3.2.1. Pretest
Before carrying out the analysis, it is recommendable to examine the correlation matrix to search for variables which do not correlate well with any other (with correlation coefficients less than 0.3), and variables which correlate too well with others (variables with some correlation coefficients higher than 0.9). The former should be eliminated from the analysis while the latter can be maintained, albeit taking into account that they may cause problems of multicollinearity. In our case, there were no problems of this kind.
We also carried out Bartlett’s test of sphericity in order to check that it was significant, in other words, that our matrix was not similar to an identity matrix. Indeed, we obtained a p-value of p < 0.05, indicating that the matrix was factorizable.
We also estimated the Keiser–Meyer–Olkin (KMO) coefficient. For the factor analysis (FA) carried out on Sections 1, 2, 3 and 4, all of the KMO coefficients were above 0.7, with values of 0.72, 0.87, 0.80 and 0.90 respectively. It should be remembered that the KMO coefficient is better when it is closer to 1, which indicates that the application here of an FA was correct and that Section 1 was the least stable. When the FA was applied to the questionnaire as a whole, a KMO of 0.91 was obtained.
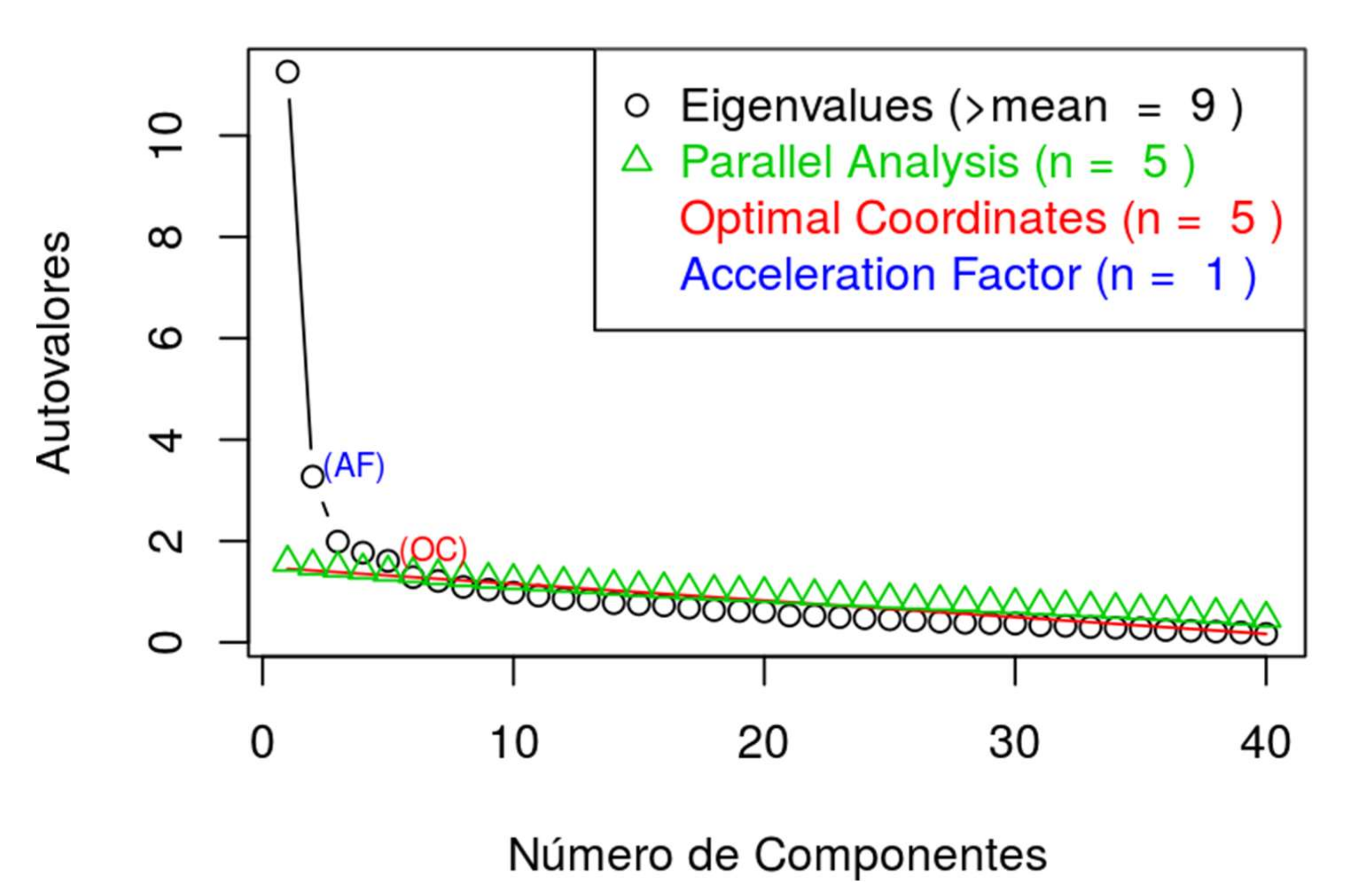
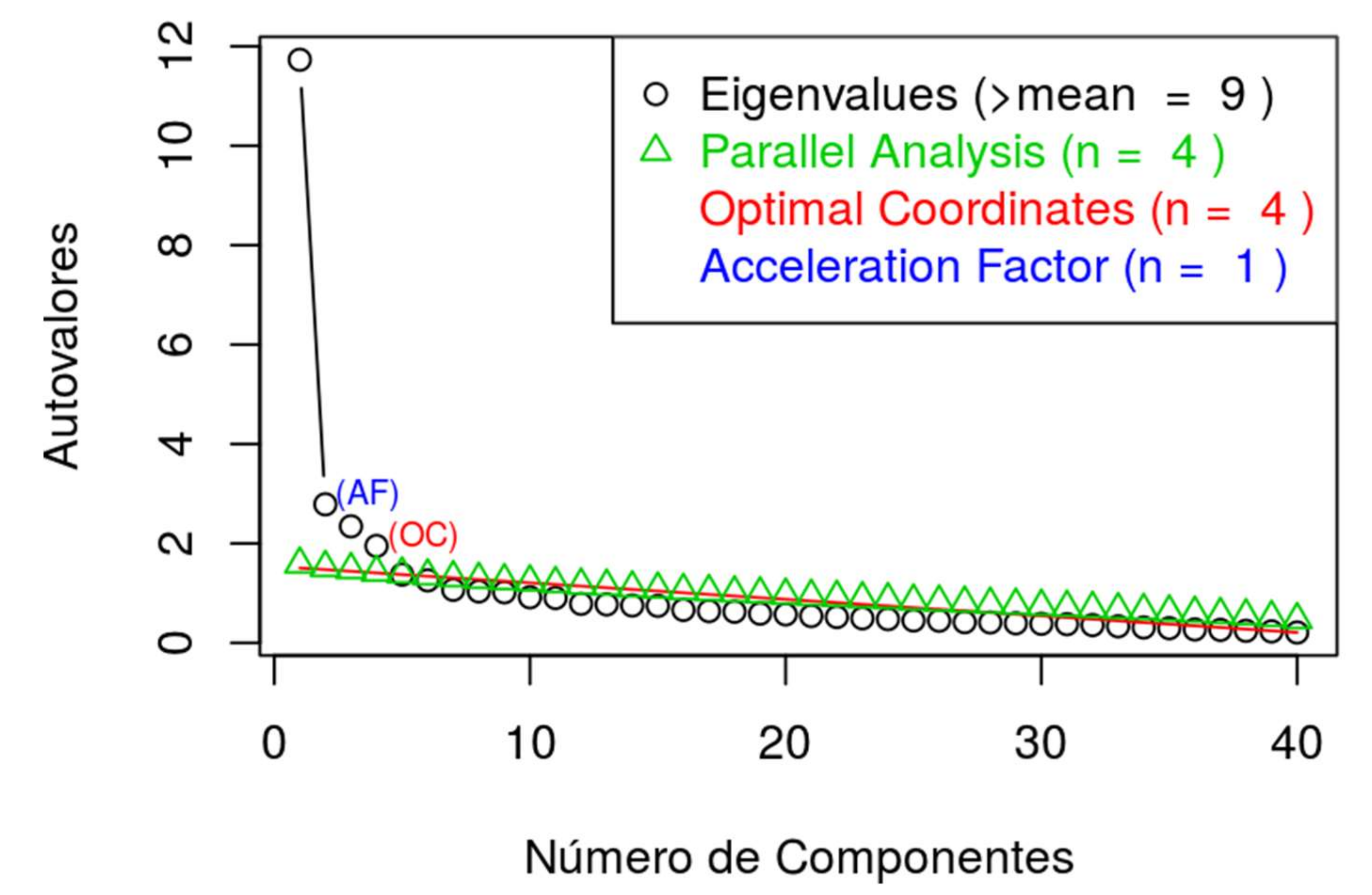
The overall EFA of the questionnaire demonstrates a distribution in five dimensions, explaining 43% of the total variance (
Figure 1).
Table 4 shows that Dimension 1 groups together the majority of the items of Sections 3 and 4 (satisfaction and learning of historical contents) and that the remaining items are distributed between the rest of the dimensions. These groupings explain 43% of the variance of the questionnaire.
In the following section, we shall perform a more in-depth examination with a confirmatory factor analysis of each section via structural equation modelling.
