

Optimizing Session-Aware Recommenders: A Deep Dive into GRU-Based Latent Interaction Integration


Abstract
:1. Introduction
- Innovative Combination: We combine GRU networks with attention mechanisms to enhance session-aware recommender systems, focusing on both short-term and long-term user preferences.
- Latent-Context GRU Model: Introducing the latent-context GRU model, a novel approach for capturing latent interaction information, demonstrating improved performance in session-aware recommendation tasks.
- Comprehensive Evaluation: Rigorous evaluation against current state-of-the-art methods provides a detailed analysis of its effectiveness and potential for further development.
2. Related Work
3. Proposed Method
3.1. Problem Statements
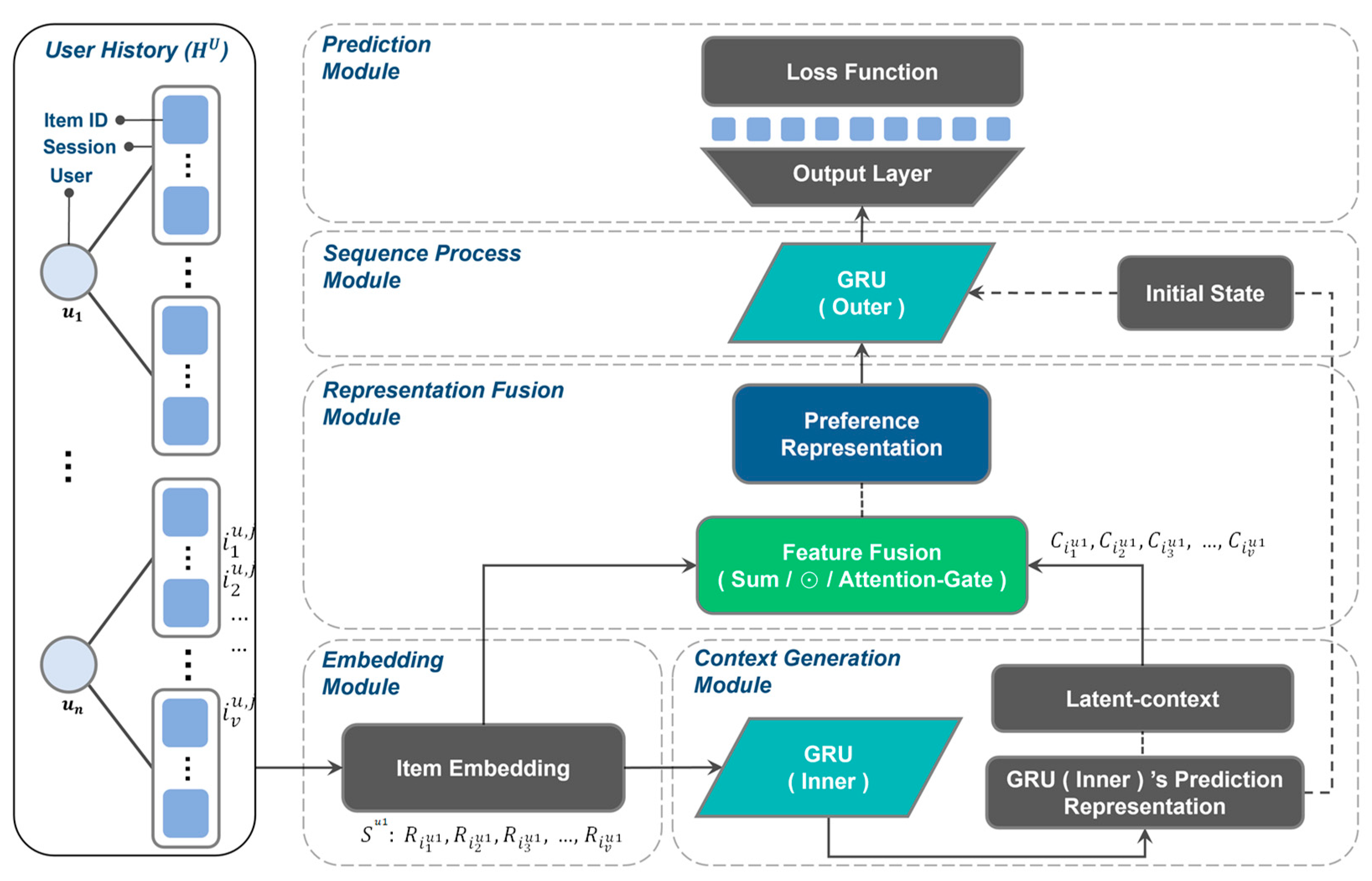
3.2. LCII Architecture
3.2.1. Embedding Module
3.2.2. Context Generation Module
