
Predictive Modeling Approach for Surface Water Quality: Development and Comparison of Machine Learning Models

 ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
2. Material and Methods
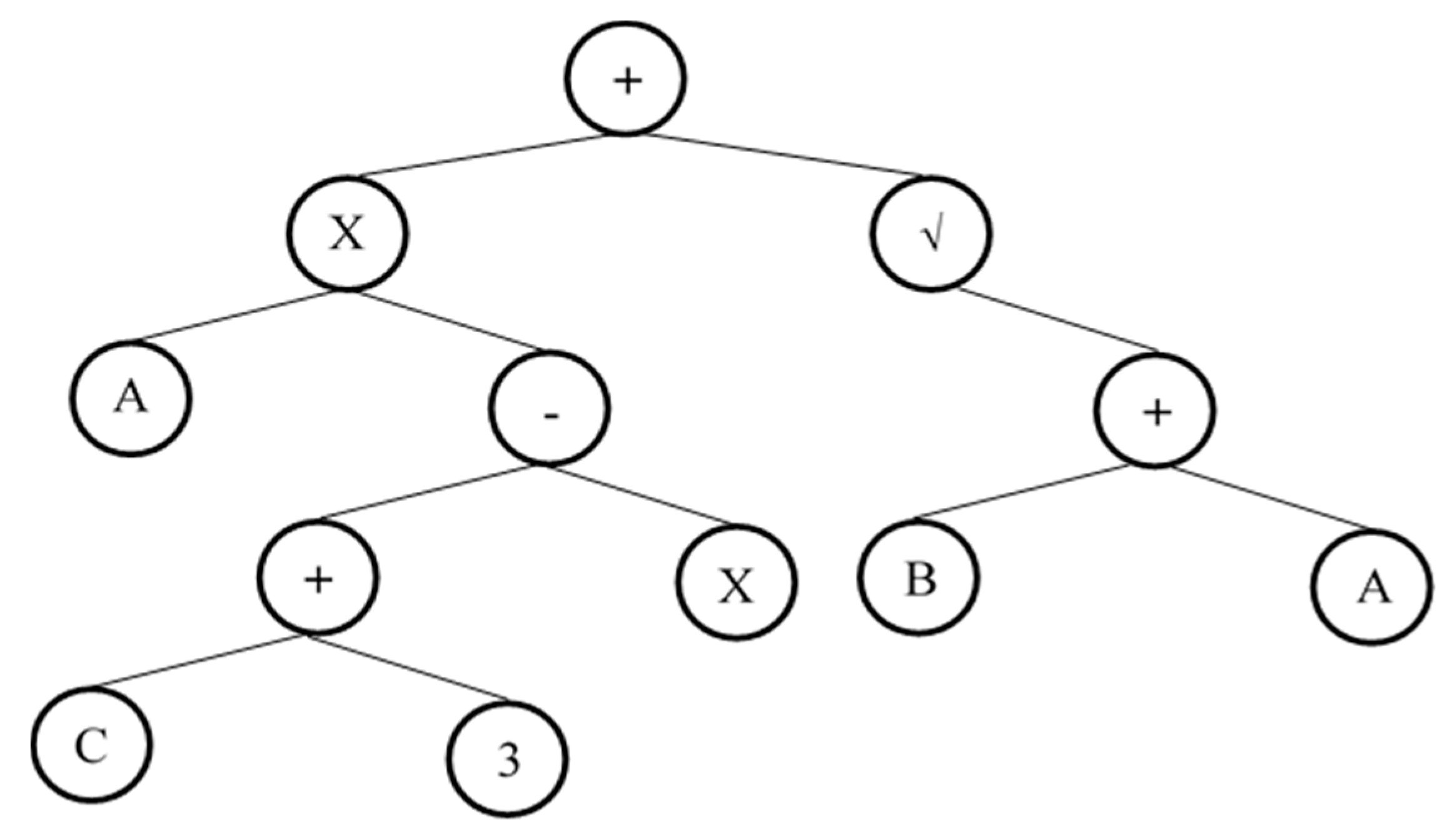
2.1. Genetic Base Algorithm
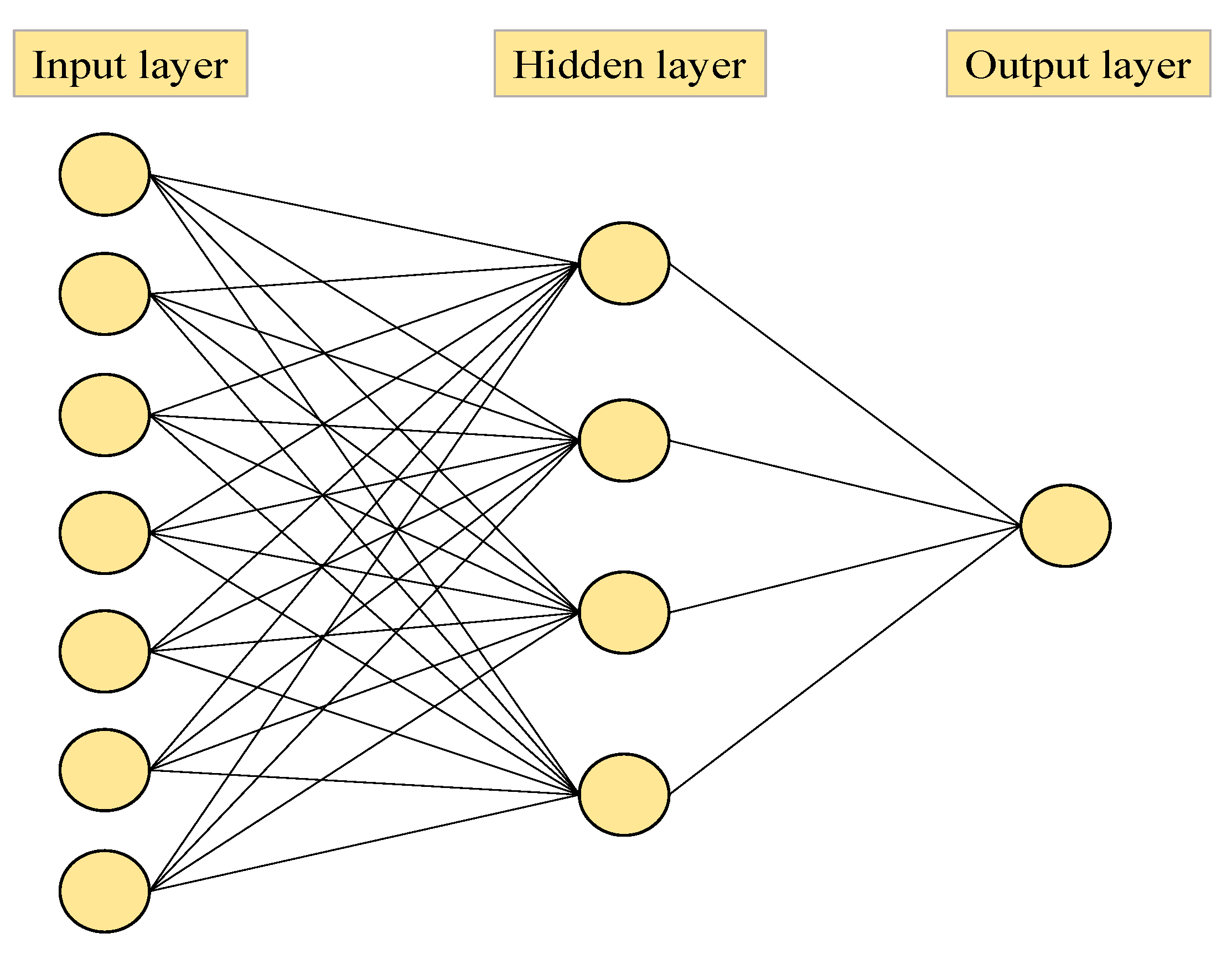
2.2. Artificial Neural Network (ANN)
2.3. Linear Regression Model (LRM)
3. Study Area, Datasets and Modeling
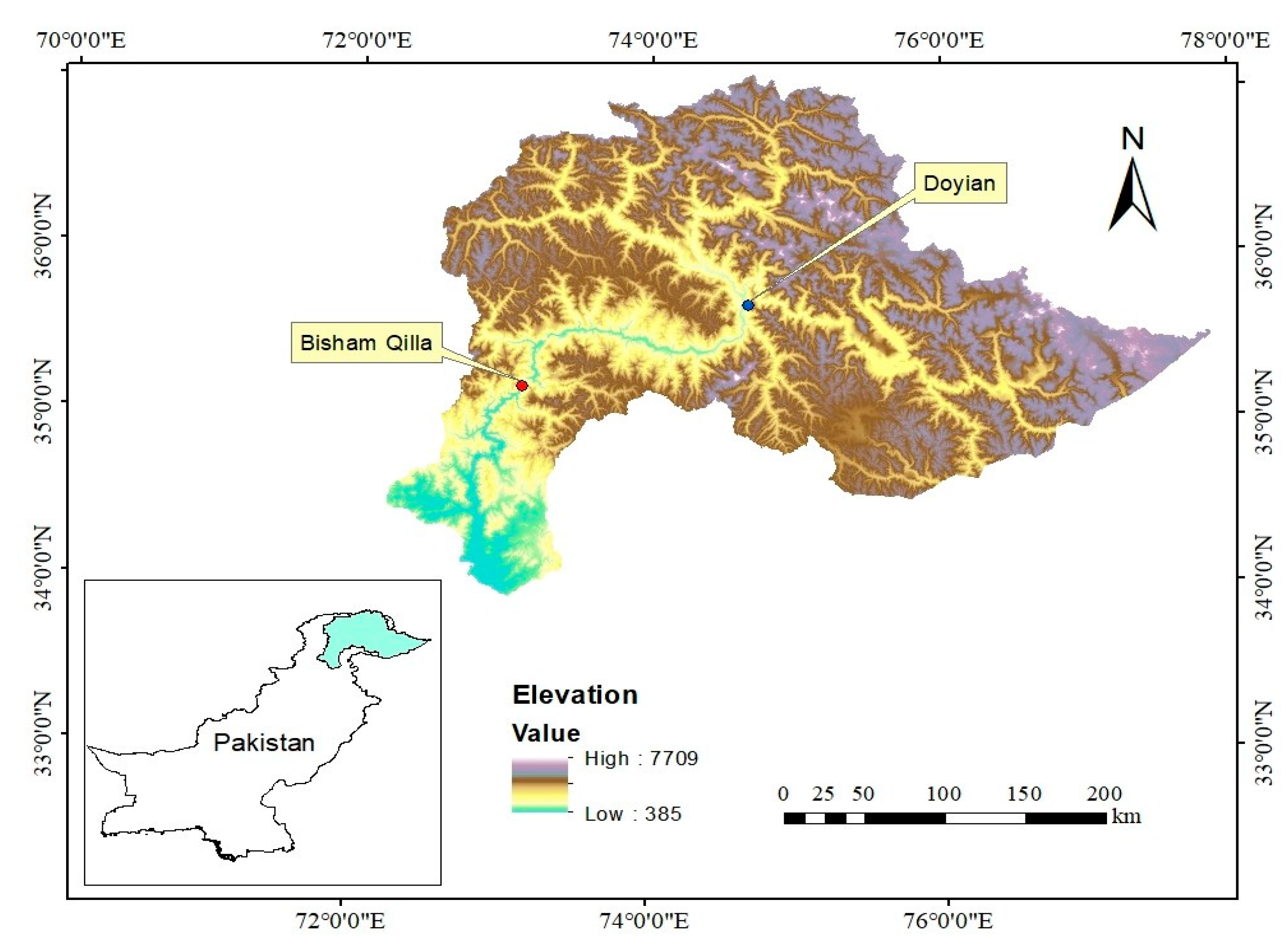
3.1. Description of the Study Area
3.2. Modeling and Water Quality Dataset
3.3. Models Performance Evaluation
4. Results and Discussion
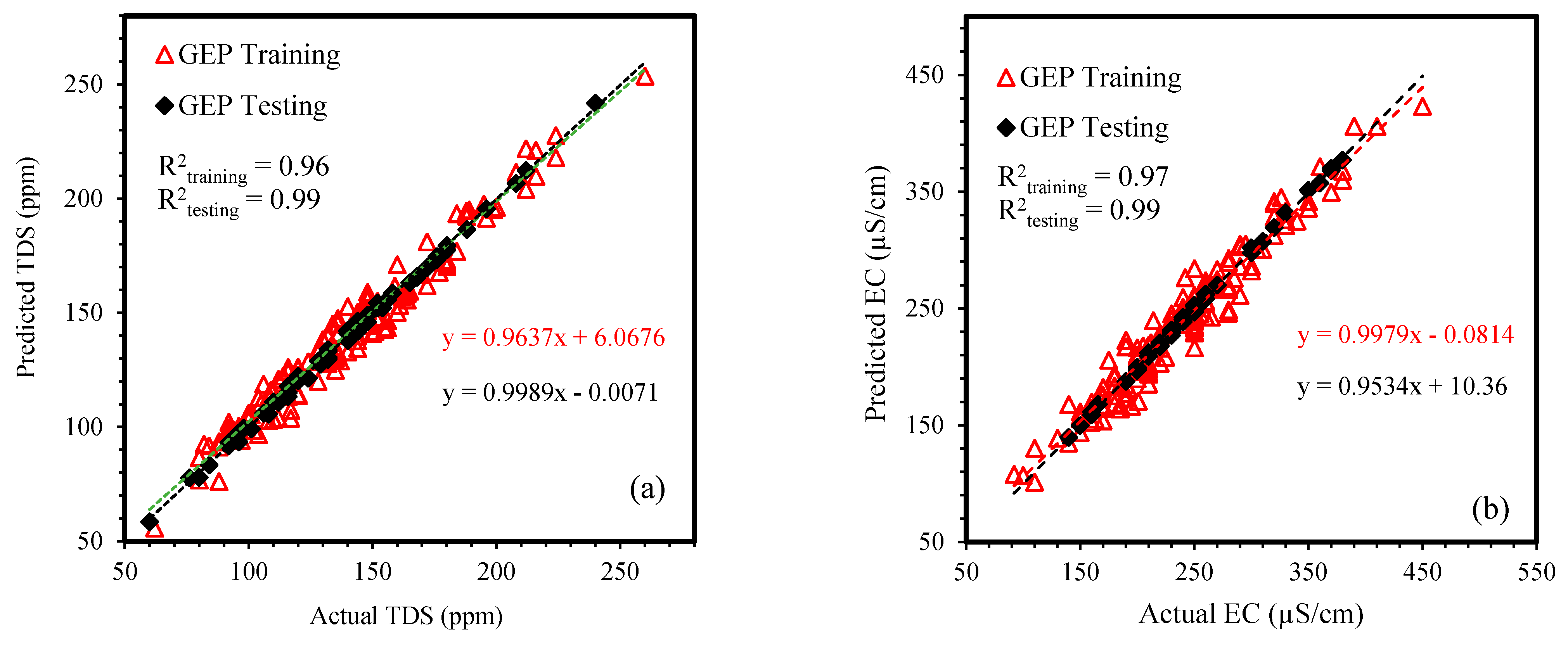
4.1. Formulation of TDS and EC Using GEP
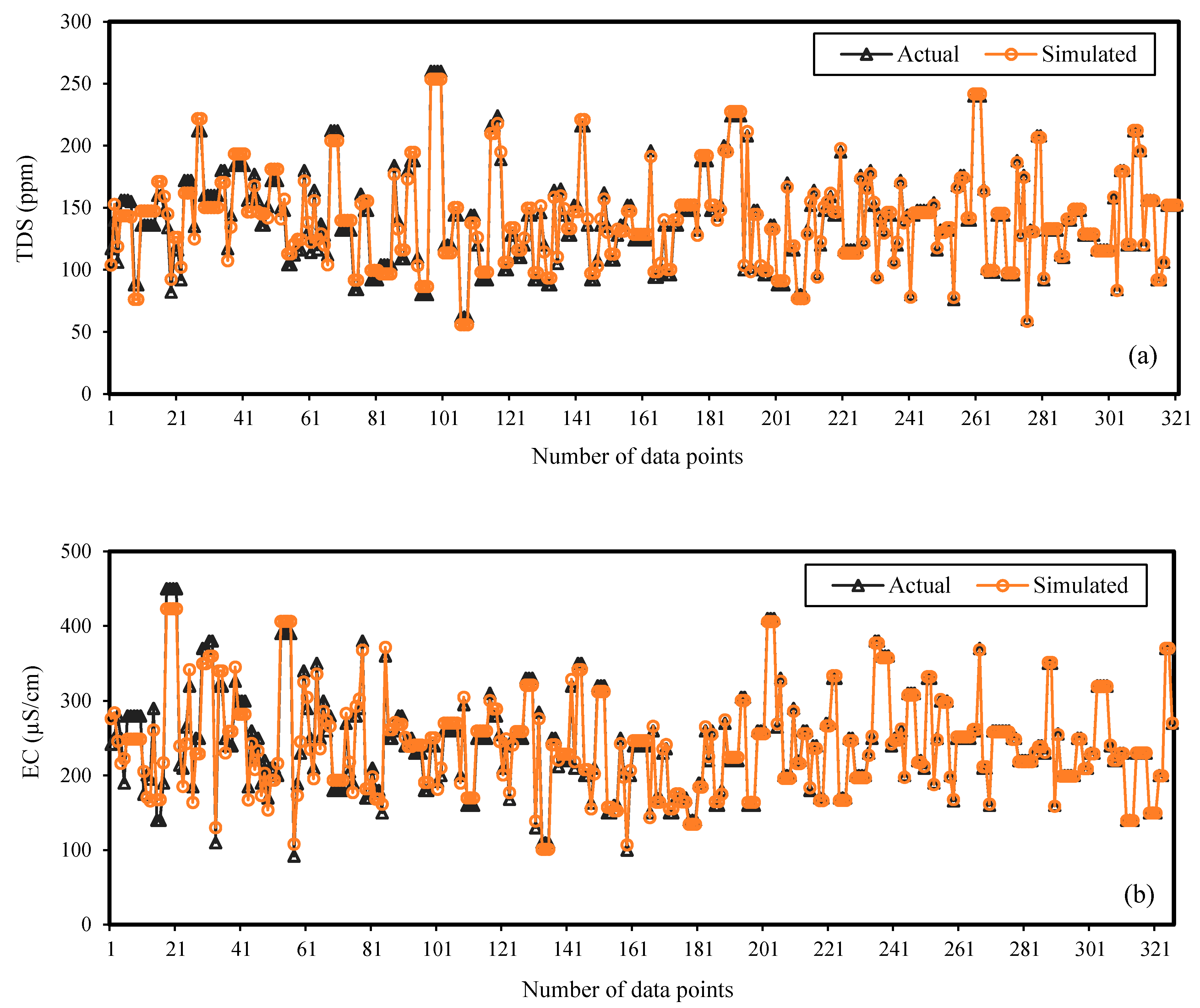
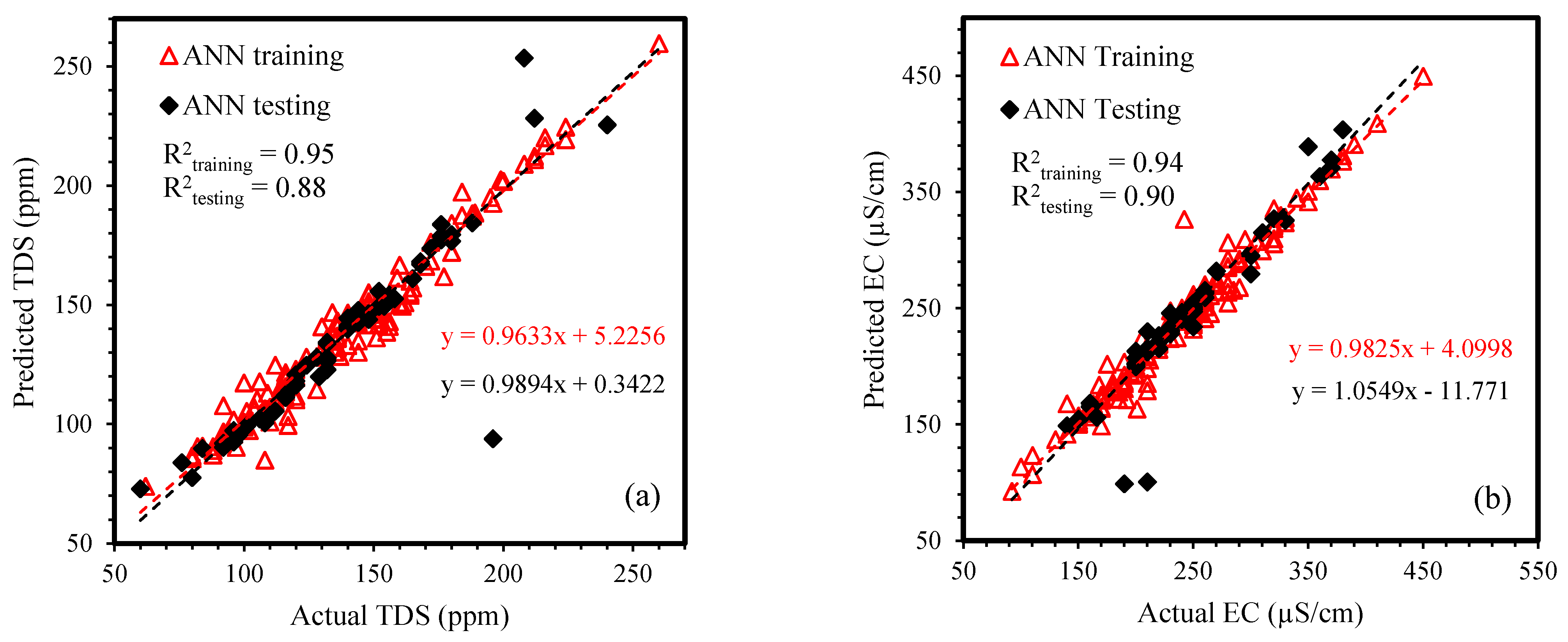
4.2. ANN Modeling Output
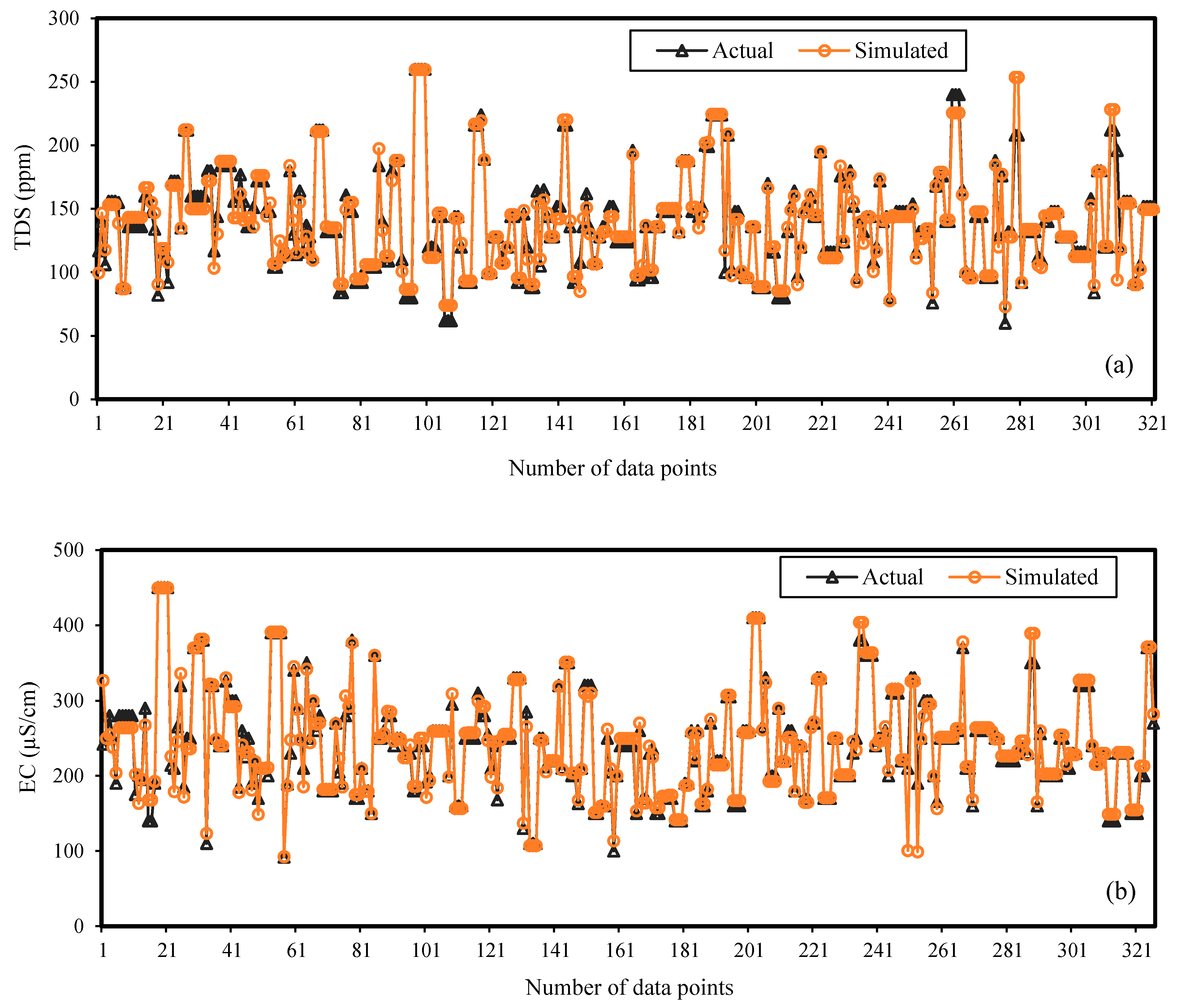
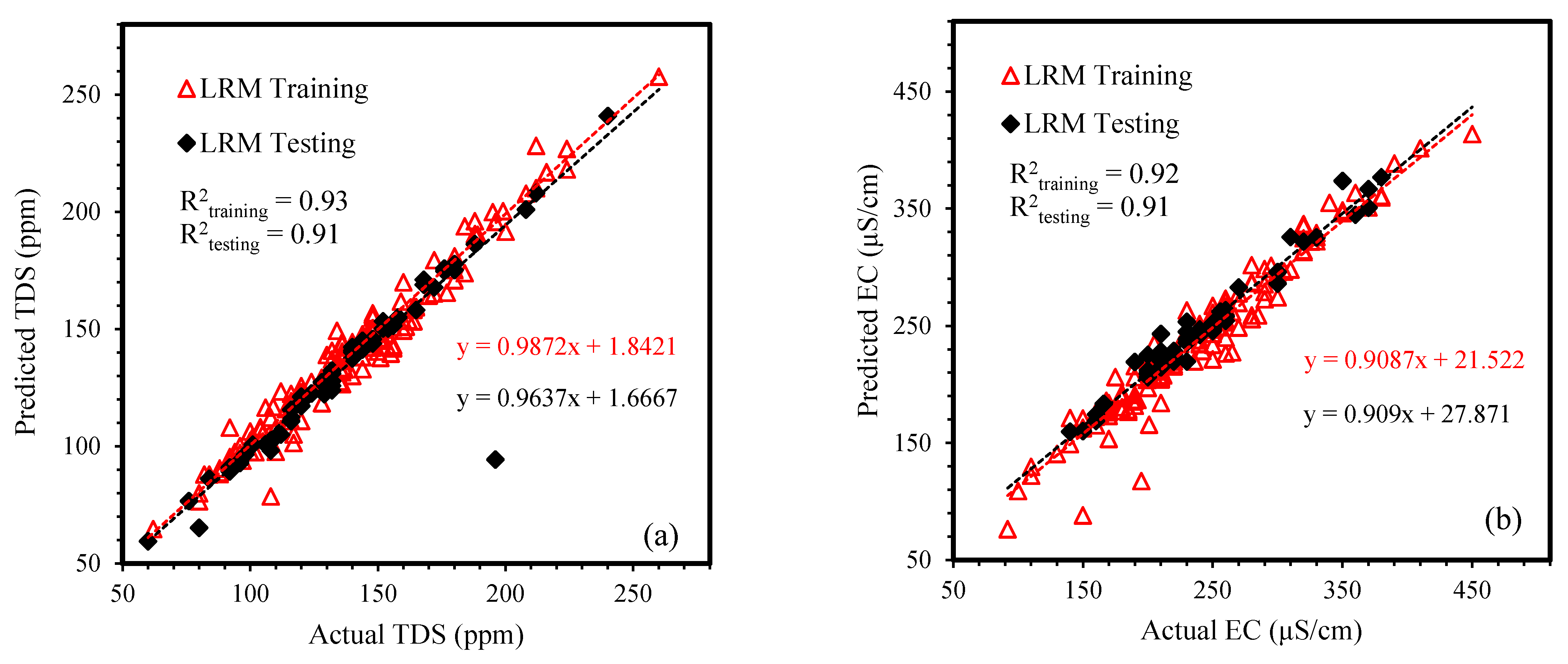
4.3. Linear Regression Modeling for TDS and EC
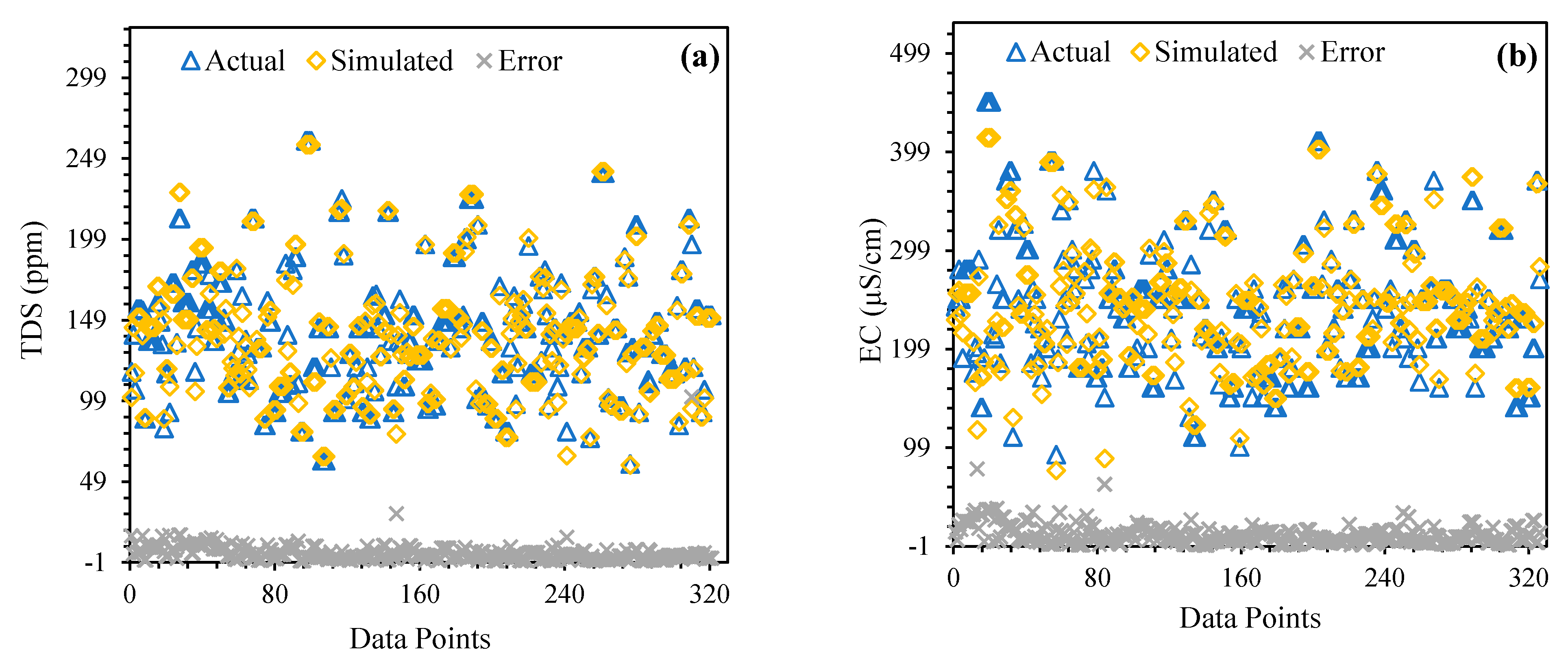
4.4. Models Comparative Analysis and Error Assessment
4.5. Models External Validation
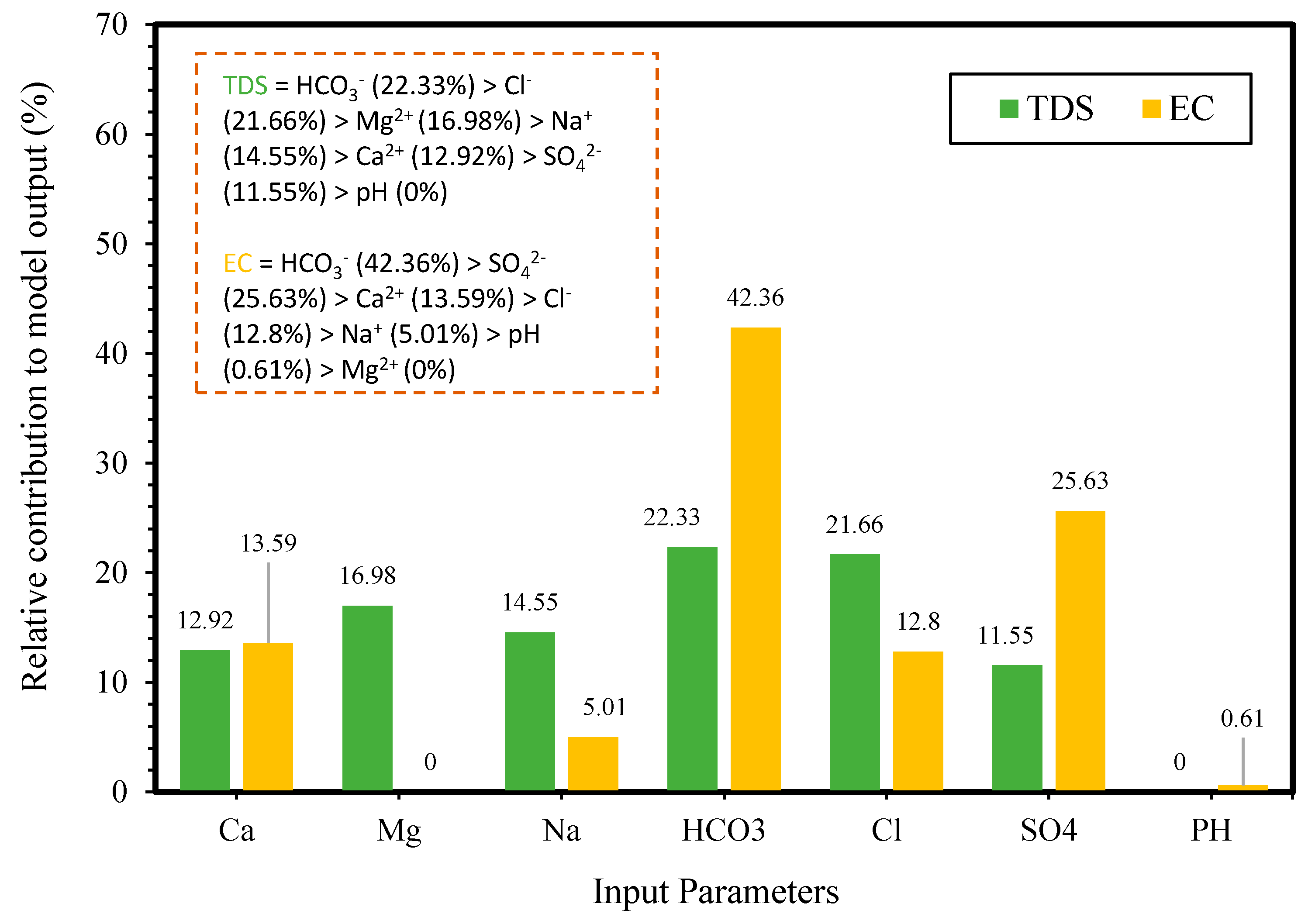
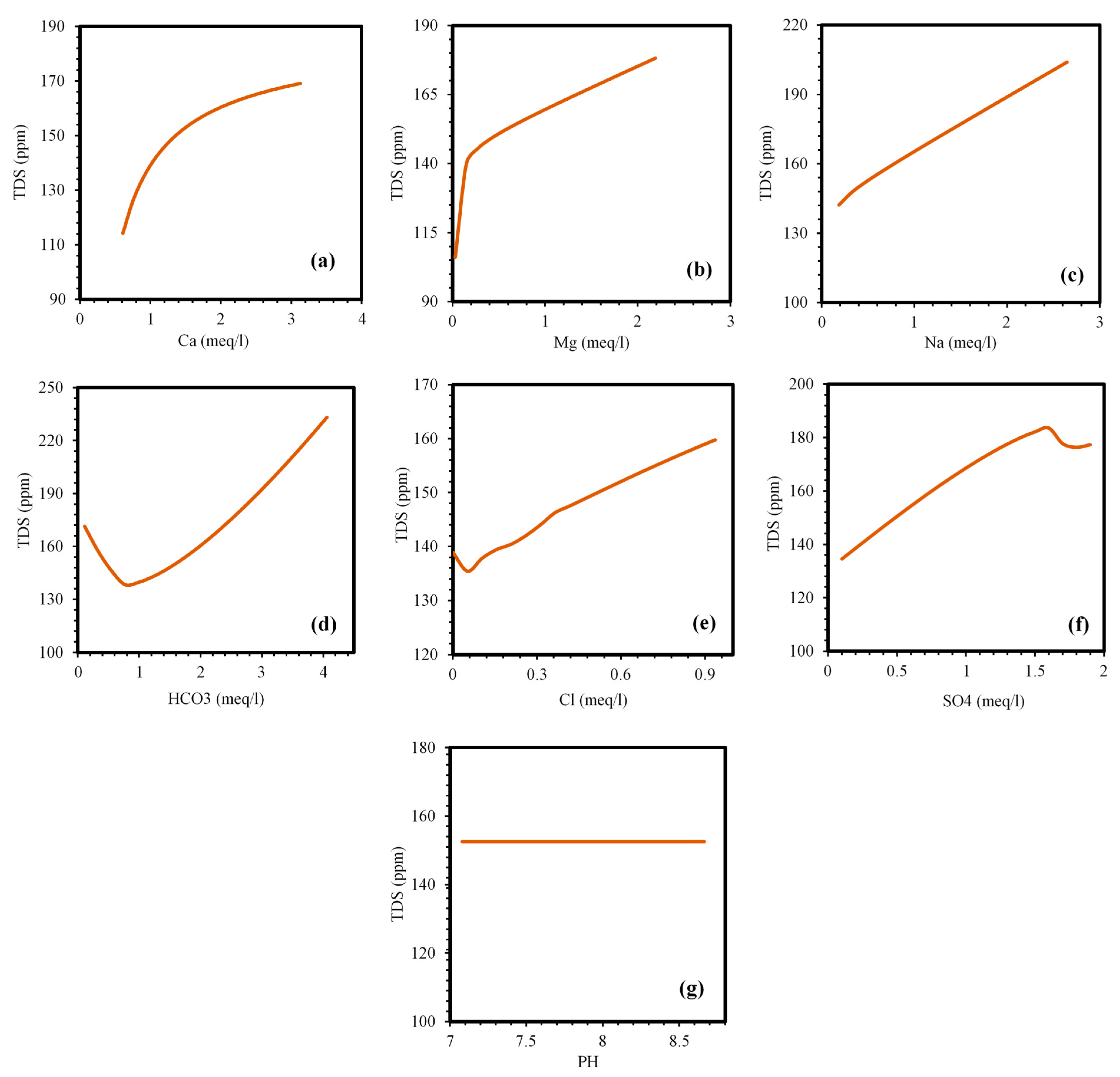
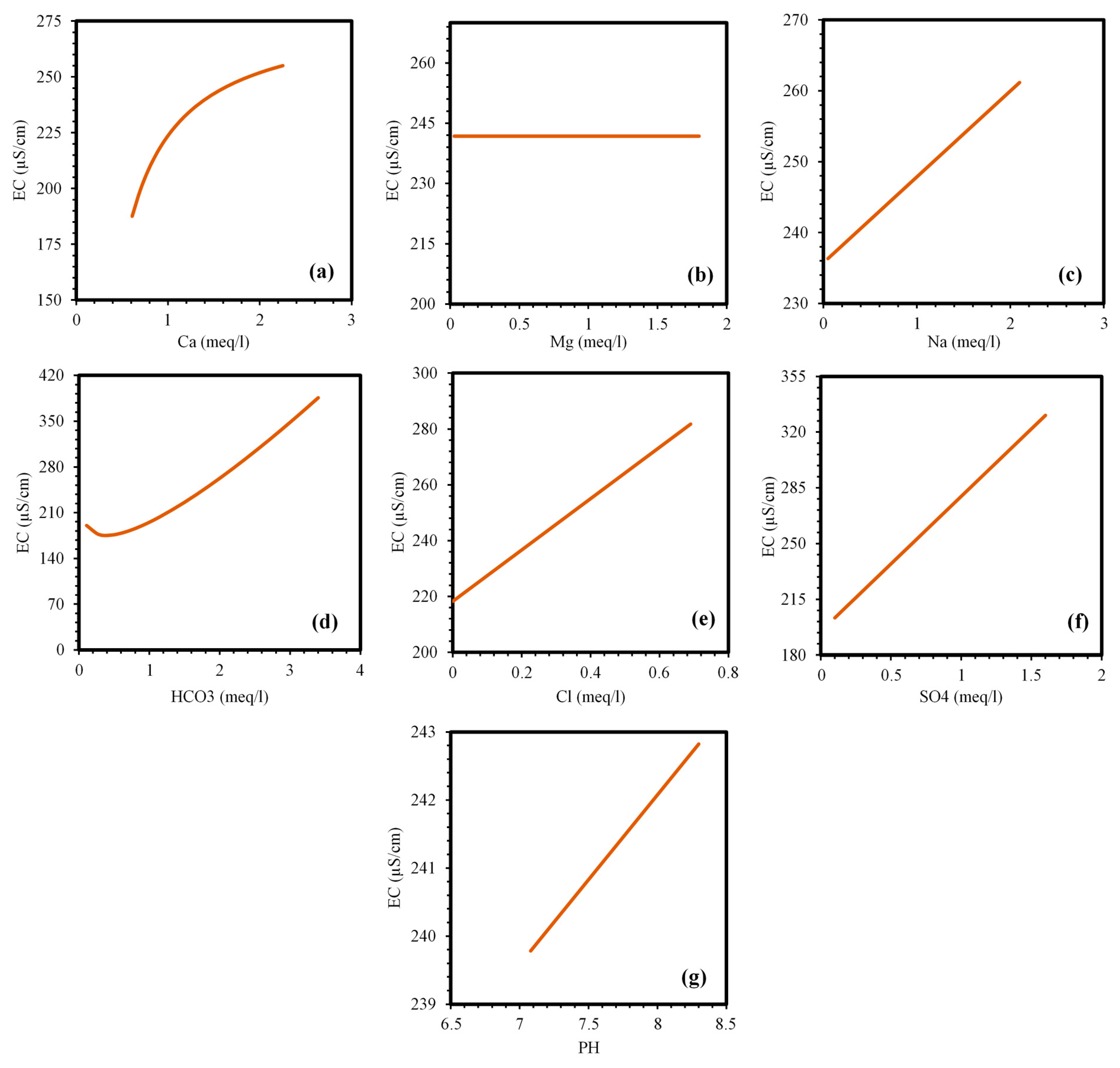
4.6. Sensitivity and Parametric Study
4.7. Environmental Aspects of Water Quality Modeling