Section 1
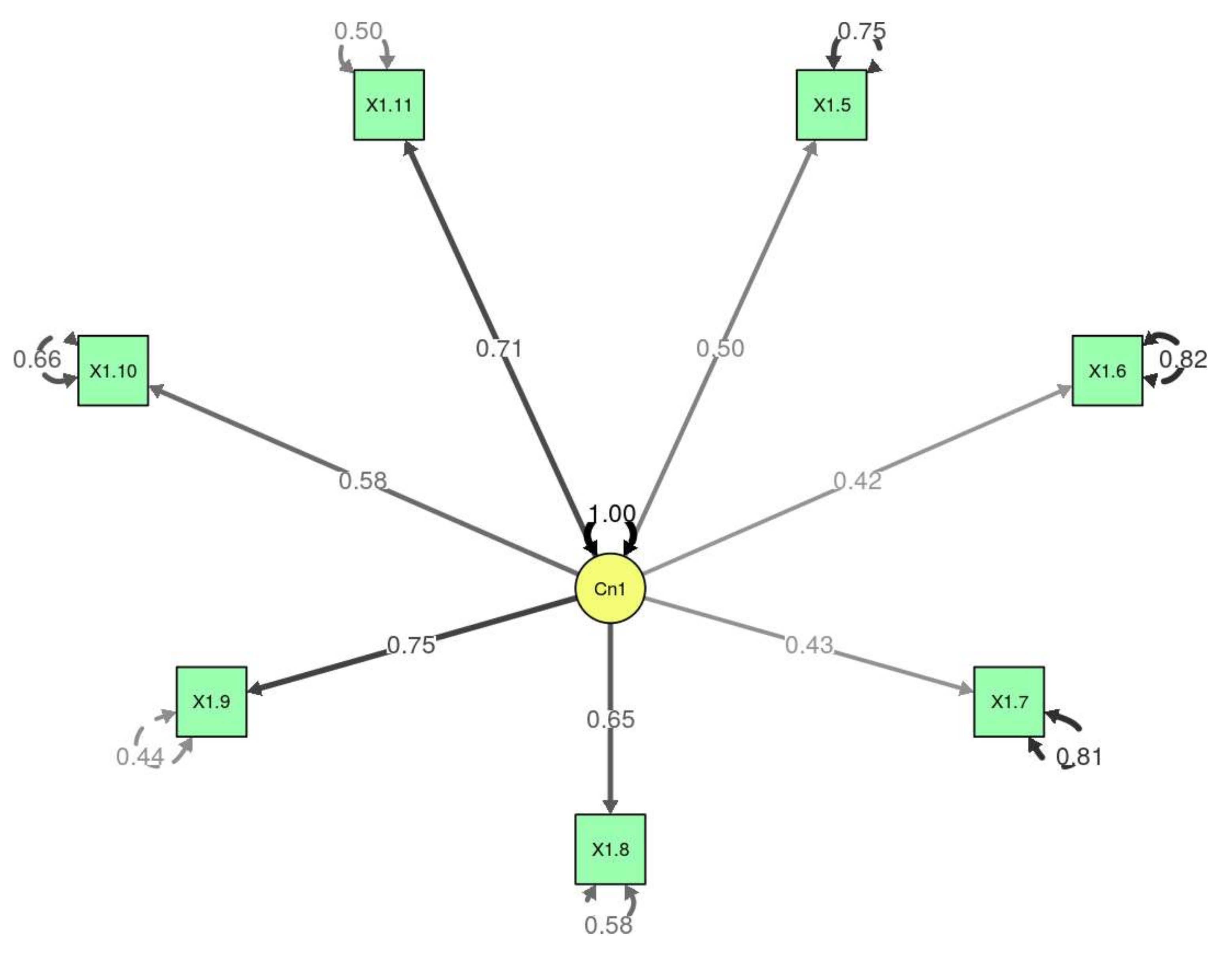
By applying the hypothesis contrast, it could be observed that the DWLS estimator had a statistic of 350.2525565 (robust estimation 386.6210834), with 65 degrees of freedom and a significant p-value (p < 0.05). All of the p-values were significant with the exceptions of items 1 and 4. Therefore, with the exception of these two items, all of the variables were different to zero. That is to say, to a greater or lesser degree, they contributed to the model.
The model with all of the items from the questionnaire did not fit correctly (TLI = 0.82; CFI =.85; RMSEA 1.01). Given that the model did not fit well with the data from Section 1, we proceeded to eliminate the variables which contributed least to the model, which was associated with the internal error of each variable. We eliminated the variables with an internal error greater than 0.85, leaving us with the variables from 1.5 to 1.11 (items relating to innovation methodology), and checked the model again. The model now fitted correctly (TLI = 0.95; CFI = 0.96; RMSEA = 0.08) (
Table 5).
