3.2. Phase I: Exploratory Factor Analysis (EFA) and Reliability Analysis
This study in total involved four scales to tap into the targeted latent constructs: ideal L2 self
own, ideal L2 self
others, ought-to L2 self
own, and ought-to L2 self
others. The generation of the four-dimension items was, in principle, referred to two distinct sources: (1) the typical item phrasings adopted by the prior empirical studies, and (2) a focus group interview of seven college learners who had English learning experiences of more than 10 years. Regarding the first source, we essentially adopted four types of item phrasing formats for the corresponding L2 self constructs: (1) “I imagine a day…”, (2) ‘‘I imagine myself…”, (3) “I think I should be able to…”, and (4) “People around me think that…” [
12]. As for the second source, the participants of the focus group were interviewed with the four questions as follows: (1) “In what ways do you think that learning English can change your view of the world?”, (2) “In what ways do you think that learning English can help you connect to the world?”, (3) “Have you experienced some sort of pressure or expectation from your friends, teachers or family members regarding English learning? If yes, would you please share some stories with us?”, and (4) “Now, let’s talk about yourself. Have you set up any personal goals or aims for yourself in English learning? If yes, what are they?" Then, the creation of sample items was fundamentally based on the genuine verbal quotes extracted from the interview data so that the content validity of the L2 self scale could be ideally fulfilled. That is, the items created bore a direct link to the language tasks that may be conducted by language learners in general language learning settings, and thus pointed to the practical and functional utility associated with authentic language use. The piloting pool in total comprised 22 items, and were categorized into a four-component factor structure as theorized by Higgins [
31]: ideal L2 self
own (5 items), ideal L2 self
others (6 items), ought-to L2 self
own (5 items), and ought-to L2 self
others (6 items). However, the dimensional space underlying the 22 items still needs to be empirically explored and confirmed. To investigate the possible dimensions behind the 22 items, the items were then subjected to Principle Axis Factoring (PAF) with Varimax rotation.
Psych package was employed to execute the EFA. A check of the locations and distributions of rotated factor loadings associated with the 22 items revealed that all of the descriptors could answer to four latent variables with eigenvalues greater than 1. However, six items were removed due to their low factor loadings (<0.3).
To verify the results of EFA, parallel analysis was further implemented. As indicated in
Figure 1, the solid line indicates the eigenvalues from the actual data, whereas the dotted line refers to the eigenvalues from the simulated data generated from the
R software. The dashed line represents the eigenvalues obtained from the resampled data.
Figure 1 clearly shows that the dotted and dashed lines completely overlapped, which suggested that both the simulated and resampled data pointed to the same results. According to
Figure 1, the number of factors (denoted by triangle) above both the dotted and dashed lines is four. In sum, the results of both PAF and parallel analysis suggested that a four-component factorial structure could be achieved.
Ideal L2 self
own consisted of four items (α = 0.82, sample item:
I imagine a day I blog in English to share my thoughts with friends abroad.); ideal L2 self
others also comprised of four items (α = 0.83, sample item:
I imagine a day that friends around me will admire me because I converse in English with international friends online.); four items were conceptualized respectively for ought-to L2 self
own (α = 0.86, sample item:
I think that I should be able to easily converse with others in English and for ought-to L2 self
others (α = 0.87, sample items:
People around me think that I should blog in English to share my thoughts with international community online.). Please refer to
Appendix A for the specific items of each L2 self measure.
3.3. Phase II: Confirmatory Factor Analysis
To validate the hypothesized quadro-component CFA model, confirmatory factor analysis was performed to test the extent to which the implied model fit the empirical model. LISREL 9.0 was used to implement the analysis. Several criteria were considered for the fit analysis. These included the chi-square difference test, Comparative Fit Index (CFI), Normed Fit Index (NFI), and Non-Normed Fit Index (NNFI), and RMSEA.
