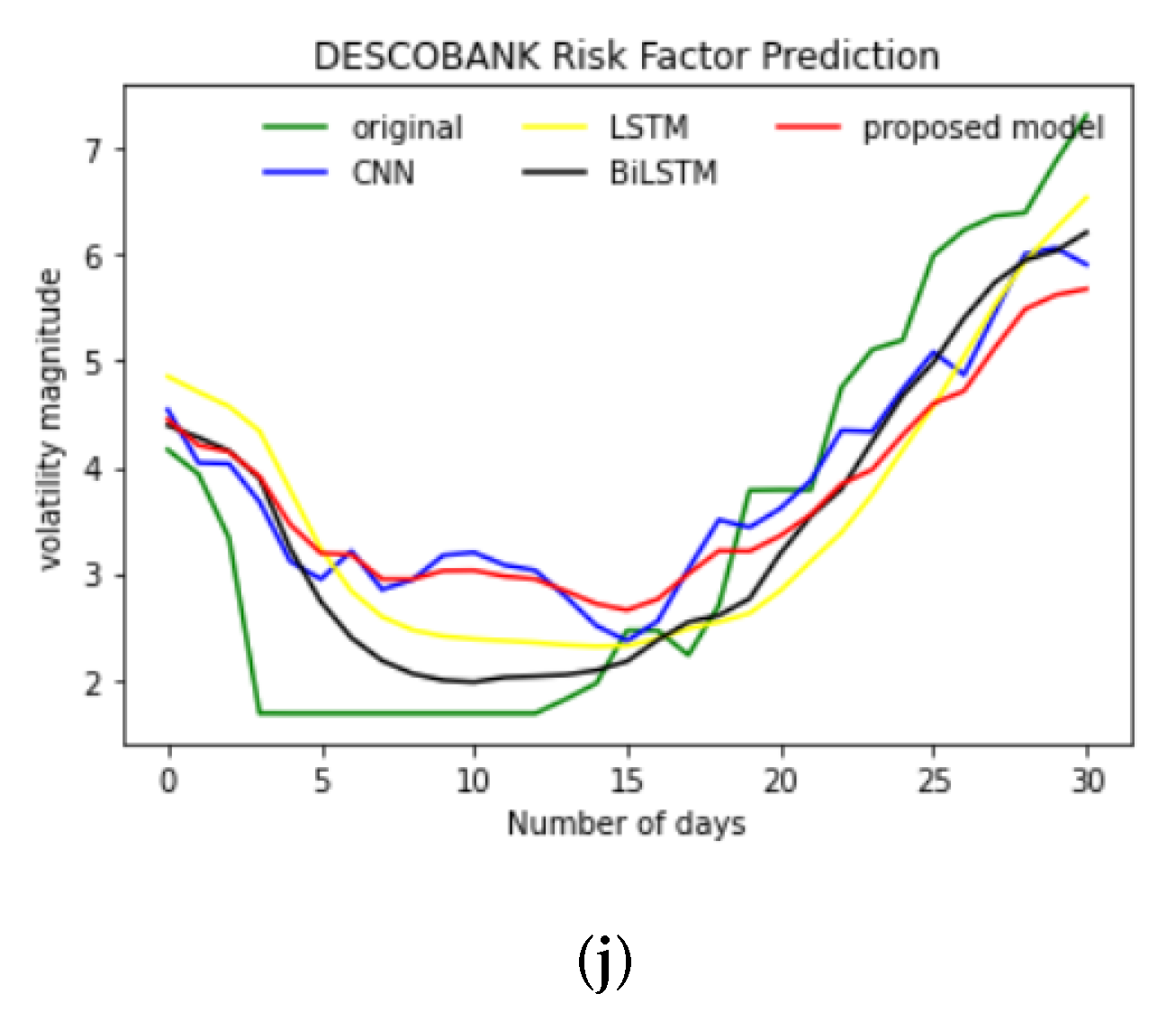
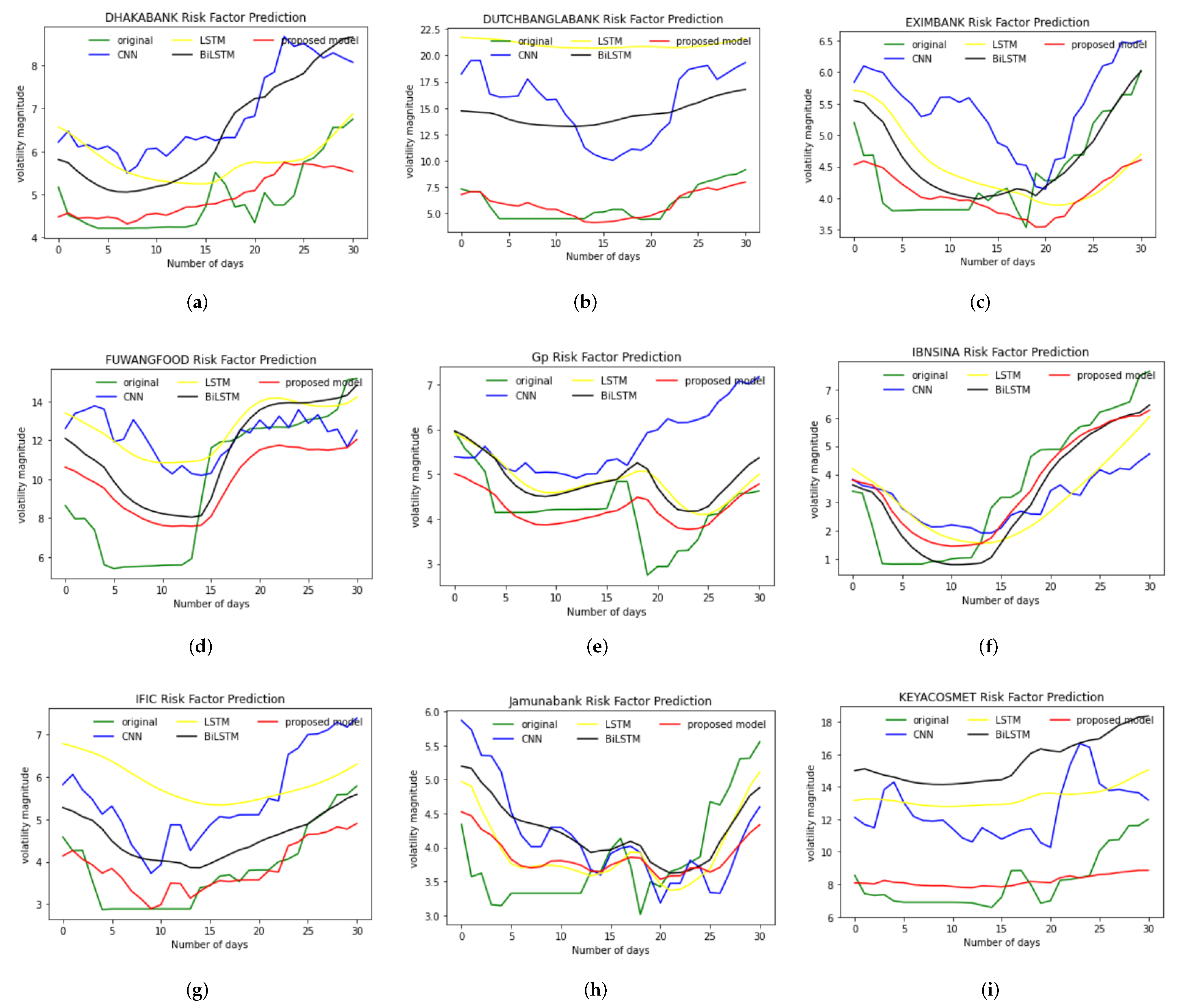
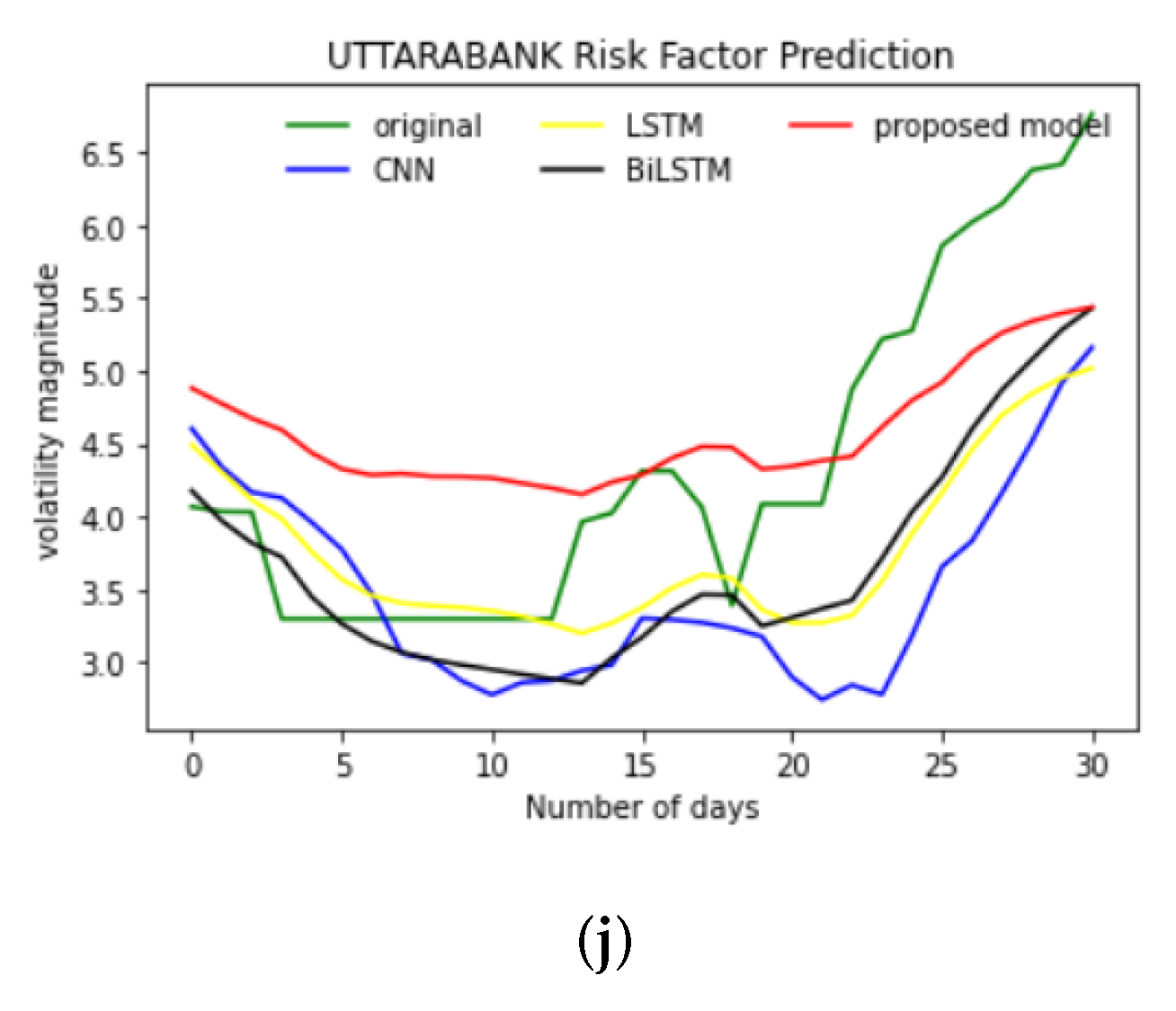
4.1. Predicted Results
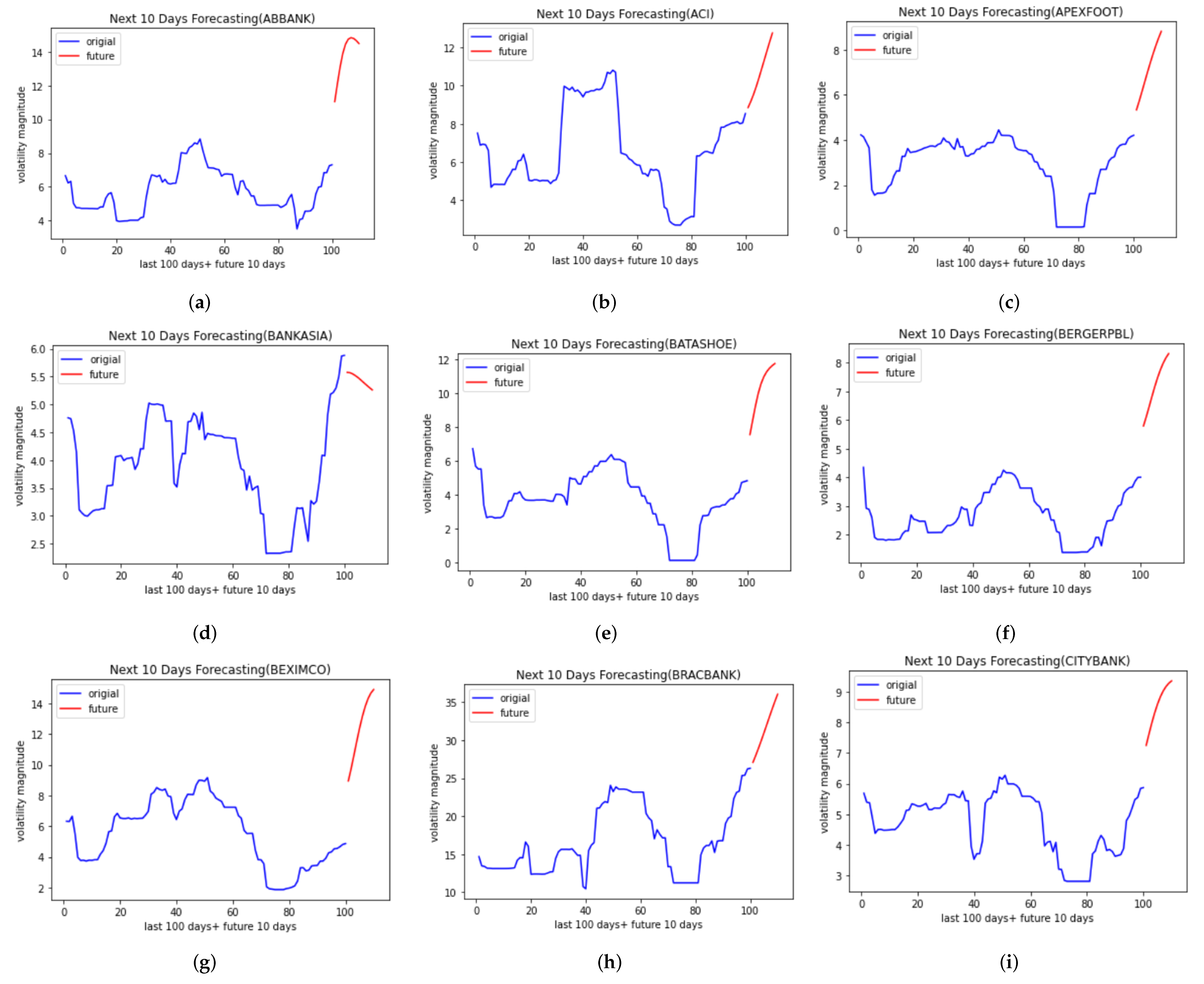
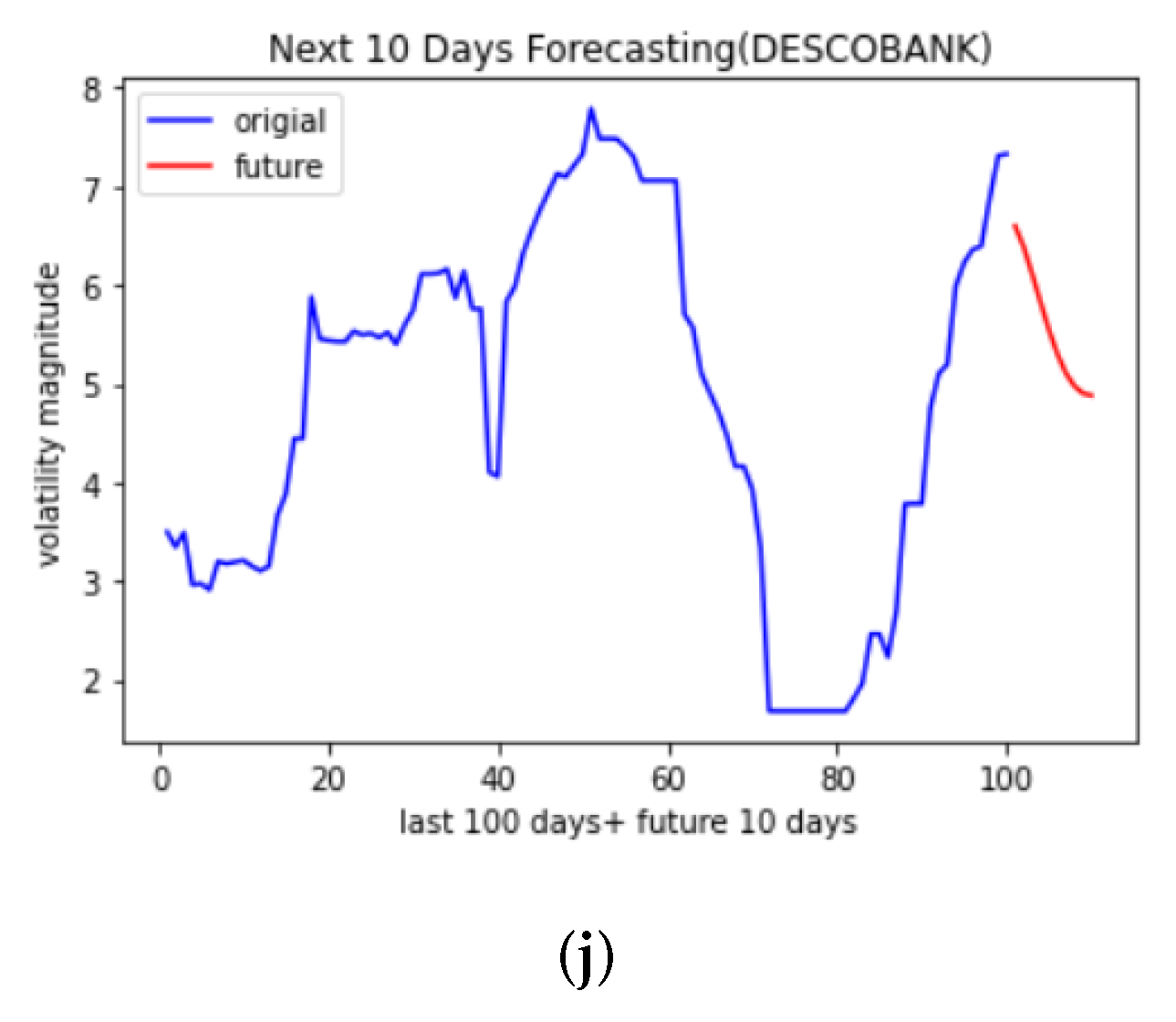
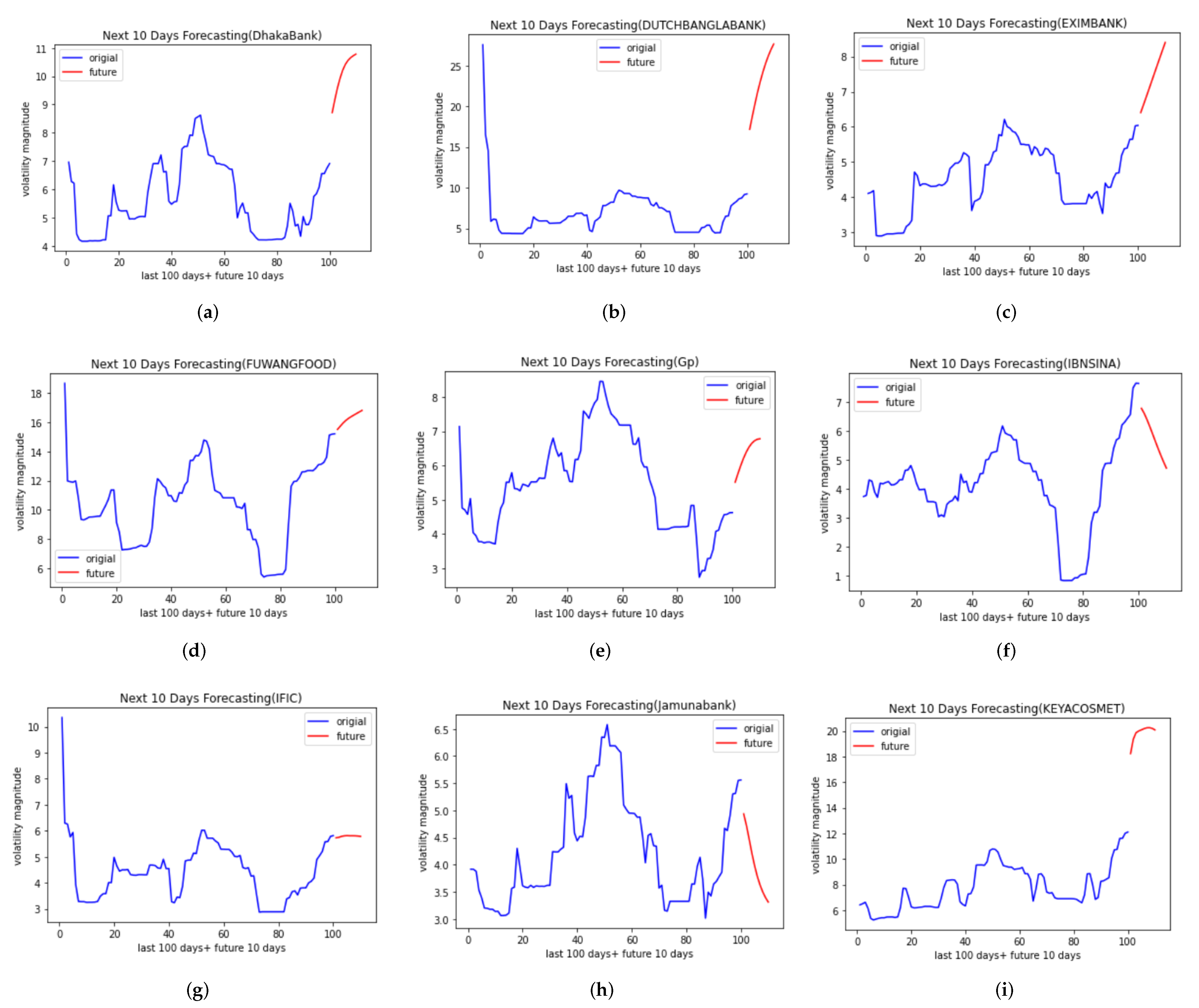
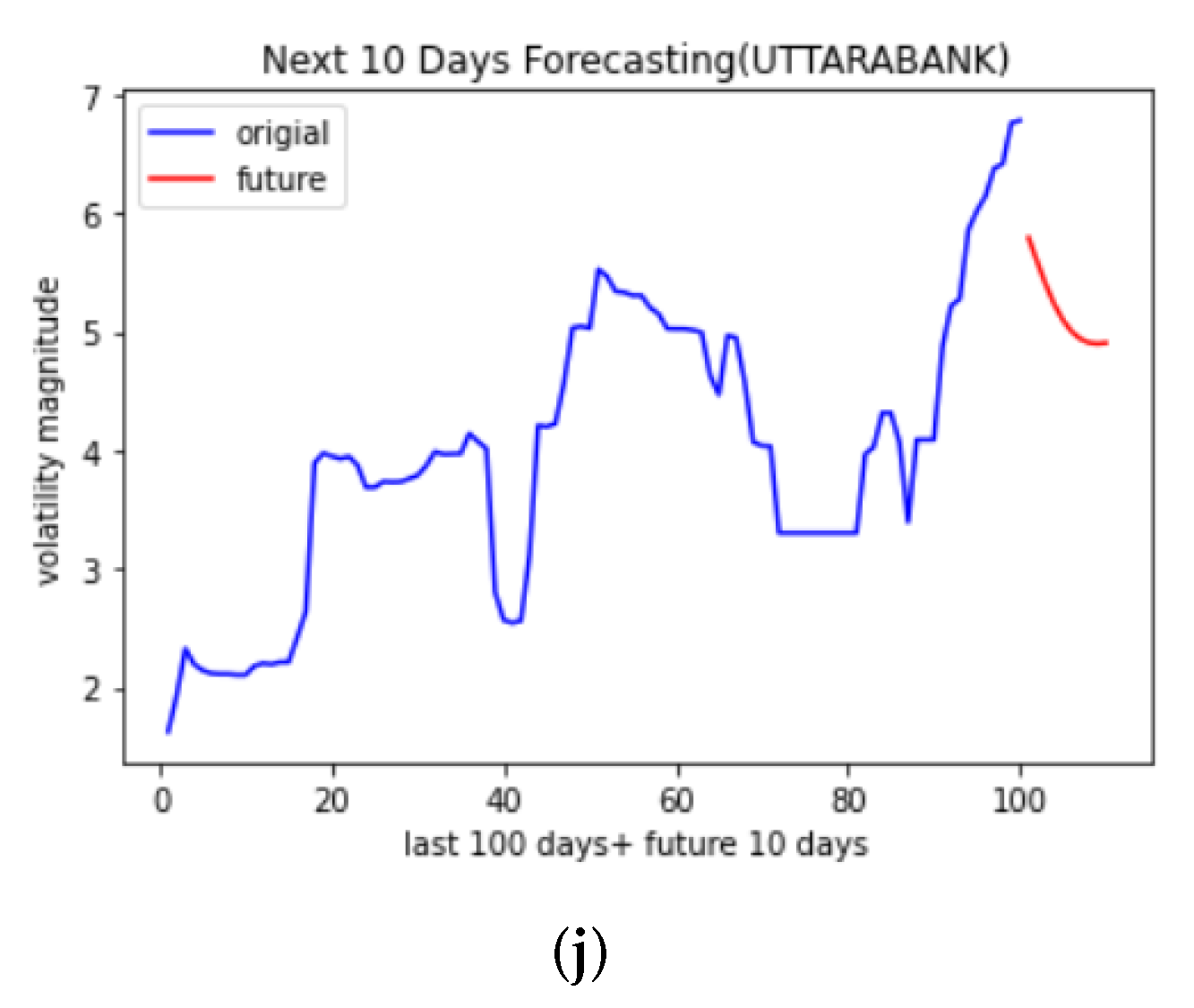
4.2. Forecasting Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gomes, M.; Chaibi, A. Volatility spillovers between oil prices and stock returns: A focus on frontier markets. J. Appl. Bus. Res. 2014, 30, 18. [Google Scholar] [CrossRef]
- Chowdhury, R.; Mahdy, M.; Alam, T.N.; Al Quaderi, G.D.; Rahman, M.A. Predicting the stock price of frontier markets using machine learning and modified Black–Scholes Option pricing model. Phys. A Stat. Mech. Appl. 2020, 555, 124444. [Google Scholar] [CrossRef]
- Anghel, D.G. Predicting Intraday Prices in the Frontier Stock Market of Romania Using Machine Learning Algorithms. Int. J. Econ. Financ. Res. 2020, 6, 170–179. [Google Scholar] [CrossRef]
- Lin, K.; Lin, Q.; Zhou, C.; Yao, J. Time series prediction based on linear regression and SVR. In Proceedings of the Third International Conference on Natural Computation (ICNC 2007), Haikou, China, 24–27 August 2007; IEEE: New York, NY, USA, 2007; Volume 1, pp. 688–691. [Google Scholar]
- Kavitha, S.; Varuna, S.; Ramya, R. A comparative analysis on linear regression and support vector regression. In Proceedings of the 2016 Online International Conference on Green Engineering and Technologies (IC-GET), Virtual, 19 November 2016; IEEE: New York, NY, USA, 2016; pp. 1–5. [Google Scholar]
- Johnsson, O. Predicting Stock Index Volatility Using Artificial Neural Networks: An Empirical Study of the OMXS30, FTSE100 & S&P/ASX200. Master’s Thesis, Lund University, Lund, Sweden, 2018. [Google Scholar]
- Madge, S.; Bhatt, S. Predicting stock price direction using support vector machines. In Independent Work Report Spring; Princeton University: Princeton, NJ, USA, 2015; Volume 45. [Google Scholar]
- Yoon, Y.; Swales, G. Predicting stock price performance: A neural network approach. In Proceedings of the Twenty-Fourth Annual Hawaii International Conference on System Sciences, Kauai, HI, USA, 8–11 January 1991; IEEE: New York, NY, USA, 1991; Volume 4, pp. 156–162. [Google Scholar]
- Zhao, Y.; Li, J.; Yu, L. A deep learning ensemble approach for crude oil price forecasting. Energy Econ. 2017, 66, 9–16. [Google Scholar] [CrossRef]
- Chen, Z.; Li, C.; Sun, W. Bitcoin price prediction using machine learning: An approach to sample dimension engineering. J. Comput. Appl. Math. 2020, 365, 112395. [Google Scholar] [CrossRef]
- Andriopoulos, N.; Magklaras, A.; Birbas, A.; Papalexopoulos, A.; Valouxis, C.; Daskalaki, S.; Birbas, M.; Housos, E.; Papaioannou, G.P. Short Term Electric Load Forecasting Based on Data Transformation and Statistical Machine Learning. Appl. Sci. 2021, 11, 158. [Google Scholar] [CrossRef]
