
Non-Profiled Unsupervised Horizontal Iterative Attack against Hardware Elliptic Curve Scalar Multiplication Using Machine Learning


Abstract
:1. Introduction
- We present a summary of existing horizontal non-profiled solutions against ECSM implementations.
- We show that even simple Artificial Neural Networks can be used to increase the correctness of horizontal attacks, and we analyze the influence of the regularization of those networks on the attack correctness.
- We sensitize our readers to the importance of precisely citing the software versions used for neural network training and the hyperparameters used. Using the example of our own analysis, we show that the regularization is implemented differently in two popular Python packages: scikit-learn and tensorflow.
2. Related Work
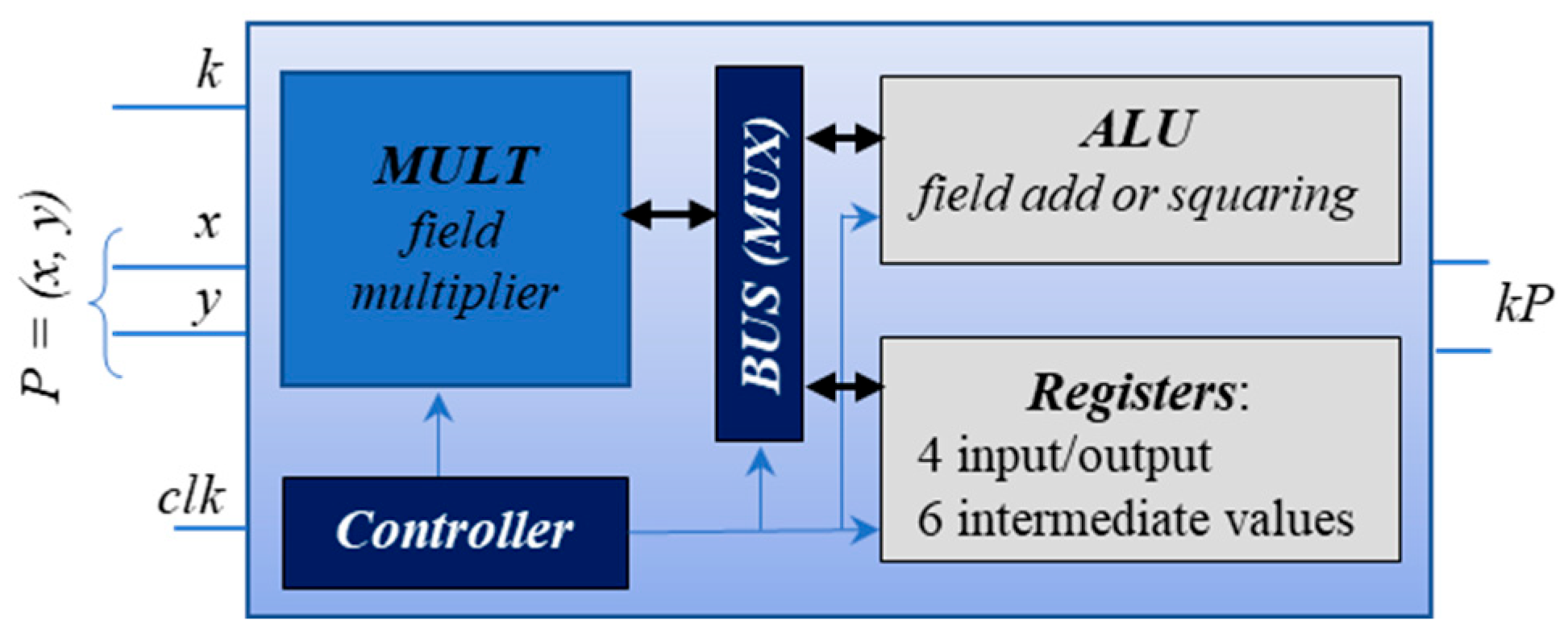
3. Target Platforms
- Design_ultra is a specific instance of our ECSM design that was compiled with the Synopsys Design Compiler using the compile_ultra feature. This high-effort compilation process involves logic-level and gate-level synthesis and optimization, aiming to achieve an optimum quality of results. The compile_ultra feature leverages all DC Ultra capabilities, balancing timing and area limitations to deliver a compact circuit that meets stringent timing criteria. The exhaustive compilation enhances synthesis quality, resulting in improved performance, reduced design area, and lower power consumption. Design_ultra was manufactured into an ASIC. in the IHP 250 nm technology [51]. The compile options increased the resistance of the design against SCA attacks. The authors applied a non-profiled horizontal statistical attack—the comparison to the mean, which is a univariate attack on each clock cycle of the ECSM iteration, capable of leveraging only the first-order leakage—and achieved 76% correctness for the power trace (PT) and 77% for electromagnetic trace (EMT) for one of the candidates. We use their attack as the first step in our analysis.
- Design_seq is another instance of our ECSM design, and it introduces a countermeasure to the bus-addressing sequence. In clock cycles where no block is specifically addressed by the Controller block, Design_seq implements regular addressing instead of some default constant address, ensuring that each of the 11 blocks, including registers, is called in sequence and its contents are written to the bus. This sequential addressing, from 1 to 11 (or 1 to B in hexadecimal), adds a layer of security against attacks like microprobing, especially for the register containing the scalar k, which is never written to the bus. This countermeasure aims to reduce the effectiveness of horizontal SCA attacks on the design by introducing artificial noise in the form of regular addressing when the bus is not in use.
