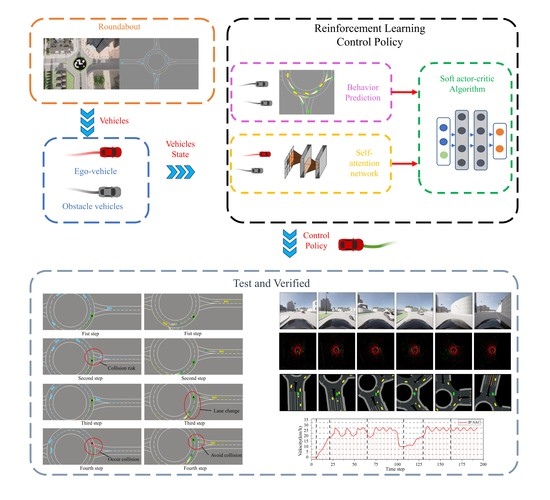
Scenario building is critical for training and evaluating the performance of autonomous vehicle driving policy. The generic approach is to test the safety of the driving policy in a natural environment but, considering the high dimensional characteristics of the environment and the probability of conflicting collision events, thousands of kilometers or multiple time cycles will be required to verify the safety of the policy, and this testing approach is very costly. In this paper, the policy algorithm is trained and improved in a simple low-dimensional simulation scenario and verified in a high-dimensional environment. The low-dimensional simulation environment has a low dimensionality and a higher incidence of conflicting collision events compared with the high-dimensional environment. Moreover, the simulation environment is parallel, and multiple environments can be tested simultaneously to accelerate the training and evaluation process.
2.1. Roundabout Simulation Scenario Construction
The research scenario is an unsignalized roundabout. Most of the autonomous driving algorithms are tested by building simulation scenarios based on natural environments, such as CARLA, Microsoft Air-Sim, NVIDIA Driver Constellation, Google/Waymo Car-Craft, and Baidu AADS. However, all these scenarios suffer from inefficiency and the driving policies are vulnerable to the influence of perception algorithms. The driving policies cannot focus on vehicle decisions, resulting in long training time or failure to converge. Therefore, it is necessary to use a low-dimensional simulation environment to verify the reinforcement learning decision algorithm, which is not affected by the perception algorithms and focuses more on the improvement of the algorithm itself. We compare six mainstream reinforcement learning simulation platforms: TORCS, Highway-ENV, CARLA, SMARTS, Driver-Gym, and SUMO, as shown in
Table 1. After considering low-dimensionality, simulation accuracy, and development time, based on Python/Gym, we choose the Highway-Env [
22] as the low-dimensional simulation platform and CARLA as the high-dimensional simulation platform.
To specifically study the roundabout scenario problem, by referring to the Chinese miniature unsignalized roundabout standards and base the CARLA Town3 map, we simplified and built a 25-m radius roundabout scenario, each vehicle’s dimensions are set at 5 m in length and 1.6 m in width, and roundabout road width of 3.75 m. In the roundabout, the ego-vehicle (autonomous vehicle) makes behavioral actions and interacts with obstacle vehicles. The ego-vehicle, from the starting point to the destination, is shown in
Figure 1.
2.2. Roundabout Obstacle Vehicles Control
In the Highway-Env, the Kinematic Bicycle model is used to simulate the motion of the vehicles, which are controlled using a hierarchical architecture: top-level control and bottom-level control. The bottom control is divided into longitudinal control and lateral control. The longitudinal control uses a simple proportional controller to control vehicle acceleration, as Equation (1).
where
is the vehicle acceleration,
is the controller proportional gain,
is the vehicle reference speed,
is the vehicle current speed.
The lateral control is divided into position control and heading control, which combines the vehicle kinematic model to calculate the front wheel angle of the vehicle through a proportional differential controller.
Lateral position controls are given by Equations (2) and (3):
Heading control is given by Equations (4)–(6):
where
is the lateral velocity,
is the lateral position control gain,
is the lateral offset of the vehicle relative to the lane centerline,
is the heading angle to compensate for the lateral position,
is the current vehicle speed,
is the vehicle target heading,
is the heading required for the look-ahead distance (to predict the turn),
is the vehicle heading transverse swing rate,
is the heading control gain,
is the current vehicle heading, and
is the front wheel angle.
Top-level control determines vehicle behaviors, such as controlling vehicle acceleration, lane keeping, and lane changing. The behavior is divided into longitudinal behavior and lateral behavior according to the behavior.
The longitudinal behavior controls the acceleration of the vehicle with the Intelligent Driver Model (IDM) control model as Equations (7) and (8). The IDM parameters are shown in
Table 2.
where
is the vehicle acceleration,
is the maximum vehicle acceleration,
is the current vehicle speed,
is the target speed,
is the constant velocity parameter,
is the distance from the front vehicle,
is the desired spacing,
is the minimum relative distance between vehicles,
is the safety time interval,
is the maximum deceleration of the vehicle.
The lateral behavior is determined by the MOBIL model based on the acceleration of surrounding vehicles to decide when to change lanes when the following conditions are met, as Equations (9) and (10):
where
c is controlled(ego-) vehicle,
n is the old follower before controlled vehicle lane change,
o is the new follower after controlled vehicle lane change lane change,
is the maximum braking deceleration of the controlled vehicle,
,
is the acceleration of the controlled vehicle before and after the lane change, respectively,
is the conservative factor, and
is the acceleration threshold that triggers whether to change lanes.
To test the effectiveness and reliability of the driving policy, IDM and MOBIL control the obstacle vehicles added in the unsignalized roundabout. The obstacle vehicles are considered being driven by a human driver and appear randomly in the roundabout scenario. Each obstacle vehicle has its own route and destination for simulating vehicles encountered in reality. In a real-life scenario, the obstacle vehicle can be either a vehicle with autonomous driving capabilities or an ordinary vehicle driven by a human. The ego-vehicle senses the surrounding obstacle vehicles through machine vision, LIDAR, and other sensing sensors combined with sensing algorithms, and passes the sensing results (in this paper, the information on the location of the obstacle vehicle is used as a sensing result) to the decision-making policy.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}