


Data Protection and Multi-Database Data-Driven Models


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- to what extent data integration is possible when data have been masked, and
- even if data integration cannot overcome the errors caused by masking methods and produces faulty databases, we want to know whether these databases are of high enough quality for data-driven models to be built.
2. Preliminaries
3. Methodology
- Partition horizontally into two parts, one for testing and the other for training. We call the training part and the testing part .
- Take and partition it vertically into two databases, and . These two databases will share some attributes. We denote by the number of attributes that are shared by both databases.
- Let be a masking method. Independently mask the two databases and . In this way, we produce two masked databases as follows: and .
- Integrate and using the common attributes of these databases. We denote by the resulting database. That is, where is an integration mechanism for databases.
- Let m denote a machine learning algorithm. Compute a data-driven model for and another data-driven model for using the same machine learning algorithm. We denote by and these two different data-driven models. We use to denote the application of this model to a record x from (not including the attribute y).
- Evaluate the integration of the two databases (that is, the resulting database ) using .
- Evaluate the performance of the models and using the test database .
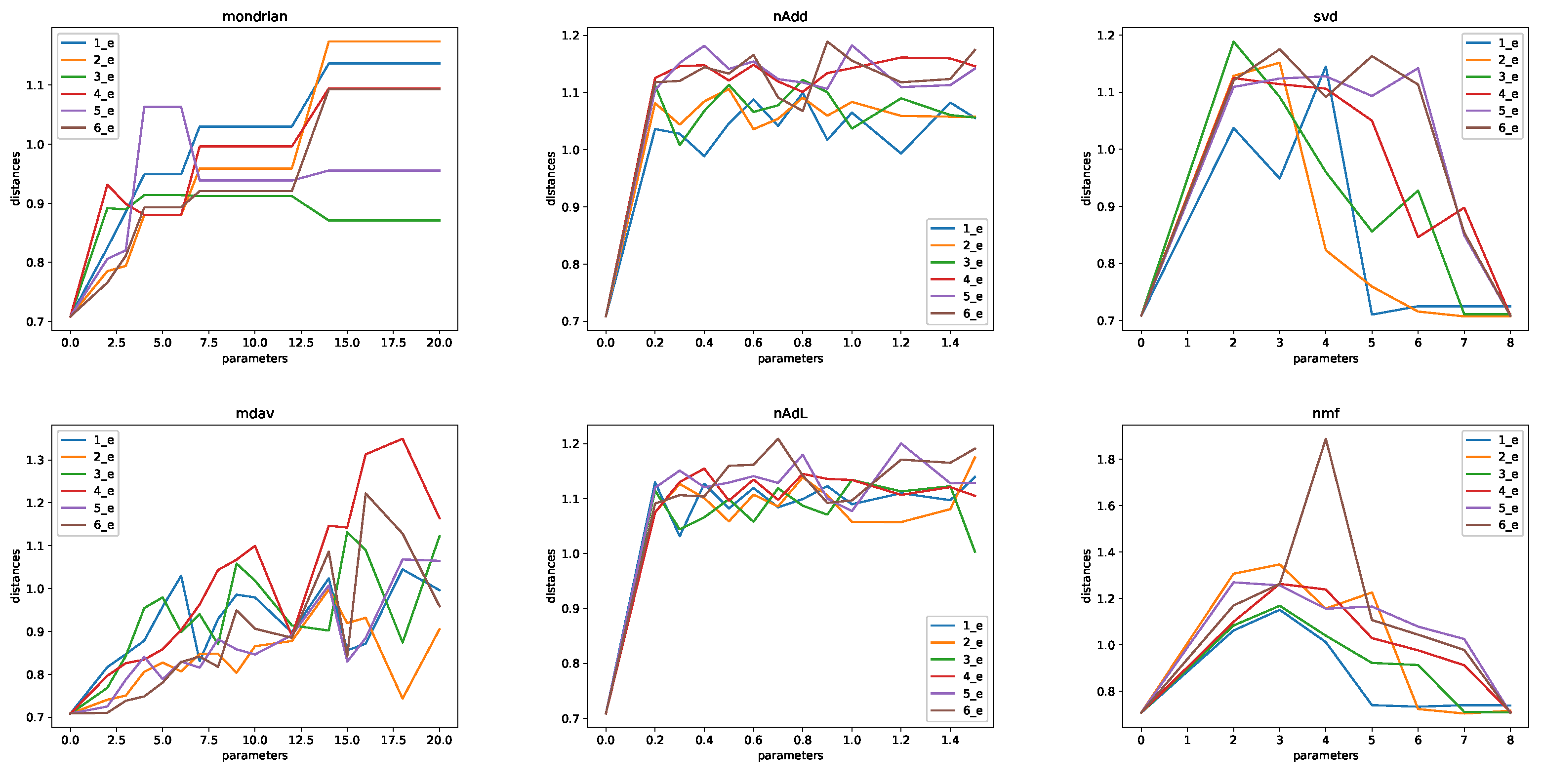
3.1. Masking Methods
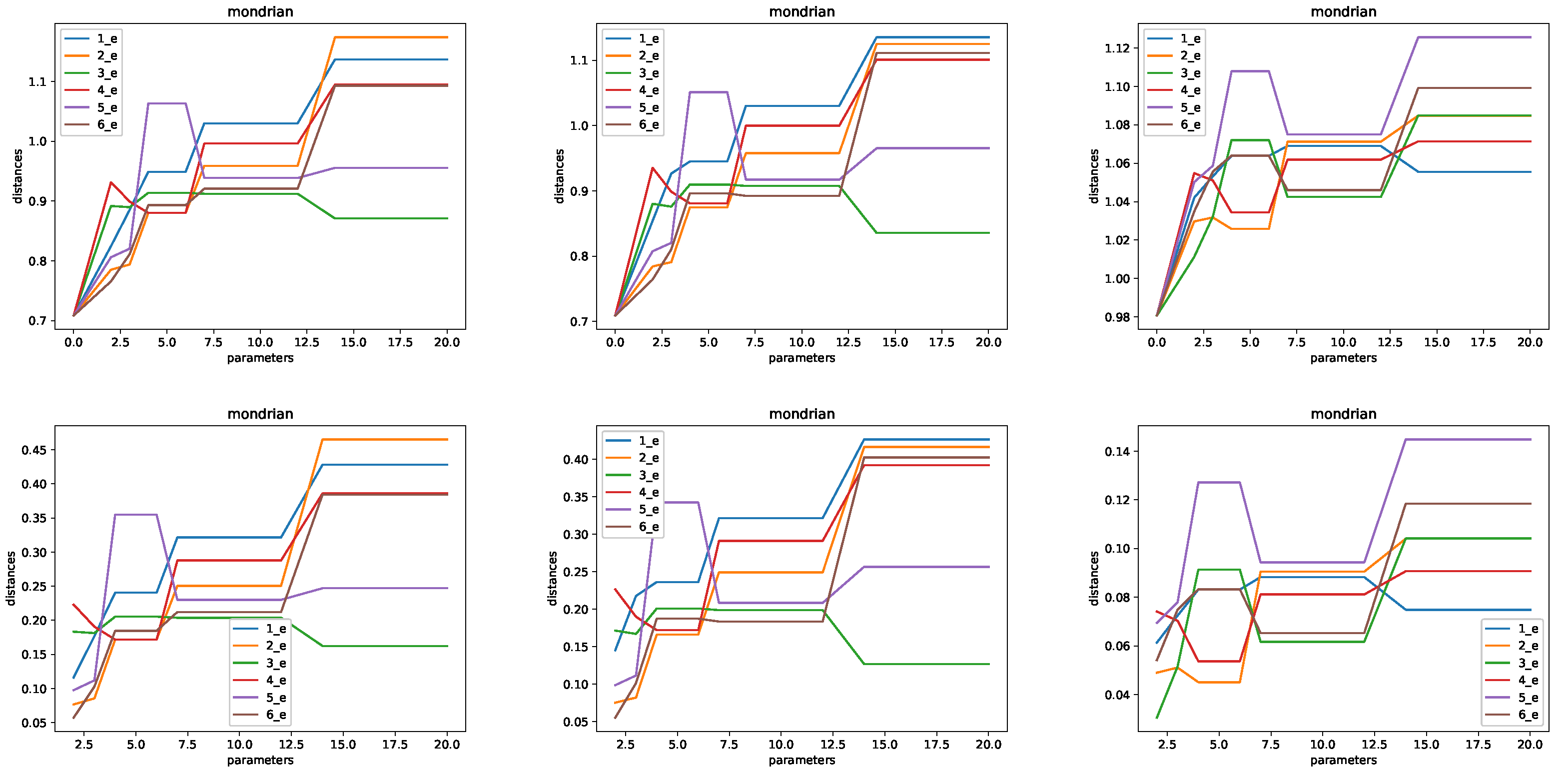
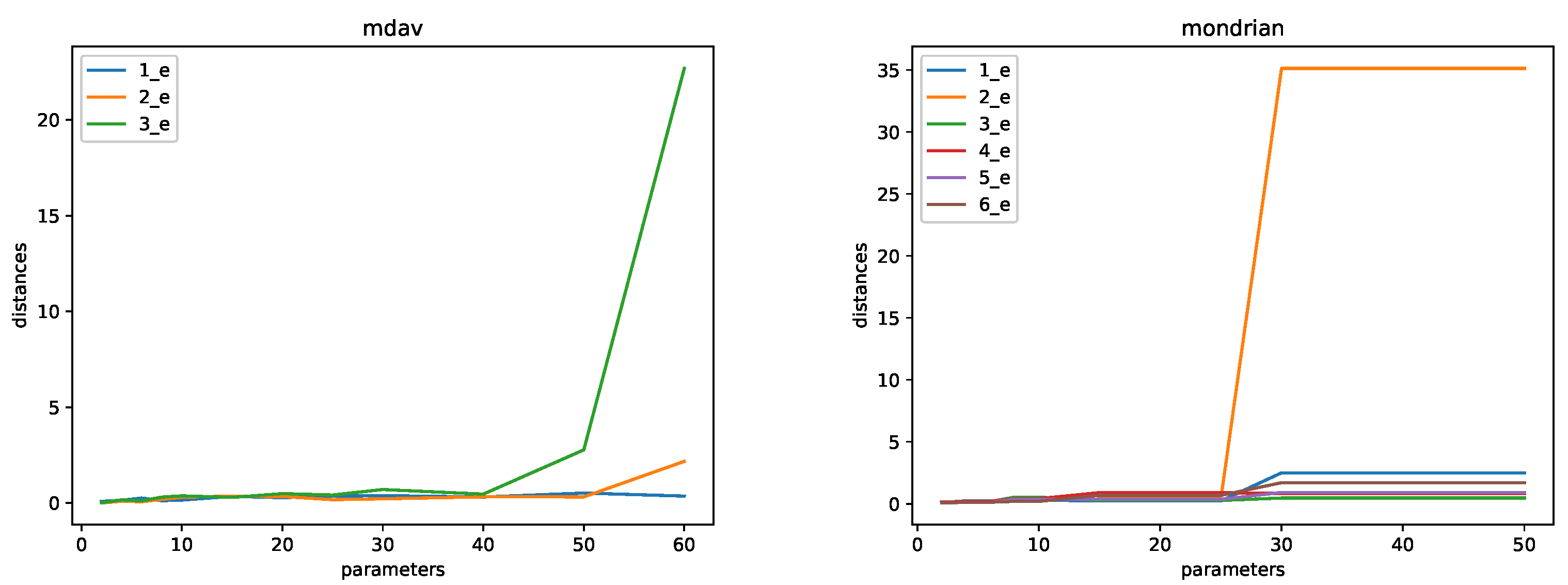
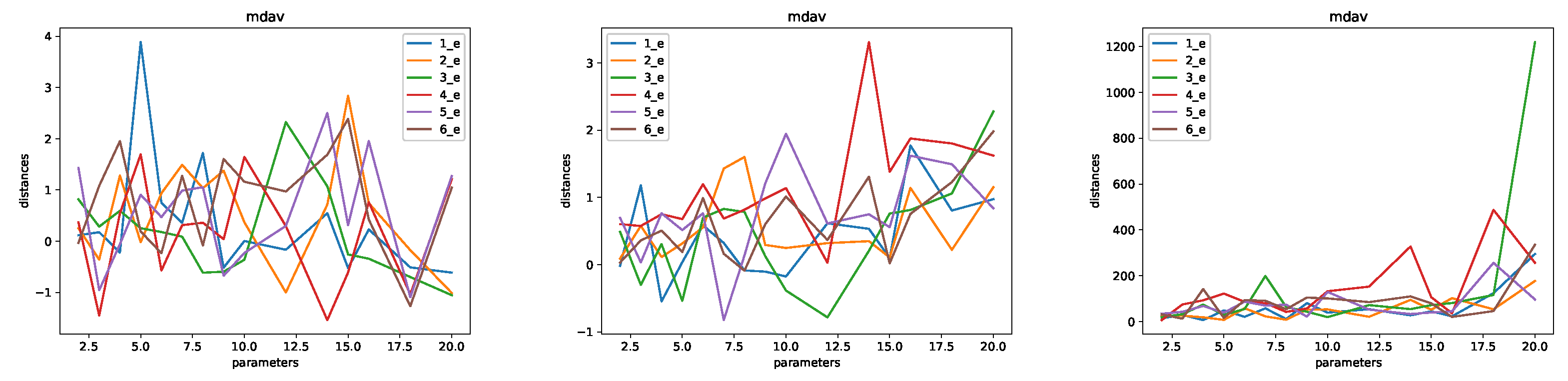
- Microaggregation: in order to protect a set of records, small clusters are built and records are replaced by a cluster representative. In order to guarantee privacy, each cluster needs to have at least k records. Thus, k is a parameter of the method. The larger the k, the larger the privacy level, and the lower the utility of the data. Optimal microaggregation is often defined in terms of the error between the cluster representatives and the original records. Optimal microaggregation is an NP-hard problem for multivariate data (see e.g., [22]). Because of this, several alternative heuristic algorithms have been developed. We have used two alternative algorithms: MDAV [23,24], and Mondrian [25]. The difference is related to the method of building the clusters. We use the mean of the records in a cluster as the cluster representative. Microaggregation provides k-anonymity by definition, as each record in the protected data set is indistinguishable from at least other records.