To validate the viability of the quadro-component CFA model, seven other competing models were further conceptualized as competing models. The quadro-component CFA model was operationalized as Modelg, whereas Modela, Modelb, Modelc, Modeld, Modele, Modelf, and Modelh were referred to as Modelg’s competing models. They are further described in detail in the following:
- (a)
Modela = 1-factor model, in which all 16 items were assumed to load on the same factor.
- (b)
Modelb = 2-factor modelUncorr., in which the items of the two types of ideal L2 self and the items of the two types of ought-to L2 self were assumed to load on the same factor, respectively, but no correlation was assumed between the two factors.
- (c)
Model
c = 2-factor model
Corr., in which the modeling strategy is the same as that of Model
b except that the correlation between the two factors was allowed to be freely estimated. The formulations of Model
b and Model
c essentially operationalized Dörnyei’s [
3] dichotomous classification of L2 self-images.
- (d)
Modeld = 3-factor modelUncorr., in which the items of ideal L2 self were assumed to load on only one factor, whereas the items of the ought-to L2 self were assumed to load on two different factors (i.e., ought-to L2 selfown and ought-to L2 selfothers). Besides, the three factors were also assumed to be mutually independent.
- (e)
Model
e = 3-factor model
Corr., the modeling strategy is the same as that of Model
d except that the correlations among the three factors were allowed to be freely estimated. The formulations of Model
d and Model
e were based on the empirical findings of Teimouri [
32].
- (f)
Modelf = 4-factor modelUncorr., in which the four types of L2 self constructs were independently modeled, and each factor had four items loaded on it.
- (g)
Model
g = 4-Factor Model
Corr., in which the mutual relationships among the four L2 self-factors are released to be freely estimated. The formulations of Model
f and Model
g were based on the theorizing of Higgins [
31].
- (h)
Modelh = 2nd-order 4-Factor ModelCorr., in which the modeling strategy is the same as that of Modelg but the correlation between the two superordinate factors was freed to be estimated.
Table 1 reports the means and standard deviations of the model variables as well as their inter-correlations. As a whole, the participants were more inclined to develop ideal L2 self
own (M = 18.77, SD = 4.74) and ideal L2 self
others (M = 18.23, SD = 5.03) images than ought-to L2 self
own (M = 15.68, SD = 4.76) and ought-to L2 self
others (M = 14.64, SD = 4.74) images. Regarding the relationships between the four types of L2 self-images, it can be seen that all the correlation coefficients reached statistical significance. The strongest relationship was detected between ideal L2 self
own and ideal L2 self
others (
r = 0.78,
p < 0.01). Similarly, ought-to L2 self
own and ought-to L2 self
others were also strongly correlated (
r = 0.7 2,
p < 0.01). Additionally, various degrees of moderate relationships were further detected among the four types of L2 self-measures. Notably, ideal L2 self
others bore a stronger relationship with ought-to L2 self
others (
r = 0.58,
p < 0.01) than with ought-to L2 self
own (
r = 0.48,
p < 0.01), whereas ideal L2 self
own was more associated with ought-to L2 self
own (
r = 0.52,
p < 0.01) than with ought-to L2 self
others (
r = 0.31,
p < 0.01).
