
Personalized Federated Learning with Adaptive Feature Extraction and Category Prediction in Non-IID Datasets



Abstract
:1. Introduction
- This study aims to develop a personalized federated learning process to mitigate the impact of data heterogeneity on federated learning. Unlike the conventional federated learning method, which trains a global model for all clients, this study proposes a personalized approach that adjusts the global model based on the data distribution of each client.
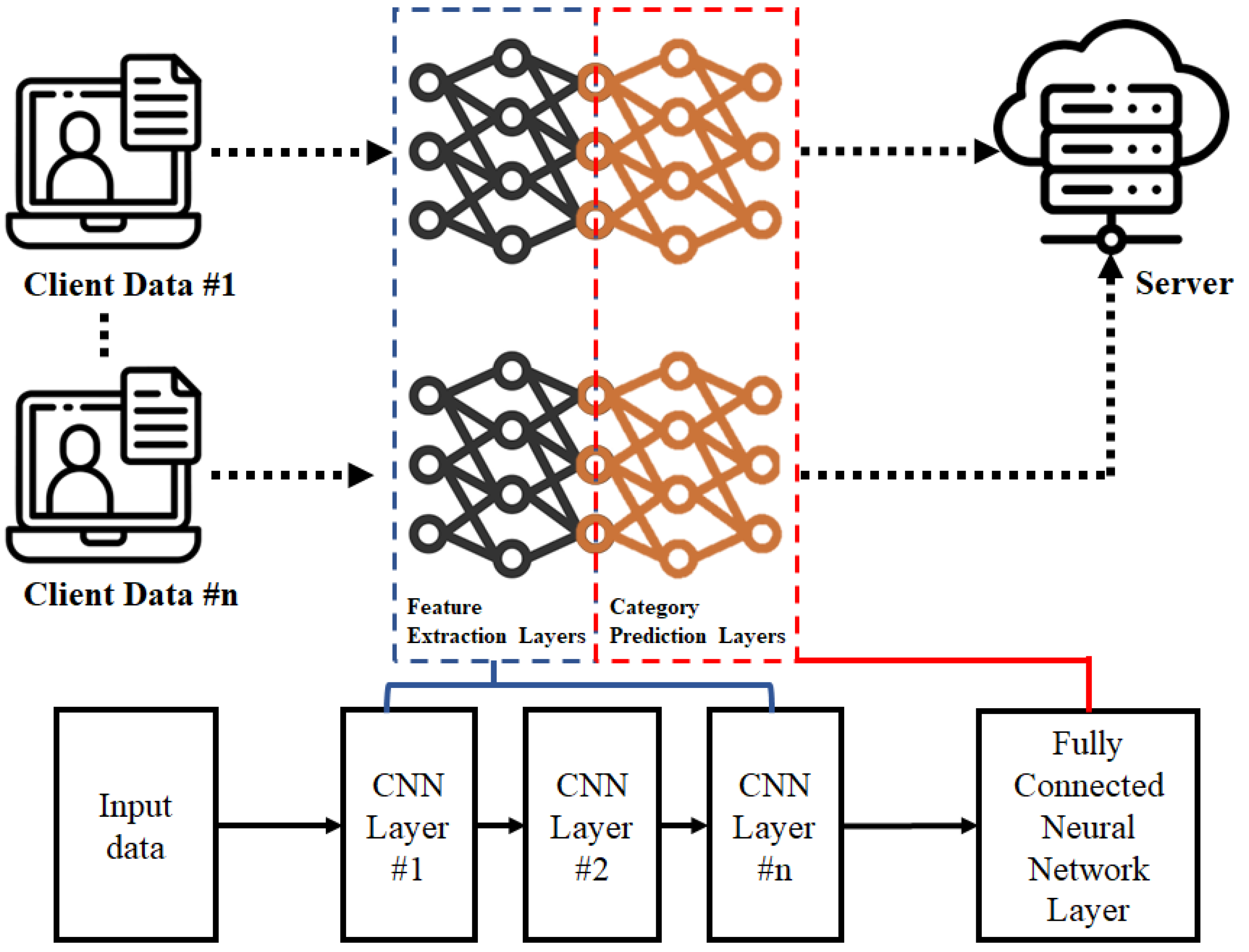
- A neural network model is used to establish personalized models for each client. This study proposes a theoretical basis for client model partitioning based on the properties of neural network models and presents a practical partitioning method that divides client models into feature extraction and category prediction layers. During federated learning training, the feature extraction layers are adjusted in a personalized manner, whereas the category prediction layers serve as elements that give the client models personalized characteristics.
