Rethinking Highway Safety Analysis by Leveraging Crowdsourced Waze Data



Abstract
:1. Introduction
- What are the spatiotemporal distribution characteristics of WIRs and PCRs?
- Can WIRs be used as a surrogate data source when PCRs are unavailable?
- Can the crash hot spots be better captured by integrating WIRs and PCRs?
2. Literature Review
2.1. Related Works

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topics | Publication | Research Purpose | Data |
|---|---|---|---|
| Comparison Between Waze Data and Other Data Sources | Goodall and Lee [11] | Evaluate the accuracy of crash and disabled vehicle Waze reports | Traffic camera and Waze |
| Amin-Naseri et al. [12] | Compare Waze with other official and unofficial data sources to evaluate its reliability and coverage | Official and unofficial incident data sources | |
| Dos Santos [13] | Compare Waze report with the official incident report and their spatial distribution | Official incidents data | |
| Fire et al. [4] | Find the correlation between the number of Waze reports and the number of police reports | Police reports and Waze | |
| Using Waze Data in Prediction Model | Flynn et al. [14] | Investigate the relationship between Waze reports and official crash report | Historical fatal crash count and traffic-related variables. |
| Parnami et al. [15] | Estimate the time of travel from point A to point B using prior Waze data | Waze only | |
| Waze Data Characterization and Visualization | Silva et al. [5] | Characterize Waze data (e.g., most common report, user participation pattern, etc.) | Waze only |
| Monge-Fallas et al. [8] | Visualize the most congested routes, traffic density, and users’ travel speed using Waze data | Waze only | |
| Estrada-S et al. [10] | Identify heavy traffic zones based on Waze using the clustering method | Waze only | |
| Perez et al. [9] | Identify Waze-intense areas and road segments using a clustering method | Waze only |
2.2. Knowledge Gaps and Solutions
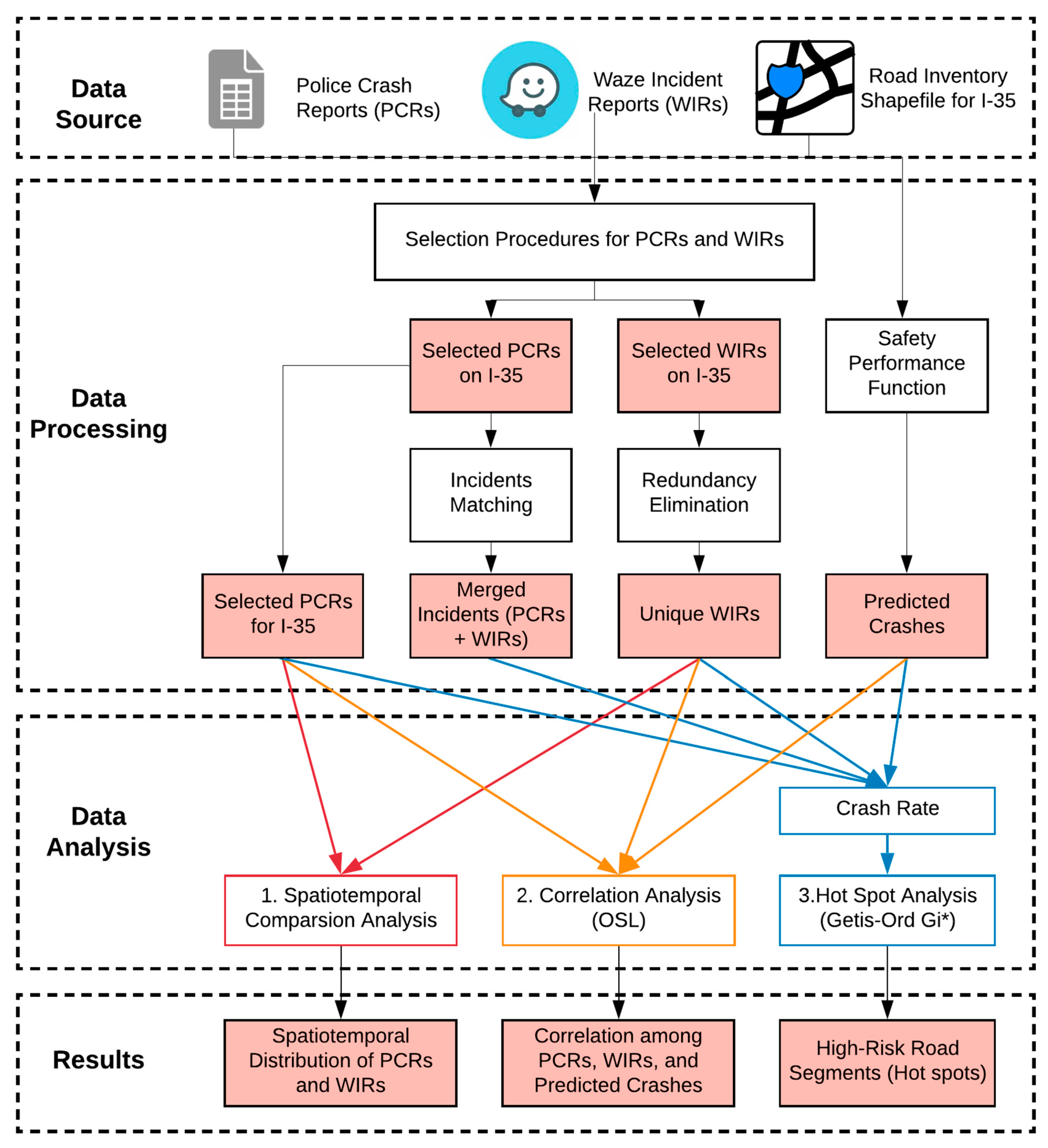
3. Data and Methods
- Spatiotemporal comparison analysis: characterize the spatiotemporal distributions of PCRs and WIRs.