- Selvin, S.; Vinayakumar, R.; Gopalakrishnan, E.; Menon, V.K.; Soman, K. Stock price prediction using LSTM, RNN and CNN-sliding window model. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; IEEE: New York, NY, USA, 2017; pp. 1643–1647. [Google Scholar]
- Patel, M.B.; Yalamalle, S.R. Stock price prediction using artificial neural network. Int. J. Innov. Res. Sci. Eng. Technol. 2014, 3, 13755–13762. [Google Scholar]
- Liu, S.; Liao, G.; Ding, Y. Stock transaction prediction modeling and analysis based on LSTM. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–1 June 2018; IEEE: New York, NY, USA, 2018; pp. 2787–2790. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The performance of LSTM and BiLSTM in forecasting time series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; IEEE: New York, NY, USA, 2019; pp. 3285–3292. [Google Scholar]
- Elliot, A.; Hsu, C.H. Time Series Prediction: Predicting Stock Price. arXiv 2017, arXiv:1710.05751. [Google Scholar]
- Elsayed, S.; Thyssens, D.; Rashed, A.; Schmidt-Thieme, L.; Jomaa, H.S. Do We Really Need Deep Learning Models for Time Series Forecasting? arXiv 2021, arXiv:2101.02118. [Google Scholar]
- Luong, C.; Dokuchaev, N. Forecasting of realised volatility with the random forests algorithm. J. Risk Financ. Manag. 2018, 11, 61. [Google Scholar] [CrossRef]
- Qiu, X.; Zhang, L.; Ren, Y.; Suganthan, P.N.; Amaratunga, G. Ensemble deep learning for regression and time series forecasting. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Ensemble Learning (CIEL), Orlando, FL, USA, 9–12 December 2014; IEEE: New York, NY, USA, 2014; pp. 1–6. [Google Scholar]
- Carta, S.; Corriga, A.; Ferreira, A.; Podda, A.S.; Recupero, D.R. A multi-layer and multi-ensemble stock trader using deep learning and deep reinforcement learning. Appl. Intell. 2021, 51, 889–905. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Stavroyiannis, S.; Pintelas, P. Ensemble deep learning models for forecasting cryptocurrency time-series. Algorithms 2020, 13, 121. [Google Scholar] [CrossRef]
- Li, S.; Yao, Y.; Hu, J.; Liu, G.; Yao, X.; Hu, J. An ensemble stacked convolutional neural network model for environmental event sound recognition. Appl. Sci. 2018, 8, 1152. [Google Scholar] [CrossRef] [Green Version]
- Dey, S.; Kumar, Y.; Saha, S.; Basak, S. Forecasting to Classification: Predicting the Direction of Stock Market Price Using Xtreme Gradient Boosting; PESIT South Campus: Bengaluru, India, 2016. [Google Scholar]
- Albaity, M.S. Impact of the monetary policy instruments on Islamic stock market index return. Econ. Discuss. Pap. 2011. [Google Scholar] [CrossRef]
- Selemela, S.M.; Ferreira, S.; Mokatsanyane, D. Analysing Volatility during Extreme Market Events Using the Mid Cap Share Index. Economica 2021, 17, 229–249. [Google Scholar]