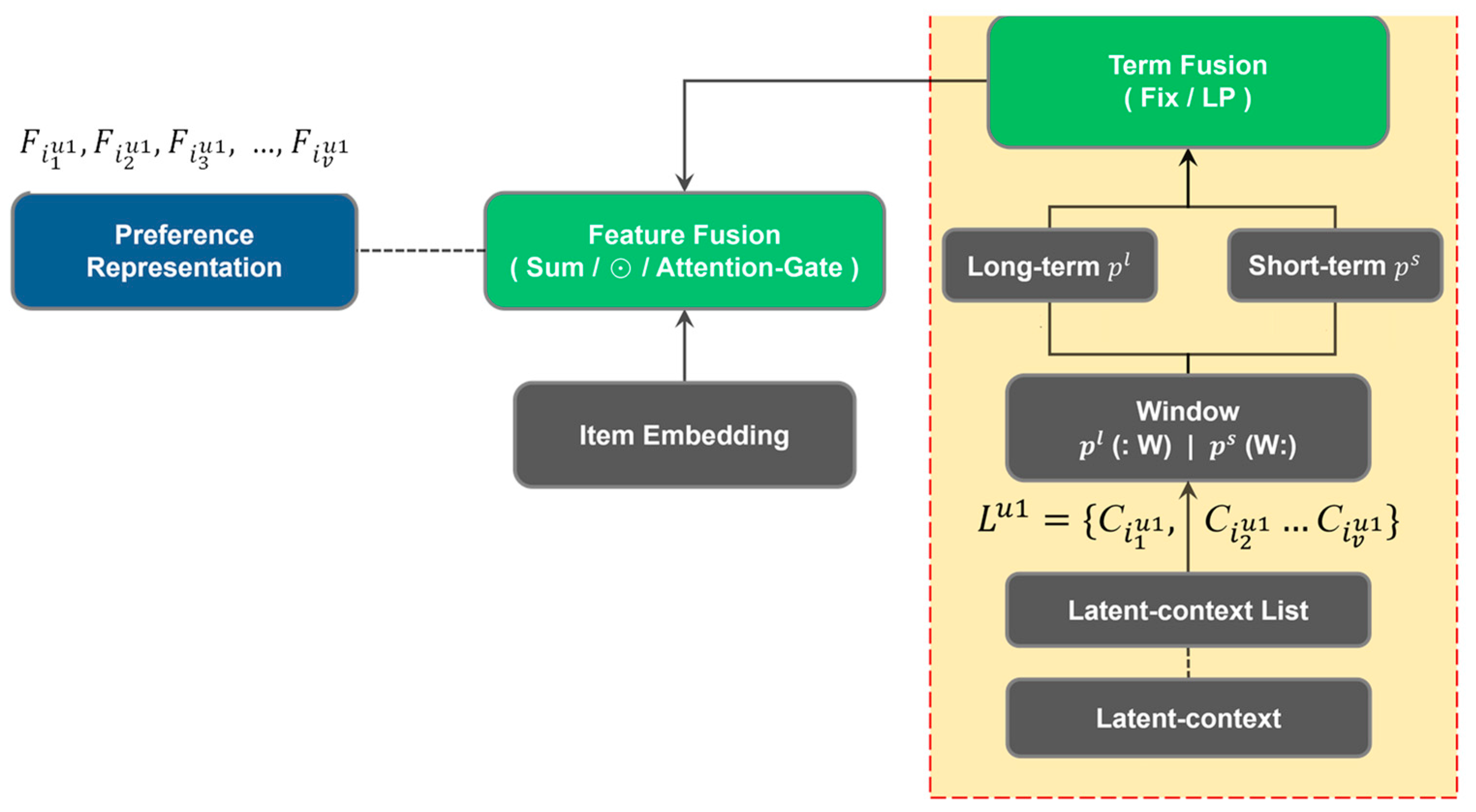
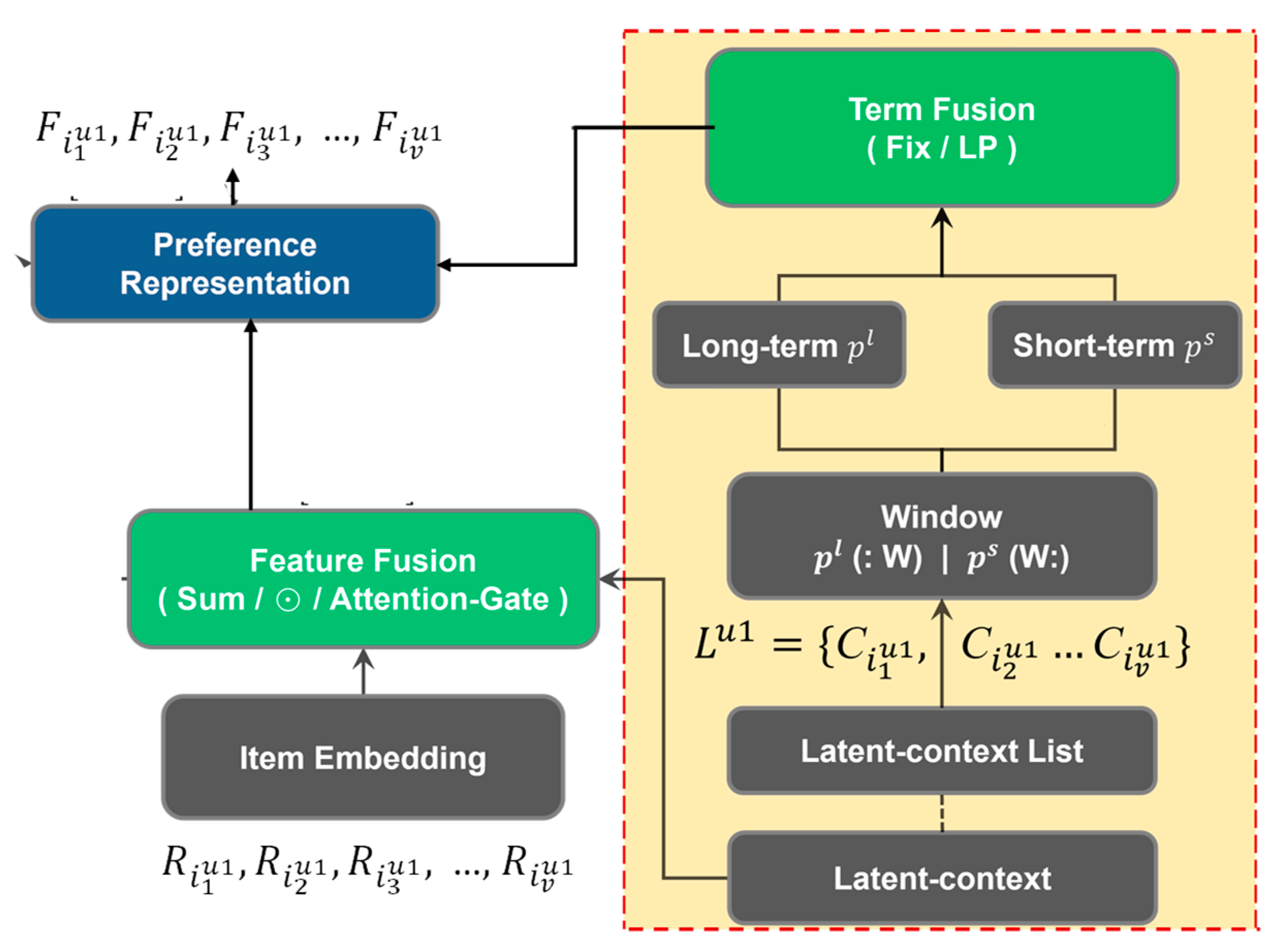
3.2.3. Representation Fusion Module
3.2.4. Sequence Processing Module
3.2.5. Prediction Module
4. Experimental Results
4.1. Datasets and Pre-Processing
4.2. Evaluation Metrics and Parameter Settings
4.3. Baseline Models
- Most-Popular: This is one of the most commonly used recommendation methods, which suggests the item that appears most frequently in each session.
