Evaluating the Driving Risk of Near-Crash Events Using a Mixed-Ordered Logit Model



Abstract
:1. Introduction
2. The Definition of a Near-Crash Event
3. Experiment Description and Data Preparation
3.1. Experimental Description
3.1.1. Experimental Design
3.1.2. Experiment Vehicle and Equipment
3.1.3. Participants
3.1.4. Experiment Routes
3.1.5. Experimental Scenarios
3.2. Data Preparation
4. Methodology
4.1. Identification of Driving Risk of Near-Crash Events
4.2. A Mixed-Ordered Logit Model for Driving Risk Levels of Near-Crash Events
5. Results Analysis
5.1. Levels of Driving Risk of Near-Crashes
5.2. Results of the Statistical Model
5.2.1. Comparison of Models
5.2.2. Model Estimates
5.2.3. Margin Effects
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- National Bureau of Statistics. The People’s Republic of China Statistical Yearbook of Road Traffic Accidents 2015; National Bureau of Statistics of China: Wuxi, China, 2016.
- Li, Z.; Liu, P.; Wang, W.; Xu, C. Using support vector machine models for crash injury severity analysis. Accid. Anal. Prev. 2012, 45, 478–486. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhang, G.; Qian, Z.; Tarefder, R.A.; Tian, Z. Investigating driver injury severity patterns in rollover crashes using support vector machine models. Accid. Anal. Prev. 2016, 90, 128–139. [Google Scholar] [CrossRef] [PubMed]
- Iragavarapu, V.; Lord, D.; Fitzpatrick, K. Analysis of injury severity in pedestrian crashes using classification regression trees. In Proceedings of the Transportation Research Board Annual Meeting, Washington, DC, USA, 11–15 January 2015. [Google Scholar]
- Chang, L.Y.; Chien, J.T. Analysis of driver injury severity in truck-involved accidents using a non-parametric classification tree model. Saf. Sci. 2013, 51, 17–22. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, G.; Huang, H.; Wang, J.; Tarefder, R.A. Examining driver injury severity outcomes in rural non-interstate roadway crashes using a hierarchical ordered logit model. Accid. Anal. Prev. 2016, 96, 79. [Google Scholar] [CrossRef] [PubMed]
- Bogue, S.; Paleti, R.; Balan, L. A modified rank ordered logit model to analyze injury severity of occupants in multivehicle crashes. Anal. Methods Accid. Res. 2017, 14, 22–40. [Google Scholar] [CrossRef]
- Guo, F. Near-Crashes as crash surrogate for naturalistic driving studies. Transp. Res. Rec. J. Transp. Res. Board. 2010, 2147, 66–74. [Google Scholar] [CrossRef]
