
An Object Classification Approach for Autonomous Vehicles Using Machine Learning Techniques



Abstract
:1. Introduction
2. Literature Review
- Some investigations produced results that showed a considerable increase in the amount of time needed for processing.
- Some studies fail in adverse weather situations such as rain.
- They did not perform well in the classification of large-scale objects.
- When it comes to categorizing large-scale items, several of the earlier studies did not perform particularly well.
- Some studies have a high misclassification rate for small objects compared to larger ones.
- There is still room for improving the accuracy measures achieved by the current studies, which results in a higher overall quality of the findings.
3. Background
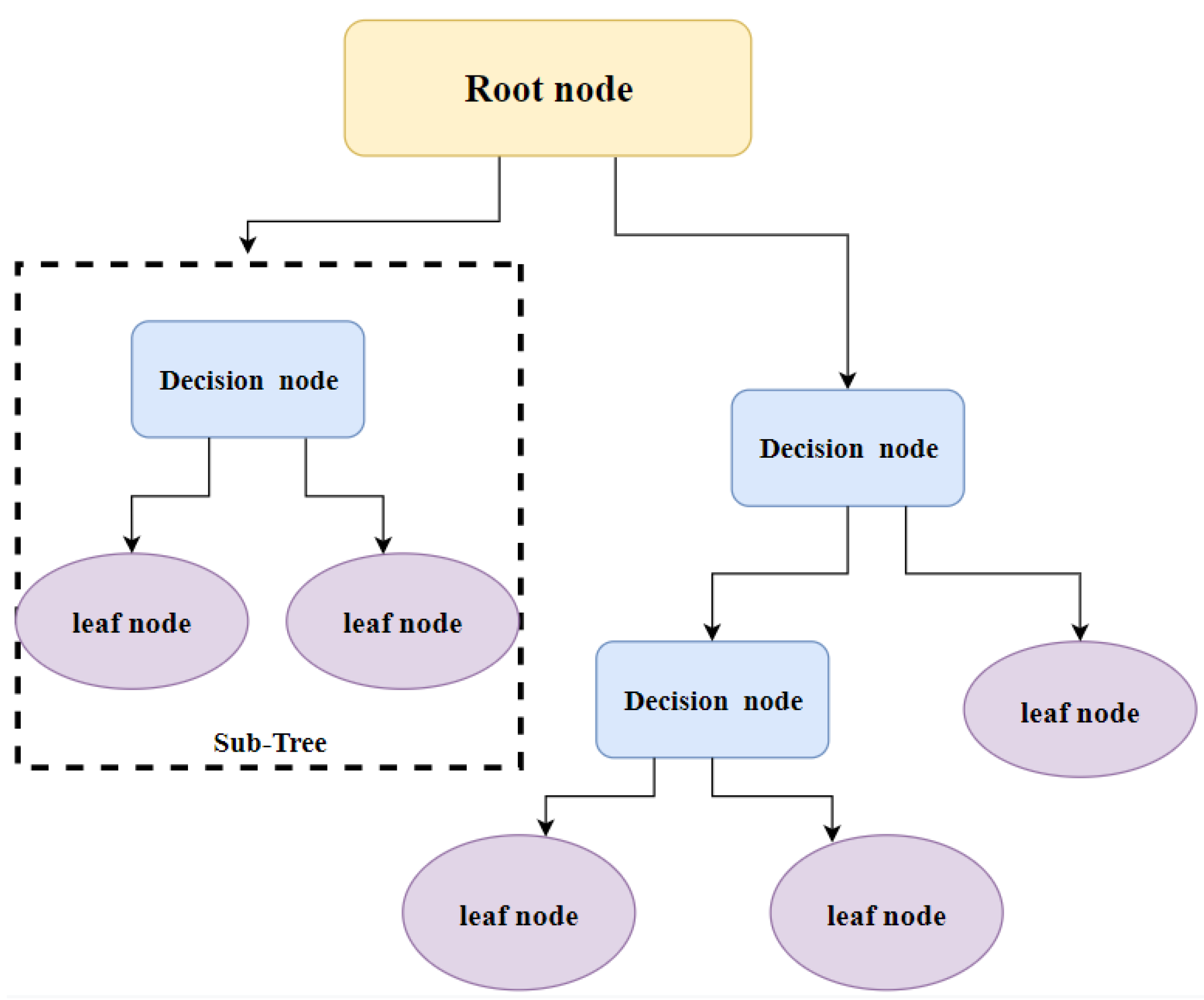
3.1. Decision Tree (DT)
3.2. Naive Bayes (NB)
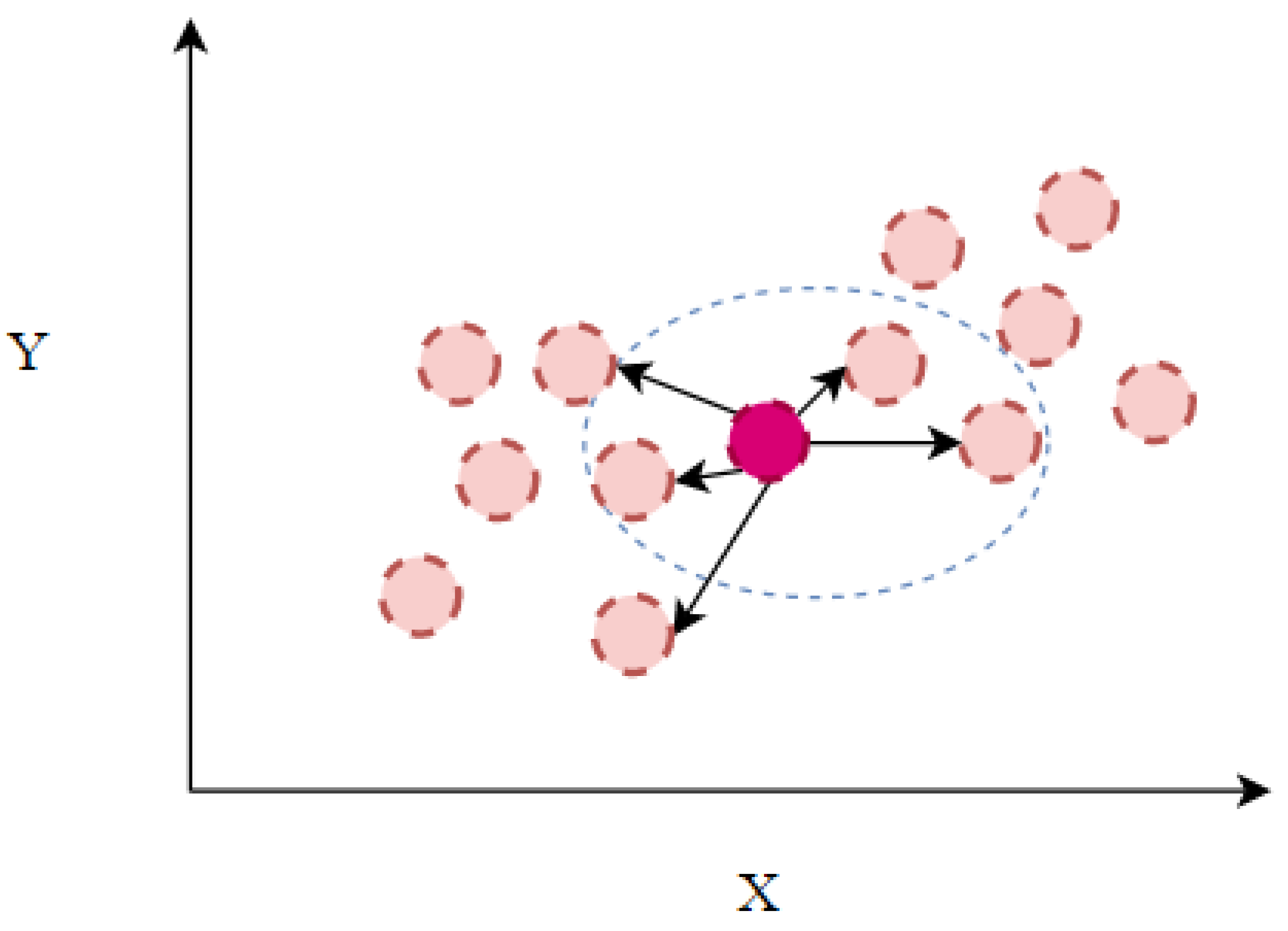
3.3. K-Nearest Neighbor (KNN)
3.4. Stochastic Gradient Descent (SGD)
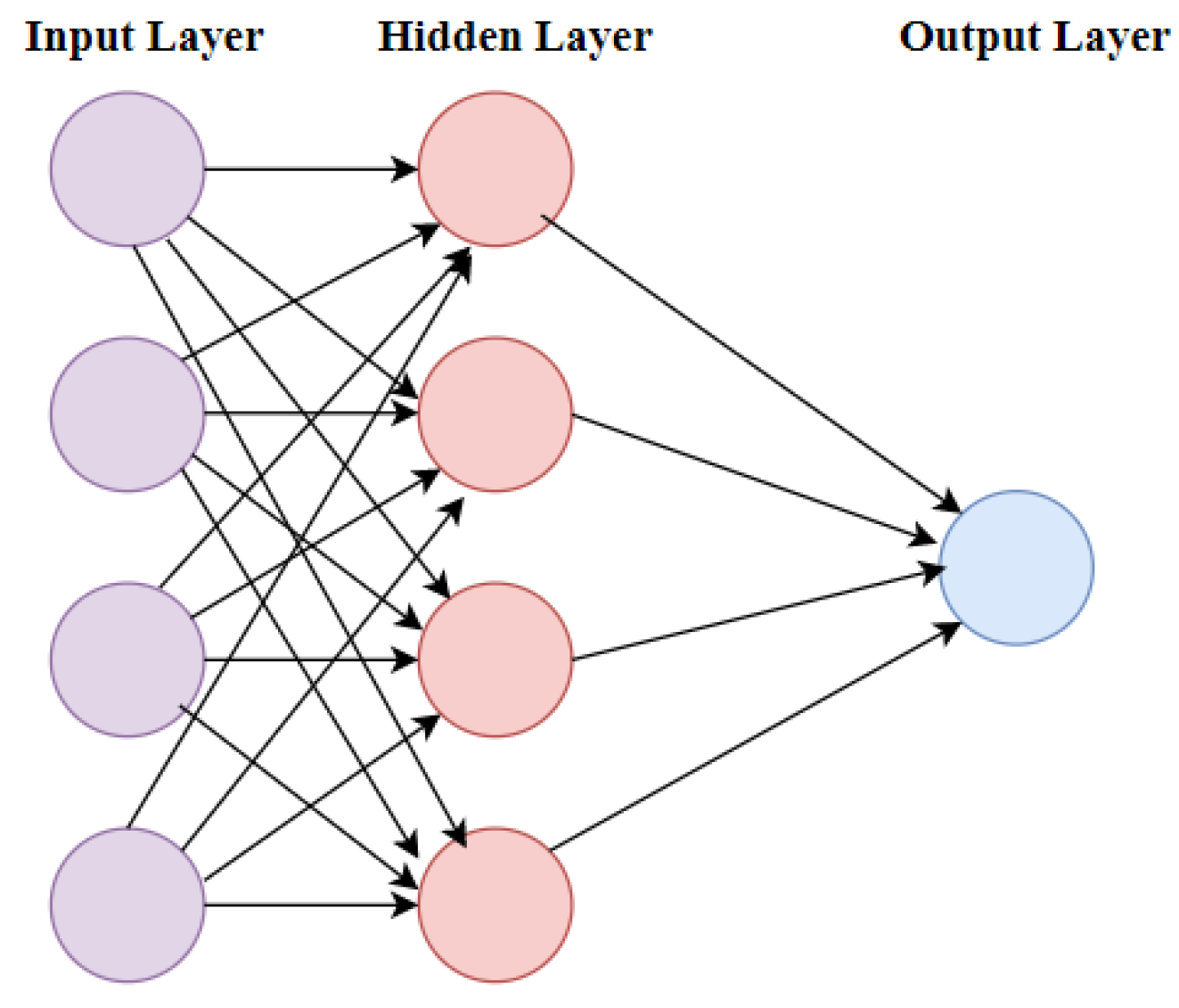
3.5. Multi-Layer Perceptron (MLP)
3.6. Logistic Regression (LR)
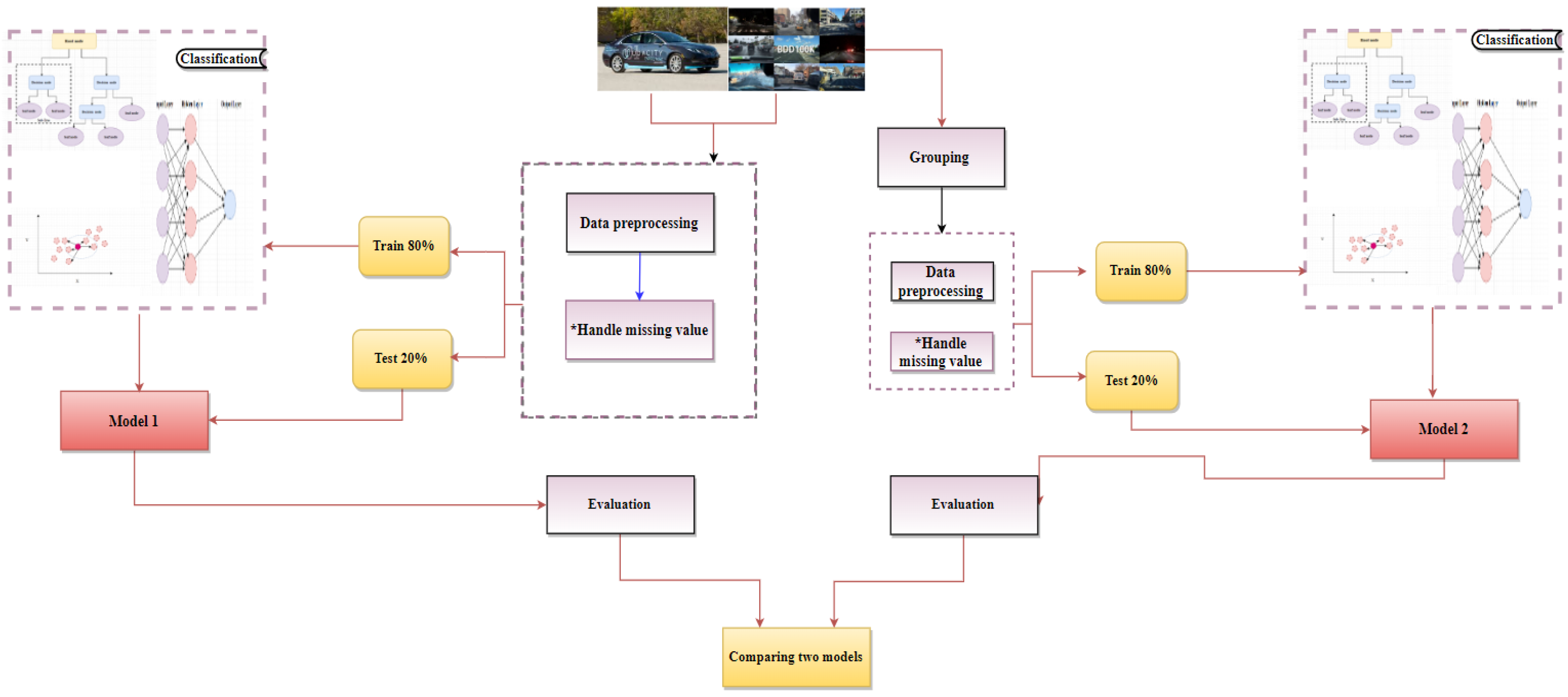
4. The Proposed Object Detection Approach for Autonomous Vehicles
4.1. Data Collection
4.2. Data Preparation
4.3. Grouping Modification
5. Experiments and Results
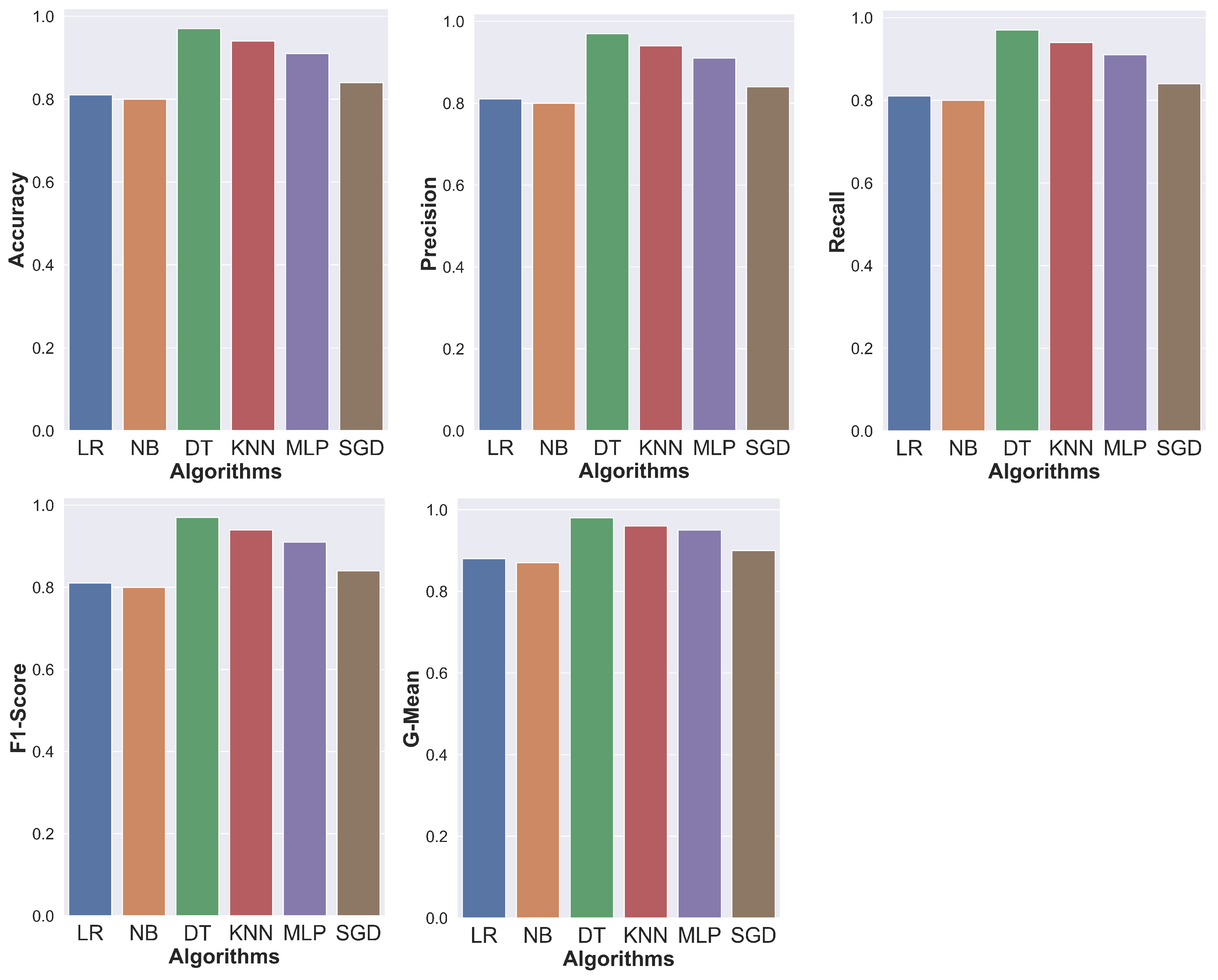
5.1. Evaluation of Classification Algorithms on the Udacity Dataset
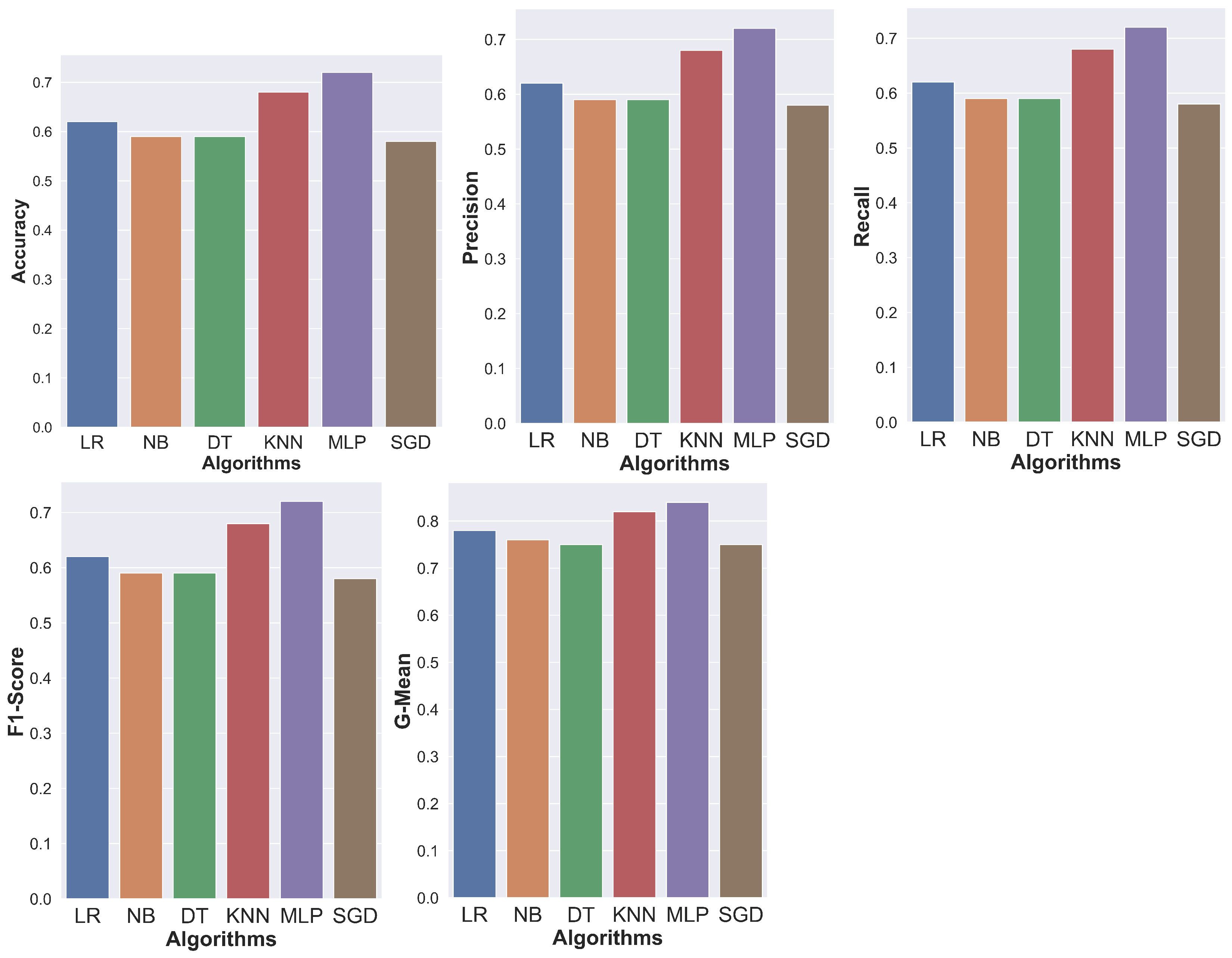
5.2. Evaluation of Classification Algorithms on the BDD100K Dataset
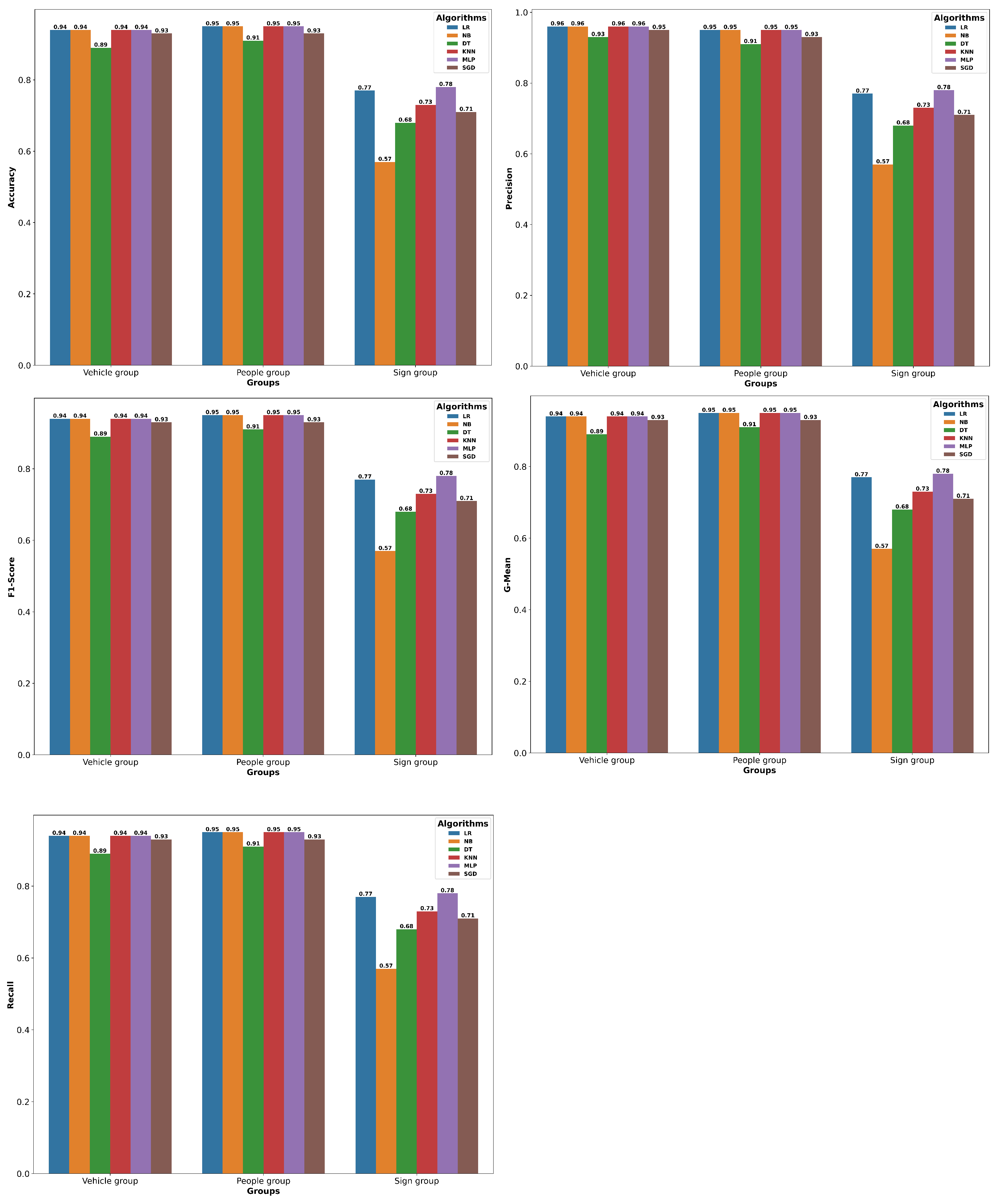
5.3. Evaluation of the Grouped Dataset