- Correlation analysis: investigate the relationship between PCRs, WIRs, and predicted crashes to test further if WIRs could be used as a surrogate safety measure when PCRs are unavailable.
- Hot spot analysis:
- (1)
- calculate crash rates for each road segment using PCRs, unique WIRs, merged dataset, and predicted crashes, respectively;
- (2)
- perform hot spot analysis (Getis-Ord Gi *) using different crash rates to identify high-risk road segments. This analysis aims to evaluate if WIRs could capture more traffic risks ignored by the conventional crash datasets (e.g., PCRs).
3.1. Data Overview
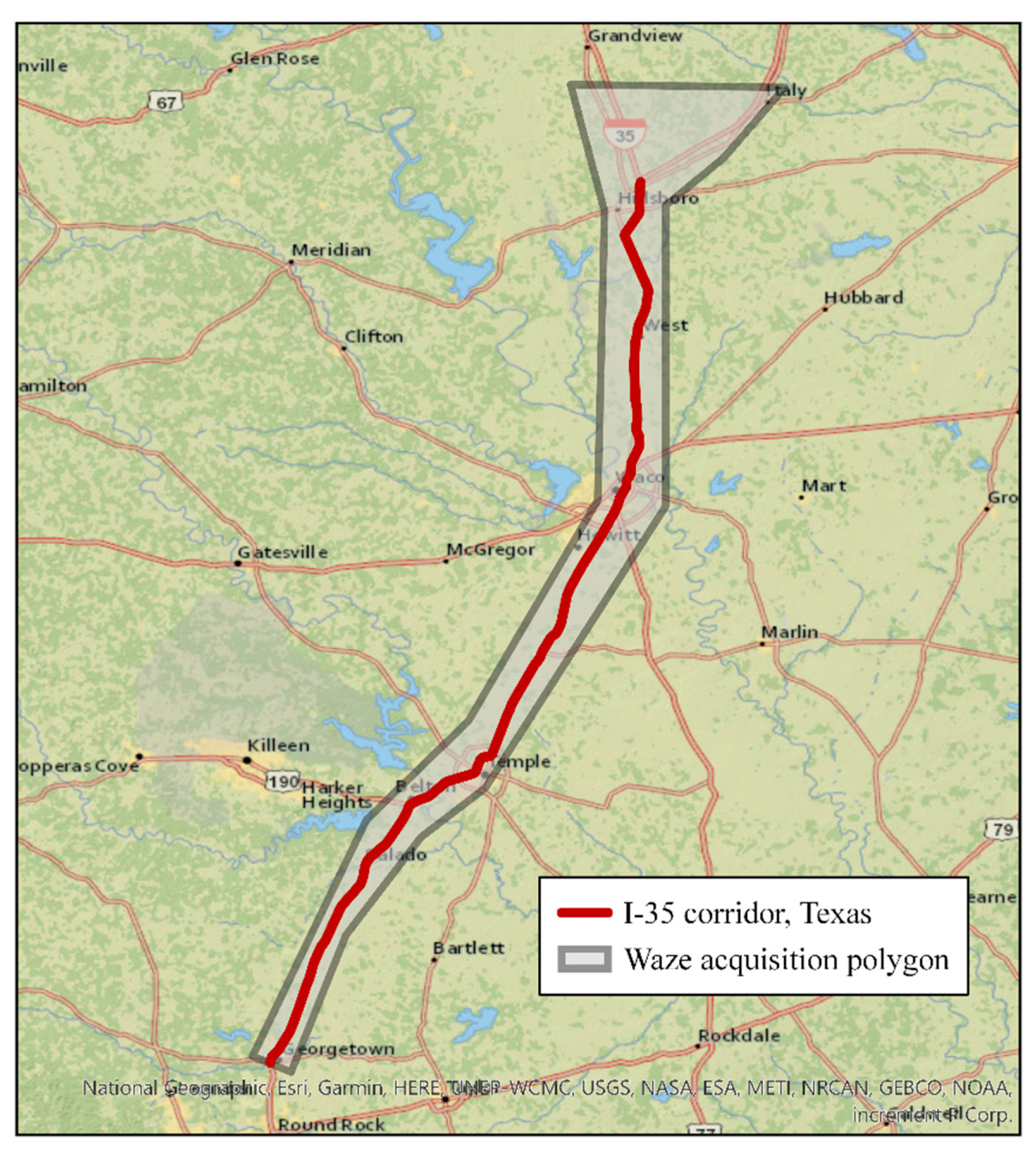
3.1.1. Waze Incidents Reports (WIRs) Acquisition and Selection
- Criteria 1: reliability score > 5 AND street name = I-35
- Criteria 2: reliability score > 5 AND road type = Freeways AND distance to I-35 < 60 m (~200 feet).