- Tarko, A.; Davis, G.A.; Saunier, N.; Sayed, T. Surrogate Measures of Safety. In Safe Mobility: Challenges, Methodology and Solutions; Emerald Publishing Limited: Bingley, UK, 2018; pp. 383–405. [Google Scholar]
- Zheng, Y.; Wang, J.; Li, X.; Yu, C. Driving risk assessment using cluster analysis based on naturalistic driving data. In Proceedings of the IEEE International Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Young, R.A. Revised odds ratio estimates of secondary tasks: A re-analysis of the 100-car naturalistic driving study data. Sae Tech. Pap. 2015. [Google Scholar] [CrossRef]
- Takeda, K.; Hansen, J.H.L.; Boyraz, P.; Malta, L.; Miyajima, C.; Abut, H. International large-scale vehicle corpora for research on driver behavior on the road. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1609–1623. [Google Scholar] [CrossRef]
- Wu, K.F.; Aguero-Valverde, J.; Jovanis, P.P. Using naturalistic driving data to explore the association between traffic safety-related events and crash risk at driver level. Accid. Anal. Prev. 2014, 72, 210–218. [Google Scholar] [CrossRef] [PubMed]
- Moreno, A.T.; García, A. Use of speed profile as surrogate measure: Effect of traffic calming devices on crosstown road safety performance. Accid. Anal. Prev. 2013, 61, 23–32. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, K.F.; Jovanis, P.P. Screening naturalistic driving study data for safety-critical events. Transp. Res. Rec. J. Transp. Res. Board 2013, 2386, 137–146. [Google Scholar] [CrossRef]
- Guo, F.; Fang, Y. Individual driver risk assessment using naturalistic driving data. Accid. Anal. Prev. 2013, 61, 3–9. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zheng, Y.; Li, X.; Yu, C.; Kodaka, K.; Li, K. Driving risk assessment using near-crash database through data mining of tree-based model. Accid. Anal. Prev. 2015, 84, 54–64. [Google Scholar] [CrossRef] [PubMed]
- Chang, F.; Li, M.; Xu, P.; Zhou, H.; Haque, M.M.; Huang, H. Injury severity of motorcycle riders involved in traffic crashes in Hunan, China: A mixed ordered logit approach. Int. J. Environ. Res. Public Health. 2016, 13, 714. [Google Scholar] [CrossRef] [PubMed]
- Lyu, N.; Deng, C.; Xie, L.; Wu, C.; Duan, Z. A field operational test in China: Exploring the effect of an advanced driver assistance system on driving performance and braking behavior. Transp. Res. Part F Traff. Psychol. Behav. 2018. [Google Scholar] [CrossRef]
