1. Introduction
Healthy soils are substrates for the habitats of innumerable living organisms. Besides supplying basic resources for survival (food, water, nutrients, and raw materials), soils provide several ecosystem services. Soil erosion and soil loss affect soil health by substantially modifying soil structure and hence causing significant damage to natural habitats and biodiversity [
1]. Human activities promote soil loss at various levels. For example, urbanization has a potential to disturb soil in large areas, which may cause substantial erosion if the principles of sustainable land use and land cover management are not applied [
2]. Exploring scenarios of land management requires having the capacity to estimate and forecast soil loss under those scenarios. Soil loss (under any land management scenario) occurs by weathering of soil during or after rain events. Run-off transports the eroded soil to nearby streams increasing the amount of soil in the water column (suspended sediment concentration). Total suspended sediment (SST) concentrations in the streams that transport the eroded soil, reflect how a particular land management scenario affects soil loss [
3]. Therefore, estimating and forecasting SST concentrations in a stream constitutes a valuable asset for sustainable land management.
Estimation of SST concentrations in streams is performed through the use of water quality models. The development of in-stream water quality models is a time-consuming and costly process [
4,
5]. The modeling task is usually initiated with the quantification of hydrological and hydraulic processes. This entails the development of hydrological models (to account for non-point sources of water) and hydrodynamic models (to account for in-stream movement of water). Once the water volumes entering the stream are quantified and the movement of water within the stream is characterized, the water quality constituents from non-point sources are calculated, and in-stream concentrations of pollutants are computed. This latter process requires the linking of hydrologic and hydrodynamic models to water quality models [
6,
7]. There are modeling tools that perform joint estimations of hydrologic, hydrodynamic, and water quality processes, but the modeling sequence does not change, and the required investment of time and resources is also substantial.
Furthermore, traditional approaches to water resources management and modeling rely on historical time-series. Climate change introduces additional uncertainty to forecasting methods based on historical data [
8]. Non-traditional approaches (deep learning and fuzzy sets) have been successfully applied to capture complexities introduced by climate change effects [
9,
10]. In Chile’s central region, where water scarcity is a prevalent problem, climate change and its effects have become an important challenge for cities with water management problems [
11].
Moreover, streamflow, sediment, and pollutant transport, are hydrological processes that strongly depend on precipitation, temperature, topography, land cover, and soil texture antecedent conditions. The state of those variables in days previous to an event will determine the hydrological response in streamflow regime, and sediment and pollutant concentrations. Seasonality is also a factor. Most hydrological variables vary drastically during the year, with trends particular to dry or wet seasons [
3]. In particular, total suspended sediment (SST) in water bodies is strongly dependent on seasonal meteorology [
12]. As such, SST concentrations are indicators of several hydrological processes taking place within a watershed. The presence of SST depends on intensity and duration of rainfall events, soil matrix, and land surface characteristics (slopes, land use, land cover, stream flow, etc.) [
3], and antecedent conditions of those hydrological variables. For this reason, the estimation or forecasting of SST concentrations and loads in rivers, is key for implementing sustainable land and water management measures.
Suspended sediment transport and sediment loads in rivers and streams have become primary concerns in Chile. Excessive soil and sediment wash-off from the mountains to rivers and streams have produced infrastructure malfunction with costly social and economic consequences. For example, in Valparaiso (the second-largest metropolitan area in Chile and one of the main seaports in the country) the topography of the city is dominated by several hills that surround the urban center and port. Several creeks drain waters from the surrounding watersheds to the city and seacoast through stormwater sewers. These watersheds are being gradually urbanized, and, with those settlements, the pervious nature of the soil has been modified producing high sediment loads that overload the storm water system of the city [
12]. Sediment transport and deposition have been a recurring problem for the existing storm water system and costly infrastructure has been built to remediate the situation [
12]. Similarly, excessive sediment and soil wash-off have also produced problems in other important Chilean cities. The Maipo River, located in central Chile, is the main source of drinking and irrigation water for the City of Santiago (Chile’s capital city). However, excessive soil erosion has generated high-turbidity events with incremental frequency and severity, leading to frequent shutdowns of drinking water treatment plants [
6]. Social and economic consequences have been substantial. In 2013, nearly 5 million people did not have access to safe drinking water during several days [
13]. Economic activities depending on regular access to drinking water also suffered consequences. These examples show the need for effective forecasting methods that would help prevent those consequences. Nevertheless, the necessity for suspended sediment loads and concentration-forecasting capabilities is more urgent in Valparaiso, since its rapid urban growth will only exacerbate the current excessive sediment loading events cited above.
Artificial neural networks (ANN) have been recently explored as a potential tool for estimating sediment processes in streams and rivers. Rajaee and Jafari [
14] and Afan et al. [
15,
16] applied ANN models to simulate river sediment processes. Their results were somewhat limited in prediction accuracy or time extent of the forecast. In a recent research, Ghose and Samantaray [
17] focused on the prediction of sediment concentrations using regression and back-propagation neural network models, using daily discharge, temperature, and sediment concentration as input data. Their results showed promise although the forecasted sediment loads were not in the form of time-series. Similarly, Alp and Cigizoglu [
18] simulated sediment-load hydrographs using two ANN methods and compared them with a multi-linear regression method. However, only a few hours (not months or years) were simulated.
This research presents a non-linear autoregressive neural network (with exogenous inputs) developed for forecasting sediment concentrations at the exit of Francia Creek watershed (Valparaiso, Chile). The neural network was built following Wu et al. [
19] methodology for neural network development and assessment. Details are presented on input data selection, data splitting, selection of model architecture, determination of model structure, model calibration/training (optimization of model parameters), and model validation. Also, the developed ANN is assessed to determine if it can be used for forecasting daily suspended sediments for a complete year.