3.1.2. Police Crash Reports (PCRs) Acquisition and Selection
- Criteria: roadway part (on which crash occurred) = main/proper lane AND roadway system = Interstate AND whether a crash occurred at an intersection and ramp = No.
3.1.3. Roadway Characteristics
3.2. Data Processing and Integration
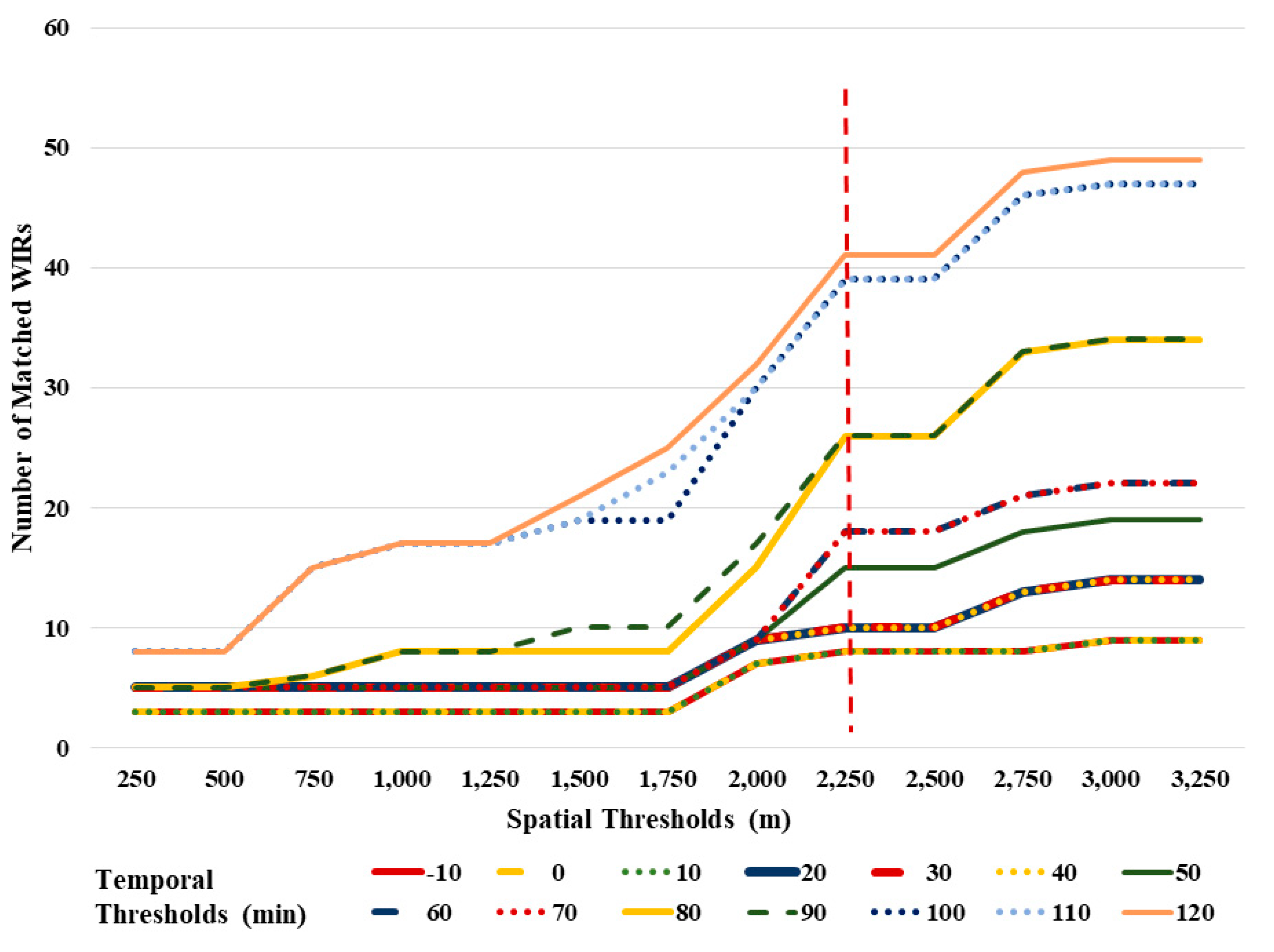
3.2.1. WIRs Redundancy Elimination and Matching with PCRs
- Spatial threshold range: from 0–3500 m (~2.5 miles) with 250 m (~0.15 miles) increment
- Temporal threshold range: from −20 (minutes earlier than PCRs)–120 (minutes later than PCRs) with a 10-min increment
3.2.2. Predictive Models for Crash Frequency Estimation
3.3. Data Analysis Methods
3.3.1. Crash Rate Calculation
3.3.2. Hot Spot Analysis (Getis-Ord Gi *)
4. Results
4.1. Result for WIRs Redundancy Elimination and Matching with PCRs
- Spatial threshold: in a 2250-m radius.