- Lyu, N.; Ren, Z.; Duan, Z.; Luo, Y. Analysis of driving behavior characteristics of drivers in Near-crash events. China Saf. Sci. J. 2017, 27, 19–24. (In Chinese) [Google Scholar]
- Lu, G.; Cheng, B.; Lin, Q.; Wang, Y. Quantitative indicator of homeostatic risk perception in car following. Saf. Sci. 2012, 50, 1898–1905. [Google Scholar] [CrossRef]
- Bagdadi, O. Assessing safety critical braking events in naturalistic driving studies. Transp. Res. Part F Traffic Psychol. Behav. 2013, 16, 117–126. [Google Scholar] [CrossRef]
- Tarko, A.; Davis, G.; Saunier, N.; Sayed, T.; Washington, S. White Paper: Surrogate Measures of Safety; Transportation Research Board, National Research Council: Washington, DC, USA, 2009. [Google Scholar]
- Shewhart, W.A.; Wilks, S.S. Cluster Analysis, 5th ed.; Elsevier: New York, NY, USA, 2011. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2011; pp. 76–77. [Google Scholar]
- Young, R.; Seaman, S.; Li, H. The dimensional model of driver demand: Visual-manual tasks. Sae Int. J. Transp. Saf. 2016, 4, 33–71. [Google Scholar] [CrossRef]
- Park, S.; Jang, K.; Park, S.H.; Kim, D.K.; Chon, K.S. Analysis of injury severity in traffic crashes: A case study of korean expressways. KSCE J. Civ. Eng. 2012, 16, 1280–1288. [Google Scholar] [CrossRef]
- Faraway, J.J. Linear Models with R, 2nd ed.; Crc Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Liu, X.; Koirala, H. Ordinal regression analysis: Using generalized ordinal logistic regression models to estimate educational data. J. Mod. Appl. Stat. Methods JMASM 2012, 11, 242–254. [Google Scholar] [CrossRef]
- Heiss, F. Discrete Choice Methods with Simulation; Cambridge University Press: Cambridge, UK, 2003; pp. 688–692. [Google Scholar]
- Wu, C.; Sun, C.; Chu, D.; Huang, Z.; Ma, J.; Li, H. Clustering of several typical behavioral characteristics of commercial vehicle drivers based on gps data mining. Transp. Res. Rec. J. Transp. Res. Board 2016, 2581, 154–163. [Google Scholar] [CrossRef]
- Miyajima, C.; Ukai, H.; Naito, A.; Amata, H.; Kitaoka, N.; Takeda, K. Driver risk evaluation based on acceleration, deceleration, and steering behavior. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Tak, S.; Kim, S.; Yeo, H. Development of a deceleration-based surrogate safety measure for rear-end collision risk. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2435–2445. [Google Scholar] [CrossRef]