The outcome model figures of all eight CFA models are shown in
Appendix B. Following the modeling strategy implemented in the study, we firstly test Model
a (1-factor model). The results showed that the 1-factor model fit the data poorly (χ
2 = 15430.5 4,
df = 104,
p < 0.001; NFI = 0.87, NNFI = 0.85, CFI = 0.87, RMSEA = 0.241, [90% CI: 0.233, 0.250]), suggesting that the L2 self construct was unlikely to be unidimensional, but was multidimensional in nature. Then, we further tested Model
b (2-factor model
Uncorr.).The results indicated that Model
b could obtain acceptable fit (χ
2 = 803.47,
df = 104,
p < 0.001; NFI = 0.93, NNFI = 0.93, CFI = 0.94, RMSEA = 0.136, [90% CI: 0.127, 0.144]) and could improve significantly in fit over Model
a. In a similar vein, when Model
c (2-factor model
Corr.) was analyzed, it was found that Model
c could not only fit the empirical data well (χ
2 = 664.65,
df = 103,
p< 0.001; NFI = 0.94, NNFI = 0.94, CFI = 0.95, RMSEA = 0.128, [90% CI: 0.120, 0.1 37]), but also overrode Model
b via an χ
2diff. test (χ
2diff. = 56.2,
dfdiff. = 1,
p < 0.001), suggesting that ideal L2 self and ought-to L2 self empirically shared common variance. After testing Model
c, we move on to implement Model
d (3-factor Model
Uncorr.) for analysis, and the results showed that the fit performance of Model
d (χ
2 = 841.28,
df = 104,
p < 0.001; NFI = 0.93, NNFI = 0.93, CFI = 0.94, RMSEA = 0.131, [90% CI: 0.123, 0.140]) was inferior to that of Model
c, supporting the intercorrelation between ideal L2 self and ought-to L2 self. Hence, we further tested Model
d (3-Factor Model
Corr.), and it was found that accounting for the intercorrelations among ideal L2 self, ought-to L2 self
own and ought-to L2 self
others helped significantly improve the model fit performance of Model
e (χ
2 = 510.77,
df = 101,
p < 0.001; NFI = 0.96, NNFI = 0.96, CFI = 0.96, RMSEA = 0.106, [90% CI: 0.097, 0.115]).
However, although Modele fit the empirical data better than its counterpart (i.e., Modeld), this did not necessarily mean that a 3-factor construct could ideally represent the inner factorial structure of L2 self. By way of testing Modelf and Modelg, the results showed that Modelg (4-factor correlated model) had a much better model fit performance (χ2 = 364.02, df = 98, p < 0.001, NFI = 0.97, NNFI = 0.9 7, CFI = 0.98, RMSEA = 0.08, [90% CI: 0.071, 0.089]) than Modelf (χ2 = 1062.47, df =104, p < 0.001, NFI = 0.91, NNFI = 0.90, CFI = 0.92, RMSEA = 0.152, [90% CI: 0.144, 0.161]). In truth, Modelg achieved the best model fit performance among the first seven competing models (Modela → Modelb → Modelc→Modeld →Modele → Modelf → Modelg). Thus, a multidimensional, mutually-correlated 4-factor structure of L2 self could be empirically supported.
Finally, on the basis of Modelg, we implemented Modelh to check whether a higher order structure of L2 self could be empirically supported. The results showed that the model fit performance of Modelh (χ2 = 370.45, df = 99, p < 0.001; NFI = 0.97, NNFI = 0.97, CFI = 0.98, RMSEA = 0.081, [90% CI: 0.071, 0.090]) was nearly identical to that of Modelg except for its slightly higher χ2 values. Nevertheless, by way of implementing a χ2diff. test to allow Modelh to compete against Modelg, it was found that Modelg was still more parsimonious than Modelh (χ2diff. = 6.43, dfdiff. = 1, p < 0.01), suggesting that a simpler, 1st-order factorial structure significantly differed from a more complex, 2nd-order one.
