
Enhancing Urban Resilience: Smart City Data Analyses, Forecasts, and Digital Twin Techniques at the Neighborhood Level





Abstract
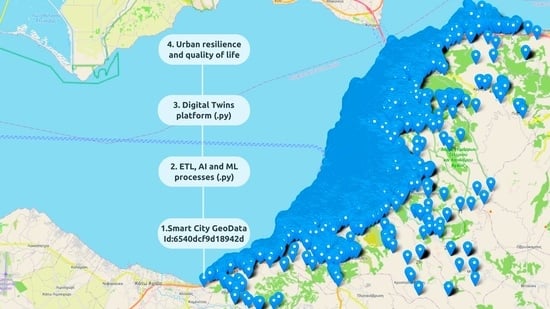
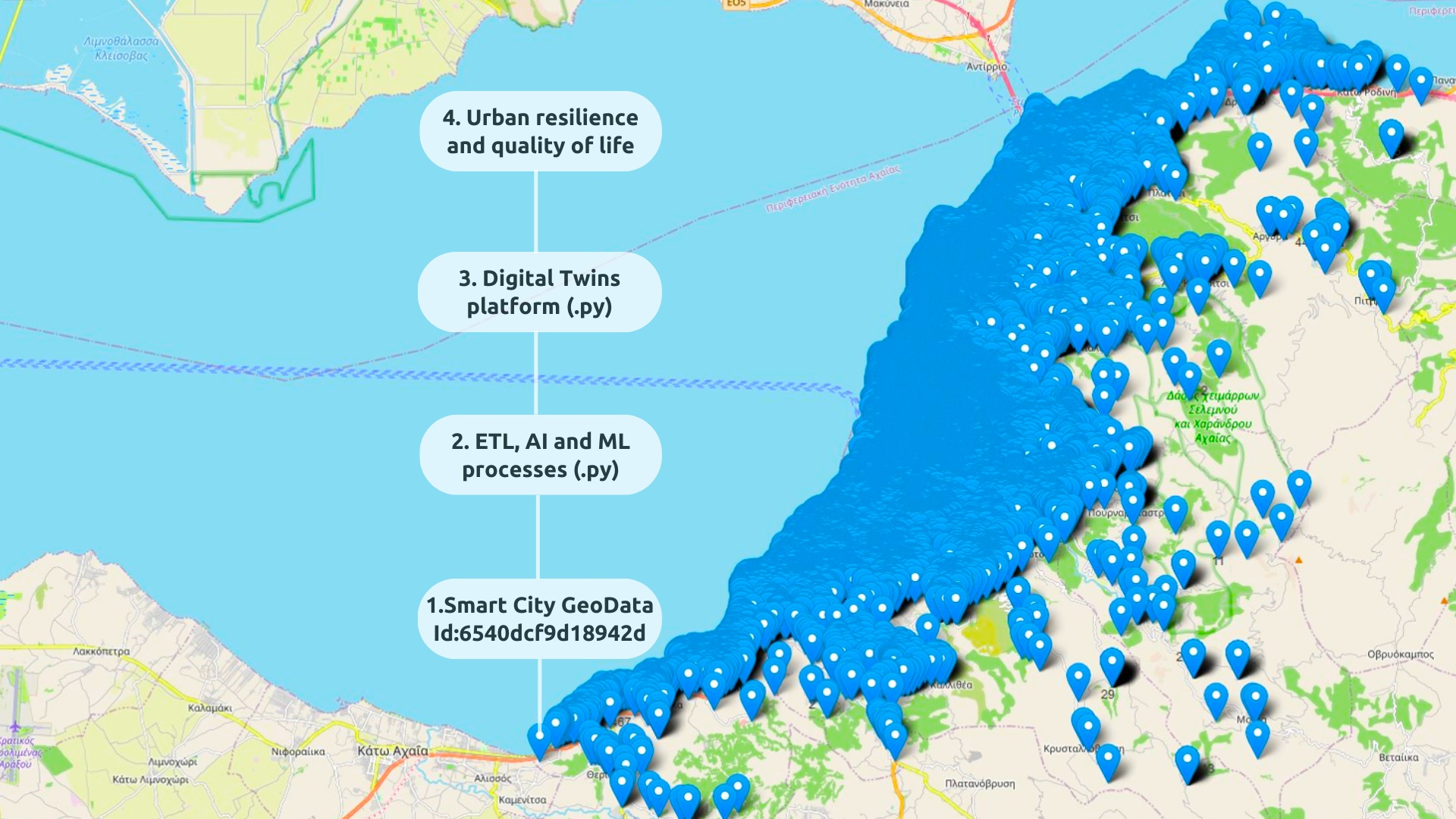
:
1. Introduction
Related Work
2. Materials and Methods
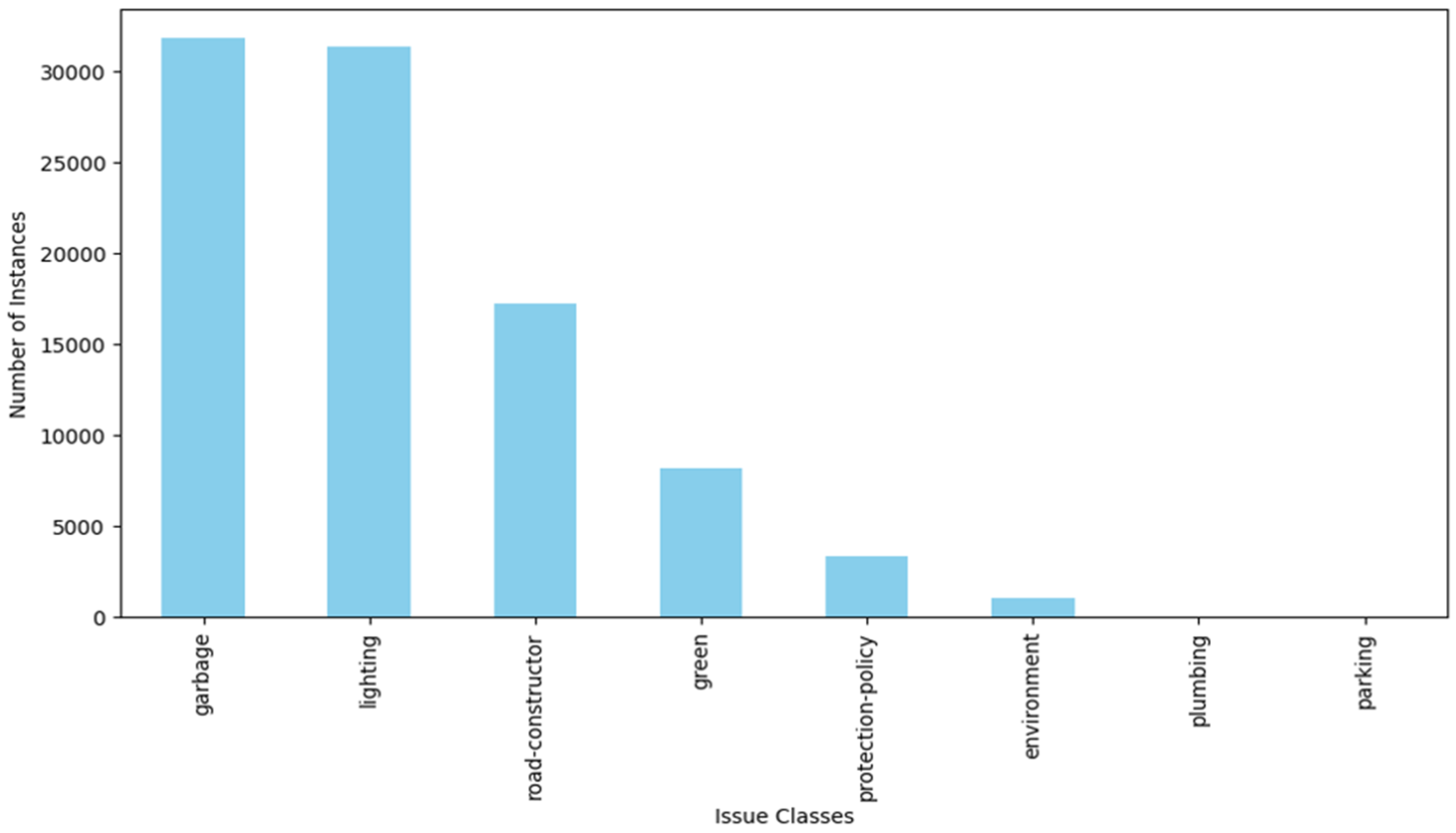
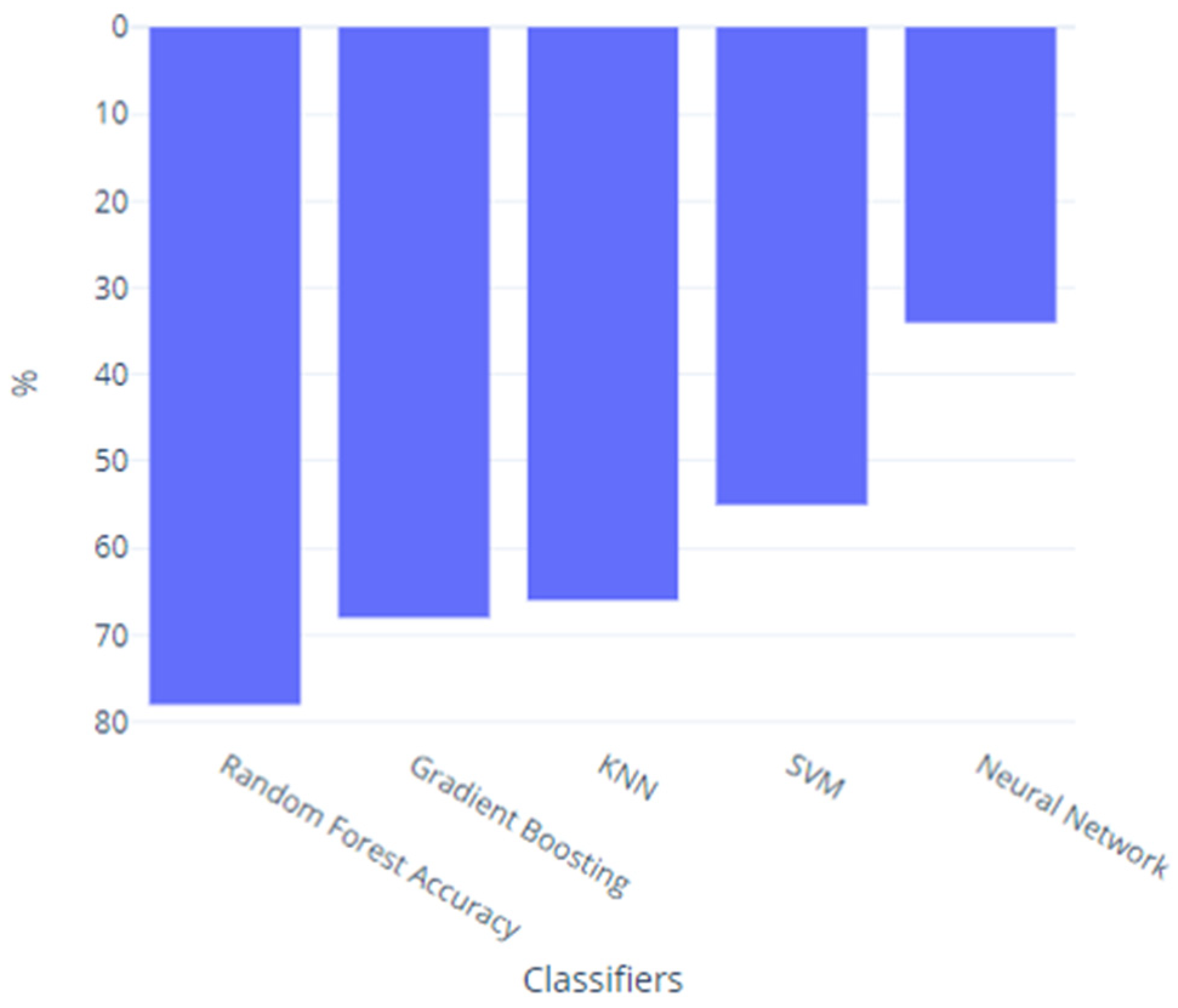
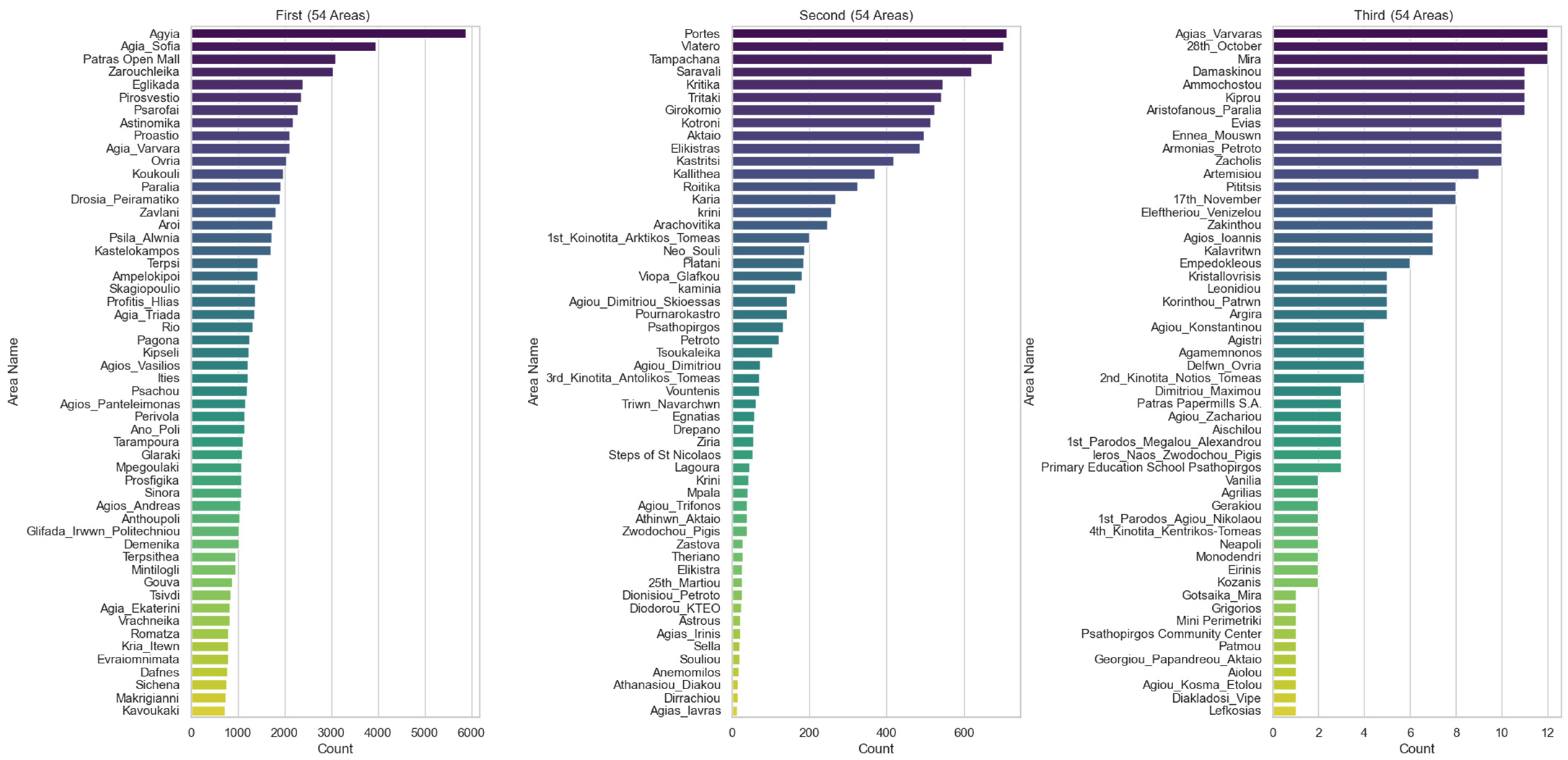
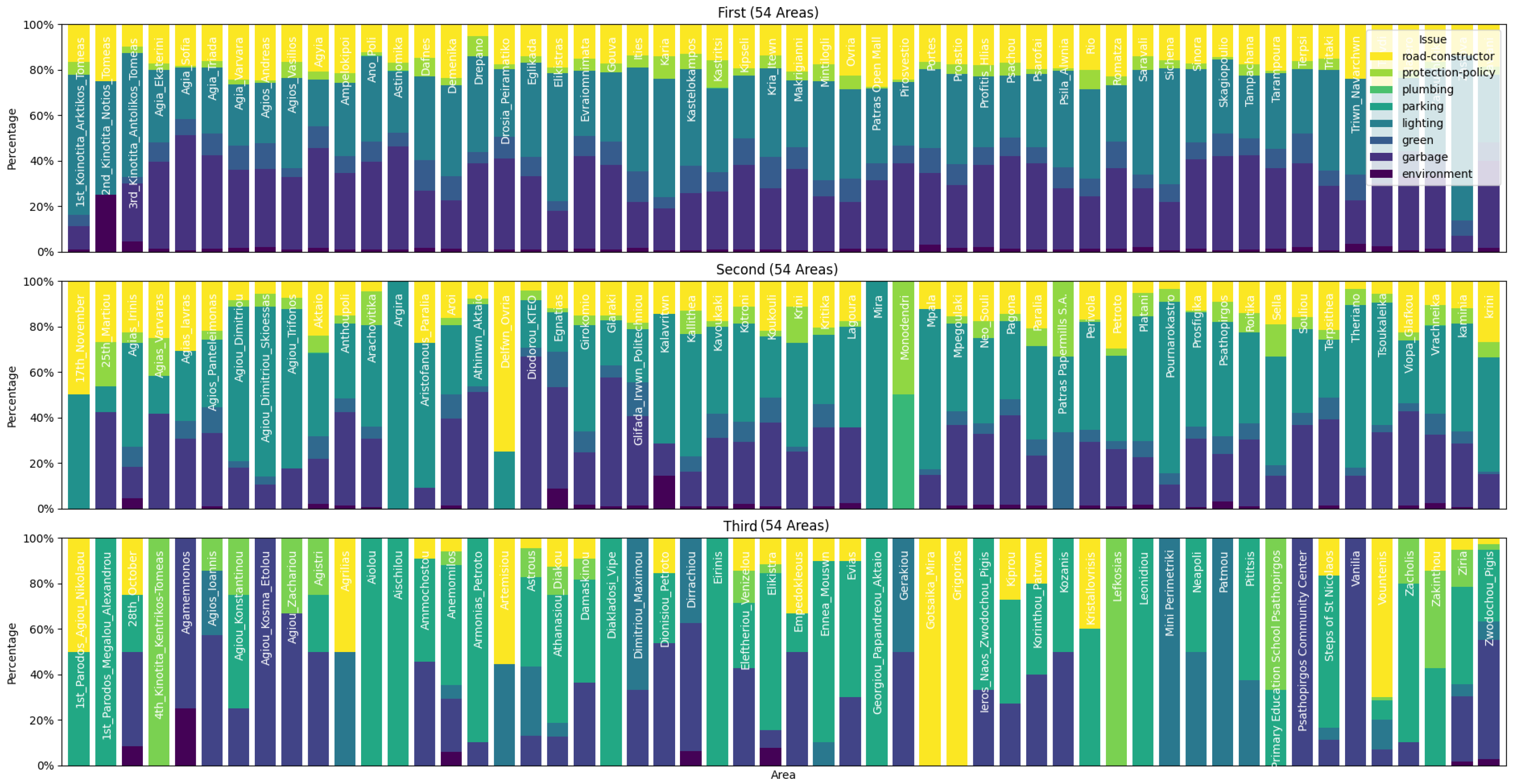
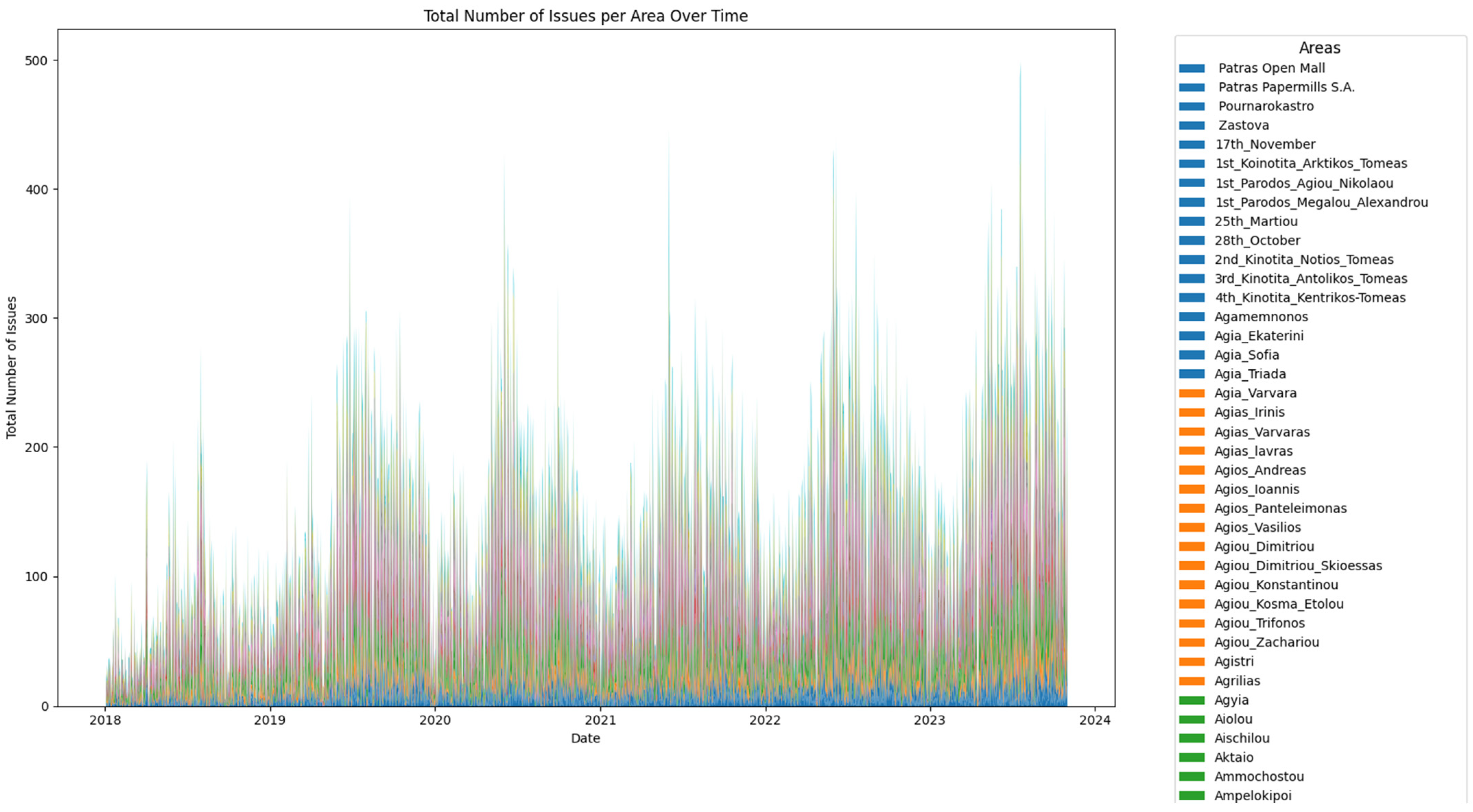
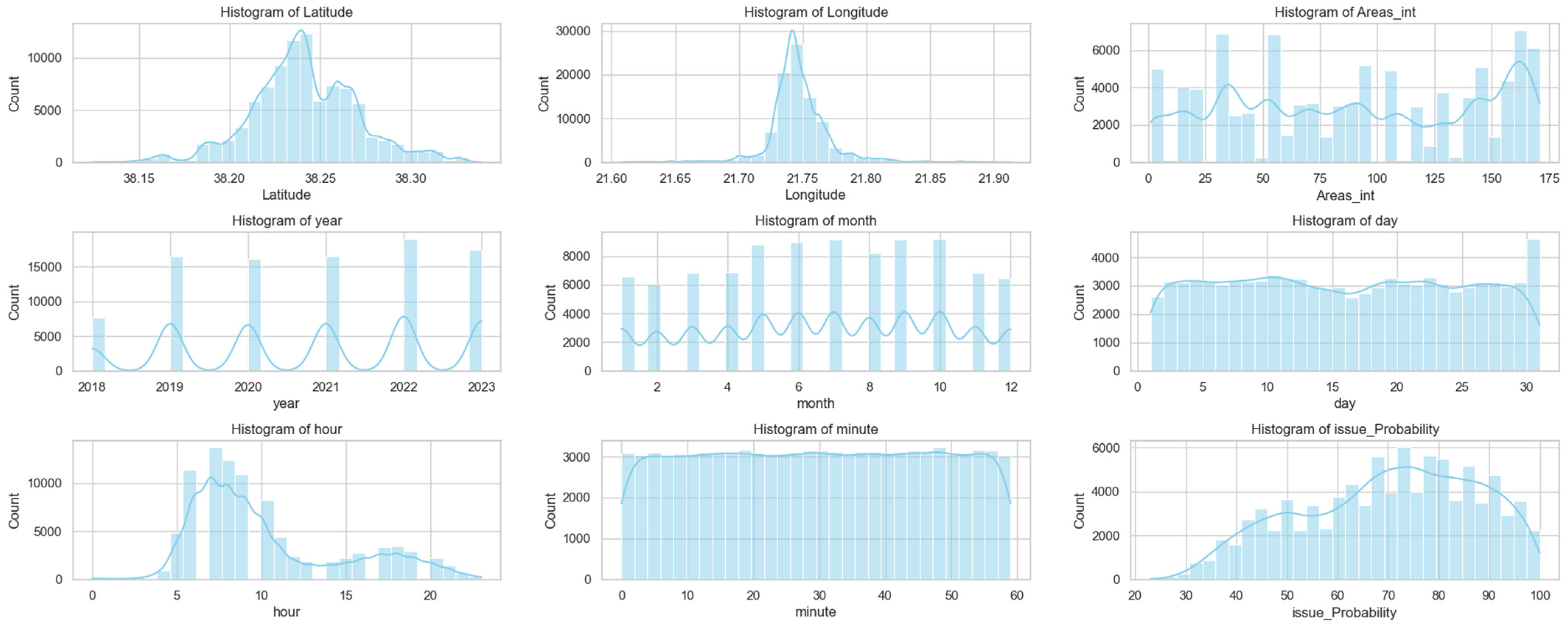
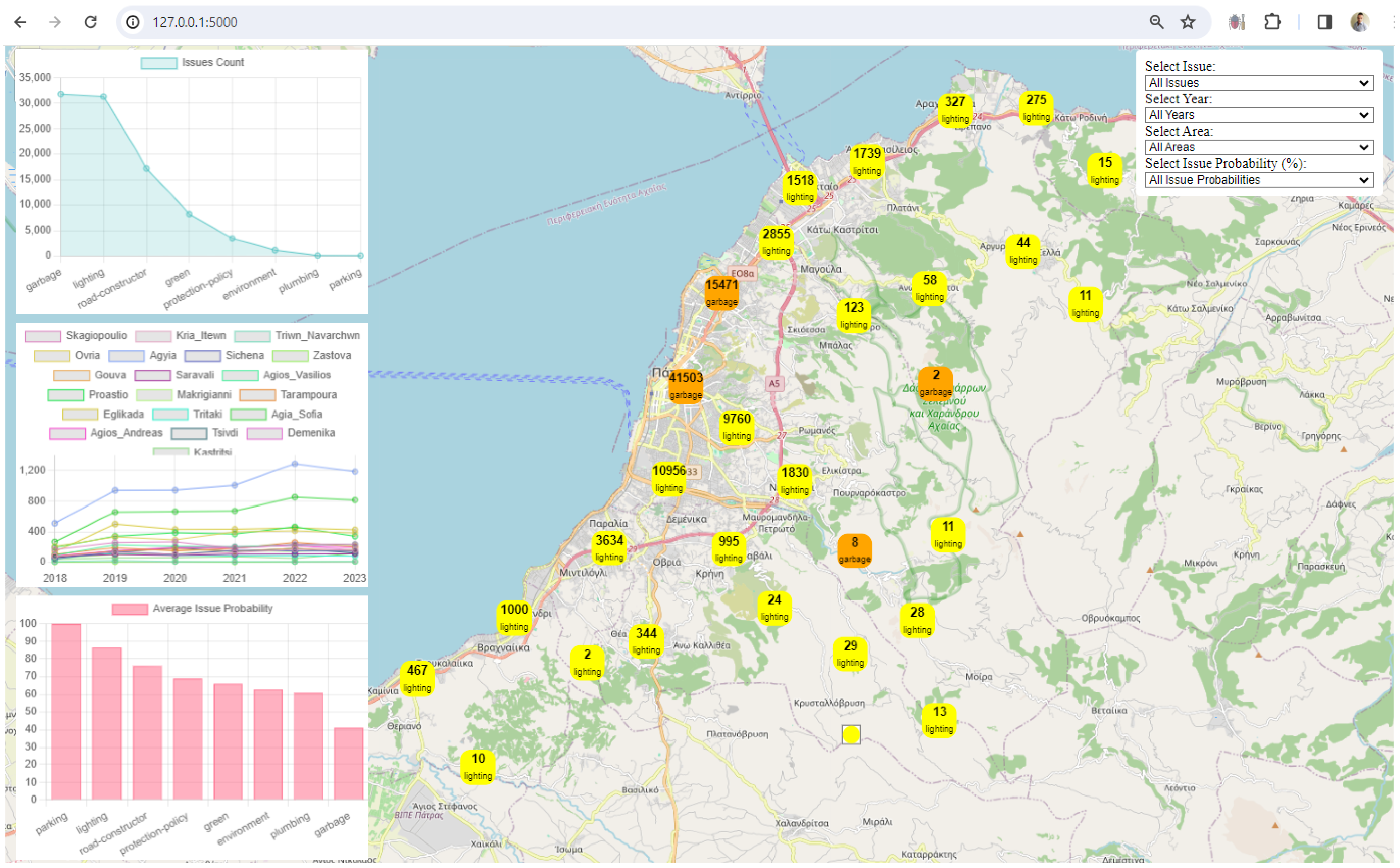
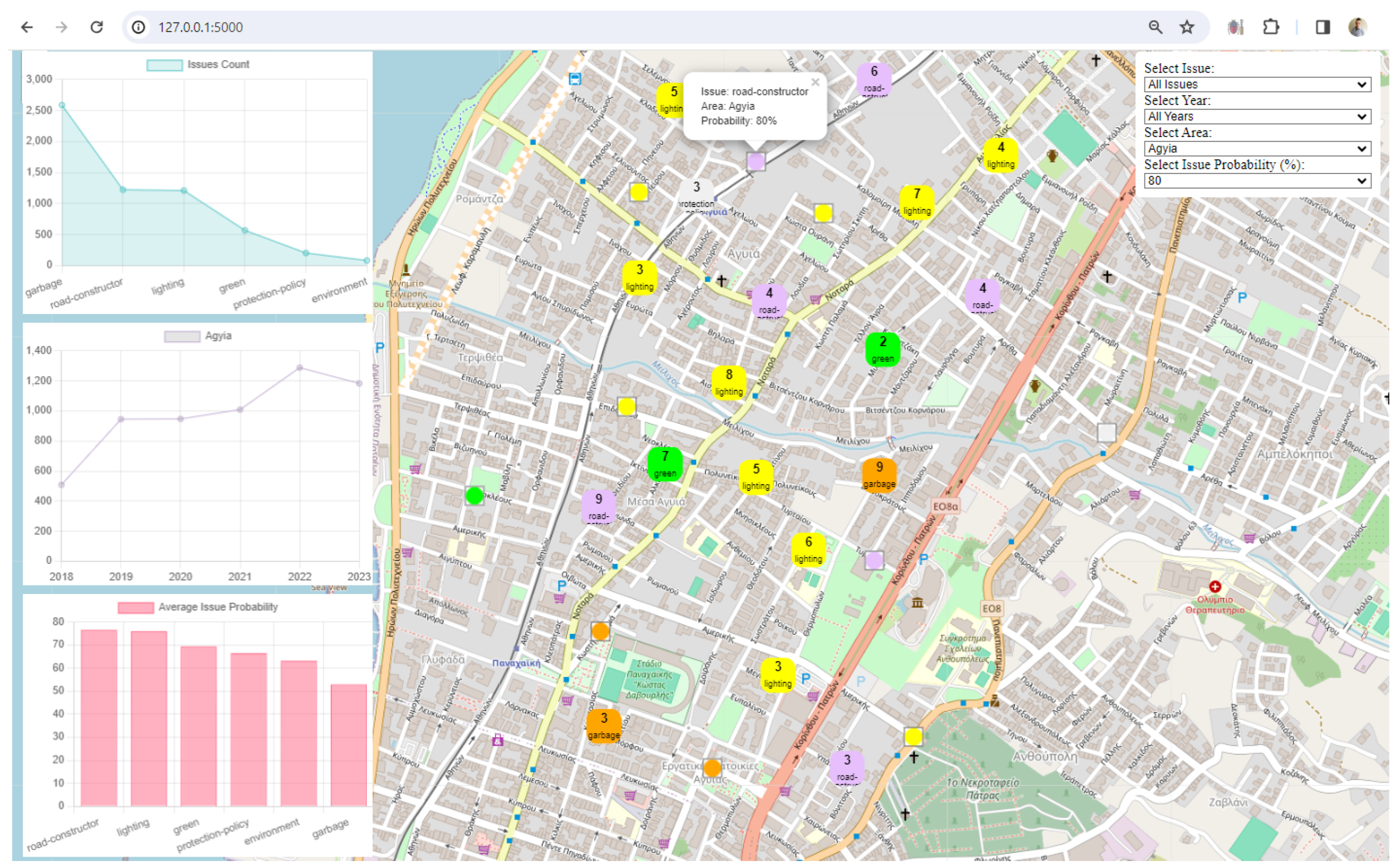
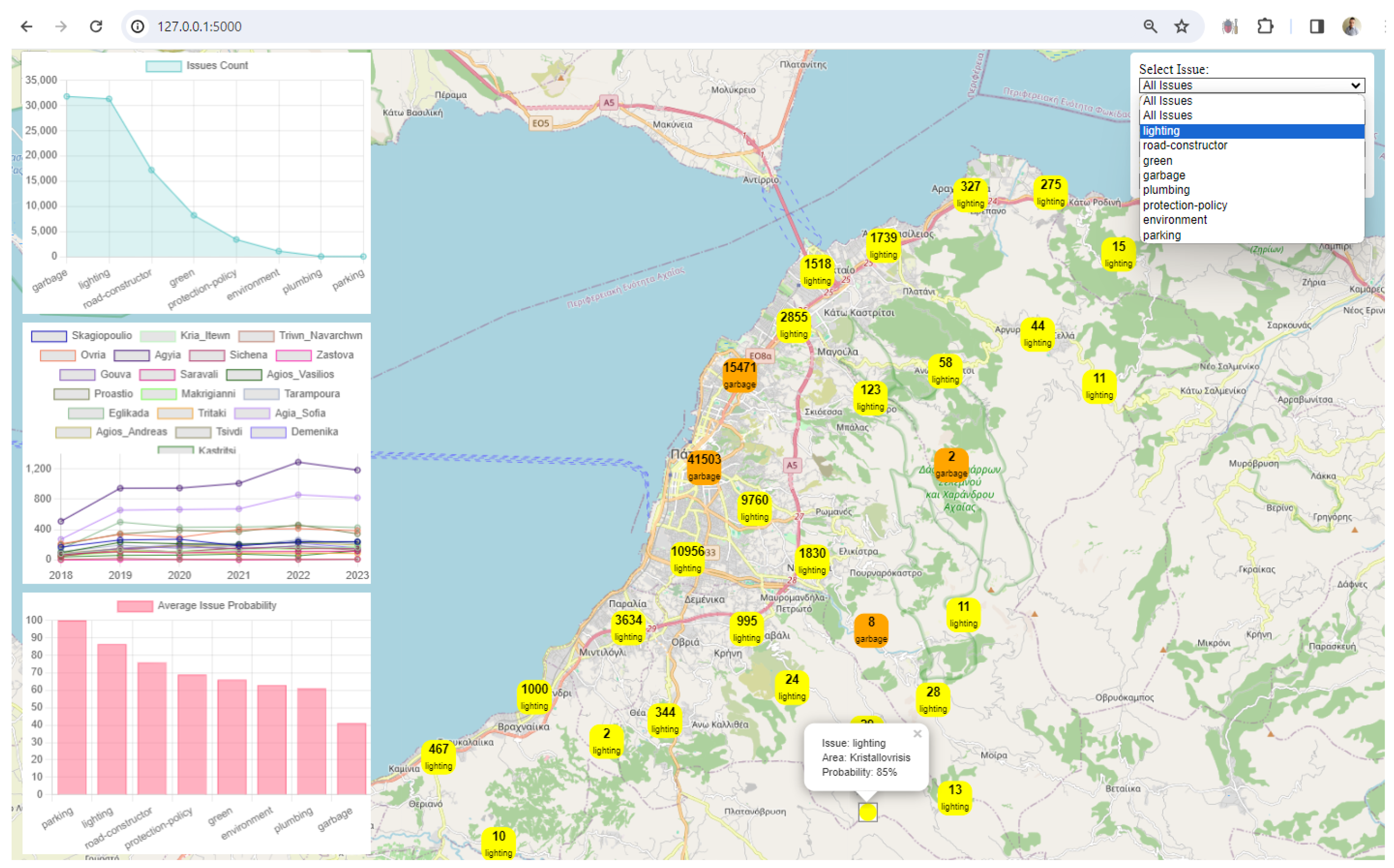
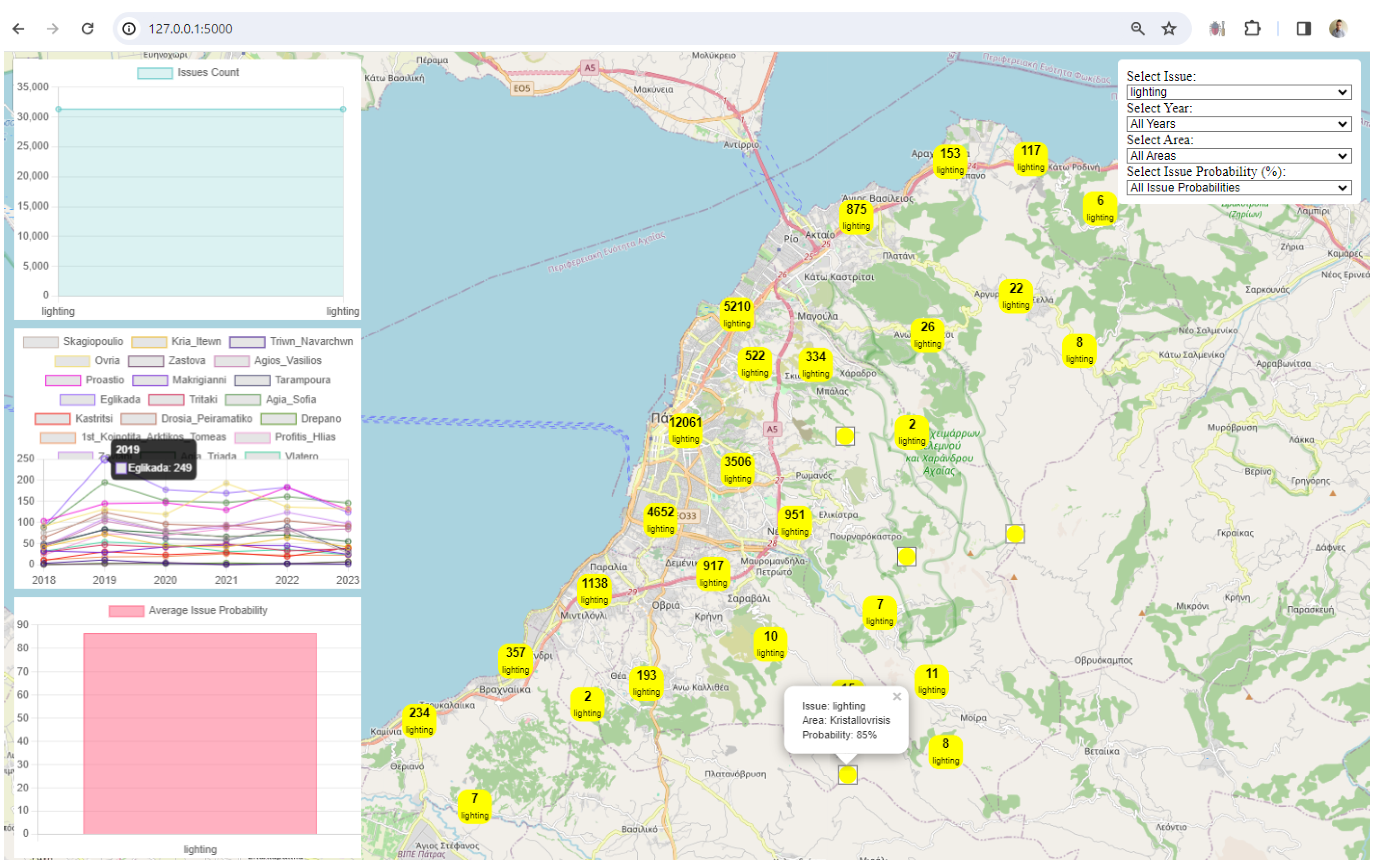
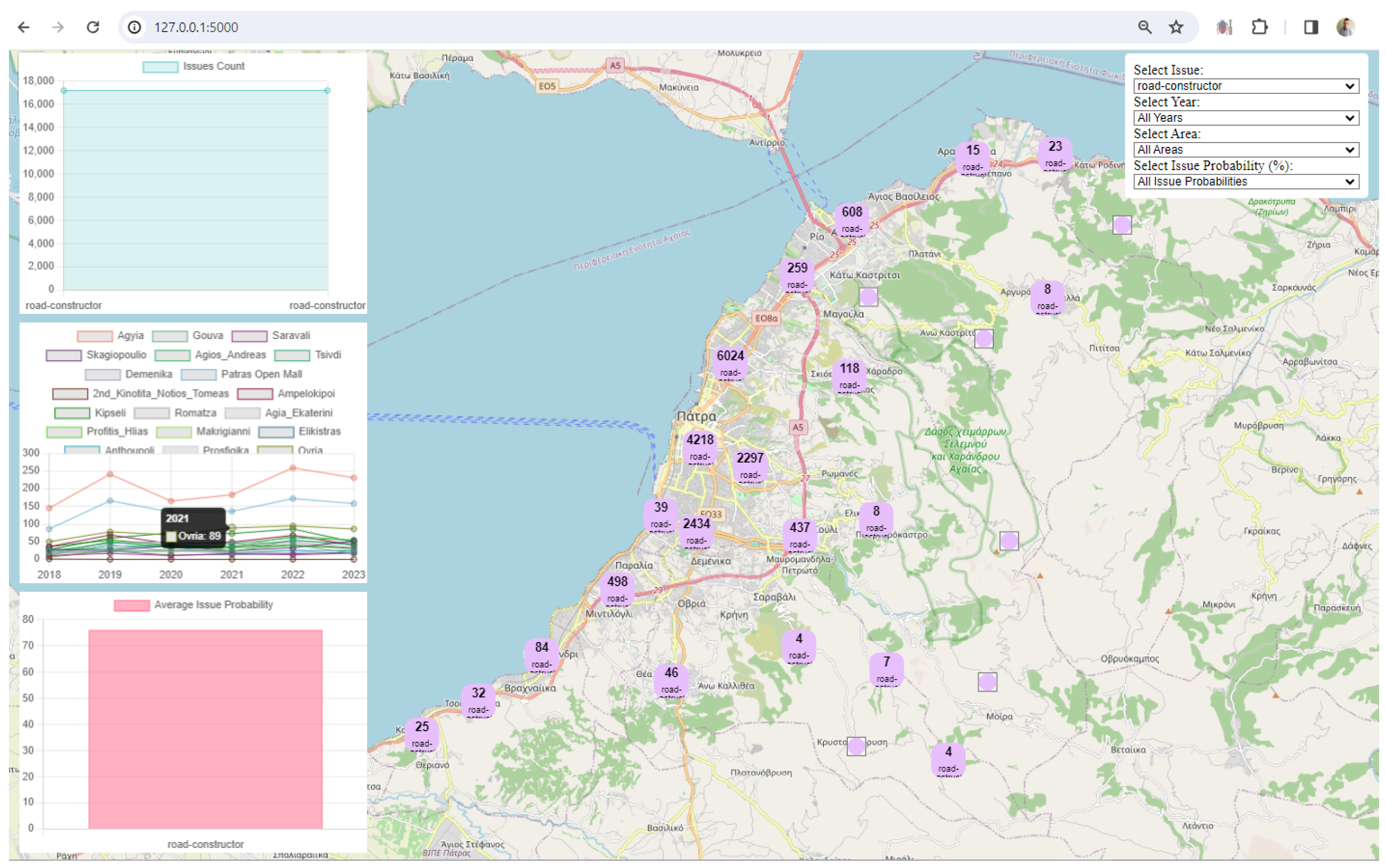
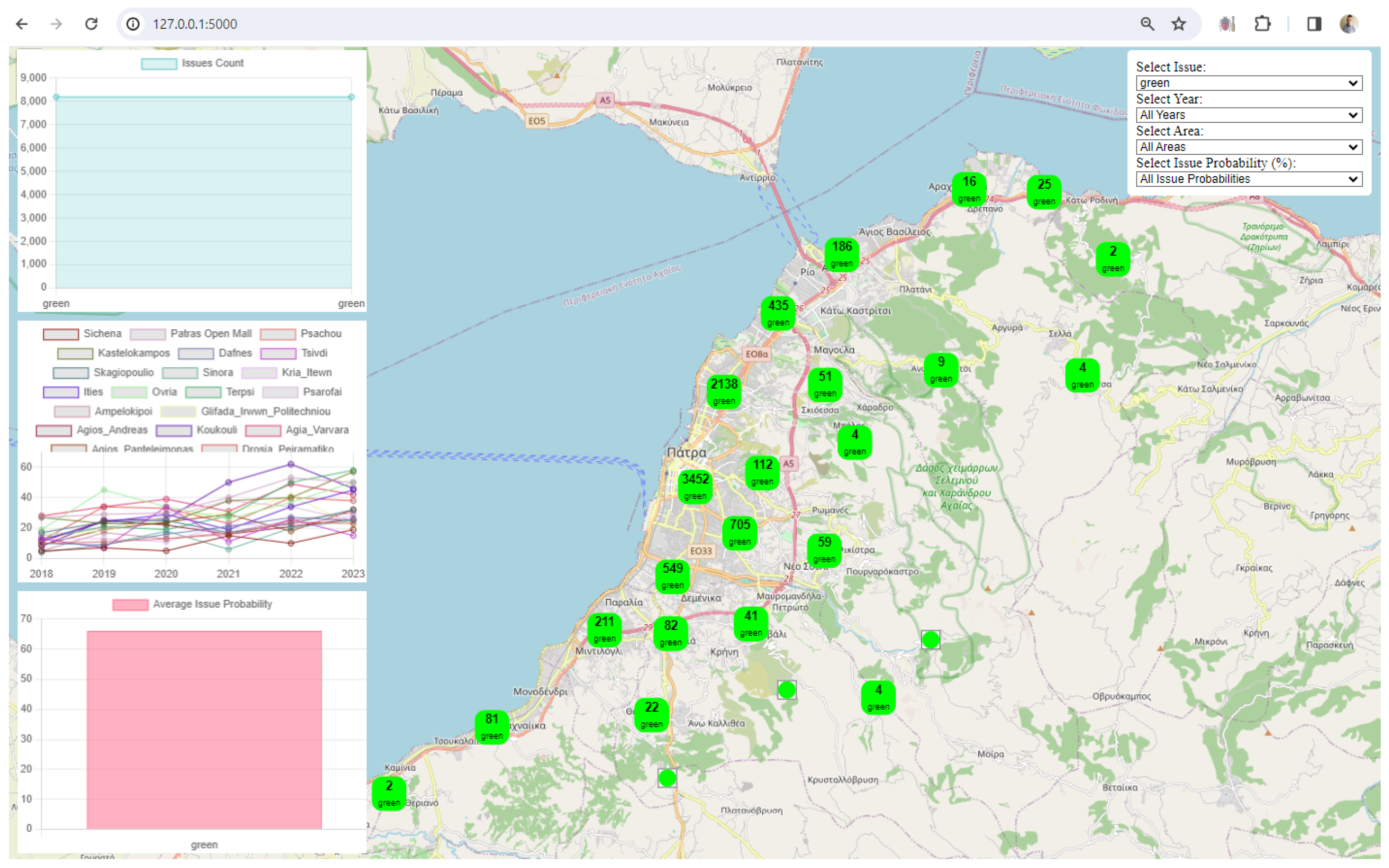
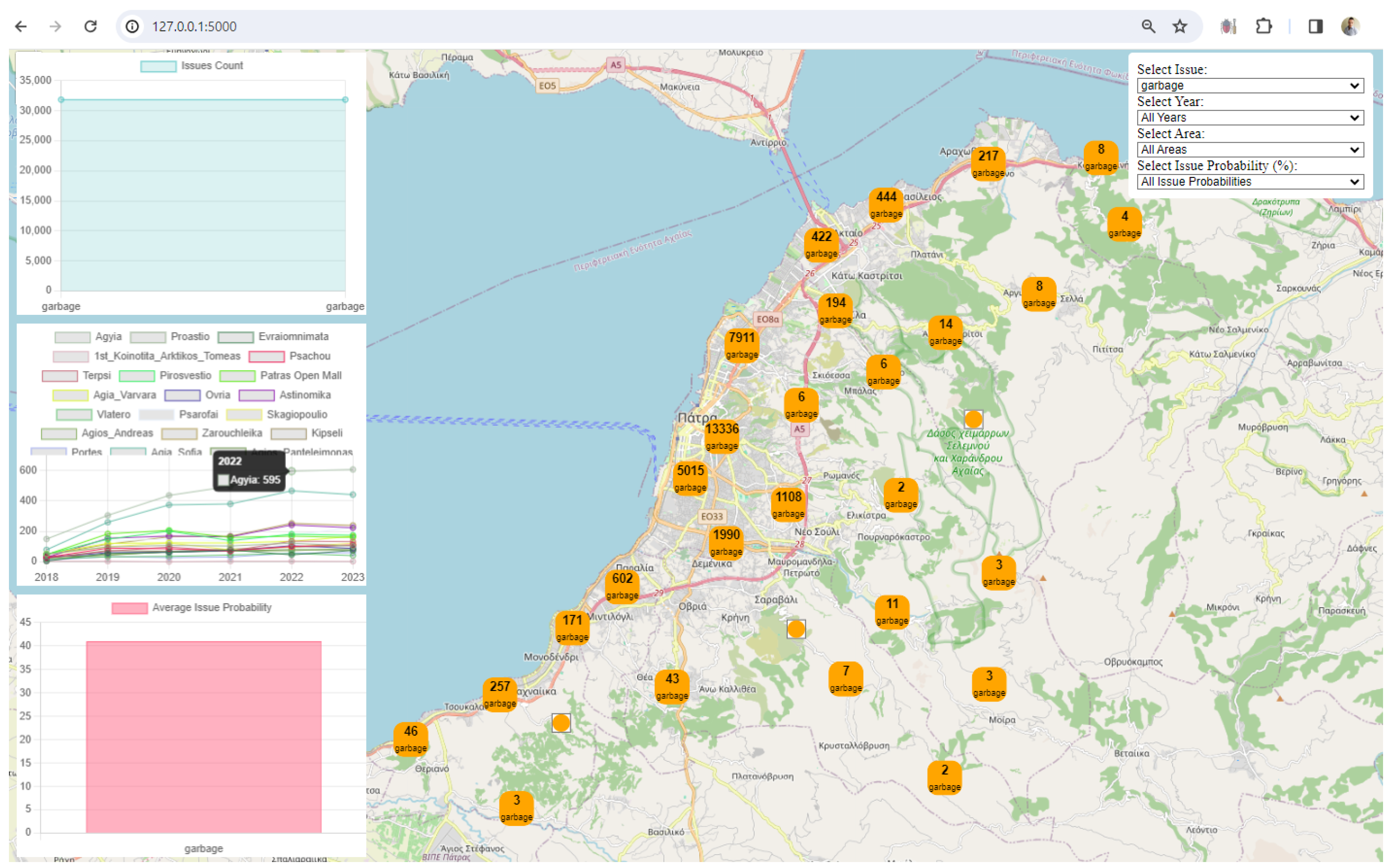
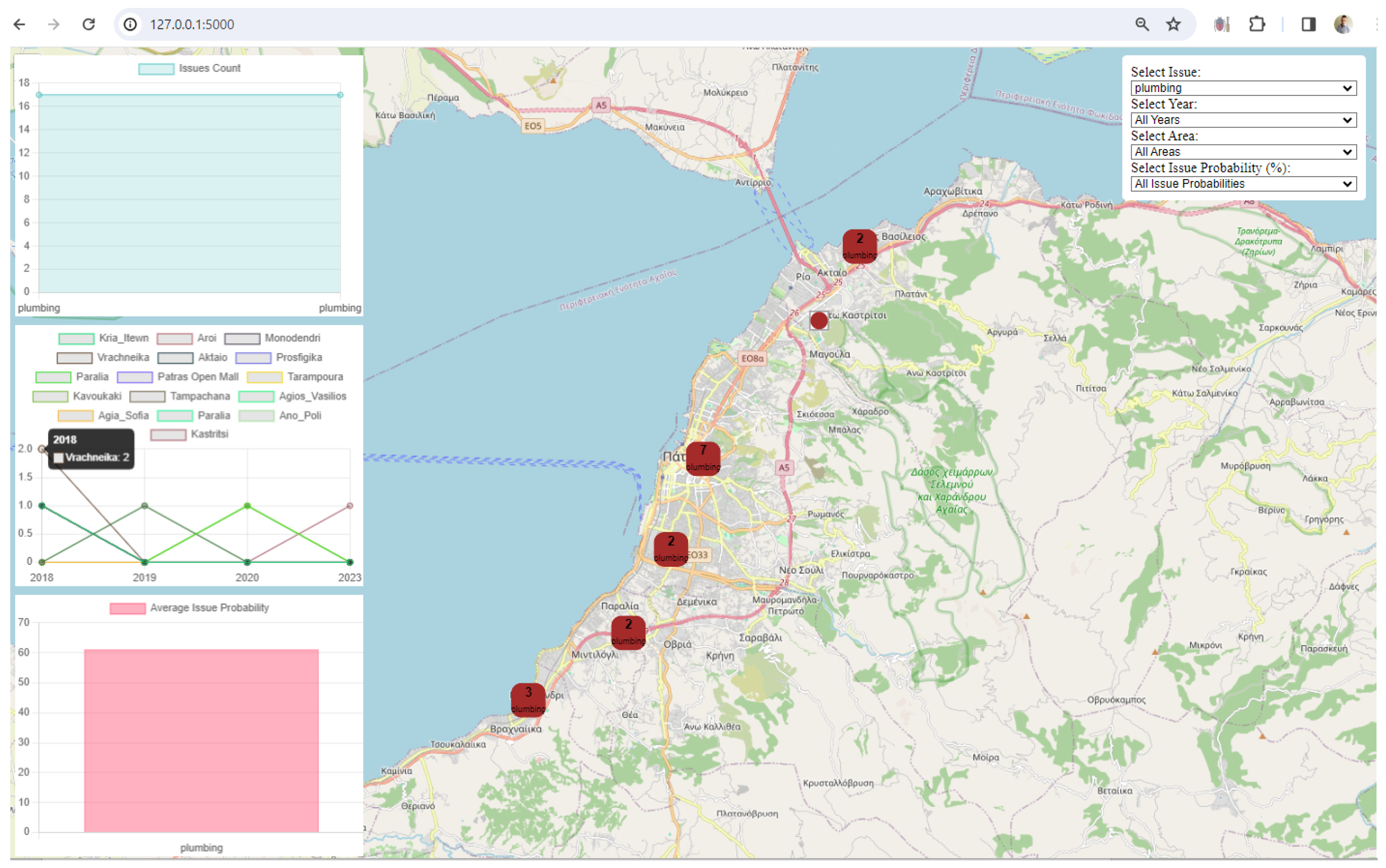
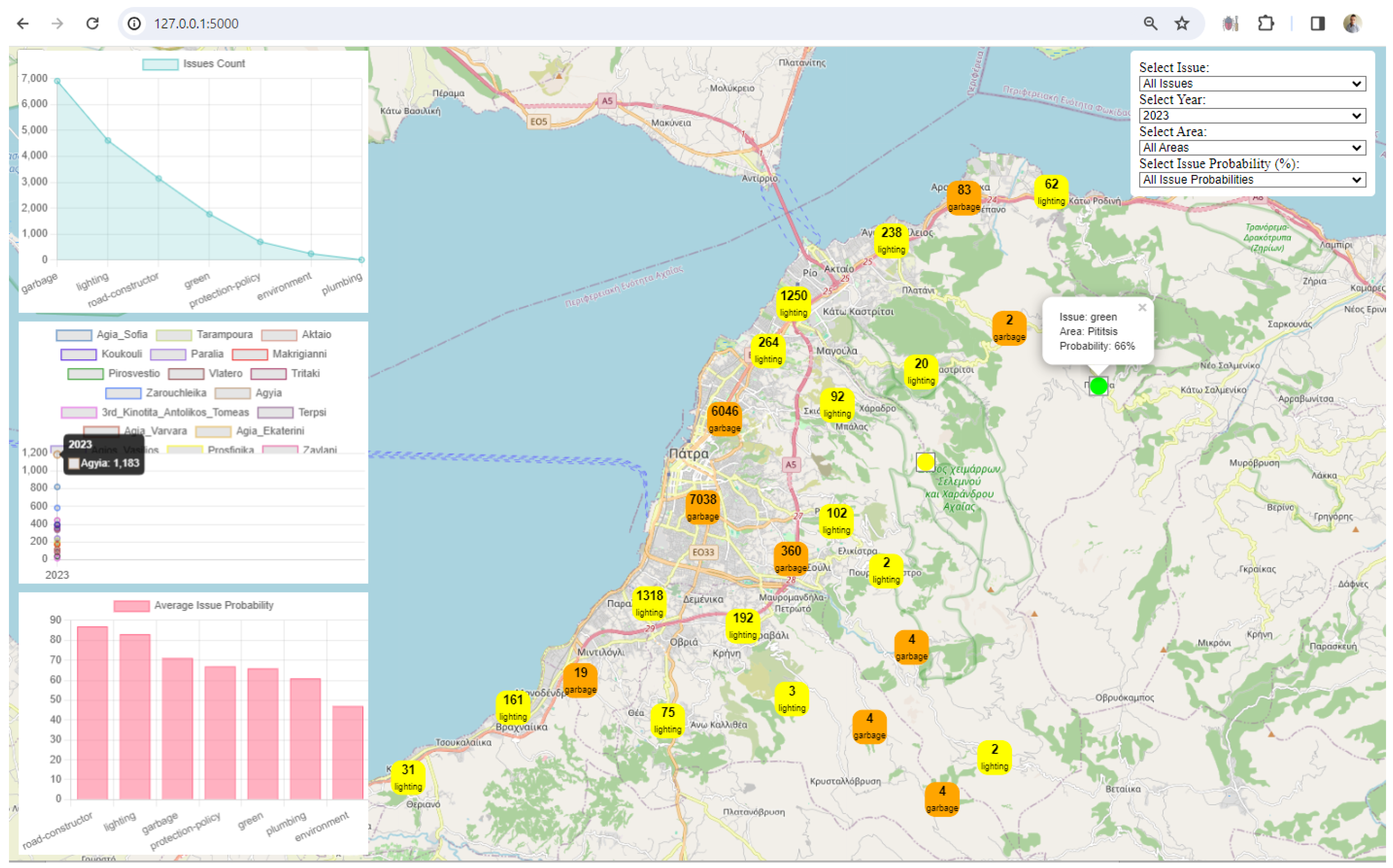
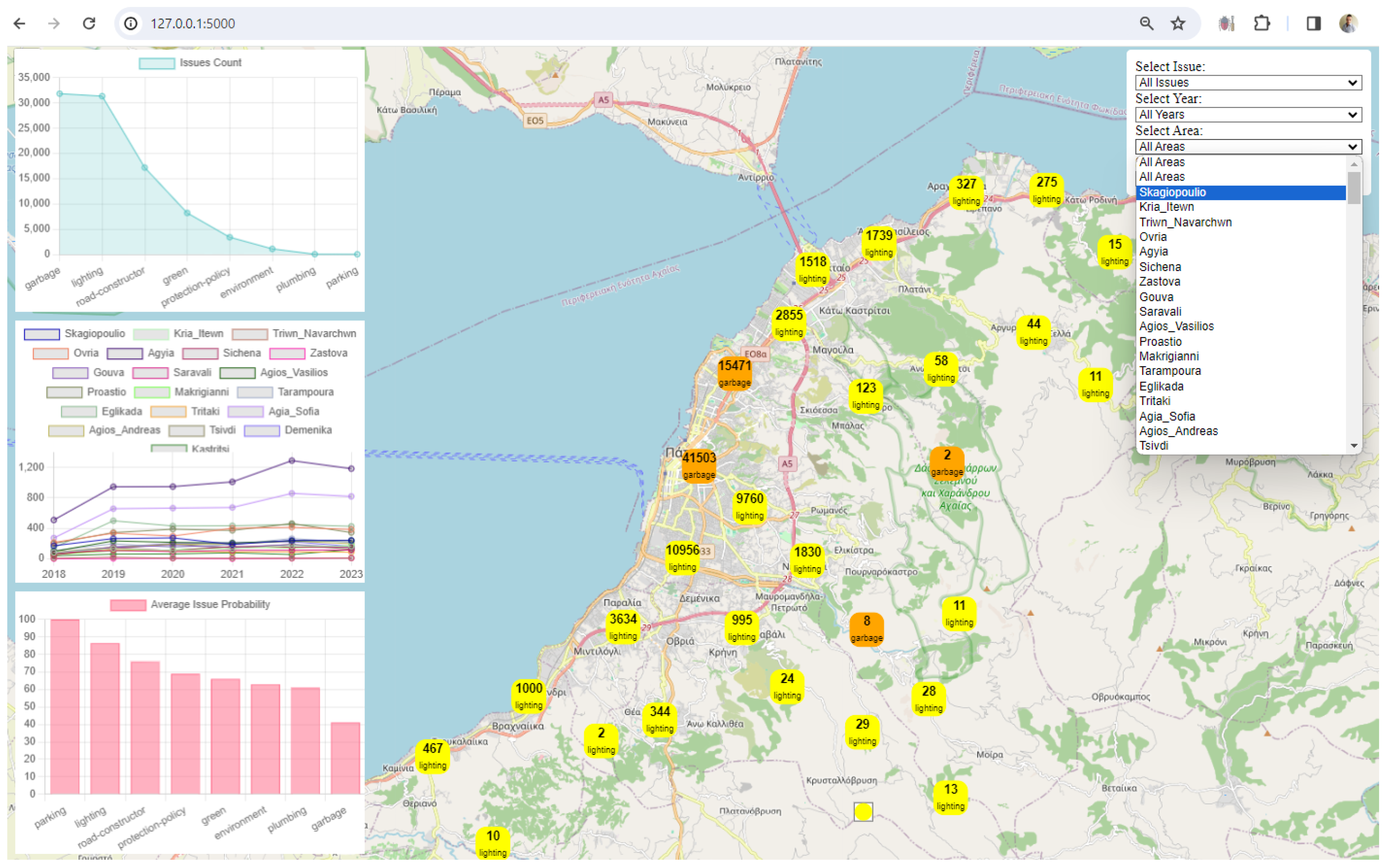
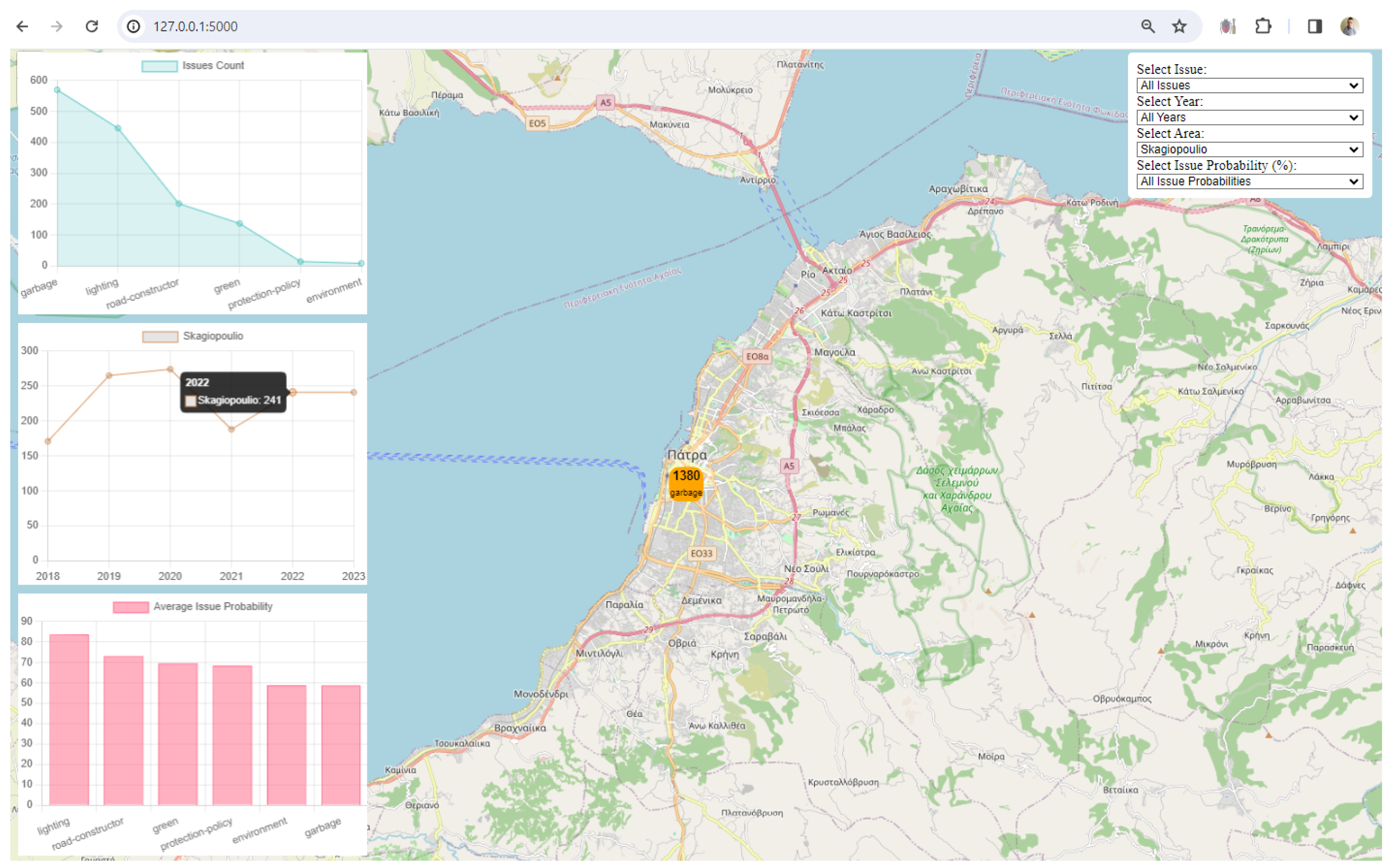
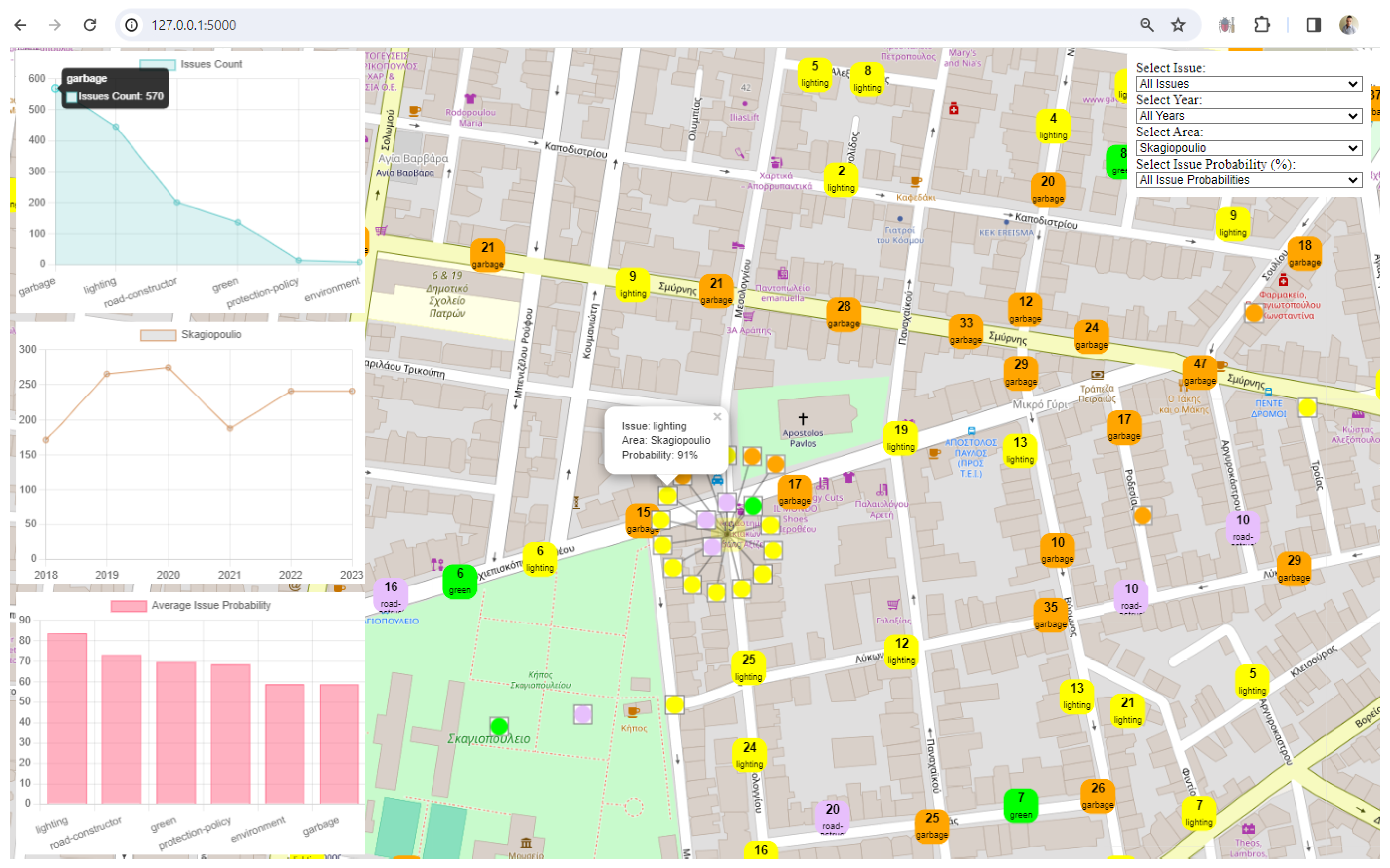
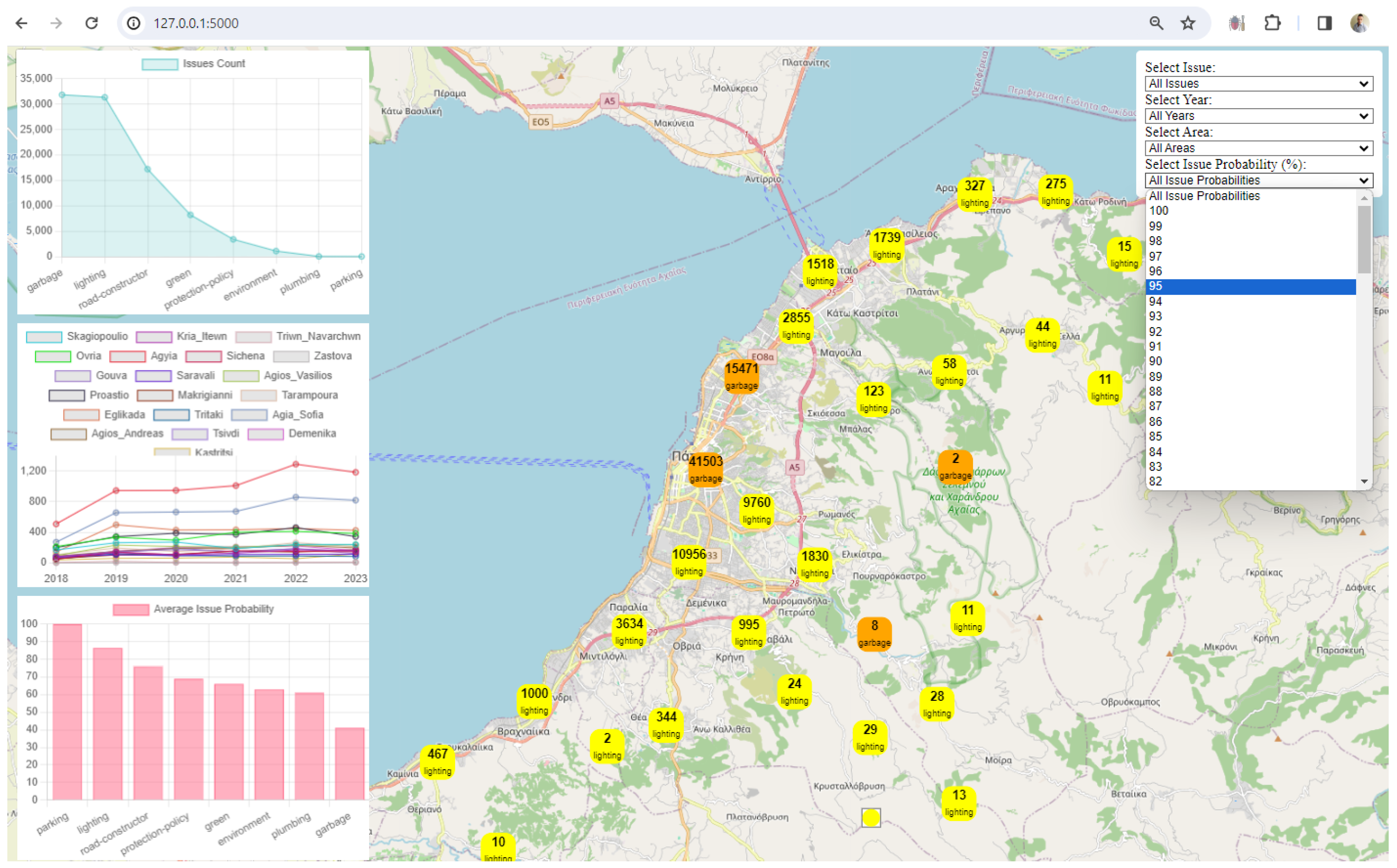
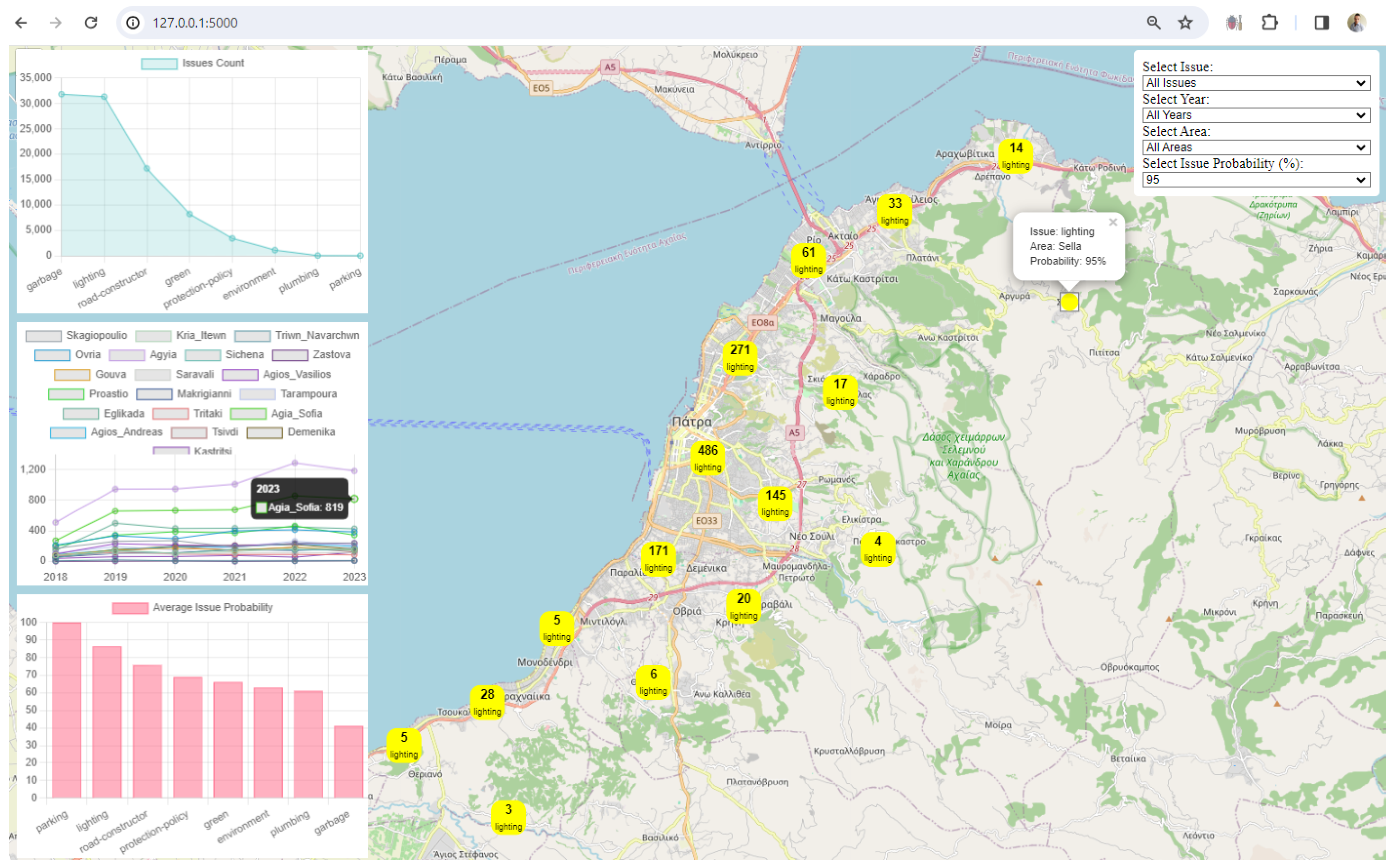
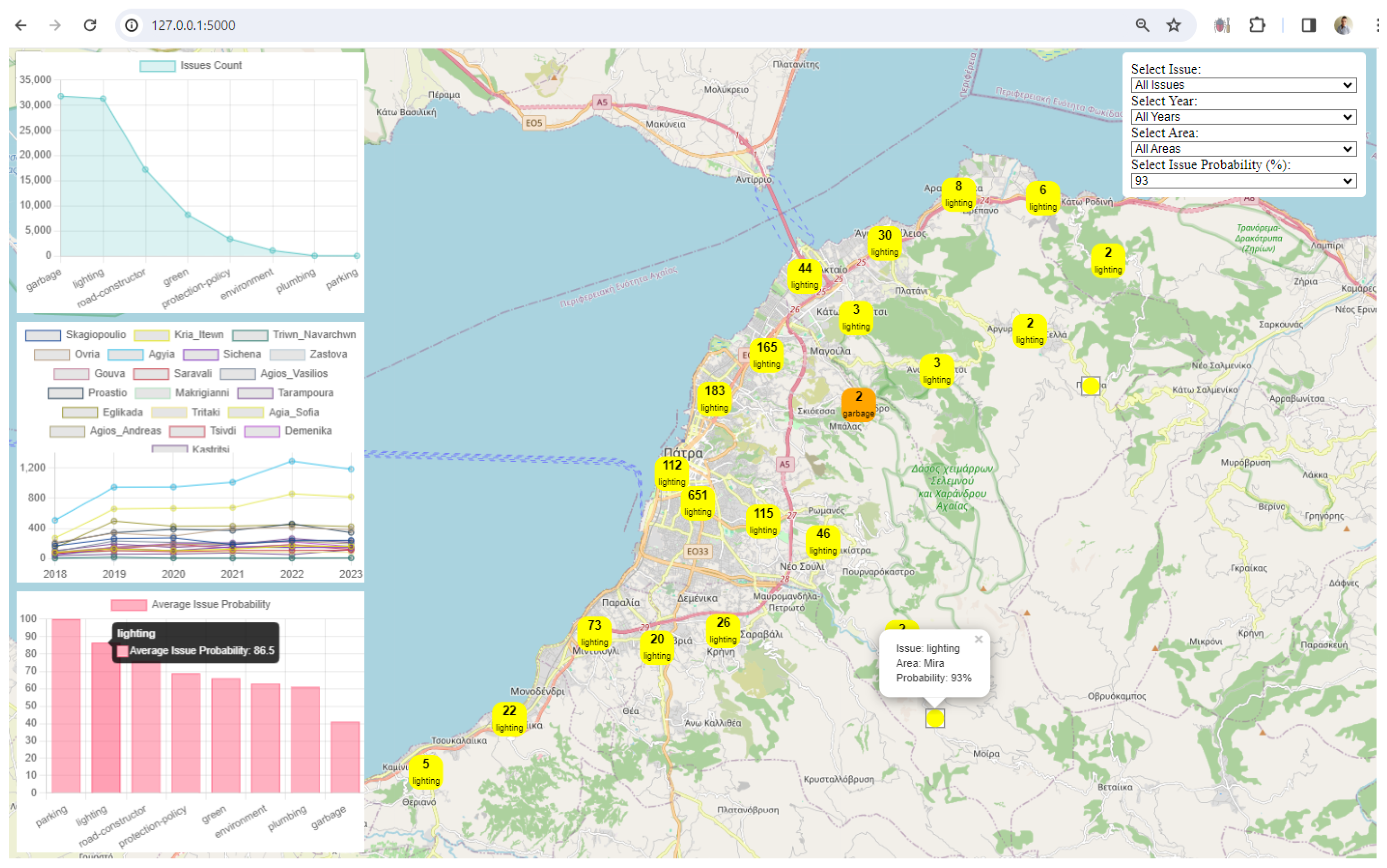
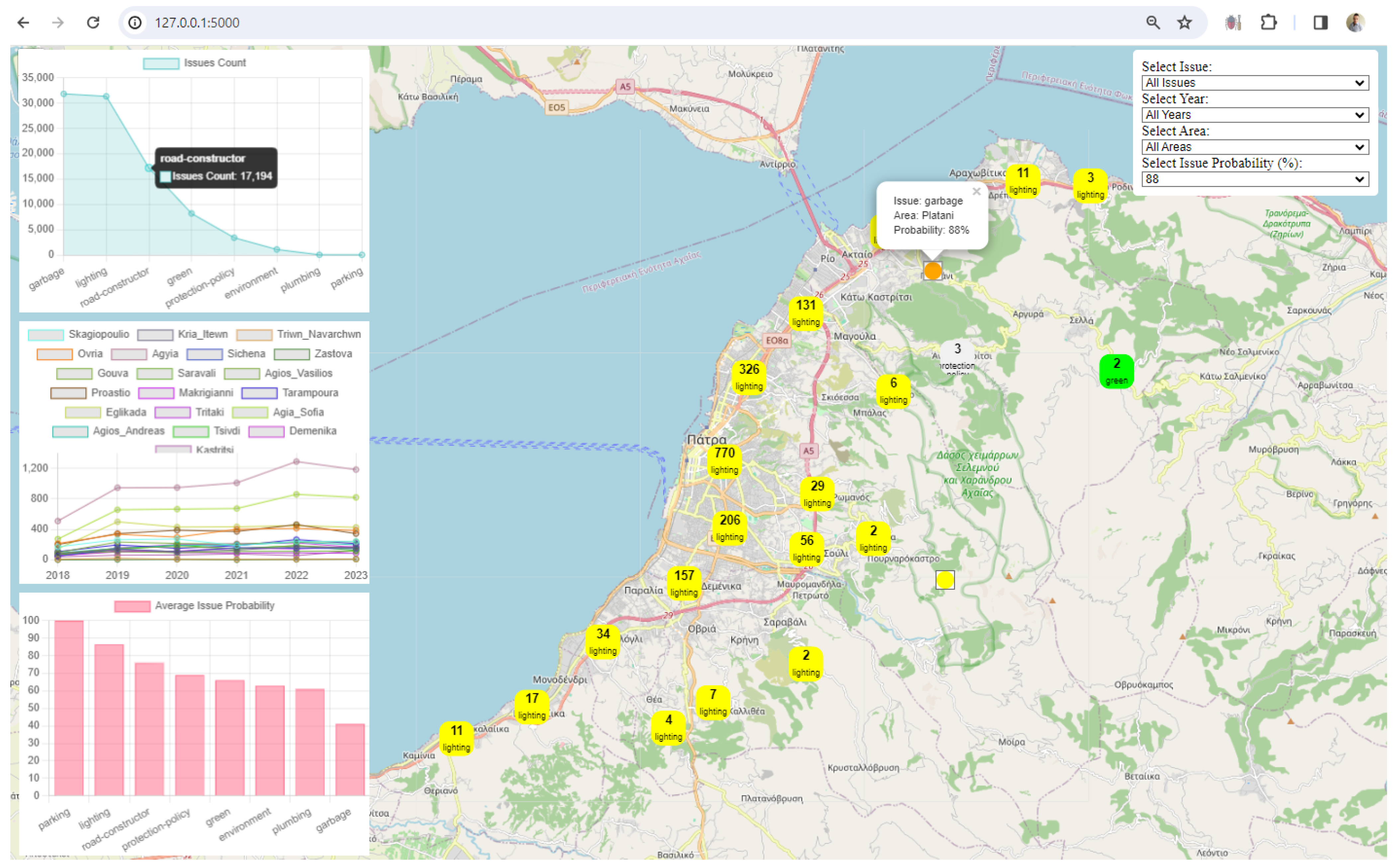
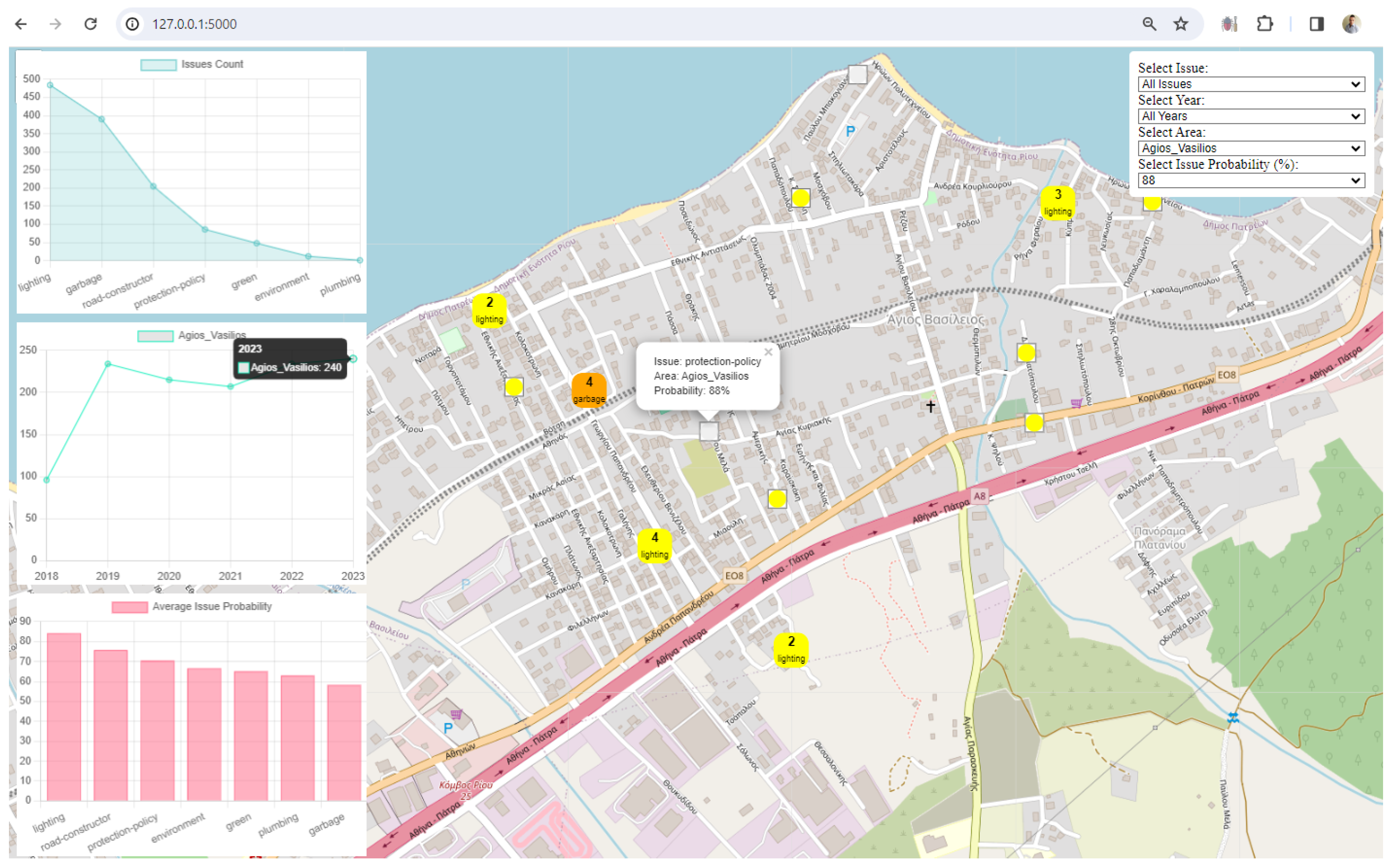
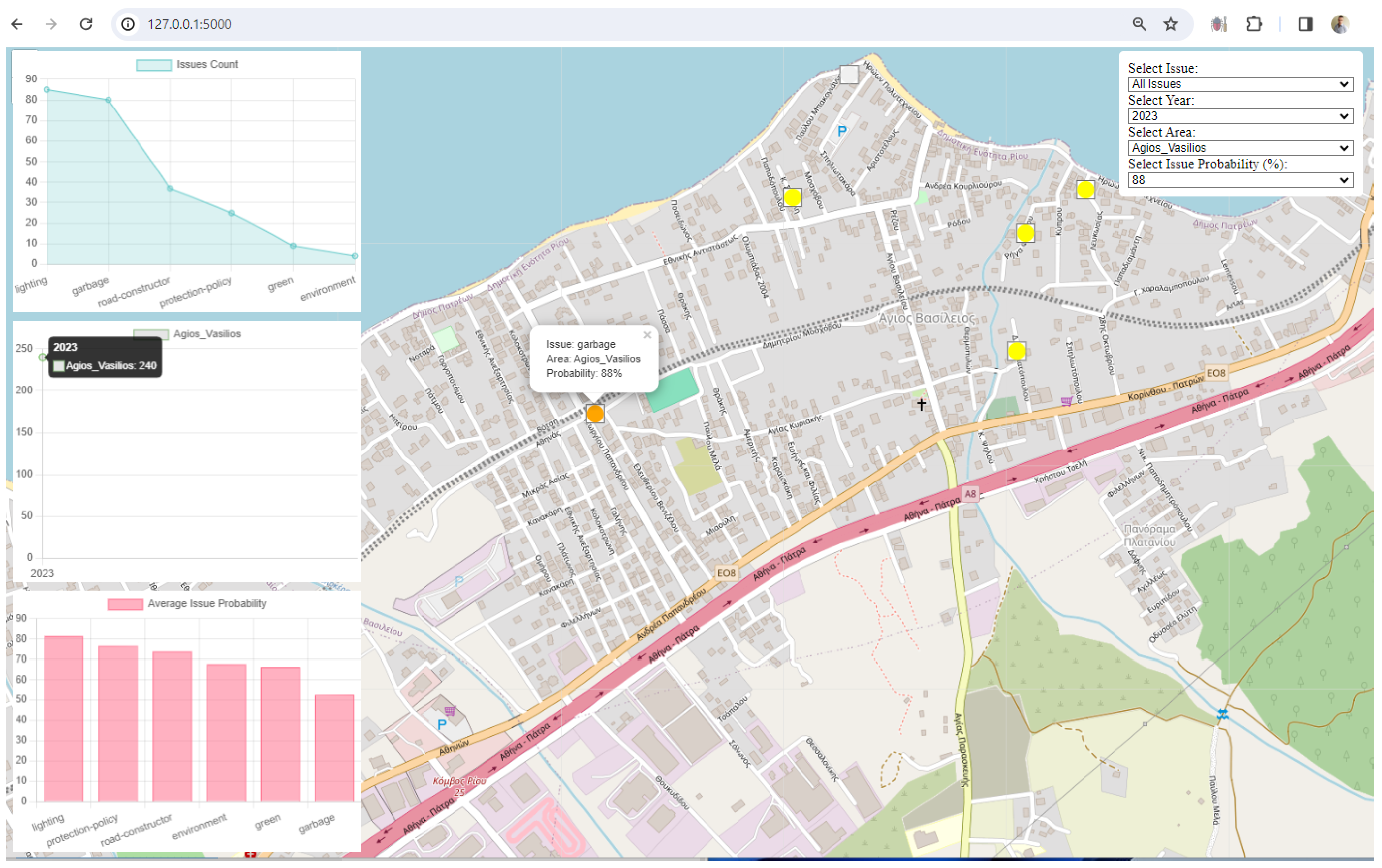
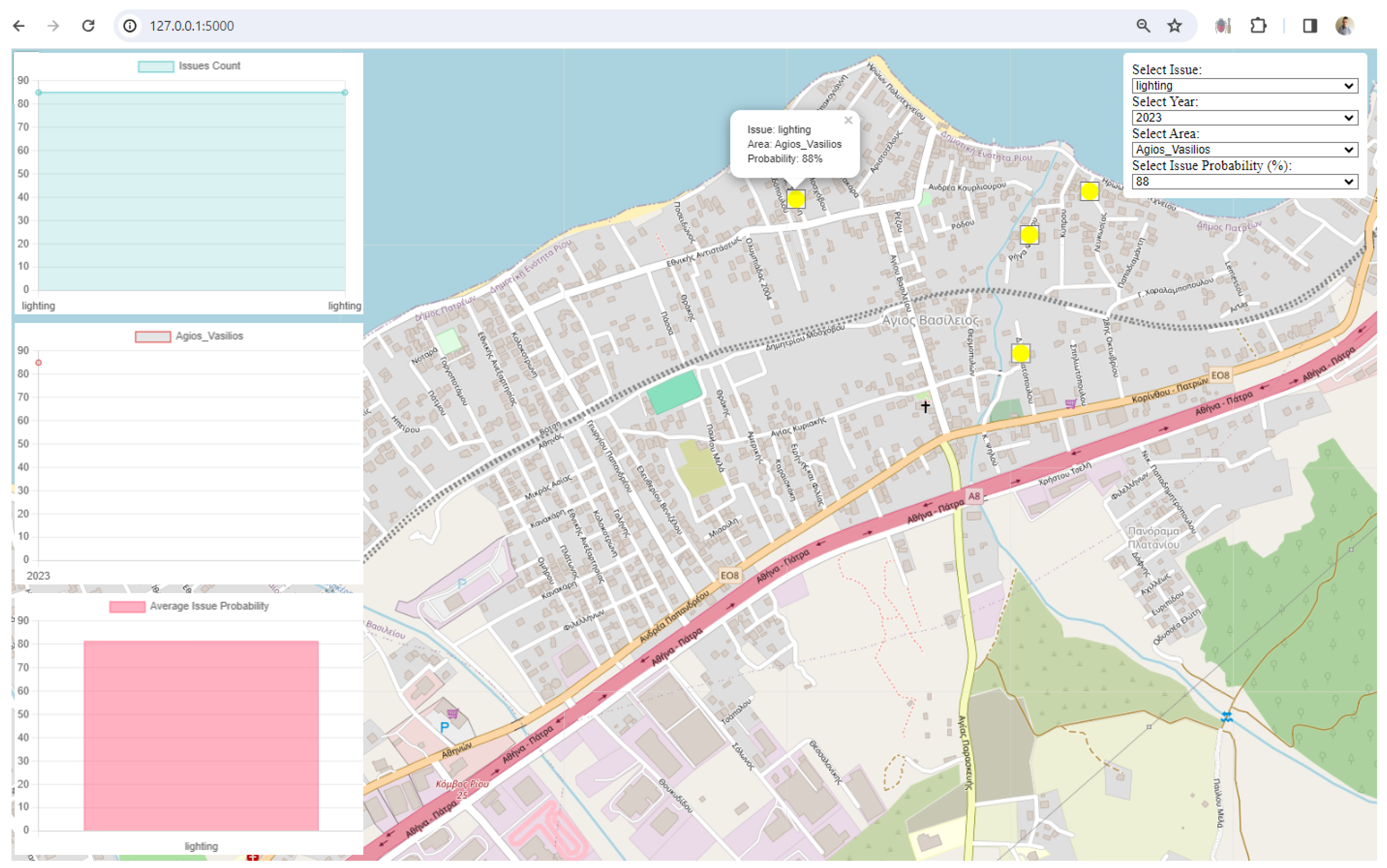
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
# Simplified Flask Code with Data Lake Processing and Output
from flask import Flask, render_template, jsonify
import pandas as pd
import json
app = Flask(__name__)
# Function to load processed data from an output CSV
def load_data_from_processed_csv(csv_path):
try:
# Load data from the CSV file
data = pd.read_csv(csv_path)
return data
except Exception as e:
print(f"Error loading data from CSV: {str(e)}")
return pd.DataFrame()
# Extract unique values for filters
def get_unique_values(data):
unique_years = data['year'].unique().tolist()
unique_areas = data['Areas'].unique().tolist()
unique_issues = data['issue'].unique().tolist()
unique_issue_Probability = data['issue_Probability'].unique().tolist()
return unique_years, unique_areas, unique_issues, unique_issue_Probability
# Route to serve the main page
@app.route('/')
def index():
try:
# Set the path to the processed CSV file from the data lake
csv_path = r"G:\DataLake\processed_data_output.csv"
# Load data from the processed CSV file
digital_twin_data = load_data_from_processed_csv(csv_path)
# Check if data is empty
if digital_twin_data.empty:
return render_template('index.html', issues='[]', unique_issue_Probability='[]')
# Get unique values for filters
unique_years, unique_areas, unique_issues, unique_issue_Probability = get_unique_values(digital_twin_data)
# Convert DataFrame to a list of dictionaries and handle NaN values
data_list = digital_twin_data.replace({pd.NaT: None}).to_dict(orient='records')
# Pass data to the HTML template
return render_template('index.html', issues=json.dumps(data_list), unique_issue_Probability=list(map(int, unique_issue_Probability)))
except Exception as e:
print(f"Error processing data: {str(e)}")
# Pass empty arrays if an error occurs
return render_template('index.html', issues='[]', unique_issue_Probability='[]')
# Run the Flask app
if __name__ == '__main__':
app.run(debug=True)
<!DOCTYPE html>
<html lang="en">
<head>
<!-- Head content including title, CSS, and scripts -->
<title>The Title</title>
<!-- Include CSS styles -->
<!-- Include Leaflet and Chart.js libraries -->