Figure 2 shows the definition of the structural equation model, in which the two-way arrows represent the covariances between the latent variables (ellipses) and the one-way arrows symbolise the influence of each latent variable (constructs) on their respective observed variables (items). Lastly, the two-way arrows over the squares (items) show the error associated to each observed variable. The three variables which contribute most to the model are 1.9 (use of the internet), 1.11 (use of research in history classes) and 1.8 (use of audio-visual resources).
Section 2
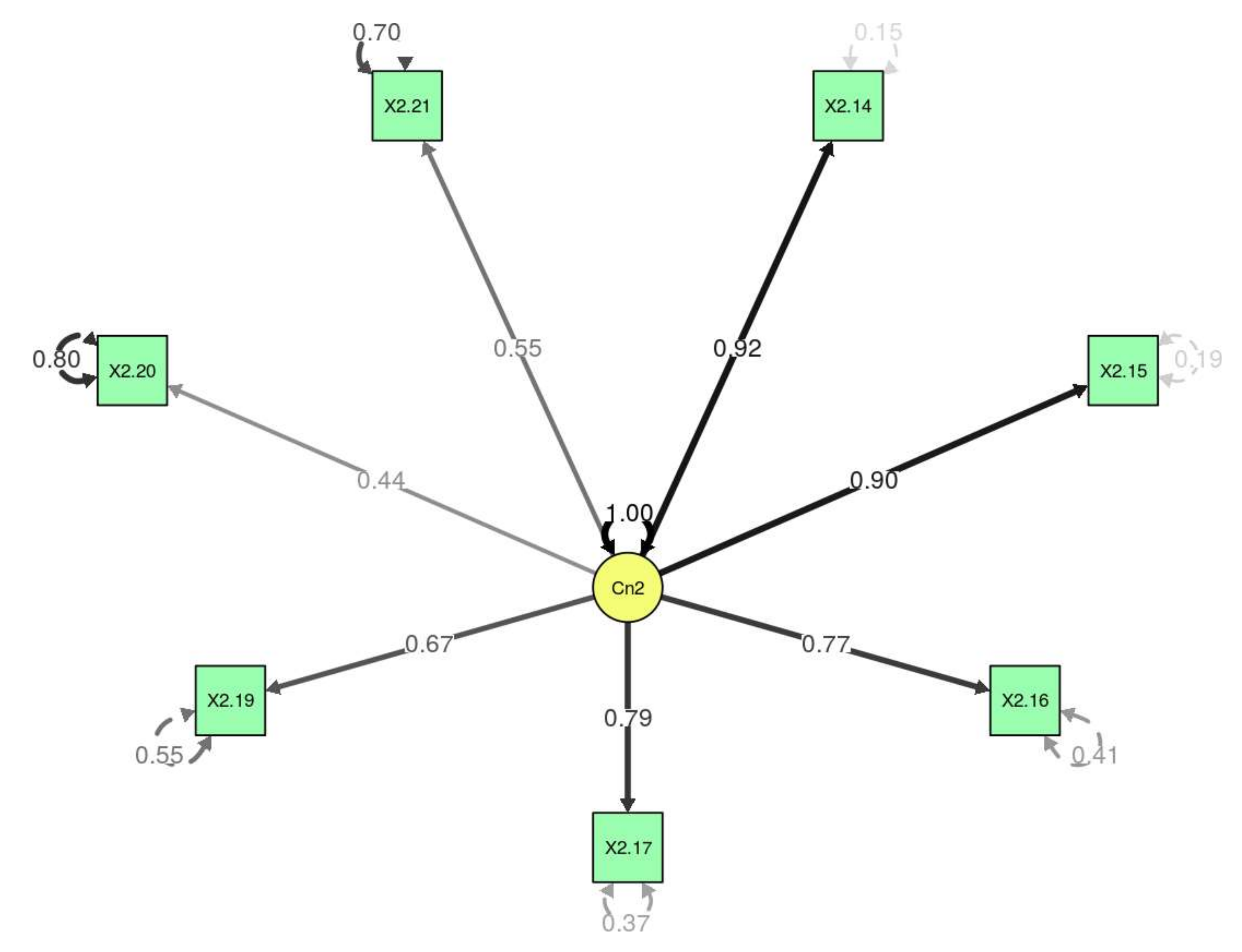