- Rakha, H.; El-Shawarby, I.; Setti, J.R. Characterizing driver behavior on signalized intersection approaches at the onset of a yellow-phase trigger. IEEE Trans. Intell. Transp. Syst. 2007, 8, 630–640. [Google Scholar] [CrossRef]
- Qu, X.; Yang, Y.; Liu, Z.; Jin, S.; Weng, J. Potential crash risks of expressway on-ramps and off-ramps: A case study in Beijing, China. Saf. Sci. 2014, 70, 58–62. [Google Scholar] [CrossRef]
- Qu, X.; Meng, Q. A note on hotspot identification for urban expressways. Saf. Sci. 2014, 66, 87–91. [Google Scholar] [CrossRef]
- Ward, H.; Shepherd, N.; Robertson, S.; Thomas, M. Night-Time Accidents: A Scoping Study; Report to The AA Motoring Trust and Rees Jeffreys Road Fund; UCL (University College London): London, UK, 2005. [Google Scholar]
- Guo, F.; Klauer, S.G.; Fang, Y.; Hankey, J.M.; Antin, J.F.; Perez, M. The effects of age on crash risk associated with driver distraction. Int. J. Epidemiol. 2017, 46, 258–265. [Google Scholar] [CrossRef] [PubMed]
- Ko, M.; Park, B.J.; Wu, L.; Walden, T.D. Exploring the relationship between driver errors and age in vehicle crash data. In Proceedings of the Transportation Research Board Annual Meeting, Washington, DC, USA, 11–15 January 2015. [Google Scholar]
- Curry, A.; Pfeiffer, M.; Durbin, D.; Elliott, M.; Kim, K. Young driver crash rates in new jersey by driving experience, age, and license phase. Driver Exp. 2014, 80, 245–250. [Google Scholar]
- Curry, A.E.; Pfeiffer, M.R.; Durbin, D.R.; Elliott, M.R. Young driver crash rates by licensing age, driving experience, and license phase. Accid. Anal. Prev. 2015, 80, 243–250. [Google Scholar] [CrossRef] [PubMed]





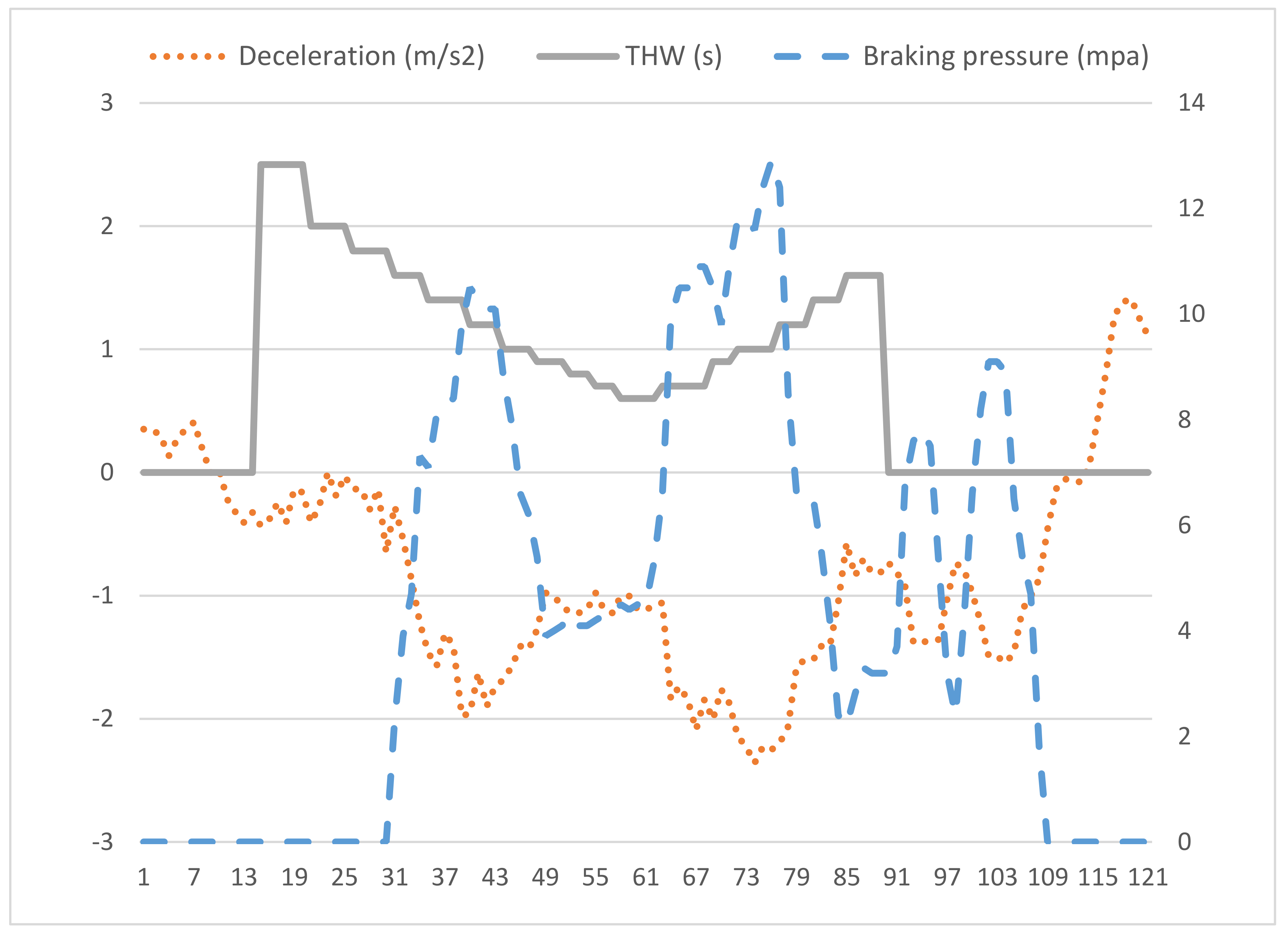{kind=link}
{kind=link}
{kind=link}
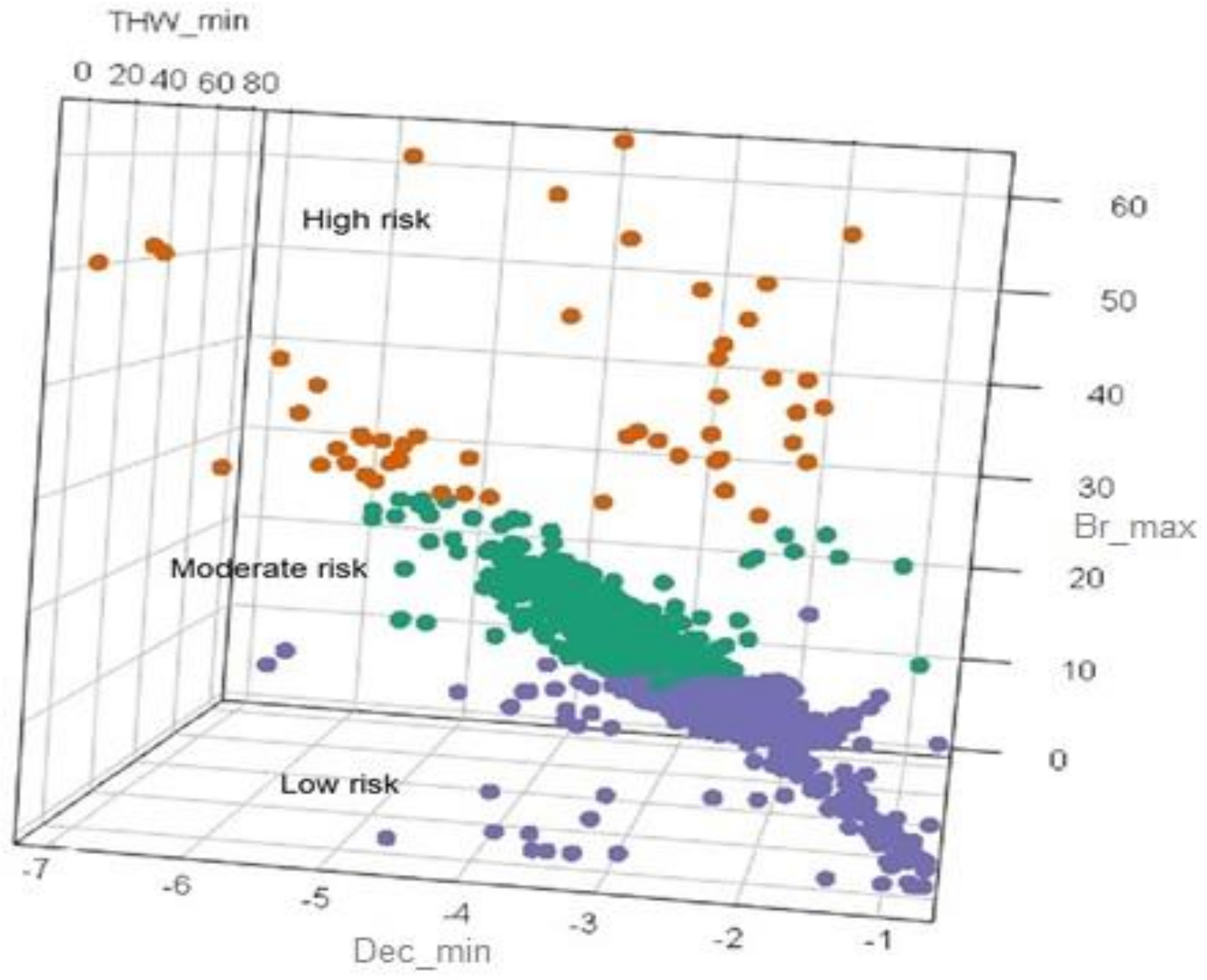{kind=link}
| Total | Age (by Years) | Experience (by Years) | Driving Miles | ||||
|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | ||
| All | 41 | 31.85 | 8.23 | 6.7 | 4.49 | 266.44 | 13.4 |
| Male | 30 | 31.46 | 8.11 | 6.2 | 4.37 | 302.90 | 10.9 |
| Female | 11 | 33.00 | 8.74 | 8 | 4.83 | 158.90 | 17.2 |
| Urban Roads | City Highways | Freeways | Ramps | Tunnels | |
|---|---|---|---|---|---|
| Near-Crash Events | 694 | 515 | 228 | 191 | 42 |
| Factor | Symbol | Data-Type | Source | Description |
|---|---|---|---|---|
| Driving Behavior | ||||
| Starting Speed | Be_Sp | continuous | Signals | Speed when a near-crash event begins (m/s) |
