


A Structured Narrative Prompt for Prompting Narratives from Large Language Models: Sentiment Assessment of ChatGPT-Generated Narratives and Real Tweets

 , , , , and
, , , , and
Abstract
:1. Introduction
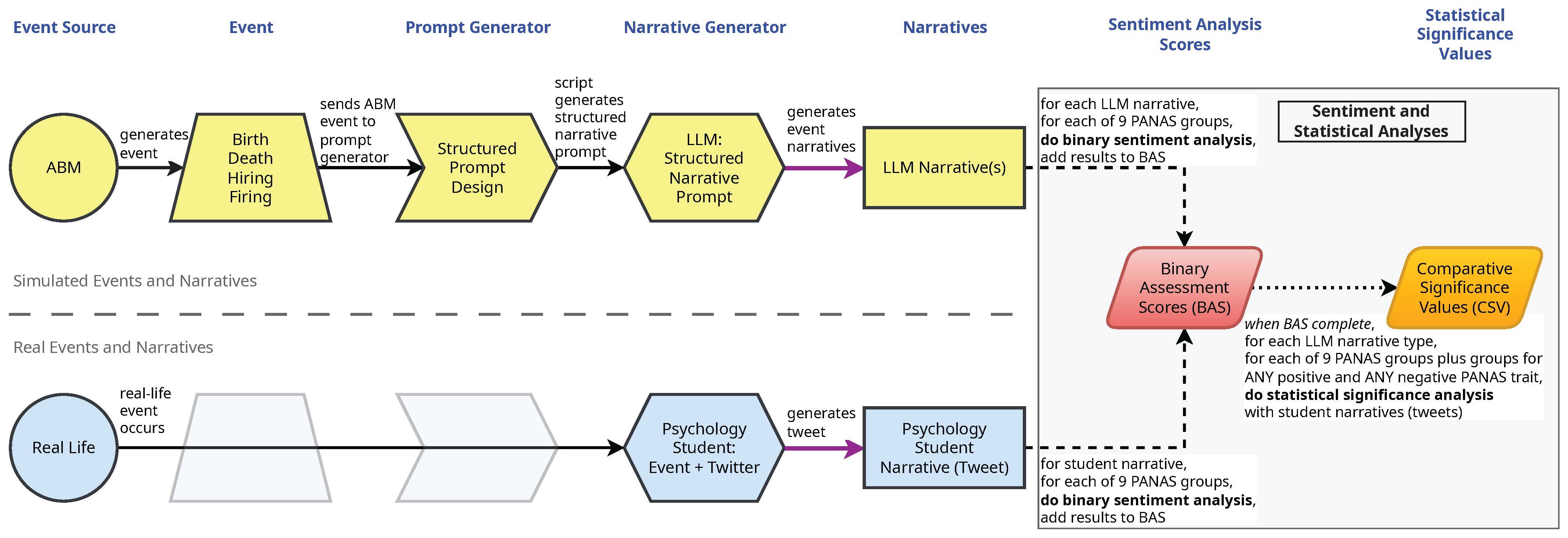
2. Materials and Methods
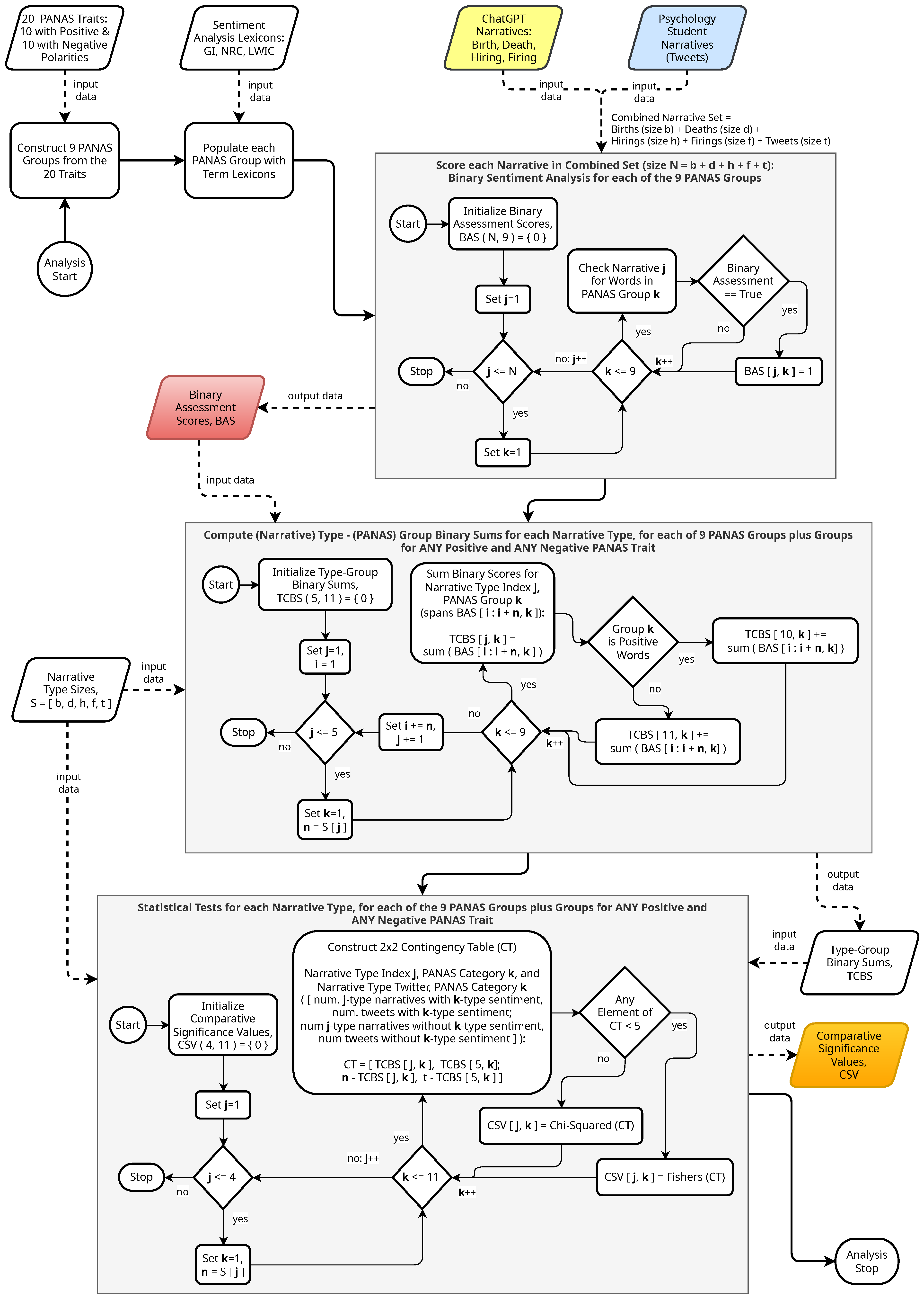
2.1. Sentiment Scoring and Statistical Analysis
2.2. LLM Selection
2.3. ChatGPT API Usage
- openai.Completion.create() is used for single-turn conversations and supports completion models such as gpt-3.5-turbo-instruct and text-davinci-003.
- openai.ChatCompletion.create() is used for single- or multi-turn conversations and supports chat completion models such as gpt-4 and gpt-3.5-turbo [84].
- User, for application- or API-user-submitted prompts;
- System, for constraints or special instructions that inform an entire conversation, which may be used by software developers to affect the experience of the application user;
- Assistant, for responses to user queries, i.e., ChatGPT responses [85].
2.4. Datasets
- ABM simulation output data on Agents’ Life Events in CSV format.
- (a)
- ABM simulation of life event data.
- Narratives generated using ChatGPT based on simulated agents’ life event information. Ten narratives generated per simulation life event.
- (a)
- Structured ChatGPT API prompts;
- (b)
- Sets of ChatGPT response narratives.
- Real tweets obtained from Twitter [43].
- (a)
- Tweet set with PII removed (dropped IDs and screen names);
- (b)
- IRB documentation.
- Also included:
- (a)
- Source codes (R): sentiment analysis and statistical significance scripts;
- (b)
- Source codes (Python): ChatGPT prompt generation, prompt submission, and analysis preparation scripts;
- (c)
- PANAS sentiment keyword lexicon.
3. Results
3.1. LLM Structured Prompt for Narrative Generation
3.1.1. Experiments with Preliminary Designs
- Adding to or embellishing narratives with information that was not provided and that it had no basis for knowing;
- Creating temporal associations to information from the past which was not provided (i.e., relating present information based on unknowable changes from the past);
- Including congratulatory messaging beyond the scope of the requested narrative content.
3.1.2. Final LLM Narrative Prompt Structure
- Narrative Event Type: What is the life event for which a narrative is being created? This can be anything deemed relevant for an agent such as a birth, marriage, change in education, etc.
- Subject of Narrative: the agent, person, etc. that is the focus of the narrative.
- Subject’s Relationship to Narrator: What is the relationship between the narrator and the subject? Is the narrator referring to itself, a family member, a friend, a co-worker, a romantic connection, etc.?
- Subject’s Characteristics: a set of characteristics pertaining to the subject that are relevant to the narrative event.
- Narrator’s Characteristics: a set of characteristics that are relevant for the creation of the narrative with respect to the narrator, such as age or gender.
- Narrative Tense: past, present, or future.
- Target Audience: Who are the intended readers of the narrative and/or what is the intended medium of the narrative, such as Twitter, email, text message, diary, etc.?
- Voice: Should the narrative use active or passive voice?
- Narrative Immediacy: Should the narrative be conveyed using immediacy? Immediacy provides a more intimate, generally first-person, connection between the narrative and the reader.
