A Novel Hybrid Evolutionary Data-Intelligence Algorithm for Irrigation and Power Production Management: Application to Multi-Purpose Reservoir Systems

 ,
, 
 ,
, 


 and
and 
Abstract
:1. Introduction
1.1. Background
1.2. Problem Statement and Novelty
1.3. Research Objectives
2. Methodological Overview
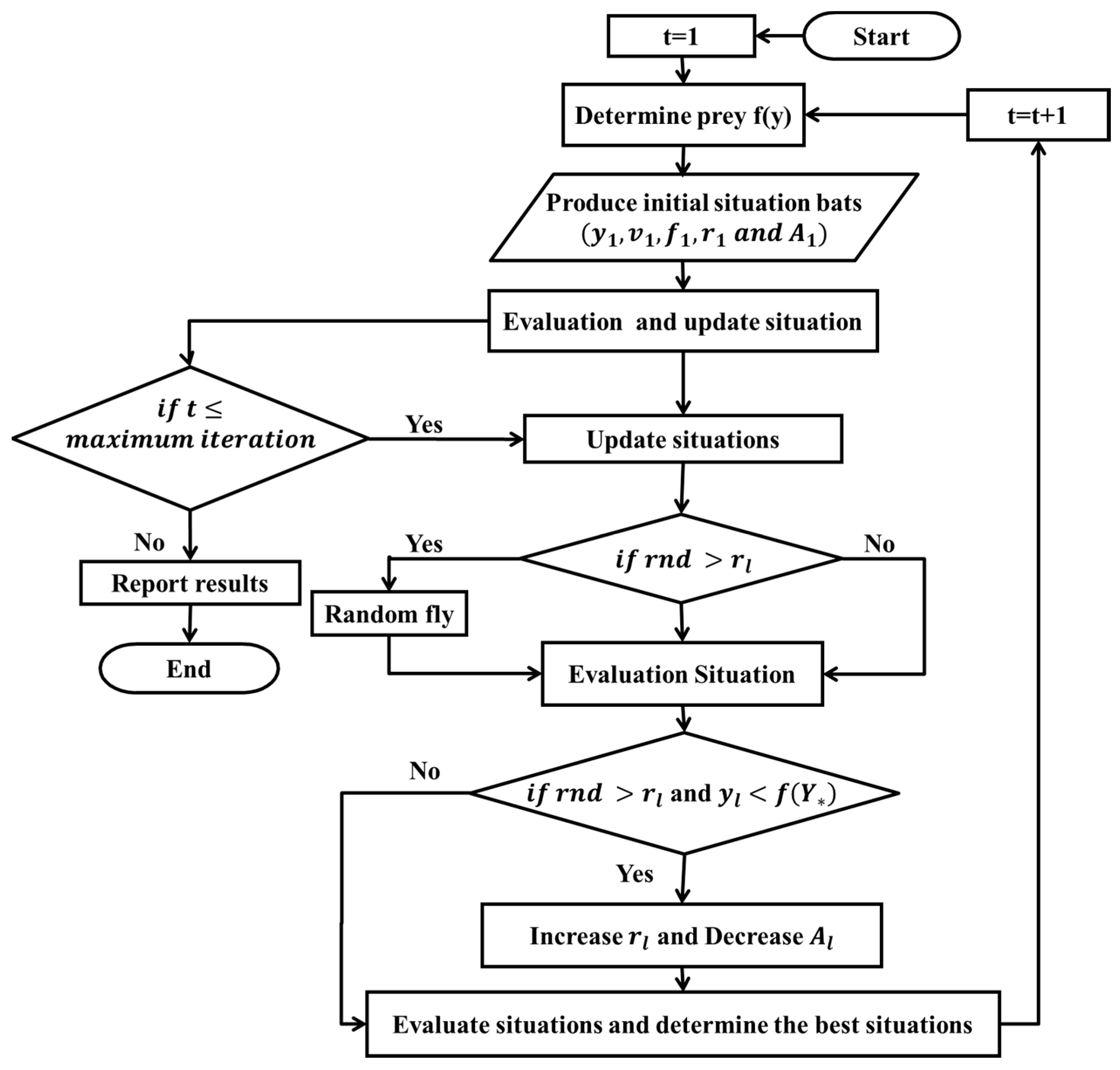
2.1. Bat Algorithm (BA)
- Echolocation is used by all bats, and this ability is helpful for identifying prey from obstacles.
- Bats fly at a random velocity, vl, and at a random location, xl. The frequency of a bat is fl. A0 and represent the loudness and wavelength of bats, respectively.
- The loudness of bats varies from A0 (i.e., a large positive number) to Amin.
2.2. Particle Swarm Optimization (PSO) Algorithm
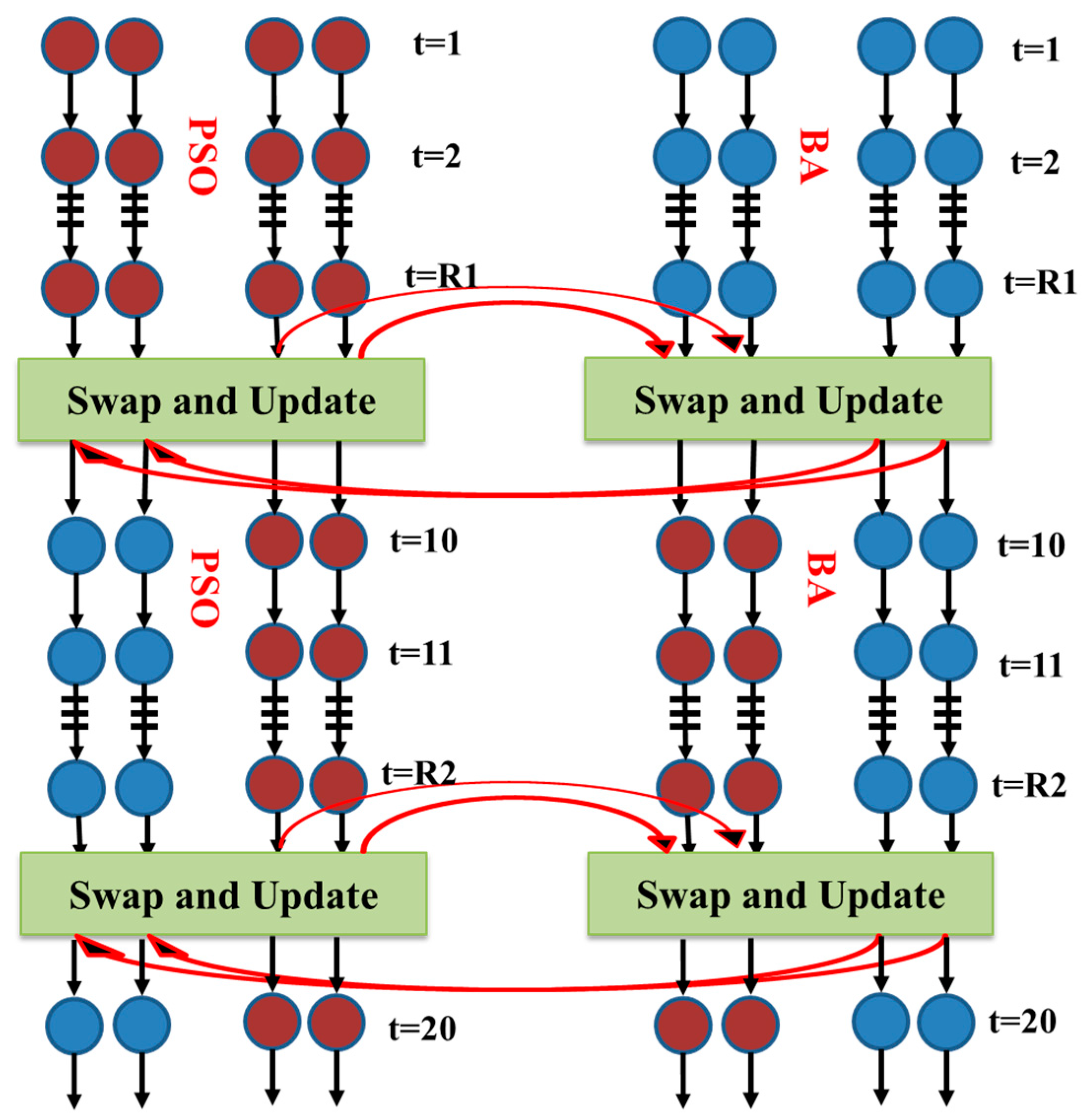
2.3. New Hybrid Algorithm (NHA)
- The random parameters are initialized for two algorithms, and then the velocity and position vectors are considered for the BA and PSO algorithms;
- The objective function is individually calculated for the two algorithms, and then the best member is determined for the two algorithms;
- The velocity and position are updated for the BA based on Equations (1)–(3), and the velocity and position are updated based on Equations (6) and (7), respectively;
- The K agent, as the best member of each algorithm, is copied to the other algorithms, which are substituted with the worst solutions of the other algorithm;
- The convergence criteria are checked, and if the algorithm is satisfied, the algorithm finishes; otherwise, the algorithm returns to the second step.
