1. Introduction
Formal safety assessment (FSA), aimed at enhancing maritime safety, is a structured and systematic methodology. FSA comprises five steps: identification of hazards (step 1), risk analysis (step 2), risk control options (step 3), cost–benefit assessment (step 4) and recommendations for decision-making (step 5). The purpose of the risk analysis in step 2 is a detailed investigation of the causes and initiating events and consequences of the more important accident scenarios identified in step 1. The output from step 2 can be used to identify the high-risk areas so that the effort can be focused to produce effective risk control measures in step 3 of the FSA [
1].
There are several methods that can be used to perform a risk analysis, and different types of risk (i.e. risks to people, the environment or property) can be addressed according to the scope of the FSA. Risk analysis methods comprise multivariate statistical techniques [
2], event tree models [
3], fault tree models [
4], risk contribution tree models [
5], risk matrixes [
6], failure mode and effect analyses [
7], fishbone diagrams [
8] and Bayesian networks [
9]. The scope of the FSA, types of hazards identified in step 1, and the level of data available will all influence which method works best for each specific application.
In most FSA application studies, the event tree model is used to perform the risk analysis and societal risk (SR) is often taken as the risk indicator [
10,
11]. SR reflects the average risk, in terms of fatalities, experienced by a whole group of people exposed to an accident scenario. It is common to represent SR by the frequency–fatality (FN) curve in a two-dimensional FN diagram, which shows the relationship between the cumulative frequency of fatality events and the number of fatalities. The evaluation of the FN curve is carried out by assessing the cumulative frequency of fatality events and the number of fatalities at the same time [
12].
In the context of FSA and the usage of risk analysis, concerns have been raised regarding the accuracy of the methodology, in particular with respect to the uncertainty of input parameters [
13]. Without assessing the significance of the uncertainty in the risk analysis process, the reliability of the risk analysis cannot be examined, which may produce risk control measures in low effect or in vain [
14,
15]. In fact, the uncertainty analysis is required to be carried out in the process of FSA by revised guidelines for FSA for use in the International Maritime Organization (IMO) rule-making process [
1]. The IMO is the United Nations specialized agency with responsibility for the safety and security of shipping and the prevention of marine pollution by ships [
16]. Although the existence of uncertainties in the FSA process is well recognized, there are few studies which quantitatively address the uncertainties [
17]. The purpose of this article is to introduce the suitable uncertainty analysis technique into the process of FSA according to the characteristics of the event tree model, which is used to perform the risk analysis in most FSA application studies.
In general, uncertainty is considered to be of two different types: aleatory and epistemic uncertainties. The aleatory uncertainty arises from randomness due to inherent variability, and the epistemic uncertainty refers to imprecision due to a lack of knowledge or information [
18,
19]. Both types of uncertainty are very common in the risk analysis process of FSA. For example, accident frequencies can often be considered as parameters with aleatory uncertainty due to inherent variability [
20]. In addition, the number of fatalities of each accident scenario, which are obtained by expert elicitation procedures can be taken as parameters with epistemic uncertainty due to incorporating diffuse information by experts [
21].
In the recent FSA application studies, both types of uncertainty are represented by means of probability distributions, which are built by the statistical analysis method of Poisson data and expert statements [
17]. When sufficiently informative data are available, probability distributions are correctly used to represent the aleatory uncertainty. However, when the available information is very scarce, even if the elicitation of expert knowledge is used, a probabilistic representation of epistemic uncertainty may not be possible [
22].
As a result of the limitations associated with a probabilistic representation of epistemic uncertainty, a number of alternative representation frameworks have been proposed. These include fuzzy set theory [
23], possibility theory [
24], interval analysis [
25] and evidence theory [
26]. In addition, several approaches have been proposed to propagate the two types of uncertainty, such as a possibilistic Monte Carlo approach [
27], a possibilistic-scenario-based approach [
28], and an evidence-theory-based hybrid approach [
29]. Among them, possibility theory has received growing attention because of its representation power and its relative mathematical simplicity [
30]. Therefore, possibility theory is used to characterize the epistemic uncertainty in this article. Correspondingly, the possibilistic Monte Carlo approach is selected to propagate aleatory and epistemic uncertainties in the risk analysis process of FSA.
The possibilistic Monte Carlo approach can be used to address the uncertainty of the cumulative frequency of fatality events calculated by the event tree model, which is one component of the FN curve. For the purpose of examining the reliability of the risk analysis, the uncertainty of the number of fatalities, which is the other component of the FN curve, should also be taken into consideration [
31,
32]. In order to make it possible to do so, a confidence-level-based SR is proposed, which is represented by a two-dimensional area for a certain degree of confidence in the FN diagram rather than a single FN curve.
An important aspect of modeling uncertainties lies in the appropriate selection of the time window, which is used for the inclusion of data [
33]. The traditional empirical approach can lead to either a too conservative or non-conservative estimates of the magnitude of uncertainties based on the arbitrary choice of the length of time window [
17]. To reduce the subjectivity of the selection of time window, a method for time window selection is proposed by analyzing the uncertainty and the stability of statistical data.
The contributions of the present study are summarized as follows. First, since uncertainty studies of the risk analysis process of FSA are few, the uncertainty analysis technique is introduced, considering the aleatory and epistemic uncertainties of input parameters. Second, confidence-level-based SR is presented to represent the SR uncertainty in two dimensions so as to identify the high-risk areas in the two-dimensional FN diagram. Third, a method for time window selection is proposed to avoid either too conservative or non-conservative estimates of the magnitude of uncertainties, which is an important aspect of modeling uncertainties.
The remainder of the paper is structured as follows. In
Section 2, the risk analysis process of FSA is described.
Section 3 discusses the process of aleatory and epistemic uncertainty modeling, time window selection and the representation of SR uncertainty. In
Section 4, the uncertainty propagation procedure in the event tree model is described. The case study is discussed and the validation of the proposed methods is made in
Section 5. Findings and limitations are provided in the last section.
