
Deterministic K-Identification for Future Communication Networks: The Binary Symmetric Channel Results †



{kind=link}
{kind=link}
{kind=link}
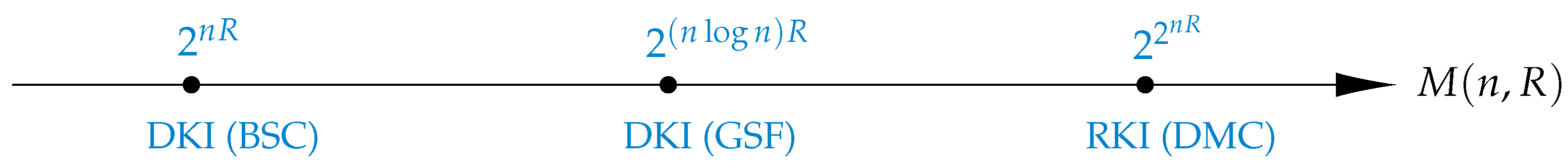{kind=link}
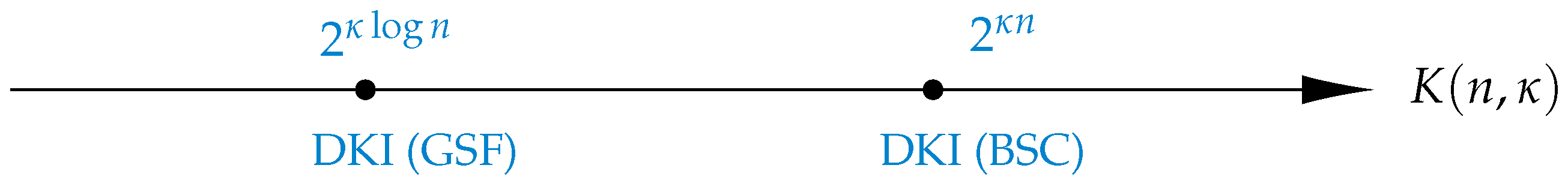{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Post-Shannon Communications for IoT
1.2. IoT Needs and Impact of the Deterministic K-Identification
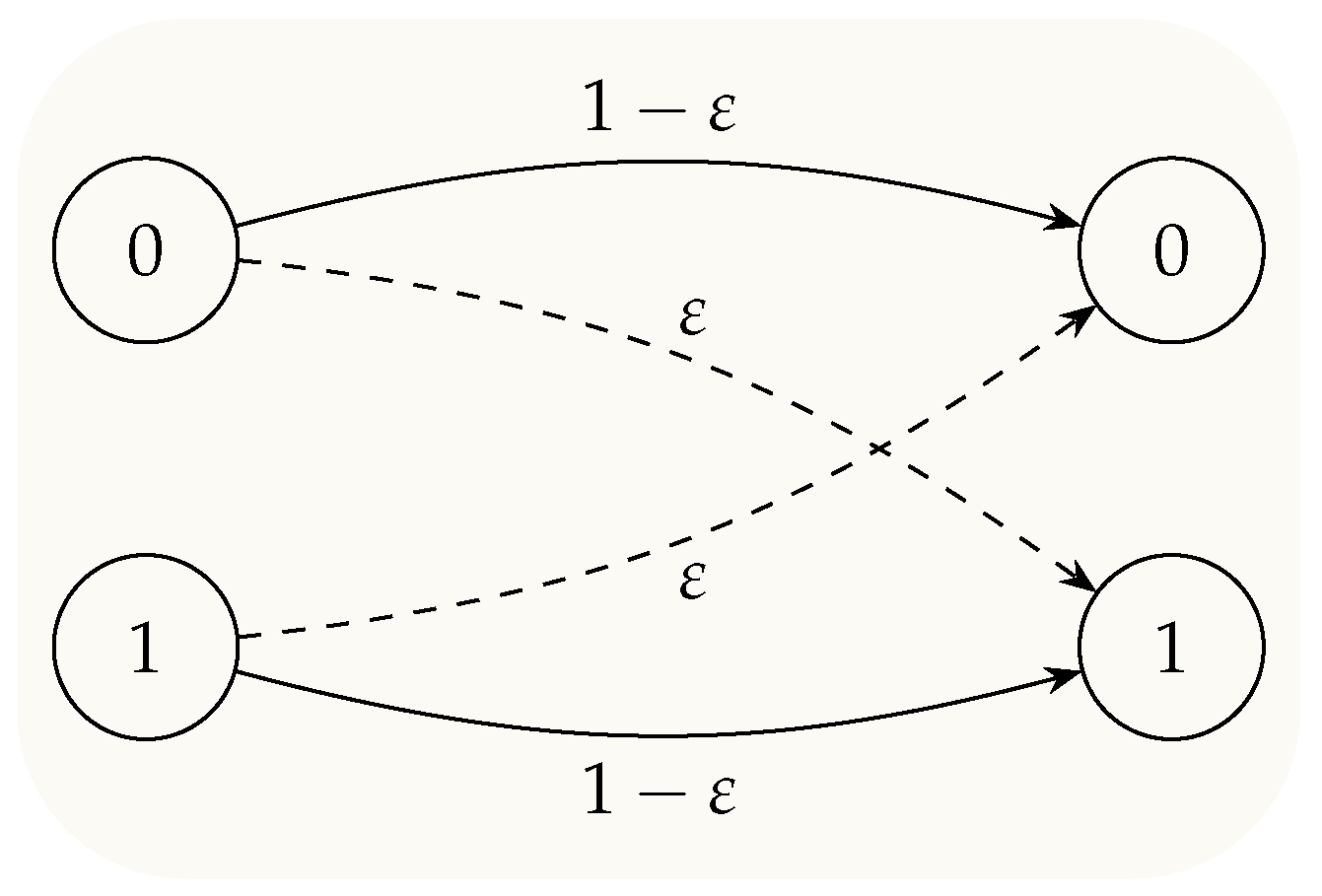
1.3. Binary Symmetric Channel
1.4. Information Theoretical Analysis of BSC-Based IoT Systems
1.5. Applications of the K-Identification Problem for IoT
1.6. Contributions
- ◊
- Generalized identification model: We examine the BSC, in which the size of the goal message set, K, may scale with the codeword length, n. As a consequence, this model incorporates the DI with , and DKI with constant 1. Therefore, we can confirm whether asymptotic codeword lengths allow for reliable identification, even when the goal message set grows in size, using our suggested generalized model. As far as is known by the authors’ knowledge, no previous research has been conducted on a generalized DKI model in the literature.