- Item-kNN [12]: A prevalent recommendation method that relies on the scores generated by users’ ratings of items. It employs cosine similarity to recommend items with similar attributes.
- II-RNN [16]: This model is a session-aware model which leverages the architecture of inner and outer GRU as its primary framework for model learning.
- SASRec [23]: The method is based on the Transformer architecture. SASRec models the entire user sequence using a casual attention mask to consider item IDs for recommendations.
- MCLRec [27]: One of the latest studies of session recommendation based on contrastive learning.
4.4. Performance Comparisons
4.4.1. Performance of Different Feature Fusion Strategies
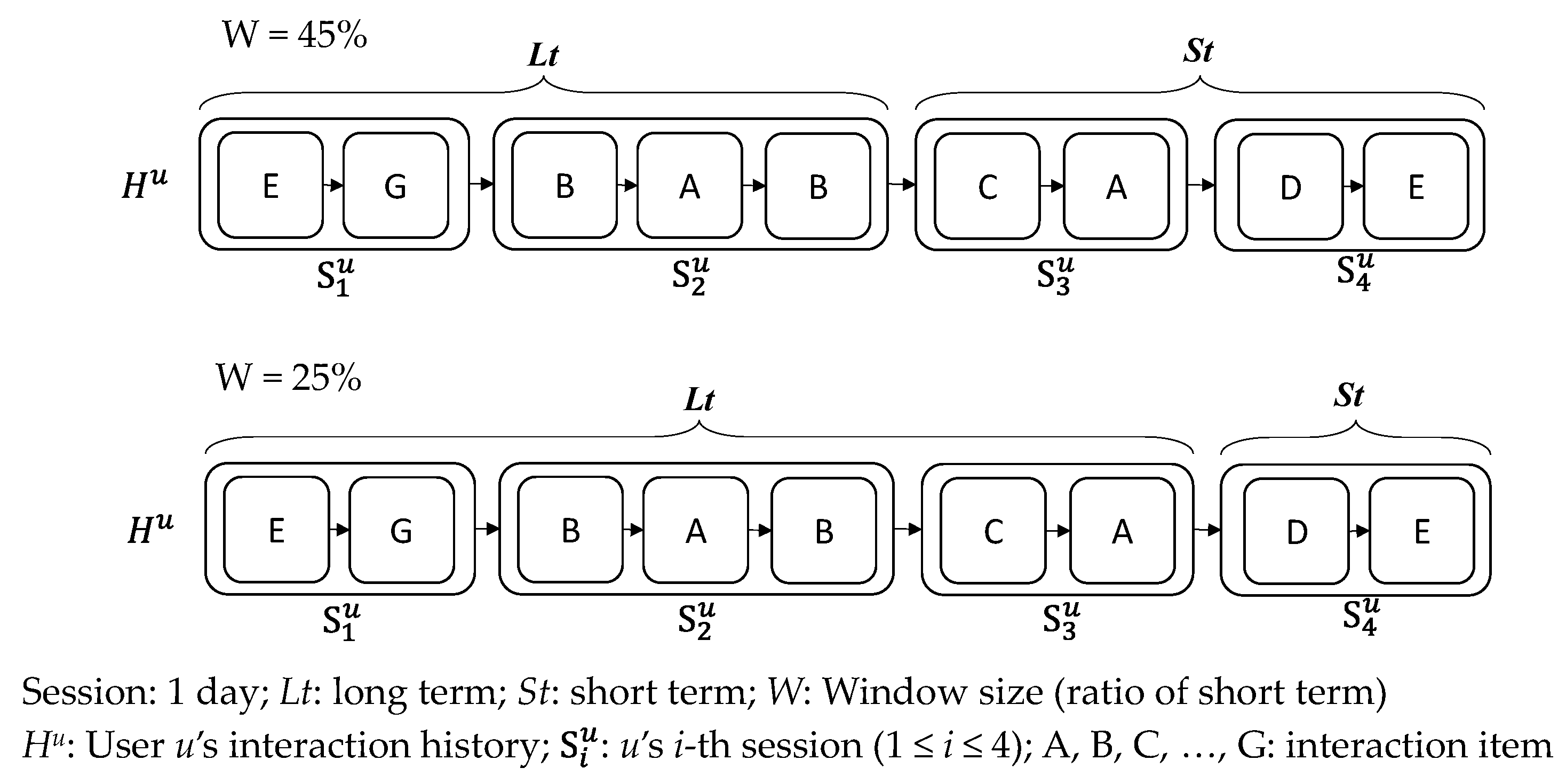
4.4.2. Performance of Different Windows
4.4.3. Long-Term and Short-Term Fixed Ratio Performance
4.4.4. Overall Comparisons
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cui, Q.; Wu, S.; Huang, Y.; Wang, L. A Hierarchical Contextual Attention-Based GRU Network for Sequential Recommendation. arXiv 2017, arXiv:1711.05114. Available online: https://arxiv.org/abs/1711.05114 (accessed on 23 September 2022).