- Maximum Temporal Proximity: In the narration, how much time has passed since the life event occurred?
- Target Sentiment Value: the intended level of emotion to convey in the narrative from −1 to +1 with −1 being strongly negative, 0 being neutral, and +1 being strongly positive.
- Subject’s History: the set of historical life events that support or expand upon the current narrative event, if any, such as prior Birth events when narrating a new birth.
- Number of Narratives: the number of narratives to generate using the above criteria.
- Maximum Length: the maximum length and unit of measure of the narrative being generated, i.e., characters, words, tokens, etc.
- Special Tokens: Should the narrative include special tokens such as hashtags and @’s?
- Hyperlinks: a set of hyperlinks to include in the narrative, if any.
- Instructions: set of instructions for getting the large language model to understand how to use this list of criteria as well as any additional instructions needed to hone focus onto only the desired narrative materials.
- Target sentiment value, −1: “Just got off the phone with Joyce, my unemployed mom. She’s been looking for work for over two years now. It’s disheartening to see her struggle. #Unemployment #JobSearch”;
- Target sentiment value, +1: “It’s been 104 weeks since my mom, Joyce, faced unemployment. She’s a fighter and won’t give up. Let’s cheer her on!
![Futureinternet 15 00375 i001]() #Unemployment #Resilience”.
#Unemployment #Resilience”.

- With narrative immediacy: “The world welcomes Baby Max, the precious son of Paul and Ally. May he grow up surrounded by love, joy, and all the wonders life has to offer. Congratulations on this incredible blessing, and may your family be filled with happiness. #BabyBoy #NewestMember”;
- Without narrative immediacy: “Sending my heartfelt congratulations to Paul and Ally on the birth of their precious baby boy, Max! May this new journey be filled with endless love, joy, and beautiful memories. #NewParents #BabyMax”.
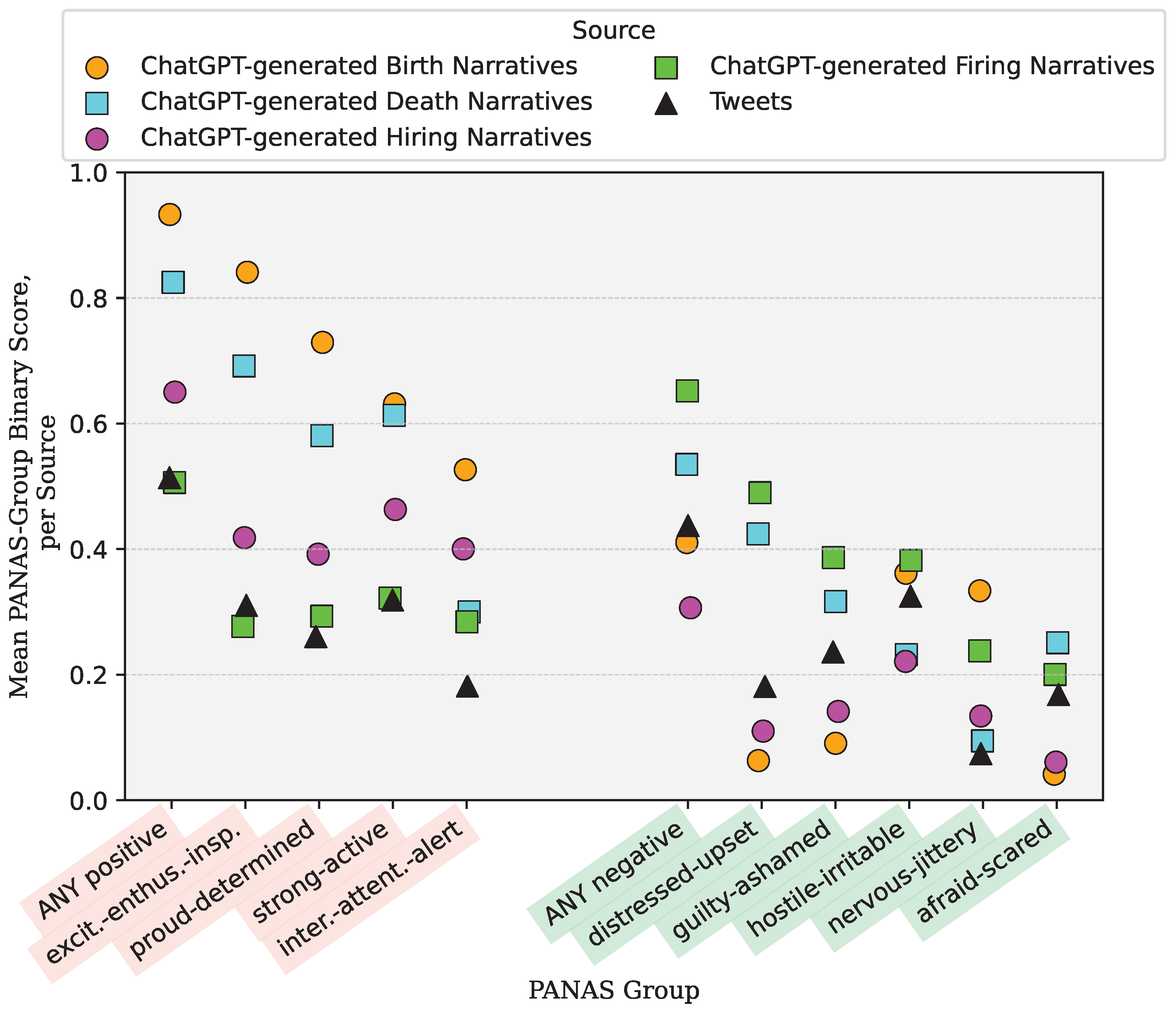
3.2. Statistically Significant and Not Statistically Significant Differences
4. Discussion
4.1. Lessons Learned
- Using the ChatGPT API for generating multiple, independent narratives. The ChatGPT API was not well suited to generating multiple instances of a requested narrative in a single response. There was a strong tendency to narrate a continuous, temporally advancing story instead of a set of independent narratives describing a single life event. Using the n parameter in the Python API ChatCompletion function call appears to remedy this behavior, as ChatGPT generates a set of n independent, unconnected responses. ChatGPT does not appear to retain knowledge of narratives 1 through i when generating the ith narrative, when using the n parameter.
- Balancing creativity with correctness. The level of stochasticity that ChatGPT employs for choosing the next token during text completion is moderated by the temperature parameter. A zero temperature outputs identical responses yielding repeated identical inputs. Increasing the temperature increases the set of next available tokens in the completion, effectively increasing the response space and allowing for greater variation among the responses. If the temperature is set too high and ChatGPT selects inappropriate tokens, this increased creative capacity can impact correctness. However, even when using a temperature of zero for the API, ChatGPT can still produce categorically incorrect responses, such as generating narratives about car fires and house fires when the prompt was to generate narratives about being fired from a job. We utilized a temperature of zero to (i) attempt to limit incorrect narratives and (ii) to address ChatGPT’s tendency toward “storytelling”, instead of generating multiple independent narratives in one response. This ultimately was not very effective, as noted in the previous lesson learned. Conversely, when using the n parameter to generate multiple, different narratives, the temperature value must not be zero as this results in only identical results. For this study, we assigned n to 1 as we requested multiple narratives to be provided in a single response. The default minimum and maximum temperature values for ChatCompletion API calls are 1, 0, and 2. The default value for n is 1.
- ChatGPT API time-out errors. The API fails frequently due to request time-out errors. Therefore, the experimental setup should account for this and should be able to resume efficiently after an error. For this study, a Python script reads prompt files from a directory and moves them to another directory after a successful response is received. In this process, if the script is restarted due to a time-out error, no prompts are lost or repeated.
4.2. Limitations
- Problem type. For this study, ChatGPT was not required to solve complex problems or rely heavily on factual information from training data. All the required factual information, including narrator and subject characteristics, was provided in the prompt. ChatGPT appears well suited to this style of creative task and provides technically correct outputs in a majority of instances as long as the instructions and constraints in the input prompt are observed. Narratives can easily be validated manually by comparing prompt inputs to the created narratives. This differs from other types of tasks, such as asking ChatGPT to solve a mathematical problem or to diagnose a medical condition [28], which require domain knowledge of much more complex background information that is not included in the prompt. These problem types are much less subjective and not as easily validated. Further, ChatGPT currently cannot accurately provide sources or references for validating the response information. In this case, the human reader has to determine if the response is legitimate or if ChatGPT has “hallucinated” some trustworthy-sounding but incorrect response, without the benefit of reliable references [36].
- Use case. For this study, the generated narratives were not posted to social media or broadcast in any way, but were used solely for analysis. Incorrect narratives were identified manually and used to inform corrections to the structured narrative prompt but did not incur any other negative consequences. For use cases in which responses are not or cannot be validated by a human before utilization, there is a risk of dissemination of erroneous information. Numerous correct prior responses do not prevent incorrect responses from occurring in the future; in other words, there is no way to bound or know the response space [36]. As noted in the second lesson learned, even with minimal stochasticity, ChatGPT generated completely incorrect narratives about car fires and house fires, which could not have been predicted by the hundreds of preceding responses for that event type which did not do this.
- ChatGPT API response speed. As noted in the third lesson learned, the Python API regularly failed due to time-out errors, so this currently might not be an appropriate tool for situations with strict time constraints.
- Token volume in real time/quicker than real time. The ability to generalize our approach for real-time applications of ChatGPT for narrative generation is limited based on the token limit of the API. The current ChatGPT API version has a rate limit of 3500 requests per minute and 90,000 tokens per minute [91].