4. Power and Electromagnetic Trace Acquisition
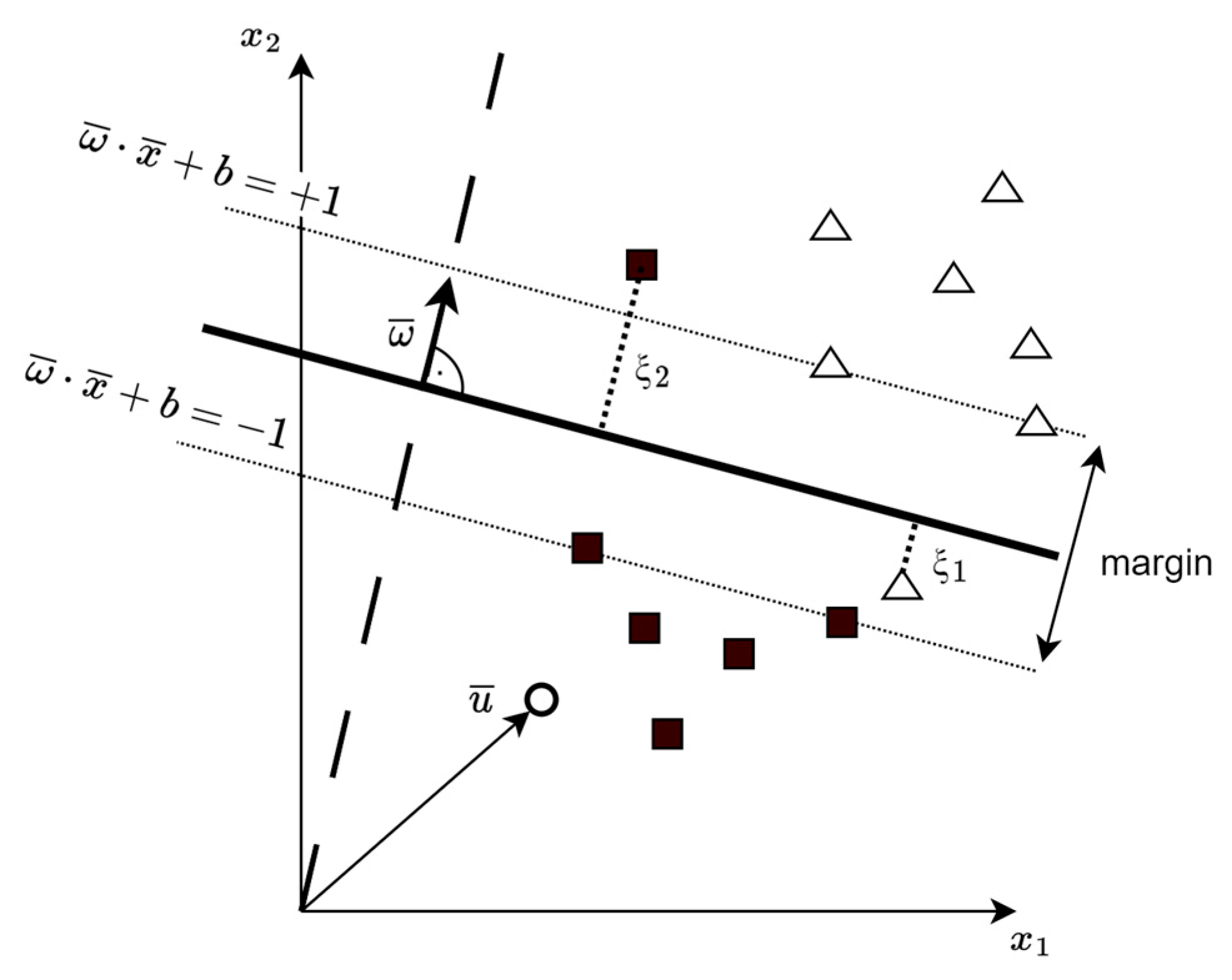
5. SVM Classification
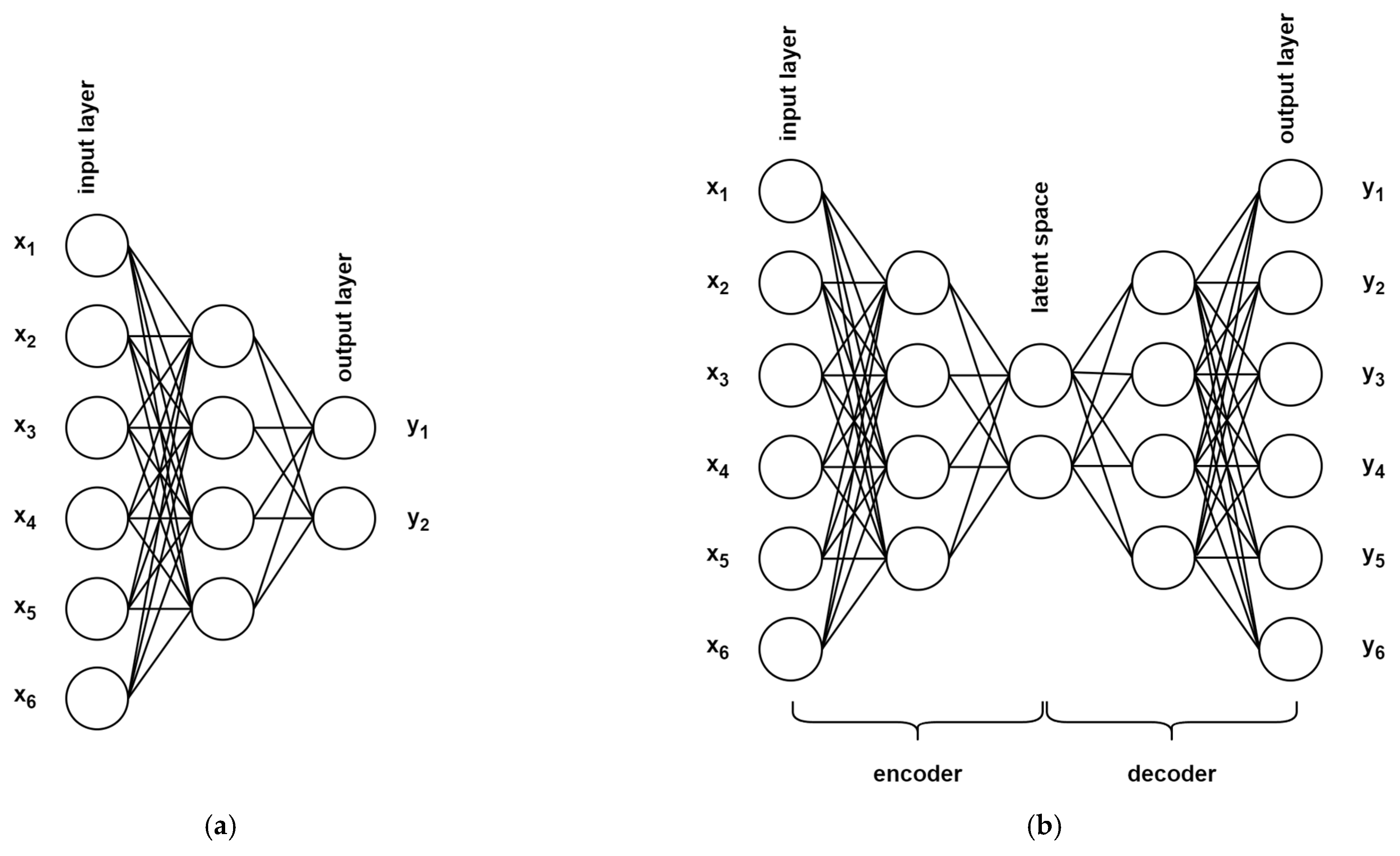
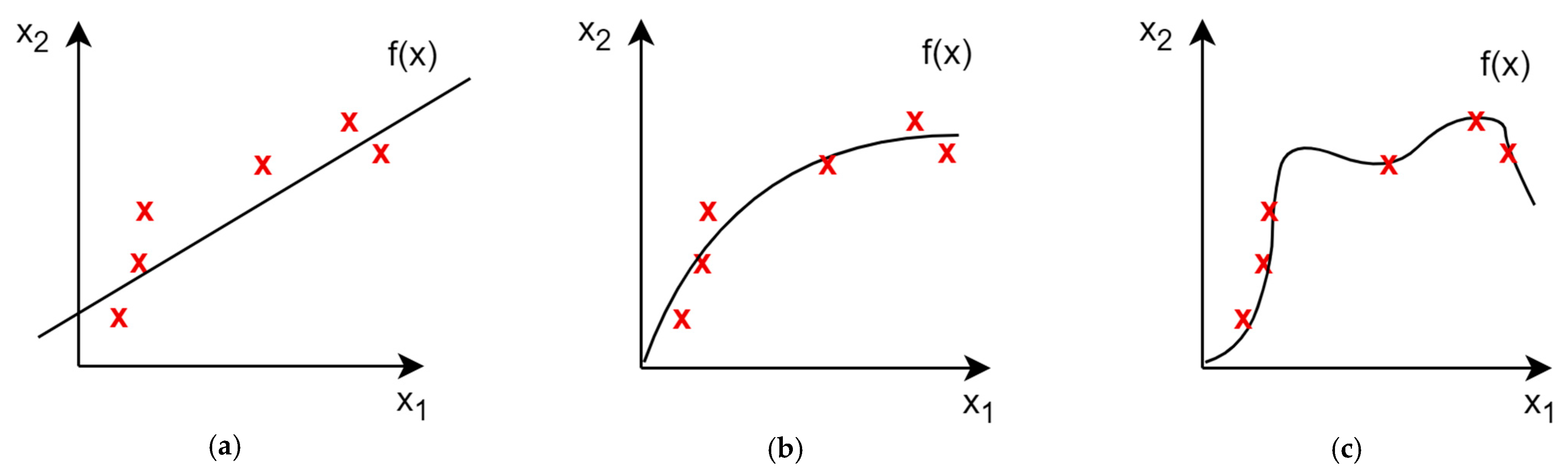
6. Artificial Neural Networks
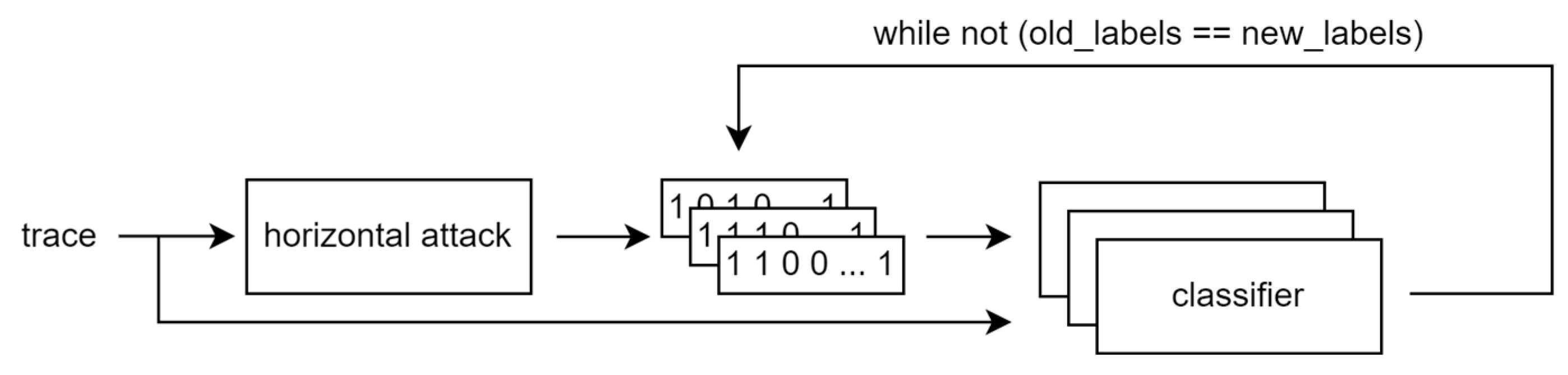
7. The Iterative Framework
- A preprocessing step, wherein we compress all values in each clock cycle, i.e., we represent S samples in each clock cycle using only a single value, which is calculated corresponding to the selected compression method; for example, it can be the arithmetic mean of all S samples or the maximum value.