<script src="https://unpkg.com/[email protected]/dist/leaflet.js"></script>
<script src="https://unpkg.com/[email protected]/dist/leaflet.markercluster.js"></script>
<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>
</head>
<body>
<div id="map"></div>
<div id="chartContainer1">
<!-- Chart container for Issue Count -->
</div>
<div id="chartContainer2">
<!-- Chart container for Area Count -->
</div>
<div id="filters">
<!-- Filters container including Issue, Year, Area, and Issue Probability filters -->
</div>
<div id="chartContainer3">
<!-- Chart container for Average Issue Probability -->
</div>
<!-- Include the custom JavaScript code for initializing the map and charts, handling filters, and updating data -->
<script>
// JavaScript code for initializing the map and charts, handling filters, and updating data
var issues = {{ issues|safe }};
var uniqueIssueProbability = {{ unique_issue_Probability|safe }};
// Use the 'issues' and 'uniqueIssueProbability' variables to initialize your charts and map
// Example: Initialize a chart using Chart.js
var ctx = document.getElementById('chartContainer1').getContext('2d');
var myChart = new Chart(ctx, {
type: 'bar',
data: {
labels: ['Label1', 'Label2', 'Label3'],
datasets: [{
label: 'Issues Count',
data: [10, 20, 30],
backgroundColor: 'rgba(75, 192, 192, 0.2)',
borderColor: 'rgba(75, 192, 192, 1)',
borderWidth: 1
}]
}
});
// Example: Initialize a map using Leaflet
var map = L.map('map').setView([51.505, -0.09], 13);
L.tileLayer('https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', {
attribution: '© OpenStreetMap contributors'
}).addTo(map);
// Add markers to the map based on 'issues' data