- Domain expertise. The creation of LLMs is based on broad ranges of volumes of reference literature. It is important to determine that generated results are in line with the domain expertise of the targeted problem or system [92]. This article does not attempt to refine the learning base of the LLM for the narration of key life events, as the broad range of potential response types for individuals was desirable as the starting point for this effort. However, future avenues of research require assessing the validity of narratives within their respective domains, such as for births and Death events, and within a larger context, such as refugee camps, natural disaster response, etc.
- Underspecification hinders narrative generation. Increased specificity in the prompting of desired narratives from ChatGPT has been beneficial in reducing the number of iterations for generating and assessing the correctness of the narratives. Similar to ML pipeline problems with underspecification, where underspecification in training leads to problems in reliability and validity [93], underspecification of narrative requests from ChatGPT led to many more erroneous responses and the expansion of the structure provided in this article.
- Tweet comparison sets. Tweets were not categorized per event type like the generated narratives. The tweet set is utilized assuming that it represents a general sample of the population. As such, the generalizability of the sentiment findings should not be extended to other sample populations without proper supporting justifications about the reasonableness of the extension.
- Not Correcting for Multiple Comparisons. For tests involving multiple comparisons, it is common practice to apply a correction to adjust the significance level of the applied hypothesis tests. However, no correction is advised if: (1) the study is restricted to a small number of planned comparisons; (2) the study is exploratory using post hoc testing of unplanned comparisons for further investigation; (3) multiple simple tests are envisaged and it is the results of the individual tests that are important; (4) it is imperative to avoid a type II error [94]. Meanwhile, a Bonferroni correction is advised if: (A) a single test of the universal null hypothesis that all tests are not significant is required; (B) it is imperative to avoid a type I error; (C) a large number of tests are carried out without preplanned hypotheses in an attempt to establish that any result may be significant [94]. The design of this study fits with all four points for when the correction is not necessary and it does not fit any of the three points pertaining to when to utilize the Bonferroni correction. Additionally, since we are interested in the individual comparisons for each PANAS category, not applying the Bonferroni correction is more appropriate for the design of this study as we are interested in identifying interesting patterns or potential relationships that may warrant further investigation. For this study, we are accepting a higher risk of Type I errors (false positives) to reduce the chance of Type II errors (false negatives). As such, this study is more willing to identify something as significant even if it might not be, in order to not miss any potential findings.
4.3. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABM | Agent-Based Model |
| API | Application Programming Interface |
| GPT | Generative Pre-trained Transformer |
| LLM | Large Language Model |
| PANAS | Positive and Negative Affect Schedule |
Appendix A. PANAS Lexicon
Breakdown of the PANAS Lexicon

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PANAS_Trait | PANAS_Group | PANAS_Polarity | Lexicon | Lexicon_Subgroup | Lexicon_Subgroup_Description | Comments |
|---|---|---|---|---|---|---|
| interested | interested | alert | attentive | positive | NRC | anticipation | 839 words associated with anticipation through MTurk crowdsourcing | only include positive words |
| alert | interested | alert | attentive | positive | General Inquirer | Perceiv | 167 words associated with perception and perceiving | only include positive words |
| attentive | interested | alert | attentive | positive | NRC | anticipation | 839 words associated with anticipation through MTurk crowdsourcing | only include positive words |
| excited | excited | enthusiastic | inspired | positive | General Inquirer | Arousal | 67 words indicating excitation; aside from pleasures or pains; but including arousal of affiliation and hostility | only include positive words |
| enthusiastic | excited | enthusiastic | inspired | positive | General Inquirer | Arousal | 67 words indicating excitation; aside from pleasures or pains; but including arousal of affiliation and hostility | only include positive words |
| inspired | excited | enthusiastic | inspired | positive | NRC | joy | 689 words associated with joy through MTurk crowdsourcing | only include positive words |
| proud | proud | determined | positive | NRC | trust | 1231 words associated with trust through MTurk crowdsourcing | only include positive words |
| determined | proud | determined | positive | General Inquirer | Pleasur | 168 words indicating the enjoyment of a feeling. Including words indicating confidence; interest and commitment | only include positive words |
| active | strong | active | positive | General Inquirer | Active | 1902 words implying strength | only include positive words |
| strong | strong | active | positive | General Inquirer | Strong | 2045 words implying an active orientation | only include positive words |
| distressed | distressed | upset | negative | General Inquirer | Pain | 254 words indicating suffering; lack of confidence; or commitment | only include negative words |
| upset | distressed | upset | negative | NRC | sadness | 1191 words associated with sadness through MTurk crowdsourcing | only include negative words |
| guilty | guilty | ashamed | negative | General Inquirer | Vice | 685 words indicating an assessment of moral disapproval or misfortune | only include negative words |
| ashamed | guilty | ashamed | negative | NRC | disgust | 1058 words associated with disgust through MTurk crowdsourcing | only include negative words |
| hostile | hostile | irritable | negative | General Inquirer | Arousal | 67 words indicating excitation; aside from pleasures or pains; but including arousal of affiliation and hostility | only include negative words |
| irritable | hostile | irritable | negative | NRC | anger | 1247 words associated with anger through MTurk crowdsourcing | only include negative words |
| nervous | nervous | jiittery | negative | LWIC | anxiety | 196 words associated with anxiety in the LWIC 2015 dictionary | only include negative words |