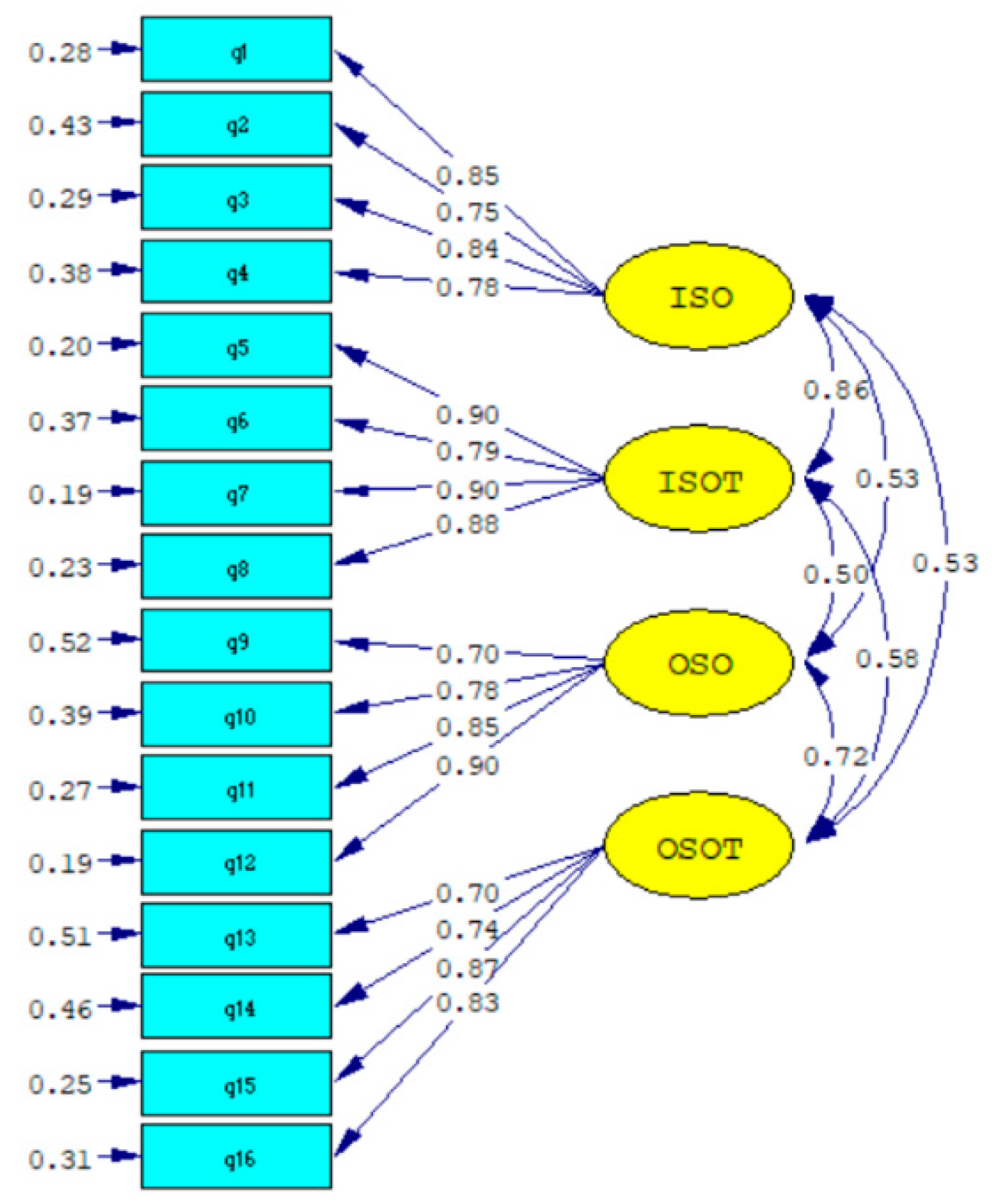
As shown in the outcome of Model
g (4-Factor Model
Corr.), it could be seen that after the measurement errors of the items were modeled, the strongest relationship was again found between ideal L2 self
own and ideal L2 self
others (
r = 0.86,
p < 0.001). Likewise, ideal L2 self
own was found to correlate with both ought-to L2 self
own and ought-to L2 self
others in an identical manner (
r = 0.53,
p< 0.001). However, ideal L2 self
others was found to correlate more with ought-to L2 self
others (
r = 0.5 8,
p < 0.001) than with ought-to L2 self
own (
r = 0.5 0,
p < 0.0 01). Furthermore, the relationship between ought-to L2self
own and ought-to L2 self
others in the CFA analysis (
r = 0.72,
p < 0.001) was the same as that in the raw data analysis as reported in
Table 1. Evidently, on top of the support of construct validity, the 4-factor Model
Corr. further demonstrated not only a strong degree of convergent validity, but also a clear level of discriminant validity among the four types of L2 self-measures. Finally, the factor loadings of all 16 items varied between 0.90 and 0.70. This finding suggested that the items developed for the four types of L2 self-measures were indicative of strong empirical validity of the specific L2 self construct they represented. The outcome model figure (Model
g, 4-factor Model
Corr.) is illustrated in
Figure 2, whereas the other rival models are shown in
Appendix B.