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-Based Recommendations with Recurrent Neural Networks. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; Available online: https://arxiv.org/abs/1511.06939 (accessed on 20 October 2022).
- Hidasi, B.; Karatzoglou, A.; Quadrana, M.; Tikk, D. Parallel Recurrent Neural Network Architectures for Feature-rich Session-Based Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems (RecSys ‘16), Boston, MA, USA, 15–19 September 2016; pp. 241–248. [Google Scholar] [CrossRef]
- Hidasi, B.; Karatzoglou, A. Recurrent Neural Networks with Top-k Gains for Session-Based Recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM ‘18), Torino, Italy, 22–26 October 2018; pp. 843–853. [Google Scholar] [CrossRef]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural Attentive Session-Based Recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (CIKM ‘17), Singapore, 6–10 November 2017; pp. 1419–1428. [Google Scholar] [CrossRef]
- Song, W.; Wang, S.; Wang, Y.; Wang, S. Next-Item Recommendations in Short Sessions. In Proceedings of the 15th ACM Conference on Recommender Systems (RecSys ‘21), Amsterdam, The Netherlands, 27 September–1 October 2021; pp. 282–291. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, D.; Ling, Y.; Chen, H. A Joint Neural Network for Session-Aware Recommendation. IEEE Access 2020, 8, 74205–74215. [Google Scholar] [CrossRef]
- Gu, W.; Dong, S.; Zeng, Z. Increasing Recommended Effectiveness with Markov Chains and Purchase Intervals. Neural Comput. Appl. 2014, 25, 1153–1162. [Google Scholar] [CrossRef]
- Phuong, T.M.; Thanh, T.C.; Bach, N.X. Neural Session-Aware Recommendation. IEEE Access 2019, 7, 86884–86896. [Google Scholar] [CrossRef]
- Seol, J.J.; Ko, Y.; Lee, S.G. Exploiting Session Information in BERT-Based Session-Aware Sequential Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ‘22), Madrid, Spain, 11–15 July 2022; pp. 2639–2644. [Google Scholar] [CrossRef]
- Gu, G.Y.; Yanxiang, L.; Chen, H. A Neighbor-Guided Memory-Based Neural Network for Session-Aware Recommendation. IEEE Access 2020, 8, 120668–120678. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Reidl, J. Item-Based Collaborative Filtering Recommendation Algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon.com Recommendations: Item-To-Item Collaborative Filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef]
- Luo, X.; Zhou, M.; Li, S.; Shang, M. An Inherently Nonnegative Latent Factor Model for High-Dimensional and Sparse Matrices from Industrial Applications. IEEE Trans. Ind. Inform. 2018, 14, 2011–2022. [Google Scholar] [CrossRef]
- Luo, X.; Zhou, M.; Li, S.; Xia, Y.; You, Z.H.; Zhu, Q.; Leung, H. Incorporation of Efficient Second-Order Solvers Into Latent Factor Models for Accurate Prediction of Missing QoS Data. IEEE Trans. Cybern. 2018, 48, 1216–1228. [Google Scholar] [CrossRef] [PubMed]
- Ruocco, M.; Skrede, O.S.L.; Langseth, H. Inter-Session Modeling for Session-Based Recommendation. In Proceedings of the 2nd Workshop on Deep Learning for Recommender Systems (DLRS 2017), Como, Italy, 27 August 2017; pp. 24–31. [Google Scholar] [CrossRef]
- Hsueh, S.C.; Shih, M.S.; Lin, M.Y. Context Enhanced Recurrent Neural Network for Session-Aware Recommendation. In Proceedings of the 28th International Conference on Technologies and Applications of Artificial Intelligence, Yunlin, Taiwan, 1–2 December 2023. [Google Scholar]
- Barkan, O.; Koenigstein, N. ITEM2VEC: Neural Item Embedding for Collaborative Filtering. In Proceedings of the IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Cui, Q.; Wu, S.; Liu, Q.; Zhong, W.; Wang, L. MV-RNN: A Multi-View Recurrent Neural Network for Sequential Recommendation. IEEE Trans. Knowl. Data Eng. 2020, 32, 317–331. [Google Scholar] [CrossRef]
- Steam Dataset. Available online: https://cseweb.ucsd.edu/~jmcauley/datasets.html#steam_data (accessed on 20 October 2022).