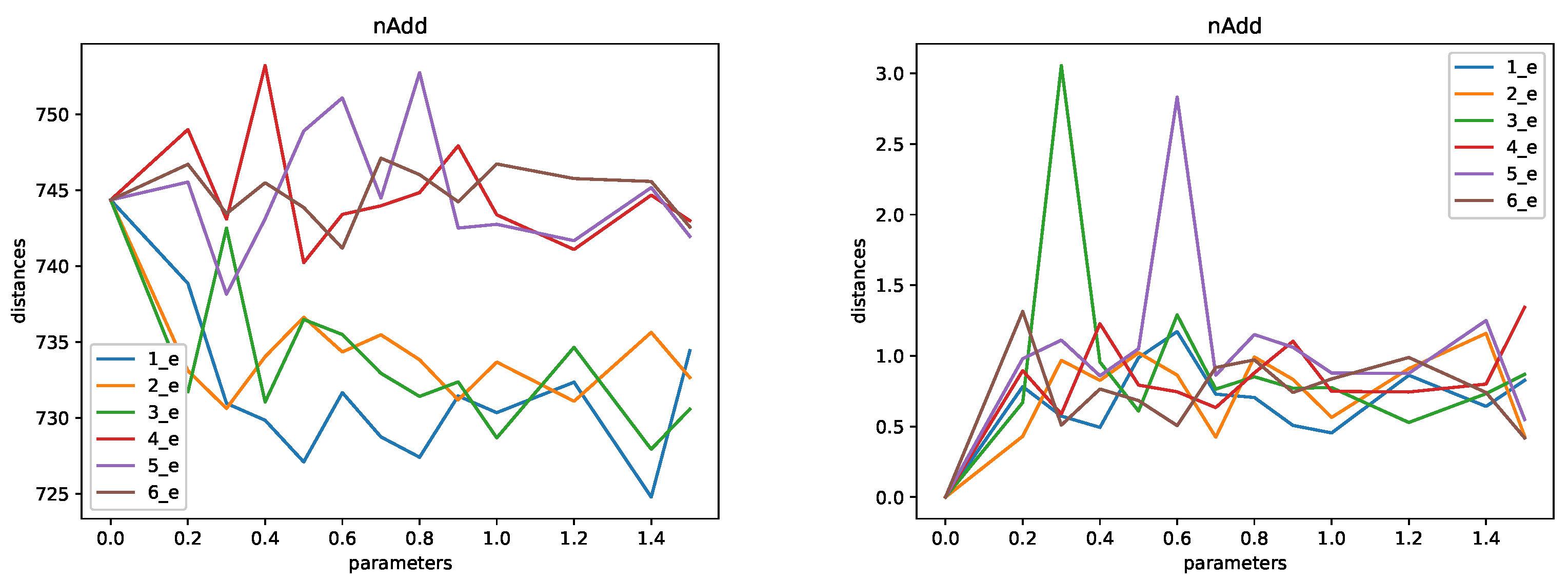
- Noise addition: in order to protect a record, noise is added to it. In other words, the original numerical value x is replaced by , where follows a given distribution. We use two different alternative distributions for protection. They are a normal distribution with mean zero and standard deviation , and a Laplace distribution with mean zero and standard deviation as above. Naturally, k corresponds to the parameter of the method. As in the case of microaggregation, the larger the k, the larger the distortion. Therefore, the larger the k, the larger the protection and the smaller the utility of the resulting protected data. Noise addition using Laplacian noise is the standard approach to implementing differential privacy. In the case of publishing a database, as we do here, this corresponds to local differential privacy.