By applying the hypothesis contrast, it could be observed that the DWLS estimator had a statistic of 82.3929415 (robust estimation 136.8868406), with 20 degrees of freedom and a significant
p-value (
p < 0.05) (
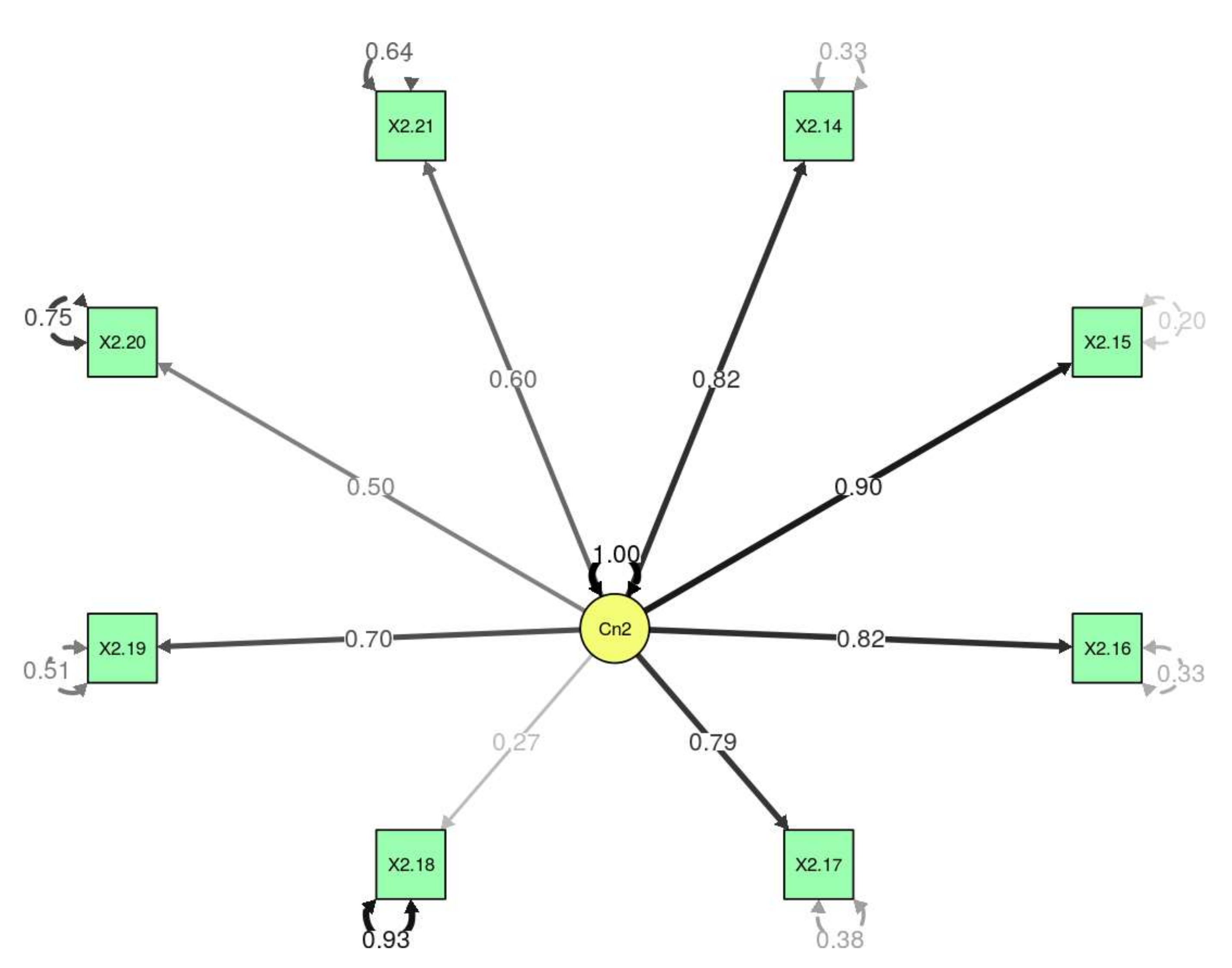
Figure 3). It can be seen that, except for item 2.18 (“History classes only motivate me to pass exams”), all of the
p-values were significant, and all of the variables were different to zero; to a greater or lesser extent they contributed to the model. When item 2.18 was eliminated, it was observed that the TLI and CFI were greater than 0.99 (
Table 6). Therefore, the model fit well. In this case, there was an RMSEA value of 0.0858781 and a non-significant
p-value, which meant that the model did indeed fit well with the data.