- MovieLens Dataset. Available online: https://grouplens.org/datasets/movielens/ (accessed on 20 October 2022).
- Amazon Dataset. Available online: http://jmcauley.ucsd.edu/data/amazon (accessed on 20 October 2022).
- Kang, W.C.; McAuley, J. Self-Attentive Sequential Recommendation. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar] [CrossRef]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM ‘19), Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar] [CrossRef]
- Taylor, W.L. Cloze Procedure: A New Tool for Measuring Readability. J. Q. 1953, 30, 415–433. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Association for Computational Linguistics (NAACL), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Qin, X.; Yuan, H.; Zhao, P.; Fang, J.; Zhuang, F.; Liu, G.; Liu, G.; Sheng, V. Meta-optimized Contrastive Learning for Sequential Recommendation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’23), Taipei, Taiwan, 23–27 July 2023; pp. 89–98. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Set of items, ix is the item ID (1 ≤ x ≤ M) | |
| Set of users, uy is the user ID (1 ≤ y ≤ N) | |
| User u’s historical interactions, is the j-th session (1 ≤ y ≤ k) | |
| Interaction items in the j-th session, is the p-th item (1 ≤ p ≤ v) | |
| Embedding representation of item | |
| Latent context representation of interactions up to item | |
| Preference representation up to |
| Description | Amazon | MovieLens 1M | Steam |
|---|---|---|---|
| Number of users | 9733 | 1196 | 6330 |
| Number of items | 46,959 | 3328 | 4332 |
| Number of actions | 700,960 | 158,498 | 49,164 |
| Feature Fusion | Recall @5 | MRR @5 | NDCG @5 | Recall @10 | MRR @10 | NDCG @10 | Recall @20 | MRR @20 | NDCG @20 |
|---|---|---|---|---|---|---|---|---|---|
| Sum | 0.2313 | 0.2208 | 0.1973 | 0.2339 | 0.2212 | 0.2132 | 0.2369 | 0.2214 | 0.2164 |
| Element-wise Multiplication | 0.2393 | 0.2194 | 0.2043 | 0.2475 | 0.2205 | 0.2224 | 0.2545 | 0.2210 | 0.2270 |
| Attention-Gate | 0.2407 | 0.2157 | 0.2060 | 0.2487 | 0.2168 | 0.2244 | 0.2553 | 0.2173 | 0.2300 |
| Window Size (%) | Recall @5 | MRR @5 | NDCG @5 | Recall @10 | MRR @10 | NDCG @10 | Recall @20 | MRR @20 | NDCG @20 |
|---|---|---|---|---|---|---|---|---|---|
| 20 | 0.2356 | 0.2118 | 0.2009 | 0.2448 | 0.2131 | 0.2200 | 0.2522 | 0.2136 | 0.2268 |
| 25 | 0.2364 | 0.2119 | 0.2015 | 0.2451 | 0.2131 | 0.2198 | 0.2537 | 0.2137 | 0.2269 |
| 30 | 0.2343 | 0.2118 | 0.2009 | 0.2433 | 0.2130 | 0.2190 | 0.2512 | 0.2136 | 0.2263 |