2. Materials and Methods
2.1. Study Area
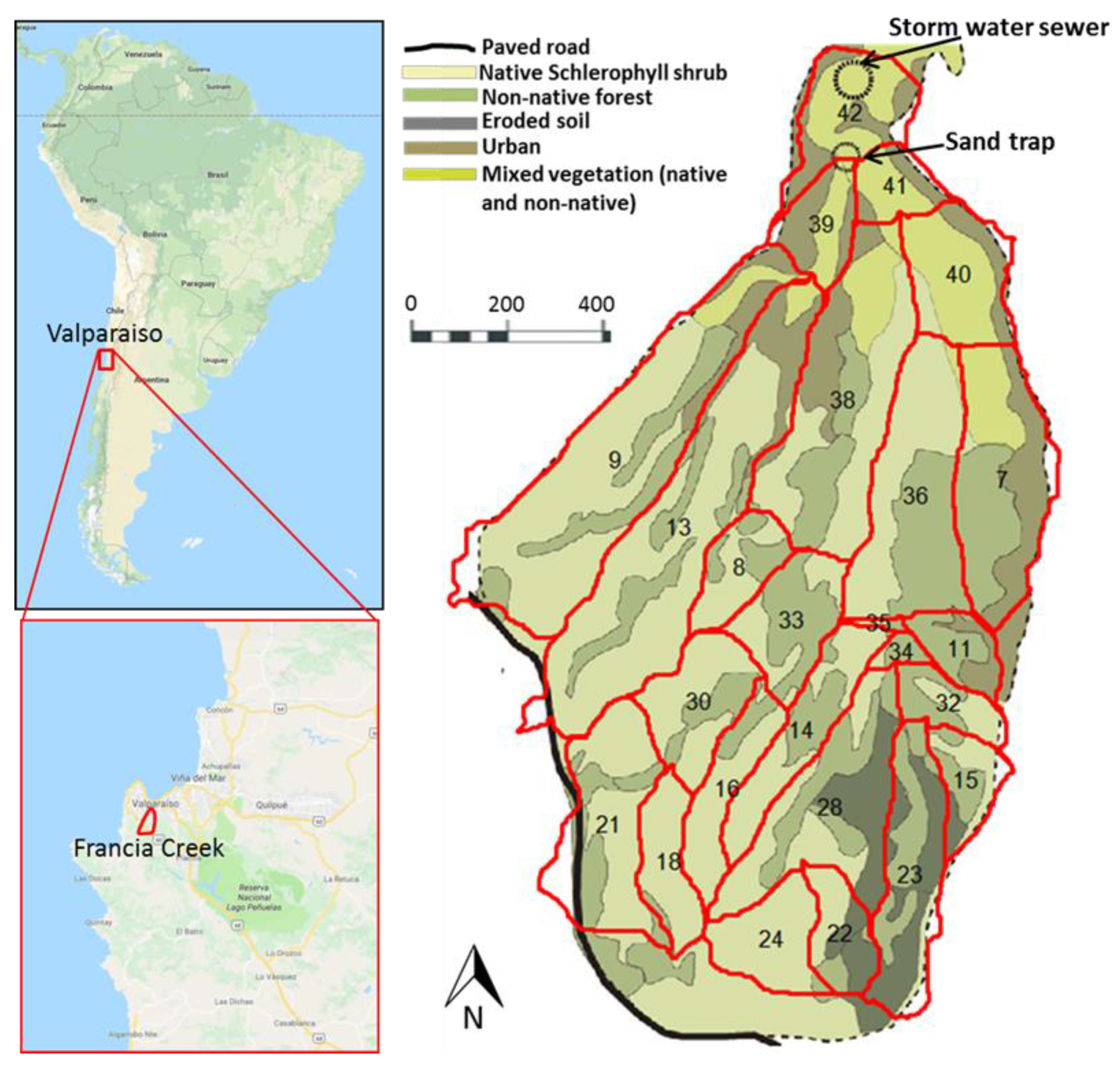
The city of Valparaiso is located in the central region of Chile. Its topography is dominated by 39 creeks (that drain waters from 44 hills that surround the city). The creeks were formed by natural terrain abrasion resulting from precipitation events. The region is characterized by dry weather, with few but intense precipitation events occurring mainly in the winter season (June–August). Baseflow erosion of the silty-clay soil, and oxidation of the granite rock that supports the soil layers also contribute to sediment concentrations and loading in the streams. The waters drained by the creeks feed the storm water pipes of the city system where sediment deposition has been a recurring problem requiring costly infrastructure implementation to remediate the situation [
12]. One of the creeks that has been identified as critical is Francia Creek (
Figure 1).
Francia Creek (
Figure 1) watershed covers approximately 3.24 km
2 [
12]. Land cover within the catchment consist mainly of native and exotic vegetation, eroded soil, and urban areas. Soils in the Francia Creek catchment consist of weathered sedimentary rock (sand, clay, and silt) with a thin organic top layer [
20]. The instability of these materials makes the watershed side slopes susceptible to mass removal processes, mainly because the sedimentary rock expands and mobilizes when rainfall increases [
21]. Hillslopes are steeper than 40% and they are prone to erodible processes and mudslides during the rainy season. Water flow in the creek can be strong enough to suspend particles in the water column and transport them downstream. To avoid the sediment entering the stormwater sewer network, a sand trap was built at the lowest point of the catchment area (
Figure 2). The sand trap accumulates up to 1500 m
3 of sediment annually. The accumulated sediment is cleaned up once a year and disposed in a sanitary landfill.
Figure 2A shows the upstream side of the sand trap soon after it was cleaned up of debris.
Figure 2B shows the sand trap almost full of debris and sediments after a series of strong precipitation events.
Since the erodible processes that have characterized Francia Creek watershed will continue to occur in the future (due to urban growth and other human activities) quantifying the risk associated with high sediment loading events would allow the development of early-warning systems that minimize damage. The initial step in the development of a warning system is building effective forecasting tools.
Alarcon and Magrini [
12] performed measurements and daily estimations of precipitation, flow, and total suspended sediment concentrations (SST) for Francia Creek watershed at the upstream section of the sand trap (
Figure 3). The figure shows that SST concentrations follow a seasonal pattern—concentration peaks occur during the rainy season (June to August). SST concentration peaks fluctuate within 1500 to 6660 mg/L and take place after or during daily precipitation events. Rainfall events accumulating 50 mm to 127 mm produce peak streamflow ranging from 8 m
3/s to 23 m
3/s. It should be noted that those peaks are preceded by lower intensity precipitation events in days previous to the peak events.