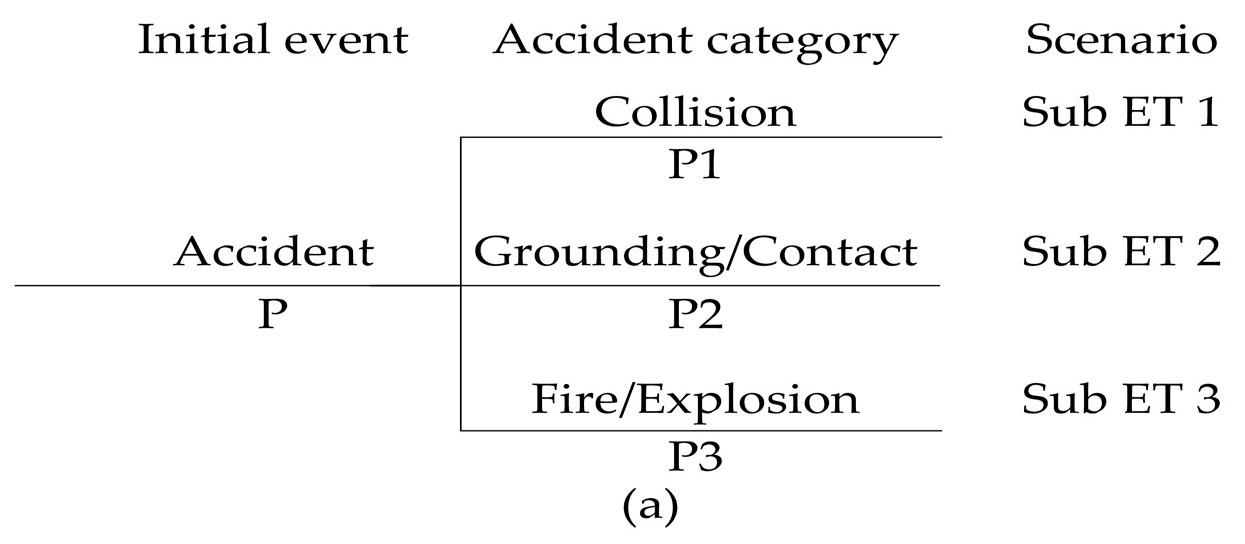
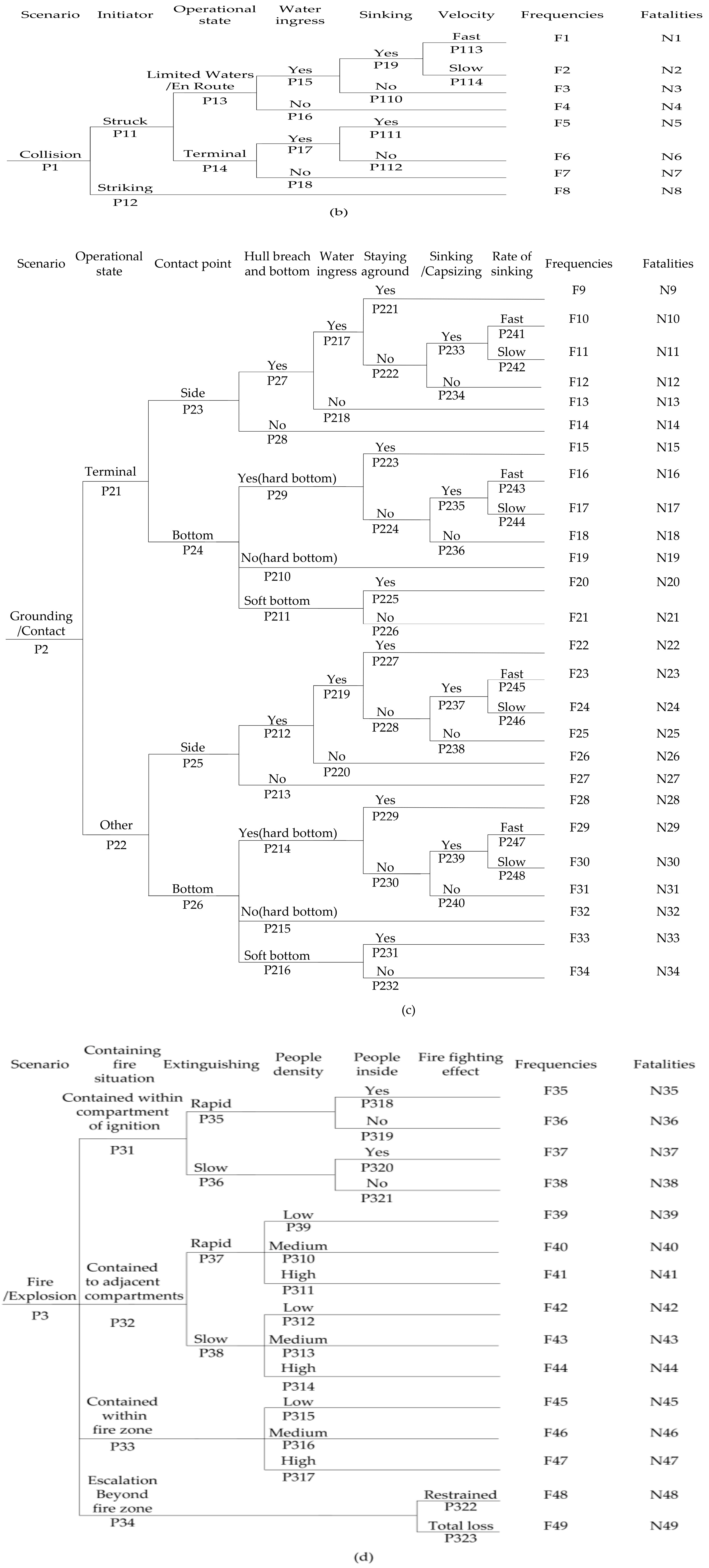
2. Risk Analysis Process of FSA
The risk analysis process of FSA is carried out by analyzing accident frequencies and accident consequences separately. Accident frequencies can be determined by means of statistical analysis on the historical accident data and accident consequences are often analyzed by the event tree model. When more information about the causes of accidents is provided, the determination of accident frequencies can be performed by the fault tree model, which can show the causal relationship between events which singly or in combination occur to cause the occurrence of a type of accident or unintended hazardous outcome [
1]. If the available information about accident frequencies and accident consequences is very scarce, the risk matrix method will be adopted to perform a risk analysis [
34]. A risk matrix displays the basic properties, “consequence” and “frequency” of an adverse risk factor and the aggregate notion of risk by means of a graph. As both the consequence and frequency in the risk matrix are measured by a category scale, applications of the risk matrix are limited in practice [
35]. As mentioned in the introduction section, the event tree model is used to perform the risk analysis in most FSA application studies according to the level of data available.