// The additional JavaScript code for handling filters and updating data
</script>
</body>
</html>
Appendix B





















References
- Weil, C.; Bibri, S.E.; Longchamp, R.; Golay, F.; Alahi, A. Urban Digital Twin Challenges: A Systematic Review and Perspectives for Sustainable Smart Cities. Sustain. Cities Soc. 2023, 99, 104862. [Google Scholar] [CrossRef]
- Deng, T.; Zhang, K.; Shen, Z.-J. A systematic review of a digital twin city: A new pattern of urban governance toward smart cities. J. Manag. Sci. Eng. 2021, 6, 125–134. [Google Scholar] [CrossRef]
- Wolf, K.; Dawson, R.J.; Mills, J.P.; Blythe, P.; Morley, J. Towards a digital twin for supporting multi-agency incident management in a smart city. Sci. Rep. 2022, 12, 16221. [Google Scholar] [CrossRef]
- Gkontzis, A.F.; Kalles, D.; Paxinou, E.; Tsoni, R.; Verykios, V.S. A Big Data Analytics Conceptual Framework for a Smart City: A Case Study. In Building on Smart Cities Skills and Competences; Internet of Things; Fitsilis, P., Ed.; Springer: Cham, Swizterland, 2022. [Google Scholar] [CrossRef]
- Salamanis, A.I.; Gravvanis, G.A.; Kotsiantis, S.B.; Vrahatis, M.N. Novel Sparse Feature Regression Method for Traffic Forecasting. Int. J. Artif. Intell. Tools 2023, 32, 2350008. [Google Scholar] [CrossRef]
- White, G.; Zink, A.; Codecá, L.; Clarke, S. A digital twin smart city for citizen feedback. Cities 2021, 110, 103064. [Google Scholar] [CrossRef]
- Najafi, P.; Mohammadi, M.; Wesemael, P.; Le Blanc, P.M. A user-centred virtual city information model for inclusive community design: State-of-art. Cities 2023, 134, 104203. [Google Scholar] [CrossRef]