| Deceleration Average | Avr_Dec | continuous | Signals | Average Deceleration (m/s2) |
| Average Speed | Avr_Sped | continuous | Signals | Average Speed (m/s) |
| Time Headway Average | Avr_THW | continuous | Signals | Average Time Headway (s) |
| Braking pressure Average | Avr_Br | continuous | Signals | Average Braking Pressure (MPA) |
| Min Deceleration | Min_Dec | continuous | Signals | Minimum Deceleration (m/s2) |
| Min Time Headway | MinTHW | continuous | Signals | Minimum Time Headway (s) |
| Max Braking pressure | Max_Br | continuous | Signals | Maximum Braking Pressure (MPA) |
| Energy * | Energy | continuous | Signals | Vehicle Kinetic Energy |
| Near-Crash Factors | ||||
| Near-Crash Type | Cra_ty | categorical | Video | Potential Crash Type 1. Subject (head)-object (head) 2. Subject (head)-object (tail) 3. Subject (head)-object (side) 4. Subject (side)-object (side) 5. Subject (side)-object (tail) 6. Pedestrian conflict 7. Road parts 8. Others |
| Near-Crash Reason | NC_reasn | categorical | Video | Near-crash Cause 1. Head vehicle suddenly stopped 2. Traffic lights 3. Traffic density 4. Road maintenance 5. Road changes 6. Road users 7. Subject vehicle turning 8. Object vehicle turning 9. Others |
| Environment and Time Features | ||||
| Wet | Wet | categorical | Video | Road condition 1. Wet 2. Dry |
| Road Type | R_ty | categorical | Video | Road Types 1. Urban roads 2. City Highways 3. Freeways 4. Ramp 5. Tunnel |
| Lane Numbers | Lane_Nu | categorical | Video | Lane numbers 1.1, 2.2, 3.3, 4.4, 5.5 |
| Speed Limit | Sp_lim | categorical | Video | Speed limit 1. 60 2. 80 3. 100–120 |
| Road Congestion | congested | categorical | Video | Is congested? 1. Yes; 0. No |
| Peak Hour | Peak_hrs | categorical | Video | Is it in peak hours (7:30–9:00 am, 4:30–5:30 pm) 1. Yes; 2. No |
| Weather | Weather | categorical | Video | Weather 1. Sunny 2. Rain 3. Cloud |
| Light | Light | categorical | Video | Light 1. Light 2. Dark |
| Weekend | Weekend | categorical | Signals | Weekend 1. Yes 2. No |
| Time of Day | Time_day | categorical | Signals | Time of day 1. 06–12 2. 12–18 3. 18–24 |
| Driver and Driving Experience Factors | ||||
| Age | Age | categorical | Questionnaire | Age 1. Less than 23 2. 23–45 3. More than 45 |
| Gender | Gender | categorical | Questionnaire | Gender 1. Male 2. Female |
| Driving Miles | Driving_miles | continuous | Questionnaire | Driving Miles (miles) |