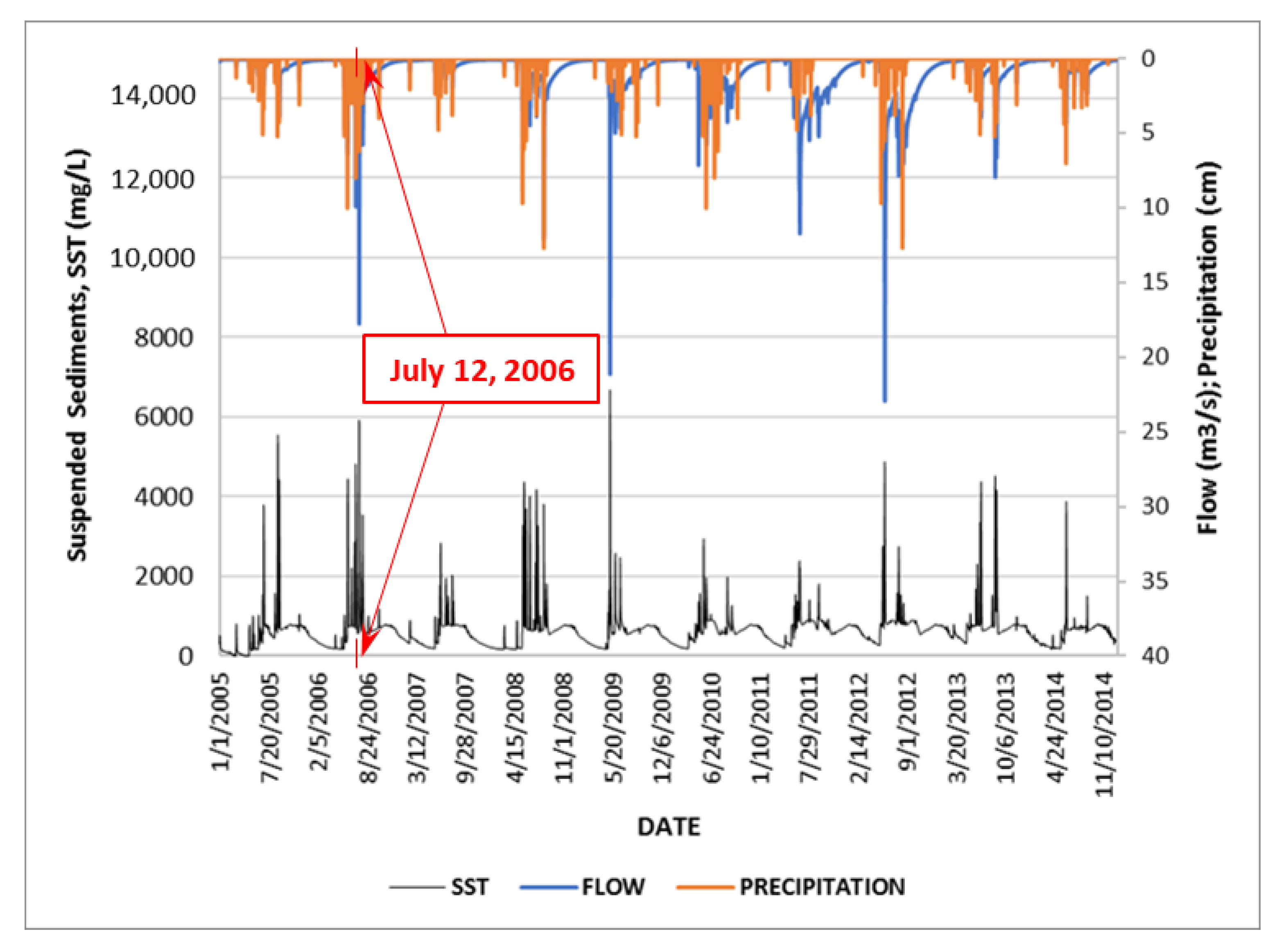
Figure 3 also shows measured and estimated SST concentrations corresponding to days when there was absence of rainfall and Francia Creek only carries baseflow (water seeping into the stream from the vadose zone even in the absence of rain). Concentrations ranging between 200 mg/L to 350 mg/L correspond to baseflows ranging between 3 L/s to 5 L/s. Baseflow is continuous throughout the year.
Figure 4 illustrates the dependence of SST concentrations on antecedent conditions of precipitation and flow and follows a discussion on a mudflow event that took place at Francia Creek watershed, on 12 July 2006. SST, flow, and precipitation data for dates 4 July 2006 to 26 July 2006 are shown. On 10 July 2006, a strong precipitation event (200 mm) generated flows of up to 9.93 m
3/s and SST concentrations of 4770 mg/L. The day after (11 July 2006), the rain continued to fall accumulating 53 mm of precipitation at the end of the day, generating flows of up to 9.90 m
3/s and SST concentrations of up to 4320 mg/L. On 12 July 2006, it did not rain, but mudflow (generated in Francia Creek watershed) produced injuries to five people and damaged several cars in areas close to the watershed exit. In total, twenty people had to be evacuated. Two weeks later (24 July 2006), a precipitation event of almost 160 mm, that produced flows of up to 18 m3/s and SST concentrations of 5920 mg/L, did not produce consequences. The difference in this latter event was that precipitation intensity in days before and after the event was much milder than the recorded peak precipitation of 160 mm. Therefore, the antecedent conditions (rainfall and soil status) in days previous to the peak precipitation event, as well as rainfall and flow occurring in the following day, strongly influenced the generation of the mudflow incident.
The analysis above illustrates the challenges for predicting or forecasting time-series of SST concentrations and loadings. The strategies and methodologies for forecasting SST events should be able to account for antecedent precipitation, flow, and SST concentrations before the occurrence of a peak SST loading or concentration event.
2.2. Forecasting or Predicting SST Time-Series
Estimating or predicting SST time-series in rivers, lakes, or estuaries is usually performed through hydrological and water quality modeling. Nevertheless, there are other quantitative approaches developed and oriented towards specific objectives. Event-based models use simpler formulations for rainfall-runoff generation [
22] but are usually developed for short-term purposes such as flood/flow forecasting and/or infrastructure designing. Other approaches that do not require information regarding the physical process (such as non-parametric algorithms) constitute an alternate method. Continuous non-parametric hydrological models were shown to be particularly useful for long-term water resources management (e.g., estimation of design flows, land-use change impacts, and effects of climate change). Non-parametric models such as antecedent precipitation indices, regression, artificial neural networks, fuzzy logic, and frequency analysis were used extensively [
22].
The artificial neural network (ANN) approach to time-series prediction is a non-parametric method. For simple non-linear functions of one or several independent variables ANN are universal interpolators, but simple ANN configurations have limitations in modeling seasonal patterns. Special configurations of ANN have been used with success to predict flows and sediment concentrations for rivers around the world [
15]. The most commonly used models are artificial neural networks with dynamic architecture (DANN), autoregressive neural networks (ARNN), non-linear autoregressive exogeneous neural networks (NARX), or hybrid configurations that combine ANN with other modeling approaches. Examples of those ANN configurations that reported good predictions of streamflow under flood and drought conditions are found in [
23,
24,
25,
26]. Similarly, ARNN and DANN were used extensively for estimating sediment concentrations (e.g., [
27,
28,
29,
30]). However, in most of those ANN applications the validation period of the model output corresponded to within-year or seasonal events because the input data was partitioned to capture the seasonality dependence of the input time-series. Also, some of those research projects scaled the input data for improving predictions. There are no ANN model applications that simulate continuous daily SST estimations for a whole year, using raw (not scaled) input data. Due to the strong non-linear SST response to precipitation and flow, non-linear autoregressive architectures with exogenous inputs (NARX ANN) seem to be the most appropriate for predicting SST concentrations if continuous daily estimations are desired, provided that exogenous data are used to capture antecedent hydrological conditions.