5.4. Comparison Results
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hopkins, D.; Schwanen, T. Talking about Automated Vehicles: What Do Levels of Automation Do? Technol. Soc. 2021, 64, 101488. [Google Scholar] [CrossRef]
- Mai, N.A.M.; Duthon, P.; Khoudour, L.; Crouzil, A.; Velastin, S.A. 3D Object Detection with SLS-Fusion Network in Foggy Weather Conditions. Sensors 2021, 21, 6711. [Google Scholar] [CrossRef] [PubMed]
- Hnewa, M.; Radha, H. Object Detection Under Rainy Conditions for Autonomous Vehicles: A Review of State-of-the-Art and Emerging Techniques. IEEE Signal Process. Mag. 2021, 38, 53–67. [Google Scholar] [CrossRef]
- Mirza, M.; Buerkle, C.; Jarquin, J.; Opitz, M.; Oboril, F.; Scholl, K.-U.; Bischof, H. Robustness of Object Detectors in Degrading Weather Conditions. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Virdi, N. Development of a Connected and Autonomous Vehicle Modelling Framework, with Implementation in Evaluating Transport Network Impacts and Safety; University of New South Wales: Kensington, NSW, Australia, 2020. [Google Scholar]
- Eraqi, H.M.; Soliman, K.; Said, D.; Elezaby, O.R.; Moustafa, M.N.; Abdelgawad, H. Automatic Roadway Features Detection with Oriented Object Detection. Appl. Sci. 2021, 11, 3531. [Google Scholar] [CrossRef]
- El-Hassan, F.T. Experimenting With Sensors of a Low-Cost Prototype of an Autonomous Vehicle. IEEE Sens. J. 2020, 20, 13131–13138. [Google Scholar] [CrossRef]
- Rebanal, J.C. Self-Localization of Autonomous Vehicles Using Landmark Object Detection; University of California: Los Angeles, CA, USA, 2020. [Google Scholar]