| jittery | nervous | jiittery | negative | NRC | anticipation | 839 words associated with anticipation through MTurk crowdsourcing | only include negative words |
| afraid | afraid | scared | negative | NRC | fear | 1476 words associated with fear through MTurk crowdsourcing | only include negative words |
| scared | afraid | scared | negative | NRC | surprise | 534 words associated with surprise through MTurk crowdsourcing | only include negative words |
Appendix B. Tests for Statistically Significant Differences per PANAS Group
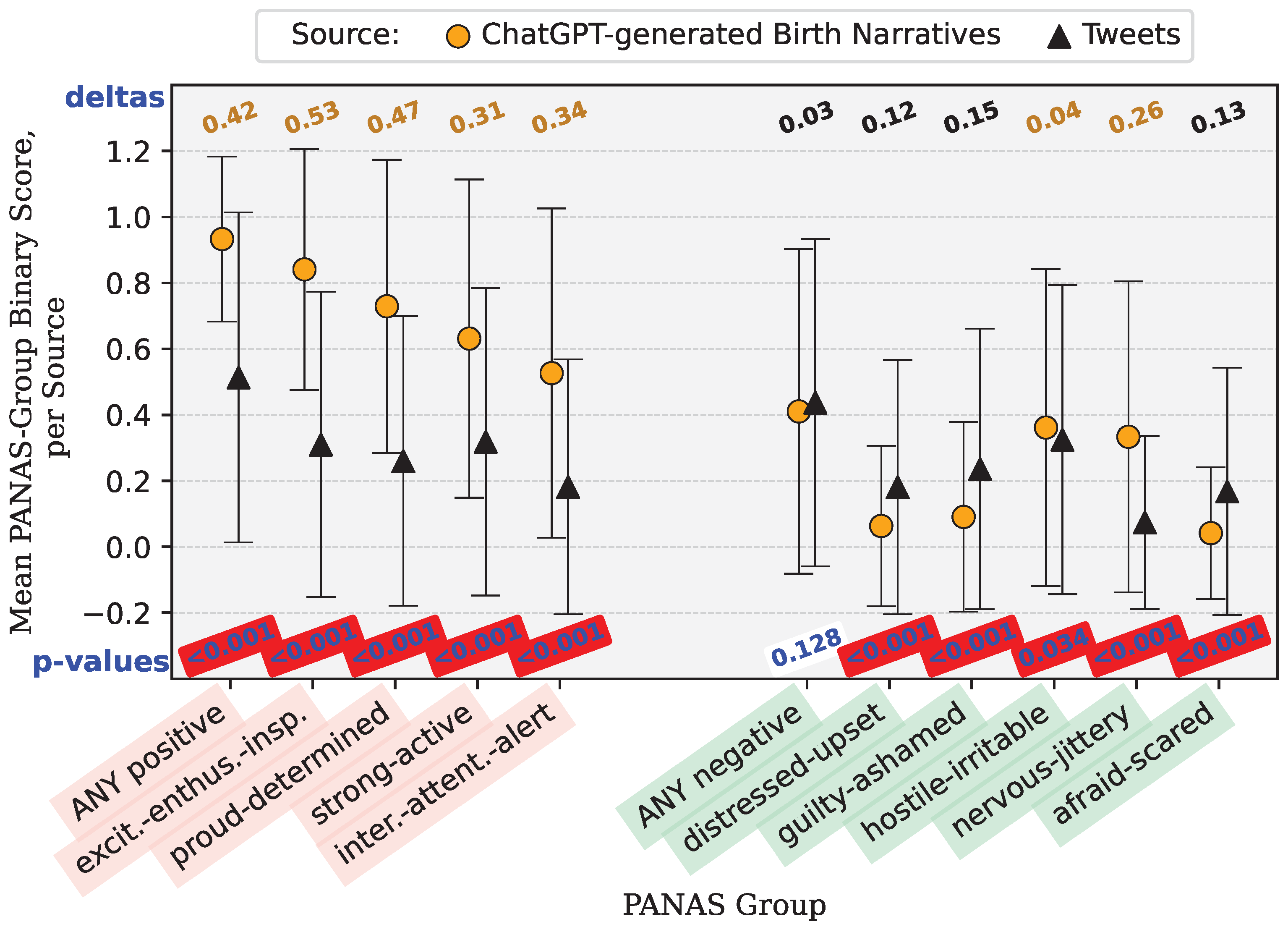
Appendix B.1. Birth Narrative Comparison—Tweets versus ChatGPT-Generated Narratives
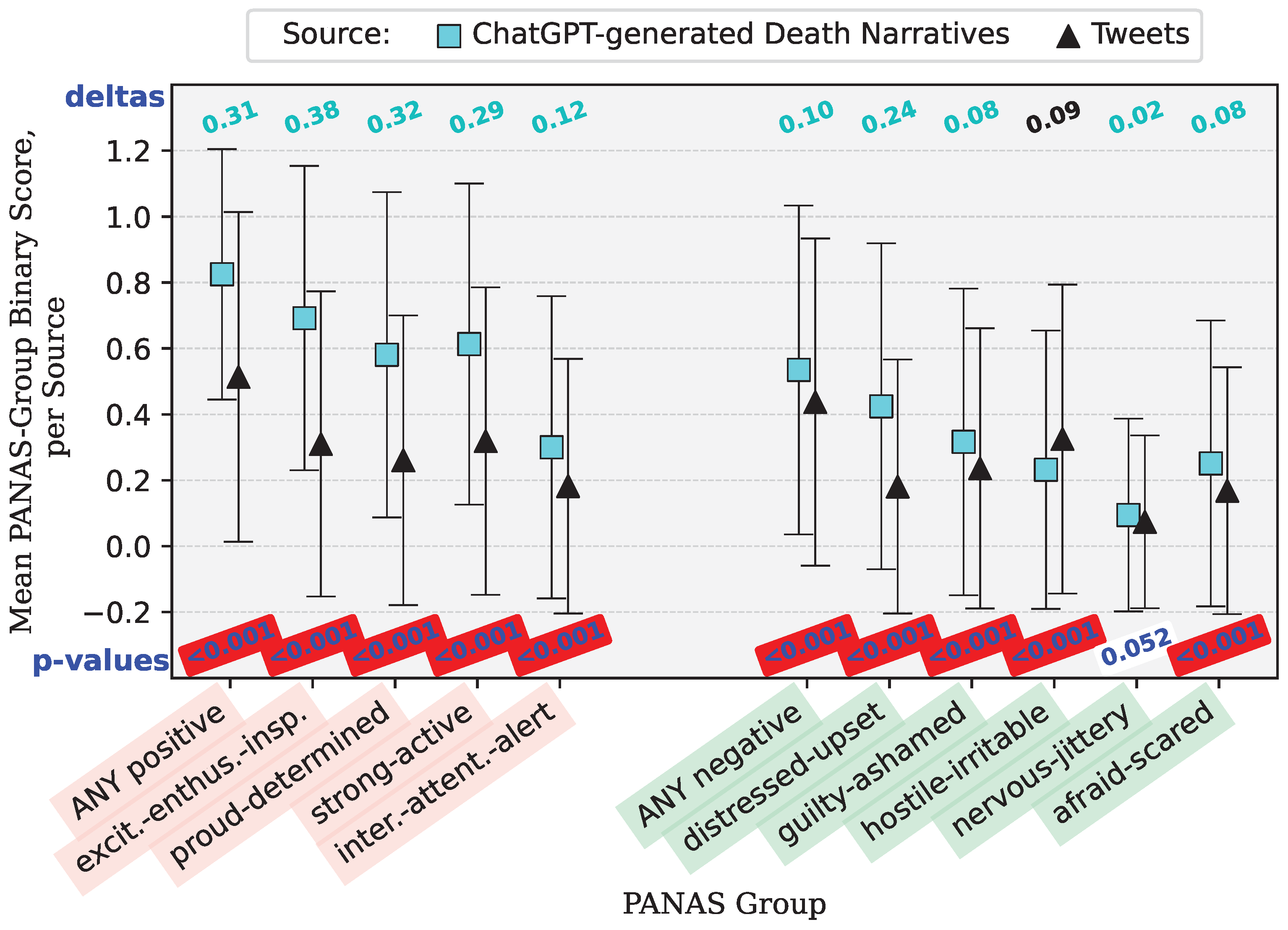
Appendix B.2. Death Narrative Comparison—Tweets versus ChatGPT-Generated Narratives
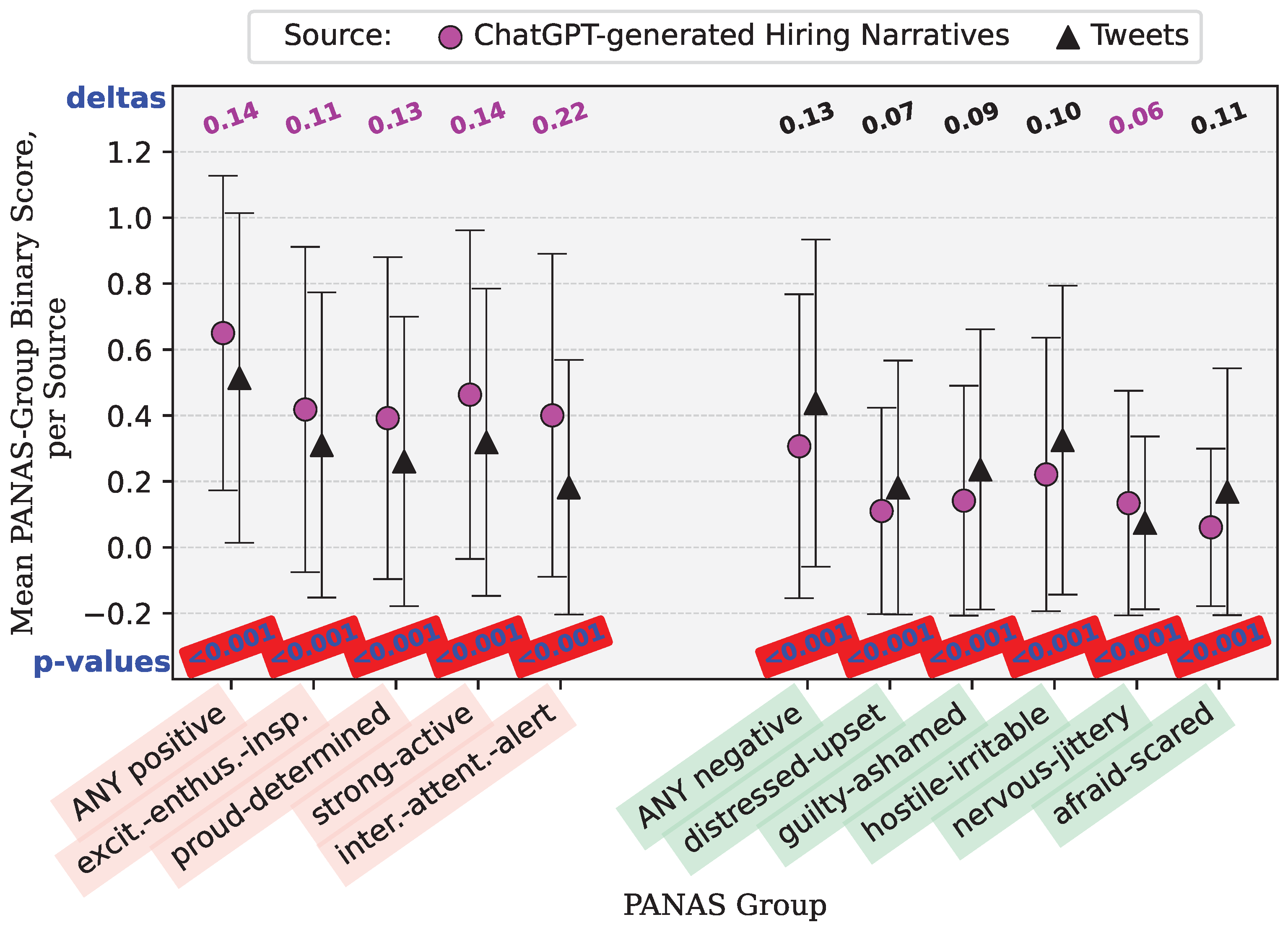
Appendix B.3. Hired Narrative Comparison—Tweets versus ChatGPT-Generated Narratives
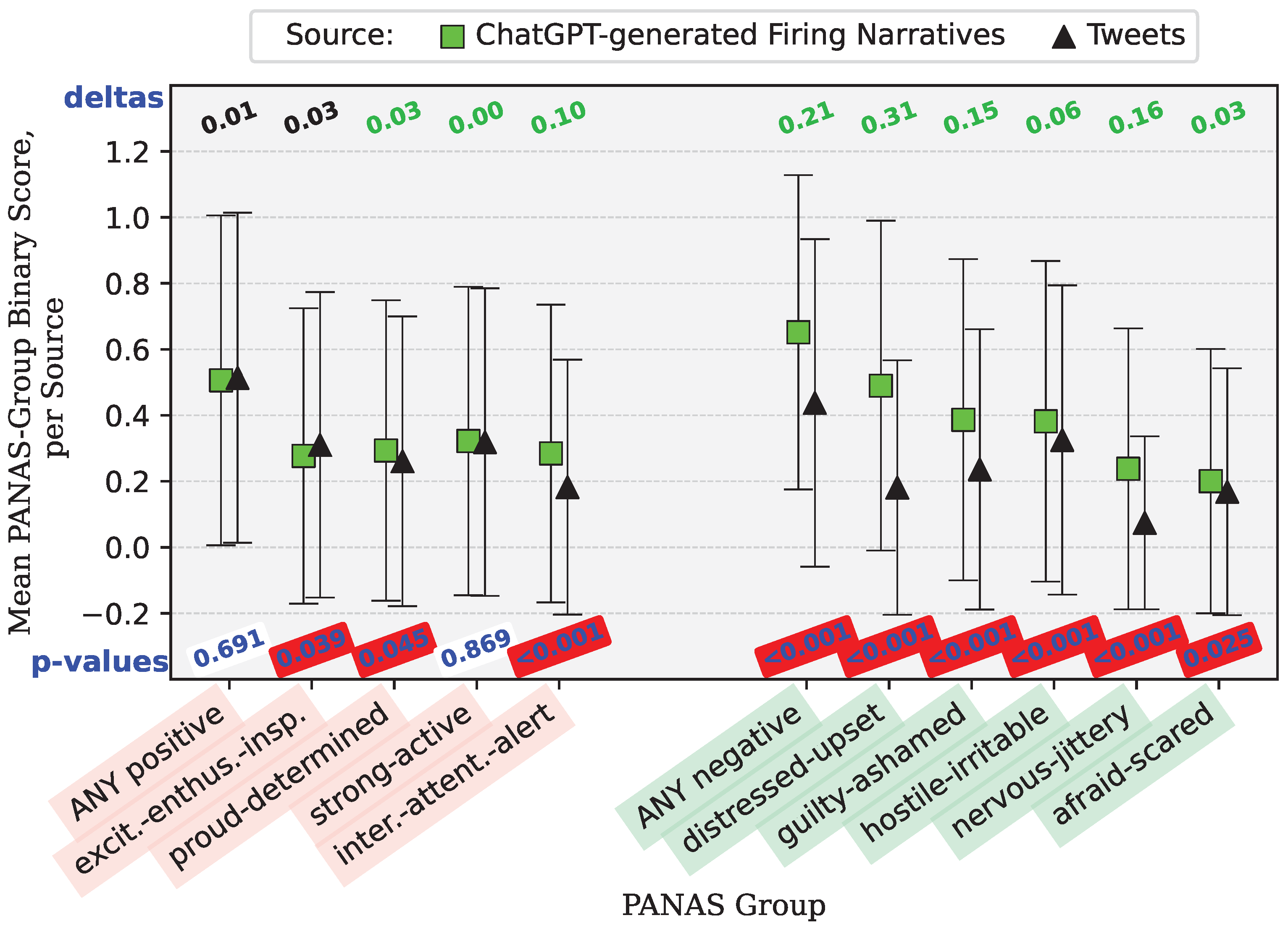
Appendix B.4. Fired Narrative Comparison—Tweets versus ChatGPT-generated Narratives
| PANAS_Group | p Value | Chi Square | Sample 1 Mean | Sample 1 Variance | Sample 2 Mean | Sample 2 Variance | Null Hypothesis Description | Interpretation |
|---|---|---|---|---|---|---|---|---|
| binary_positive | 1.54 × 10 | 1271.77609751028 | 0.933046902971715 | 0.06248156521243 | 0.513771186440678 | 0.250075264662006 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_positive. | Reject the null hypothesis. |
| binary_negative | 1.28 × 10 | 2.3175529292593 | 0.410490511994271 | 0.242031379766721 | 0.4375 | 0.246354718981972 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_negative. | Fail to reject the null hypothesis. |
| binary_interested_attentive_alert | 3.85 × 10 | 382.341055827289 | 0.526494808449696 | 0.249342662193276 | 0.182203389830508 | 0.149163326563258 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_interested_attentive_alert. | Reject the null hypothesis. |
| binary_excited_enthusiastic_inspired | 7.54 × 10 | 1259.39464167701 | 0.841031149301826 | 0.133721693926593 | 0.310381355932203 | 0.214271752610673 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_excited_enthusiastic_inspired. | Reject the null hypothesis. |
| binary_proud_determined | 6.84 × 10 | 790.3284693054 | 0.729323308270677 | 0.197446166894407 | 0.260593220338983 | 0.192888725128961 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_proud_determined. | Reject the null hypothesis. |
| binary_strong_active | 2.03 × 10 | 323.91325121501 | 0.63139992839241 | 0.232775730091311 | 0.31885593220339 | 0.217417141470604 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_strong_active. | Reject the null hypothesis. |
| binary_distressed_upset | 1.27 × 10 | 150.62480849508 | 0.0631936985320444 | 0.0592108548644921 | 0.18114406779661 | 0.148488191311537 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_distressed_upset. | Reject the null hypothesis. |
| binary_guilty_ashamed | 5.39 × 10 | 170.629609145227 | 0.0907626208378088 | 0.082539543641044 | 0.236228813559322 | 0.180616091809407 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_guilty_ashamed. | Reject the null hypothesis. |
| binary_hostile_irritable | 3.37 × 10 | 4.50908186021549 | 0.361618331543144 | 0.230891847857269 | 0.32521186440678 | 0.219681821449755 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_hostile_irritable. | Reject the null hypothesis. |
| binary_nervous_jittery | 1.99 × 10 | 259.704615446121 | 0.333691371285356 | 0.2223812504788 | 0.0741525423728814 | 0.0687267465894998 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_nervous_jittery. | Reject the null hypothesis. |
| binary_afraid_scared | 1.11 × 10 | 228.762692248594 | 0.0415324024346581 | 0.0398145895497152 | 0.168432203389831 | 0.140211325197261 | There is no difference in association between ChatGPT and Twitter for event type Birth in relation to PANAS group: binary_afraid_scared. | Reject the null hypothesis. |
| PANAS_Group | p-Value | Chi Square | Sample 1 Mean | Sample 1 Variance | Sample 2 Mean | Sample 2 Variance | Null Hypothesis Description | Interpretation |
|---|---|---|---|---|---|---|---|---|
| binary_positive | 2.27 × 10 | 443.113978240721 | 0.825024437927664 | 0.144387342969351 | 0.513771186440678 | 0.250075264662006 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_positive. | Reject the null hypothesis. |
| binary_negative | 4.56 × 10 | 29.8974363771416 | 0.534897360703812 | 0.248830821492837 | 0.4375 | 0.246354718981972 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_negative. | Reject the null hypothesis. |
| binary_interested_attentive_alert | 1.85 × 10 | 54.1561060728244 | 0.300097751710655 | 0.210080162519387 | 0.182203389830508 | 0.149163326563258 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_interested_attentive_alert. | Reject the null hypothesis. |
| binary_excited_enthusiastic_inspired | 3.62 × 10 | 497.329564193082 | 0.69188660801564 | 0.213221215141308 | 0.310381355932203 | 0.214271752610673 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_excited_enthusiastic_inspired. | Reject the null hypothesis. |
| binary_proud_determined | 4.56 × 10 | 326.897373112863 | 0.580840664711632 | 0.243512394435225 | 0.260593220338983 | 0.192888725128961 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_proud_determined. | Reject the null hypothesis. |
| binary_strong_active | 6.55 × 10 | 280.273129126093 | 0.613294232649071 | 0.237210792369938 | 0.31885593220339 | 0.217417141470604 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_strong_active. | Reject the null hypothesis. |
| binary_distressed_upset | 5.98 × 10 | 197.905833824767 | 0.424437927663734 | 0.244338142166999 | 0.18114406779661 | 0.148488191311537 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_distressed_upset. | Reject the null hypothesis. |
| binary_guilty_ashamed | 1.01 × 10 | 23.9027316013673 | 0.316520039100684 | 0.216377406471645 | 0.236228813559322 | 0.180616091809407 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_guilty_ashamed. | Reject the null hypothesis. |
| binary_hostile_irritable | 1.25 × 10 | 36.8931130725158 | 0.231867057673509 | 0.178139552131251 | 0.32521186440678 | 0.219681821449755 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_hostile_irritable. | Reject the null hypothesis. |
| binary_nervous_jittery | 5.19 × 10 | 3.777433589273 | 0.0946236559139785 | 0.0856867717124823 | 0.0741525423728814 | 0.0687267465894998 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_nervous_jittery. | Fail to reject the null hypothesis. |