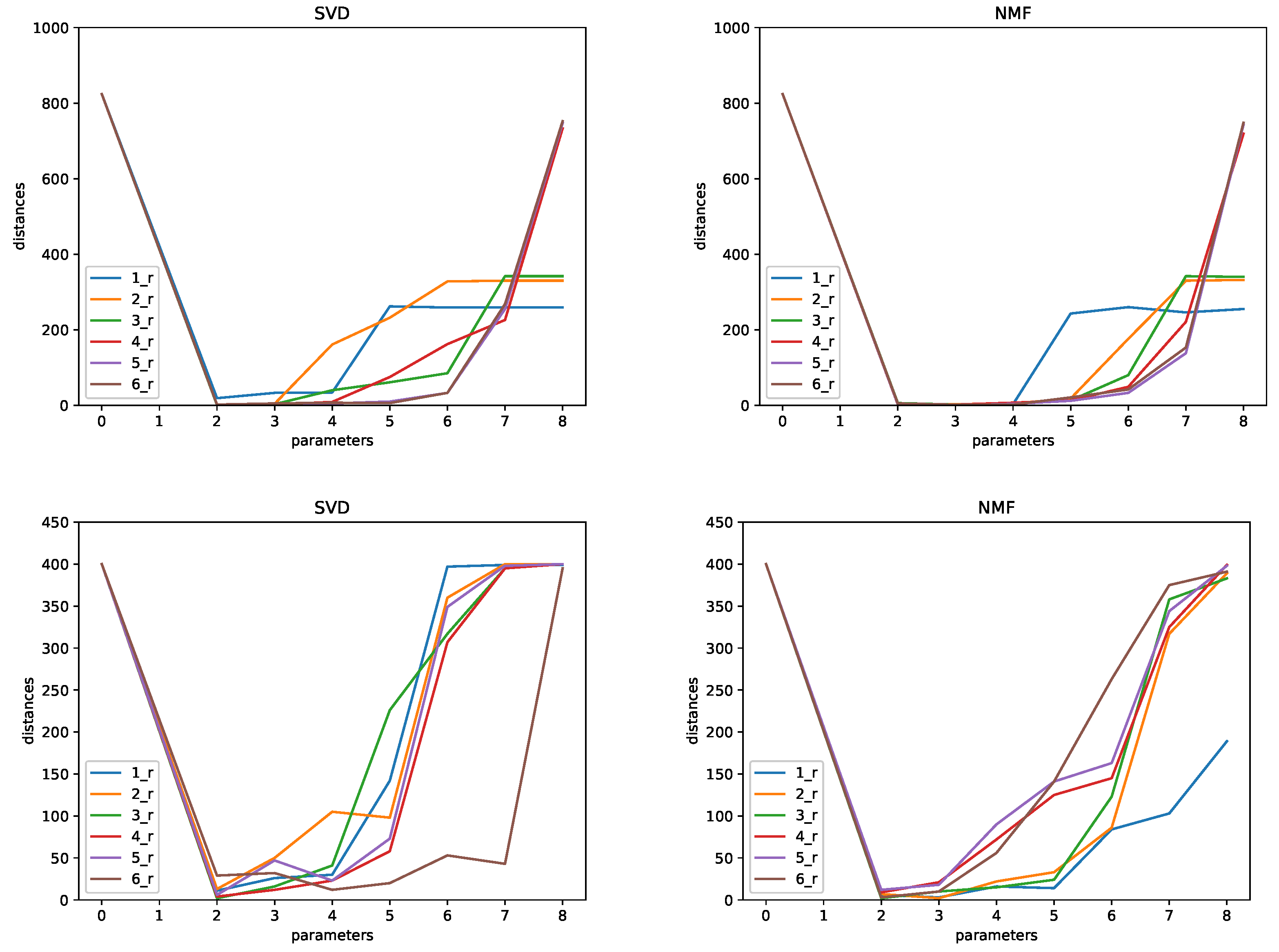
- Transform-based protection: these methods reduce the quality of the data by transforming the data into another space in which we can remove details. We have considered the use of singular value decomposition (SVD), principal component analysis (PCA), and non-negative matrix factorization (NMF) for this purpose. In the case of SVD and PCA, we apply the decomposition, select the principal components, and then we rebuild the matrix with only these selected components. The parameter of the method is the number of components selected. We denote this k. In this case, the larger the k, the better the reconstruction of the original data. Therefore, the smaller the k, the larger the protection, and at the same time, the smaller the utility of the resulting protected data. This approach is similar to non-negative matrix factorization. For NMF, as above, the smaller the number of components k, the larger the protection and the smaller the utility. While SVD and PCA can be applied to matrices with arbitrary real numbers, NMF can only be applied to positive data. Because of this, data are scaled into the [0,1] interval before the application of the NMF protection. The data are re-scaled back after the NMF protection.
3.2. Machine Learning Algorithms
- linear_model.LinearRegression (linear regression): a linear approach to modeling the relationship between a dependent variable and one or more independent variables.
- sklearn.linear_model.SGDRegressor (SGD regression): a linear regression model fitted by minimizing a regularized empirical loss with stochastic gradient descent.