- Ederington, L.H.; Guan, W. Measuring historical volatility. J. Appl. Financ. 2006, 16, 10. [Google Scholar]
- Poon, S.H.; Granger, C. Practical issues in forecasting volatility. Financ. Anal. J. 2005, 61, 45–56. [Google Scholar] [CrossRef]
- Botchkarev, A. Performance metrics (error measures) in machine learning regression, forecasting and prognostics: Properties and typology. arXiv 2018, arXiv:1809.03006. [Google Scholar]
- Garosi, Y.; Sheklabadi, M.; Conoscenti, C.; Pourghasemi, H.R.; Van Oost, K. Assessing the performance of GIS-based machine learning models with different accuracy measures for determining susceptibility to gully erosion. Sci. Total. Environ. 2019, 664, 1117–1132. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Optimal deep learning lstm model for electric load forecasting using feature selection and genetic algorithm: Comparison with machine learning approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef]
- Altan, A.; Karasu, S. The effect of kernel values in support vector machine to forecasting performance of financial time series. J. Cogn. Syst. 2019, 4, 17–21. [Google Scholar]
- Song, H.; Dai, J.; Luo, L.; Sheng, G.; Jiang, X. Power transformer operating state prediction method based on an LSTM network. Energies 2018, 11, 914. [Google Scholar] [CrossRef]
- Botchkarev, A. Evaluating Performance of Regression Machine Learning Models Using Multiple Error Metrics in Azure Machine Learning Studio. 2018. Available online: https://ssrn.com/abstract=3177507 (accessed on 10 July 2022). [CrossRef]
- Xu, W.; Zhang, J.; Zhang, Q.; Wei, X. Risk prediction of type II diabetes based on random forest model. In Proceedings of the 2017 Third International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics (AEEICB), Chennai, India, 27–28 February 2017; IEEE: New York, NY, USA, 2017; pp. 382–386. [Google Scholar]
- Shaik, A.B.; Srinivasan, S. A brief survey on random forest ensembles in classification model. In Proceedings of the International Conference on Innovative Computing and Communications, VŠB-Technical University of Ostrava, Ostrava, Czech Republic, 21–22 March 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 253–260. [Google Scholar]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Hu, W.; Hu, W.; Maybank, S. Adaboost-based algorithm for network intrusion detection. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2008, 38, 577–583. [Google Scholar] [PubMed]
- Zhang, Y.; Haghani, A. A gradient boosting method to improve travel time prediction. Transp. Res. Part C Emerg. Technol. 2015, 58, 308–324. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Polikar, R. Ensemble learning. In Ensemble Machine Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–34. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, Y. Ensemble Machine Learning: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Sun, X. Pitch accent prediction using ensemble machine learning. In Proceedings of the Seventh International Conference on Spoken Language Processing, Denver, CO, USA, 16–20 September 2002. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Ince, T.; Hamila, R.; Gabbouj, M. Convolutional neural networks for patient-specific ECG classification. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; IEEE: New York, NY, USA, 2015; pp. 2608–2611. [Google Scholar]
- Kiranyaz, S.; Ince, T.; Gabbouj, M. Real-time patient-specific ECG classification by 1-D convolutional neural networks. IEEE Trans. Biomed. Eng. 2015, 63, 664–675. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Inman, D. Structural damage detection in real time: Implementation of 1D convolutional neural networks for SHM applications. In Structural Health Monitoring & Damage Detection, Volume 7; Springer: Cham, Switzerland, 2017; pp. 49–54. [Google Scholar]
- Kiranyaz, S.; Gastli, A.; Ben-Brahim, L.; Al-Emadi, N.; Gabbouj, M. Real-time fault detection and identification for MMC using 1-D convolutional neural networks. IEEE Trans. Ind. Electron. 2018, 66, 8760–8771. [Google Scholar] [CrossRef]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-time motor fault detection by 1-D convolutional neural networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Abdeljaber, O.; Avci, O.; Kiranyaz, M.S.; Boashash, B.; Sodano, H.; Inman, D.J. 1-D CNNs for structural damage detection: Verification on a structural health monitoring benchmark data. Neurocomputing 2018, 275, 1308–1317. [Google Scholar] [CrossRef]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Boashash, B.; Sodano, H.; Inman, D.J. Efficiency validation of one dimensional convolutional neural networks for structural damage detection using a SHM benchmark data. In Proceedings of the 25th International Congress on Sound and Vibration 2018, (ICSV 25), Hiroshima, Japan, 8–12 July 2018; pp. 4600–4607. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Ragab, M.G.; Abdulkadir, S.J.; Aziz, N.; Al-Tashi, Q.; Alyousifi, Y.; Alhussian, H.; Alqushaibi, A. A Novel One-Dimensional CNN with Exponential Adaptive Gradients for Air Pollution Index Prediction. Sustainability 2020, 12, 10090. [Google Scholar] [CrossRef]
- Haidar, A.; Verma, B. Monthly rainfall forecasting using one-dimensional deep convolutional neural network. IEEE Access 2018, 6, 69053–69063. [Google Scholar] [CrossRef]
- Huang, S.; Tang, J.; Dai, J.; Wang, Y. Signal status recognition based on 1DCNN and its feature extraction mechanism analysis. Sensors 2019, 19, 2018. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Liu, Z.; Peng, D.; Qin, Y. Understanding and learning discriminant features based on multiattention 1DCNN for wheelset bearing fault diagnosis. IEEE Trans. Ind. Inform. 2019, 16, 5735–5745. [Google Scholar] [CrossRef]