Section 3
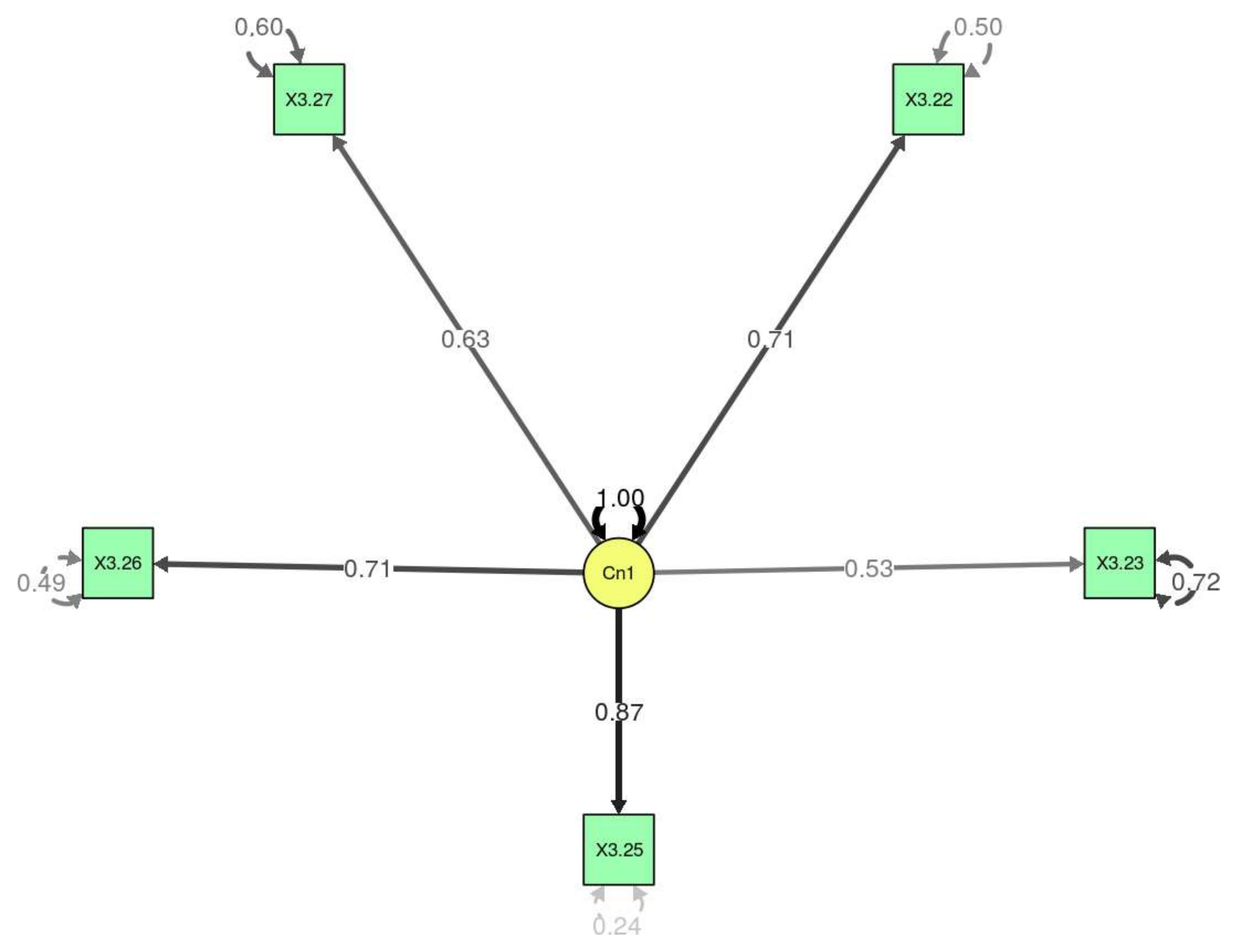
By applying the hypothesis contrast, it could be observed that the DWLS estimator had a statistic of 82.3929415 (robust estimation 136.8868406), with 20 degrees of freedom and a significant
p-value (
p < 0.05) (
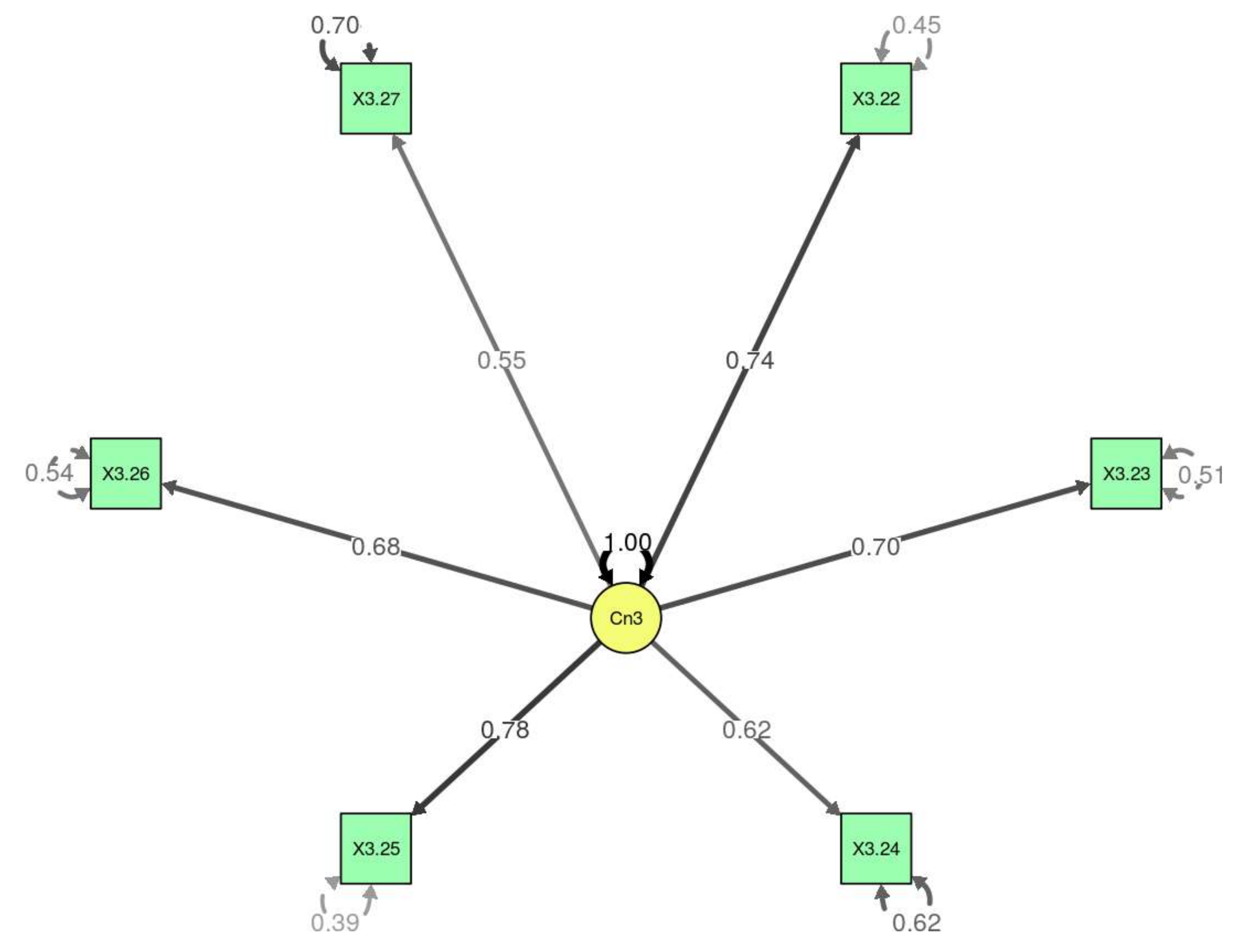
Figure 4). All of the
p-values were significant, and all of the variables were different to zero; to a greater or lesser extent they contributed to the model. The model with all of the items of the questionnaire did not fit well (TLI = 0.96; CFI = 0.98; RMSEA = 0.1). Given that the model did not fit the data of Section 3, we proceeded to eliminate variable 3.24 (“I am satisfied with the work of my classmates when we work in groups”), which is that which contributed least to the model. In this case, the model fit correctly (TLI = 0.99; CFI = 0.99; RMSEA = 0.05) (
Table 7).
Section 4
By applying the hypothesis contrast, it could be observed that the DWLS estimator had a statistic of 82.3929415 (robust estimation 136.8868406), with 20 degrees of freedom and a significant
p-value (
p < 0.05) (
Figure 5). All of the
p-values were significant and all of the variables were different to zero; to a greater or lesser extent they contributed to the model. It is clear that variables 4.28 and 4.29 (items relating to the knowledge of historical events and figures) are those which contributed most to the model, whereas 4.36 (“I learn to work in groups with my classmates”) contributed almost nothing. The model with all of the items of the questionnaire did not fit correctly (TLI = 0.97; CFI = 0.97; RMSEA = 0.11). Given that the model does not fit well with the data of Section 3, we proceeded to eliminate the variables which contributed least to the model (4.36 and 4.38). In this case, the model fitted better, although the RMSEA was questionable (TLI = 0.98; CFI = 0.98; RMSEA = 0.10) (