- sklearn.kernel_ridge.KernelRidge (kernel ridge regression): a regression model combining ridge regression (imposing a penalty with l2 regularization) with the kernel trick. It can model linear and nonlinear relationships between a dependent variable and one or more independent variables.
- sklearn.svm.SVR (epsilon-support vector regression): a regression model using the same principles (e.g., maximal margin) as the SVM for classification. One difference is that a margin of tolerance (epsilon) is set.
3.3. Implementation
3.4. Databases
- CASC: this data set has been used in several papers on data privacy, and it is provided by the sdcMicro package in R (it is called CASCrefmicrodata in the package). The data set was created in the EU project CASC. See, e.g., Hundepool et al. [3] and the sdcMicro package description for detailed information on this data set. The data set consists of 1080 records and 13 numerical attributes.
- Tarragona: this data set is also provided by the sdcMicro package in R. There are 834 records described in terms of 13 numerical attributes.
- Concrete Compressive Strength: this data set is described by Yeh [29,30] and has been used in several works related to regression models. It is provided by the UCI repository. The data set consists of 1030 records and 9 numerical attributes. We have selected this file because the data are numerical and because it has been used for regression.
3.5. Parameters
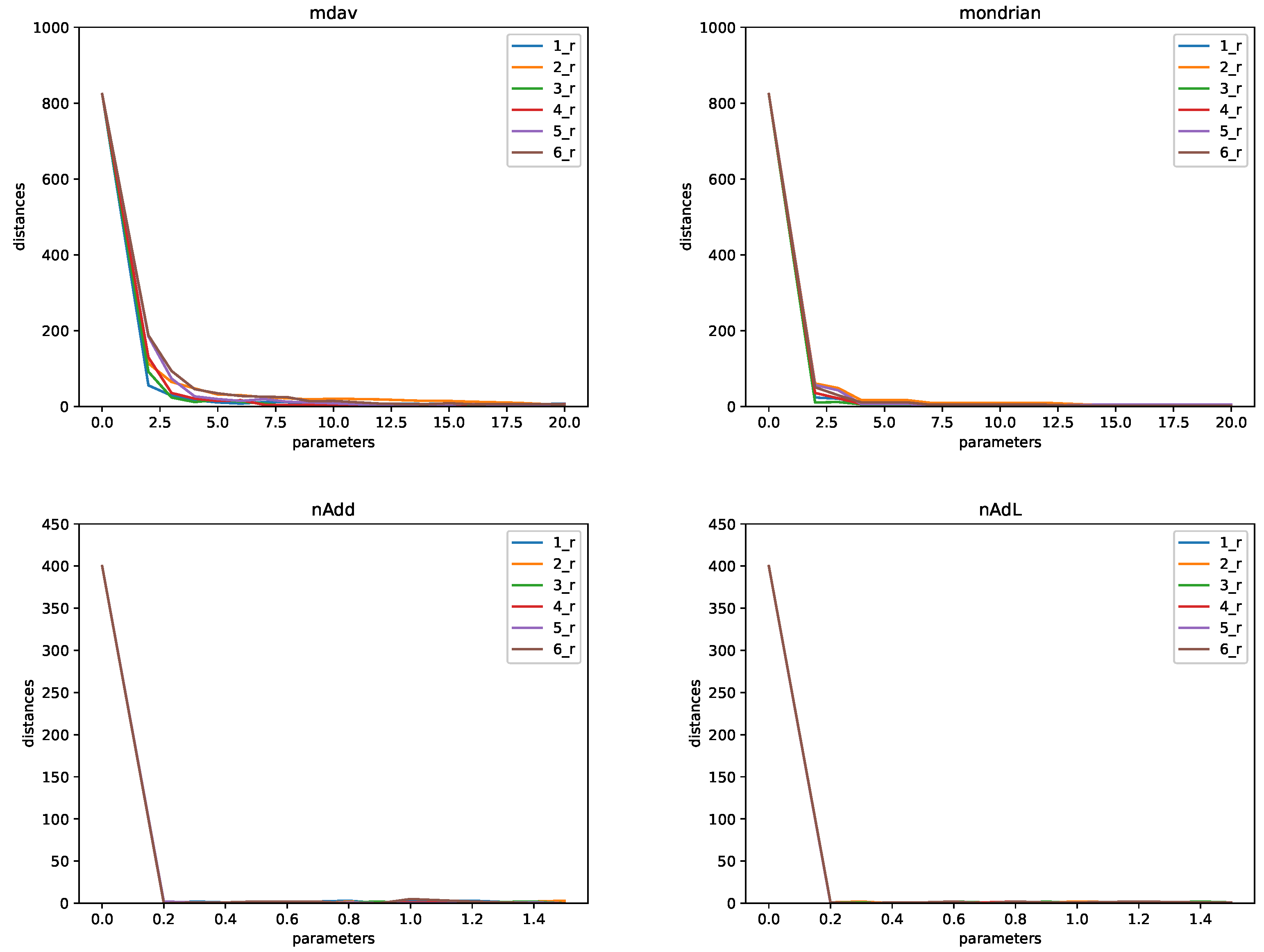
- CASC: The number of common attributes for and considered is . That is, we considered six different pairs of databases. These databases were built as follows. For the first pair, includes attributes 0–5, and includes attributes 5–11 (0–5 and 5–11 correspond to columns in the database, with the first column denoted by zero). Databases for are defined in terms of attributes 0–6, 0–6, 0–7, 0–7, and 0–7. Databases for are defined with attributes 5–11, 4–11, 4–11, 3–11, and 2–11.