| Driving Experience | Dri_years | continuous | Questionnaire | Driving years with license (years) |
| Driving Risk Levels | Events Number | Percentile (%) | Mean and SD of Driving Behavior Characteristics | |||||
|---|---|---|---|---|---|---|---|---|
| THW_Min (m/s) | DEC_Min (m/s2) | Br_Max (MPA) | ||||||
| Mean | SD | Mean | SD | Mean | SD | |||
| Low | 531 | 31.8 | 1.80 | 1.47 | −3.13 | 0.52 | 21.28 | 3.12 |
| Moderate | 1087 | 65 | 2.32 | 3.64 | −2.15 | 0.51 | 13.19 | 3.27 |
| High | 52 | 3.2 | 2.05 | 0.87 | −3.83 | 1.48 | 41.00 | 8.46 |
| Factor | Events No | Low | Moderate | High | Factor | Events No | Low | Moderate | High |
|---|---|---|---|---|---|---|---|---|---|
| % | % | % | % | % | % | ||||
| Crash Type | Lane Numbers | ||||||||
| 1. Subject (head)-object (head) | 14 | 28.5 | 71.5 | 0 | 1. One Lane | 91 | 30.6 | 65.1 | 4.3 |
| 2. Subject (head)-object (tail) | 1053 | 31.7 | 65.9 | 2.3 | 2. Two Lanes | 366 | 34 | 63.3 | 2.7 |
| 3. Subject (head)-object (side) | 306 | 33.3 | 64.7 | 1.9 | 3.Three Lanes | 780 | 30 | 67.1 | 3.3 |
| 4. Subject (side)-object (side) | 30 | 23.3 | 70 | 6.6 | 4. Four Lanes | 427 | 33.4 | 62.7 | 4.6 |
| 5. Subject (side)-object (tail) | 12 | 16.6 | 83.3 | 0 | 5. Five Lanes | 14 | 28.5 | 42.85 | 14.2 |
| 6. Pedestrian conflict | 28 | 35.7 | 64.2 | 0 | Time of Day | ||||
| 7. Road parts | 59 | 35.5 | 61.0 | 3.3 | 1.06–12 | 743 | 32.8 | 64.7 | 2.4 |
| 8. Others | 168 | 30.3 | 59.5 | 10.1 | 2.12–18 | 888 | 30.9 | 65.4 | 3.6 |
| Near-Crash Reason | 3.18–24 | 39 | 30.7 | 64.1 | 5.1 | ||||
| 1. Head Vehicle Suddenly Stopped | 247 | 31.5 | 66.3 | 2.0 | Road Congestion | ||||
| 2. Traffic Lights | 153 | 24.8 | 67.3 | 7.8 | 0. No | 883 | 34.8 | 62.9 | 2.1 |
| 3. Traffic Density | 600 | 35.6 | 6.2 | 2.3 | 1. Yes | 787 | 28.3 | 67.4 | 4.1 |
| 4. Fixing Road | 14 | 42.8 | 57.1 | 0 | Peak Hour | ||||
| 5. Road Changes | 59 | 27.1 | 71.1 | 1.6 | 1. Yes | 370 | 30.8 | 67.2 | 1.9 |
| 6. Road Users | 32 | 37.5 | 62.5 | 0 | 2. No | 1300 | 32 | 64.4 | 3.4 |
| 7. Subject Vehicle Turning | 182 | 31.3 | 67.5 | 1.0 | Weather | ||||
| 8. Object Vehicle Turning | 222 | 28.8 | 68.9 | 2.2 | 1. Sunny | 1499 | 32.1 | 65.3 | 2.5 |
| 9. Others | 161 | 28.5 | 63.3 | 8.0 | 2. Rain | 98 | 31.6 | 653 | 3 |
| Road Type | 3. Cloudy | 73 | 24.6 | 60.2 | 15.2 | ||||
| 1. Urban | 694 | 30.2 | 67.2 | 2.5 | Weekend | ||||
| 2. City Highway | 515 | 33.7 | 63.8 | 2.3 | 0. Yes | 429 | 32.4 | 65.9 | 1.6 |