The event tree model is an inductive logic and diagrammatic method for identifying the various possible outcomes of a given initial event. The frequency of each particular outcome can be considered as the product of an initial event frequency and the conditional probability of the subsequent events along the related branch. Based on these frequencies of outcomes, one can compute the cumulative frequency of outcomes by summing up all of the frequencies of particular outcomes [
36]. The structure of the event tree model, in terms of its branches, is determined by input parameters, which are event frequencies and outcomes caused by a chain of events. Some event frequencies are estimated by sufficient statistical data, which can be statistically verified. The other event frequencies and all outcomes caused by a chain of events are obtained based on qualitative considerations and expert judgement because the available information is very scarce [
37].
As mentioned in the introduction section, SR is often taken as the risk indicator in the risk analysis process of FSA. When dealing with SR, outcomes caused by a chain of events and frequencies of these outcomes in the event tree model refer specifically to the number of fatalities (
N) and the exact frequencies of
N fatalities. It is common to represent SR by the FN curve in the FN diagram, which shows the cumulative frequencies of events causing
N or more fatalities on the vertical axis against the number of fatalities (
N) on the horizontal axis. Based on the outcomes and their frequencies in the event tree model, the cumulative frequencies of events causing
N or more fatalities can be calculated by adding all the exact frequencies of
N or more fatalities and plotted in the form of an FN curve [
38].
When the number of fatalities (
N) is set to 0, there is no need to calculate the frequency of
N fatalities because the abscissa of the FN curve starts at the non-zero value of fatalities on the horizontal axis and increases gradually [
38]. In other words, the FN curve shows the relationship between the cumulative frequencies of events causing
N or more fatalities and non-zero values of fatalities (
N) in a two-dimensional diagram. In most FSA application studies, accident consequences are specified by expert judgement considering casualty reports, observation in model tests, as well as numerical investigations because of the uncertainty and the potentiality of the accident occurrence [
17]. It should be noted that the focus of this article is on the uncertainty analysis of the estimated risk in FSA studies, which has been carried out. Thus, the event tree model and all its input parameters have already been provided and described in FSA application studies.
3. Handling Uncertainties in the Risk Analysis Process
3.1. Aleatory and Epistemic Uncertainty Modeling
When using the event tree model to perform the risk analysis in step 2 of the FSA, input parameters are event frequencies and outcomes caused by a chain of events. These input parameters can be categorized into two types in the uncertainty analysis. If the uncertainty of input parameters arises from randomness due to inherent variability, these input parameters can be categorized as input parameters with aleatory uncertainty, such as event frequencies estimated by sufficient statistical data [
17]. When the uncertainty of the input parameters refers to imprecision due to a lack of knowledge or information, these input parameters can be categorized as input parameters with epistemic uncertainty, such as event frequencies and outcomes obtained by expert judgement [
39].
Aleatory and epistemic uncertainties require different mathematical representations. Probability distributions are assigned to represent aleatory uncertainties when there is sufficient information for statistical analysis. In the situation that the available information is very scarce, even if one adopts the elicitation of expert knowledge to incorporate diffuse information, possibility distributions are used to model the epistemic uncertainty.
The probabilistic uncertainty modeling depends upon the selection of the probability distribution of input parameters, which can be propagated using the Monte Carlo technique along the related branch in the event tree model. Since beta distribution is a suitable model for the random behavior of percentages and proportions defined on the interval [0, 1] [
40], it was selected as the probability distribution for event frequencies with aleatory uncertainty in this study. Beta distribution is parametrized by two shape parameters, denoted by
and
. The mean (
µ) of beta distribution can be expressed by [
40]:
In order to determine the two parameters of beta distribution, we adopt the assumption that the occurrence of events in the event tree model of FSA is Poisson-distributed [
17]. Based on the Poisson distribution assumption, the confidence interval of the number of times an event occurs can be calculated by [
41]:
where
and
are the upper boundary and lower boundary of the confidence interval for the mean value of a Poisson distribution, respectively;
is the number of times an event occurs in an interval, such as the number of marine accidents;
ω is defined as the significance level of the statistics;
is the
th quantile of the chi-squared distribution with
degrees of freedom;
is the
th quantile of the chi-squared distribution with
degrees of freedom; and
and
can be found in the table of chi-squared distribution.
Then the mean value of event frequencies and the corresponding confidence interval can be estimated by:
where
θ is defined as the mean value of event frequencies;
and
are the upper boundary and lower boundary of the confidence interval of
θ, respectively; and
S is the product of the number of experiments and an interval of time, such as ship years. It should be noted that the assumption that the occurrence of events is Poisson-distributed does not conflict with the selection of beta distribution to model the aleatory uncertainty of event frequencies, because the objects modeled are different.
Then the two parameters of beta distribution can be determined when the mean value (
θ) and bounds of the confidence interval (
and
) calculated by the Poisson distribution are regarded as the beta distribution’s mean value (
µ) and the bounds of the confidence interval under the same confidence level [
17]. The confidence interval of the beta distribution, which is parametrized by
ω,
and
can be obtained by the software @RISK [
42]. In other words, under the constraints of Equation (1), the two parameters of beta distribution can be estimated roughly through the enumeration method to make the confidence interval of the beta distribution deviate slightly from the confidence interval calculated by the Poisson distribution under the same confidence level (
ω).