- ◊
- Codebook scale: We prove that, for K-identification over the BSC with deterministic encoding, the codebook size grows in n, similarly to that of the DI problem () [32,33] and the TR problem [17] over the same channel, namely exponentially in the codeword length n, i.e., ∼, where R is the DKI coding rate, even when the size of the goal message set grows exponentially in n, i.e., , where is the identification goal rate, and certain functions of the channel statistics and input restrictions set upper bounds on it. This result implies that one can extend the collection of goal messages for identification without compromising the codebook’s scalability.
- ◊
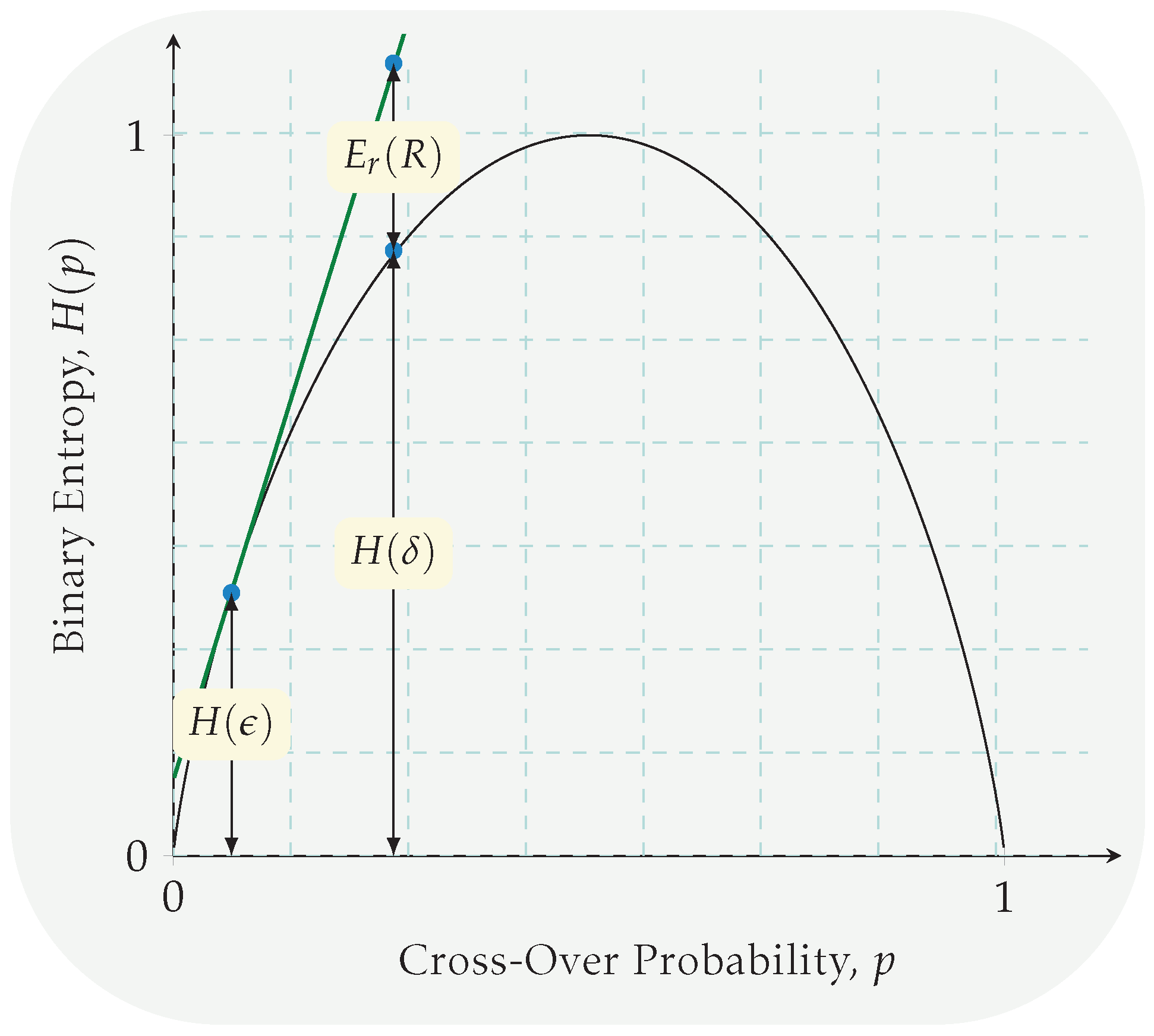
- Capacity formula: We derive inner and outer bounds on the DKI capacity region for constant and growing , for the BSC with and without Hamming weight constraints. Our capacity bounds reflect the impact of the channels statistics, i.e., cross-over probability and the input constraint A in the optimal scale of the codebook size, i.e., . In particular, in the coding procedure, we define a parameter , referred to as the distinction property of the codebook which adjust the Hamming distance property for the constructed codebook. Then, assuming a given codebook distinction, , a channel with asymptotic small cross-over probability (i.e., an almost perfect channel) causes the feasible range for the goal identification rate to shrink; that is, the capability of the BSC for K-identification decreases, which is unfavorable. On the other hand, when the cross-over probability increases and converges to its maximum possible values, i.e., (almost pure noisy channel), then the feasible range for begins to enlarge favorably. This observation can be interpreted as follows: The channel noise can be exploited as an additional inherent source embedded in the communication setting for performing the K-identification task with a larger value of K. This observation is in contrast to previous results for DKI over the slow fading channel [51], or the DI for Gaussian and Poisson channels [32,48,52], where capacity bounds were shown to be independent of the input constraints or the channel parameters. We demonstrate that the suggested upper and lower bounds on attainable rates are independent of K for constant K, whereas they are functions of the goal identification rate for increasing goal message sets.