| 35 | 0.2340 | 0.2098 | 0.2002 | 0.2434 | 0.2111 | 0.2190 | 0.2523 | 0.2117 | 0.2266 |
| 40 | 0.2357 | 0.2118 | 0.2008 | 0.2455 | 0.2131 | 0.2197 | 0.2540 | 0.2137 | 0.2275 |
| 45 | 0.2356 | 0.2111 | 0.2013 | 0.2454 | 0.2124 | 0.2200 | 0.2534 | 0.2130 | 0.2274 |
| 50 | 0.2357 | 0.2120 | 0.2014 | 0.2447 | 0.2133 | 0.2198 | 0.2526 | 0.2138 | 0.2262 |
| 55 | 0.2366 | 0.2117 | 0.2009 | 0.2455 | 0.2128 | 0.2198 | 0.2532 | 0.2134 | 0.2272 |
| 60 | 0.2359 | 0.2132 | 0.2014 | 0.2445 | 0.2143 | 0.2205 | 0.2524 | 0.2149 | 0.2274 |
| 65 | 0.2365 | 0.2134 | 0.2017 | 0.2451 | 0.2145 | 0.2206 | 0.2517 | 0.2150 | 0.2271 |
| 70 | 0.2357 | 0.2122 | 0.2013 | 0.2446 | 0.2134 | 0.2201 | 0.2521 | 0.2139 | 0.2268 |
| 75 | 0.2344 | 0.2100 | 0.2008 | 0.2429 | 0.2111 | 0.2191 | 0.2527 | 0.2118 | 0.2274 |
| 80 | 0.2344 | 0.2115 | 0.2011 | 0.2432 | 0.2127 | 0.2192 | 0.2519 | 0.2133 | 0.2262 |
| Model | Recall @5 | MRR @5 | NDCG @5 | Recall @10 | MRR @10 | NDCG @10 | Recall @20 | MRR @20 | NDCG @20 |
|---|---|---|---|---|---|---|---|---|---|
| Most-Popular | 0.0041 | 0.0022 | 0.0026 | 0.0075 | 0.0025 | 0.0039 | 0.0144 | 0.0030 | 0.0065 |
| Item-kNN | 0.2172 | 0.1796 | 0.1820 | 0.2239 | 0.1804 | 0.2044 | 0.2260 | 0.1806 | 0.2143 |
| II-RNN | 0.2238 | 0.2139 | 0.1926 | 0.2264 | 0.2143 | 0.2080 | 0.2294 | 0.2145 | 0.2117 |
| CAII-P | 0.2295 | 0.2115 | 0.1929 | 0.2342 | 0.2121 | 0.2081 | 0.2364 | 0.2123 | 0.2120 |
| SASRec | 0.0908 | - | 0.0821 | 0.1007 | - | 0.0853 | 0.1102 | - | 0.0877 |
| 0.1093 | - | 0.0900 | 0.1205 | - | 0.0936 | 0.1327 | - | 0.0967 | |
| 0.1231 | - | 0.1060 | 0.1343 | - | 0.1096 | 0.1409 | - | 0.1113 | |
| MCLRec | 0.1933 | - | 0.1601 | 0.1956 | - | 0.1597 | 0.1873 | - | 0.1534 |
| LCII | 0.2407 | 0.2157 | 0.2060 | 0.2487 | 0.2168 | 0.2244 | 0.2553 | 0.2173 | 0.2300 |
| LCII- | 0.2360 | 0.2064 | 0.2017 | 0.2450 | 0.2077 | 0.2204 | 0.2529 | 0.2082 | 0.2275 |
| LCII- | 0.2368 | 0.2119 | 0.2019 | 0.2467 | 0.2133 | 0.2219 | 0.2538 | 0.2138 | 0.2281 |
| LCII- | 0.2357 | 0.2127 | 0.2008 | 0.2446 | 0.2140 | 0.2205 | 0.2528 | 0.2145 | 0.2279 |
| LCII-PostFix | 0.2371 | 0.2147 | 0.2029 | 0.2442 | 0.2156 | 0.2212 | 0.2519 | 0.2162 | 0.2273 |
| Model | Recall @5 | MRR @5 | NDCG @5 | Recall @10 | MRR @10 | NDCG @10 | Recall @20 | MRR @20 | NDCG @20 |
|---|---|---|---|---|---|---|---|---|---|
| II-RNN | 0.4196 | 0.3955 | 0.3945 | 0.4401 | 0.3982 | 0.4158 | 0.4679 | 0.4001 | 0.4277 |