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Mukhtar, M.; Al-Yaseen, F. Modeling water quality parameters using data-driven models, a case study Abu-Ziriq marsh in south of Iraq. Hydrology 2019, 6, 24. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wang, L.; Li, Z.; Xie, Y.; Wang, X.; Fang, Q. Exploring the spatial-seasonal dynamics of water quality, submerged aquatic plants and their influencing factors in different areas of a lake. Water 2017, 9, 707. [Google Scholar] [CrossRef] [Green Version]
- Singh, K.P.; Malik, A.; Mohan, D.; Sinha, S. Multivariate statistical techniques for the evaluation of spatial and temporal variations in water quality of Gomti River (India)—A case study. Water Res. 2004, 38, 3980–3992. [Google Scholar] [CrossRef] [PubMed]
- Mohammadpour, R.; Shaharuddin, S.; Zakaria, N.A.; Ghani, A.A.; Vakili, M.; Chan, N.W. Prediction of water quality index in free surface constructed wetlands. Environ. Earth Sci. 2016, 75, 139. [Google Scholar] [CrossRef]
- Schleiter, I.M.; Borchardt, D.; Wagner, R.; Dapper, T.; Schmidt, K.-D.; Schmidt, H.-H.; Werner, H. Modelling water quality, bioindication and population dynamics in lotic ecosystems using neural networks. Ecol. Model. 1999, 120, 271–286. [Google Scholar] [CrossRef]