- Then, a horizontal attack is used to derive initial key candidates, which are expected to be somewhat incorrect. We have applied the comparison to the mean method used in [50] to have a baseline for our attack, but it could be some other statistical or machine-learning-based attack, which produces initial key candidates.
- At the end, an iterative classification algorithm is used to improve the labeling and hopefully extract the secret scalar. In [17], we used Support Vector Machines; here, we introduce Artificial Neural Networks to the framework. The classifiers are trained based on the initial key candidates derived from the horizontal attack, i.e., one classifier per key candidate, and new candidates are computed. The new candidates are used for subsequent training until the candidates do not change anymore between iterations. We initialize new ANNs after every iteration of the framework although, according to our experiments, there is no difference in the result of the framework whether we reuse already-trained ANNs from the previous iteration or initialize new ones each time. Both the SVM and ANN methods produce single classification for each slot. We used compressed values as inputs, i.e., there are only 54 features, one for each clock cycle of the ECSM iteration. The general idea is shown in Figure 5.
7.1. Preprocessing
7.2. Horizontal Attack
7.3. Neural Network Iterative Classification
7.4. Attack Evaluation
8. Results
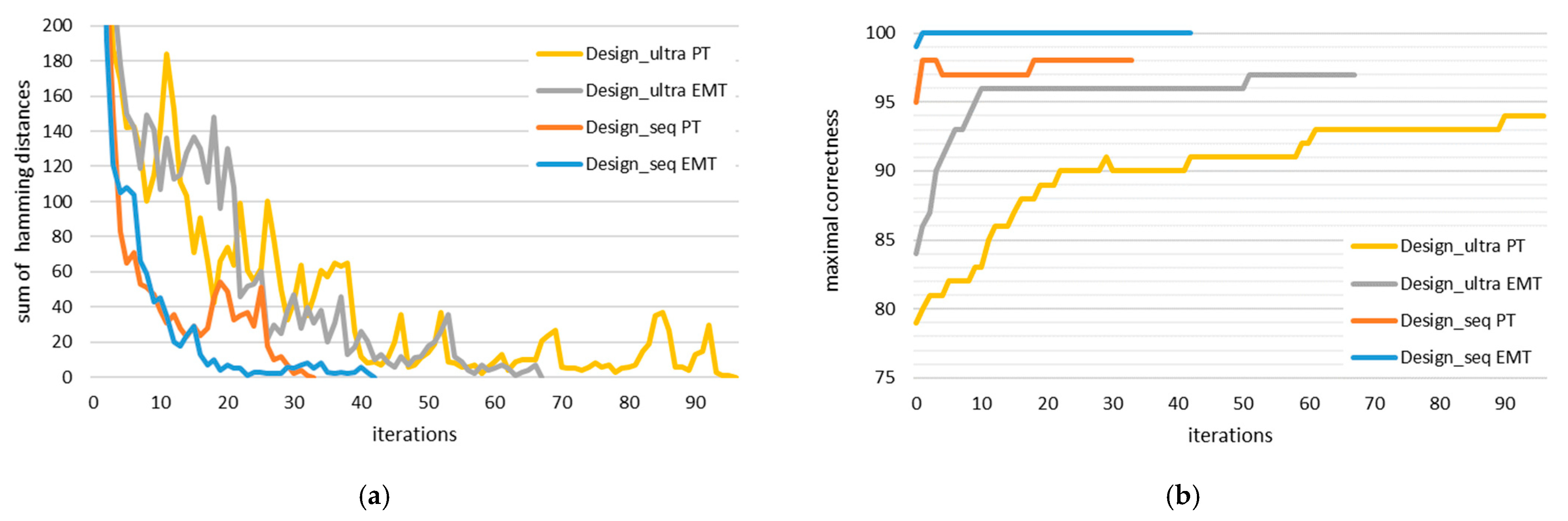
8.1. Search for Optimal L1 and L2 Parameters
8.2. Stopping Condition
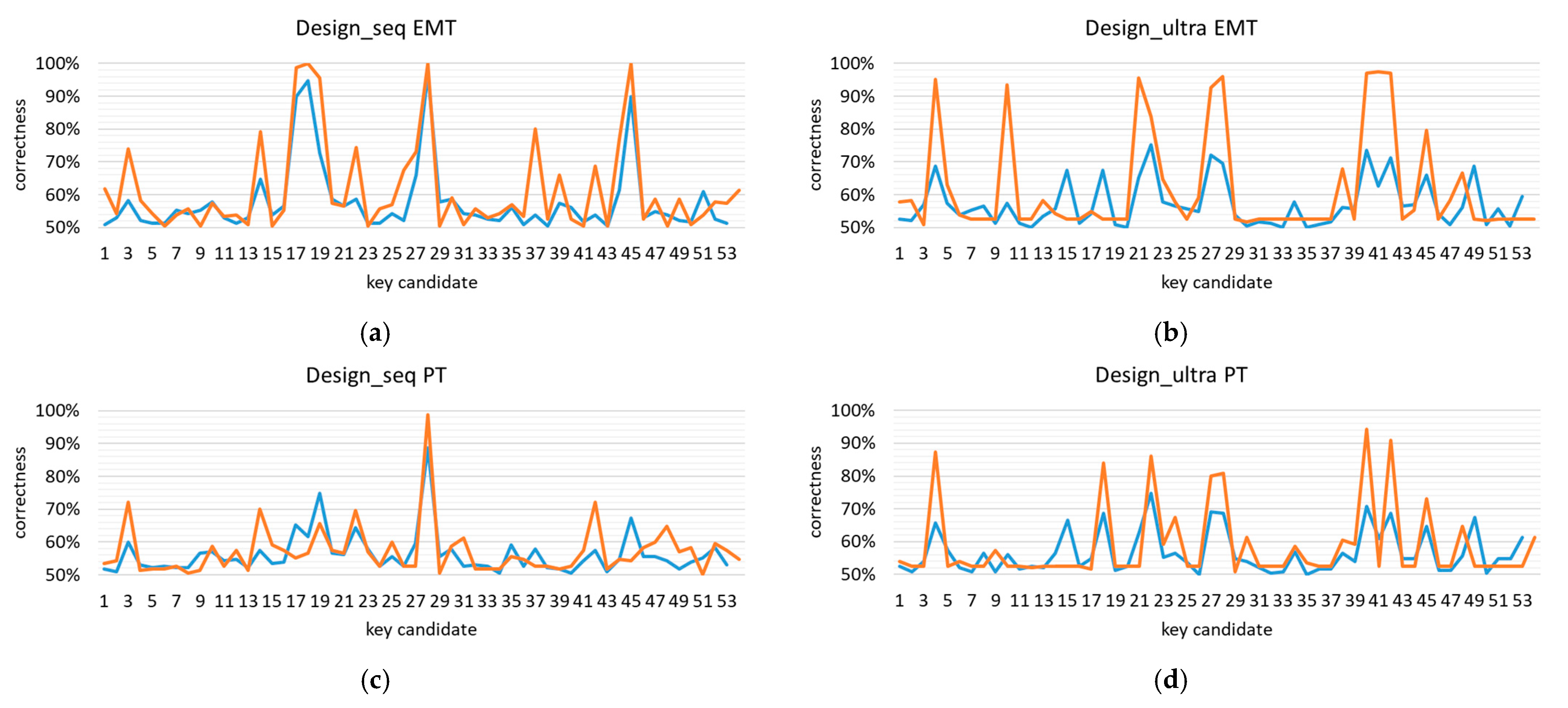
8.3. Number and Position of Best Key Candidates
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sinha, S. State of IoT 2023: Number of Connected IoT Devices Growing 16% to 16.7 Billion Globally. IoT Analytics GmbH, 24 May 2023. Available online: https://iot-analytics.com/number-connected-iot-devices/ (accessed on 3 November 2023).
- Kocher, P.; Horn, J.; Fogh, A.; Genkin, D.; Gruss, D.; Haas, W.; Hamburg, M.; Lipp, M.; Mangard, S.; Prescher, T.; et al. Spectre Attacks: Exploiting Speculative Execution. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 1–19. [Google Scholar]
- Lipp, M.; Schwaz, M.; Gruss, D.; Prescher, T.; Haas, W.; Mangard, S.; Kocher, P.; Genkin, D.; Yarom, Y.; Hamburg, M.; et al. Meltdown. Available online: https://arxiv.org/pdf/1801.01207.pdf (accessed on 30 November 2023).