- Younes, M.B.; Boukerche, A. Traffic efficiency applications over downtown roads: A new challenge for intelligent connected vehicles. Acm Comput. Surv. CSUR 2020, 53, 1–30. [Google Scholar] [CrossRef]
- Younes, M.B. Towards Green Driving: A Review of Efficient Driving Techniques. World Electr. Veh. J. 2022, 13, 103. [Google Scholar] [CrossRef]
- Perumal, P.S.; Sujasree, M.; Chavhan, S.; Gupta, D.; Mukthineni, V.; Shimgekar, S.R.; Khanna, A.; Fortino, G. An Insight into Crash Avoidance and Overtaking Advice Systems for Autonomous Vehicles: A Review, Challenges and Solutions. Eng. Appl. Artif. Intell. 2021, 104, 104406. [Google Scholar] [CrossRef]
- Bachute, M.R.; Subhedar, J.M. Autonomous Driving Architectures: Insights of Machine Learning and Deep Learning Algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Al-refai, G.; Al-refai, M. Road Object Detection Using Yolov3 and Kitti Dataset. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 1–7. [Google Scholar] [CrossRef]
- Qaddoura, R.; Bani Younes, M.; Boukerche, A. November. Predicting traffic characteristics of real road scenarios in Jordan and Gulf region. In Proceedings of the 17th ACM Symposium on QoS and Security for Wireless and Mobile Networks, Alicante, Spain, 22–26 November 2021; pp. 115–121. [Google Scholar]
- Qaddoura, R.; Younes, M.B. Temporal prediction of traffic characteristics on real road scenarios in Amman. J. Ambient. Intell. Humaniz. Comput. 2022, 1–16. [Google Scholar] [CrossRef]