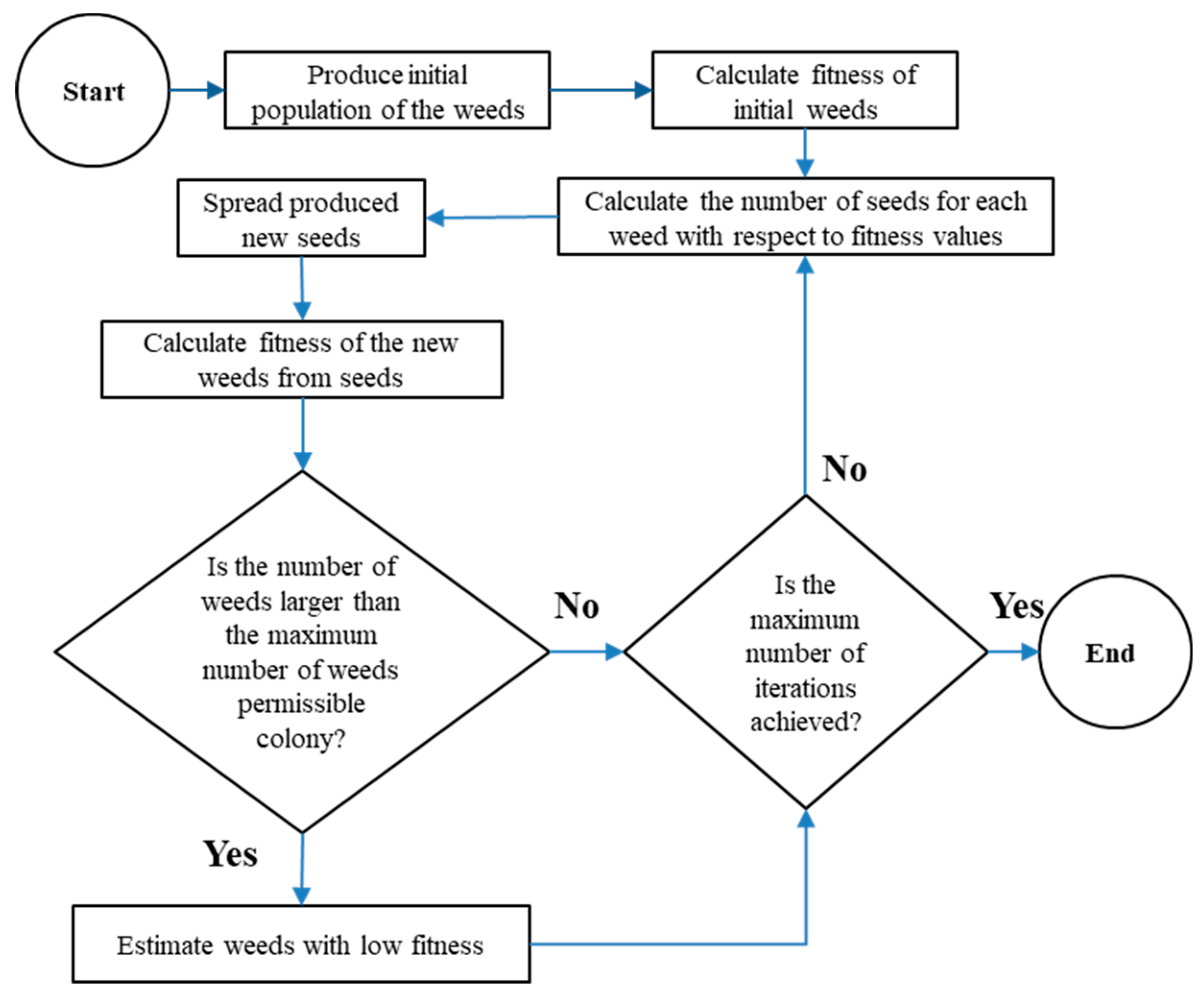
2.4. Weed Algorithm (WA)
- Weeds are grown based on seeds, which are spread throughout the environment.
- Weeds that grow close to each other are known as a colony, and they can produce seeds based on their equality.
- Each produced seed distributes randomly throughout the environment.
- The algorithm finishes when the number of weeds reaches the maximum number.
- The different levels for the WA are based on the following levels:
- First, the initial population of the algorithm (Pinitial) is considered, and the position of each weed in the environment (i.e., search space) is considered a decision variable.
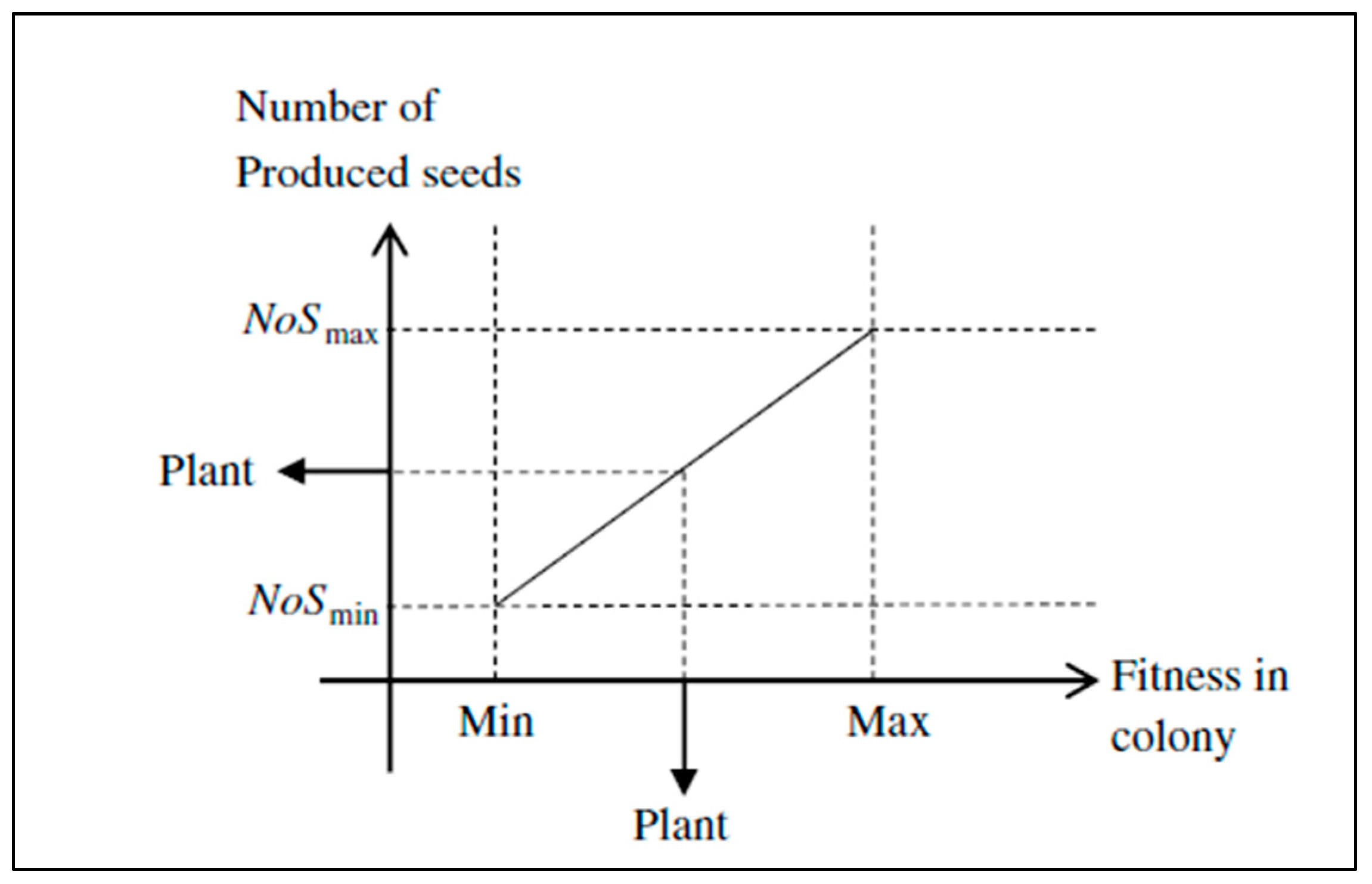
- The next level is known as the reproduction level. Reproduction causes new seeds to be produced from colonies, and the maximum and minimum numbers of seeds are and , respectively (see Figure 3). Reproduction is an important level for the WA because there are two group solutions in the evolutionary algorithms. Appropriate solutions have a high chance of reproduction to continue the production of the best member for the next generation, and inappropriate solutions may have a weak chance of reproduction; however, they may have important information for the next levels of the algorithm. Thus, reproduction may be extended to inappropriate solutions that are not removed from the population, and they can continue their life based on suitable reproduction and the improvement in their quality. Some inappropriate solutions have important information, and this information can be used for the next levels of the algorithm.
- The produced seeds are distributed in the search space based on a normal distribution and zero mean.