| SASRec | 0.4945 | - | 0.4160 | 0.5218 | - | 0.4675 | 0.5551 | - | 0.4760 |
| 0.4938 | - | 0.4622 | 0.5267 | - | 0.4729 | 0.5634 | - | 0.4820 | |
| 0.5423 | - | 0.5175 | 0.5692 | - | 0.5262 | 0.5995 | - | 0.5338 | |
| LCII | 0.5904 | 0.5353 | 0.5430 | 0.6192 | 0.5391 | 0.5778 | 0.6514 | 0.5414 | 0.5925 |
| LCII- | 0.5860 | 0.5329 | 0.5409 | 0.6151 | 0.5368 | 0.5745 | 0.6450 | 0.5388 | 0.5885 |
| LCII- | 0.5923 | 0.5360 | 0.5453 | 0.6200 | 0.5397 | 0.5805 | 0.6527 | 0.5420 | 0.5965 |
| LCII-PostLP | 0.5936 | 0.5364 | 0.5449 | 0.6240 | 0.5404 | 0.5807 | 0.6545 | 0.5426 | 0.5945 |
| LCII- | 0.5961 | 0.5410 | 0.5506 | 0.6232 | 0.5446 | 0.5837 | 0.6526 | 0.5466 | 0.5978 |
| Model | Recall @5 | MRR @5 | NDCG @5 | Recall @10 | MRR @10 | NDCG @10 | Recall @20 | MRR @20 | NDCG @20 |
|---|---|---|---|---|---|---|---|---|---|
| II-RNN | 0.1160 | 0.0632 | 0.0183 | 0.1761 | 0.0711 | 0.0440 | 0.2636 | 0.0770 | 0.0981 |
| SASRec | 0.0920 | - | 0.0553 | 0.1522 | - | 0.0747 | 0.2400 | - | 0.0968 |
| 0.0686 | - | 0.0409 | 0.1396 | - | 0.0637 | 0.2308 | - | 0.0866 | |
| 0.0870 | - | 0.0513 | 0.1472 | - | 0.0707 | 0.2567 | - | 0.0981 | |
| LCII | 0.1144 | 0.0598 | 0.0214 | 0.1809 | 0.0685 | 0.0501 | 0.2746 | 0.0749 | 0.1088 |
| LCII- | 0.0921 | 0.0467 | 0.0191 | 0.1518 | 0.0545 | 0.0442 | 0.2373 | 0.0604 | 0.0959 |
| LCII- | 0.1183 | 0.0624 | 0.0231 | 0.1852 | 0.0712 | 0.0527 | 0.2821 | 0.0778 | 0.1138 |
| LCII- | 0.0922 | 0.0479 | 0.0194 | 0.1483 | 0.0553 | 0.0433 | 0.2354 | 0.0612 | 0.0946 |
| LCII- | 0.1141 | 0.0606 | 0.0209 | 0.1800 | 0.0694 | 0.0482 | 0.2699 | 0.0755 | 0.1041 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, M.-Y.; Wu, P.-C.; Hsueh, S.-C. Optimizing Session-Aware Recommenders: A Deep Dive into GRU-Based Latent Interaction Integration. Future Internet 2024, 16, 51. https://doi.org/10.3390/fi16020051
Lin M-Y, Wu P-C, Hsueh S-C. Optimizing Session-Aware Recommenders: A Deep Dive into GRU-Based Latent Interaction Integration. Future Internet. 2024; 16(2):51. https://doi.org/10.3390/fi16020051
Chicago/Turabian StyleLin, Ming-Yen, Ping-Chun Wu, and Sue-Chen Hsueh. 2024. "Optimizing Session-Aware Recommenders: A Deep Dive into GRU-Based Latent Interaction Integration" Future Internet 16, no. 2: 51. https://doi.org/10.3390/fi16020051
APA StyleLin, M. -Y., Wu, P. -C., & Hsueh, S. -C. (2024). Optimizing Session-Aware Recommenders: A Deep Dive into GRU-Based Latent Interaction Integration. Future Internet, 16(2), 51. https://doi.org/10.3390/fi16020051