- Temporal thresholds: 90 min (−20 to 70 min).
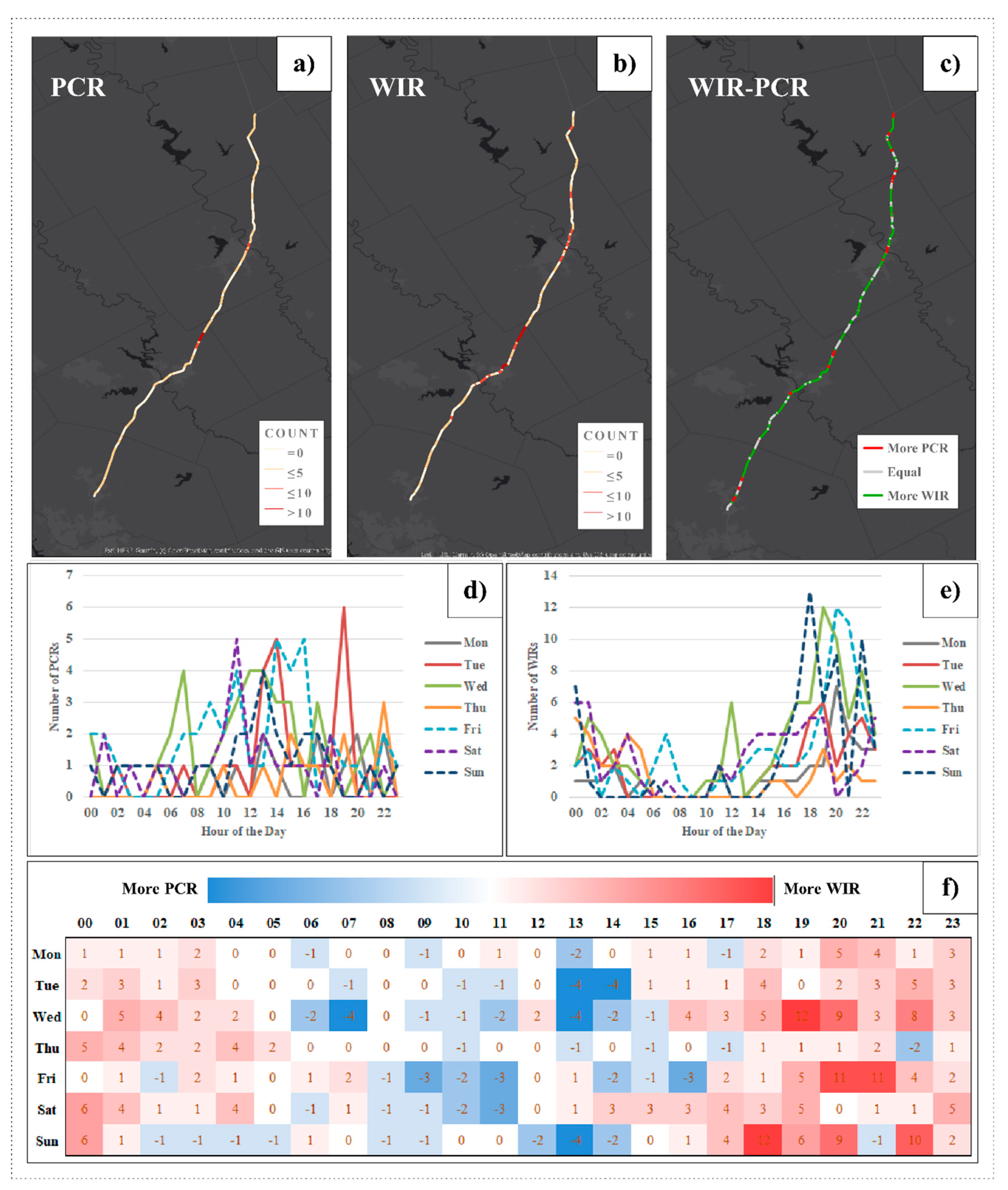
4.2. Spatiotemporal Comparison Analysis
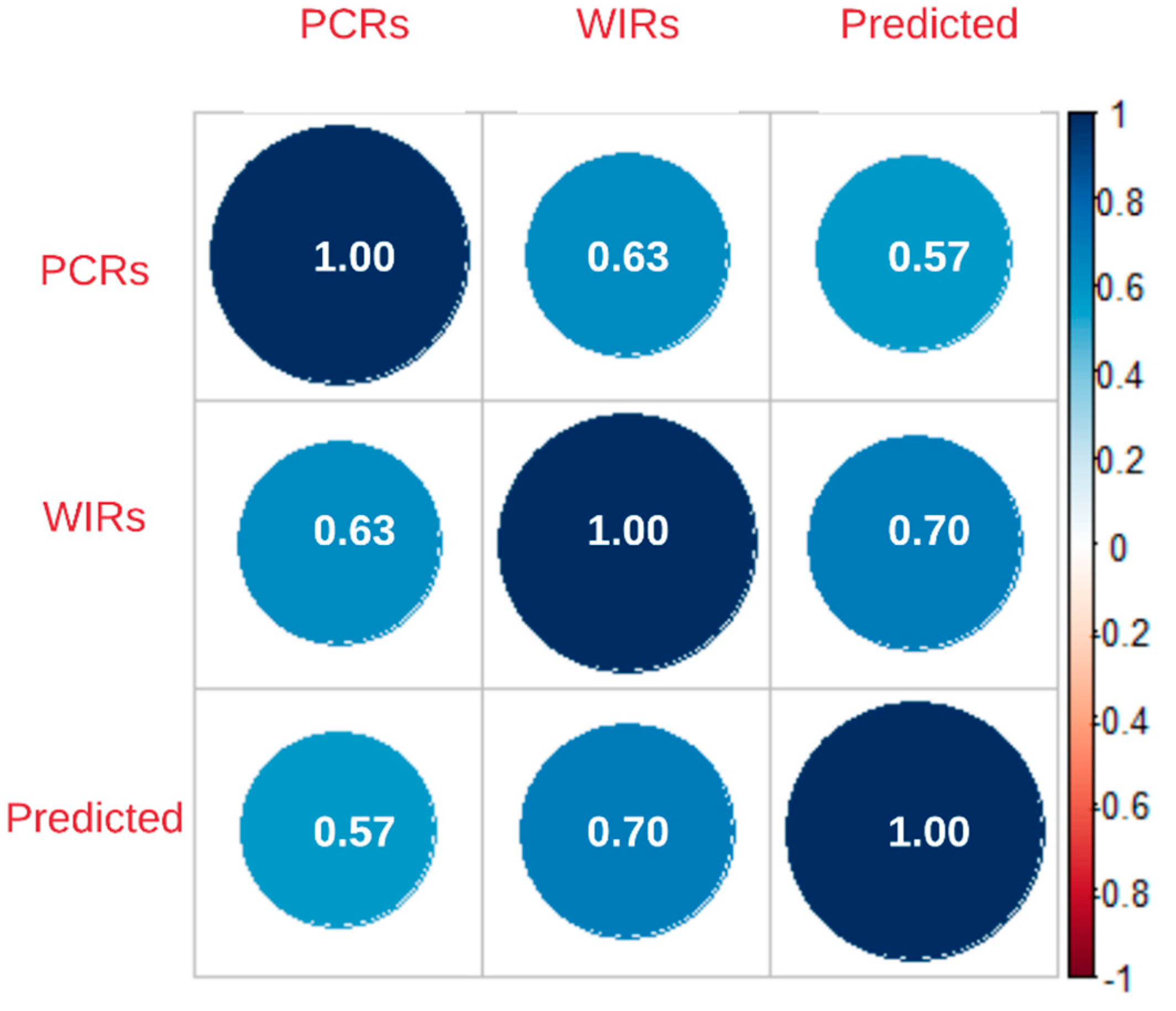
4.3. Correlation Analysis
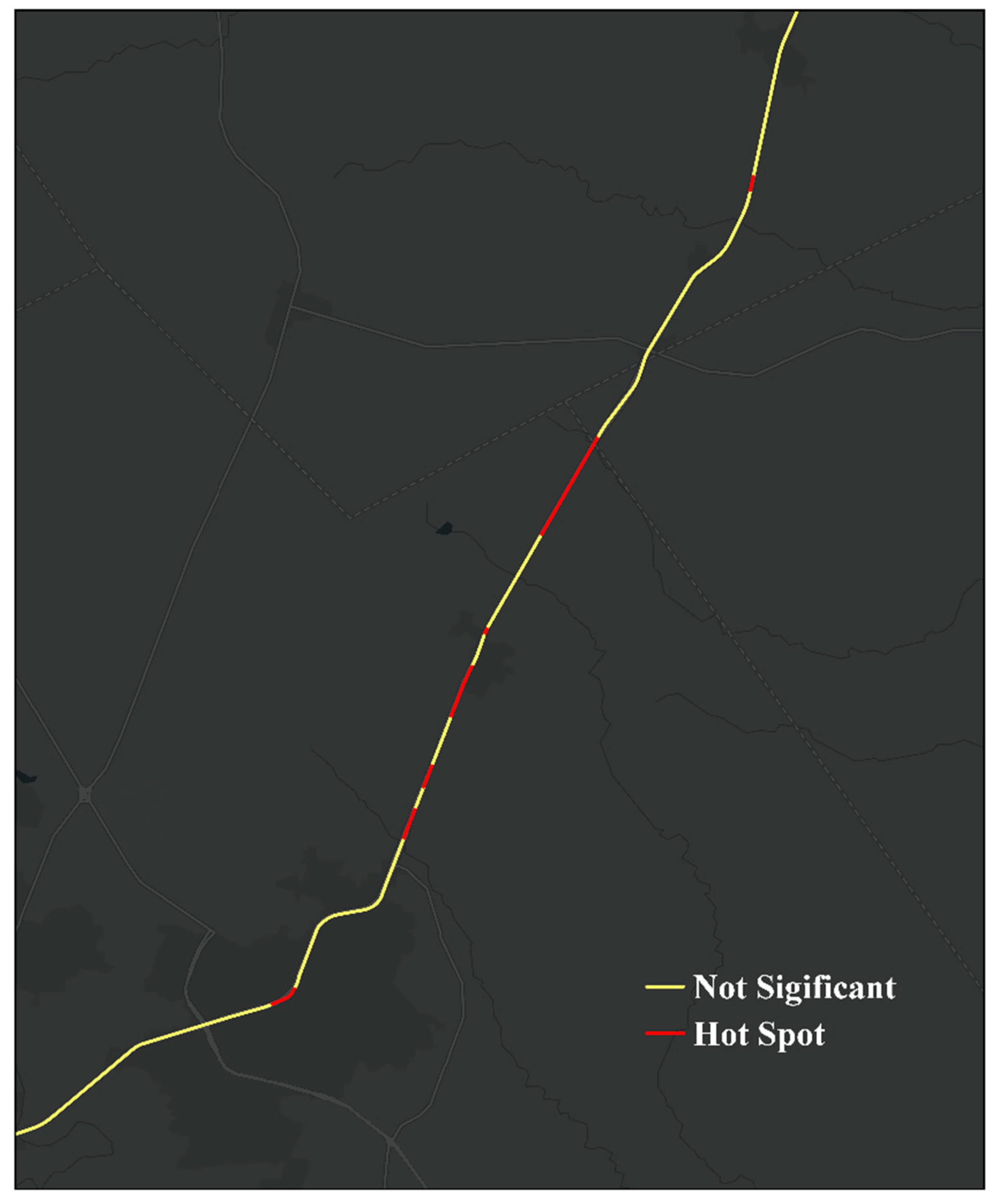
4.4. Hot Spot Analysis
5. Discussion
6. Conclusions
- PCRs and WIRs show a very similar spatial distribution; however, their temporal distribution can be significantly different.
- PCRs are highly correlated with WIRs, suggesting that WIRs can be a strong predictor in crash prediction models.
- By combining PCRs and WIRs, more high-risk road segments can be identified, which suggests that both official crash records and crowdsourced traffic incidents need to be considered in future safety analysis.