- Zhao, X.; Solé-Casals, J.; Li, B.; Huang, Z.; Wang, A.; Cao, J.; Tanaka, T.; Zhao, Q. Classification of Epileptic IEEG Signals by CNN and Data Augmentation. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: New York, NY, USA, 2020; pp. 926–930. [Google Scholar]
- Mandic, D.; Chambers, J. Recurrent Neural Networks for Prediction: Learning Algorithms, Architectures and Stability; John and Wiley and Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Schmidhuber, J. A fixed size storage O (n 3) time complexity learning algorithm for fully recurrent continually running networks. Neural Comput. 1992, 4, 243–248. [Google Scholar] [CrossRef]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 606–615. [Google Scholar]
- Du, J.; Cheng, Y.; Zhou, Q.; Zhang, J.; Zhang, X.; Li, G. Power load forecasting using BiLSTM-attention. Proc. Iop Conf. Ser. Earth Environ. Sci. 2020, 440, 032115. [Google Scholar] [CrossRef]
- Vasquez, S.; Lewis, M. Melnet: A generative model for audio in the frequency domain. arXiv 2019, arXiv:1906.01083. [Google Scholar]
- Jung, J.w.; Heo, H.S.; Kim, J.h.; Shim, H.j.; Yu, H.J. Rawnet: Advanced end-to-end deep neural network using raw waveforms for text-independent speaker verification. arXiv 2019, arXiv:1904.08104. [Google Scholar]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Names of Companies | Duration |
|---|---|
| ABBANK | 2018-01-10–2020-12-07 |
| ACIBANK | 2018-01-10–2020-12-07 |
| APEXFOOT | 2018-02-10–2020-12-07 |
| BANKASIA | 2018-01-10–2020-12-07 |
| BATASHOE | 2018-01-10–2020-12-02 |
| BERGERPBL | 2018-01-10–2020-12-07 |
| BEXIMCO | 2018-01-10–2020-12-07 |
| BRACBANK | 2018-02-10–2020-12-07 |
| CITYBANK | 2018-01-10–2020-12-07 |
| DESCO | 2018-01-10–2020-12-07 |
| DHAKABANK | 2018-01-10–2020-12-07 |
| DUTCHBANGLABANK | 2018-01-10–2020-12-07 |
| Eximbank | 2018-01-10–2020-12-02 |
| Fuwangfood | 2018-01-10–2020-12-07 |
| IBNSINA | 2018-01-10–2020-12-07 |
| IFIC | 2018-01-10–2020-12-07 |
| JAMUNABANK | 2018-01-10–2020-12-07 |
| KEYACOSMET | 2018-01-10–2020-12-07 |
| UTTARABANK | 2018-01-10–2020-12-07 |
| GP | 2018-01-10–2020-12-07 |
| Dataset | Deep Learning Models | RMSE | MAE |
|---|---|---|---|
| ABBANK | CNN | 3.6829 | 3.4811 |
| LSTM | 3.8222 | 3.7760 | |
| BiLSTM | 3.9660 | 3.9122 | |
| Proposed Stacking Ensemble of Neural Network | 0.6766 | 0.5116 | |
| ACIBANK | CNN | 2.3866 | 1.8764 |
| LSTM | 1.2314 | 0.9824 | |
| BiLSTM | 0.2280 | 0.1931 | |
| Proposed Stacking Ensemble of Neural Network | 1.1880 | 0.8805 | |
| APEXFOOT | CNN | 5.4682 | 5.3320 |
| LSTM | 4.7450 | 4.5975 | |
| BiLSTM | 1.3357 | 1.0584 | |
| Proposed Stacking Ensemble of Neural Network | 1.0634 | 0.9504 | |
| BANKASIA | CNN | 0.6713 | 0.5675 |
| LSTM | 0.4191 | 0.3472 | |
| BiLSTM | 0.4956 | 6.8461 | |
| Proposed Stacking Ensemble of Neural Network | 0.8139 | 0.6806 | |
| BATASHOE | CNN | 6.3256 | 6.0763 |
| LSTM | 7.7107 | 7.5957 | |
| BiLSTM | 1.5567 | 1.3306 | |