- Abdeen, F.N.; Shirowzhan, S.; Sepasgozar, S.M.E. Citizen-centric digital twin development with machine learning and interfaces for maintaining urban infrastructure. Telemat. Inform. 2023, 84, 102032. [Google Scholar] [CrossRef]
- Jeddoub, I.; Nys, G.-A.; Hajji, R.; Billen, R. Digital Twins for cities: Analyzing the gap between concepts and current implementations with a specific focus on data integration. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103440. [Google Scholar] [CrossRef]
- Xia, H.; Liu, Z.; Efremochkina, M.; Liu, X.; Lin, C. Study on city digital twin technologies for sustainable smart city design: A review and bibliometric analysis of geographic information system and building information modeling integration. Sustain. Cities Soc. 2022, 84, 104009. [Google Scholar] [CrossRef]
- Bonney, M.S.; de Angelis, M.; Dal Borgo, M.; Andrade, L.; Beregi, S.; Jamia, N.; Wagg, D.J. Development of a digital twin operational platform using Python Flask. Data-Centric Eng. 2022, 3, e1. [Google Scholar] [CrossRef]
- Casali, Y.; Aydin, N.Y.; Comes, T. Machine learning for spatial analyses in urban areas: A scoping review. Sustain. Cities Soc. 2022, 85, 104050. [Google Scholar] [CrossRef]
- Omar, A.; Delnaz, A.; Nik-Bakht, M. Comparative analysis of machine learning techniques for predicting water main failures in the City of Kitchener. J. Infrastruct. Intell. Resil. 2023, 2, 100044. [Google Scholar] [CrossRef]
- Ariyachandra, M.F.; Wedawatta, G. Digital Twin Smart Cities for Disaster Risk Management: A Review of Evolving Concepts. Sustainability 2023, 15, 11910. [Google Scholar] [CrossRef]
- Martí, P.; Serrano-Estrada, L.; Nolasco-Cirugeda, A. Social Media data: Challenges, opportunities and limitations in urban studies. Comput. Environ. Urban Syst. 2019, 74, 161–177. [Google Scholar] [CrossRef]