- Salami, E.S.; Salari, M.; Ehteshami, M.; Bidokhti, N.T.; Ghadimi, H. Application of artificial neural networks and mathematical modeling for the prediction of water quality variables (case study: Southwest of Iran). Desalin. Water Treat. 2016, 57, 27073–27084. [Google Scholar] [CrossRef]
- Najah, A.; El-Shafie, A.; Karim, O.A.; El-Shafie, A.H. Application of artificial neural networks for water quality prediction. Neural Comput. Appl. 2013, 22, 187–201. [Google Scholar] [CrossRef]
- Shah, M.I.; Abunama, T.; Javed, M.F.; Bux, F.; Aldrees, A.; Tariq, M.A.U.R.; Mosavi, A. Modeling surface water quality using the adaptive neuro-fuzzy inference system aided by input optimization. Sustainability 2021, 13, 4576. [Google Scholar] [CrossRef]
- Sattari, M.T.; Joudi, A.R.; Kusiak, A. Estimation of water quality parameters with data-driven model. J. Am. Water Works Assoc. 2016, 108, E232–E239. [Google Scholar] [CrossRef] [Green Version]
- Basant, N.; Gupta, S.; Malik, A.; Singh, K.P. Linear and nonlinear modeling for simultaneous prediction of dissolved oxygen and biochemical oxygen demand of the surface water—A case study. Chemom. Intell. Lab. Syst. 2010, 104, 172–180. [Google Scholar] [CrossRef]
- Gholampour, A.; Gandomi, A.H.; Ozbakkaloglu, T. New formulations for mechanical properties of recycled aggregate concrete using gene expression programming. Const. Build. Mater. 2017, 130, 122–145. [Google Scholar] [CrossRef]