| binary_afraid_scared | 5.56 × 10 | 29.5095216189555 | 0.251026392961877 | 0.188048907203158 | 0.168432203389831 | 0.140211325197261 | There is no difference in association between ChatGPT and Twitter for event type Death in relation to PANAS group: binary_afraid_scared. | Reject the null hypothesis. |
| PANAS_Group | p-Value | Chi Square | Sample 1 Mean | Sample 1 Variance | Sample 2 Mean | Sample 2 Variance | Null Hypothesis Description | Interpretation |
|---|---|---|---|---|---|---|---|---|
| binary_positive | 1.57 × 10 | 63.5460828619453 | 0.650082614283092 | 0.227516978116704 | 0.513771186440678 | 0.250075264662006 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_positive. | Reject the null hypothesis. |
| binary_negative | 3.16 × 10 | 62.1642168708749 | 0.306590783917753 | 0.212631911652103 | 0.4375 | 0.246354718981972 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_negative. | Reject the null hypothesis. |
| binary_interested_attentive_alert | 1.73 × 10 | 163.735966599973 | 0.40040389205067 | 0.240124699125503 | 0.182203389830508 | 0.149163326563258 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_interested_attentive_alert. | Reject the null hypothesis. |
| binary_excited_enthusiastic_inspired | 5.59 × 10 | 38.4587917449052 | 0.418211859739306 | 0.243355377068281 | 0.310381355932203 | 0.214271752610673 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_excited_enthusiastic_inspired. | Reject the null hypothesis. |
| binary_proud_determined | 1.71 × 10 | 58.8354788930908 | 0.39195887644575 | 0.238370877485921 | 0.260593220338983 | 0.192888725128961 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_proud_determined. | Reject the null hypothesis. |
| binary_strong_active | 2.24 × 10 | 67.379017495558 | 0.463190747200294 | 0.248690735367914 | 0.31885593220339 | 0.217417141470604 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_strong_active. | Reject the null hypothesis. |
| binary_distressed_upset | 8.88 × 10 | 37.5565339193202 | 0.11015237745548 | 0.0980368295128006 | 0.18114406779661 | 0.148488191311537 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_distressed_upset. | Reject the null hypothesis. |
| binary_guilty_ashamed | 1.81 × 10 | 54.1980526347543 | 0.141545805030292 | 0.121532902005443 | 0.236228813559322 | 0.180616091809407 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_guilty_ashamed. | Reject the null hypothesis. |
| binary_hostile_irritable | 5.23 × 10 | 47.5976419941658 | 0.221222691389756 | 0.172314847020812 | 0.32521186440678 | 0.219681821449755 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_hostile_irritable. | Reject the null hypothesis. |
| binary_nervous_jittery | 3.56 × 10 | 25.9203411667911 | 0.134202313199927 | 0.116213387633282 | 0.0741525423728814 | 0.0687267465894998 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_nervous_jittery. | Reject the null hypothesis. |
| binary_afraid_scared | 3.66 × 10 | 130.225462320604 | 0.0607673948962732 | 0.0570851987310565 | 0.168432203389831 | 0.140211325197261 | There is no difference in association between ChatGPT and Twitter for event type Hired in relation to PANAS group: binary_afraid_scared. | Reject the null hypothesis. |
| PANAS_Group | p-Value | Chi Square | Sample 1 Mean | Sample 1 Variance | Sample 2 Mean | Sample 2 Variance | Null Hypothesis Description | Interpretation |
|---|---|---|---|---|---|---|---|---|
| binary_positive | 6.91 × 10 | 0.157707980552807 | 0.506150174407931 | 0.250008073660913 | 0.513771186440678 | 0.250075264662006 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_positive. | Fail to reject the null hypothesis. |
| binary_negative | 7.91 × 10 | 156.134224715704 | 0.651918487240683 | 0.226962440655221 | 0.4375 | 0.246354718981972 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_negative. | Reject the null hypothesis. |
| binary_interested_attentive_alert | 8.38 × 10 | 42.1673533305469 | 0.284376721130898 | 0.203543969696702 | 0.182203389830508 | 0.149163326563258 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_interested_attentive_alert. | Reject the null hypothesis. |
| binary_excited_enthusiastic_inspired | 3.91 × 10 | 4.25626862354168 | 0.277033229300532 | 0.200322595847502 | 0.310381355932203 | 0.214271752610673 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_excited_enthusiastic_inspired. | Reject the null hypothesis. |
| binary_proud_determined | 4.53 × 10 | 4.00823113260934 | 0.293188911327336 | 0.207267225231407 | 0.260593220338983 | 0.192888725128961 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_proud_determined. | Reject the null hypothesis. |
| binary_strong_active | 8.69 × 10 | 0.0272449639570703 | 0.322195704057279 | 0.218425732533873 | 0.31885593220339 | 0.217417141470604 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_strong_active. | Fail to reject the null hypothesis. |
| binary_distressed_upset | 3.20 × 10 | 309.235428470664 | 0.489810905085368 | 0.249942068533279 | 0.18114406779661 | 0.148488191311537 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_distressed_upset. | Reject the null hypothesis. |
| binary_guilty_ashamed | 1.17 × 10 | 77.7566103482615 | 0.386451257572976 | 0.237150220860978 | 0.236228813559322 | 0.180616091809407 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_guilty_ashamed. | Reject the null hypothesis. |
| binary_hostile_irritable | 9.81 × 10 | 10.8626035628716 | 0.382045162474757 | 0.236130006773785 | 0.32521186440678 | 0.219681821449755 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_hostile_irritable. | Reject the null hypothesis. |
| binary_nervous_jittery | 1.49 × 10 | 127.442104037455 | 0.237929135303837 | 0.181352155829274 | 0.0741525423728814 | 0.0687267465894998 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_nervous_jittery. | Reject the null hypothesis. |
| binary_afraid_scared | 2.47 × 10 | 5.04651465849531 | 0.200477326968974 | 0.160315600247866 | 0.168432203389831 | 0.140211325197261 | There is no difference in association between ChatGPT and Twitter for event type Fired in relation to PANAS group: binary_afraid_scared. | Reject the null hypothesis. |
References
- Goodman, A.; Morgan, R.; Kuehlke, R.; Kastor, S.; Fleming, K.; Boyd, J. “We’ve been researched to death”: Exploring the research experiences of urban Indigenous Peoples in Vancouver, Canada. Int. Indig. Policy J. 2018, 9, 1–20. [Google Scholar] [CrossRef]
- Omata, N. ‘Over-researched’and ‘Under-researched’refugee groups: Exploring the phenomena, causes and consequences. J. Hum. Rights Pract. 2020, 12, 681–695. [Google Scholar] [CrossRef]
- Frydenlund, E. Modeling and simulation as a bridge to advance practical and theoretical insights About forced migration studies. J. Migr. Hum. Secur. 2021, 9, 165–181. [Google Scholar] [CrossRef]