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- World Health Organization Global Status Report on Road Safety. 2018. Available online: https://www.who.int/violence_injury_prevention/road_safety_status/2018/en/ (accessed on 28 January 2019).
- U.S. National Highway Traffic Safety Administration Traffic Safety Facts 2016 Data. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/812580 (accessed on 25 August 2019).
- Li, X.; Goldberg, D.W. Toward a mobile crowdsensing system for road surface assessment. Comput. Environ. Urb. Syst. 2018, 69, 51–62. [Google Scholar] [CrossRef]
- Fire, M.; Kagan, D.; Puzis, R.; Rokach, L.; Elovici, Y. Data Mining Opportunities in Geosocial Networks for Improving Road Safety. In Proceedings of the 2012 IEEE 27th Convention of Electrical and Electronics Engineers in Israel, Eilat, Israel, 14–17 November 2012. [Google Scholar]
- Silva, T.H.; Vaz De Melo, P.O.S.; Viana, A.C.; Almeida, J.M.; Salles, J.; Loureiro, A.A.F. Traffic condition is more than colored lines on a map: Characterization of Waze alerts. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2013; Volume 8238, pp. 309–318. [Google Scholar]
- Li, X.; Huo, D.; Goldberg, D.W.; Chu, T.; Yin, Z.; Hammond, T. Embracing crowdsensing: An enhanced mobile sensing solution for road anomaly detection. ISPRS Int. J. Geo. Inf. 2019, 8, 412. [Google Scholar] [CrossRef] [Green Version]
- Waze Waze Company Factsheet. Available online: https://assets.brandfolder.com/p31v19-dpmnts-ci9it3/original/WazeCompanyFactsheet.pdf (accessed on 18 July 2019).