- Hu, A.; Yabuki, N.; Fukuda, T.; Kaga, H.; Takeda, S.; Matsuo, K. Harnessing multiple data sources and emerging technologies for comprehensive urban green space evaluation. Cities 2023, 143, 104562. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, X.; Li, N. Zooming into mobility to understand cities: A review of mobility-driven urban studies. Cities 2022, 130, 103939. [Google Scholar] [CrossRef]
- Chen, Z.; Chan, I.C.C. Smart cities and quality of life: A quantitative analysis of citizens’ support for smart city development. Inf. Technol. People 2023, 36, 263–285. [Google Scholar] [CrossRef]
- Wirtz, B.W.; Müller, W.M.; Schmidt, F.W. Digital Public Services in Smart Cities—An Empirical Analysis of Lead User Preferences. Public Organ. Rev. 2021, 21, 299–315. [Google Scholar] [CrossRef]
- Wirtz, B.W.; Becker, M.; Schmidt, F.W. Smart city services: An empirical analysis of citizen preferences. Public Organ. Rev. 2022, 22, 1063–1080. [Google Scholar] [CrossRef]
- Li, W.; Feng, T.; Timmermans, H.J.P.; Li, Z.; Zhang, M.; Li, B. Analysis of citizens’ motivation and participation intention in urban planning. Cities 2020, 106, 102921. [Google Scholar] [CrossRef]
- Allen, B.; Tamindael, L.E.; Bickerton, S.H.; Cho, W. Does citizen coproduction lead to better urban services in smart cities projects? An empirical study on e-participation in a mobile big data platform. Gov. Inf. Q. 2020, 37, 101412. [Google Scholar] [CrossRef]
- Oh, J. Smart City as a Tool of Citizen-Oriented Urban Regeneration: Framework of Prelim-inary Evaluation and Its Application. Sustainability 2020, 12, 6874. [Google Scholar] [CrossRef]