- ◊
- Technical novelty: To obtain the proposed inner bound on the DKI capacity region, we address the input set imposed by the input constraints, and exploit it for an appropriate ball covering (overlapping balls with identical radius); namely, we consider covering of hyper balls inside a Hamming cube, whose Hamming radius grows in the codeword length n, i.e., ∼, for some upper bounded by a function of the channel statistic. We exploit a greedy construction similar as for the Gilbert bound method. While the radius of the small balls in the DI problem for the Gaussian channel with slow and fast fading [32], tends to zero as , here, the radius similar to the DKI problem for the slow fading channel [51] grows in the codeword length n for asymptotic n. In general, the derivation of lower bound for the BSC is more complicated compared to that for the Gaussian [32] and Poisson channels with/out memory [48,52], and entails exploiting of new analysis and inequalities. Here, the error analysis in the achievability proof requires dealing with several combinatorial arguments and using of bounds on the tail for the cumulative distribution function (CDF) of the Binomial distribution. The DKI problem was recently investigated in [52] for a DTPC with ISI where the size of the ISI taps is assumed to scale as . In contrast to the findings in [52], where the attainable rate region of triple rates for the Poisson channel with memory was derived, here, we study the DKI problem for a memoryless BSC, i.e., , and the attainable rate region of pair rates is established. Furthermore, while the method in the achievability proof of [52] is based on sphere packing, which includes an arrangement of non-overlapping spheres in the feasible input set. Here, we use a rather different approach called sphere/ball covering, which allows for the spheres/ball to overlap with each other. For the derivation of the outer bound on the DKI capacity region, it is assumed that a random series of code with diminishing error probabilities is provided. Then, for such a sequence, we prove that an one-to-one mapping between the message set and the set of the feasible input set (induced by the input constraint) can be established. Unlike the previous upper bound proof for DI over the DMC [32]; here, the proof for corresponding lemma is adopted in order to incorporate relevant set of the goal message sets, appropriately. Moreover, in the converse proof, similarly to [52], the method of proof by contradiction was utilized; that is, assuming that a certain property regarding the distance or number of the codewords is negated, we lead to a contradiction related to the sum of the sort I and sort II error probabilities. However, unlike [52], where a sub-linear function for the size of the goal message set was considered, i.e., , here, our converse entails a faster function, namely .