| Proposed Stacking Ensemble of Neural Network | 0.9859 | 0.7908 | |
| BERGERPBL | CNN | 5.4822 | 5.4256 |
| LSTM | 5.4605 | 5.3972 | |
| BiLSTM | 4.4781 | 4.4417 | |
| Proposed Stacking Ensemble of Neural Network | 0.4721 | 0.3812 | |
| BEXIMCO | CNN | 5.8887 | 5.8245 |
| LSTM | 5.3503 | 5.3172 | |
| BiLSTM | 2.5656 | 2.5383 | |
| Proposed Stacking Ensemble of Neural Network | 0.6300 | 0.4795 | |
| BRACBANK | CNN | 4.3199 | 3.7514 |
| LSTM | 2.7113 | 2.3612 | |
| BiLSTM | 4.0452 | 3.3964 | |
| Proposed Stacking Ensemble of Neural Network | 2.1705 | 2.4467 | |
| CITYBANK | CNN | 3.2923 | 3.1774 |
| LSTM | 1.8324 | 1.7528 | |
| BiLSTM | 2.7964 | 2.7133 | |
| Proposed Stacking Ensemble of Neural Network | 0.7283 | 0.6993 | |
| DESCO | CNN | 1.0141 | 0.8770 |
| LSTM | 0.9895 | 0.8442 | |
| BiLSTM | 0.7367 | 0.5795 | |
| Proposed Stacking Ensemble of Neural Network | 0.8349 | 0.8349 | |
| DHAKABANK | CNN | 1.5500 | 0.8770 |
| LSTM | 1.0917 | 1.0176 | |
| BiLSTM | 1.6444 | 1.4745 | |
| Proposed Stacking Ensemble of Neural Network | 0.5206 | 0.5206 | |
| DUTCHBANGLABANK | CNN | 11.5777 | 11.4175 |
| LSTM | 15.2332 | 15.1668 | |
| BiLSTM | 10.1262 | 10.0926 | |
| Proposed Stacking Ensemble of Neural Network | 1.0317 | 0.9021 | |
| EXIMBANK | CNN | 0.8822 | 0.7254 |
| LSTM | 1.04872 | 0.8899 | |
| BiLSTM | 0.4895 | 0.3822 | |
| Proposed Stacking Ensemble of Neural Network | 0.4631 | 0.4093 | |
| FUWANGFOOD | CNN | 3.6536 | 2.7259 |
| LSTM | 4.4977 | 3.5727 | |
| BiLSTM | 2.2982 | 1.8985 | |
| Proposed Stacking Ensemble of Neural Network | 2.5696 | 2.444 | |
| GP | CNN | 1.6824 | 1.4521 |
| LSTM | 0.9660 | 0.7848 | |
| BiLSTM | 1.0760 | 0.9343 | |
| Proposed Stacking Ensemble of Neural Network | 0.5970 | 0.4611 | |
| IBNSINA | CNN | 1.4132 | 1.2915 |
| LSTM | 1.6709 | 1.5288 | |
| BiLSTM | 1.0107 | 0.8399 | |
| Stacking Neural Network Ensemble | 0.9153 | 0.9659 | |
| IFIC | CNN | 1.1520 | 0.9446 |
| LSTM | 1.81234 | 1.5902 | |
| BiLSTM | 1.8714 | 1.8041 | |
| Proposed Stacking Ensemble of Neural Network | 0.3626 | 0.3682 | |
| JAMUNABANK | CNN | 1.0167 | 0.8089 |
| LSTM | 0.4649 | 0.3752 | |
| BiLSTM | 0.7879 | 0.6579 | |
| Proposed Stacking Ensemble of Neural Network | 0.5614 | 0.5526 | |
| KEYACOSMET | CNN | 6.8706 | 6.6129 |
| LSTM | 5.8391 | 5.7513 | |
| BiLSTM | 8.4249 | 8.3693 | |
| Proposed Stacking Ensemble of Neural Network | 1.0614 | 0.9095 | |
| UTTARABANK | CNN | 1.3121 | 1.0543 |
| LSTM | 0.9504 | 0.7705 | |
| BiLSTM | 0.6997 | 0.5853 | |
| Proposed Stacking Ensemble of Neural Network | 0.6741 | 0.6611 |
| Dataset | Machine Learning Models | RMSE | MAE |
|---|---|---|---|
| ABBANK | ML ensemble method (RandomForest) | 4.3384 | 4.2509 |
| ML ensemble method (AdaBoost) | 6.1229 | 6.0434 | |
| ML ensemble method (GradientBoosting) | 6.9083 | 6.8461 | |
| ML Stacking Ensemble Learning | 5.1710 | 4.8450 | |