3.4. Phase III: Multidimensional Rasch Analysis
After the inner factorial structure was empirically confirmed, we then examined the item fit performance on the basis of the 4-factor correlated model. To achieve this, item parameter fits were calculated using the multidimensional Rasch model. The weighted MNSQ values served as item fit indices for evaluating the adequacy of the multidimensional model. The software ConQuest 3.0 was used to generate item fit indices for all 16 items.
As the previous literature [
39,
40] has suggested, the performance of item fit was assessed by checking the value of mean square fit statistics, ideally ranging between 0.7 and 1.3. As reported in
Table 2, the weighted MNSQ fit values of all the 16 final items fell within this acceptable range, indicating that these items all showed good fit.
Furthermore, we used
category characteristic curves to examine whether the items fit the multidimensional Rasch measurement model. Category characteristic curves illustrate the anticipated pattern of the probability for a person to endorse a response category, with higher person ability or latent trait levels entailing higher probabilities of endorsing a higher-level response category. Since a total of six response categories (Absolutely Not True of Me—Not True of Me—Slightly Not True of Me—Slightly True of Me—True of Me—Very True of Me) were embedded in every scale item, every item could ideally have five ordered thresholds as signified by the Delta points along the horizontal axis for latent trait logits. The category characteristic curves of Item 6 altogether serve as an example of category characteristic curves bearing five ordered thresholds as well as six arc-shaped lines (see
Figure 3).
In
Figure 3, the curve of response category 1 showed that a person with an ideal L2 self
others trait level of −5.0 logits has about a 0.97 probability of selecting the ‘
absolutely not true of me’ category, whereas a person with a trait level of 0.0 logits had a relatively much lower probability (0.03) of selecting the same category in Item 6. As for the curve of response category 4, a person with an ideal L2 self
others trait level of about −2.7 logits had a near zero probability of selecting the ‘
slightly true of me’ category, in contrast with a person of a trait level of near 0.5 logits having an approximately 0.4 probability of selecting the same category.
Furthermore, the curve of response category 6 displayed that a person with an ideal L2 self
others trait level of −0.6 logits has a probability near zero of selecting the ‘
very true of me’ category, while a person with a trait level of 2.0 logits had a probability of approximately 0.58 of selecting the same category. In sum,
Figure 3 illustrates that the respondents could justifiably and consistently differentiate the response categories as specified by the scale.
Figure 4 further displays the item information curves based on the 4-factor multidimensional Rasch model analysis. It was shown that all the curves peaked above 1, suggesting that all 16 items were informative in that they were representative of the corresponding dimensions to which they belong. This result could be triangulated with the high factor loadings as revealed in the 4-factor correlated CFA model.