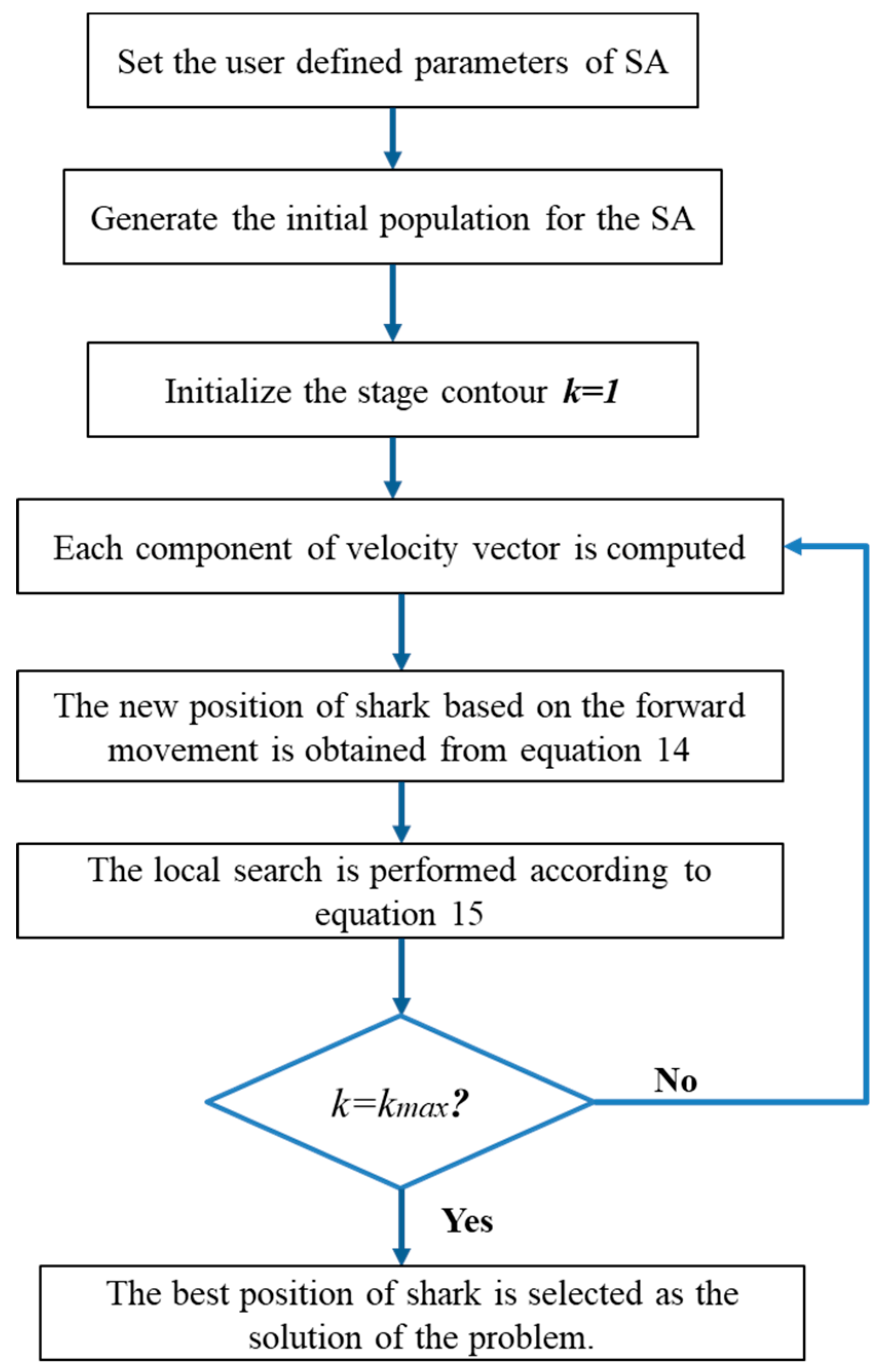
2.5. Shark Algorithm (SA)
- Injured fish are considered to be prey for sharks, as fish bodies distribute blood throughout the sea. Additionally, injured fish have negligible speeds compared with sharks.
- The blood is distributed into the sea regularly, and the effect of water flow is not considered for blood distribution.
- Each injured fish is considered as one blood production resource for sharks; therefore, the olfactory receptors help sharks find their prey.
- The initial population for sharks is shown by . Each solution candidate or shark position can have the following components based on the following equation:where is the initial position vector; x1ij is the jth dimension of the shark position; and ND is the number of decision variables. The initial velocity for sharks is shown by . The velocity components are considered based on the following equation:where is the initial velocity vector and v1ij is the jth dimension of the shark velocity. When the shark receives greater odour intensity, it moves faster towards its prey. Thus, if the odour intensity is considered an objective function, the velocity changes with the variation in the objective function based on the following equation:where is the number between 0 and 1; is the random number; and is the objective function.
2.6. Genetic Algorithm (GA)
3. Case Study and Modelling Procedure
3.1. Benchmark Function
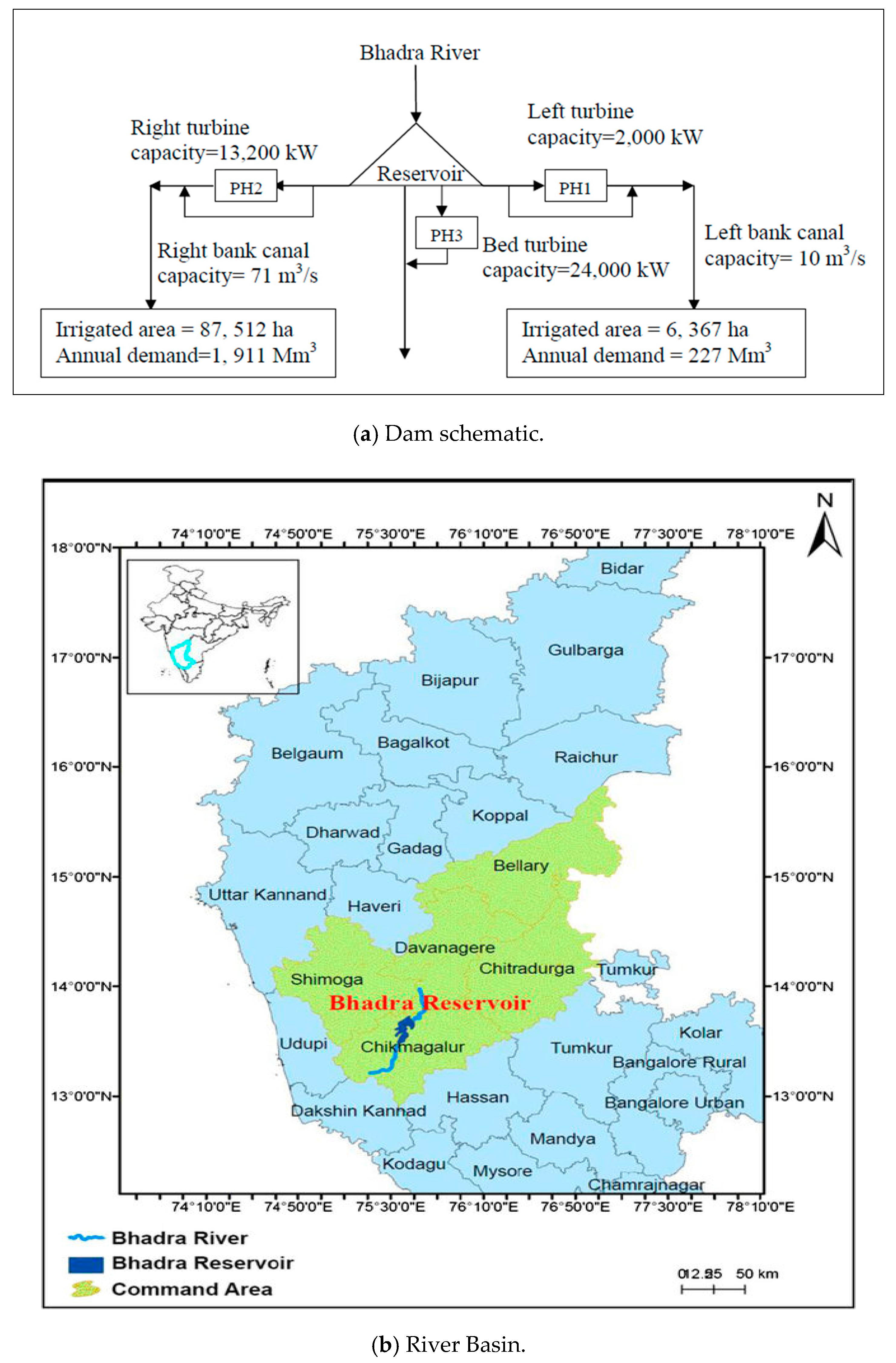
3.2. Multi-Purpose Reservoir Operation
- The storage constraint is as follows:where is the maximum storage and is the minimum storage.
- The power production constraints are as follows:where , , and represent the maximum energy for the left canal, right canal, and riverbed, respectively.
- The canal capacity constraints are as follows:where is the maximum capacity for the left canal and is the maximum capacity for the right canal.
- The irrigation demands are as follows:where is the minimum demand for the left canal; is the maximum demand for the left canal; is the minimum demand for the right canal; and is the maximum demand for the right canal.
- The steady storage constraint is as follows:
- The decision variables for the left canal, right canal, and riverbed are initialized based on the initial matrix for the NHA. In fact, the released water for the downstream demands is considered as the initial population.
- The storage reservoir can be calculated based on the continuity equation, and the different constraints should be checked.
- If the constraints are not satisfied, the penalty functions are considered as violations; then, the objective function is calculated based on Equation (31).
- Then, the NHA process is considered for the optimization process based on the independent performances of the BA and PSO algorithm in the NHA.
- The convergence criteria are checked, and if the algorithm is satisfied, it finishes; otherwise, the algorithm returns to the second step.
4. Modelling Evaluation Indexes
- Volumetric reliability index. This index is based on the ratio of released water to irrigation demands. Thus, a high percentage of this index represents the high performance of each algorithm.where is the volumetric reliability; is the released water; is the demand; is the number of periods in which demand is not supplied; and T is the total number of operational periods.
- Vulnerability index. This index represents the maximum intensity of the failure that occurred during the operation period of a system. The periods for which irritation demands are not met are known as failure periods or critical periods, and maximum deficiency occurrences during these periods are represented by the vulnerability index; thus, a low percentage for this index is preferable [35].