- Savastano, M.; Suciu, M.-C.; Gorelova, I.; Stativă, G.A. How smart is mobility in smart cities? An analysis of citizens’ value perceptions through ICT applications. Cities 2023, 132, 104071. [Google Scholar] [CrossRef]
- Noori, N.; Hoppe, T.; Jong, M.D.; Stamhuis, E. Transplanting good practices in Smart City development: A step-wise approach. Gov. Inf. Q. 2023, 40, 101802. [Google Scholar] [CrossRef]
- Bala, M.; Boussaid, O.; Alimazighi, Z. A Fine-Grained Distribution Approach for ETL Processes in Big Data Environments. Data Knowl. Eng. 2017, 111, 114–136. [Google Scholar] [CrossRef]
- Alexandropoulos, S.-A.N.; Kotsiantis, S.B.; Vrahatis, M.N. Data preprocessing in predictive data mining. Knowl. Eng. Rev. 2019, 34, e1. [Google Scholar] [CrossRef]
- Gkontzis, A.F.; Kontsiantis, S.; Kalles, D.; Panagiotakopoulos, C.T.; Verykios, V.S. Polarity, Emotions, and Online Activity of Students and Tutors as Features in Predicting Grades. Int. J. Intell. Decis. Technol. 2020, 14, 409–436. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
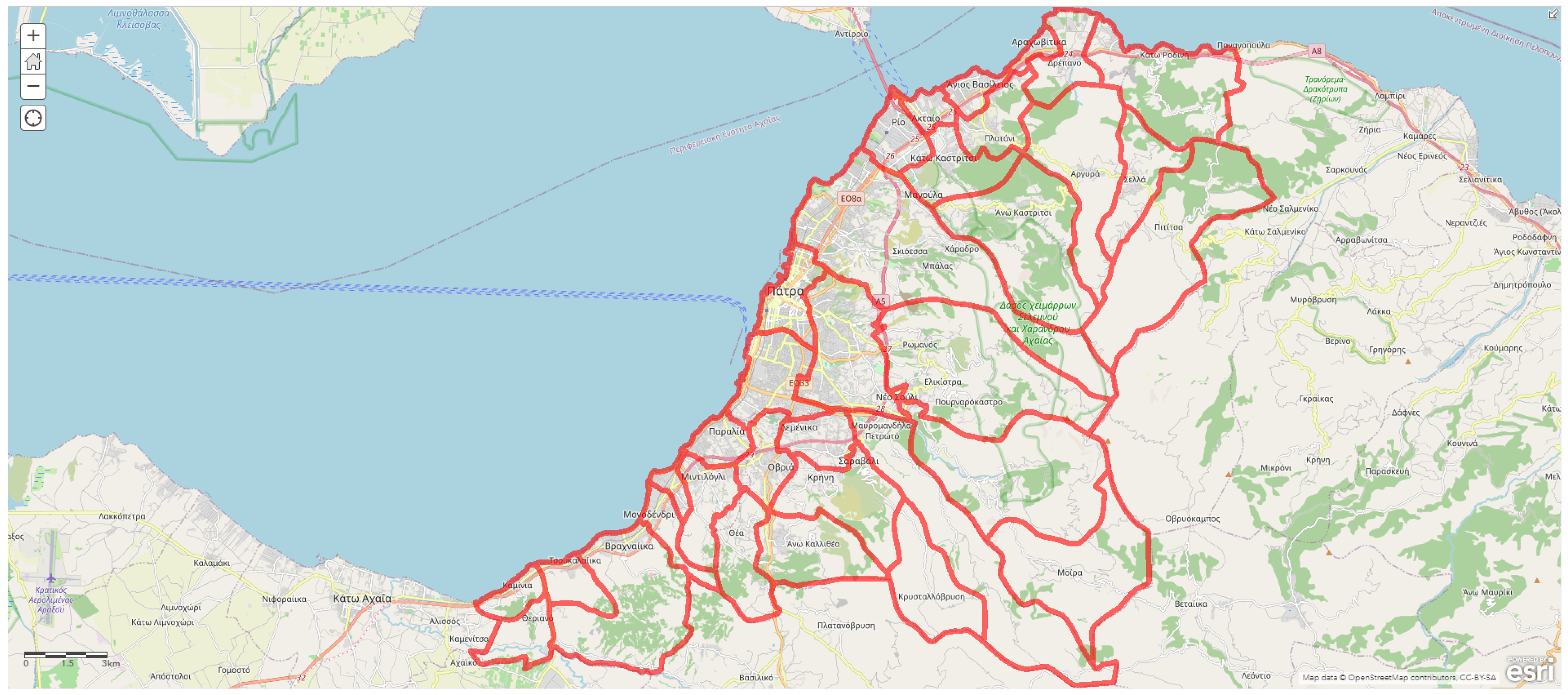{kind=link}
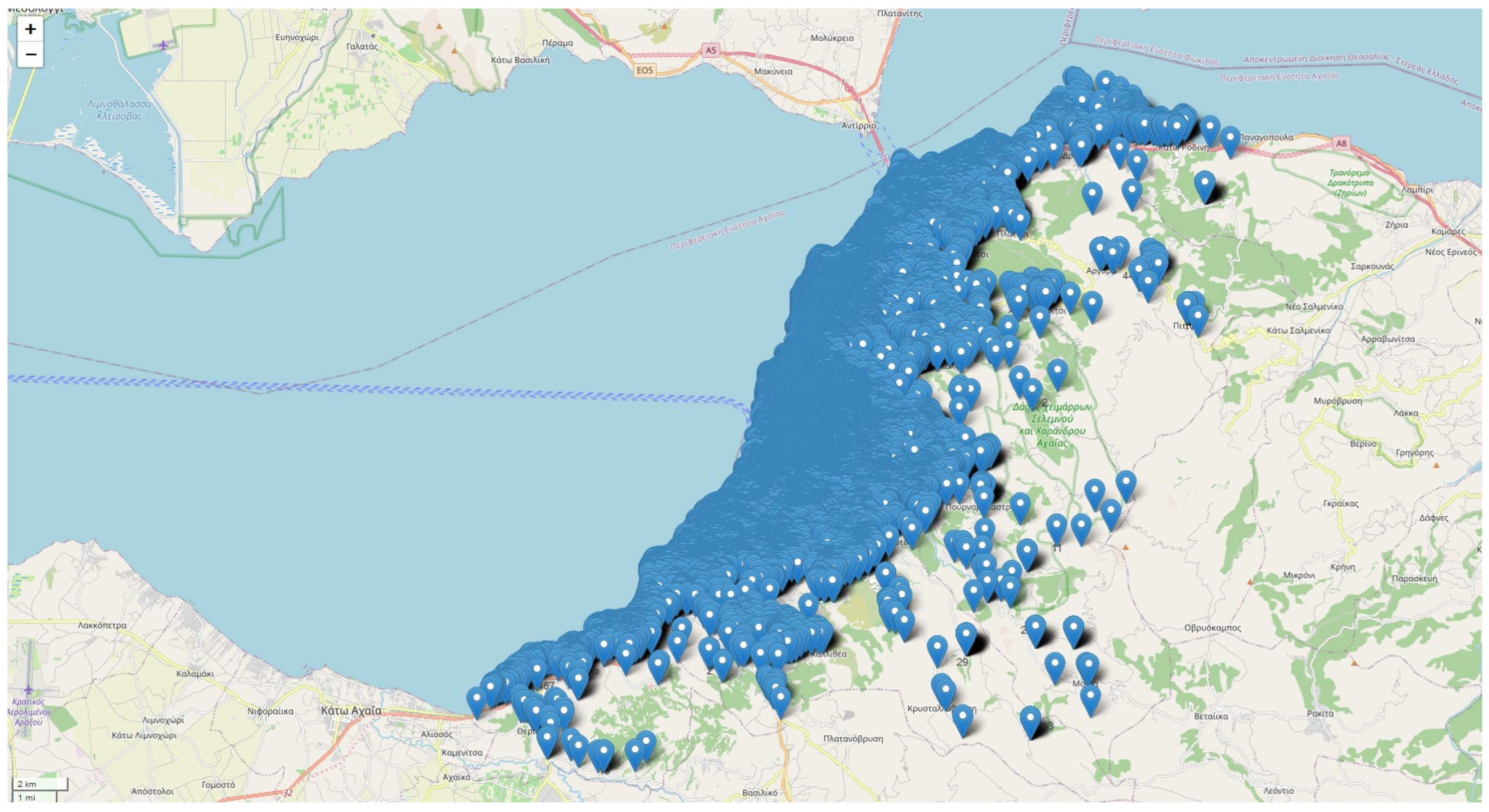{kind=link}
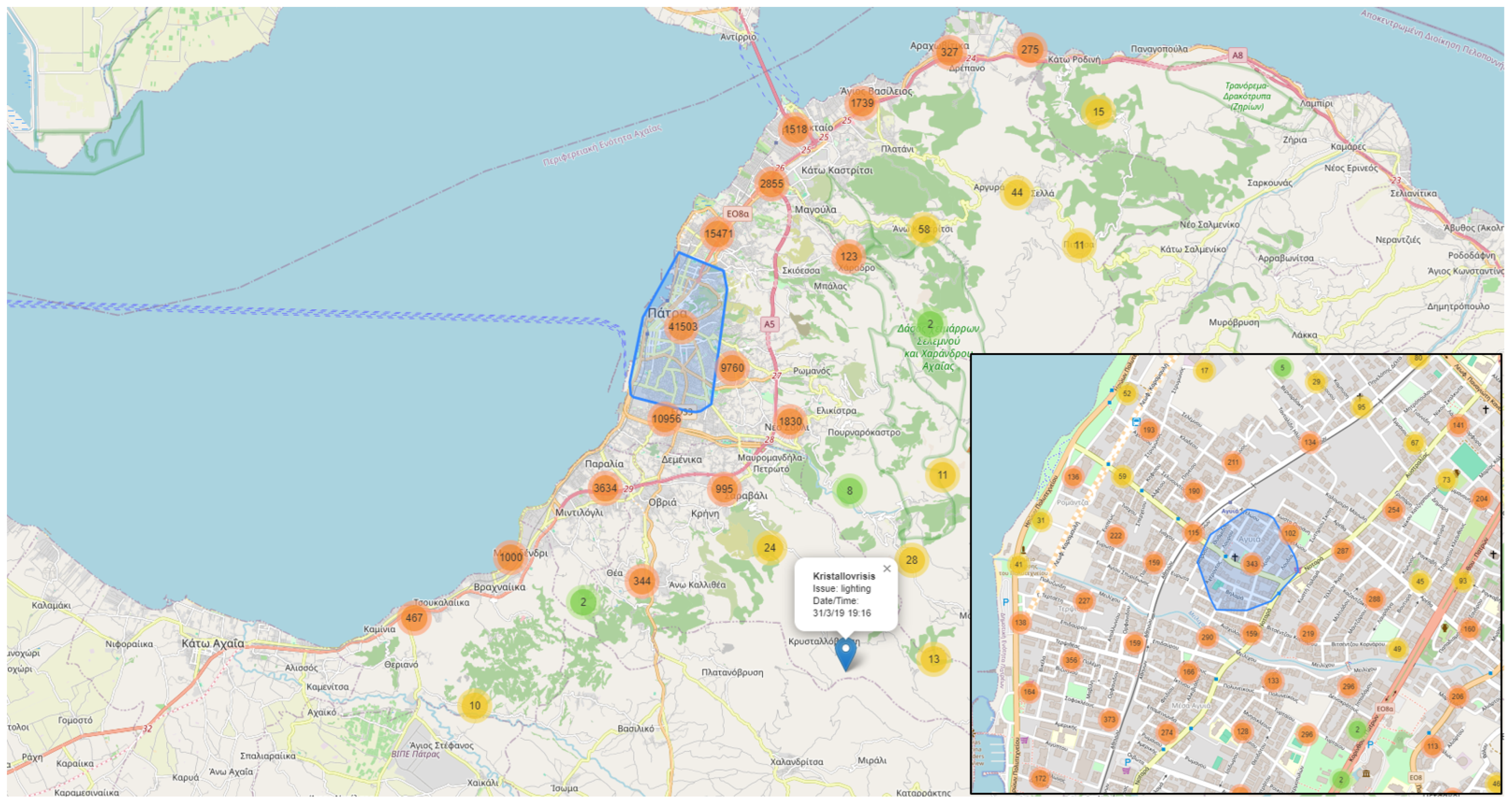{kind=link}
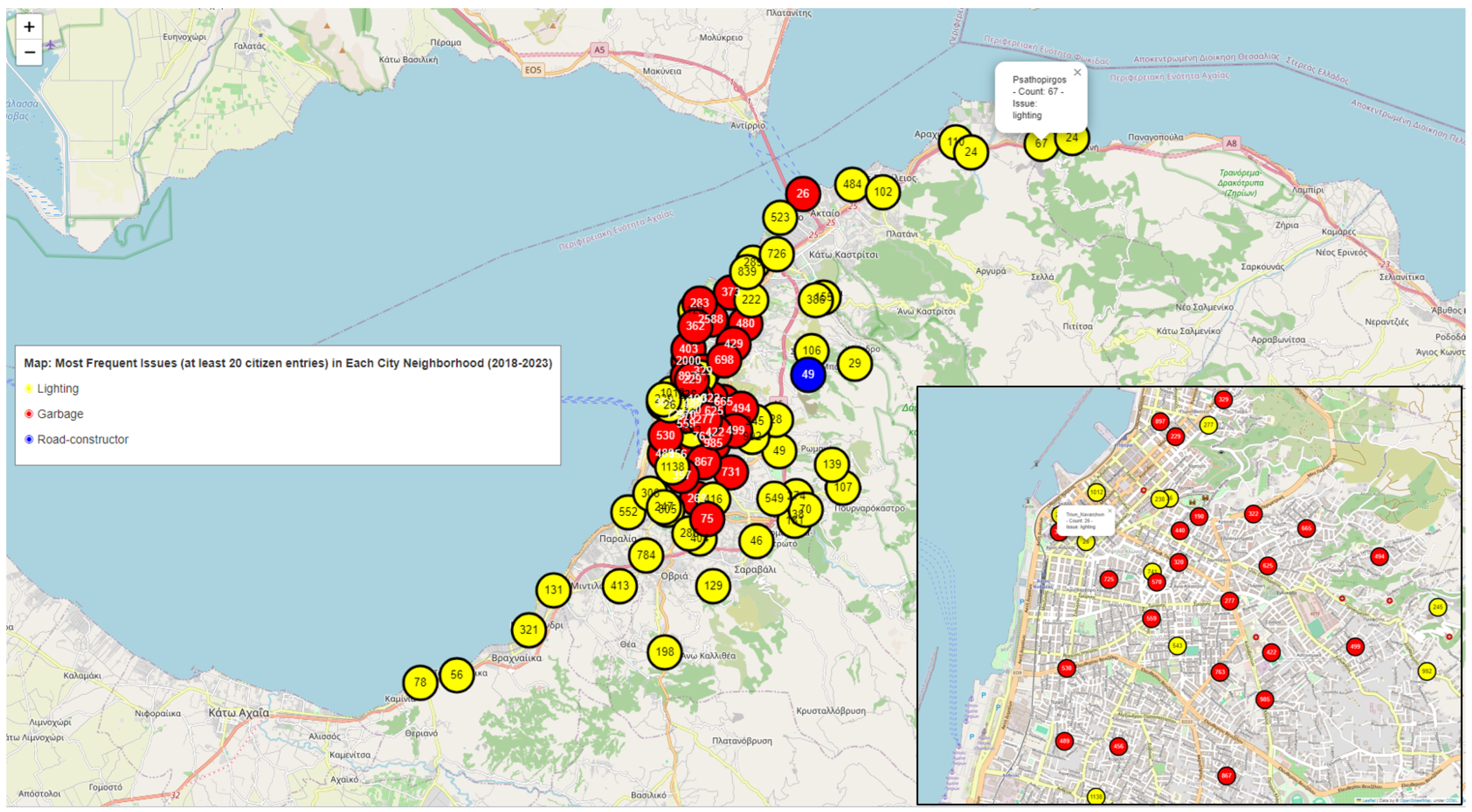{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| stat_report[numeric_cols] = stat_report[numeric_cols].applymap(lambda x: f”{int(x) if pd.notna(x) else ‘‘}”) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Latitude | Longitude | Areas | Areas_Int | Issue | Issue_Int | Reported_Date_Time | Year | Month | Day | Hour | Minute | Issue_Probability | |
| count | 93,053 | 93,053 | 93,043 | 93,053 | 93,053 | 93,053 | 93,053 | 93,053 | 93,053 | 93,053 | 93,053 | 93,053 | 93,053 |
| unique | 162 | 8 | 89,003 | ||||||||||