- Pinto, S.; Rodrigues, C. Hand Me Your SECRET, MCU!: Microarchitectural Timing Attacks on Microcontrollers Are Practical. Presented at the Black Hat Asia, Singapore, 9–12 May 2023; Available online: https://www.youtube.com/watch?v=xso4e4BdzFo (accessed on 30 November 2023).
- Daemen, J.; Rijmen, V. The Design of Rijndael: AES—The Advanced Encryption Standard; Springer: Berlin, Germany; London, UK, 2011. [Google Scholar]
- Advanced Encryption Standard (AES), FIPS 197. Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.197-upd1.pdf (accessed on 30 November 2023).
- Rivest, R.L.; Shamir, A.; Adleman, L.M. Cryptographic Communications System and Method. U.S. Patent 4,405,829, 20 September 1983. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Koblitz, N. Elliptic curve cryptosystems. Math. Comput. 1987, 48, 203–209. [Google Scholar] [CrossRef]
- Miller, V.S. Use of Elliptic Curves in Cryptography. In Proceedings of the Conference on the Theory and Application of Cryptographic Techniques, Santa Barbara, CA, USA, 18–22 August 1985; Springer: Berlin/Heidelberg, Germany, 2000; Volume 218, pp. 417–426. [Google Scholar] [CrossRef]
- Shoup, V. A Proposal for an ISO Standard for Public Key Encryption. Available online: https://eprint.iacr.org/2001/112 (accessed on 30 November 2023).
- Johnson, D.; Menezes, A.; Vanstone, S. The Elliptic Curve Digital Signature Algorithm (ECDSA). Int. J. Inf. Secur. 2001, 1, 36–63. [Google Scholar] [CrossRef]
- Digital Signature Standard (DSS), NIST FIPS 186-4. Available online: https://csrc.nist.gov/pubs/fips/186-4/final (accessed on 30 November 2023).
- Barker, E. NIST Special Publication 800-57 Part 1 Revision 5: Recommendation for Key Management; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2020. [CrossRef]
- Kocher, P.C. Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems. In Advances in Cryptology—CRYPTO’96: 16th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 1996; Koblitz, N., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1996; pp. 104–113. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Advances in Neural Information Processing Systems NeurlPS’12, 2012; Available online: https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 30 November 2023).