For input parameters with epistemic uncertainty, we use symmetric triangular distributions to model the epistemic uncertainty. As described in
Section 2, values for these input parameters are estimated by expert judgement as crisp values. According to the interpretation of uncertainty in these parameters, value ranges of these input parameters can also be estimated roughly. Based on the crisp values and their approximate ranges, symmetric triangular distributions can be formed by introducing an as small as possible uncertainty. When there are more interpretations of these input parameters, the selection of other possibilistic distributions is possible. Using different possibilistic distributions to model the epistemic uncertainty will lead to relatively small differences in uncertainty quantifications. The symmetric triangular distribution was parametrized by three parameters, denoted by lower limit
, upper limit
and mode
. Also,
equals the average value of
and
. We used the crisp values of input parameters as the mode
, which has a membership value of one. Then we assigned symmetric triangular distributions to input parameters with epistemic uncertainty according to the interpretation of uncertainty in these parameters.
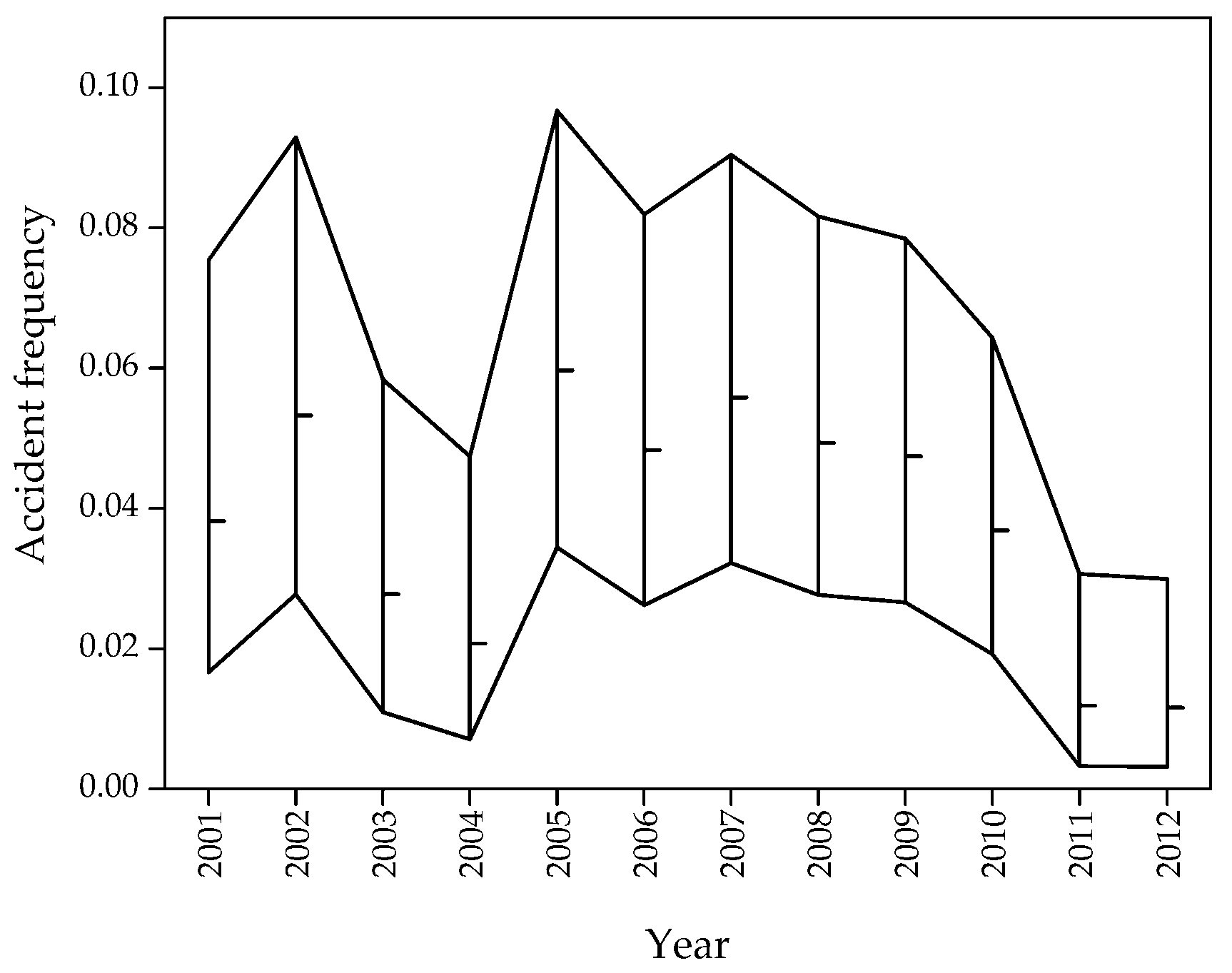
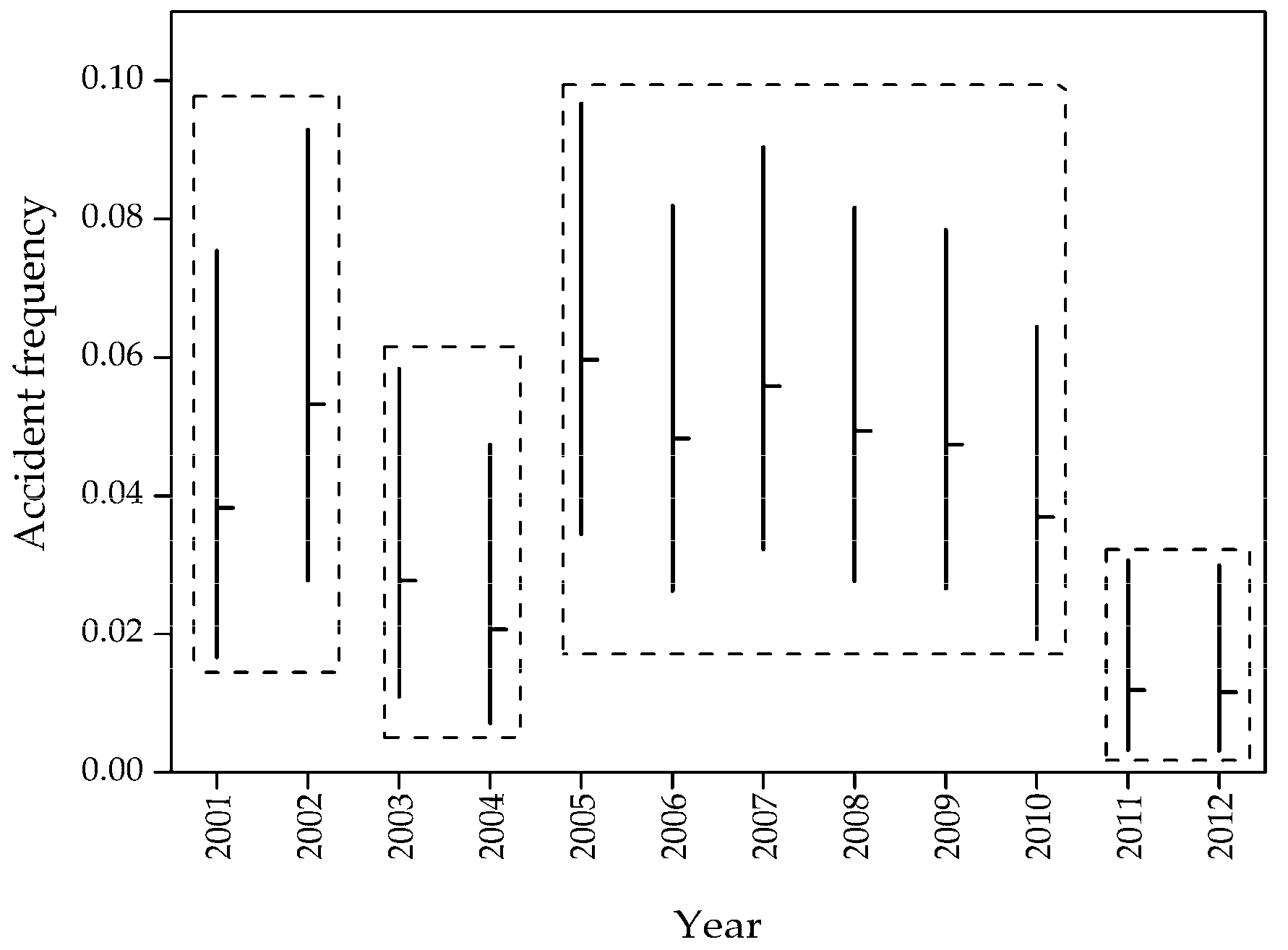
3.2. A Method for Time Window Selection
Although the length of time window is an important factor for modeling the uncertainty of input parameters, it has received little empirical study. The time window can be taken as the time interval for which historical data are collected [
43]. The longer the time window is, the more informative the data for statistical analysis, and the more accurate uncertainty modeling is. There are also indications that more recent statistics represent a more conclusive database than old statistics reflecting recent technical or operational developments, new requirements, or specific arrangements on ships being analyzed. To coordinate the contradiction described above, the uncertainty and the stability of statistical data are used as the two indexes to determine the optimal length of time window, over which the uncertainty of input parameters cannot be estimated too conservatively or non-conservatively.