- Reinhold, A.M.; Raile, E.D.; Izurieta, C.; McEvoy, J.; King, H.W.; Poole, G.C.; Ready, R.C.; Bergmann, N.T.; Shanahan, E.A. Persuasion with Precision: Using Natural Language Processing to Improve Instrument Fidelity for Risk Communication Experimental Treatments. J. Mix. Methods Res. 2022, 17, 373–395. [Google Scholar] [CrossRef]
- Shanahan, E.A.; Jones, M.D.; McBeth, M.K. How to conduct a Narrative Policy Framework study. Soc. Sci. J. 2018, 55, 332–345. [Google Scholar] [CrossRef]
- Bonabeau, E. Agent-based modeling: Methods and techniques for simulating human systems. Proc. Natl. Acad. Sci. USA 2002, 99, 7280–7287. [Google Scholar] [CrossRef] [PubMed]
- Axelrod, R. Advancing the art of simulation in the social sciences. In Simulating Social Phenomena; Springer: Berlin/Heidelberg, Germany, 1997; pp. 21–40. [Google Scholar] [CrossRef]
- Takadama, K.; Kawai, T.; Koyama, Y. Micro-and macro-level validation in agent-based simulation: Reproduction of human-like behaviors and thinking in a sequential bargaining game. J. Artif. Soc. Soc. Simul. 2008, 11, 9. [Google Scholar]
- Gilbert, N. Agent-Based Models; Sage Publications: Thousand Oaks, CA, USA, 2019. [Google Scholar]
- Courdier, R.; Guerrin, F.; Andriamasinoro, F.H.; Paillat, J.M. Agent-based simulation of complex systems: Application to collective management of animal wastes. J. Artif. Soc. Soc. Simul. 2002, 5, 1–4. [Google Scholar]
- Xiang, X.; Kennedy, R.; Madey, G.; Cabaniss, S. Verification and validation of simulation models. In Proceedings of the 2011 Winter Simulation Conference (WSC), Phoenix, AZ, USA, 11–14 December 2011; The Society for Modeling and Simulation International: San Diego, CA, USA, 2005; Volume 47, p. 55. [Google Scholar] [CrossRef]
- Diallo, S.Y.; Gore, R.; Lynch, C.J.; Padilla, J.J. Formal methods, statistical debugging and exploratory analysis in support of system development: Towards a verification and validation calculator tool. Int. J. Model. Simul. Sci. Comput. 2016, 7, 1641001. [Google Scholar] [CrossRef]
- Gore, R.J.; Lynch, C.J.; Kavak, H. Applying statistical debugging for enhanced trace validation of agent-based models. Simulation 2017, 93, 273–284. [Google Scholar] [CrossRef]
- Padilla, J.J.; Diallo, S.Y.; Lynch, C.J.; Gore, R. Observations on the practice and profession of modeling and simulation: A survey approach. Simulation 2018, 94, 493–506. [Google Scholar] [CrossRef]
- Kornhauser, D.; Wilensky, U.; Rand, W. Design guidelines for agent based model visualization. J. Artif. Soc. Soc. Simul. 2009, 12, 1. [Google Scholar]
- Epstein, J.M.; Axtell, R. Growing Artificial Societies: Social Science from the Bottom Up; Brookings Institution Press: Washington, DC, USA, 1996. [Google Scholar]
- Kemper, P.; Tepper, C. Trace based analysis of process interaction models. In Proceedings of the Winter Simulation Conference, Orlando, FL, USA, 4 December 2005; pp. 427–436. [Google Scholar] [CrossRef]
- Andersson, C.; Runeson, P. Verification and validation in industry-a qualitative survey on the state of practice. In Proceedings of the International Symposium on Empirical Software Engineering, Nara, Japan, 3–4 October 2002; pp. 37–47. [Google Scholar] [CrossRef]
- Lynch, C.J. A Lightweight, Feedback-Driven Runtime Verification Methodology. Ph.D. Thesis, Old Dominion University, Norfolk, VA, USA, 2019. [Google Scholar]
- Eek, M.; Kharrazi, S.; Gavel, H.; Ölvander, J. Study of industrially applied methods for verification, validation and uncertainty quantification of simulator models. Int. J. Model. Simul. Sci. Comput. 2015, 6, 1550014. [Google Scholar] [CrossRef]
- Lozić, E.; Štular, B. Fluent but Not Factual: A Comparative Analysis of ChatGPT and Other AI Chatbots’ Proficiency and Originality in Scientific Writing for Humanities. Future Internet 2023, 15, 336. [Google Scholar] [CrossRef]
- Griewing, S.; Gremke, N.; Wagner, U.; Lingenfelder, M.; Kuhn, S.; Boekhoff, J. Challenging ChatGPT 3.5 in Senology—An Assessment of Concordance with Breast Cancer Tumor Board Decision Making. J. Pers. Med. 2023, 13, 1502. [Google Scholar] [CrossRef] [PubMed]
- Barrington, N.M.; Gupta, N.; Musmar, B.; Doyle, D.; Panico, N.; Godbole, N.; Reardon, T.; D’Amico, R.S. A Bibliometric Analysis of the Rise of ChatGPT in Medical Research. Med. Sci. 2023, 11, 61. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Van Dis, E.A.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five priorities for research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef]
- Szabó, Z.; Bilicki, V. A New Approach to Web Application Security: Utilizing GPT Language Models for Source Code Inspection. Future Internet 2023, 15, 326. [Google Scholar] [CrossRef]
- Filippi, S. Measuring the Impact of ChatGPT on Fostering Concept Generation in Innovative Product Design. Electronics 2023, 12, 3535. [Google Scholar] [CrossRef]
- Lee, P.; Bubeck, S.; Petro, J. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 2023, 388, 1233–1239. [Google Scholar] [CrossRef] [PubMed]
- Garg, R.K.; Urs, V.L.; Agrawal, A.A.; Chaudhary, S.K.; Paliwal, V.; Kar, S.K. Exploring the Role of Chat GPT in patient care (diagnosis and Treatment) and medical research: A Systematic Review. medRxiv 2023. [Google Scholar] [CrossRef]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef] [PubMed]
- Xue, V.W.; Lei, P.; Cho, W.C. The potential impact of ChatGPT in clinical and translational medicine. Clin. Transl. Med. 2023, 13, e1216. [Google Scholar] [CrossRef] [PubMed]
- Tikayat Ray, A.; Cole, B.F.; Pinon Fischer, O.J.; Bhat, A.P.; White, R.T.; Mavris, D.N. Agile Methodology for the Standardization of Engineering Requirements Using Large Language Models. Systems 2023, 11, 352. [Google Scholar] [CrossRef]
- Pal, S.; Bhattacharya, M.; Lee, S.S.; Chakraborty, C. A Domain-Specific Next-Generation Large Language Model (LLM) or ChatGPT is Required for Biomedical Engineering and Research. Ann. Biomed. Eng. 2023, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Thapa, S.; Adhikari, S. ChatGPT, Bard, and Large Language Models for Biomedical Research: Opportunities and Pitfalls. Ann. Biomed. Eng. 2023, 51, 2647–2651. [Google Scholar] [CrossRef]
- Stokel-Walker, C.; Van Noorden, R. The Promise and Peril of Generative AI. Nature 2023, 614, 214–216. [Google Scholar] [CrossRef]
- Gilbert, S.; Harvey, H.; Melvin, T.; Vollebregt, E.; Wicks, P. Large Language Model AI Chatbots Require Approval as Medical Devices. Nat. Med. 2023, 29, 2396–2398. [Google Scholar] [CrossRef]
- Karabacak, M.; Margetis, K. Embracing Large Language Models for Medical Applications: Opportunities and Challenges. Cureus 2023, 15, 1–5. [Google Scholar] [CrossRef]
- Shah, N.H.; Entwistle, D.; Pfeffer, M.A. Creation and Adoption of Large Language Models in Medicine. JAMA 2023, 330, 866–869. [Google Scholar] [CrossRef] [PubMed]