- Vats, S.; Sagar, B.B.; Singh, K.; Ahmadian, A.; Pansera, B.A. Performance evaluation of an independent time optimized infrastructure for big data analytics that maintains symmetry. Symmetry 2020, 12, 1274. [Google Scholar] [CrossRef]
- Pakdaman, M.; Falamarzi, Y.; Yazdi, H.S.; Ahmadian, A.; Salahshour, S.; Ferrara, F. A kernel least mean square algorithm for fuzzy differential equations and its application in earth’s energy balance model and climate. Alex. Eng. J. 2020, 59, 2803–2810. [Google Scholar] [CrossRef]
- Sarkar, A.; Pandey, P. River water quality modelling using artificial neural network technique. Aquat. Procedia 2015, 4, 1070–1077. [Google Scholar] [CrossRef]
- Chebud, Y.; Naja, G.M.; Rivero, R.G.; Melesse, A.M. Water quality monitoring using remote sensing and an artificial neural network. Water Air Soil Pollut. 2012, 223, 4875–4887. [Google Scholar] [CrossRef]
- Palani, S.; Liong, S.-Y.; Tkalich, P. An ANN application for water quality forecasting. Mar. Pollut. Bullet. 2008, 56, 1586–1597. [Google Scholar] [CrossRef]
- Firat, M.; Güngör, M. Monthly total sediment forecasting using adaptive neuro fuzzy inference system. Stoch. Environ. Res. Risk Assess. 2010, 24, 259–270. [Google Scholar] [CrossRef]