When event frequencies are listed in time order, a time series can be built up. Through the uncertainty analysis of the time series, each individual value of a time series is no longer an exact value but an interval of possible values, which is defined as an uncertain time series. The confidence interval of each individual value of the time series under a certain level of confidence can be calculated according to Equations (2) and (3).
With respect to the stability of statistical data, the sliding window method is used to implement the segmentation of uncertain time series, which aggregates the relatively concentrative confidence interval. Each of the segments represents a level of event frequencies. The sliding window method takes the first point in time as the first segment and continues to expand until the value at a certain point in time goes beyond the confidence interval of a previous segment. This point in time is taken as the beginning of the next segment. The above process repeats until it comes to the end of the uncertain time series. When a segment only contains one point in time, this point in time should be placed into the adjacent segment which has a smaller difference with the value at this point in time according to the orderliness and the continuity of the time series. After the segmentation of the uncertain time series, the closest segmentation to the research date is taken as the optimal time window used for modeling the uncertainty of the input parameters.
Whether the value at a certain point in time goes beyond the confidence interval of a previous segment is the condition for the segmentation. According to the orderliness and the continuity of the time series, when the value at a certain point in time goes beyond the confidence interval of a previous segment under a certain level of confidence, it means that the value at a certain point in time changes a lot compared with the previous segment. In other words, the value at a certain point in time still changes aside from the random fluctuation of data and it is reasonable to consider this point in time as the beginning of the next segment under a certain level of confidence.