2.3. Selection of Model Architecture
The NARX network is a dynamical neural architecture commonly used for nonlinear dynamical systems. When applied to time-series prediction, the NARX network is designed as a feedforward time-delayed neural network (TDNN). NARX neural networks are recurrent dynamic networks, provided with feedback connections which enclose at least two layers of the network, and can use past values of predicted or true (measured) time-series [
31]. In this research, a NARX configuration, is proposed, in which past values of the SST time-series, past values of the driving time-series (precipitation and flow), and current precipitation and flow time-series (exogeneous input) are used to perform the SST concentration forecast.
2.4. Determination of Model Structure
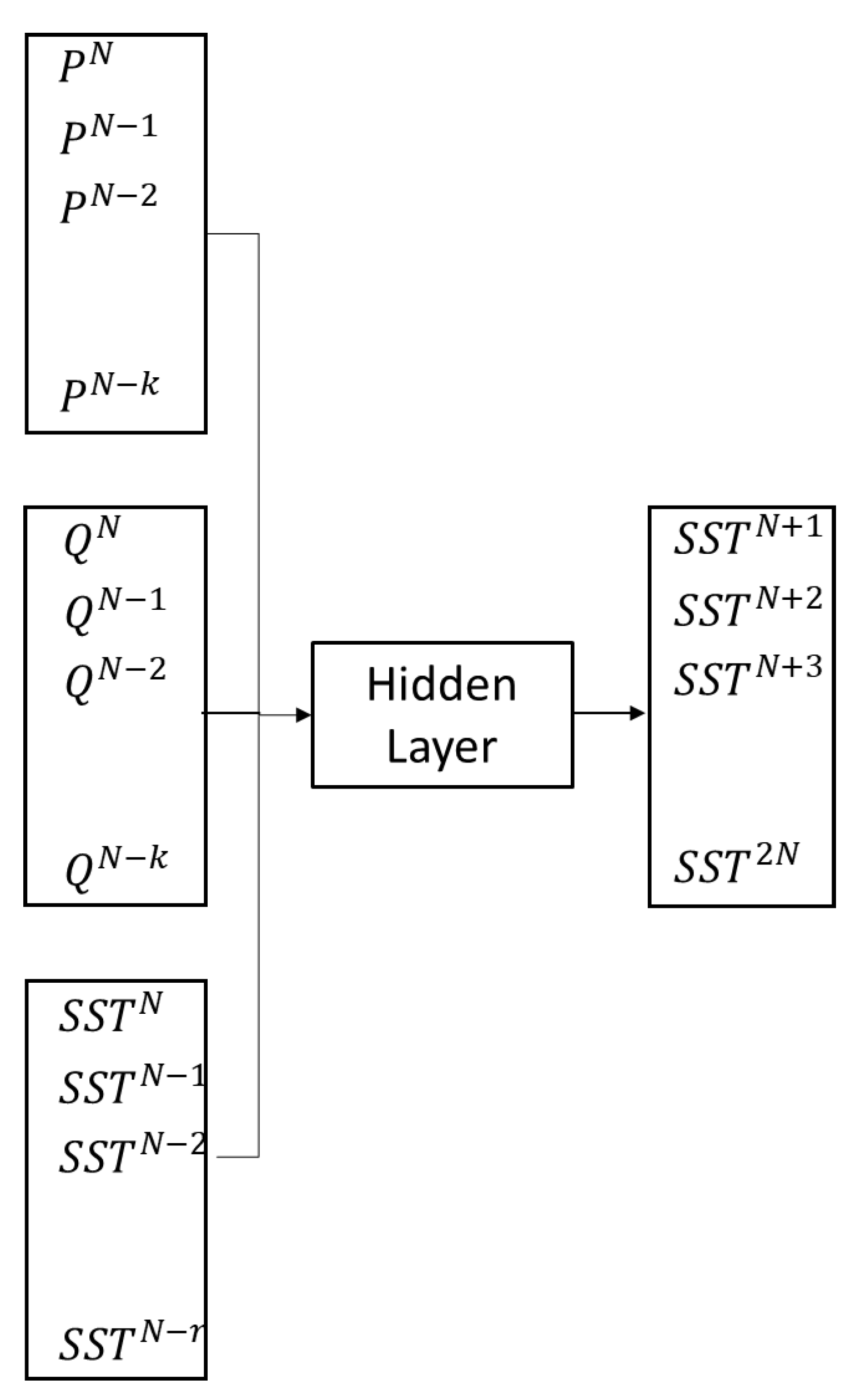
To forecast a total suspended sediments time-series of size
N (
) using a NARX net, based on three time-series that contain past precipitation (
P), flow (
Q), and total suspended sediments (
SST) data (
), there are important ANN specifications that have to be predetermined. There are two types of NARX architectures—closed-loop NARX architecture in which prediction of total suspended sediments is done from the present and past measured values of precipitation and stream flow, and the past predicted values of total suspended sediments and open-loop architecture, in which the future value of total suspended sediments,
, is predicted from the observed present and past values of precipitation (
), and stream flow (
), and the observed past values of total suspended sediments (
). In this research, an open-loop NARX net was used. In the above equations,
k and
r are the input and feedback delays, respectively, and represent the number of time-series data that are used (from each input time-series data) to perform the forecast with the calibrated open network.
Figure 5 presents a conceptual description of the NARX net used in this research.
The reason for using an open network is to avoid uncertainty propagation. In other fields of research where data uncertainty in the observed data is low, an open loop NARX is used to train the network, and then a closed-loop architecture (in which the network generates a forecast using the predicted data as the feedback input) is used for forecasting [
32]. However, since observed SST time-series data are usually measured indirectly via turbidity samplers that allow estimation of SST concentrations, they have an important (but acceptable) degree of uncertainty [
33]. Forecasting SST concentration values using NARX-forecasted SST concentrations (as it is done in closed NARX nets) may result in unnecessary propagation of the inherent uncertainty of observed SST data.