- Kajiwara, S. Evaluation of Driver Status in Autonomous Vehicles: Using Thermal Infrared Imaging and Other Physiological Measurements. Int. J. Veh. Inf. Commun. Syst. 2019, 4, 232–241. [Google Scholar] [CrossRef]
- Suriya Prasath, G.D.; Rahgul Poopathi, M.K.; Sarvesh, P.; Samuel, A. Application of Machine Learning Algorithms in Autonomous Vehicles Navigation System. IOP Conf. Ser. Mater. Sci. Eng. 2020, 912, 62028. [Google Scholar] [CrossRef]
- Ilci, V.; Toth, C. High Definition 3D Map Creation Using GNSS/IMU/LiDAR Sensor Integration to Support Autonomous Vehicle Navigation. Sensors 2020, 20, 899. [Google Scholar] [CrossRef] [PubMed]
- Roy, S.; Rahman, M.S. Emergency Vehicle Detection on Heavy Traffic Road from CCTV Footage Using Deep Convolutional Neural Network. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar]
- Owais, M. Traffic Sensor Location Problem: Three Decades of Research. Expert Syst. Appl. 2022, 208, 118134. [Google Scholar] [CrossRef]
- Owais, M.; El deeb, M.; Abbas, Y.A. Distributing Portable Excess Speed Detectors in AL Riyadh City. Int. J. Civ. Eng. 2020, 18, 1301–1314. [Google Scholar] [CrossRef]
- Owais, M.; Matouk, A.E. A Factorization Scheme for Observability Analysis in Transportation Networks. Expert Syst. Appl. 2021, 174, 114727. [Google Scholar] [CrossRef]
- Owais, M.; Moussa, G.S.; Hussain, K.F. Robust Deep Learning Architecture for Traffic Flow Estimation from a Subset of Link Sensors. J. Transp. Eng. Part A Syst. 2020, 146, 1–13. [Google Scholar] [CrossRef]
- Owais, M.; Shahin, A.I. Exact and Heuristics Algorithms for Screen Line Problem in Large Size Networks: Shortest Path-Based Column Generation Approach. IEEE Trans. Intell. Transp. Syst. 2022, 23, 24829–24840. [Google Scholar] [CrossRef]