- Resiliency index. This index represents the existing speed of a system from failure. Thus, a high percentage for this index is preferable. This index shows the flexibility of different algorithms versus the critical periods when they should manage the system well [35].where is the resiliency index; fsi is the number of failure series that occurred; and is the number of failure periods that occurred. These indexes were used to evaluate the percentage of success of the examined optimization algorithms based on their achieved operation rules to minimize the gap between the water release and water demand. Furthermore, to evaluate the performance of each algorithm with respect to the computational time needed for convergence, the time consumption for each algorithm to achieve the operation rule was determined. The best algorithm is the one that could achieve the global optima in less time for convergence.
5. Results, Discussion, and Application Analysis
5.1. Benchmark Functions
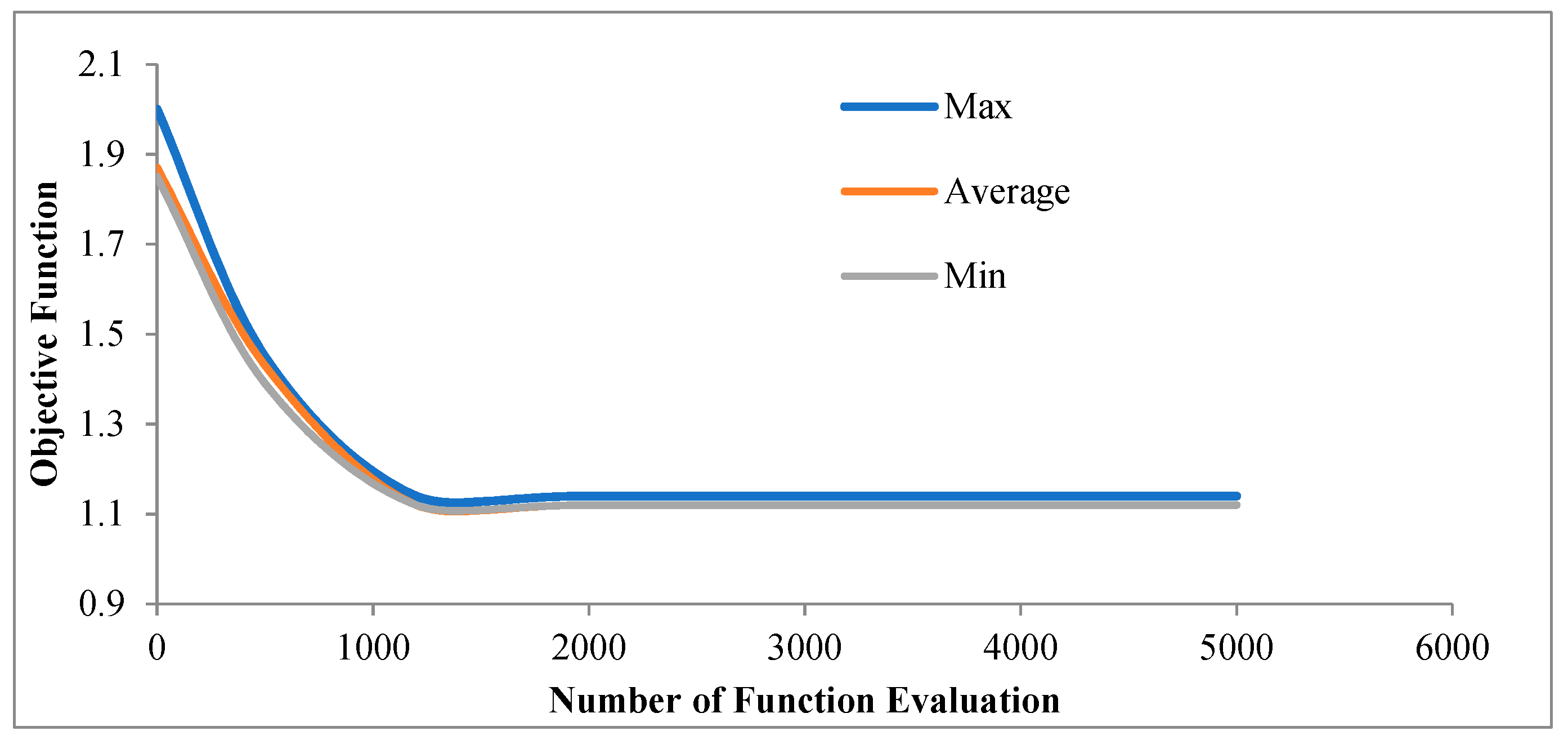
5.2. Sensitivity Analysis for the NHA
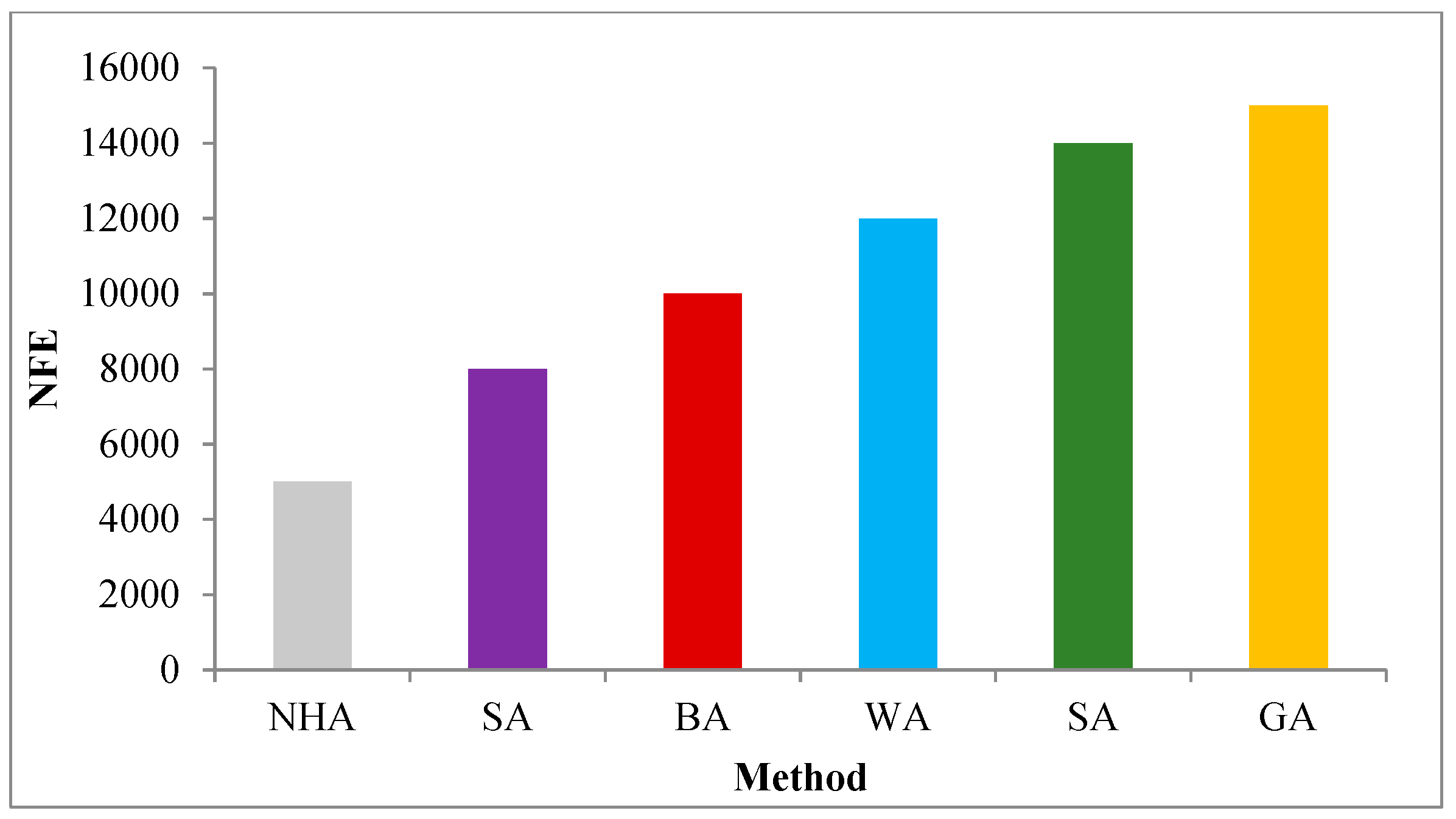
5.3. Ten Random Results for Evolutionary Algorithms
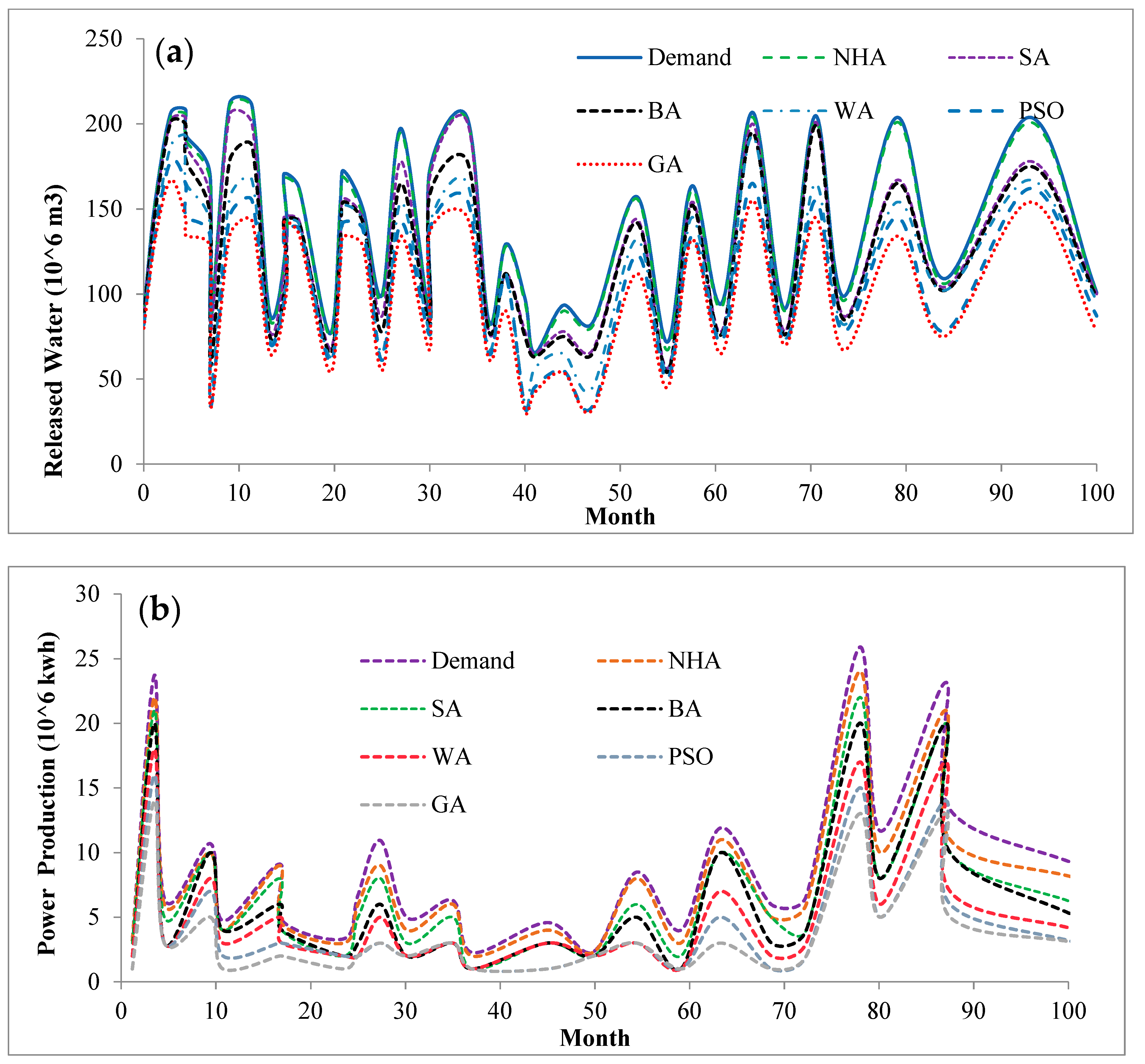
5.4. Computed Irrigation Deficiencies
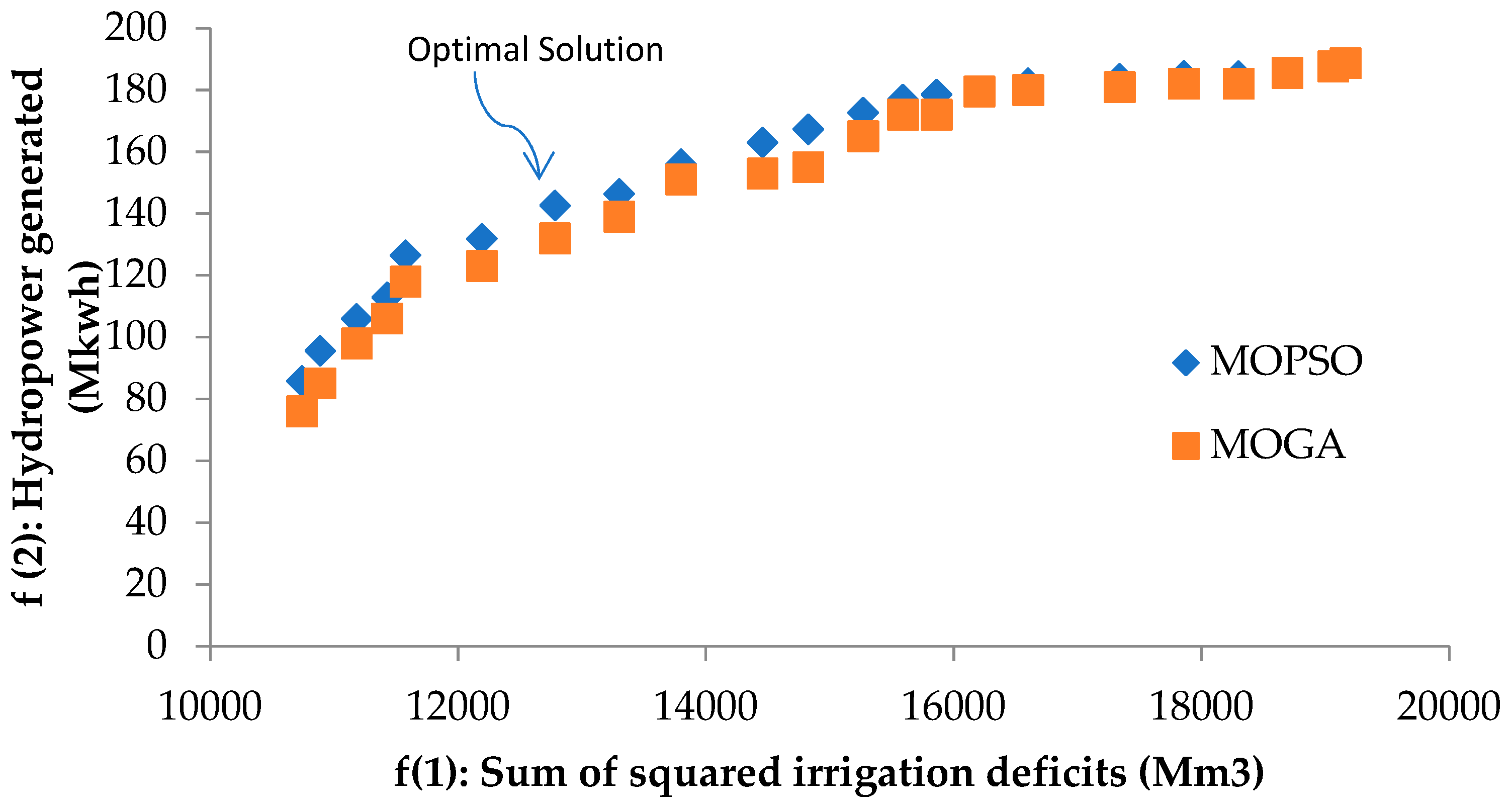
5.5. Computational Power Production
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Pedro-Monzonís, M.; Solera, A.; Ferrer, J.; Estrela, T.; Paredes-Arquiola, J. A review of water scarcity and drought indexes in water resources planning and management. J. Hydrol. 2015, 527, 482–493. [Google Scholar] [CrossRef]
- You, J.Y.; Cai, X. Hedging rule for reservoir operations: 2. A numerical model. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Fang, H.; Hu, T.; Zeng, X.; Wu, F. Simulation-optimization model of reservoir operation based on target storage curves. Water Sci. Eng. 2014, 7, 433–445. [Google Scholar] [CrossRef]
- Srinivasan, K.; Kumar, K. Multi-Objective Simulation-Optimization Model for Long-term Reservoir Operation using Piecewise Linear Hedging Rule. Water Resour. Manag. 2018, 32, 1901–1911. [Google Scholar] [CrossRef]
- Xie, A.; Liu, P.; Guo, S.; Zhang, X.; Jiang, H.; Yang, G. Optimal Design of Seasonal Flood Limited Water Levels by Jointing Operation of the Reservoir and Floodplains. Water Resour. Manag. 2017, 32, 179–193. [Google Scholar] [CrossRef]
- Adeyemo, J.A. Reservoir operation using multi-objective evolutionary algorithms—A review. Asian J. Sci. Res. 2011, 4, 16–27. [Google Scholar] [CrossRef]
- Karamouz, M.; Nazif, S.; Sherafat, M.A.; Zahmatkesh, Z. Development of an Optimal Reservoir Operation Scheme Using Extended Evolutionary Computing Algorithms Based on Conflict Resolution Approach: A Case Study. Water Resour. Manag. 2014, 28, 3539–3554. [Google Scholar] [CrossRef]
- Azizipour, M.; Ghalenoei, V.; Afshar, M.H.; Solis, S.S. Optimal Operation of Hydropower Reservoir Systems Using Weed Optimization Algorithm. Water Resour. Manag. 2016, 30, 3995–4009. [Google Scholar] [CrossRef]
- Han, C.; Zheng, B.; Qin, Y.; Ma, Y.; Yang, C.; Liu, Z.; Cao, W.; Chi, M. Impact of upstream river inputs and reservoir operation on phosphorus fractions in water-particulate phases in the Three Gorges Reservoir. Sci. Total Environ. 2018, 610–611, 1546–1556. [Google Scholar] [CrossRef]
- Wan, W.; Guo, X.; Lei, X.; Jiang, Y.; Wang, H. A Novel Optimization Method for Multi-Reservoir Operation Policy Derivation in Complex Inter-Basin Water Transfer System. Water Resour. Manag. 2017, 32, 31–51. [Google Scholar] [CrossRef]
- Moeini, R.; Babaei, M. Constrained improved particle swarm optimization algorithm for optimal operation of large scale reservoir: Proposing three approaches. Evol. Syst. 2017, 8, 287–301. [Google Scholar] [CrossRef]
- Zyoud, S.H.; Kaufmann, L.G.; Shaheen, H.; Samhan, S.; Fuchs-Hanusch, D. A framework for water loss management in developing countries under fuzzy environment: Integration of Fuzzy AHP with Fuzzy TOPSIS. Expert Syst. Appl. 2016, 61, 86–105. [Google Scholar] [CrossRef]
- Rabiei, M.; Aalami, M.; Talatahari, S. Reservoir Operation Optimization using CBO, ECBO and vps algorithms. Iran Univ. Sci. Technol. 2018, 8, 489–509. [Google Scholar]
- Tayfur, G. Modern Optimization Methods in Water Resources Planning, Engineering and Management. Water Resour. Manag. 2017, 31, 3205–3233. [Google Scholar] [CrossRef]