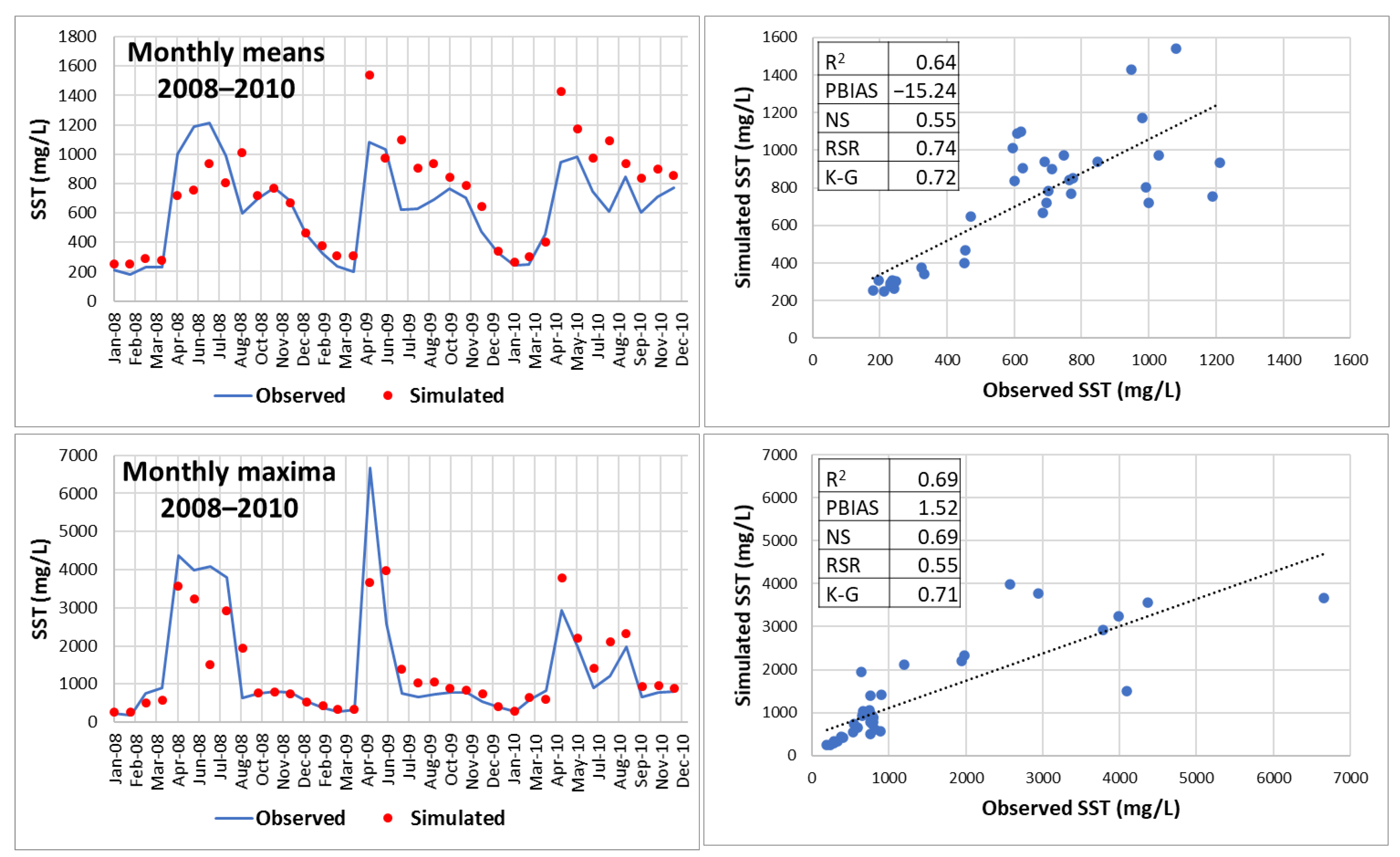
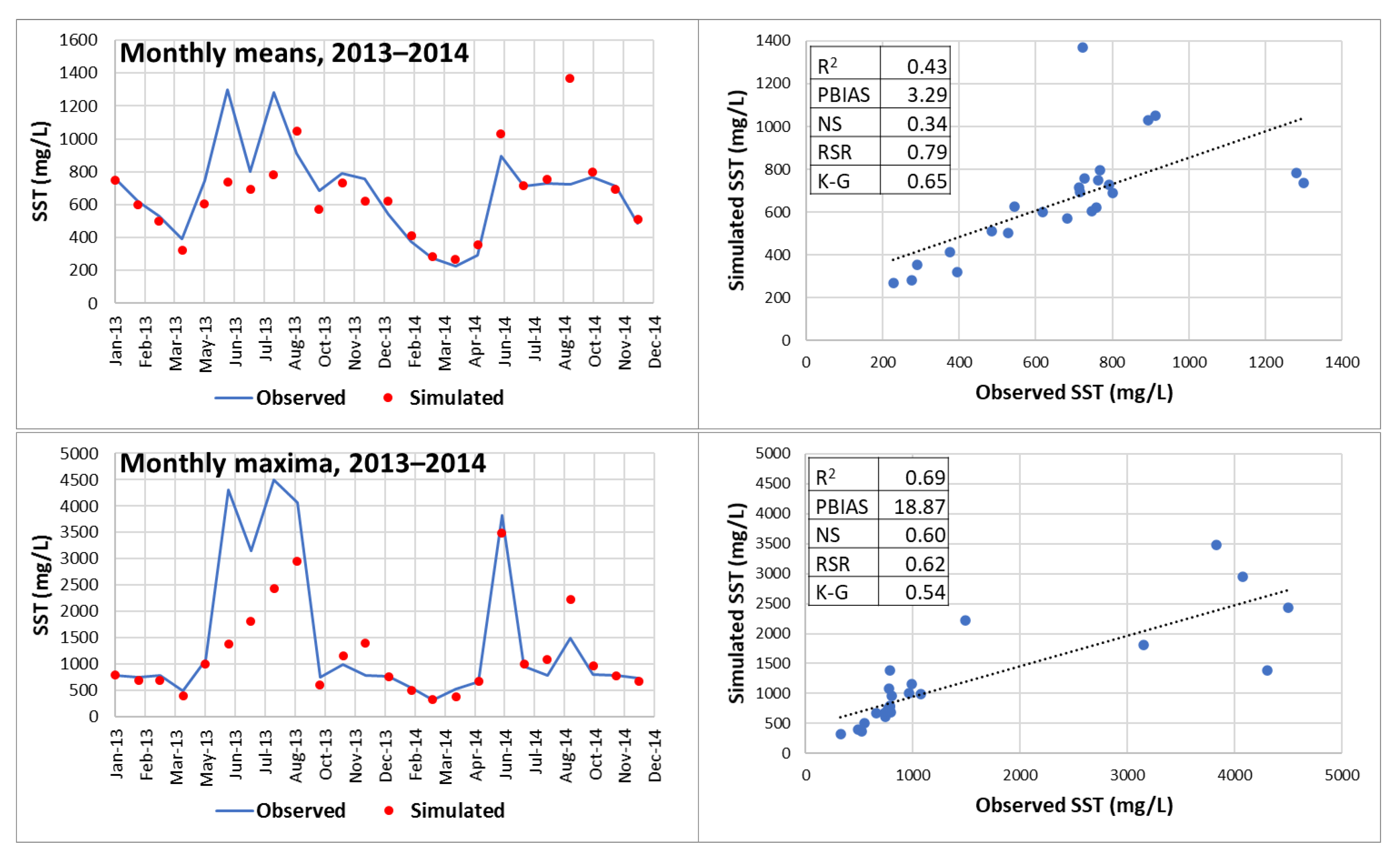
In this research, forecasting of SST concentrations was performed without scaling the input data. Efforts were put on forecasting daily SST concentrations for extended periods of time (N > 365). However, forecasting of monthly mean and monthly maximum concentrations was also performed using the developed NARX network. All computations were performed using MATLAB.