- Tarragona: The number of common attributes is the same as for the CASC data set, and the databases were also constructed following the same pattern.
- Concrete: In this case, we also have . For , we have with attributes 0–5 and with attributes 5–7. For , we have with attributes 0–6 and with attributes 5–7. For larger , we have with attributes 0–6, 0–7, 0–7, and 0–7, and with attributes 4–7, 4–7, 3–7, and 2–7.
- Microaggregation (MDAV and Mondrian). The following values of k were considered: . For some experiments, we used larger values. In that case, we used , 20, 25, 30, 40, 50, 60, 70, 100, 200, 300, 400, .
- Noise addition (Gaussian and Laplacian noise). We used noise with parameters in the set .
- SVD and NMF. In this case, we used parameters equal to .
- PCA. We used one, two, and three principal components.
4. Experiment and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cavoukian, A. Privacy by Design. The 7 Foundational Principles in Privacy by Design. Strong Privacy Protection—Now, and Well Into the Future. 2011. Available online: https://www.ipc.on.ca/wp-content/uploads/Resources/7foundationalprinciples.pdf (accessed on 5 February 2023).
- Duncan, G.T.; Elliot, M.; Salazar, J.J. Statistical Confidentiality; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Hundepool, A.; Domingo-Ferrer, J.; Franconi, L.; Giessing, S.; Nordholt, E.S.; Spicer, K.; de Wolf, P.-P. Statistical Disclosure Control; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Torra, V. A Guide to Data Privacy; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Herranz, J.; Matwin, S.; Nin, J.; Torra, V. Classifying data from protected statistical datasets. Comput. Secur. 2010, 29, 875–890. [Google Scholar] [CrossRef] [Green Version]
- Mitra, R.; Blanchard, S.; Dove, I.; Tudor, C.; Spicer, K. Confidentiality challenges in releasing longitudinally linked data. Trans. Data Priv. 2020, 13, 151–170. [Google Scholar]
- Wang, H.; He, J.; Zhu, N. Improving Data Utilization of K-anonymity through Clustering Optimization. Trans. Data Priv. 2022, 15, 177–192. [Google Scholar]
- Liu, F. Statistical Properties of Sanitized Results from Differentially Private Laplace Mechanism with Univariate Bounding Constraints. Trans. Data Priv. 2019, 12, 169–195. [Google Scholar]
- Jiang, L.; Torra, V. On the Effects of Data Protection on Multi-database Data-Driven Models. In Integrated Uncertainty in Knowledge Modelling and Decision Making, Proceedings of the 9th International Symposium, IUKM 2022, Ishikawa, Japan, 18–19 March 2022; Springer: Cham, Switzerland, 2022; pp. 226–238. [Google Scholar]
- De Capitani di Vimercati, S.; Foresti, S.; Livraga, G.; Samarati, P. Data Privacy: Definitions and Techniques. Int. J. Unc. Fuzz. Knowl. Based Syst. 2012, 20, 793–817. [Google Scholar] [CrossRef] [Green Version]
- Samarati, P. Protecting Respondents’ Identities in Microdata Release. IEEE Trans. Knowl. Data Eng. 2001, 13, 1010–1027. [Google Scholar] [CrossRef] [Green Version]
- Samarati, P.; Sweeney, L. Protecting privacy when disclosing information: k-anonymity and its enforcement through generalization and suppression. SRI Intl. Tech. Rep. 1998. Available online: https://dataprivacylab.org/dataprivacy/projects/kanonymity/paper3.pdf (accessed on 5 February 2023).