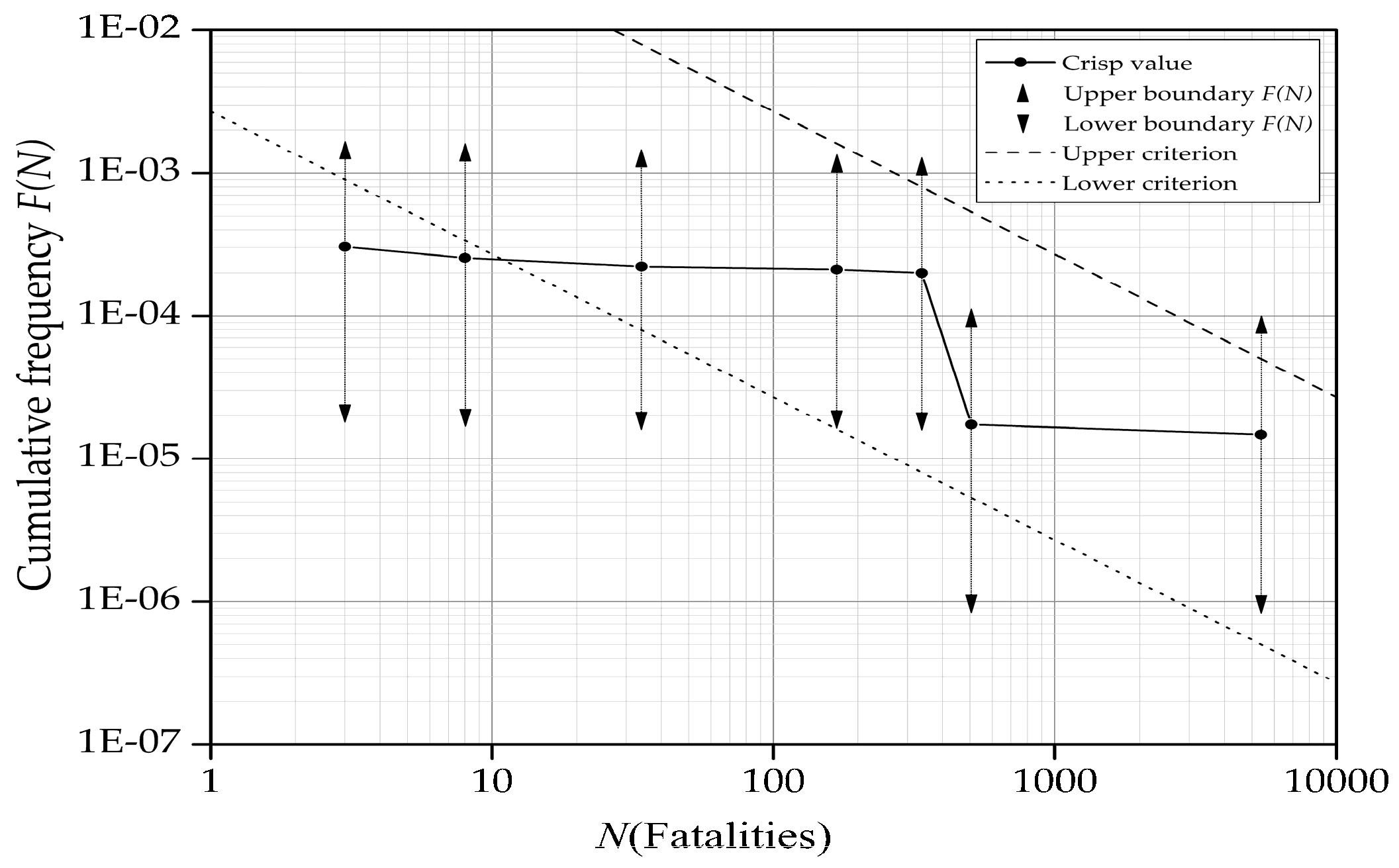
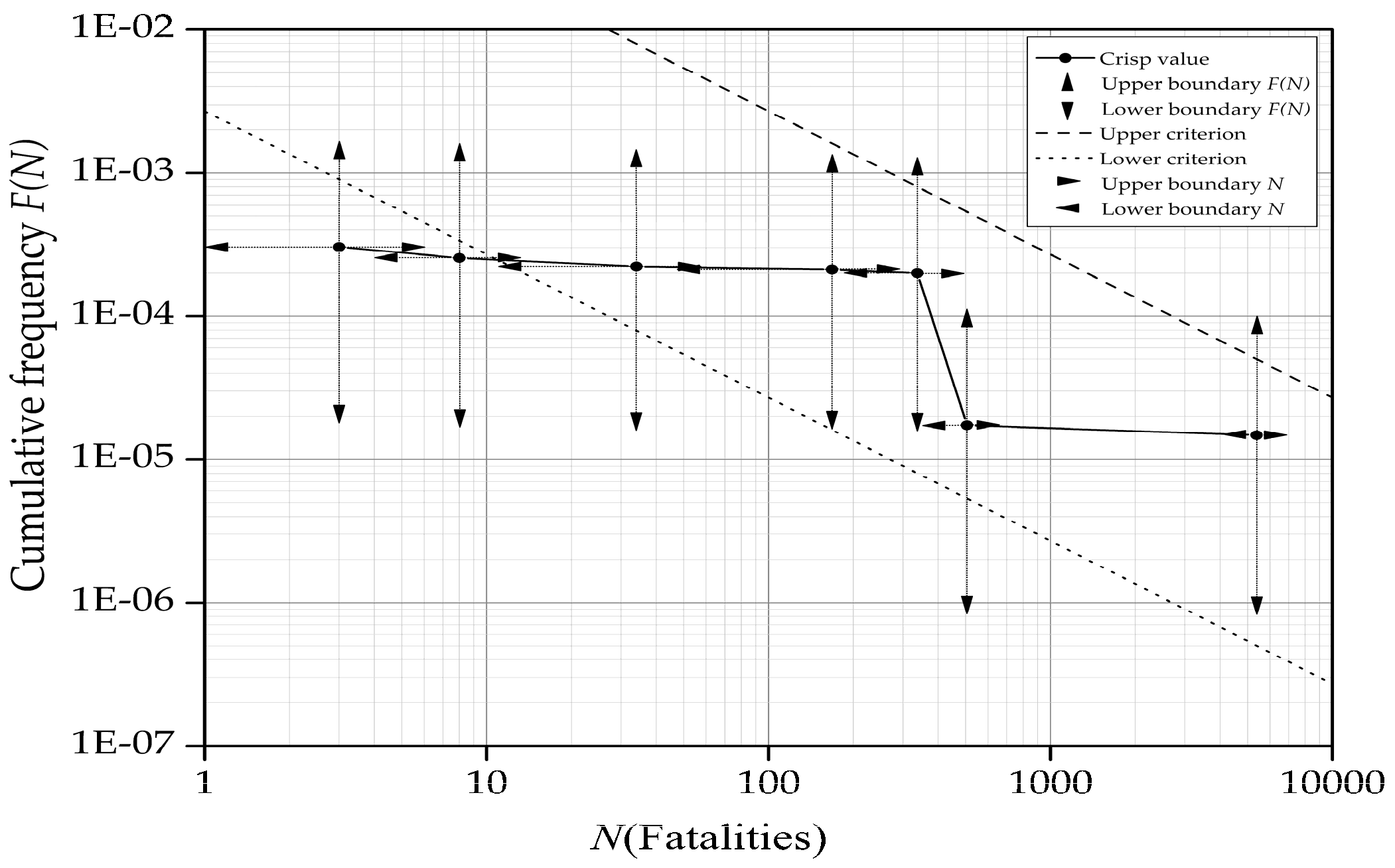
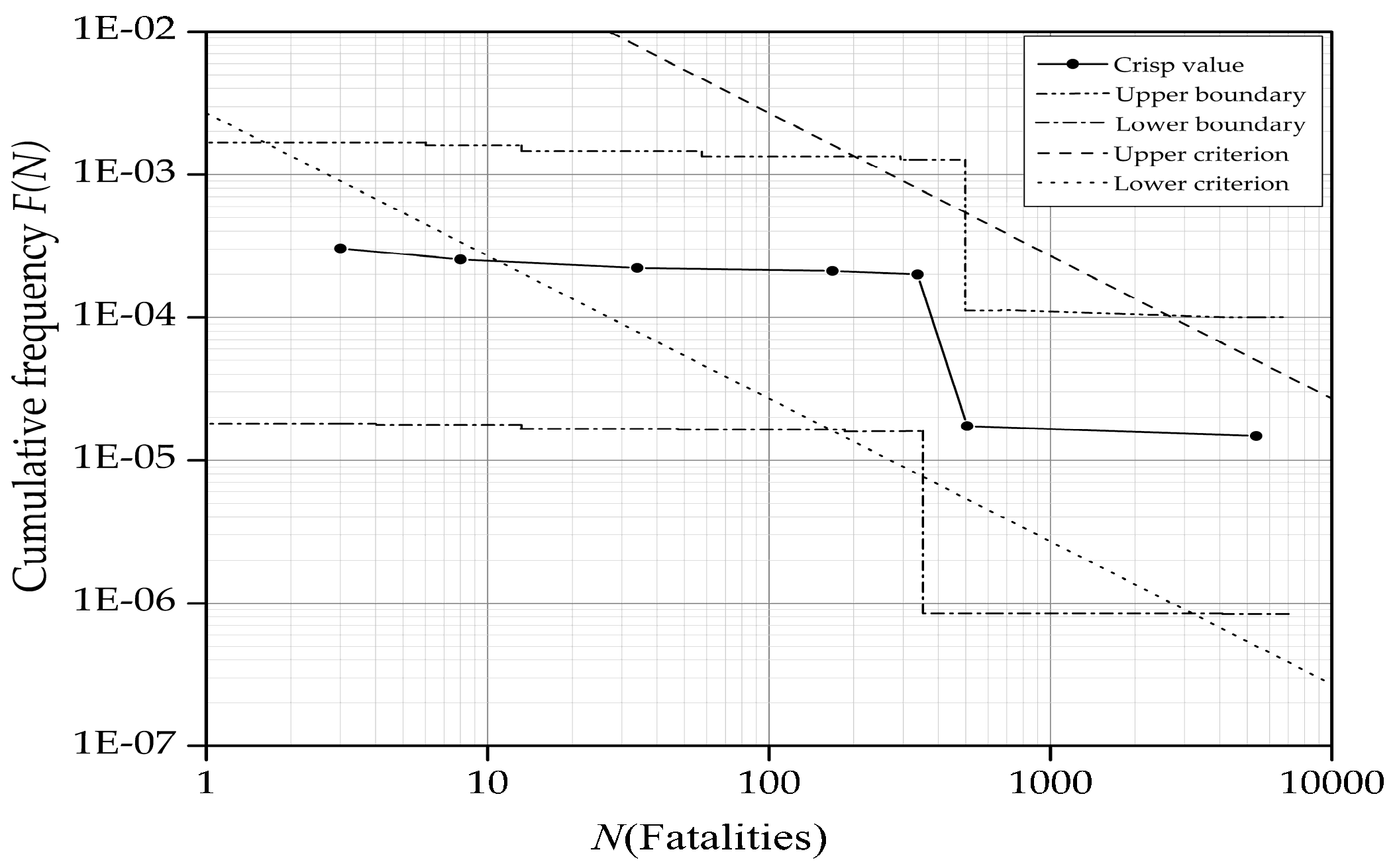
3.3. The Representation of Societal Risk Uncertainty
As described in the introductory section, SR is often taken as the risk indicator in most FSA application studies and it is common to represent SR by the FN curve. The evaluation of the FN curve can be carried out by assessing the cumulative frequency of events causing N or more fatalities, denoted by F(N), and the number of fatalities, denoted by N, at the same time. In order to examine the reliability of the FN curve evaluation, confidence level based SR is put up to consider F(N) and N as fuzzy variables and to represent the SR uncertainty in two dimensions in the FN diagram. Specifically, α-cuts of F(N) and N are taken as the confidence interval in the process of quantifying the SR uncertainty according to the possibility theory.
In the possibility theory, for each set
A contained in the universe of discourse
UC of the variable
C, the
α-cut of
C is defined as
Aα and it is possible to obtain the confidence level of the interval
Aα by the possibility measure
and the necessary measure
from the possibilistic distribution
of
C, by [
18]:
If we replace
A with
Aα, then we have:
According to the definition of the possibility measure
and the necessary measure
, we get
and
. Through proper simplification, we thus have
As can be seen from Equation (6), Aα can be taken as the confidence interval with a confidence degree of (1 − α). Thus, uncertainties of SR can be quantified as confidence intervals, α-cuts of F(N) and N, on the vertical and horizontal orientation in the FN diagram, respectively. It should be noted that α-cuts of F(N) and N can be plotted on the same FN diagram with the same degree of confidence.