1.7. Organization
2. Background on the Identification Problem
2.1. Identification Problem
2.2. Previous Results on DI Capacity
2.3. Previous Results on DKI Capacity
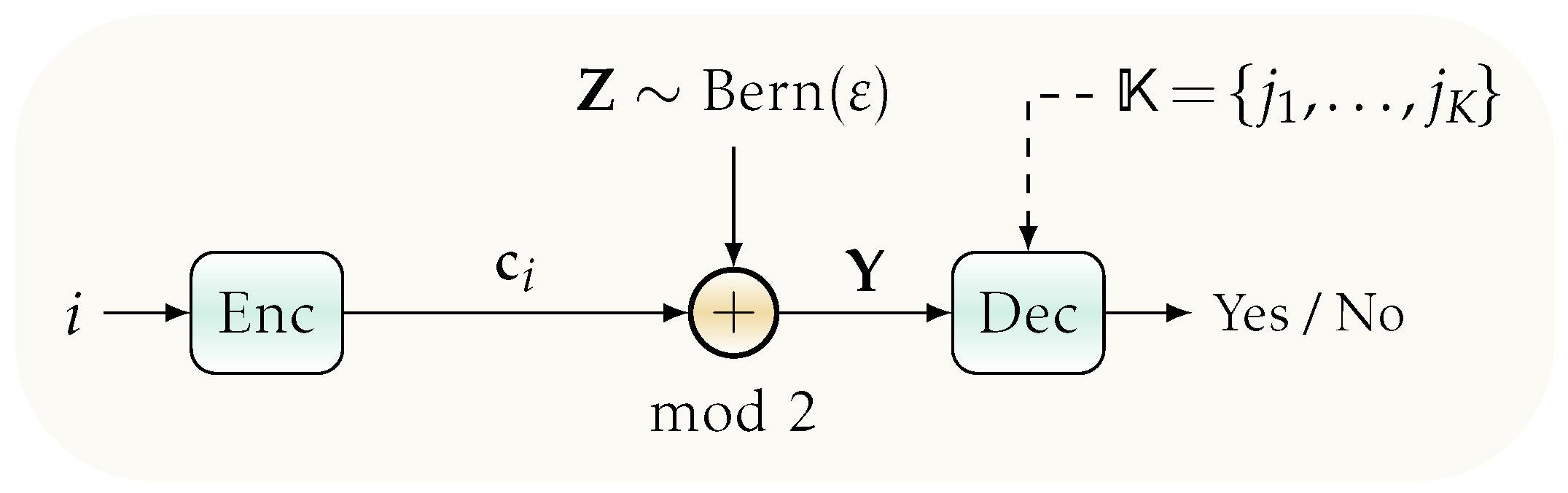
3. System Model and Preliminaries
3.1. System Model
3.2. DKI Coding for the BSC
- ◊
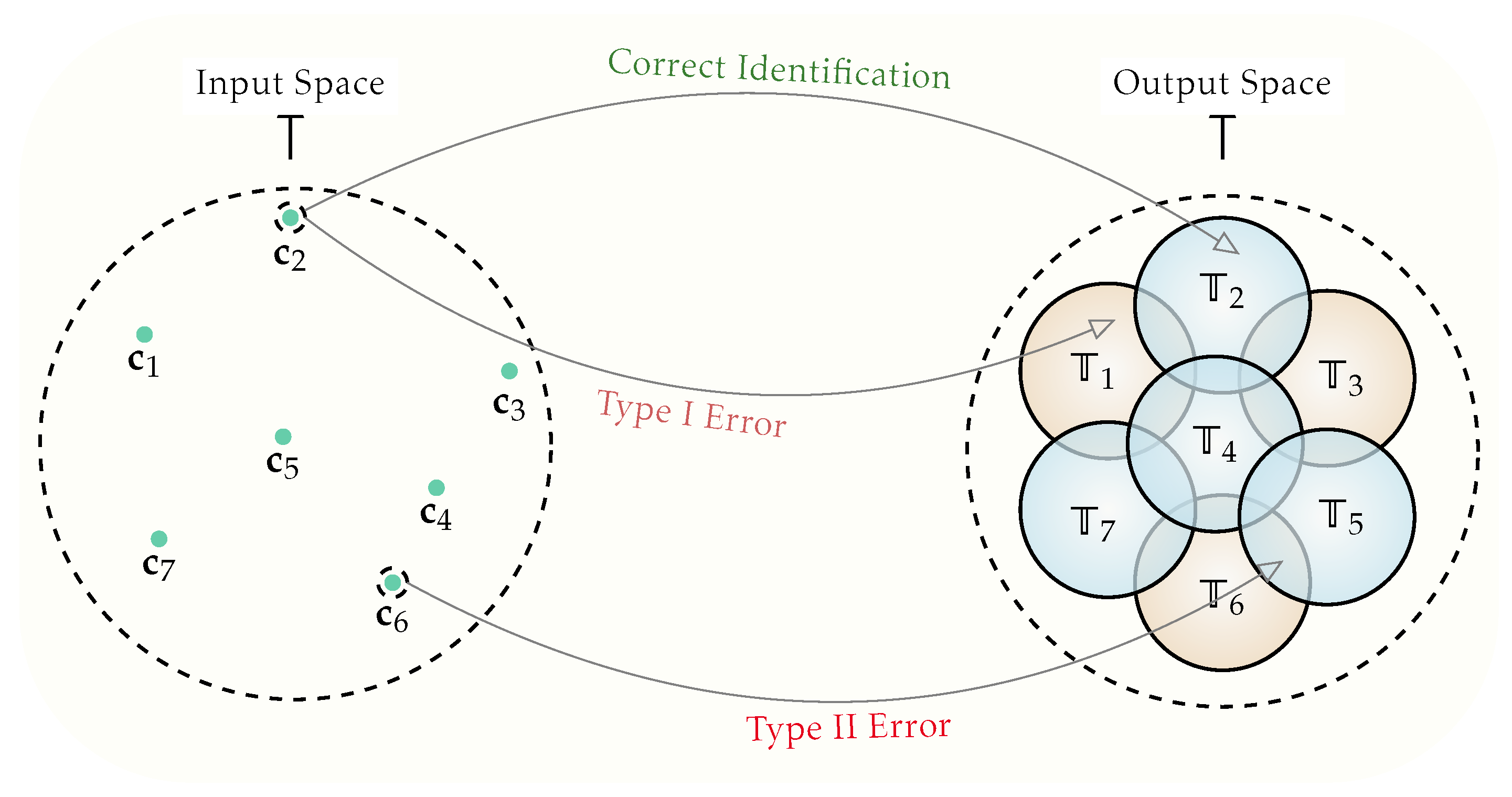
- Sort I Error Event: Rejection of the actual message; .
- ◊
- Sort II Error Event: Acceptance of a wrong message; .
4. DKI Capacity Region of the BSC
4.1. Main Results
- ◊
- Input constraint: Theorem 1 reveals an important observation regarding the impact of the input constraint (when it is effective, i.e., ) on the inner and outer regions formulas for the DKI capacity. In contrast to previous results for DI over Gaussian channel [32] or DKI over slow fading channel [51], where the capacity bounds does not reflect the impact of the input constraint, our results for DKI over the BSC in this paper reflect the impact of the Hamming weight constraint on the inner and outer regions.
- ◊
- Scale of codebook: The inner and outer bounds on the DKI capacity region given in Theorem 1 are valid in the standard scale for the codebook size, i.e., , where R is the coding rate. This result coincides the conventional behavior of the codebook size for TR [17] and DI [32] problems over the BSC. Other scales higher than the exponential for the codebook size of K-identification problem are reported in the literature; see Figure 4.
- ◊
- Scale of goal message set: Theorem 1 unveils that the size of the set of the goal messages scales exponentially in the codeword length, i.e., ∼. In particular, the result in Theorem 1 about size of the goal message set constitutes of the subsequent three cases in terms of K:
- DI, : In this scenario, the goal message set is a degenerate case; that is, , with , and is equivalent to the standard identification setup (), where . As a result, the identification setup in randomized regimes [49] and deterministic regimes [32] can be thought of as a particular instance of the K-identification that is examined in this work. See Corollary 1 for further details.
- Constant : The scenario where as is implied by a constant . Our capacity bounds in Theorem 1 on the attainable rate pairs are the same as those for . That is, the result in this cases converge to those for given in Corollary 1, for the asymptotic .
- Growing K: The fact that a trustworthy K-identification is still attainable, even in cases where K scales with the codeword length as ∼ for some , is another significant finding of Theorem 1 ; see Figure 5.