- Owais, M. Location Strategy for Traffic Emission Remote Sensing Monitors to Capture the Violated Emissions. J. Adv. Transp. 2019, 2019, 6520818. [Google Scholar] [CrossRef] [Green Version]
- Gamba, J. Radar Signal Processing for Autonomous Driving; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Ortiz Castelló, V.O.; Salvador Igual, I.S.; del Tejo Catalá, O.; Perez-Cortes, J.-C. High-Profile VRU Detection on Resource-Constrained Hardware Using YOLOv3/v4 on BDD100K. J. Imaging 2020, 6, 142. [Google Scholar] [CrossRef]
- Boukerche, A.; Hou, Z. Object Detection Using Deep Learning Methods in Traffic Scenarios. ACM Comput. Surv. CSUR 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Mobahi, M.; Sadati, S.H. An Improved Deep Learning Solution for Object Detection in Self-Driving Cars. In Proceedings of the 2020 28th Iranian Conference on Electrical Engineering, ICEE 2020, Tabriz, Iran, 4–6 August 2020; pp. 5–9. [Google Scholar] [CrossRef]
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep Learning-Based Image Recognition for Autonomous Driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Chen, J.; Bai, T. SAANet: Spatial Adaptive Alignment Network for Object Detection in Automatic Driving. Image Vis. Comput. 2020, 94, 103873. [Google Scholar] [CrossRef]