- Chen, L.; Jamal, M.; Tan, C.; Alabbadi, B. A study of applying genetic algorithm to predict reservoir water quality. Int. J. Model. Optim. 2017, 7, 98. [Google Scholar] [CrossRef] [Green Version]
- Martí, P.; Shiri, J.; Duran-Ros, M.; Arbat, G.; De Cartagena, F.R.; Puig-Bargués, J. Artificial neural networks vs. gene expression programming for estimating outlet dissolved oxygen in micro-irrigation sand filters fed with effluents. Comput. Electron. Agric. 2013, 99, 176–185. [Google Scholar] [CrossRef]
- Amin, R.; Shah, K.; Khan, I.; Asif, M.; Salimi, M.; Ahmadian, A. Efficient numerical scheme for the solution of tenth order boundary value problems by the Haar wavelet method. Mathematics 2020, 8, 1874. [Google Scholar] [CrossRef]
- Farooq, F.; Nasir Amin, M.; Khan, K.; Rehan Sadiq, M.; Faisal Javed, M.; Aslam, F.; Alyousef, R.A. Comparative study of random forest and genetic engineering programming for the prediction of compressive strength of high strength concrete (HSC). Appl. Sci. 2020, 10, 7330. [Google Scholar] [CrossRef]
- Aslam, F.; Farooq, F.; Amin, M.N.; Khan, K.; Waheed, A.; Akbar, A.; Alabdulijabbar, H. Applications of gene expression programming for estimating compressive strength of high-strength concrete. Adv. Civ. Eng. 2020, 2020, 1–23. [Google Scholar] [CrossRef]