Table 8).
In conclusion, for Section 1, the SEM eliminated half of the questions, just as the exploratory factor analysis distributed the items of this section into different constructs. For Section 2, the SEM retained all of the items, although it indicated that 2.18 did not contribute to the model. For Section 3, the SEM retained all of the items, with the exception of 3.24, which did not contribute to the model, coinciding completely with the FA, which kept the items together and placed 3.24 in another dimension. Finally, for Section 4, the SEM was not able to fit the model. It indicated that 4.36 and 4.38 did not contribute to the model. Again, this coincided with the FA, which kept the items together and placed those questions in other dimensions, along with 4.39, which is the one which contributed least according to the SEM. In general, it could be observed that the results obtained here were in agreement with those obtained in the general FA, and proposed a division of Section 1, whereas the rest of the sections were better adjusted.
3.2.2. Post-test
In the analysis of the correlation matrix, there were no variables which did not correlate well or with a correlation coefficient greater than 0.9. Likewise, in the Bartlett sphericity analysis, we obtained a p-value of p < 0.05, indicating that the matrix was not similar to the identity matrix. In the FA carried out on Sections 1, 2, 3 and 4, all of the KMO coefficients were close to or above 0.7, with values of 0.68, 0.86, 0.77 and 0.91 respectively. This indicated that the application here of an FA was well considered and that Section 1 was the least stable.