| 3. Freeway | 228 | 28.5 | 64 | 7.4 | 1. No | 1241 | 31.5 | 64.7 | 3.6 |
| 4. Ramp | 191 | 36.7 | 61.8 | 1.6 | Age | ||||
| 5. Tunnel | 42 | 28.6 | 66.7 | 4.7 | 1. less than 23 | 176 | 34.6 | 61.9 | 3.4 |
| Wet | 2. 23–45 | 1200 | 31.4 | 65.3 | 3.2 | ||||
| 1. Dry | 1479 | 32.1 | 65.1 | 2.7 | 3. More than 45 | 172 | 26.7 | 71.5 | 1.7 |
| 2. Wet | 194 | 28.4 | 65.6 | 6.3 | Gender | ||||
| 1. Male | 1165 | 33 | 64.6 | 2.4 | |||||
| 2. Female | 505 | 28.9 | 66.1 | 4.9 | |||||
| Model Statistic | Basic | Mixed |
|---|---|---|
| Observations, n | 1670 | 1670 |
| Significant parameters, k | 9 | 10 |
| Log likelihood at zero, LL (0) | −1255.5942 | −1255.5942 |
| Log likelihood at convergence, LL (β) | −911.19892 | −777.880 |
| AIC | 1639.761 | 1625.054 |
| Adj Likelihood ratio index | 0.207 | 0.307 |
| Degree of Freedom | 14 | 14 |
| Dependent Variable | Coefficient | Standard Error | p > |z| | Z-Statistic | Mean |
|---|---|---|---|---|---|
| Driving Behavior Features | |||||
| Vehicle Kinetic Energy | −4.357163 | 0.2454721 | <0.001 * | −17.75 | 0.40211 |
| Deceleration Average | 1.102912 | 0.0846138 | <0.001 * | 13.03 | −2.042 |
| Near-Crash Features | |||||
| Near-Crash Reason | 4.42814 | ||||
| 1. Head Vehicle Suddenly Stopped | −0.4246619 | −0.2144163 | 0.048 * | −1.98 | |
| 2. Traffic Lights | 0.543326 | 0.2551985 | 0.033 * | 2.13 | |
| 3. Traffic Density a | 0 | 0 | 0 | ||
| 4. Road Fixing | −1.421049 | −0.6403748 | 0.026 * | −2.22 | |
| 7. Subject Vehicle Turning | −0.4656817 | 0.2249775 | 0.038 * | −2.07 | |
| Environment and Time | |||||
| Road Type | |||||
| 1. Urban a | 0 | 0 | 0 | 3.07964 | |
| 2. City Highway | −0.6653231 | 0.1554658 | 0.008 * | −4.28 | |
| 4. Ramp | −0.6350275 | 0.2075957 | 0.002 * | −3.06 | |
| Road Congestion | 0.52874 | ||||
| 0. Yes | 0.2926946 | 0.1613912 | 0.094 ** | 1.98 | |
| 1. No a | 0 | 0 | 0 | ||
| Time of Day | 1.57844 | ||||
| 2.12–18 a | 0 | 0 | 0 | ||
| 3.18–24 | 1.140956 | 0.4467025 | 0.011 * | 2.55 | |
| Weekend | 1.74311 | ||||
| 0. No a | 0 | 0 | 0 | 0 | |
| 1. Yes | −0.740657 | 0.3487634 | 0.081 ** | −2.16 | |
| Driver Demographic and Driving Experience Features | |||||
| Age | 1.99761 | ||||
| 2. 23–45 a | 0 | 0 | 0 | ||
| 3. More than 45 | −0.3049686 | 0.2429392 | −0.084 ** | 2.35 | |
| Driving Mileages | −0.002227 | 0.0007862 | 0.005 * | −2.83 | 89948.7 |
| Driving Experience (years) | −0.0601705 | 0.0228715 | 0.009 * | −2.63 | 6.6 |