- Dwork, C. Differential privacy. In Automata, Languages and Programming, Proceedings of the 33rd International Colloquium, ICALP 2006, Venice, Italy, 10–14 July 2006; Springer: Berlin, Germany, 2006; Volume 4052, pp. 1–12. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Theory and Applications of Models of Computation, Proceedings of the 5th International Conference, TAMC 2008, Xi’an, China, 25–29 April 2008; Springer: Berlin, Germany, 2008; Volume 4978, pp. 1–19. [Google Scholar]
- Evfimievski, A.; Gehrke, J.; Srikant, R. Limiting privacy breaches in privacy preserving data mining. In Proceedings of the Twenty-Second ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, San Diego, CA, USA, 9–12 June 2003. [Google Scholar]
- Winkler, W.E. Re-identification methods for masked microdata. In Privacy in Statistical Databases, Proceedings of the CASC Project International Workshop, PSD 2004, Barcelona, Spain, 9–11 June 2004; Springer: Berlin, Germany, 2004; Volume 3050, pp. 216–230. [Google Scholar]
- Drechsler, J. Synthetic Datasets for Statistical Disclosure Control: Theory and Implementation; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Christen, P.; Ranbaduge, T.; Schnell, R. Linking Sensitive Data: Methods and Techniques for Practical Privacy-Preserving Information Sharing; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Herzog, T.N.; Scheuren, F.J.; Winkler, W.E. Data Quality and Record Linkage Techniques; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Sakuma, J.; Osame, T. Recommendation based on k-anonymized ratings. Trans. Data Priv. 2017, 11, 47–60. [Google Scholar]
- Aggarwal, C.C.; Yu, P.S. A Condensation Approach to Privacy Preserving Data Mining. In Advances in Database Technology—EDBT 2004, Proceedings of the 9th International Conference on Extending Database Technology, Heraklion, Crete, Greece, 14–18 March 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 183–199. [Google Scholar]
- Oganian, A.; Domingo-Ferrer, J. On the Complexity of Optimal Microaggregation for Statistical Disclosure Control. Stat. United Nations Econ. Comm. Eur. 2000, 18, 345–354. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J.; Mateo-Sanz, J.M. Practical data-oriented microaggregation for statistical disclosure control. IEEE Trans. Knowl. Data Eng. 2002, 14, 189–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Domingo-Ferrer, J.; Martinez-Balleste, A.; Mateo-Sanz, J.M.; Sebe, F. Efficient Multivariate Data-Oriented Microaggregation. Int. J. Very Large Databases 2006, 15, 355–369. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Multidimensional k-Anonymity; Technical Report 1521; University of Wisconsin: Madison, WI, USA, 2005; Available online: https://minds.wisconsin.edu/bitstream/handle/1793/60428/TR1521.pdf?sequence=1 (accessed on 5 February 2023).
- Bozorgpanah, A.; Torra, V.; Aliahmadipour, L. Privacy and explainability: The effects of data protection on Shapley values. Technologies 2022, 10, 125. [Google Scholar] [CrossRef]
- Code Python. Available online: www.mdai.cat/code (accessed on 5 February 2023).
- Templ, M. Statistical Disclosure Control for Microdata Using the R-Package sdcMicro. Trans. Data Priv. 2008, 1, 67–85. [Google Scholar]
- Yeh, I.-C. Modeling of strength of high performance concrete using artificial neural networks. Cem. Concr. Res. 1998, 28, 1797–1808. [Google Scholar] [CrossRef]
- Yeh, I.-C. Analysis of strength of concrete using design of experiments and neural networks. J. Mater. Civ. Eng. 2006, 18, 597–604. [Google Scholar] [CrossRef]
- Wojcik, S.; Adam, H. Sizing up Twitter users. Pew Res. Cent. 2019, 24, 1–23. [Google Scholar]
- Padilla, J.J.; Kavak, H.; Lynch, C.J.; Gore, R.J.; Diallo, S.Y. Temporal and spatiotemporal investigation of tourist attraction visit sentiment on Twitter. PLoS ONE 2018, 13, e0198857. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gore, R.J.; Diallo, S.; Padilla, J. You are what you tweet: Connecting the geographic variation in America’s obesity rate to twitter content. PLoS ONE 2015, 10, e0133505. [Google Scholar] [CrossRef] [PubMed] [Green Version]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, L.; Torra, V. Data Protection and Multi-Database Data-Driven Models. Future Internet 2023, 15, 93. https://doi.org/10.3390/fi15030093
Jiang L, Torra V. Data Protection and Multi-Database Data-Driven Models. Future Internet. 2023; 15(3):93. https://doi.org/10.3390/fi15030093
Chicago/Turabian StyleJiang, Lili, and Vicenç Torra. 2023. "Data Protection and Multi-Database Data-Driven Models" Future Internet 15, no. 3: 93. https://doi.org/10.3390/fi15030093
APA StyleJiang, L., & Torra, V. (2023). Data Protection and Multi-Database Data-Driven Models. Future Internet, 15(3), 93. https://doi.org/10.3390/fi15030093