- Shah, M.I.; Amin, M.N.; Khan, K.; Niazi, M.S.K.; Aslam, F.; Alyousef, R.; Mosavi, A. Performance evaluation of soft computing for modeling the strength properties of waste substitute green concrete. Sustainability 2021, 13, 2867. [Google Scholar] [CrossRef]
- Shah, M.I.; Memon, S.A.; Khan Niazi, M.S.; Amin, M.N.; Aslam, F.; Javed, M.F. Machine learning-based modeling with optimization algorithm for predicting mechanical properties of sustainable concrete. Adv. Civ. Eng. 2021, 2021. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1999; Volume 7458, pp. 161–175. [Google Scholar]
- Tung, T.M.; Yaseen, Z.M. A survey on river water quality modelling using artificial intelligence models: 2000–2020. J. Hydrol. 2020, 585, 124670. [Google Scholar]
- Bermejo, J.F.; Fernández, J.F.G.; Polo, F.O.; Márquez, A.C. A review of the use of artificial neural network models for energy and reliability prediction. A study of the solar PV, hydraulic and wind energy sources. Appl. Sci. 2019, 9, 1844. [Google Scholar] [CrossRef] [Green Version]
- Koza, J.R.; Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992; Volume 1. [Google Scholar]
- Javed, M.F.; Farooq, F.; Memon, S.A.; Akbar, A.; Khan, M.A.; Aslam, F.; Rehman, S.K.U. New prediction model for the ultimate axial capacity of concrete-filled steel tubes: An evolutionary approach. Crystals 2020, 10, 741. [Google Scholar] [CrossRef]