- This method includes personalized feature extraction for client data. Federated learning requires datasets with similar properties to achieve results similar to those of multitask learning by finding an excellent feature extraction function. However, the effect of client drift makes it difficult for the feature extraction layer to achieve excellent feature extraction capabilities, which affects the final performance. Therefore, this study proposes an adaptive approach to reduce the adverse effects of client drift on the feature extraction layer.
2. Related Work
3. Research Methodology
3.1. Personalized Client Models
3.2. Adaptive Feature Extraction
| Algorithm 1. l |
| let Wf be the parameters of feature extraction layers. |
| let Wg be the parameters of the category predictions layer. |
| let i be the ith global round. |
| let c be the cth selected client. |
| let γ be the learning rate. |
| let β be the mixing ration, and the initial value is 0.5. |
| for i = 1,2, …,N do |
| set β to initial value |
| if i == N then all clients do |
| new β = betaupdate (β) |
| client own model ← () |
| break |
| else each selected clients C ∈ {C1,C2...Cm} parallel do |
| receive from server. |
| new β = betaupdate (β) |
| () ← modelupdate (( |
| keep the |
| send back to server |
| finish the federated learning |
3.3. Adaptive Mixing Ratio–β
4. Experiment Results and Analysis
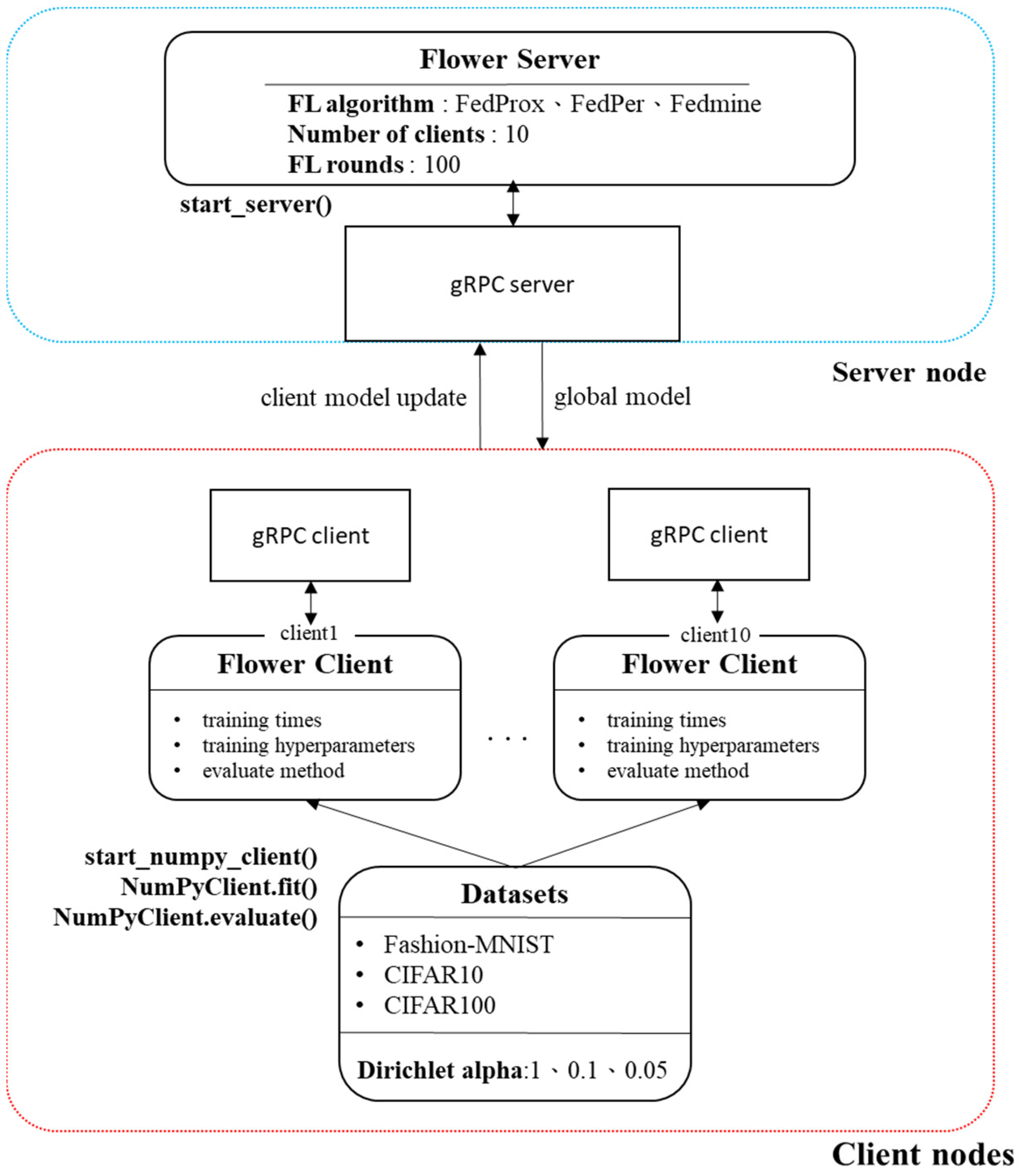
4.1. Experimental Framework and Dataset
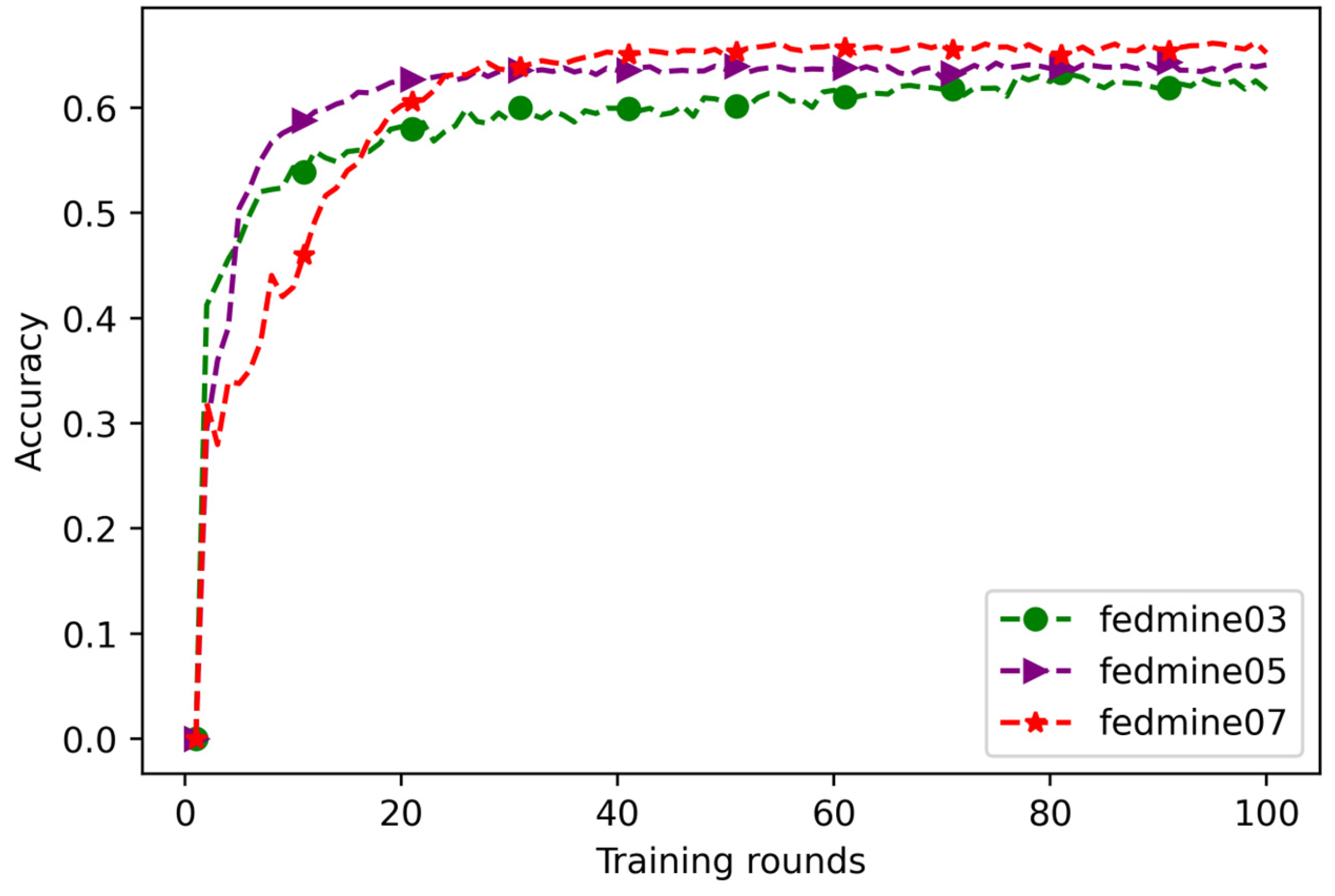
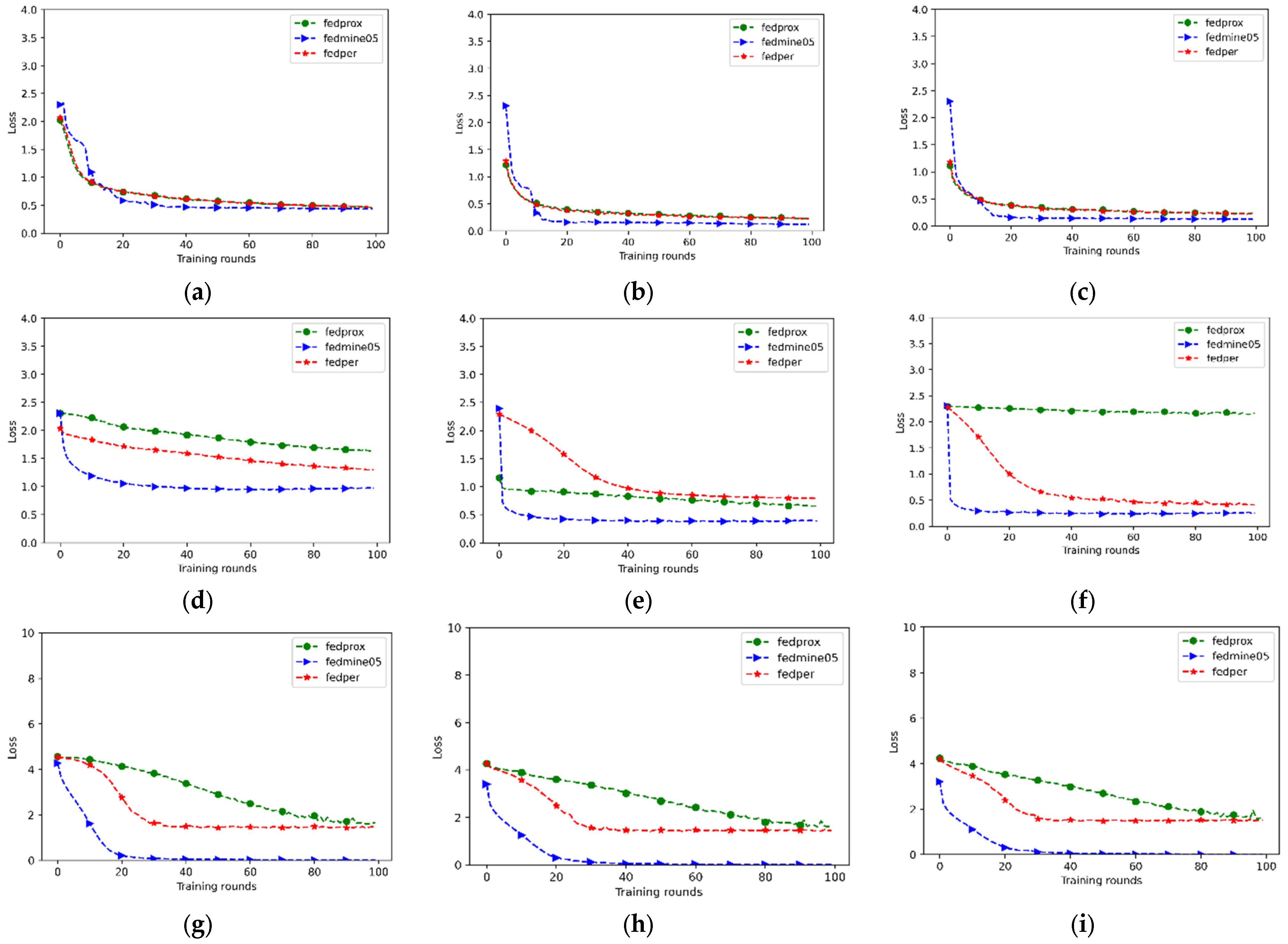
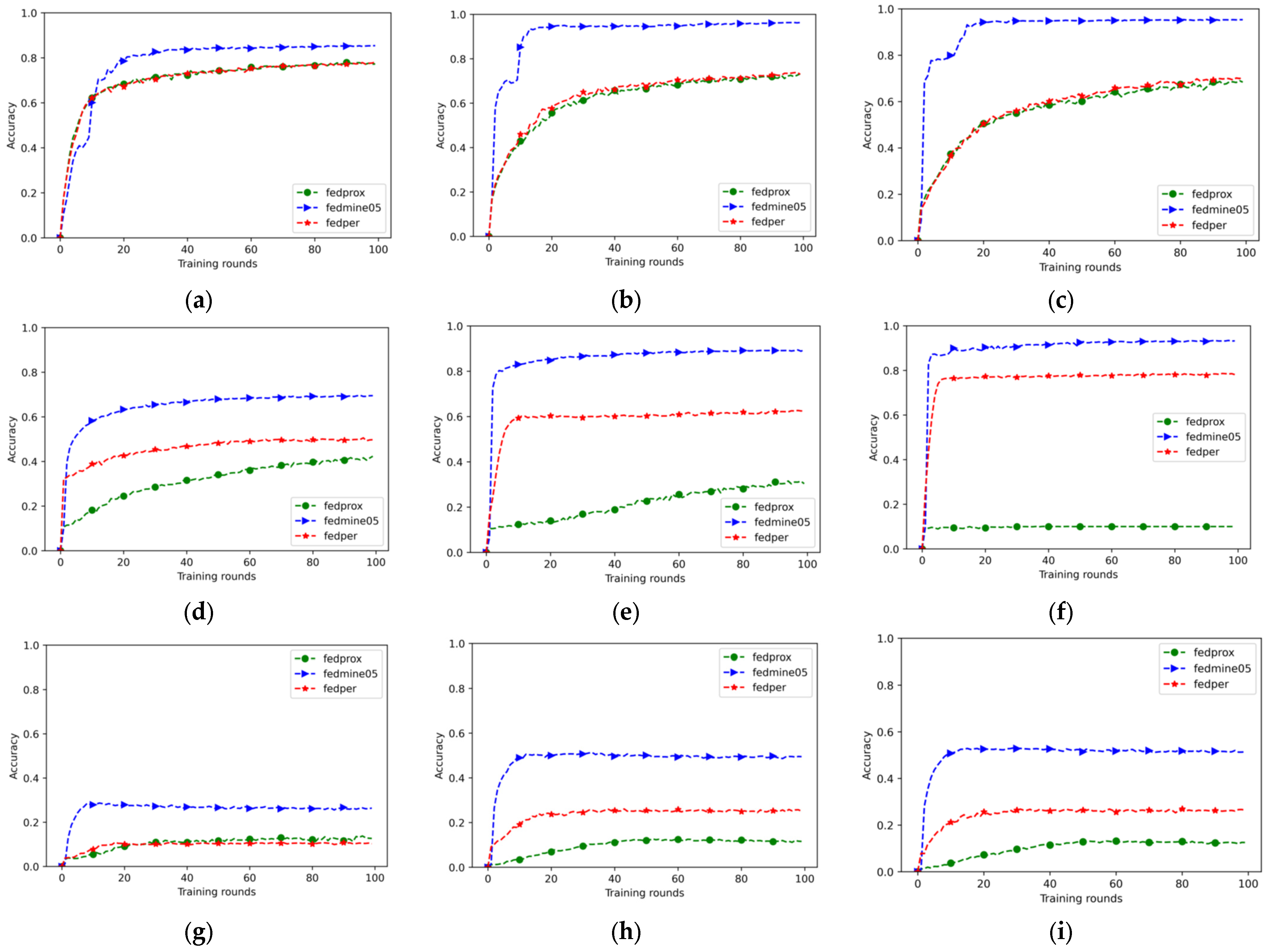
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chung, Y.-L. Application of an Effective Hierarchical Deep-Learning-Based Object Detection Model Integrated with Image-Processing Techniques for Detecting Speed Limit Signs, Rockfalls, Potholes, and Car Crashes. Future Internet 2023, 15, 322. [Google Scholar] [CrossRef]
- Yen, C.T.; Chen, G.Y. A Deep Learning-Based Person Search System for Real-World Camera Images. J. Internet Technol. 2022, 23, 839–851. [Google Scholar]
- Ma, Y.W.; Chen, J.L.; Chen, Y.J.; Lai, Y.H. Explainable deep learning architecture for early diagnosis of Parkinson’s disease. Soft Comput. 2023, 27, 2729–2738. [Google Scholar] [CrossRef]
- Prasetyo, H.; Prayuda, A.W.H.; Hsia, C.H.; Wisnu, M.A. Integrating Companding and Deep Learning on Bandwidth-Limited Image Transmission. J. Internet Technol. 2022, 23, 467–473. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu Xu He, B. A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection. IEEE Trans. Knowl. Data Eng. 2023, 35, 3347–3366. [Google Scholar] [CrossRef]