- Aftowicz, M.; Kabin, I.; Dyka, Z.; Langendoerfer, P. Non-profiled semi-supervised horizontal attack against Elliptic Curve Scalar Multiplication using Support Vector Machines. In Proceedings of the 26th Euromicro Conference Series on Digital System Design (DSD), Durres, Albania, 6–8 September 2023. [Google Scholar]
- Perin, G.; Chmielewski, L.; Batina, L.; Picek, S. Keep it Unsupervised: Horizontal Attacks Meet Deep Learning. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2020, 2021, 343–372. [Google Scholar] [CrossRef]
- Hospodar, G.; Gierlichs, B.; De Mulder, E.; Verbauwhede, I.; Vandewalle, J. Machine learning in side-channel analysis: A first study. J. Cryptogr. Eng. 2011, 1, 293–302. [Google Scholar] [CrossRef]
- Jap, D.; Breier, J. Overview of machine learning based side-channel analysis methods. In Proceedings of the 2014 International Symposium on Integrated Circuits, Singapore, 10–12 December 2014; pp. 38–41. [Google Scholar]
- Heyszl, J.; Ibing, A.; Mangard, S.; de Santis, F.; Sigl, G. Clustering Algorithms for Non-profiled Single-Execution Attacks on Exponentiations. In Sublibrary: SL 4, Security and Cryptology, Proceedings of the Smart Card Research and Advanced Applications: 12th International Conference, CARDIS 2013, Berlin, Germany, 27–29 November 2013; Revised Selected Papers; Francillon, A., Rohatgi, P., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8419, pp. 79–93. [Google Scholar] [CrossRef]
- Perin, G.; Imbert, L.; Torres, L.; Maurine, P. Attacking Randomized Exponentiations Using Unsupervised Learning. In Proceedings of the Constructive Side-Channel Analysis and Secure Design: 5th International Workshop, COSADE 2014, Paris, France, 13–15 April 2014; Revised Selected Papers. Prouff, E., Ed.; Springer: Cham, Switzerland, 2014; Volume 8622, pp. 144–160. [Google Scholar] [CrossRef]
- Hodgers, P.; Regazzoni, F.; Gilmore, R.; Moore, C.; Oder, T. State-of-the-Art in Physical Side-Channel Attacks and Resistant Technologies. Secure Architectures of Future Emerging Cryptography (SAFEcrypto) D7.1. February 2016. Available online: https://ec.europa.eu/research/participants/documents/downloadPublic?documentIds=080166e5a63fd691&appId=PPGMS (accessed on 30 November 2023).
- Papachristodoulou, L.; Batina, L.; Mentens, N. Recent Developments in Side-Channel Analysis on Elliptic Curve Cryptography Implementations. In Hardware Security and Trust: Design and Deployment of Integrated Circuits in a Threatened Environment; Sklavos, N., Chaves, R., Di Natale, G., Regazzoni, F., Eds.; Springer International Publishing: Cham, Swtizerland, 2017; pp. 49–76. [Google Scholar] [CrossRef]
- Benadjila, R.; Prouff, E.; Strullu, R.; Cagli, E.; Canovas, C. Study of Deep Learning Techniques for Side-Channel Analysis and Introduction to ASCAD Database. J. Cryptogr. Eng. 2018, 2018, 53. [Google Scholar]
- Taouil, M.; Aljuffri, A.; Hamdioui, S. Power Side Channel Attacks: Where Are We Standing? In Proceedings of the 2021 16th International Conference on Design & Technology of Integrated Systems in Nanoscale Era (DTIS), Montpellier, France, 28–30 June 2021; pp. 1–6. [Google Scholar]
- Jovic, A.; Jap, D.; Papachristodoulou, L.; Heuser, A. Traditional Machine Learning Methods for Side-Channel Analysis. In Security and Artificial Intelligence: A Crossdisciplinary Approach; Batina, L., Bäck, T., Buhan, I., Picek, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Swtizerland, 2022; Volume 13049, pp. 25–47. [Google Scholar] [CrossRef]
- Krček, M.; Li, H.; Paguada, S.; Rioja, U.; Wu, L.; Perin, G.; Chmielewski, Ł. Deep Learning on Side-Channel Analysis. In Security and Artificial Intelligence: A Crossdisciplinary Approach; Batina, L., Bäck, T., Buhan, I., Picek, S., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2022; Volume 13049, pp. 48–71. [Google Scholar] [CrossRef]
- Hettwer, B. Deep Learning-Enhanced Side-Channel Analysis of Cryptographic Implementations. Ph.D. Thesis, Ruhr-Universität Bochum, Bochum, Germany, 2021. [Google Scholar] [CrossRef]
- Picek, S.; Perin, G.; Mariot, L.; Wu, L.; Batina, L. SoK: Deep Learning-based Physical Side-channel Analysis. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Weissbart, L. 25519 WolfSSL. Available online: https://github.com/leoweissbart/MachineLearningBasedSideChannelAttackonEdDSA (accessed on 30 November 2023).
- Chmielewski, Ł. REASSURE (H2020 731591) ECC Dataset. Zenodo. 16 January 2020. Available online: https://zenodo.org/records/3609789 (accessed on 30 November 2023).