- Kumar, C.R. Research Article A Comparative Study On Machine Learning Algorithms Using Hog Features For Vehicle Tracking Furthermore, Detection. Turk. J. Comput. Math. Educ. 2021, 12, 1676–1679. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A Survey on 3d Object Detection Methods for Autonomous Driving Applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Masmoudi, M.; Ghazzai, H.; Frikha, M.; Massoud, Y. Object Detection Learning Techniques for Autonomous Vehicle Applications. In Proceedings of the 2019 IEEE International Conference on Vehicular Electronics and Safety (ICVES), Cairo, Egypt, 4–6 September 2019; pp. 1–5. [Google Scholar]
- Lidestam, B.; Thorslund, B.; Selander, H.; Näsman, D.; Dahlman, J. In-Car Warnings of Emergency Vehicles Approaching: Effects on Car Drivers’ Propensity to Give Way. Front. Sustain. Cities 2020, 2, 19. [Google Scholar] [CrossRef]
- Agafonov, A.; Yumaganov, A. 3D Objects Detection in an Autonomous Car Driving Problem. In Proceedings of the 2020 International Conference on Information Technology and Nanotechnology (ITNT), Samara, Russia, 26–29 May 2020; pp. 1–5. [Google Scholar]
- Muhammad, L.J.; Algehyne, E.A.; Usman, S.S.; Ahmad, A.; Chakraborty, C.; Mohammed, I.A. Supervised Machine Learning Models for Prediction of COVID-19 Infection Using Epidemiology Dataset. SN Comput. Sci. 2021, 2, 11. [Google Scholar] [CrossRef]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing Different Supervised Machine Learning Algorithms for Disease Prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 281. [Google Scholar] [CrossRef]
- Ahmad, I.S.; Bakar, A.A.; Yaakub, M.R.; Muhammad, S.H. A Survey on Machine Learning Techniques in Movie Revenue Prediction. SN Comput. Sci. 2020, 1, 235. [Google Scholar] [CrossRef]