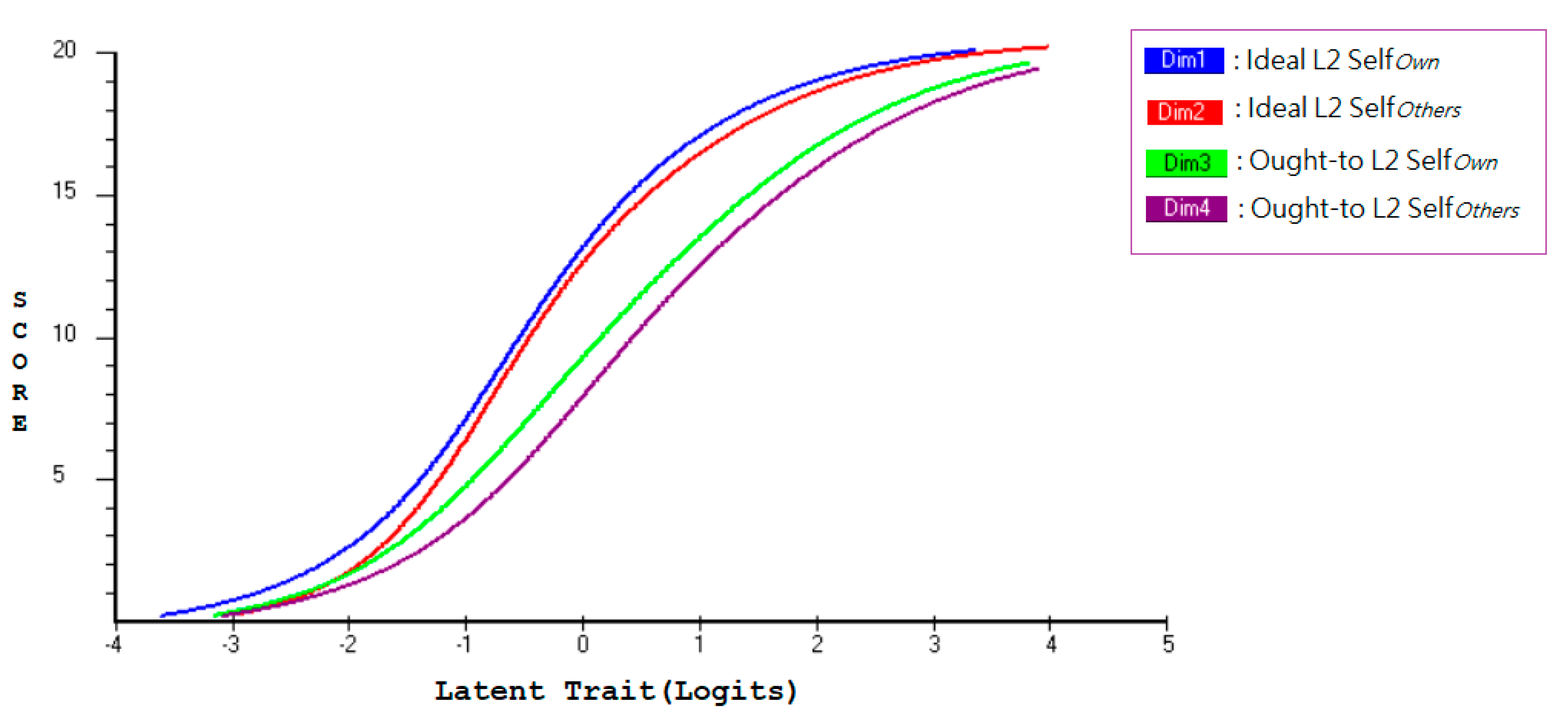
On the basis of the four-dimension analysis,
Figure 5 illustrates that, regardless of which latent trait level, ideal L2 self
own was the most likely to be configured by the participants of the study, followed by ideal L2 self
others, then by ought-to self
own, and the least by ought-to self
others. This finding suggests that the two ideal L2 self-guides (blue curve and red curve) may carry more weight than the two ought-to self-guides (green curve and purple curve) in leading L2 learners to exhibit a higher degree of intended effort regarding L2 learning. Furthermore, by way of comparison, the two own-driven self-guides (blue curve and green curve) were more likely to be endorsed than their counterparts which were typically driven by significant others (red curve and purple curve).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}