- Bennett, C.; Stewart, R.A.; Beal, C.D. ANN-based residential water end-use demand forecasting model. Expert Syst. Appl. 2013, 40, 1014–1023. [Google Scholar] [CrossRef]
- Nabaei, A.; Hamian, M.; Parsaei, M.R.; Safdari, R.; Samad-Soltani, T.; Zarrabi, H.; Ghassemi, A. Topologies and performance of intelligent algorithms: A comprehensive review. Artif. Intell. Rev. 2016. [Google Scholar] [CrossRef]
- Ethteram, M.; Mousavi, S.F.; Karami, H.; Farzin, S.; Deo, R.; Othman, F.B.; Chau, K.; Sarkamaryan, S.; Singh, V.P.; El-Shafie, A. Bat algorithm for dam–reservoir operation. Environ. Earth Sci. 2018, 77, 510. [Google Scholar] [CrossRef]
- Ehteram, M.; Singh, V.; Karami, H.; Hosseini, K.; Dianatikhah, M.; Hossain, M.; Ming Fai, C.; El-Shafie, A. Irrigation Management Based on Reservoir Operation with an Improved Weed Algorithm. Water 2018, 10, 1267. [Google Scholar] [CrossRef]
- Allawi, M.F.; Jaafar, O.; Mohamad Hamzah, F.; Ehteram, M.; Hossain, M.S.; El-Shafie, A. Operating a reservoir system based on the shark machine learning algorithm. Environ. Earth Sci. 2018, 77, 366. [Google Scholar] [CrossRef]
- Allawi, M.F.; Jaafar, O.; Mohamad Hamzah, F.; Koting, S.B.; Mohd, N.S.B.; El-Shafie, A. Forecasting hydrological parameters for reservoir system utilizing artificial intelligent models and exploring their influence on operation performance. Knowl.-Based Syst. 2019, 163, 907–926. [Google Scholar] [CrossRef]
- Raso, L.; Chiavico, M.; Dorchies, D. Optimal and Centralized Reservoir Management for Drought and Flood Protection on the Upper Seine–Aube River System Using Stochastic Dual Dynamic Programming. J. Water Resour. Plan. Manag. 2019, 145, 5019002. [Google Scholar] [CrossRef]
- Allawi, M.F.; Jaafar, O.; Ehteram, M.; Mohamad Hamzah, F.; El-Shafie, A. Synchronizing Artificial Intelligence Models for Operating the Dam and Reservoir System. Water Resour. Manag. 2018, 32, 3373–3389. [Google Scholar] [CrossRef]
- Ehteram, M.; Karami, H.; Farzin, S. Reservoir Optimization for Energy Production Using a New Evolutionary Algorithm Based on Multi-Criteria Decision-Making Models. Water Resour. Manag. 2018, 32, 2539–2560. [Google Scholar] [CrossRef]
- Ehteram, M.; Mousavi, S.F.; Karami, H.; Farzin, S.; Emami, M.; Binti Othman, F.; Amini, Z.; Kisi, O.; El-Shafie, A. Fast convergence optimization model for single and multi-purposes reservoirs using hybrid algorithm. Adv. Eng. Inform. 2017, 32, 287–298. [Google Scholar] [CrossRef]
- Afshar, A.; Shafii, M.; Haddad, O.B. Optimizing multi-reservoir operation rules: An improved HBMO approach. J. Hydroinform. 2010, 13, 121. [Google Scholar] [CrossRef]
- Fallah-Mehdipour, E.; Bozorg Haddad, O.; Mariño, M.A. Real-Time Operation of Reservoir System by Genetic Programming. Water Resour. Manag. 2012, 26, 4091–4103. [Google Scholar] [CrossRef]
- Ostadrahimi, L.; Mariño, M.A.; Afshar, A. Multi-reservoir Operation Rules: Multi-swarm PSO-based Optimization Approach. Water Resour. Manag. 2011, 26, 407–427. [Google Scholar] [CrossRef]
- Bolouri-Yazdeli, Y.; Bozorg Haddad, O.; Fallah-Mehdipour, E.; Mariño, M.A. Evaluation of real-time operation rules in reservoir systems operation. Water Resour. Manag. 2014, 28, 715–729. [Google Scholar] [CrossRef]
- Akbari-Alashti, H.; Bozorg Haddad, O.; Fallah-Mehdipour, E.; Mariño, M.A. Multi-reservoir real-time operation rules: A new genetic programming approach. Proc. Inst. Civ. Eng. Water Manag. 2014, 167, 561–576. [Google Scholar] [CrossRef]
- Haddad, O.B.; Moravej, M.; Loáiciga, H.A. Application of the Water Cycle Algorithm to the Optimal Operation of Reservoir Systems. J. Irrig. Drain. Eng. 2015, 141, 04014064. [Google Scholar] [CrossRef]
- Haddad, O.B.; Hosseini-Moghari, S.-M.; Loáiciga, H.A. Biogeography-Based Optimization Algorithm for Optimal Operation of Reservoir Systems. J. Water Resour. Plan. Manag. 2016, 142, 04015034. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, Y.; Zhang, S.; Geng, S.; Wang, H.; Sang, G. An adaptive particle swarm optimization algorithm for reservoir operation optimization. Appl. Soft Comput. J. 2014, 18, 167–177. [Google Scholar] [CrossRef]
- Hosseini-Moghari, S.-M.; Morovati, R.; Moghadas, M.; Araghinejad, S. Optimum Operation of Reservoir Using Two Evolutionary Algorithms: Imperialist Competitive Algorithm (ICA) and Cuckoo Optimization Algorithm (COA). Water Resour. Manag. 2015, 29, 3749–3769. [Google Scholar] [CrossRef]