| Threshold | Coefficient | Standard Error | |||
| Cut-point 1 (between low ~moderate) | −5.727851 | 0.3434905 | |||
| Cut-point 2 (between moderate ~high) | −5.524819 | 0.3411096 | |||
| Dependent Variable | Marginal Effects of Risk Levels | ||
|---|---|---|---|
| Low | Moderate | High | |
| Driving Behavior Features | |||
| Vehicle Kinetic Energy | 0.6876918 | −0.7180673 | 0.0303755 |
| Deceleration Average | −0.1825126 | −0.0080616 | 0.1905742 |
| Near-Crash Features | |||
| Near-Crash Reason | |||
| 1. Head Vehicle Suddenly Stopped | 0.3610219 | 0.7430515 | −0.0328883 |
| 2. Traffic Lights | 0.2276311 | 0.0263799 | 0.6782394 |
| 3. Traffic Density a | 0 | 0 | 0 |
| 4. Road Fixing | 0.4695475 | 0.4951566 | 0.0352959 |
| 7. Subject Vehicle Turning | 0.0101273 | −0.0105746 | 0.0004473 |
| Environment and Time | |||
| Road Type | |||
| 1. Urban a | 0 | 0 | 0 |
| 2. City Highway | 0.3484643 | 0.6184576 | 0.0330782 |
| 4. Ramp | 0.3480709 | 0.0330646 | 0.6188645 |
| Road Congestion | |||
| 0. Yes | 0.3254279 | 0.6422137 | 0.0323583 |
| 1. No a | 0 | 0 | 0 |
| Time of Day | |||
| 2.12–18 a | 0 | 0 | 0 |
| 3.18–24 | 0.1775779 | 0.0233632 | 0.7990589 |
| Weekend | |||
| 0. No a | 0 | 0 | 0 |
| 1. Yes | 0.3311193 | 0.6691787 | 0.032426 |
| Driver Demographic and Driving Experience Features | |||
| Age | |||
| 2. 23–45 a | 0 | 0 | 0 |
| 3. More than 45 | 0.0327717 | 0.6128834 | 0.354345 |
| Driving Mileages | −4.10 × 10−7 | 4.28 × 10−7 | −1.81 × 10−8 |
| Driving Experience (years) | 0.0093566 | −0.0097702 | 0.0004135 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naji, H.A.H.; Xue, Q.; Lyu, N.; Wu, C.; Zheng, K. Evaluating the Driving Risk of Near-Crash Events Using a Mixed-Ordered Logit Model. Sustainability 2018, 10, 2868. https://doi.org/10.3390/su10082868
Naji HAH, Xue Q, Lyu N, Wu C, Zheng K. Evaluating the Driving Risk of Near-Crash Events Using a Mixed-Ordered Logit Model. Sustainability. 2018; 10(8):2868. https://doi.org/10.3390/su10082868
Chicago/Turabian StyleNaji, Hasan. A. H., Qingji Xue, Nengchao Lyu, Chaozhong Wu, and Ke Zheng. 2018. "Evaluating the Driving Risk of Near-Crash Events Using a Mixed-Ordered Logit Model" Sustainability 10, no. 8: 2868. https://doi.org/10.3390/su10082868
APA StyleNaji, H. A. H., Xue, Q., Lyu, N., Wu, C., & Zheng, K. (2018). Evaluating the Driving Risk of Near-Crash Events Using a Mixed-Ordered Logit Model. Sustainability, 10(8), 2868. https://doi.org/10.3390/su10082868