- Lyu, L.; Yu, H.; Zhao, J.; Yang, Q. Threats to Federated Learning. In Federated Learning; Lecture Notes in Computer Science; Yang, Q., Fan, L., Yu, H., Eds.; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Tan, Y.; Long, G.; Liu, L.; Zhou, T.; Lu, Q.; Jiang, J.; Zhang, C. Fedproto: Federated prototype learning across heterogeneous clients. Proc. AAAI Conf. Artif. Intell. 2022, 36, 8432–8440. [Google Scholar] [CrossRef]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated learning for healthcare informatics. J. Healthc. Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhou, Y.; Sun, Y.; Wang, Z.; Liu, B.; Li, K. Applications of federated learning in smart cities: Recent advances, taxonomy, and open challenges. Connect. Sci. 2022, 34, 1–28. [Google Scholar] [CrossRef]
- Nikolaidis, F.; Symeonides, M.; Trihinas, D. Towards Efficient Resource Allocation for Federated Learning in Virtualized Managed Environments. Future Internet 2023, 15, 261. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Singh, P.; Singh, M.K.; Singh, R.; Singh, N. Federated learning: Challenges, methods, and future directions. In Federated Learning for IoT Applications; Springer International Publishing: Cham, Switzerland, 2022; pp. 199–214. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Online, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Karimireddy, S.P.; Jaggi, M.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. Mime: Mimicking centralized stochastic algorithms in federated learning. arXiv 2020, arXiv:2008.03606. [Google Scholar]
- Wang, H.; Kaplan, Z.; Niu, D.; Li, B. Optimizing federated learning on non-iid data with reinforcement learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1698–1707. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. In Proceedings of the Machine Learning and Systems, Austin, TX, USA, 2–4 March 2020; Volume 2, pp. 429–450. [Google Scholar]
- Wu, Q.; He, K.; Chen, X. Personalized federated learning for intelligent IoT applications: A cloud-edge based framework. IEEE Open J. Comput. Soc. 2020, 1, 35–44. [Google Scholar] [CrossRef]
- Li, H.; Cai, Z.; Wang, J.; Tang, J.; Ding, W.; Lin, C.T.; Shi, Y. FedTP: Federated Learning by Transformer Personalization. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Shao, Z.; Huangfu, H.; Yu, H.; Teoh, A.B.J.; Li, X.; Shan, H.; Zhang, Y. Energizing Federated Learning via Filter-Aware Attention. arXiv 2023, arXiv:2311.12049. [Google Scholar] [CrossRef]
- Li, T.; Hu, S.; Beirami, A.; Smith, V. Ditto: Fair and robust federated learning through personalization. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 6357–6368. [Google Scholar]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated learning with personalization layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 7. [Google Scholar]
- Deng, Y.; Kamani, M.M.; Mahdavi, M. Adaptive personalized federated learning. arXiv 2020, arXiv:2003.13461. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Fernandez-Marques, J.; Gao, Y.; Sani, L.; Li, K.H.; Parcollet, T.; de Gusmão, P.P.B.; et al. Flower: A friendly federated learning research framework. arXiv 2020, arXiv:2007.14390. [Google Scholar]
- Li, K.H.; de Gusmão, P.P.B.; Beutel, D.J.; Lane, N.D. Secure aggregation for federated learning in flower. In Proceedings of the 2nd ACM International Workshop on Distributed Machine Learning, Munich, Germany, 7 December 2021; pp. 8–14. [Google Scholar]
- Brum, R.; Drummond, L.; Castro, M.C.; Teodoro, G. Towards optimizing computational costs of federated learning in clouds. In Proceedings of the 2021 International Symposium on Computer Architecture and High Performance Computing Workshops (SBAC-PADW), Belo Horizonte, Brazil, 26–29 October 2021; pp. 35–40. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 7 July 2022).