| ACIBANK | ML ensemble method (RandomForest) | 2.3326 | 1.6824 |
| ML ensemble method (AdaBoost) | 2.7053 | 2.0491 | |
| ML ensemble method (GradientBoosting) | 2.4149 | 1.8078 | |
| ML Stacking Ensemble Learning | 1.9230 | 1.6032 | |
| APEXFOOT | ML ensemble method (Randomforest) | 6.6466 | 6.4764 |
| ML ensemble method (AdaBoost) | 7.3927 | 7.2382 | |
| ML ensemble method (GradientBoosting) | 7.6668 | 7.526 | |
| ML Stacking Ensemble Learning | 5.2078 | 5.0352 | |
| BANKASIA | ML ensemble method (RandomForest) | 0.4049 | 0.3000 |
| ML ensemble method (AdaBoost) | 0.4208 | 0.2945 | |
| ML ensemble method (GradientBoosting) | 0.4052 | 0.2987 | |
| ML Stacking Ensemble Learning | 0.6428 | 0.4658 | |
| BATASHOE | ML ensemble method (RandomForest) | 6.2606 | 5.9338 |
| ML ensemble method (AdaBoost) | 7.1886 | 6.9948 | |
| ML ensemble method (GradientBoosting) | 6.0615 | 5.7666 | |
| ML Stacking Ensemble Learning | 5.7256 | 5.6674 | |
| BERGERPBL | ML ensemble method (RandomForest) | 5.3535 | 5.2818 |
| ML ensemble method (AdaBoost) | 7.8242 | 7.7765 | |
| ML ensemble method (GradientBoosting) | 6.6984 | 7.0529 | |
| ML Stacking Ensemble Learning | 4.9378 | 4.8600 | |
| BEXIMCO | ML ensemble method (RandomForest) | 6.4896 | 6.3802 |
| ML ensemble method (AdaBoost) | 7.1802 | 7.0570 | |
| ML ensemble method (GradientBoosting) | 7.1802 | 7.5636 | |
| ML Stacking Ensemble Learning | 9.5758 | 9.5000 | |
| BRACBANK | ML ensemble method (Randomforest) | 5.8722 | 4.4277 |
| ML ensemble method (AdaBoost) | 6.3241 | 4.8102 | |
| ML ensemble method (GradientBoosting) | 7.1432 | 5.7192 | |
| ML Stacking Ensemble Learning | 6.5281 | 5.6115 | |
| CITYBANK | ML ensemble method (Randomforest) | 3.6603 | 3.5544 |
| ML ensemble method (Adaboost) | 5.1566 | 5.0716 | |
| ML ensemble method (GradientBoosting) | 4.5469 | 4.4633 | |
| ML Stacking Ensemble Learning | 3.6076 | 3.5365 | |
| DESCO | ML ensemble method (Randomforest) | 1.0350 | 0.8394 |
| ML ensemble method (Adaboost) | 1.6060 | 1.3092 | |
| ML ensemble method (GradientBoosting) | 1.1690 | 0.9720 | |
| ML Stacking Ensemble Learning | 0.9726 | 0.8290 | |
| DHAKABANK | ML ensemble method (RandomForest) | 1.4607 | 1.2543 |
| ML ensemble method (AdaBoost) | 1.7555 | 1.6016 | |
| ML ensemble method (GradientBoosting) | 1.6657 | 1.4554 | |
| ML Stacking Ensemble Learning | 1.6992 | 1.5735 | |
| DUTCHBANGLABANK | ML ensemble method (RandomForest) | 15.4895 | 15.4166 |
| ML ensemble method (AdaBoost) | 18.8228 | 18.7540 | |
| ML ensemble method (GradientBoosting) | 14.9011 | 14.8032 | |
| ML Stacking Ensemble Learning | 20.4852 | 20.4260 | |
| Eximbank | ML ensemble method (Randomforest) | 0.9836 | 0.8807 |
| ML ensemble method (Adaboost) | 1.4827 | 1.3170 | |
| ML ensemble method (GradientBoosting) | 1.2541 | 1.0899 | |
| ML Stacking Ensemble Learning | 0.7287 | 0.6072 | |