4.2. Inner Bound (Achievability Proof)
- ◊
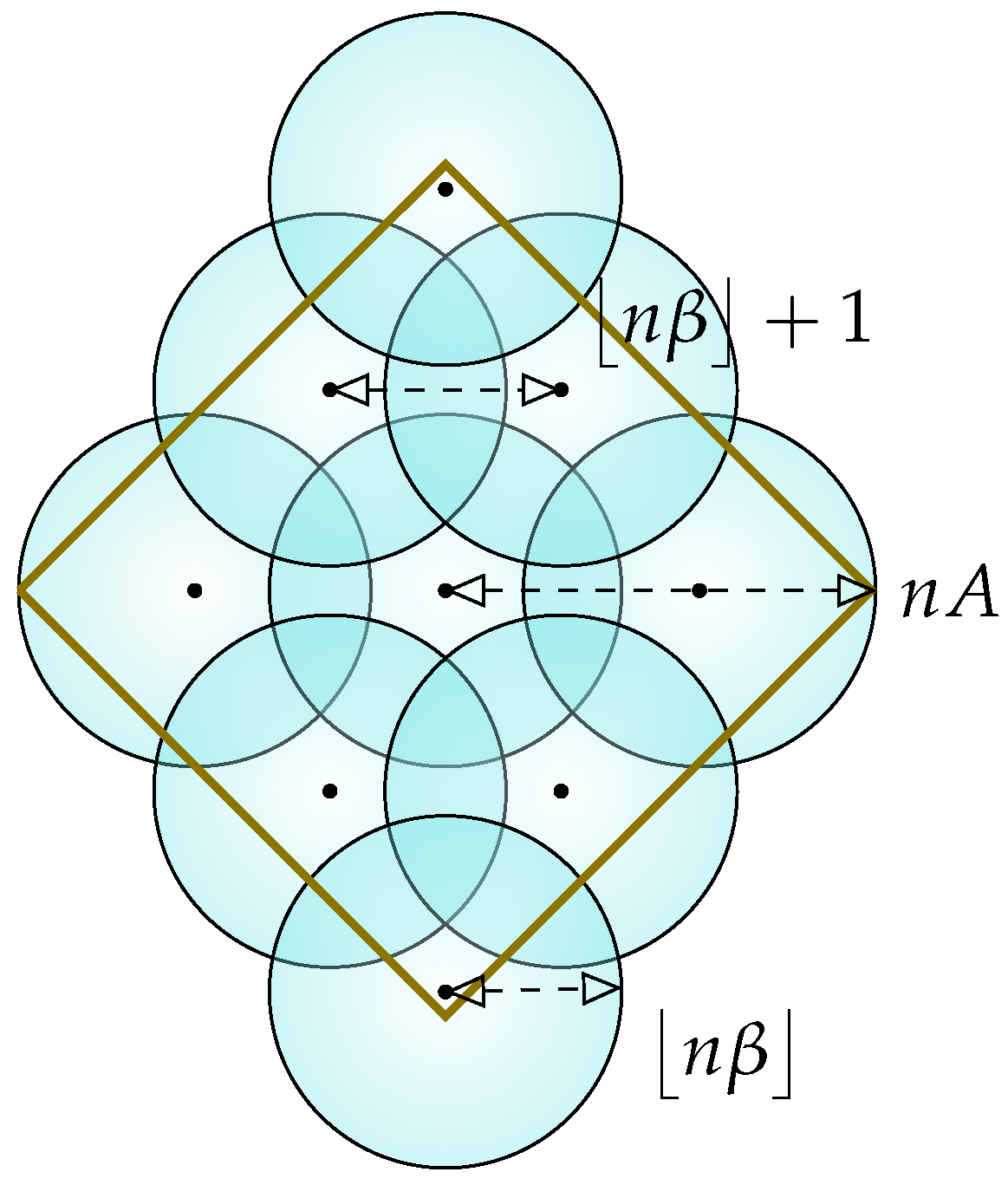
- Step 1 (rate analysis): First, we propose a greedy-wise method for codebook construction, which has a flavor similar to that observed in the classical approach of the Gilbert–Varshamov (GV) bound (the early introduction of such a bound in the literature is accomplished by Gilbert in [63]) for covering of overlapping balls embedded in the input set. More specifically, we introduce a codebook of exponential size in the codeword length n, which fulfills the input constraint and enjoys a Hamming distance property; namely, every pair of distinct codewords are separated by a certain distance. Moreover, we introduced a parameter in order to account/adjust such a distance. This step is particularly relevant in the sort II error analysis, as well as the derivation for the final lower bound on the identification coding rate. Additionally, we identify the whole range across which the parameter can change, which is needed to derive an analytical lower bound on the corresponding codebook size.
- ◊
- Step 2 (error analysis): In the second part (error analysis), we show that the suggested codebook in the previous part is optimal, i.e., leads to an attainable rate pairs . To this end, we begin with introducing a decision rule which is a distance decoder based on the Hamming metric, and would show that the associated errors of the sort I and the II probabilities vanish in the asymptotic codeword length, i.e., when . Moreover, the error analysis for the sort II error probability determines the associated error exponent. As a result, the feasible region for the goal identification rate is obtained.

- ◊
- Case 1—with Hamming weight constraint: , then the condition is non-trivial in the sense that it induces a strict subset of the entire input set . We denote such subset by and is equivalent to .
- ◊
- Case 2—without Hamming weight constraint: , then each codeword belonging to the n-dimensional Hamming cube fulfilled the Hamming weight constraint, since . Therefore, we address the entire input set as the possible set of codewords and attempt to exhaust it in a brute-force manner in the asymptotic, i.e., as .

- .
- .
- ◊
- Hamming distance property: , where .
- ◊
- Codebook size: the codebook size is at least .

- ◊
- Hamming distance property: For every , where , we have
- ◊
- Codebook size: The codebook size is at least .



- is output of channel at time tconditioned that , i.e., .
- The vector of symbols is .
4.3. Upper Bound (Converse Proof)
- ◊
- Step 1: we show in Lemma 3 that for any attainable DKI rate whose error probabilities of sort I and sort II tends to zero as , any pair of distinct messages are associated with different codewords.
- ◊
- Step 2: exploiting Lemma 3, we acquire an upper bound for the DKI codebook size of a the BSC.


5. Future Directions and Summary
- ◊
- Explicit code construction: In this paper, we mainly address the determination of basic performance constraints for the DKI for the BSC with/without Hamming weight constraint, where an explicit code construction was not investigated. That is, in the achievability proof, we only guarantee the existence of a code without suggesting a systematic method for construction of the code. Therefore, an important direction for research may be explicit construction of K-identification codes for the BSC and development of efficient encoding and low complexity decoding schemes. Furthermore, the efficiency of such concrete designs can be measured versus the information theoretical bounds derived in this paper.
- ◊
- Generalized channel models: We consider in this work one of the simplest and most basic channel model, namely the BSC in the absence of channel state, memory, or feedback. Therefore, our result can be extended to a DMC (with or without memory/feedback), compound, and arbitrary varying channels, which are generalizations of the BSC. In particular, several realistic IoT scenarios modeled by the BSC feature memory to some extent and the effect of memory may not be made negligible in a straightforward manner. Therefore, the application of memoryless channels as conducted in this paper to these realistic instances may in general yields different capacity results. In addition, it may be possible to exploit the memory effect in terms of gaining more optimum inner and outer bounds on the DKI capacity, as well as the specification of the encoding and decoding modules; cf. [61,67,68,69] for detailed studies on the BSC models with memory.
- ◊
- Multi-user and multi-antenna systems: The results in this paper study a point-to-point single user system, and might be extended to advanced scenarios proper for the future communication network settings including multiple-input multiple-output channels or multi-user channels, which are deemed to be more relevant in the complex IoT systems.