- Masure, L.; Dumas, C.; Prouff, E. A Comprehensive Study of Deep Learning for Side-Channel Analysis. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2020, 348–375. [Google Scholar] [CrossRef]
- Jin, S.; Kim, S.; Kim, H.; Hong, S. Recent advances in deep learning-based side-channel analysis. ETRI J. 2020, 42, 292–304. [Google Scholar] [CrossRef]
- Kaur, J.; Lamba, S.; Saini, P. Advanced Encryption Standard: Attacks and Current Research Trends. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 112–116. [Google Scholar]
- Batina, L.; Hogenboom, J.; Mentens, N.; Moelans, J.; Vliegen, J. Side-channel evaluation of FPGA implementations of binary Edwards curves. In Proceedings of the 2010 17th IEEE International Conference on Electronics, Circuits and Systems—(ICECS 2010), Athens, Greece, 12–15 December 2010; pp. 1248–1251. [Google Scholar]
- Kabin, I.; Dyka, Z.; Klann, D.; Mentens, N.; Batina, L.; Langendoerfer, P. Breaking a fully Balanced ASIC Coprocessor Implementing Complete Addition Formulas on Weierstrass Elliptic Curves. In Proceedings of the 2020 23rd Euromicro Conference on Digital System Design (DSD), Kranj, Slovenia, 26–28 August 2020; pp. 270–276. [Google Scholar] [CrossRef]
- Specht, R.; Heyszl, J.; Kleinsteuber, M.; Sigl, G. Improving Non-profiled Attacks on Exponentiations Based on Clustering and Extracting Leakage from Multi-channel High-Resolution EM Measurements. In Sublibrary: SL 4, Security and Cryptology, Proceedings of the 6th International Workshop on Constructive Side-Channel Analysis and Secure Design, Berlin, Germany, 13–14 April 2015; Revised selected papers; Mangard, S., Poschmann, A.Y., Eds.; Lecture Notes in Computer Science; Springer: Cham, Swtizerland, 2015; Volume 9064, pp. 3–19. [Google Scholar] [CrossRef]
- Kabin, I.; Aftowicz, M.; Varabei, Y.; Klann, D.; Dyka, Z.; Langendoerfer, P. Horizontal Attacks using K-Means: Comparison with Traditional Analysis Methods. In Proceedings of the 2019 10th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Canary Islands, Spain, 24–26 June 2019; pp. 1–7. [Google Scholar]
- Aftowicz, M.; Kabin, I.; Dyka, Z.; Langendoerfer, P. Clustering versus Statistical Analysis for SCA: When Machine Learning is Better. In Proceedings of the 2021 10th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 7–10 June 2021; pp. 1–5. [Google Scholar]
- Järvinen, K.; Balasch, J. Single-Trace Side-Channel Attacks on Scalar Multiplications with Precomputations. In Proceedings of the Smart Card Research and Advanced Applications: 15th International Conference, CARDIS 2016, Cannes, France, 7–9 November 2016; Revised Selected Papers. Lemke-Rust, K., Tunstall, M., Eds.; Springer: Cham, Switzerland, 2017; Volume 10146, pp. 137–155. [Google Scholar] [CrossRef]
- Aljuffri, A. Exploring Deep Learning for Hardware Attacks. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2018. Available online: http://resolver.tudelft.nl/uuid:c0dddd21-bdc1-4641-bd5d-4abdbd7fe35f (accessed on 30 November 2023).
- Xu, T. A Novel Simple Power Analysis (SPA) Attack against Elliptic Curve Cryptography (ECC). Ph.D. Thesis, Northeastern University, Boston, MA, USA, 2021. [Google Scholar] [CrossRef]
- Nascimento, E.; Chmielewski, Ł. Applying Horizontal Clustering Side-Channel Attacks on Embedded ECC Implementations. In Sublibrary: SL 4, Security and Cryptology, Proceedings of the International Conference on Smart Card Research and Advanced Applications, Lugano, Switzerland, 13–15 November; Revised selected papers; Eisenbarth, T., Teglia, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 10728, pp. 213–231. [Google Scholar] [CrossRef]
- Perin, G.; Chmielewski, Ł. A Semi-Parametric Approach for Side-Channel Attacks on Protected RSA Implementations. In Sublibrary: SL 4, Security and Cryptology, Proceedings of the International Conference on Smart Card Research and Advanced Applications, Bochum, Germany, 4–6 November 2015; Revised Selected Papers; Homma, N., Medwed, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9514, pp. 34–53. [Google Scholar] [CrossRef]
- Ravi, P.; Jungk, B.; Jap, D.; Najm, Z.; Bhasin, S. Feature Selection Methods for Non-Profiled Side-Channel Attacks on ECC. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–5. [Google Scholar]
- Sim, B.-Y.; Kang, J.; Han, D.-G. Key Bit-Dependent Side-Channel Attacks on Protected Binary Scalar Multiplication. Appl. Sci. 2018, 8, 2168. [Google Scholar] [CrossRef]
- López, J.; Dahab, R. Fast Multiplication on Elliptic Curves Over GF(2m) without precomputation. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Worcester, MA, USA, 12–13 August 1999; Koç, Ç.K., Paar, C., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1717, pp. 316–327. [Google Scholar] [CrossRef]
- Joye, M.; Yen, S.-M. The Montgomery Powering Ladder. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Redwood Shores, CA, USA, 13–15 August 2002; Kaliski, B.S., Koç, C.K., Paar, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 291–302. [Google Scholar] [CrossRef]
- Kabin, I. Horizontal Address-Bit SCA Attacks against ECC and Appropriate Countermeasures. Ph.D. Thesis, BTU Cottbus—Senftenberg, Cottbus, Germany, 2023. [Google Scholar] [CrossRef]
- IHP-Solutions: Foundry Service, SiGe BiCMOS Technology. Available online: https://www.ihp-solutions.com/services (accessed on 8 January 2024).
- Riscure, Driving Your Security forward—Riscure. Available online: https://www.riscure.com/ (accessed on 8 January 2024).
- Langer EMV-Technik GmbH. Available online: https://www.langer-emv.de/de/index (accessed on 8 January 2024).
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaus, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Google. TensorFlow. Available online: https://www.tensorflow.org (accessed on 22 February 2023).