- Monge-Fallas, J.; Hernandez-Castro, F.; Gonzalez-Villalobos, S.; Barquero-Rodriguez, E.; Esquivel-Piedra, J. Traffic Data Visualization in costa Rica: A Visualization of Top 100 Routes with the Highest Traffic Density in Costa Rica. PONTE Int. Sci. Res. J. 2016, 72, 262–273. [Google Scholar] [CrossRef]
- Perez, G.V.A.; Lopez, J.C.; Cabello, A.L.R.; Grajales, E.B.; Espinosa, A.P.; Fabian, J.L.Q. Road Traffic Accidents Analysis in Mexico City through Crowdsourcing Data and Data Mining Techniques. Int. J. Comp. Inf. Eng. 2018, 12, 604–608. [Google Scholar]
- Estrada, S.R.F.; Molina, A.; Perez-Espinosa, A.; Reyes, C.A.L.; Quiroz, F.J.L.; Bravo, G.E. Zonification of Heavy Traffic in Mexico City. In Proceedings of the International Conference on Data Mining (DMIN), Las Vegas, NV, USA, 25–28 July 2016. [Google Scholar]
- Goodall, N.; Lee, E. Comparison of Waze crash and disabled vehicle records with video ground truth. Transp. Res. Interdiscip. Perspect. 2019, 1, 100019. [Google Scholar] [CrossRef]
- Amin-Naseri, M.; Chakraborty, P.; Sharma, A.; Gilbert, S.B.; Hong, M. Evaluating the Reliability, Coverage, and Added Value of Crowdsourced Traffic Incident Reports from Waze. Transp. Res. Rec. 2018, 2672, 34–43. [Google Scholar] [CrossRef] [Green Version]
- Dos Santos, S.R.; Davis, C.A.; Smarzaro, R. Integration of Data Sources on Traffic Accidents. In Proceedings of the Brazilian Symposium on GeoInformatics, Campos do Jordão, SP, Brazil, 27–30 November 2016; National Institute for Space Research, INPE: São José dos Campos, Brasil, 2016; Volume 2016, pp. 192–203. [Google Scholar]
- Flynn, D.; Gilmore, M.; Sudderth, E. Estimating Traffic Crash Counts Using Crowdsourced Data: Pilot Analysis of 2017 Waze Data and Police Accident Reports in Maryland; Volpe National Transportation Systems Center: Cambridge, MA, USA, 2018. [Google Scholar]
- Parnami, A.; Bavi, P.; Papanikolaou, D.; Akella, S.; Lee, M.; Krishnan, S. Deep Learning Based Urban Analytics Platform: Applications to Traffic Flow Modeling and Prediction. In ACM SIGKDD Workshop on Mining Urban Data (MUD3); ACM: London, UK, 2018. [Google Scholar]
- Texas DOT Crash Records Information System. Available online: https://cris.dot.state.tx.us/public/Purchase/app/home/welcome (accessed on 25 July 2019).
- Texas DOT Roadway Inventory. Available online: https://www.txdot.gov/inside-txdot/division/transportation-planning/roadway-inventory.html (accessed on 25 July 2019).
- American Association of State Highway and Transportation Officials. Highway Safety Manual, 1st ed.; American Association of State Highway and Transportation Officials: Washington, DC, USA, 2010. [Google Scholar]
- Bonneson, J.A.; Pratt, M.P. Roadway Safety Design Workbook.; Texas Transportation Institute: Bryan, TX, USA, 2009. [Google Scholar]
- The U.S. National Highway Safety Administration Crash Rate Calculations. Available online: https://safety.fhwa.dot.gov/local_rural/training/fhwasa1109/app_c.cfm (accessed on 5 July 2020).
- Songchitruksa, P.; Zeng, X. Getis-ord spatial statistics to identify hot spots by using incident management data. Transp. Res. Rec. 2010, 2165, 42–51. [Google Scholar] [CrossRef]
- Esri How Hot Spot Analysis (Getis-Ord Gi*) Works. Available online: https://pro.arcgis.com/en/pro-app/tool-reference/spatial-statistics/h-how-hot-spot-analysis-getis-ord-gi-spatial-stati.htm (accessed on 2 December 2020).