The
narxnet MATLAB function, with input and feedback delays, open feedback mode, and Bayesian regularization training algorithm (
trainbr), was used. Bayesian regularization is a mathematical method that converts a nonlinear regression into a “well-posed” statistical problem by minimizing a linear combination of squared errors and weights [
34]. The resulting ANN is neither overtrained nor overfit, with a reduced number of effective network parameters or weights, considerably smaller than the number of weights in a standard fully connected back-propagation neural net [
34].
2.5. Input Data Selection and Data Splitting
In order to explore the effect of training data size to achieve a successful prediction of SST, the number of years for training and prediction was varied.
Table 1 details the process.
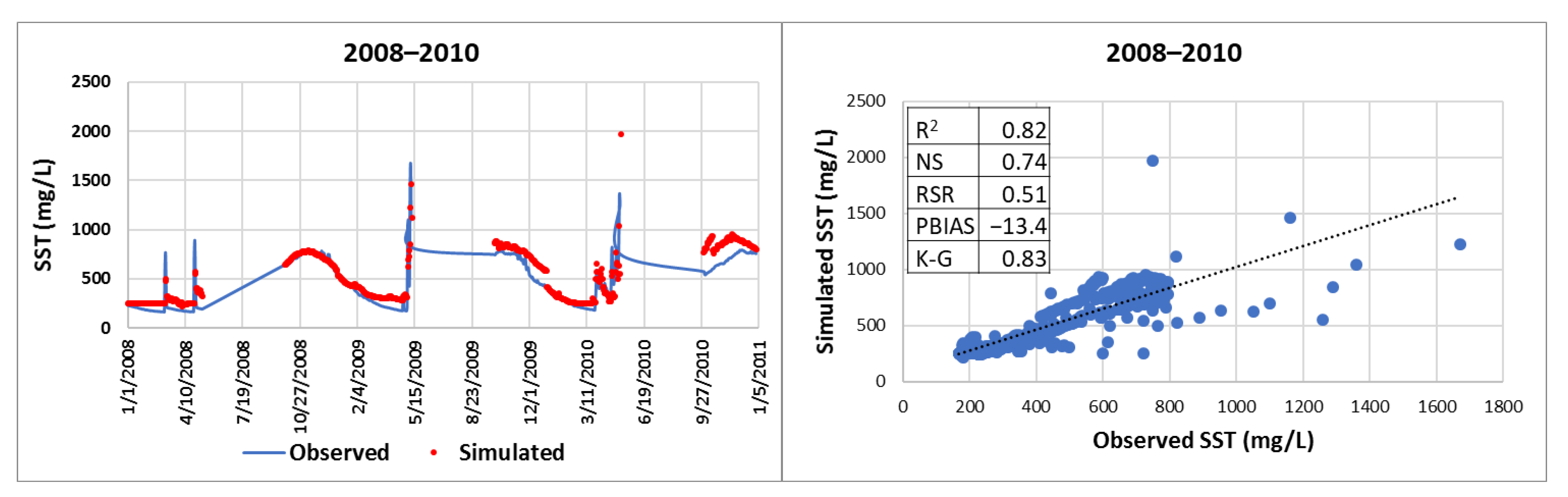
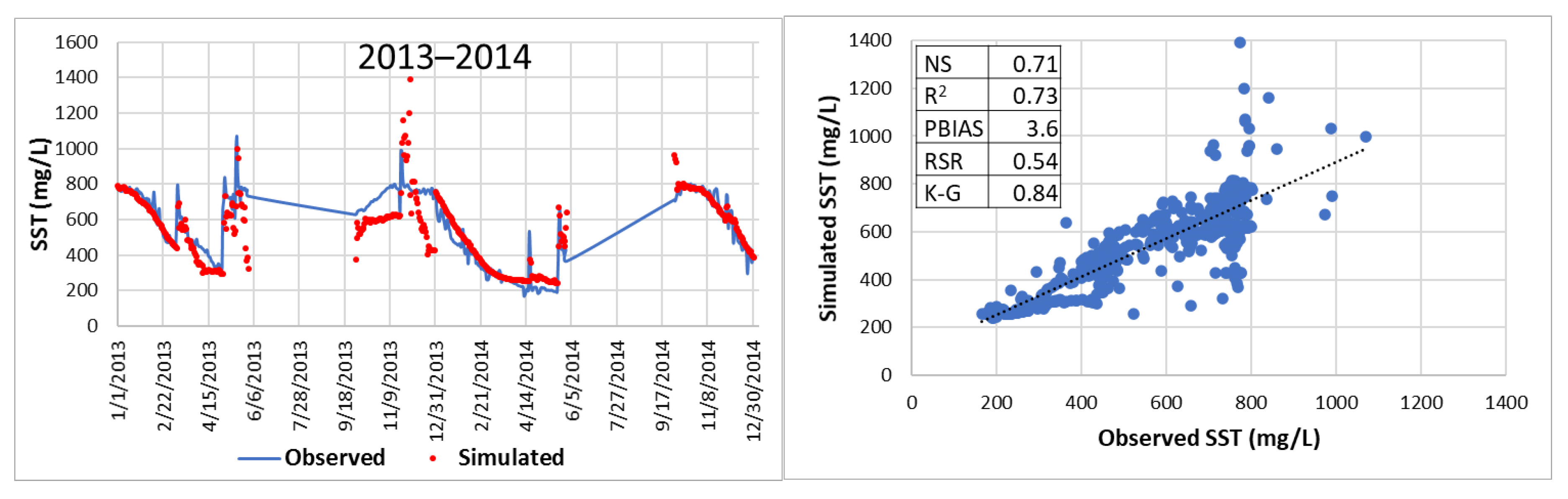
Initially, precipitation (), flow data (), and total suspended sediment concentrations () data from years 2005 to 2012 were used for training the NARX net. Several combinations of yearly datasets were tested until optimal statistical indicators of fit between simulated and observed daily SST concentrations data were achieved. The final training data set (, , and ) corresponded to years 2011 and 2012 with respective input delay, k, and feedback delay, r, which are discussed in subsequent sections of this paper. For the prediction phase, data from years 2011 through 2012 were used to predict total suspended sediments, , for years 2013 and 2014. To account for antecedent conditions of precipitation and flow, and , data (corresponding to the forecasted years) was used as exogenous input.