When the EFA was applied to the whole questionnaire, we obtained a distribution in 4 dimensions, explaining 41% of the total variance, with a KMO of 0.92 (
Figure 6).
Table 9 shows that the first dimension groups together many of the items relating to traditional methodology (assessment via different techniques, use of the internet and audio-visual resources, critical work with sources, etc.), with the majority of the items from Sections 2, 3 and 4. The variance explained by a single factor per process is 16%, 43%, 37% and 37%, with Section 1, again, being the most heterogeneous.
In the following section, we shall look in more detail at the validation of the construct for each of the sections of the questionnaire.
Section 1
By applying the hypothesis contrast, it could be observed that the DWLS estimator had a statistic of 760.9003772 (robust estimation 693.4870295), with 65 degrees of freedom and a significant
p-value (
p < 0.05) (
Figure 7). In our case, variables 1.13, 1.12 and 1.6 were those which contributed most to the model.
The model with all of the items from Section 1 did not fit correctly (TLI = 0.57; CFI = 0.64; RMSEA = 0.16). Given that the model did not fit well with the data of Section 1, we proceeded to eliminate the variables which contributed least to the model. We eliminated the variables with an internal error greater than 0.80 and checked the model again. We eliminated 7 variables: 1.1, 1.2, 1.3, 1.8, 1.9, 1.10 and 1.11. In this way, it was possible to achieve a better fit of the model (
Table 10), although the RMSEA was questionable (TLI = 0.92, CFI = 0.95; RMSEA = 0.1). In this model, the items relating to innovative methodology had a negative load (1.5, 1.6, 1.7, 1.12 and 1.13), whereas item 1.4 (“In order to pass, I learn the contents by rote”) had a positive load.
Section 2
By applying the hypothesis contrast, it could be observed that the DWLS estimator had a statistic of 96.2166894 (robust estimation 161.1879894), with 20 degrees of freedom and a significant
p-value (
p < 0.05) (
Figure 8). With the exception of item 2.18, all of the p-values were significant, and all of the variables were different to zero and, to a greater or lesser extent, contributed to the model. It could be seen that variables 2.14, 2.15 and 2.16 (“The classes motivate me to learn history, to make an effort and to understand social reality”) were those which contributed most to the model, whereas item 2.18 (“History classes only motivate me to pass the exams”) contributed nothing. The model with all of the items of the section fit correctly (TLI = 0.98; CFI = 0.98; RMSEA = 0.09) (
Table 11).
Section 3
By applying the hypothesis contrast, it could be observed that the DWLS estimator had a statistic of 96.2166894 (robust estimation 161.1879894), with 20 degrees of freedom and a significant
p-value (
p < 0.05) (
Figure 9). All of the
p-values were significant, all of the variables were different to zero and, to a greater or lesser extent, they contributed to the model. Variables 3.22, 3.23 and 3.25 (“I am satisfied with my role in the classroom and with the working atmosphere in the classroom”) were those which contributed most to the model. The model with all of the items from Section 3 fit correctly, albeit with a questionable RMSEA (TLI = 0.96; CFI = 0.97; RMSEA = 1) (
Table 12).
Section 4
By applying the hypothesis contrast, it could be observed that the DWLS estimator had a statistic of 96.2166894 (robust estimation 161.1879894), with 20 degrees of freedom and a significant
p-value (
p < 0.05) (
Figure 10). All of the
p-values were significant, all of the variables re different to zero and, to a greater or lesser extent, they contributed to the model. Variables 4.28, 4.32 and 4.40 (“I have learnt about the main historical events, changes and continuities and to debate issues relating to current affairs”) were those which contributed most to the model, whereas item 4.36 (“I have learnt to carry out group work”) hardly contributed anything. When item 4.36 was eliminated, the model fit correctly (TLI = 0.97; CFI = 0.98; RMSEA = 0.08) (
Table 13).
In conclusion, for Section 1, the SEM eliminated half of the questions, leaving 6 of the initial 13, just as the factor analysis distributed the items from this section into different constructs. For Section 2, the SEM retained all of the items, although it indicated that 2.18 did not contribute to the model. The FA kept the items together, although it moved 2.18 to one dimension and 2.20 to another, with the latter being the second least-explained item in the SEM. For Section 3, the SEM retained all of the items, coinciding completely with the FA, which kept all of the items together, with the exception of 3.24, which contributed little to the SEM model and was placed in another dimension. Finally, for Section 4, the SEM retained all of the items, with the exception of 4.36. Again, it coincided with the FA in this aspect, although the FA also removed 4.37 and 4.38. In general, it can be observed that the results obtained here were in agreement with those obtained in the general FA and proposed a division of Section 1.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}