- Reese, J.; Danis, D.; Caufield, J.H.; Casiraghi, E.; Valentini, G.; Mungall, C.J.; Robinson, P.N. On the limitations of large language models in clinical diagnosis. medRxiv 2023. [Google Scholar] [CrossRef]
- Alawida, M.; Mejri, S.; Mehmood, A.; Chikhaoui, B.; Isaac Abiodun, O. A Comprehensive Study of ChatGPT: Advancements, Limitations, and Ethical Considerations in Natural Language Processing and Cybersecurity. Information 2023, 14, 462. [Google Scholar] [CrossRef]
- Nazary, F.; Deldjoo, Y.; Di Noia, T. ChatGPT-HealthPrompt. Harnessing the Power of XAI in Prompt-Based Healthcare Decision Support using ChatGPT. arXiv 2023, arXiv:2308.09731. [Google Scholar]
- OpenAI. ChatGPT, August 2023 version; OpenAI: San Francisco, CA, USA, 2023. [Google Scholar]
- Gore, R.J.; Lynch, C.J. [1902417-1] Understanding Twitter Users. Old Dominion University Institutional Review Board, 13 May 2022. IRB Exempt Status, Exemption Category #2. Available online: https://data.mendeley.com/datasets/nyxndvwfsh/2 (accessed on 19 November 2023).
- Watson, D.; Clark, L.A.; Tellegen, A. Development and validation of brief measures of positive and negative affect: The PANAS scales. J. Personal. Soc. Psychol. 1988, 54, 1063. [Google Scholar] [CrossRef]
- Crawford, J.R.; Henry, J.D. The Positive and Negative Affect Schedule (PANAS): Construct validity, measurement properties and normative data in a large non-clinical sample. Br. J. Clin. Psychol. 2004, 43, 245–265. [Google Scholar] [CrossRef] [PubMed]
- Diallo, S.Y.; Lynch, C.J.; Rechowicz, K.J.; Zacharewicz, G. How to Create Empathy and Understanding: Narrative Analytics in Agent-Based Modeling. In Proceedings of the 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 9–12 December 2018; pp. 1286–1297. [Google Scholar] [CrossRef]
- Hanna, J.J.; Wakene, A.D.; Lehmann, C.U.; Medford, R.J. Assessing Racial and Ethnic Bias in Text Generation for Healthcare-Related Tasks by ChatGPT. medRxiv 2023. [Google Scholar] [CrossRef]
- Tsai, M.L.; Ong, C.W.; Chen, C.L. Exploring the use of large language models (LLMs) in chemical engineering education: Building core course problem models with Chat-GPT. Educ. Chem. Eng. 2023, 44, 71–95. [Google Scholar] [CrossRef]
- Qadir, J. Engineering education in the era of ChatGPT: Promise and pitfalls of generative AI for education. In Proceedings of the 2023 IEEE Global Engineering Education Conference (EDUCON), Kuwait, Kuwait, 1–4 May 2023; pp. 1–9. [Google Scholar]
- Borji, A. A categorical archive of chatgpt failures. arXiv 2023, arXiv:2302.03494. [Google Scholar]
- Makridakis, S.; Petropoulos, F.; Kang, Y. Large Language Models: Their Success and Impact. Forecasting 2023, 5, 536–549. [Google Scholar] [CrossRef]
- Sham, A.H.; Aktas, K.; Rizhinashvili, D.; Kuklianov, D.; Alisinanoglu, F.; Ofodile, I.; Ozcinar, C.; Anbarjafari, G. Ethical AI in facial expression analysis: Racial bias. Signal Image Video Process. 2023, 17, 399–406. [Google Scholar] [CrossRef]
- Noor, P. Can we trust AI not to further embed racial bias and prejudice? BMJ 2020, 368, m363. [Google Scholar] [CrossRef]
- Seyyed-Kalantari, L.; Zhang, H.; McDermott, M.B.; Chen, I.Y.; Ghassemi, M. Underdiagnosis bias of artificial intelligence algorithms applied to chest radiographs in under-served patient populations. Nat. Med. 2021, 27, 2176–2182. [Google Scholar] [CrossRef] [PubMed]
- Guo, L.N.; Lee, M.S.; Kassamali, B.; Mita, C.; Nambudiri, V.E. Bias in, bias out: Underreporting and underrepresentation of diverse skin types in machine learning research for skin cancer detection—A scoping review. J. Am. Acad. Dermatol. 2022, 87, 157–159. [Google Scholar] [CrossRef]
- Kassem, M.A.; Hosny, K.M.; Damaševičius, R.; Eltoukhy, M.M. Machine learning and deep learning methods for skin lesion classification and diagnosis: A systematic review. Diagnostics 2021, 11, 1390. [Google Scholar] [CrossRef] [PubMed]
- Gross, N. What ChatGPT Tells Us about Gender: A Cautionary Tale about Performativity and Gender Biases in AI. Soc. Sci. 2023, 12, 435. [Google Scholar] [CrossRef]
- Hämäläinen, P.; Tavast, M.; Kunnari, A. Evaluating large language models in generating synthetic hci research data: A case study. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–28 April 2023; pp. 1–19. [Google Scholar] [CrossRef]
- Sankararaman, K.A.; Wang, S.; Fang, H. Bayesformer: Transformer with uncertainty estimation. arXiv 2022, arXiv:2206.00826. [Google Scholar]
- Shelmanov, A.; Tsymbalov, E.; Puzyrev, D.; Fedyanin, K.; Panchenko, A.; Panov, M. How certain is your Transformer? In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Kyiv, Ukraine, 19–23 April 2021; pp. 1833–1840. [Google Scholar]
- Vallès-Peris, N.; Domènech, M. Caring in the in-between: A proposal to introduce responsible AI and robotics to healthcare. AI Soc. 2023, 38, 1685–1695. [Google Scholar] [CrossRef]
- Shults, F.L.; Wildman, W.J.; Diallo, S.; Puga-Gonzalez, I.; Voas, D. The artificial society analytics platform. In Advances in Social Simulation: Looking in the Mirror; Springer: Berlin/Heidelberg, Germany, 2020; pp. 411–426. [Google Scholar]
- Upton, G.J. Fisher’s exact test. J. R. Stat. Soc. Ser. A (Stat. Soc.) 1992, 155, 395–402. [Google Scholar] [CrossRef]
- Bower, K.M. When to use Fisher’s exact test. In Six Sigma Forum Magazine; American Society for Quality: Milwaukee, WI, USA, 2003; Volume 2, pp. 35–37. [Google Scholar]
- Yi, D.; Yang, J.; Liu, J.; Liu, Y.; Zhang, J. Quantitative identification of urban functions with fishers’ exact test and POI data applied in classifying urban districts: A case study within the sixth ring road in Beijing. ISPRS Int. J. Geo-Inf. 2019, 8, 555. [Google Scholar] [CrossRef]
- Pęksa, M.; Kamieniecki, A.; Gabrych, A.; Lew-Tusk, A.; Preis, K.; Świątkowska-Freund, M. Loss of E-cadherin staining continuity in the trophoblastic basal membrane correlates with increased resistance in uterine arteries and proteinuria in patients with pregnancy-induced hypertension. J. Clin. Med. 2022, 11, 668. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Y.; Xiong, Y.; Yang, C.; He, N.; He, J.; Luo, W.; Chen, Y.; Zeng, X.; Wu, Z. Investigation of Parasitic Infection in Crocodile Lizards (Shinisaurus crocodilurus) Using High-Throughput Sequencing. Animals 2022, 12, 2726. [Google Scholar] [CrossRef] [PubMed]
- Yokoyama, S.; Al Mahmuda, N.; Munesue, T.; Hayashi, K.; Yagi, K.; Yamagishi, M.; Higashida, H. Association study between the CD157/BST1 gene and autism spectrum disorders in a Japanese population. Brain Sci. 2015, 5, 188–200. [Google Scholar] [CrossRef] [PubMed]
- Miñana-Signes, V.; Monfort-Pañego, M.; Bosh-Bivià, A.H.; Noll, M. Prevalence of low back pain among primary school students from the city of Valencia (Spain). Healthcare 2021, 9, 270. [Google Scholar] [CrossRef] [PubMed]