- ◊
- Finite codeword length coding: The obtained bounds on the K-identification capacity region studied in this paper determine the performance limits of BSC with/without Hamming weight constraint when the codeword length can grow arbitrarily. However, in practical applications, the codeword length is finite, where there is no way to afford significant encoding/decoding delays. As a result, studying the non-asymptotic DKI capacity of the BSC is an interesting direction for future research.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| IoMT | Internet of Medical Things |
| pH | Potential Hydrogen |
| IoBNT | Internet of Bio-Nano Things |
| MC | Molecular Communications |
| 6G | Sixth-Generation |
| PSC | Post-Shannon Communications |
| XG | Future-Generation |
| BSC | Binary Symmetric Channel |
| TR | Shannon’s Message Transmission |
| Bern | Bernoulli |
| DI | Deterministic Identification |
| DMC | Discrete Memoryless Channel |
| RV | Random Variable |
| Vol | Volume |
| DKI | Deterministic K-Identification |
| CDF | Cumulative Distribution Function |
| RI | Randomized Identification |
| RKI | Randomized K-Identification |
| DTPC | Memoryless Discrete-Time Poisson Channel |
| GSF | Gaussian Channel With Slow Fading |
| GV | Gilbert–Varshamov |
| ISI | Inter-Symbol Interference |
| CRF | Channel Reliability Function |
Appendix A. Sort I Error Analysis
Appendix B. Sort II Error Analysis
Appendix C. Cover-Free Families
Appendix D. Lower Bound on the Volume of the Hamming Ball
Appendix E. Upper Bound on the Volume of the Hamming Ball
Appendix F. Bound on the Upper Tail of the Binomial Cumulative Distribution Function—Part 1
Appendix G. Bound on the Upper Tail of the Binomial Cumulative Distribution Function—Part 2
Appendix H. Bound on the Binomial Cumulative Distribution Function
References
- Li, S.; Xu, L.D.; Zhao, S. The Internet of Things: A Survey. Inf. Syst. Front. 2015, 17, 243–259. [Google Scholar] [CrossRef]
- Da Xu, L.; He, W.; Li, S. Internet of Things in Industries: A Survey. IEEE Trans. Ind. Inform. 2014, 10, 2233–2243. [Google Scholar]
- Stankovic, J.A. Research Directions For The Internet of Things. IEEE Internet Things J. 2014, 1, 3–9. [Google Scholar] [CrossRef]
- Sun, L.; Du, Q. A Review of Physical Layer Security Techniques For Internet of Things: Challenges and Solutions. Entropy 2018, 20, 730. [Google Scholar] [CrossRef] [PubMed]
- Batty, M.; Axhausen, K.W.; Giannotti, F.; Pozdnoukhov, A.; Bazzani, A.; Wachowicz, M.; Ouzounis, G.; Portugali, Y. Smart Cities of The Future. Eur. Phys. J. Spec. Top. 2012, 214, 481–518. [Google Scholar] [CrossRef]
- Ray, P.P. An Introduction to Dew Computing: Definition, Concept and Implications. IEEE Access 2018, 6, 723–737. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Paiva, S.; Ahad, M.A.; Tripathi, G.; Feroz, N.; Casalino, G. Enabling Technologies For Urban Smart Mobility: Recent Trends, Opportunities and Challenges. Sensors 2021, 21, 2143. [Google Scholar] [CrossRef]
- Mahmud, K.; Town, G.E.; Morsalin, S.; Hossain, M. Integration of Electric Vehicles and Management in The Internet of Energy. Renew. Sustain. Energy Rev. 2018, 82, 4179–4203. [Google Scholar] [CrossRef]
- Fascista, A.; Coluccia, A.; Ravazzi, C. A Unified Bayesian Framework For Joint Estimation and Anomaly Detection in Environmental Sensor Networks. IEEE Access 2023, 11, 227–248. [Google Scholar] [CrossRef]
- Gatouillat, A.; Badr, Y.; Massot, B.; Sejdić, E. Internet of Medical Things: A Review of Recent Contributions Dealing With Cyber-Physical Systems in Medicine. IEEE Internet Things J. 2018, 5, 3810–3822. [Google Scholar] [CrossRef]
- da Costa, C.A.; Pasluosta, C.F.; Eskofier, B.; da Silva, D.B.; da Rosa Righi, R. Internet of Health Things: Toward Intelligent Vital Signs Monitoring in Hospital Wards. Med. Artif. Intell. 2018, 89, 61–69. [Google Scholar] [CrossRef]
- Lee, C.; Koo, B.H.; Chae, C.B.; Schober, R. The Internet of Bio-Nano Things in Blood Vessels: System Design and Prototypes. J. Commun. Netw. 2023, 25, 222–231. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Pierobon, M.; Balasubramaniam, S.; Koucheryavy, Y. The Internet of Bio-Nano Things. IEEE Commun. Mag. 2015, 53, 32–40. [Google Scholar] [CrossRef]
- Nakano, T.; Eckford, A.W.; Haraguchi, T. Molecular Communication; Cambridge University Press: New York, NY, USA, 2013. [Google Scholar]
- Farsad, N.; Yilmaz, H.B.; Eckford, A.; Chae, C.B.; Guo, W. A Comprehensive Survey of Recent Advancements in Molecular Communication. IEEE Commun. Surv. Tutor. 2016, 18, 1887–1919. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Cabrera, J.A.; Boche, H.; Deppe, C.; Schaefer, R.F.; Scheunert, C.; Fitzek, F.H. 6G and the Post-Shannon Theory. In Shaping Future 6G Networks: Needs, Impacts, and Technologies; IEEE Press: Piscataway, NJ, USA, 2021; pp. 271–294. [Google Scholar]