- Ehteram, M.; Karami, H.; Mousavi, S.-F.; Farzin, S.; Kisi, O. Evaluation of contemporary evolutionary algorithms for optimization in reservoir operation and water supply. J. Water Supply Res. Technol. 2017, jws2017109. [Google Scholar] [CrossRef]
- Ehteram, M.; Karami, H.; Mousavi, S.-F.; Farzin, S.; Kisi, O. Optimization of energy management and conversion in the multi-reservoir systems based on evolutionary algorithms. J. Clean. Prod. 2017, 168, 1132–1142. [Google Scholar] [CrossRef]
- Garg, H. A hybrid GSA-GA algorithm for constrained optimization problems. Inf. Sci. 2019, 478, 499–523. [Google Scholar] [CrossRef]
- Patwal, R.S.; Narang, N.; Garg, H. A novel TVAC-PSO based mutation strategies algorithm for generation scheduling of pumped storage hydrothermal system incorporating solar units. Energy 2018, 142, 822–837. [Google Scholar] [CrossRef]
- Garg, H. A hybrid PSO-GA algorithm for constrained optimization problems. Appl. Math. Comput. 2016, 274, 292–305. [Google Scholar] [CrossRef]
- Garg, H. An efficient biogeography based optimization algorithm for solving reliability optimization problems. Swarm Evol. Comput. 2015, 24, 1–10. [Google Scholar] [CrossRef]
- Shah, H.; Tairan, N.; Garg, H.; Ghazali, R. Global Gbest Guided-Artificial Bee Colony Algorithm for Numerical Function Optimization. Computers 2018, 7, 69. [Google Scholar] [CrossRef]
- Yang, X.S. Bat algorithm for multi-objective optimisation. Int. J. Bio-Inspired Comput. 2011, 3, 267. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Yang, X.S. Chaotic bat algorithm. J. Comput. Sci. 2014, 5, 224–232. [Google Scholar] [CrossRef]
- Yang, X.S. A new metaheuristic Bat-inspired Algorithm. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2010; Volume 284, pp. 65–74. [Google Scholar]
- Bozorg-Haddad, O.; Karimirad, I.; Seifollahi-Aghmiuni, S.; Loáiciga, H.A. Development and Application of the Bat Algorithm for Optimizing the Operation of Reservoir Systems. J. Water Resour. Plan. Manag. 2015, 141, 04014097. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Zhou, J.; Zhou, C.; Wang, Y.Y.; Qin, H.; Lu, Y. An improved self-adaptive PSO technique for short-term hydrothermal scheduling. Expert Syst. Appl. 2012, 39, 2288–2295. [Google Scholar] [CrossRef]
- Karami, H.; Mousavi, S.F.; Farzin, S.; Ehteram, M.; Singh, V.P.; Kisi, O. Improved Krill Algorithm for Reservoir Operation. Water Resour. Manag. 2018, 32, 3353–3372. [Google Scholar] [CrossRef]
- Li, L.; Zhou, Y. A novel complex-valued bat algorithm. Neural Comput. Appl. 2014, 25, 1369–1381. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. Neural Netw. 1995, 4, 1942–1948. [Google Scholar] [CrossRef]
- Ehteram, M.; Karami, H.; Farzin, S. Reducing Irrigation Deficiencies Based Optimizing Model for Multi-Reservoir Systems Utilizing Spider Monkey Algorithm. Water Resour. Manag. 2018, 32, 2315–2334. [Google Scholar] [CrossRef]
- Mehrabian, A.R.; Lucas, C. A novel numerical optimization algorithm inspired from weed colonization. Ecol. Inform. 2006, 1, 355–366. [Google Scholar] [CrossRef]
- Hersovici, M.; Jacovi, M.; Maarek, Y.S.; Pelleg, D.; Shtalhaim, M.; Ur, S. The shark-search algorithm. An application: Tailored Web site mapping. Comput. Netw. ISDN Syst. 1998, 30, 317–326. [Google Scholar] [CrossRef]
- Bansal, J.C.; Sharma, H.; Jadon, S.S.; Clerc, M. Spider Monkey Optimization algorithm for numerical optimization. Memetic Comput. 2014, 6, 31–47. [Google Scholar] [CrossRef]
- Reddy, M.J.; Kumar, D.N. Optimal reservoir operation using multi-objective evolutionary algorithm. Water Resour. Manag. 2006, 20, 861–878. [Google Scholar] [CrossRef]
- Deb, K.; Zhu, L.; Kulkarni, S. Multi-scenario, multi-objective optimization using evolutionary algorithms: Initial results. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation, Sendai, Japan, 25–28 May 2015; pp. 1877–1884. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
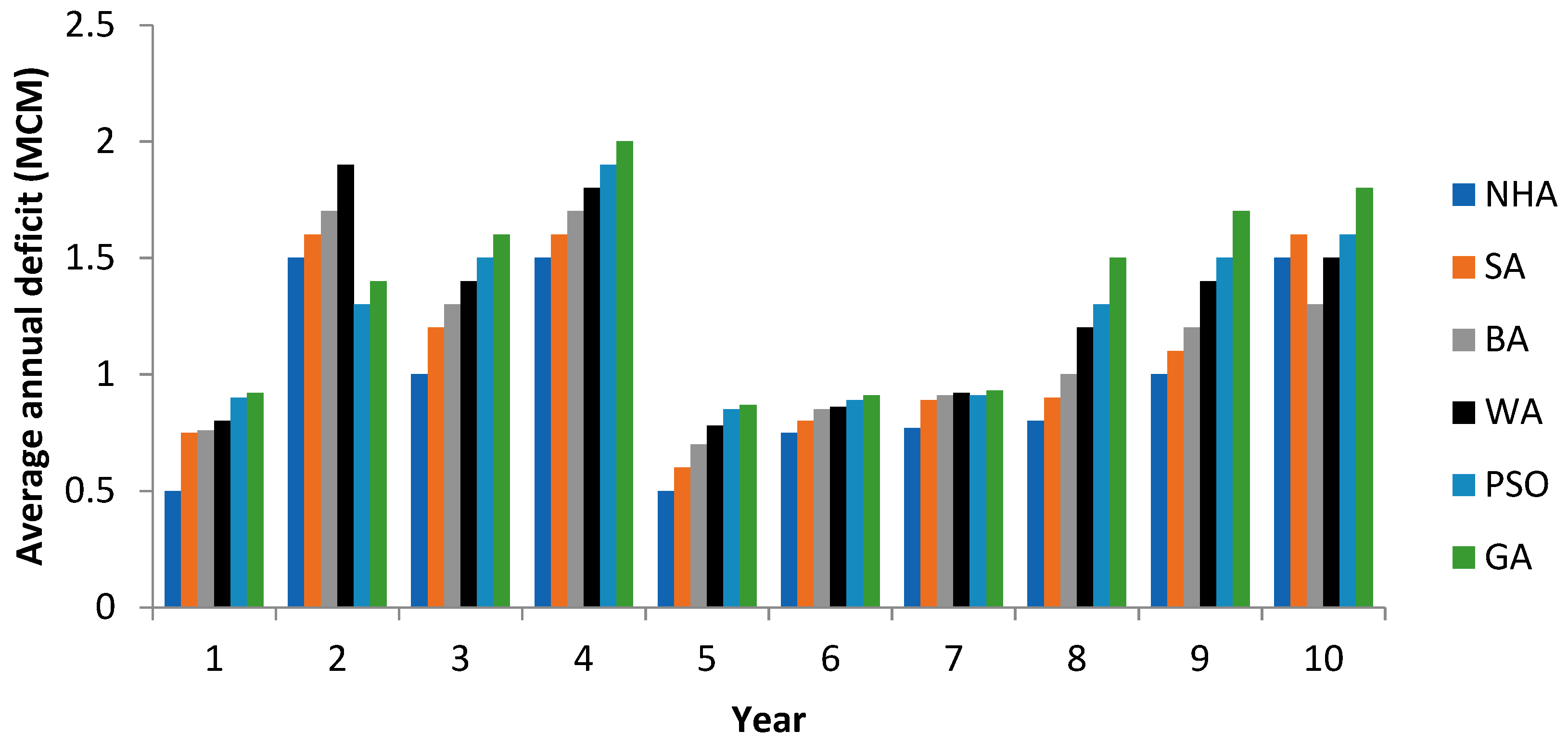{kind=link}
| Test Problem | Objective Function | Search Range | Optimum Value | Dimension | Characteristic | Acceptable Error (AE) |
|---|---|---|---|---|---|---|
| Schwefel function [52] | [−100, 100] | 0 | 30 | Unimodal | 1.0 × 10−3 | |
| Rastrigin [52] | [−5.12, 5.12] | 0 | 30 | Multimodal | 5.0 × 10−1 | |