- Boyd, R.L.; Ashokkumar, A.; Seraj, S.; Pennebaker, J.W. The Development and Psychometric Properties of LIWC-22; University of Texas at Austin: Austin, TX, USA, 2022; pp. 1–47. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. NRC emotion lexicon. Natl. Res. Counc. Can. 2013, 2, 234. [Google Scholar]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Kiritchenko, S.; Zhu, X.; Mohammad, S.M. Sentiment analysis of short informal texts. J. Artif. Intell. Res. 2014, 50, 723–762. [Google Scholar] [CrossRef]
- Gore, R.J.; Lynch, C.J. Effective & Individualized Risk Communication; Number 300916-010; Old Dominion University: Norfolk, VA, USA, 2023. [Google Scholar]
- Google. Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance—Google Research Blog. 2022. Available online: https://blog.research.google/2022/04/pathways-language-model-palm-scaling-to.html (accessed on 4 November 2023).
- Google. Google AI PaLM 2—Google AI. 2023. Available online: https://ai.google/discover/palm2/ (accessed on 4 November 2023).
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Webster, J.J.; Kit, C. Tokenization as the initial phase in NLP. In COLING 1992 Volume 4, Proceedings of the 14th International Conference on Computational Linguistics, Nantes, France, 23–28 July 1992; Springer: Berlin-Verlag/Heidelberg, Germany, 1992. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Roumeliotis, K.I.; Tselikas, N.D. ChatGPT and Open-AI Models: A Preliminary Review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- OpenAI. API Reference-OpenAI API. 2023. Available online: https://platform.openai.com/docs/api-reference (accessed on 18 September 2023).
- OpenAI. GPT-OpenAI API. 2023. Available online: https://platform.openai.com/docs/guides/gpt/chat-completions-api (accessed on 18 September 2023).
- Lynch, C.J.; Gore, R.; Jensen, E. Large Language Model-Driven Narrative Generation Study Data: ChatGPT-Generated Narratives, Real Tweets, and Source Code. 2023. Available online: https://data.mendeley.com/datasets/nyxndvwfsh/2 (accessed on 19 November 2023).
- Reynolds, L.; McDonell, K. Prompt programming for large language models: Beyond the few-shot paradigm. In Proceedings of the CHI EA ’21: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Mitchell, L.; Frank, M.R.; Harris, K.D.; Dodds, P.S.; Danforth, C.M. The geography of happiness: Connecting twitter sentiment and expression, demographics, and objective characteristics of place. PLoS ONE 2013, 8, e64417. [Google Scholar] [CrossRef] [PubMed]
- Gore, R.J.; Diallo, S.; Padilla, J. You are what you tweet: Connecting the geographic variation in America’s obesity rate to twitter content. PLoS ONE 2015, 10, e0133505. [Google Scholar] [CrossRef] [PubMed]
- Padilla, J.J.; Kavak, H.; Lynch, C.J.; Gore, R.J.; Diallo, S.Y. Temporal and spatiotemporal investigation of tourist attraction visit sentiment on Twitter. PLoS ONE 2018, 13, e0198857. [Google Scholar] [CrossRef] [PubMed]
- OpenAI. How Can I Use the ChatGPT API?|OpenAI Help Center. 2023. Available online: https://help.openai.com/en/articles/7232945-how-can-i-use-the-chatgpt-api (accessed on 20 September 2023).
- National Academies of Sciences, Engineering, and Medicine; Division on Engineering and Physical Sciences; Computer Science and Telecommunications Board; Committee on Responsible Computing Research: Ethics and Governance of Computing Research and Its Applications. Fostering Responsible Computing Research: Foundations and Practices; The National Academies Press: Washington, DC, USA, 2022. [Google Scholar] [CrossRef]
- D’Amour, A.; Heller, K.; Moldovan, D.; Adlam, B.; Alipanahi, B.; Beutel, A.; Chen, C.; Deaton, J.; Eisenstein, J.; Hoffman, M.D.; et al. Underspecification Presents Challenges for Credibility in Modern Machine Learning. J. Mach. Learn. Res. 2022, 23, 10237–10297. [Google Scholar] [CrossRef]
- Armstrong, R.A. When to use the Bonferroni correction. Ophthalmic Physiol. Opt. 2014, 34, 502–508. [Google Scholar] [CrossRef]
- National Academies of Sciences, Engineering, and Medicine; Health and Medicine Division; Board on Population Health and Public Health Practice; Roundtable on Health Literacy. The Roles of Trust and Health Literacy in Achieving Health Equity: Clinical Settings: Proceedings of a Workshop-in Brief; The National Academies Press: Washington, DC, USA, 2023. [Google Scholar] [CrossRef]










| LLM Benefits | LLM Challenges |
|---|---|
|
|
| Life Event Type | Total ABM Simulated Life Events | Total Filtered Simulated Life Events | Total Sampled Simulated Life Events | Num. ChatGPT Narratives | Num. Tweets |
|---|---|---|---|---|---|
| Birth | 4728 | 4155 | 600 | 6000 | 6148 * |
| Death | 17,340 | 618 | 600 | 6000 | 6148 * |
| Hiring | 26,317 | 3924 | 600 | 6000 | 6148 * |
| Firing | 25,026 | 2860 | 600 | 6000 | 6148 * |
| Real-Life Tweets (total) | NA | NA | NA | NA | 6148 |
| Real-Life Tweets (filtered) | NA | NA | NA | NA | 4163 |
| Event Type | Num. PANAS Sentiment ChatGPT Narratives | Num. PANAS Sentiment Tweets |
|---|---|---|
| Birth | 5586 | 944 * |
| Death | 5115 | 944 * |
| Hiring | 5447 | 944 * |
| Firing | 5447 | 944 * |
| Life Event | Number of Comparisons for Rejecting the Null Hypothesis | Number of Comparisons for Failing to Reject the Null Hypothesis |
|---|---|---|
| Birth | 10 | 1 |
| Death | 10 | 1 |
| Hired | 11 | 0 |
| Fired | 9 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lynch, C.J.; Jensen, E.J.; Zamponi, V.; O’Brien, K.; Frydenlund, E.; Gore, R. A Structured Narrative Prompt for Prompting Narratives from Large Language Models: Sentiment Assessment of ChatGPT-Generated Narratives and Real Tweets. Future Internet 2023, 15, 375. https://doi.org/10.3390/fi15120375
Lynch CJ, Jensen EJ, Zamponi V, O’Brien K, Frydenlund E, Gore R. A Structured Narrative Prompt for Prompting Narratives from Large Language Models: Sentiment Assessment of ChatGPT-Generated Narratives and Real Tweets. Future Internet. 2023; 15(12):375. https://doi.org/10.3390/fi15120375
Chicago/Turabian StyleLynch, Christopher J., Erik J. Jensen, Virginia Zamponi, Kevin O’Brien, Erika Frydenlund, and Ross Gore. 2023. "A Structured Narrative Prompt for Prompting Narratives from Large Language Models: Sentiment Assessment of ChatGPT-Generated Narratives and Real Tweets" Future Internet 15, no. 12: 375. https://doi.org/10.3390/fi15120375
APA StyleLynch, C. J., Jensen, E. J., Zamponi, V., O’Brien, K., Frydenlund, E., & Gore, R. (2023). A Structured Narrative Prompt for Prompting Narratives from Large Language Models: Sentiment Assessment of ChatGPT-Generated Narratives and Real Tweets. Future Internet, 15(12), 375. https://doi.org/10.3390/fi15120375