2.6. Model Calibration and Validation
After adopting the type of neural network (NARX) and developing a strategy for data-splitting, the ANN network was calibrated with several values and combinations of number of neurons in hidden layer, number of hidden layer nodes, and number of iterations. Other NARX net parameters were also varied in the training process. Input and feedback delays partitioned the input time-series data into subsets, during the computation of the forecasted SST time-series. Physically they represented the set of past precipitation, flow, and SST data values that determined the forecasted SST concentration. In MATLAB, input delays could range from 0 to N, while the range of feedback delays is 1 to N. By exploring the behavior of the observed data through time, initial numerical values of input and feedback delays were determined. From the initial estimation of the delay values, a heuristic approach was followed until obtaining a calibrated NARX net. In this research, input delays were varied from 1:15 to 1:60 and feedback delays from 1:2 to 1:6 (MATLAB notation for these parameters is used).
During NARX training, the general practice is to divide the data into three subsets—a training set (used for computing the gradient and updating the network weights and biases), a validation set (for comparing NARX generated output to the validation set), and a test set (that provides an additional check on que quality of the NARX output) [
35]. Nevertheless, since in this research an actual validation of the NARX model was performed with observed SST time-series data that were independent from the time-series used during training, the preliminary validation that MATLAB performs was used only as an indicator of the ANN training quality. In this context, training set ratios were varied from 1/60 to 1/95, validation set ratios from 1/5 to 1/40, and test ratios from 1/5 to 1/20 (MATLAB notation for these parameters is used).
Statistical indicators of fit between forecasted and observed data and corresponding statistical errors were computed to quantify the quality of simulated data. The following indicators were used for assessing statistical fit: coefficient of determination (R
2); Nash–Sutcliffe coefficient (NS), Kling-Gupta efficiency index (K-G), and Willmott’s index of agreement (d). The root-mean-squared-error to standard deviation ratio (RSR) was calculated to quantify statistical errors, and percent bias (PBIAS) was computed to determine the bias of simulated data with respect to observed data [
25].
Table 2 summarizes the statistical indicators used.
Model validation was performed at daily and monthly levels. The hindcasting and forecasting capabilities of the NARX net was assessed. The acceptable ranges or threshold values of the statistical indicators were defined after thorough review of the literature.
Moriasi et al. [
36] states that if the statistical fit indicators (for monthly SST simulations) are within the following ranges, the simulation is satisfactory: RSR < 0.70, −30% < percent bias (PBIAS) < 55%, R
2 > 0.5, and NS > 0.50. However, the statistical indicators’ ranges need to be modified appropriately for shorter simulation time-steps. It is recommended to extend the acceptability ranges corresponding to monthly simulations by 20% to apply them to daily simulations. [
36]. Nevertheless, the literature shows that the modeling community reports much wider and flexible ranges when assessing the quality of simulated data, which reflects the degree of difficulty on modeling and simulating SST concentrations. The following NS ranges for daily sediment concentration simulations are reported in Moriasi et al. [
36]: −2.5 < NS < 0.11 for calibration and −3.51 < NS < 0.23 for validation. The following ranges were found by Ang and Oeurng [
26]: NS > 0.38, PBIAS < 5.1%, and RSR < 0.79, for calibration. For validation: NSE > −6.61, PBIAS < −78.38%, and RSR < 2.67 are reported [
37]. Kling-Gupta efficiencies within the range 0.5 < K-G < 1.0 are usually considered acceptable ([
38].
In this research, the acceptability ranges for the indicators of statistical fit (NS, R
2, and K-G) were set up so that the prediction capabilities of the NARX model are better than satisfactory. The upper limit for the estimators of fit is 1.0, corresponding to perfect fit between simulated and observed data. On the other hand, correlation coefficient values greater than 0.7 are considered acceptable (R > 0.7); therefore, the acceptability range for the coefficient of determination would be: R
2 > 0.5. Moreover, Knoben et al. [
38] (after performing a random sampling experiment) report that K-G = 0.5 correspond (in average) to NS = 0.5. Based on these considerations,
Table 2 shows the statistical indicators acceptability ranges and formulae used in this research.
Summarizing, the quality of the NARX output was categorized as having good statistical fit with observed data according to the following criteria:
Monthly time-step simulations: RSR < 0.7, −15% < PBIAS < 15%, R2 > 0.6, NS > 0.6, and K-G > 0.6.
Daily time-step simulations: RSR < 0.79, −18% < PBIAS < 18%, R2 > 0.5, NS > 0.5, and K-G > 0.5.
In cases in which simulations for SST produced unbalanced performance ratings, the Willmott’s index of agreement (d) was calculated, and if most statistical indicators were on the acceptable ranges, the simulation was rated “satisfactory”. Since in this research, d is used as a deciding qualifier of statistical fit, its threshold values of acceptability are more stringent than those of R2 and NS indicators–for monthly simulations d > 0.78 and for daily simulations d > 0.65.
Ranges for PBIAS and RSR were assigned after [
36].