| Dekkers and Aarts [52] | [−20,20] | −24,777 | 2 | Unimodal | 1.0 × 10−5 | |
| Step function [52] | [−100, 100] | 0 | 30 | Unimodal | 1.0 × 10−3 | |
| Axis parallel function [52] | [−5.12, 5.12] | 0 | 30 | Unimodal | 1.0 × 10−5 |
| Description | Quantity |
|---|---|
| Gross storage capacity | 2025 Mm3 |
| Live storage capacity | 1784 Mm3 |
| Dead storage capacity | 241 Mm3 |
| Average annual inflow | 2845 Mm3 |
| Left bank canal capacity | 10 m3/s |
| Right bank canal capacity | 71 m3/s |
| Left bank turbine capacity | 2000 kW |
| Right bank turbine capacity (Phase2) | 13,200 kW |
| Riverbed turbine capacity (Phase3) | 24,000 kW |
| Function | Algorithms | SD | ME | ANFE | SR |
|---|---|---|---|---|---|
| f1 | Differential Evolution Algorithm | 1.42 × 10−4 [52] | 8.68 × 10−4 [52] | 27,378 [52] | 100 |
| Artificial Bee Colony Algorithm | 2.02 × 10−4 [52] | 7.54 × 10−4 [52] | 35,091 [52] | 100 | |
| Particle Swarm Optimization | 6.72 × 10−5 | 9.34 × 10−4 | 45,914.5 | 100 | |
| Bat Algorithm | 5.12 × 10−5 | 6.12 × 10−4 | 231,245 | 100 | |
| Shark Algorithm | 5.01 × 10−5 | 5.25 × 10−4 | 209,878 | 100 | |
| Genetic Algorithm | 1.34 × 10−5 | 9.56 × 10−4 | 37,094 | 100 | |
| Spider Monkey Algorithm | 2.12 × 10−6 [52] | 5.65 × 10−5 | 19,878 [52] | 100 | |
| Krill Algorithm | 2.22 × 10−6 [52] | 7.12 × 10−5 | 18,235 [52] | 100 | |
| NHA | 5.25 × 10−7 | 8.12 × 10−6 | 14,224 | 100 | |
| f2 | Differential Evolution Algorithm | 4.93 [52] | 2.09 × 10−3 [53] | 200,000 [52] | 98 |
| Artificial Bee Colony Algorithm | 3.14 × 10−4 [52] | 7.48 × 10−4 [53] | 87,039 [52] | 98 | |
| Particle Swarm Optimization | 1.35 × 10+1 | 2.98 × 10−3 | 200,000 | 98 | |
| Bat Algorithm | 3.24 × 10−5 | 3.12 × 10−5 | 54,223 | 98 | |
| Shark Algorithm | 4.56 × 10−7 | 4.12 × 10−6 | 45,221 | 98 | |
| Genetic Algorithm | 8.78 | 2.12 × 10−3 | 205,000 | 98 | |
| Spider Monkey Algorithm | 6.12 × 10−8 [53] | 5.12 × 10−7 [53] | 32,124 [53] | 98 | |
| Krill Algorithm | 7.91 × 10−7 [53] | 6.12 × 10−7 [53] | 35,125 [53] | 100 | |
| NHA | 9.12 × 10−9 | 7.12 × 10−8 | 310,191 | 100 | |
| f3 | Differential Evolution Algorithm | 1.12 × 10−3 | 4.09 × 10−1 | 2725.5 | 100 |
| Artificial Bee Colony Algorithm | 5.25 × 10−3 | 4.09 × 10−1 | 2567 | 85 | |
| Particle Swarm Optimization | 5.64 × 10−3 | 4.02 × 10−1 | 4979 | 85 | |
| Bat Algorithm | 4.12 × 10−4 | 3.12 × 10−2 | 1285 | 85 | |
| Shark Algorithm | 5.12 × 10−5 | 3.22 × 10−2 | 1100 | 98 | |
| Genetic Algorithm | 1.12 × 10−2 | 4.12 × 10+1 | 1400 | 98 | |
| Spider Monkey Algorithm | 5.78 × 10−5 | 2.12 × 10−4 | 987 | 98 | |
| Krill Algorithm | 5.45 × 10−3 | 3.12 × 10−5 | 765 | 98 | |
| NHA | 1.14 × 10−6 | 1.12 × 10−6 | 654 | 100 | |
| f4 | Differential Evolution Algorithm | 1.12 × 10+2 | 2.19 × 10+1 | 180,000 | 84 |
| Artificial Bee Colony Algorithm | 1.18 × 10+1 | 1.19 × 10+1 | 170,000 | 84 | |
| Particle Swarm Optimization | 6.70 × 10+2 | 2.80 × 10−3 | 200,000 | 84 | |
| Bat Algorithm | 5.70 × 10−3 | 1.12 × 10−4 | 180,000 | 84 | |
| Shark Algorithm | 4.71 × 10−3 | 5.45 × 10−5 | 160,000 | 84 | |
| Genetic Algorithm | 6.14 × 10+3 | 1.21 × 10−2 | 210,000 | 84 | |
| Spider Monkey Algorithm | 1.45 × 10−4 | 3.12 × 10−5 | 180,000 | 84 | |
| Krill Algorithm | 1.23 × 10−5 | 4.21 × 10−5 | 165,000 | 84 | |
| NHA | 2.12 × 10−6 | 2.12 × 10−7 | 140,000 | 98 | |
| f5 | Differential Evolution Algorithm | 1.31 × 10−6 | 4.90 × 10−1 | 2741 | 100 |
| Artificial Bee Colony Algorithm | 2.00 × 10−6 | 4.87 × 10−1 | 4811 | 100 | |
| Particle Swarm Optimization | 6.12 × 10−7 | 4.75 × 10−1 | 4912 | 100 | |
| Bat Algorithm | 2.12 × 10−8 | 2.22 × 10−3 | 1811 | 100 | |
| Shark Algorithm | 1.11 × 10−8 | 2.12 × 10−4 | 1712 | 100 | |
| Genetic Algorithm | 1.21 × 10−5 | 3.21 × 10−4 | 5121 | 100 | |
| Spider Monkey Algorithm | 2.12 × 10−8 | 5.12 × 10−3 | 1001 | 100 | |
| Krill Algorithm | 1.14 × 10−8 | 5.45 × 10−4 | 987 | 100 | |
| NHA | 1.41 × 10−9 | 6.78 × 10−5 | 567 | 100 |
| Size Population | Objective Function | W (Inertia Coefficient) | Objective Function | c1 = c2 | Objective Function | Maximum Frequency | Objective Function | Minimum Loudness | Objective Function |
|---|---|---|---|---|---|---|---|---|---|
| 10 | 2.45 | 0.30 | 2.21 | 1.6 | 2.34 | 1 | 2.11 | 0.3 | 2.23 |
| 30 | 2.24 | 0.50 | 2.00 | 1.8 | 2.12 | 2 | 2.00 | 0.5 | 2.05 |