- Zhai, R.; Chen, X.; Pei, L.; Ma, Z. A Federated Learning Framework against Data Poisoning Attacks on the Basis of the Genetic Algorithm. Electronics 2023, 12, 560. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Characteristic | Research Target and Advantages |
|---|---|---|
| FedAvg [13] | The first federated learning algorithm proposed by Google. | FedAvg is a collaborative training neural network with data privacy. |
| Mime [15] | It combines control variates and server-level optimizer state. | Mime overcomes the natural client heterogeneity and is faster than any centralized method. |
| FAVOR [16] | It proposes a new method based on Q-learning to select a subset of devices. | FAVOR focuses on validation accuracy and penalizes the use of more communication rounds. |
| FedProx [18] | FedProx allows for the emergence of inadequately trained local models and adds a proximal term to the clients’ loss function. | FedProx reduces the impact of non-IID on federated learning and improves the accuracy relative to FedAvg. |
| FedPer [21] | It separates the client model into two parts and trains each individually. | FedPer demonstrates the ineffectiveness of FedAvg and the effectiveness of modeling personalization tasks. |
| FedTP [24] | It learns personalized self-attention for each client while aggregating the other parameters among the clients. | It combines FedTP with other methods, including FedPer, FedRod, and KNN-Per, to further enhance the model performance. It achieves better accuracy and learning performance. |
| Proposed method | It proposes a personalized federated learning with adaptive feature extraction and category prediction. | The study shows faster convergence speed and lower data loss than the FedProx and the FedPer federated learning algorithms in Fashion-MNIST, CIFAR10, and CIFAR100 datasets. |
| Parameters\Dataset | Fashion-MNIST | CIFAR10 | CIFAR100 |
|---|---|---|---|
| Input shape | (28, 28, 1) | (32, 32, 3) | (32, 32, 3) |
| CNN layer | 2 | 2 | 3 |
| FCNN layer | 1 | 1 | 2 |
| Federated round | 100 | 100 | 100 |
| Participating clients | 10 | 10 | 10 |
| Participating fraction | 0.8 | 0.8 | 0.8 |
| Client training epoch | 1 | 1 | 3 |
| Data batch size | 32 | 32 | 32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, Y.-H.; Chen, S.-Y.; Chou, W.-C.; Hsu, H.-Y.; Chao, H.-C. Personalized Federated Learning with Adaptive Feature Extraction and Category Prediction in Non-IID Datasets. Future Internet 2024, 16, 95. https://doi.org/10.3390/fi16030095
Lai Y-H, Chen S-Y, Chou W-C, Hsu H-Y, Chao H-C. Personalized Federated Learning with Adaptive Feature Extraction and Category Prediction in Non-IID Datasets. Future Internet. 2024; 16(3):95. https://doi.org/10.3390/fi16030095
Chicago/Turabian StyleLai, Ying-Hsun, Shin-Yeh Chen, Wen-Chi Chou, Hua-Yang Hsu, and Han-Chieh Chao. 2024. "Personalized Federated Learning with Adaptive Feature Extraction and Category Prediction in Non-IID Datasets" Future Internet 16, no. 3: 95. https://doi.org/10.3390/fi16030095
APA StyleLai, Y. -H., Chen, S. -Y., Chou, W. -C., Hsu, H. -Y., & Chao, H. -C. (2024). Personalized Federated Learning with Adaptive Feature Extraction and Category Prediction in Non-IID Datasets. Future Internet, 16(3), 95. https://doi.org/10.3390/fi16030095