- Hada, D.S.; Gupta, U.; Sharma, S.C. Seasonal evaluation of hydro-geochemical parameters using goal programming with multiple nonlinear regression. Gen. Math. Notes 2014, 25, 137–147. [Google Scholar]
- Ahmed, A.N.; Othman, F.B.; Afan, H.A.; Ibrahim, R.K.; Fai, C.M.; Hossain, M.S.; Elshafie, A. Machine learning methods for better water quality prediction. J. Hydrol. 2019, 578, 124084. [Google Scholar] [CrossRef]
- Granata, F.; Papirio, S.; Esposito, G.; Gargano, R.; De Marinis, G. Machine learning algorithms for the forecasting of wastewater quality indicators. Water 2017, 9, 105. [Google Scholar] [CrossRef] [Green Version]
- Haghiabi, A.H.; Nasrolahi, A.H.; Parsaie, A. Water quality prediction using machine learning methods. Water Qual. Res. J. 2018, 53, 3–13. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, X.; Smith, K.; Inial, G.; Liu, S.; Conil, L.B.; Pan, B. Integrating water quality and operation into prediction of water production in drinking water treatment plants by genetic algorithm enhanced artificial neural network. Water Res. 2019, 164, 114888. [Google Scholar] [CrossRef]
- Ferreira, C. Gene expression programming: A new adaptive algorithm for solving problems. arXiv 2001, arXiv:cs/0102027. Available online: https://arxiv.org/abs/cs/0102027 (accessed on 5 April 2021).