- Rukmawan, S.H.; Aszhari, F.R.; Rustam, Z.; Pandelaki, J. Cerebral Infarction Classification Using the K-Nearest Neighbor and Naive Bayes Classifier. J. Phys. Conf. Ser. 2021, 1752, 012045. [Google Scholar] [CrossRef]
- Anil Gokte, S. Most Popular Distance Metrics Used in KNN and When to Use Them; Praxis Business School: West Bengal, India, 2020. [Google Scholar]
- Tseng, C.Y.; Wayne, F. Path Finding of Auto Driving Car Using Deep Learning. Ph.D. Thesis, Purdue University Graduate School, West Lafayette, IN, USA, 2020. [Google Scholar]
- Hikmat Haji, S.; Mohsin Abdulazeez, A. Comparison of Optimization Techniques Based on Gradient Descent Algorithm: A Review. PalArch’s J. Archaeol. Egypt/Egyptol. 2021, 18, 2715–2743. [Google Scholar]
- Bento, C. Multilayer Perceptron Explained with a Real-Life Example and Python Code: Sentiment Analysis | by Carolina Bento | Towards Data Science. Towards Data Sci. 2021. [Google Scholar]
- Malik, M.; Nandal, R.; Dalal, S.; Jalglan, V.; Le, D.N. Deriving Driver Behavioral Pattern Analysis and Performance Using Neural Network Approaches. Intell. Autom. Soft Comput. 2022, 32, 87–99. [Google Scholar] [CrossRef]
- Lade, S.; Shrivastav, P.; Waghmare, S.; Hon, S.; Waghmode, S.; Teli, S. Simulation of Self Driving Car Using Deep Learning. In Proceedings of the 2021 International Conference on Emerging Smart Computing and Informatics, ESCI 2021, Thoothukudi, India, 3–5 December 2021; pp. 175–180. [Google Scholar] [CrossRef]
- Roboflow Self Driving Car Dataset. 2020. Available online: https://public.roboflow.com/object-detection/self-driving-car (accessed on 2 February 2023).