| Roadway Design Elements | Maximum | Minimum | Mean | Std. Dev. |
|---|---|---|---|---|
| Length (in miles) | 4.136 | 0.001 | 0.374 | 0.530 |
| Annual average daily traffic (AADT) | 132,225 | 56,176 | 73,685.068 | 14,747.346 |
| Lane Width (in feet) | 20 | 11 | 12.238 | 1.135 |
| Inside Shoulder Width (in feet) | 32 | 0 | 13.745 | 5.699 |
| Outside Shoulder Width (in feet) | 44 | 0 | 20.065 | 4.460 |
| % of Trucks in AADT | 30.3 | 1.2 | 25.260 | 4.089 |
| Median Width (in feet) | 50 | 3 | 28.432 | 9.076 |
| Typical Segment Types (Number of Segments) | 82 | Urban 6-lane | Urban 4-lane | 58 |
| 108 | Rural 6-lane | Rural 4-lane | 46 |
| Goodness of Fit Statistics | CD20 | CD30 | CD40 | CD50 | CD60 | CD70 |
|---|---|---|---|---|---|---|
| t-statistic | −1 | −1.63299 | −2.23607 | −1.98248 | −2.2088 | −2.6295 |
| p-value one-tail | 0.195501 | 0.088904 | 0.037793 | 0.047349 | 0.031454 | 0.015101 |
| t Critical one-tail | 2.353363 | 2.131847 | 2.015048 | 1.94318 | 1.894579 | 1.859548 |
| p-value two-tail | 0.391002 | 0.177808 | 0.075587 | 0.094698 | 0.062909 | 0.030201 |
| t Critical two-tail | 3.182446 | 2.776445 | 2.570582 | 2.446912 | 2.364624 | 2.306004 |
| Model Parameters | Model 1 | Model 2 |
|---|---|---|
| Estimate (St. D.) | Estimate (St. D.) | |
| Intercept | 0.144 (0.069) | 0.030 (0.072) |
| Unique WIRs | 0.354 *** (0.025) | 0.255 *** (0.035) |
| Predicted Crashes | 0.123 *** (0.031) | |
| R-squared | 0.402 | 0.434 |
| Adjusted R-squared | 0.400 | 0.430 |
| No. observations | 294 | |
| Datasets | August | October | November | December | Four-month |
|---|---|---|---|---|---|
| PCRs | 266, 278, 318, 323, 334, 337, 341, 350, 352, 354, 355, 357, 363 | 266, 276, 298, 299, 303, 306, 308, 310, 317, 327, 351, 356, 358, 368 | 291, 292, 303, 306, 308, 318, 333, 334, 343, 351, 353, 358, 363, 367 | 266, 288, 303, 306, 317, 332, 334, 342 | 266, 298, 303, 317, 334, 342, 358, 363 |
| WIRs | 294, 318, 319, 356, 363, 364 | 298, 299, 303, 305, 307, 308, 310, 315, 319, 344, 350, 356, 357, 366, 368 | 291, 303, 315, 318, 336, 344, 357, 363, 368 | 291, 299, 303, 305, 306, 308, 310, 318, 327, 332, 350, 359 | 284, 294, 303, 307, 315, 317, 319, 344, 356, 357, 363, 364, 368 |
| Merged dataset (WIR+PCR) | 264, 266, 294, 318, 319, 337, 352, 354, 355, 356, 363, 364, 366, 367 | 248, 298, 299, 303, 307, 308, 310, 315, 317, 319, 336, 351, 356, 357, 358, 366, 368 | 291, 292, 303, 315, 317, 318, 334, 344, 358, 363, 368 | 266, 291, 305, 308, 327, 332, 342, 334, 350, 359, | 284, 294, 298, 303, 315, 317, 334, 336, 356, 357, 358, 363, 364, 368 |
| Predicted Crashes (2016) | 317, 363, 293, 317, 385 | ||||
| |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Dadashova, B.; Yu, S.; Zhang, Z. Rethinking Highway Safety Analysis by Leveraging Crowdsourced Waze Data. Sustainability 2020, 12, 10127. https://doi.org/10.3390/su122310127
Li X, Dadashova B, Yu S, Zhang Z. Rethinking Highway Safety Analysis by Leveraging Crowdsourced Waze Data. Sustainability. 2020; 12(23):10127. https://doi.org/10.3390/su122310127
Chicago/Turabian StyleLi, Xiao, Bahar Dadashova, Siyu Yu, and Zhe Zhang. 2020. "Rethinking Highway Safety Analysis by Leveraging Crowdsourced Waze Data" Sustainability 12, no. 23: 10127. https://doi.org/10.3390/su122310127
APA StyleLi, X., Dadashova, B., Yu, S., & Zhang, Z. (2020). Rethinking Highway Safety Analysis by Leveraging Crowdsourced Waze Data. Sustainability, 12(23), 10127. https://doi.org/10.3390/su122310127