- Zhang, C.; Zou, H.; Lasaulce, S.; Saad, W.; Kountouris, M.; Bennis, M. Goal-Oriented Communications For The IoT and Application to Data Compression. IEEE Internet Things Mag. 2022, 5, 58–63. [Google Scholar] [CrossRef]
- Schwenteck, P.; Nguyen, G.T.; Boche, H.; Kellerer, W.; Fitzek, F.H.P. 6G Perspective of Mobile Network Operators, Manufacturers, and Verticals. IEEE Netw. Lett. 2023, 5, 169–172. [Google Scholar] [CrossRef]
- Fettweis, G.P.; Boche, H. 6G: The Personal Tactile Internet—And Open Questions for Information Theory. IEEE BITS Inf. Theory Mag. 2021, 1, 71–82. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Mu, X.; Hou, T.; Xu, J.; Di Renzo, M.; Al-Dhahir, N. Reconfigurable Intelligent Surfaces: Principles and Opportunities. IEEE Commun. Surv. Tutor. 2021, 23, 1546–1577. [Google Scholar] [CrossRef]
- Fascista, A.; Keskin, M.F.; Coluccia, A.; Wymeersch, H.; Seco-Granados, G. RIS-Aided Joint Localization and Synchronization With a Single-Antenna Receiver: Beamforming Design and Low-Complexity Estimation. IEEE J. Sel. Top. Signal Process. 2022, 16, 1141–1156. [Google Scholar] [CrossRef]
- Shi, J.; Chan, T.T.; Pan, H.; Lok, T.M. Reconfigurable Intelligent Surface Assisted Semantic Communication Systems. arXiv 2023, arXiv:2306.09650. [Google Scholar]
- Torres-Figueroa, L.; Ferrara, R.; Deppe, C.; Boche, H. Message Identification for Task-Oriented Communications: Exploiting an Exponential Increase in the Number of Connected Devices. IEEE Internet Things Mag. 2023, 6, 42–47. [Google Scholar] [CrossRef]
- Ahlswede, R. General Theory of Information Transfer: Updated. Discrete Appl. Math. 2008, 156, 1348–1388. [Google Scholar] [CrossRef]
- Seyhan, K.; Akleylek, S. Classification of Random Number Generator Applications in IoT: A Comprehensive Taxonomy. J. Inf. Secur. Appl. 2022, 71, 103365. [Google Scholar] [CrossRef]
- Hughes, J.P.; Diffie, W. The Challenges of IoT, TLS, and Random Number Generators in The Real World: Bad Random Numbers are Still With us and Are Proliferating in Modern Systems. Queue 2022, 20, 18–40. [Google Scholar] [CrossRef]
- Brakerski, Z.; Kalai, Y.T.; Saxena, R.R. Deterministic and Efficient Interactive Coding From Hard-to-Decode Tree Codes. In Proceedings of the IEEE Symposium on Foundations of Computer Science, Durham, NC, USA, 16–19 November 2020; pp. 446–457. [Google Scholar]
- Bocchino, R.L.; Adve, V.; Adve, S.; Snir, M. Parallel Programming Must be Deterministic by Default. Usenix HotPar 2009, 6, 1855591–1855595. [Google Scholar]
- Arıkan, E. Channel Polarization: A Method For Constructing Capacity-Achieving Codes For Symmetric Binary-Input Memoryless Channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef]
- Salariseddigh, M.J.; Pereg, U.; Boche, H.; Deppe, C. Deterministic Identification Over Channels With Power Constraints. IEEE Trans. Inf. Theory 2022, 68, 1–24. [Google Scholar] [CrossRef]
- JáJá, J. Identification is Easier Than Decoding. In Proceedings of the Annual Symposium on Foundations of Computer Science, Portland, OR, USA, 21–23 October 1985; pp. 43–50. [Google Scholar]
- Cover, T.; Thomas, J. Elements of Information Theory; Wiley Series Telecomm.; John Wiley & Sons: New York, NY, USA, 1991. [Google Scholar]
- Gallager, R.G. Information Theory and Reliable Communication; John Wiley & Sons, Inc.: New York, NY, USA, 1968. [Google Scholar]
- Gamal, A.E.; Kim, Y.H. Network Information Theory; Cambridge University Press: New York, NY, USA, 2012. [Google Scholar]
- MacKay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Zhang, G.; Chen, K.; Ma, C.; Reddy, S.K.; Ji, B.; Li, Y.; Han, C.; Zhang, X.; Fu, Z. Decision Fusion For Multi-Route and Multi-Hop Wireless Sensor Networks Over The Binary Symmetric Channel. Comput. Commun. 2022, 196, 167–183. [Google Scholar] [CrossRef]
- Premkumar, K.; Chen, X.; Leith, D.J. Utility Optimal Coding For Packet Transmission Over Wireless Networks—Part I: Networks of Binary Symmetric Channels. In Proceedings of the 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 28–30 September 2011; pp. 1592–1599. [Google Scholar] [CrossRef]
- Slepian, D. A Class of Binary Signaling Alphabets. Bell Syst. Tech. J. 1956, 35, 203–234. [Google Scholar] [CrossRef]
- Elias, P. Coding For Noisy Channels. In Proceedings of the IRE WESCON Convention Record; 1955; Volume 2, pp. 94–104. Available online: https://cir.nii.ac.jp/crid/1570009750462156928 (accessed on 13 February 2024).
- Elias, P. Coding For Two Noisy Channels. In Proceedings of the 3rd London Symposium in Information Theory, London, UK, September 1955; Available online: https://cir.nii.ac.jp/crid/1571417125336937088 (accessed on 13 February 2024).