| 50 | 1.98 | 0.70 | 1.98 | 2.0 | 1.98 | 3 | 2.14 | 0.7 | 2.0 |
| 70 | 2.01 | 0.90 | 2.12 | 2.2 | 2.12 | 4 | 2.16 | 0.90 | 2.1 |
| Size Population | Objective Function | βk (Velocity Limiter) | Objective Function | αk | Objective Function |
|---|---|---|---|---|---|
| 10 | 2.45 | 2 | 2.44 | 0.20 | 2.55 |
| 30 | 2.12 | 4 | 2.12 | 0.40 | 2.12 |
| 50 | 2.24 | 6 | 2.34 | 0.60 | 2.67 |
| 70 | 2.36 | 8 | 2.44 | 0.80 | 2.78 |
| Pinitial | Objective Function | Pmax | Objective Function | N0Smax | Objective Function |
|---|---|---|---|---|---|
| 5 | 3.69 | 10 | 3.55 | 3 | 3.78 |
| 10 | 3.12 | 30 | 3.12 | 5 | 3.34 |
| 15 | 3.24 | 50 | 3.28 | 7 | 3.12 |
| 20 | 3.36 | 70 | 3.32 | 9 | 3.44 |
| Size Population | Objective Function | Mutation Probability | Objective Function | Crossover Probability | Objective Function |
|---|---|---|---|---|---|
| 10 | 5.12 | 0.30 | 4.88 | 0.20 | 4.69 |
| 30 | 4.98 | 0.50 | 4.55 | 0.40 | 4.34 |
| 50 | 4.15 | 0.70 | 4.15 | 0.60 | 4.12 |
| 70 | 4.55 | 0.90 | 4.24 | 0.80 | 4.24 |
| Run | NHA | SA | BA | WA | PSO | GA |
|---|---|---|---|---|---|---|
| 1 | 1.99 | 2.12 | 2.45 | 3.16 | 3.45 | 4.15 |
| 2 | 1.98 | 2.12 | 2.47 | 3.12 | 3.51 | 4.24 |
| 3 | 1.98 | 2.12 | 2.49 | 3.12 | 3.45 | 4.26 |
| 4 | 1.98 | 2.12 | 2.45 | 3.12 | 3.45 | 4.15 |
| 5 | 1.98 | 2.14 | 2.45 | 3.12 | 3.45 | 4.15 |
| 6 | 1.98 | 2.12 | 2.45 | 3.12 | 3.45 | 4.15 |
| 7 | 1.98 | 2.12 | 2.45 | 3.12 | 3.45 | 4.15 |
| 8 | 1.98 | 2.12 | 2.45 | 3.12 | 3.45 | 4.15 |
| 9 | 1.98 | 2.12 | 2.45 | 3.12 | 3.45 | 4.15 |
| 10 | 1.98 | 2.12 | 2.45 | 3.12 | 3.45 | 4.15 |
| Average solution | 1.98 | 2.12 | 2.45 | 3.12 | 3.45 | 4.17 |
| Coefficient variation | 0.001 | 0.002 | 0.005 | 0.004 | 0.005 | 0.006 |
| Time | 50 | 70 | 79 | 83 | 91 | 94 |
| Index | Equation | NHA | SA | BA | WA | PSO | GA | MOGA | MOPSO |
|---|---|---|---|---|---|---|---|---|---|
| Correlation Coefficient | 0.93 | 0.91 | 0.86 | 0.87 | 0.75 | 0.67 | 0.74 | 0.83 | |
| Root Mean Square Error (RMSE) (106 m3) | 5.1 | 7.2 | 8.8 | 9.3 | 10.5 | 11.8 | 9.6 | 8.7 | |
| Mean absolute Error (106 m3) | 4.3 | 5.59 | 6.1 | 7.1 | 6.9 | 6.4 | 6.3 | 6.1 | |
| Volumetric Reliability Index% | 95% | 90% | 87% | 78% | 75% | 64% | 77% | 79% | |
| Resiliency Index% | 45% | 40% | 38% | 35% | 33% | 29% | 35% | 34% | |
| Vulnerability Index | 14% | 20% | 21% | 23% | 24% | 25% | 22% | 21% |
| Index | Equation | NHA | SA | BA | WA | PSO | GA | MOGA (Reddy, 2006) | MOPSO (Reddy, 2006) |
|---|---|---|---|---|---|---|---|---|---|
| Correlation Coefficient | 93% | 90% | 87% | 75% | 69% | 65% | 73% | 75% | |
| Root Mean Square Error (RMSE) (106 kwh) | 3.1 | 4.9 | 4.2 | 3.8 | 4.2 | 3.7 | 3.5 | 3.8 | |
| Mean Absolute Error (MAE) (106 kwh) | 3.2 | 4.1 | 3.8 | 3.6 | 3.4 | 3.5 | 3.3 | 3.4 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yaseen, Z.M.; Ehteram, M.; Hossain, M.S.; Fai, C.M.; Binti Koting, S.; Mohd, N.S.; Binti Jaafar, W.Z.; Afan, H.A.; Hin, L.S.; Zaini, N.; et al. A Novel Hybrid Evolutionary Data-Intelligence Algorithm for Irrigation and Power Production Management: Application to Multi-Purpose Reservoir Systems. Sustainability 2019, 11, 1953. https://doi.org/10.3390/su11071953
Yaseen ZM, Ehteram M, Hossain MS, Fai CM, Binti Koting S, Mohd NS, Binti Jaafar WZ, Afan HA, Hin LS, Zaini N, et al. A Novel Hybrid Evolutionary Data-Intelligence Algorithm for Irrigation and Power Production Management: Application to Multi-Purpose Reservoir Systems. Sustainability. 2019; 11(7):1953. https://doi.org/10.3390/su11071953
Chicago/Turabian StyleYaseen, Zaher Mundher, Mohammad Ehteram, Md. Shabbir Hossain, Chow Ming Fai, Suhana Binti Koting, Nuruol Syuhadaa Mohd, Wan Zurina Binti Jaafar, Haitham Abdulmohsin Afan, Lai Sai Hin, Nuratiah Zaini, and et al. 2019. "A Novel Hybrid Evolutionary Data-Intelligence Algorithm for Irrigation and Power Production Management: Application to Multi-Purpose Reservoir Systems" Sustainability 11, no. 7: 1953. https://doi.org/10.3390/su11071953
APA StyleYaseen, Z. M., Ehteram, M., Hossain, M. S., Fai, C. M., Binti Koting, S., Mohd, N. S., Binti Jaafar, W. Z., Afan, H. A., Hin, L. S., Zaini, N., Ahmed, A. N., & El-Shafie, A. (2019). A Novel Hybrid Evolutionary Data-Intelligence Algorithm for Irrigation and Power Production Management: Application to Multi-Purpose Reservoir Systems. Sustainability, 11(7), 1953. https://doi.org/10.3390/su11071953