| top | Agyia | garbage | 14/10/2019 | 7:32:00 | |||||||||
| freq | 5881 | 31,836 | 4 | ||||||||||
| mean | 38 | 21 | NaN | 90 | NaN | 2 | nan | 2020 | 6 | 15 | 10 | 29 | 69 |
| std | 0 | 0 | NaN | 53 | NaN | 1 | nan | 1 | 3 | 8 | 4 | 17 | 17 |
| min | 38 | 21 | NaN | 1 | NaN | 1 | nan | 2018 | 1 | 1 | 0 | 0 | 23 |
| 25% | 38 | 21 | NaN | 41 | NaN | 1 | nan | 2019 | 4 | 8 | 7 | 15 | 57 |
| 50% | 38 | 21 | NaN | 89 | NaN | 2 | nan | 2021 | 7 | 16 | 9 | 30 | 72 |
| 75% | 38 | 21 | NaN | 144 | NaN | 4 | nan | 2022 | 9 | 23 | 12 | 45 | 84 |
| max | 38 | 21 | NaN | 171 | NaN | 8 | nan | 2023 | 12 | 31 | 23 | 59 | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gkontzis, A.F.; Kotsiantis, S.; Feretzakis, G.; Verykios, V.S. Enhancing Urban Resilience: Smart City Data Analyses, Forecasts, and Digital Twin Techniques at the Neighborhood Level. Future Internet 2024, 16, 47. https://doi.org/10.3390/fi16020047
Gkontzis AF, Kotsiantis S, Feretzakis G, Verykios VS. Enhancing Urban Resilience: Smart City Data Analyses, Forecasts, and Digital Twin Techniques at the Neighborhood Level. Future Internet. 2024; 16(2):47. https://doi.org/10.3390/fi16020047
Chicago/Turabian StyleGkontzis, Andreas F., Sotiris Kotsiantis, Georgios Feretzakis, and Vassilios S. Verykios. 2024. "Enhancing Urban Resilience: Smart City Data Analyses, Forecasts, and Digital Twin Techniques at the Neighborhood Level" Future Internet 16, no. 2: 47. https://doi.org/10.3390/fi16020047
APA StyleGkontzis, A. F., Kotsiantis, S., Feretzakis, G., & Verykios, V. S. (2024). Enhancing Urban Resilience: Smart City Data Analyses, Forecasts, and Digital Twin Techniques at the Neighborhood Level. Future Internet, 16(2), 47. https://doi.org/10.3390/fi16020047