- Elias, P. List Decoding For Noisy Channels. In Proceedings of the IRE WESCON Convention Record, San Francisco, CA, USA, 20–23 August 1957; pp. 94–104. [Google Scholar]
- Golay, M.J. Notes on Digital Coding. Proc. IEEE 1949, 37, 657. [Google Scholar]
- Hamming, R.W. Error Detecting and Error Correcting Codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Reed, I.S. A Class of Multiple-Error-Correcting Codes and The Decoding Scheme. IEEE Trans. Inf. Theory 1954, 4, 38–49. [Google Scholar] [CrossRef]
- Dabbabi, O.; Salariseddigh, M.J.; Deppe, C.; Boche, H. Deterministic K-Identification For Binary Symmetric Channel. arXiv 2023, arXiv:2305.04260. [Google Scholar]
- Salariseddigh, M.J.; Jamali, V.; Pereg, U.; Boche, H.; Deppe, C.; Schober, R. Deterministic Identification For Molecular Communications Over The Poisson Channel. IEEE Trans. Mol. Biol. Multi-Scale Commun. 2023, 9, 408–424. [Google Scholar] [CrossRef]
- Ahlswede, R.; Dueck, G. Identification Via Channels. IEEE Trans. Inf. Theory 1989, 35, 15–29. [Google Scholar] [CrossRef]
- Kumar, S.; Marescaux, J. Telesurgery; Springer Science & Business Media: New York, NY, USA, 2008. [Google Scholar]
- Spahovic, M.; Salariseddigh, M.J.; Deppe, C. Deterministic K-Identification For Slow Fading Channels. In Proceedings of the IEEE Information Theory Workshop (ITW), Saint-Malo, France, 23–28 April 2023; pp. 353–358. [Google Scholar] [CrossRef]
- Salariseddigh, M.J.; Jamali, V.; Pereg, U.; Boche, H.; Deppe, C.; Schober, R. Deterministic K-Identification For MC Poisson Channel With Inter-Symbol Interference. IEEE Open J. Commun. Soc. 2024. [Google Scholar] [CrossRef]
- Abu-Mostafa, Y.S. Complexity in Information Theory; Springer: New York, NY, USA, 1988. [Google Scholar]
- Yao, A.C. Some Complexity Questions Related to Distributive Computing. In Proceedings of the Annual ACM Symposium on the Theory Computing, Atlanta, GA, USA, 30 April–2 May 1979; pp. 209–213. [Google Scholar]
- Verdu, S.; Wei, V. Explicit Construction of Optimal Constant-Weight Codes For Identification Via Channels. IEEE Trans. Inf. Theory 1993, 39, 30–36. [Google Scholar] [CrossRef]
- Günlü, O.; Kliewer, J.; Schaefer, R.F.; Sidorenko, V. Code Constructions and Bounds For Identification Via Channels. IEEE Trans. Commun. 2021, 70, 1486–1496. [Google Scholar] [CrossRef]
- Ahlswede, R.; Cai, N. Identification Without Randomization. IEEE Trans. Inf. Theory 1999, 45, 2636–2642. [Google Scholar] [CrossRef]
- Mehlhorn, K.; Schmidt, E.M. Las Vegas is Better Than Determinism in VLSI and Distributed Computing. In Proceedings of the 14th Annal ACM Symposium on Theory of Computation, San Francisco, CA, USA, 5–7 May 1982; pp. 330–337. [Google Scholar]
- Salariseddigh, M.J.; Jamali, V.; Boche, H.; Deppe, C.; Schober, R. Deterministic Identification For MC Binomial Channel. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Taipei, Taiwan, 25–30 June 2023; pp. 448–453. [Google Scholar] [CrossRef]
- Yamamoto, H.; Ueda, M. Multiple Object Identification Coding. IEEE Trans. Inf. Theory 2015, 61, 4269–4276. [Google Scholar] [CrossRef]
- Kennedy, R.S. Finite-Sate Binary Symmetric Channels. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1963. [Google Scholar]
- Rudin, W. Principles of Mathematical Analysis; McGraw-Hill: New York, NY, USA, 1953. [Google Scholar]
- Gilbert, E.N. A Comparison of Signalling Alphabets. Bell Syst. Tech. J. 1952, 31, 504–522. [Google Scholar] [CrossRef]
- Richardson, T.; Urbanke, R. Modern Coding Theory; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Conway, J.H.; Sloane, N.J.A. Sphere Packings, Lattices and Groups; Springer: New York, NY, USA, 2013. [Google Scholar]
- Van Lint, J.H. Introduction to Coding Theory; Springer Science & Business Media: New York, NY, USA, 1998; Volume 86. [Google Scholar]
- Gilbert, E.N. Capacity of a Burst-Noise Channel. Bell Syst. Tech. J. 1960, 39, 1253–1265. [Google Scholar] [CrossRef]
- Alexander, A.A.; Gryb, R.M.; Nast, D.W. Capabilities of The Telephone Network For Data Transmission. Bell Syst. Tech. J. 1960, 39, 431–476. [Google Scholar] [CrossRef]
- Fontaine, A.B.; Gallager, R.G. Error Statistics and Coding For Binary Transmission Over Telephone Circuits. Proc. IRE 1961, 49, 1059–1065. [Google Scholar] [CrossRef]
- Kautz, W.; Singleton, R. Nonrandom Binary Superimposed Codes. IEEE Trans. Inf. Theory 1964, 10, 363–377. [Google Scholar] [CrossRef]
- Füredi, Z. On r-Cover-Free Families. J. Comb. Theory Ser. A 1996, 73, 172–173. [Google Scholar] [CrossRef]
- Flum, J.; Grohe, M. Parameterized Complexity Theory; Texts in Theoretical Computer Science (An EATCS Series); Springer: New York, NY, USA, 2006. [Google Scholar]
- Robbins, H. A Remark On Stirling’s Formula. Am. Math. Mon. 1955, 62, 26–29. [Google Scholar] [CrossRef]
- Jeřábek, E. Dual Weak Pigeonhole Principle, Boolean Complexity, and Derandomization. Ann. Pure Appl. Log. 2004, 129, 1–37. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salariseddigh, M.J.; Dabbabi, O.; Deppe, C.; Boche, H. Deterministic K-Identification for Future Communication Networks: The Binary Symmetric Channel Results. Future Internet 2024, 16, 78. https://doi.org/10.3390/fi16030078
Salariseddigh MJ, Dabbabi O, Deppe C, Boche H. Deterministic K-Identification for Future Communication Networks: The Binary Symmetric Channel Results. Future Internet. 2024; 16(3):78. https://doi.org/10.3390/fi16030078
Chicago/Turabian StyleSalariseddigh, Mohammad Javad, Ons Dabbabi, Christian Deppe, and Holger Boche. 2024. "Deterministic K-Identification for Future Communication Networks: The Binary Symmetric Channel Results" Future Internet 16, no. 3: 78. https://doi.org/10.3390/fi16030078
APA StyleSalariseddigh, M. J., Dabbabi, O., Deppe, C., & Boche, H. (2024). Deterministic K-Identification for Future Communication Networks: The Binary Symmetric Channel Results. Future Internet, 16(3), 78. https://doi.org/10.3390/fi16030078