4. Uncertainty Propagation Procedure
Let us consider the event tree model whose output is a function
f(
x1,
x2, ...,
xI,
y1,
y2, …,
yJ) of (
I +
J) input variables, which are ordered in such a way that the first
I variables are described by random variables (
X1,
X2, …,
XI) and the following
J variables are characterized by fuzzy numbers (
Y1,
Y2, …,
YJ). The propagation of such mixed uncertainty information can be performed by the Monte Carlo technique combined with the
α-cuts for fuzzy calculus [
44]. The uncertainty propagation procedure is described as the following steps:
Step 1. Sample the r-th realization of the random variables (X1, X2, …, XI);
Step 2. Select a possibility value α [0:Δα:1] (Δα is the step size, e.g., 0.05) and the corresponding α-cuts of fuzzy numbers (Y1, Y2, …, YJ);
Step 3. Compute the smallest and largest values of , denoted by and , respectively, considering all values located within the α-cut interval for each fuzzy number.
Step 4. Return to step 2 and repeat for another α-cut. After having repeated steps 2–3 for all the α-cuts of interest, the fuzzy random realization of f(x1, x2, …, xI, y1, y2, …, yJ, z1, z2, ..., zK) is obtained as the collection of the values and ;
Step 5. Return to step 1 to generate a new realization of the random variable. An ensemble of realizations of fuzzy intervals is obtained, where r is the number of realizations for random variables (X1, X2, …, XI);
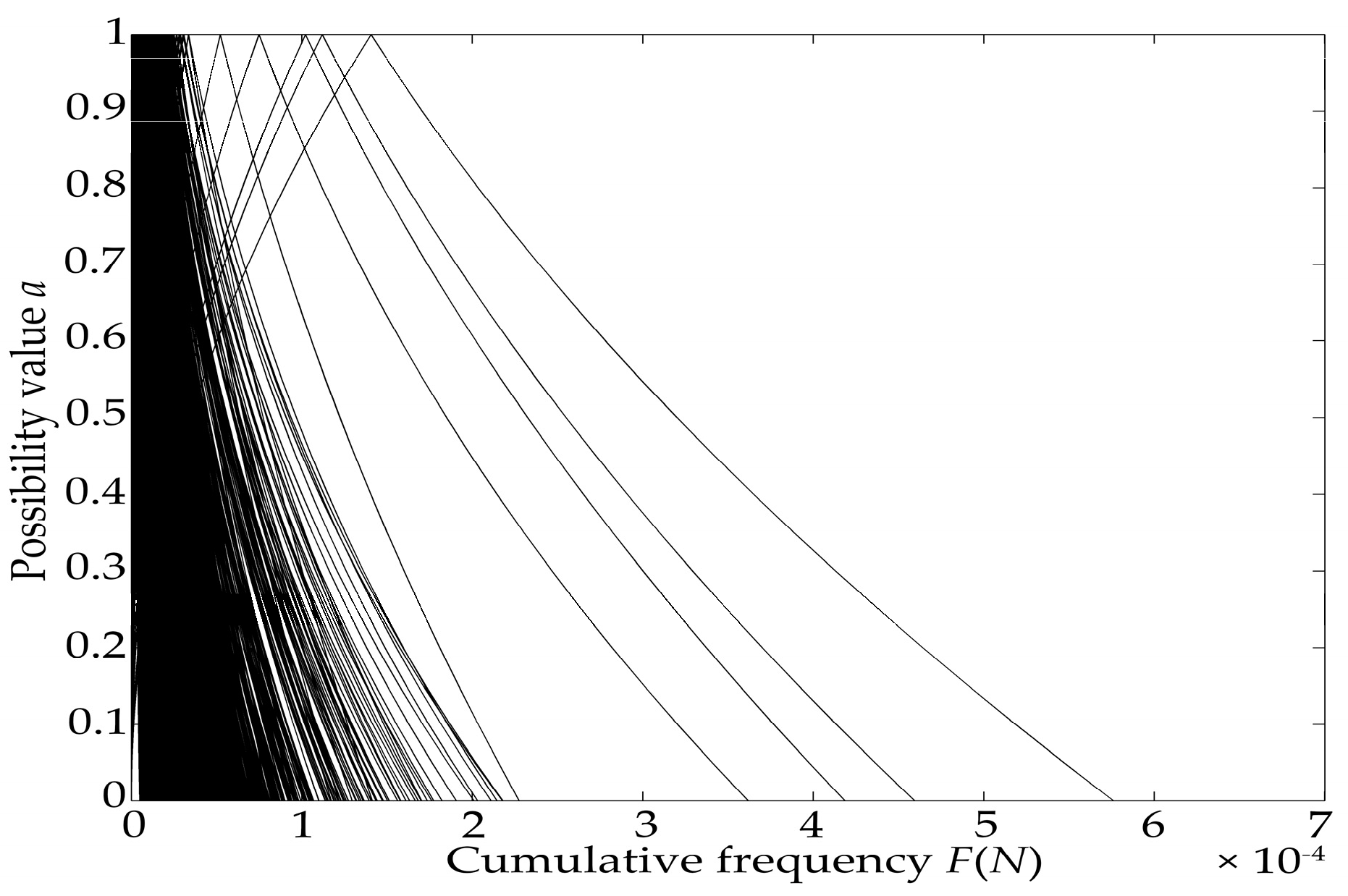
For each value of
α, an imaginary horizontal line is drawn. This line crosses each of the individual fuzzy intervals
twice, and therefore
is obtained. The confidence interval of
f(
x1,
x2, …,
xI,
y1,
y2, …,
yJ,
z1,
z2, …,
zK) for the confidence value (1 −
α) can be determined by a
probability of getting lower and higher values of
and
, respectively [
45].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}