4. Discussion
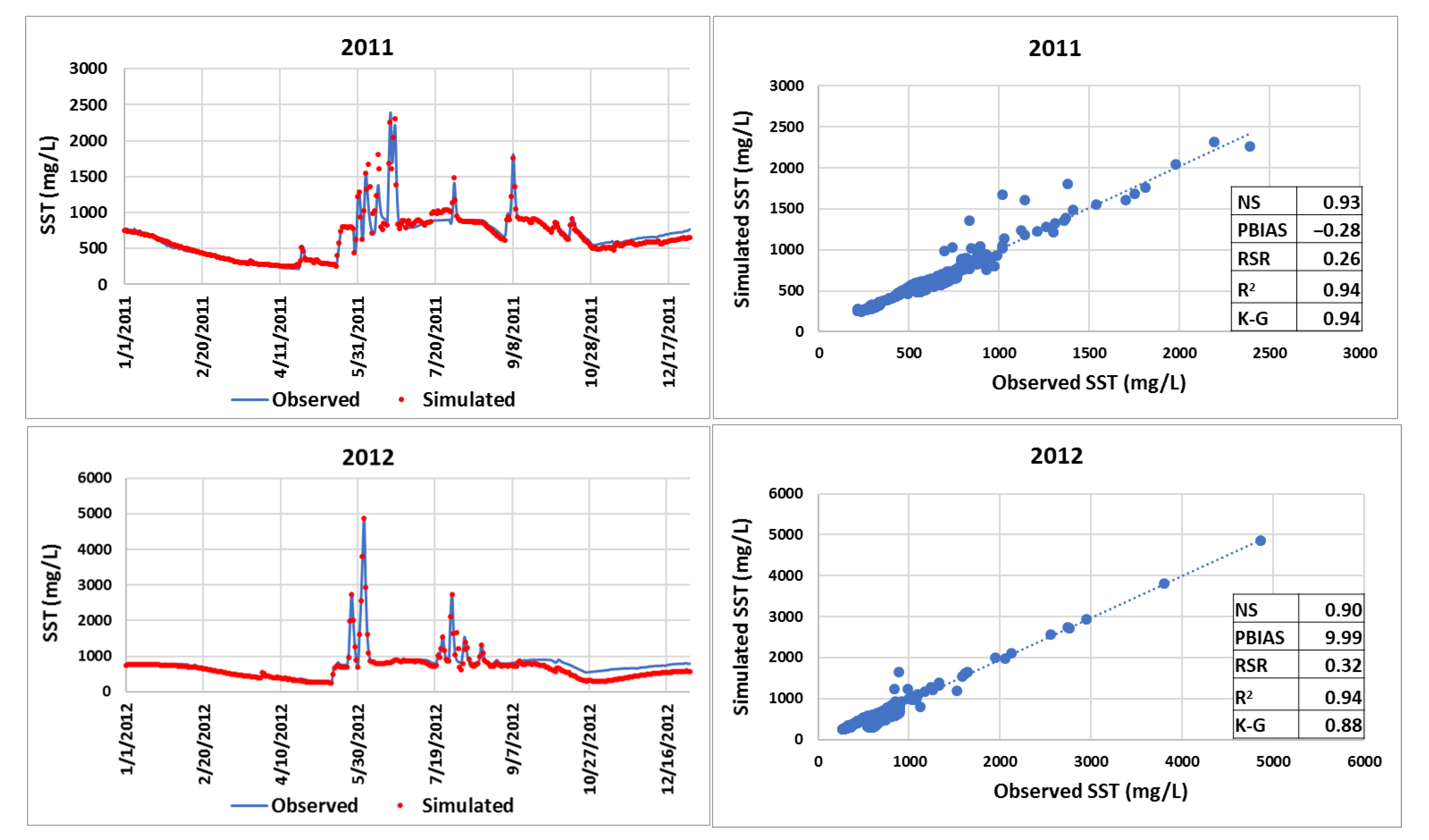
This research shows that forecasting total suspended sediment (SST) concentrations can be performed using a non-linear autoregressive artificial neural network with exogenous inputs (NARX). Although the modeling strategy and the resulting neural network were applied to estimate SST concentrations occurring at Francia Creek (Valparaiso, Chile), the NARX could be adjusted (via re-training) to estimate SST concentrations in other streams and watersheds. The NARX developed in this study was able to predict daily and monthly SST concentrations for years 2013 and 2014, based on precipitation and SST concentrations from previous years (2011 and 2012). The daily SST concentrations were more accurately forecasted for baseflow conditions. Indicators of statistical fit between forecasted and observed data were R2 = 0.73, NS = 0.71, and K-G = 0.84, which indicate very good quality prediction levels of daily SST concentrations under baseflow conditions. Indicators of statistical error were below the acceptable maximum values—PBIAS = 3.6% < 15%, RSR = 0.54 < 0.79, which demonstrates that the simulated daily SST data had low residual variation and low bias, characteristics of accurate forecasting.
When comparing simulated and observed daily SST concentrations for a complete year, the NARX network produces a satisfactory forecasting of daily data. For year 2014, the statistical indicators of fit were R2 = 0.53, NS = 0.47, K-G = 0.60, Willmott’s index of agreement d = 0.82. Therefore, the statistical indicators of fit were within acceptable margins. The forecasted SST concentrations underperformed in statistical error (RSR = 0.91 > 0.79) but overperformed bias indicators (PBIAS = −15.86% is within the range: −18% < PBIAS < 18%).
Predicting daily SST concentrations for two years decreases the forecasting quality of the neural network. Predictions for 2013 and 2014 yielded the following indicators of statistical fit: K-G = 0.5, R2 = 0.28, NS = 0.21, Willmott’s index of agreement, d = 0.68. Indicators of statistical error were PBIAS = 3.41 (low bias), RSR = 0.89 > 0.79. Therefore, the daily forecasting of SST concentrations for years 2013 and 2014 was satisfactory. However, monthly maximum SST concentrations for the two-year period (2013 and 2014) were well captured by the NARX network: RSR = 0.62 > 0.6, PBIAS = 18.87% < 20%, R2 = 0.69 > 0.6, NS = 0.60 > 0.6, K-G = 0.54 > 0.5, d = 0.84 > 0.8.
In consequence, the NARX network successfully forecasted daily SST concentrations for baseflow conditions for two years (2013 and 2014). Also, the neural network was able to forecast (within acceptable statistical fit margins) daily SST for up to one continuous year (2014). At a monthly level, the NARX network was able to predict maximum SST concentrations for two years (2013 and 2014).
The results reported in this paper are relevant to sustainable land management as they provide a forecasting methodology applicable to other watersheds. Nevertheless, the NARX-based forecasting model developed in this research is more site-specific than physically based models (such as the SWAT-MUSLE applications reported in [
39]), and it may require substantial adjustments if meteorological conditions and flow regimes are very different to those encountered in this study.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}