- Akosa, J.S. Predictive Accuracy: A Misleading Performance Measure for Highly Imbalanced Data. SAS Glob. Forum 2017, 942, 1–12. [Google Scholar]
- Tohka, J.; van Gils, M. Evaluation of Machine Learning Algorithms for Health and Wellness Applications: A Tutorial. Comput. Biol. Med. 2021, 132, 104324. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Tested Algorithms | Main Objective | Finding | Measures | Limitation | Dataset |
|---|---|---|---|---|---|---|
| (Ortiz Castell´o et al., 2020) [27] | YOLOv3, YOLOv4, MISH, and SWISH | Obtain more accurate models to confidently classify the on-road conditions aimed to decrease limitations in processing capacity and bandwidth | YOLOv4 convolutional layers using the new MISH and SWISH functions produced better results with minor improvements in classification quality; MISH was the function that made the best results | Average, Precision, and AP5 | The expense of an essential rise in processing time | MS-COCO and BDD100K |
| (Mobahi and Sadati, 2020) [29] | SSD, Faster R-CNN, and PyTorch | To improve the classification in a simple way of different scales, especially small ones from the self-driving car | Compared to recent approaches, it performed better in the category of small-scale objects by PyTorch and improves the accuracy of object classification at various scales, especially the small ones | Average, Precision, (IoU), Average Precision (scale) | Detecting large-scale objects | BDD100K |
| (Mai et al., 2021) [2] | SLS-Fusion, Pseudo-LiDAR++ | Investigate the effects of fog on object classification in driving scenarios to increase performance in foggy weather | This result is very satisfying because it indicates the SLS-Fusion algorithm’s robustness while dealing with foggy datasets | Average Precision (AP) over union (IoU) thresholds at 0.5 and 0.7 | Depends on the quality of cameras or LiDAR used | KITTI Clear +MultiFog |
| (Mirza et al., 2021) [4] | YOLOv3, PointPillars, AVODS | Aim to handle autonomous object classification systems in weather circumstances including rain, fog, and snow, and examine how performance degrades when weather conditions degrade | Detectors that work well in clear weather can fail in adverse weather conditions; to cover such situations benchmarking datasets must be improved | Average Precision (AP50) | Fails in adverse weather conditions such as rain | NuScenes, Waymo, KITTI, A*3D |
| (Al-refai and Al-refai, 2020) [13] | YOLOv3-Darknet CNN | The goal is to detect four different categories of pedestrians, vehicles, trucks, and cyclists, and to evaluate dataset images gathered from public roadways using the front-facing camera of a vehicle | YOLOv3-Darknet algorithm has high misclassification rate for small objects like pedestrians and cyclists compared to larger objects like cars | Precision Recall | High rate of misclassification for small objects compared to larger objects | KITTI |
| (Agafonov and Yumaganov, 2020) [37] | AVOD, PointRCNN, and SECOND | The object classification experiment was on a car category to evaluate the performance of the algorithms for 3D object detection and classification on both real and synthetic data | 3D objects detection and classification methods when trained on synthetic data cannot be applied to detect objects with real data | AP on 2D images, AP on BEV projections, AP of 3D objects | Fails to detect 3D objects in realistic synthetic data | KITTI CARLA |
| Algorithms | Accuracy | Precision | F1-Score | G-Mean | Recall |
|---|---|---|---|---|---|
| DT | 97% | 97% | 97% | 98% | 97% |
| NB | 80% | 80% | 80% | 87% | 80% |
| KNN | 94% | 94% | 94% | 96% | 94% |
| MLP | 91% | 91% | 91% | 95% | 91% |
| SGD | 84% | 84% | 84% | 90% | 84% |
| LR | 81% | 81% | 81% | 88% | 81% |
| Algorithms | Accuracy | Precision | F1-Score | G-Mean | Recall |
|---|---|---|---|---|---|
| DT | 59% | 59% | 59% | 75% | 59% |
| NB | 59% | 59% | 59% | 76% | 59% |
| KNN | 68% | 68% | 68% | 82% | 68% |
| MLP | 72% | 72% | 72% | 84% | 72% |
| SGD | 58% | 58% | 58% | 75% | 58% |
| LR | 62% | 62% | 62% | 78% | 62% |
| Groups | Algorithms | Accuracy | Precision | F1-Score | G-Mean | Recall |
|---|---|---|---|---|---|---|
| Vehicle group | DT | 89% | 89% | 89% | 93% | 89% |
| NB | 94% | 94% | 94% | 96% | 94% | |
| KNN | 94% | 94% | 94% | 96% | 94% | |
| MLP | 94% | 94% | 94% | 96% | 94% | |
| SGD | 93% | 93% | 93% | 95% | 93% | |
| LR | 94% | 94% | 94% | 96% | 94% | |
| People group | DT | 91% | 91% | 91% | 91% | 91% |
| NB | 95% | 95% | 95% | 95% | 95% | |
| KNN | 95% | 95% | 95% | 95% | 95% | |
| MLP | 95% | 95% | 95% | 95% | 95% | |
| SGD | 93% | 93% | 93% | 93% | 93% | |
| LR | 95% | 95% | 95% | 95% | 95% | |
| Sign group | DT | 68% | 68% | 68% | 68% | 68% |
| NB | 57% | 57% | 57% | 57% | 57% | |
| KNN | 73% | 73% | 73% | 73% | 73% | |
| MLP | 78% | 78% | 78% | 78% | 78% | |
| SGD | 71% | 71% | 71% | 71% | 71% | |
| LR | 77% | 77% | 77% | 77% | 77% |
| Measure | DT (C. R. Kumar, 2021) | DT (Our Approach) |
|---|---|---|
| Accuracy | 93% | 97% |
| Precision | 90% | 98% |
| F1-score | 90% | 97% |
| G-Mean | X% | 97% |
| Recall | 90% | 97% |
| DT | NB | KNN | MLP | SGD | LR | |
|---|---|---|---|---|---|---|
| Accuracy | 1 | 6 | 2 | 3 | 4 | 5 |
| Precision | 1 | 6 | 2 | 3 | 4 | 5 |
| F1-Score | 1 | 6 | 2 | 3 | 4 | 5 |
| G-Mean | 1 | 6 | 2 | 3 | 4 | 5 |
| Recall | 1 | 6 | 2 | 3 | 4 | 5 |
| Total Rank | 5 | 30 | 10 | 15 | 20 | 25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alqarqaz, M.; Bani Younes, M.; Qaddoura, R. An Object Classification Approach for Autonomous Vehicles Using Machine Learning Techniques. World Electr. Veh. J. 2023, 14, 41. https://doi.org/10.3390/wevj14020041
Alqarqaz M, Bani Younes M, Qaddoura R. An Object Classification Approach for Autonomous Vehicles Using Machine Learning Techniques. World Electric Vehicle Journal. 2023; 14(2):41. https://doi.org/10.3390/wevj14020041
Chicago/Turabian StyleAlqarqaz, Majd, Maram Bani Younes, and Raneem Qaddoura. 2023. "An Object Classification Approach for Autonomous Vehicles Using Machine Learning Techniques" World Electric Vehicle Journal 14, no. 2: 41. https://doi.org/10.3390/wevj14020041
APA StyleAlqarqaz, M., Bani Younes, M., & Qaddoura, R. (2023). An Object Classification Approach for Autonomous Vehicles Using Machine Learning Techniques. World Electric Vehicle Journal, 14(2), 41. https://doi.org/10.3390/wevj14020041