- Kabin, I.; Dyka, Z.; Klann, D.; Aftowicz, M.; Langendoerfer, P. FFT based Horizontal SCA Attack against ECC. In Proceedings of the 2021 11th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 19–21 April 2021; pp. 1–5. [Google Scholar]
- Genevey-Metat, C.; Gérard, B.; Heuser, A. Combining sources of side-channel information. In Proceedings of the Cybersecurity Conferences Series C&ESAR’19, Rennes, France, 2019; Available online: https://hal.science/hal-02456646v1/document (accessed on 30 November 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Implementation | Platform | Trace Type | Preprocessing | Classifier |
|---|---|---|---|---|---|
| [36] | HW: FPGA | Virtex-II Pro | PT 1 | mean of consecutive samples, PCA 3 | visual inspection |
| [21] | HW: FPGA | Spartan-3 | PT, EMT 2 | sum of squared values in each clock cycle | k-means |
| [38] | HW: FPGA | Spartan 3A | EMT | PCA | EM 4 clustering |
| [41] | SW: simulation | 8-bit AVR microcontroller | PT | averaging over multiple traces (same point means same precomputed values) | k-means |
| [42] | SW | - | PT | SdAEN 5 | k-means; IDEC 6 |
| [44] | SW: µNaCl | ARM Cortex-M4 | EMT | low-pass filter, outliers replaced with median of non-outliers | k-Means, fuzzy k-means, EM clustering, SOSD 7, SOST 8, MIA 9 |
| [46] | HW: FPGA | Virtex-5 | EMT | k-means, DoM 10, covariance, variance, range as POI selection | thresholding |
| SW: µNacl | ATmega2560 | trace alignment (for SW) | |||
| [47] | HW: FPGA | SASEBO-GII FPGA | PT, EMT | low-pass filter, POI 11 selection with SOST, trace alignment | k-means, fuzzy k-means, EM, SPA 12 |
| SW: mbedTLS, OpenSSL | AVR XMEGA 128D4 | ||||
| [39] | HW: FPGA | Spartan 6 | PT | sum of squared values in each clock cycle | difference to the mean and k-means |
| [18] | SW: μNaCl | ARM Cortex-M4 | EMT | low-pass filter, Gradient Visualization for POI selection | CLA 13 (k-means, fuzzy k-means, EM clustering) followed by CNN 14 |
| [17] | HW: FPGA, ASIC | Spartan 6 | PT, EMT | sum of squared values in each clock cycle | difference to the mean followed by SVM 15 |
| This | followed by ANN 16 |
| λ | ||||||
|---|---|---|---|---|---|---|
| Analyzed Trace | Method | 0.001 | 0.01 | 0.1 | 1 | 10 |
| Design_seq (FPGA) EMT | initial | 96% | ||||
| SVM C = 0.3 | 100% | |||||
| scikit-learn L2 | 96% | 100% | ||||
| tensorflow L2 | 96% | 98% | 100% | 98% | ||
| tensorflow L1 | 96% | 99% | 52% | 57% | 52% | |
| Design_Seq (FPGA) PT | initial | 88% | ||||
| SVM C = 0.3 | 99% | |||||
| scikit-learn L2 | 88% | 94% | ||||
| tensorflow L2 | 88% | 91% | 97% | 69% | ||
| tensorflow L1 | 88% | 53% | 52% | |||
| Design_ultra (ASIC) EMT | initial | 75% | ||||
| SVM C = 0.3 | 90% | |||||
| scikit-learn L2 | 75% | 82% | ||||
| tensorflow L2 | 75% | 77% | 84% | 86% | ||
| tensorflow L1 | 75% | 55% | 56% | 58% | ||
| Design_ultra (ASIC) PT | initial | 74% | ||||
| SVM C = 0.3 | 89% | |||||
| scikit-learn L2 | 74% | 81% | ||||
| tensorflow L2 | 74% | 76% | 80% | 84% | ||
| tensorflow L1 | 74% | 75% | 63% | 52% | 62% | |
| Analyzed Trace | Method | Max Score | Scores > 95% | Iterations |
|---|---|---|---|---|
| Design_seq (FPGA) EMT | initial | 96% | 1 | - |
| SVM C = 0.3 | 100% | 4 | 1 | |
| scikit-learn L2 λ = 10 | 100% | 5 | 43 | |
| tensorflow L2 λ = 1 | 100% | 4 | 29 | |
| tensorflow L1 λ = 0.01 | 100% | 4 | 41 | |
| Design_Seq (FPGA) PT | initial | 88% | - | - |
| SVM C = 0.3 | 99% | 1 | 1 | |
| scikit-learn L2 λ = 10 | 98% | 1 | 34 | |
| tensorflow L2 λ = 1 | 98% | 1 | 48 | |
| tensorflow L1 λ = 0.01 | 90% | - | 90 | |
| Design_ultra (ASIC) EMT | initial | 75% | - | - |
| SVM C = 0.3 | 90% | - | 1 | |
| scikit-learn L2 λ = 10 | 97% | 6 | 68 | |
| tensorflow L2 λ = 1 | 98% | 4 | 64 | |
| tensorflow L1 λ = 0.01 | 79% | - | 52 | |
| Design_ultra (ASIC) PT | initial | 74% | - | - |
| SVM C = 0.3 | 89% | - | 1 | |
| scikit-learn L2 λ = 10 | 94% | - | 97 | |
| tensorflow L2 λ = 1 | 92% | - | 39 | |
| tensorflow L1 λ = 0.01 | 74% | - | 56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aftowicz, M.; Kabin, I.; Dyka, Z.; Langendörfer, P. Non-Profiled Unsupervised Horizontal Iterative Attack against Hardware Elliptic Curve Scalar Multiplication Using Machine Learning. Future Internet 2024, 16, 45. https://doi.org/10.3390/fi16020045
Aftowicz M, Kabin I, Dyka Z, Langendörfer P. Non-Profiled Unsupervised Horizontal Iterative Attack against Hardware Elliptic Curve Scalar Multiplication Using Machine Learning. Future Internet. 2024; 16(2):45. https://doi.org/10.3390/fi16020045
Chicago/Turabian StyleAftowicz, Marcin, Ievgen Kabin, Zoya Dyka, and Peter Langendörfer. 2024. "Non-Profiled Unsupervised Horizontal Iterative Attack against Hardware Elliptic Curve Scalar Multiplication Using Machine Learning" Future Internet 16, no. 2: 45. https://doi.org/10.3390/fi16020045
APA StyleAftowicz, M., Kabin, I., Dyka, Z., & Langendörfer, P. (2024). Non-Profiled Unsupervised Horizontal Iterative Attack against Hardware Elliptic Curve Scalar Multiplication Using Machine Learning. Future Internet, 16(2), 45. https://doi.org/10.3390/fi16020045