| Fuwangfood | ML ensemble method (RandomForest) | 7.3138 | 6.1929 |
| ML ensemble method (AdaBoost) | 7.5585 | 6.2670 | |
| ML ensemble method (GradientBoosting) | 9.7713 | 8.6078 | |
| ML Stacking Ensemble Learning | 5.2664 | 4.5548 | |
| IBNSINA | ML ensemble method (RandomForest) | 1.3931 | 1.1716 |
| ML ensemble method (AdaBoost) | 1.5116 | 1.2887 | |
| ML ensemble method (GradientBoosting) | 1.4613 | 1.2196 | |
| ML Stacking Ensemble Learning | 1.2653 | 1.0263 | |
| IFIC | ML ensemble method (Randomforest) | 3.5166 | 3.4134 |
| ML ensemble method (AdaBoost) | 3.8412 | 3.7434 | |
| ML ensemble method (GradientBoosting) | 4.2209 | 4.0965 | |
| ML Stacking Ensemble Learning | 2.9332 | 2.8153 | |
| JAMUNABANK | ML ensemble method (RandomForest) | 0.3725 | 0.2716 |
| ML ensemble method (AdaBoost) | 0.4013 | 0.2725 | |
| ML ensemble method (GradientBoosting) | 0.5965 | 0.4986 | |
| ML Stacking Ensemble Learning | 0.5364 | 0.4164 | |
| KEYACOSMET | ML ensemble method (RandomForest) | 6.7334 | 6.4327 |
| ML ensemble method (AdaBoost) | 7.7225 | 7.4159 | |
| ML ensemble method (GradientBoosting) | 8.1252 | 7.5307 | |
| ML Stacking Ensemble Learning | 9.0140 | 8.8783 | |
| UTTARABANK | ML ensemble method (RandomForest) | 0.9987 | 0.6482 |
| ML ensemble method (AdaBoost) | 1.0256 | 0.6621 | |
| ML ensemble method (GradientBoosting) | 1.0327 | 0.6583 | |
| ML stacking Ensemble Learning | 0.9832 | 0.7307 |
| Dataset Name | SVR | FNN | DBN | ENN | Proposed |
|---|---|---|---|---|---|
| Mackey-Glass | 0.0024 | 0.002 | 0.0018 | 0.0226 | 0.0015 |
| NSW | 74.3053 | 95.8105 | 90.2061 | 78.6394 | 72.2545 |
| SA | 44.6742 | 38.8585 | 35.9375 | 34.9473 | 30.5989 |
| TAS | 20.1068 | 19.7952 | 19.9187 | 19.9034 | 19.7580 |
| CART | 0.0406 | 0.0420 | 0.0412 | 0.0428 | 0.0403 |
| FAD | 0.0339 | 0.0349 | 0.0320 | 0.0315 | 0.0313 |
| CH | 0.1637 | 0.1803 | 0.1773 | 0.1615 | 0.1508 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akter, M.S.; Shahriar, H.; Chowdhury, R.; Mahdy, M.R.C. Forecasting the Risk Factor of Frontier Markets: A Novel Stacking Ensemble of Neural Network Approach. Future Internet 2022, 14, 252. https://doi.org/10.3390/fi14090252
Akter MS, Shahriar H, Chowdhury R, Mahdy MRC. Forecasting the Risk Factor of Frontier Markets: A Novel Stacking Ensemble of Neural Network Approach. Future Internet. 2022; 14(9):252. https://doi.org/10.3390/fi14090252
Chicago/Turabian StyleAkter, Mst. Shapna, Hossain Shahriar, Reaz Chowdhury, and M. R. C. Mahdy. 2022. "Forecasting the Risk Factor of Frontier Markets: A Novel Stacking Ensemble of Neural Network Approach" Future Internet 14, no. 9: 252. https://doi.org/10.3390/fi14090252
APA StyleAkter, M. S., Shahriar, H., Chowdhury, R., & Mahdy, M. R. C. (2022). Forecasting the Risk Factor of Frontier Markets: A Novel Stacking Ensemble of Neural Network Approach. Future Internet, 14(9), 252. https://doi.org/10.3390/fi14090252