- Azim, I.; Yang, J.; Javed, M.F.; Iqbal, M.F.; Mahmood, Z.; Wang, F.; Liu, Q.F. Prediction model for compressive arch action capacity of RC frame structures under column removal scenario using gene expression programming. Structures 2020, 25, 212–228. [Google Scholar] [CrossRef]
- Lopes, H.S.; Weinert, W.R. A gene expression programming system for time series modeling. In Proceedings of the XXV Iberian Latin American Congress on Computational Methods in Engineering, Recife, Brazil, 10–12 November 2004. [Google Scholar]
- Shah, M.I.; Javed, M.F.; Alqahtani, A.; Aldrees, A. Environmental assessment based surface water quality prediction using hyper-parameter optimized machine learning models based on consistent big data. Process Saf. Environ. Prot. 2021, 151, 324–340. [Google Scholar] [CrossRef]
- Iqbal, M.F.; Liu, Q.-F.; Azim, I.; Zhu, X.; Yang, J.; Javed, M.F.; Rauf, M. Prediction of mechanical properties of green concrete incorporating waste foundry sand based on gene expression programming. J. Hazard. Mater. 2020, 384, 121322. [Google Scholar] [CrossRef] [PubMed]
- Guven, A.; Gunal, M. Genetic programming approach for prediction of local scour downstream of hydraulic structures. J. Irrig. Drain. Eng. 2008, 134, 241–249. [Google Scholar] [CrossRef]
- Ferreira, C. Gene expression programming in problem solving. In Soft Computing and Industry; Springer: London, UK, 2002; pp. 635–653. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biol. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Azamathulla, H.M.; Rathnayake, U.; Shatnawi, A. Gene expression programming and artificial neural network to estimate atmospheric temperature in Tabuk, Saudi Arabia. Appl. Water Sci. 2018, 8, 184. [Google Scholar] [CrossRef] [Green Version]
- Weisberg, S. Applied Linear Regression; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 528. [Google Scholar]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Shah, M.I.; Khan, A.; Akbar, T.A.; Hassan, Q.K.; Khan, A.J.; Dewan, A. Predicting hydrologic responses to climate changes in highly glacierized and mountainous region Upper Indus Basin. R. Soc. Open Sci. 2020, 7, 191957. [Google Scholar] [CrossRef] [PubMed]
- Javed, M.F.; Amin, M.N.; Shah, M.I.; Khan, K.; Iftikhar, B.; Farooq, F.; Aslam, F.; Alyousef, R.; Alabduljabbar, H. Applications of Gene Expression Programming and Regression Techniques for Estimating Compressive Strength of Bagasse Ash based Concrete. Crystals 2020, 10, 737. [Google Scholar] [CrossRef]
- Tahir, A.A.; Chevallier, P.; Arnaud, Y.; Neppel, L.; Ahmad, B. Modeling snowmelt-runoff under climate scenarios in the Hunza River basin, Karakoram Range, Northern Pakistan. J. Hydrol. 2011, 409, 104–117. [Google Scholar] [CrossRef]
- Shah, M.I.; Javed, M.F.; Abunama, T. Proposed formulation of surface water quality and modelling using gene expression, machine learning, and regression techniques. Environ. Sci. Pollut. Res. 2021, 28, 13202–13220. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.J.; Koch, M. Correction and informed regionalization of precipitation data in a high mountainous region (Upper Indus Basin) and its effect on SWAT-modelled discharge. Water 2018, 10, 1557. [Google Scholar] [CrossRef] [Green Version]
- Hasson, S.U. Future water availability from Hindukush-Karakoram-Himalaya Upper Indus Basin under conflicting climate change scenarios. Climate 2016, 4, 40. [Google Scholar] [CrossRef] [Green Version]
- Ali, S.; Li, D.; Congbin, F.; Khan, F. Twenty first century climatic and hydrological changes over Upper Indus Basin of Himalayan region of Pakistan. Environ. Res. Lett. 2015, 10, 014007. [Google Scholar] [CrossRef]
- Ayers, R.S.; Westcot, D.W. Water Quality for Agriculture; Food and Agriculture Organization of the United Nations: Rome, Italy, 1985; Volume 29. [Google Scholar]
- Jamei, M.; Ahmadianfar, I.; Chu, X.; Yaseen, Z.M. Prediction of surface water total dissolved solids using hybridized wavelet-multigene genetic programming: New approach. J. Hydrol. 2020, 589, 125335. [Google Scholar] [CrossRef]
- Montaseri, M.; Ghavidel, S.Z.Z.; Sanikhani, H. Water quality variations in different climates of Iran: Toward modeling total dissolved solid using soft computing techniques. Stoch. Environ. Res. Risk Assess. 2018, 32, 2253–2273. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Gandomi, A.; Alavi, A.H.; MirzaHosseini, M.R.; Nejad, F.M. Nonlinear genetic-based models for prediction of flow number of asphalt mixtures. J. Mater. Civ. Eng. 2011, 23, 248–263. [Google Scholar] [CrossRef]
- Frank, I.E.; Todeschini, R. The Data Analysis Handbook; Elsevier: Amsterdam, The Netherlands, 1994. [Google Scholar]
- Golbraikh, A.; Tropsha, A. Beware of q2! J. Mol. Graph. Model. 2002, 20, 269–276. [Google Scholar] [CrossRef]
- Roy, P.P.; Roy, K. On some aspects of variable selection for partial least squares regression models. QSAR Comb. Sci. 2008, 27, 302–313. [Google Scholar] [CrossRef]
- Alavi, A.H.; Ameri, M.; Gandomi, A.H.; Mirzahosseini, M.R. Formulation of flow number of asphalt mixes using a hybrid computational method. Constr. Build. Mater. 2011, 25, 1338–1355. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Yun, G.J.; Alavi, A.H. An evolutionary approach for modeling of shear strength of RC deep beams. Mater. Struct. 2013, 46, 2109–2119. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
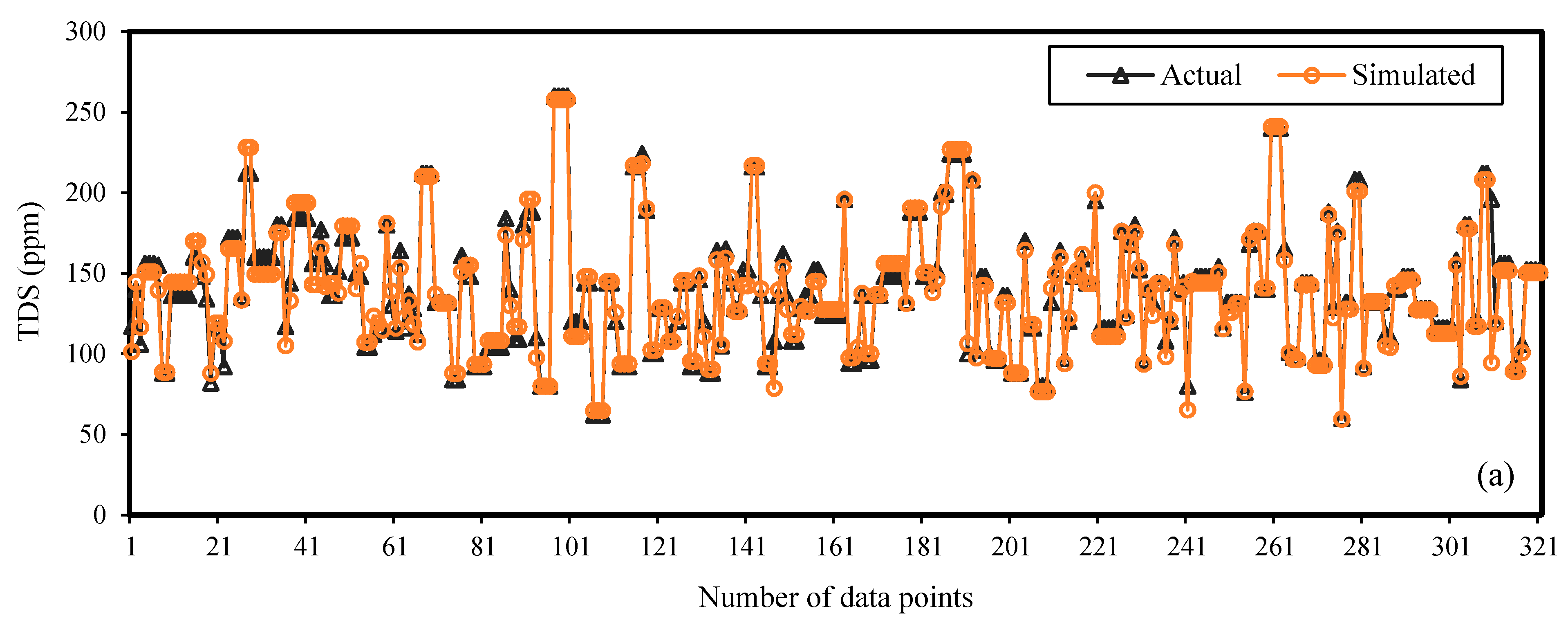{kind=link}
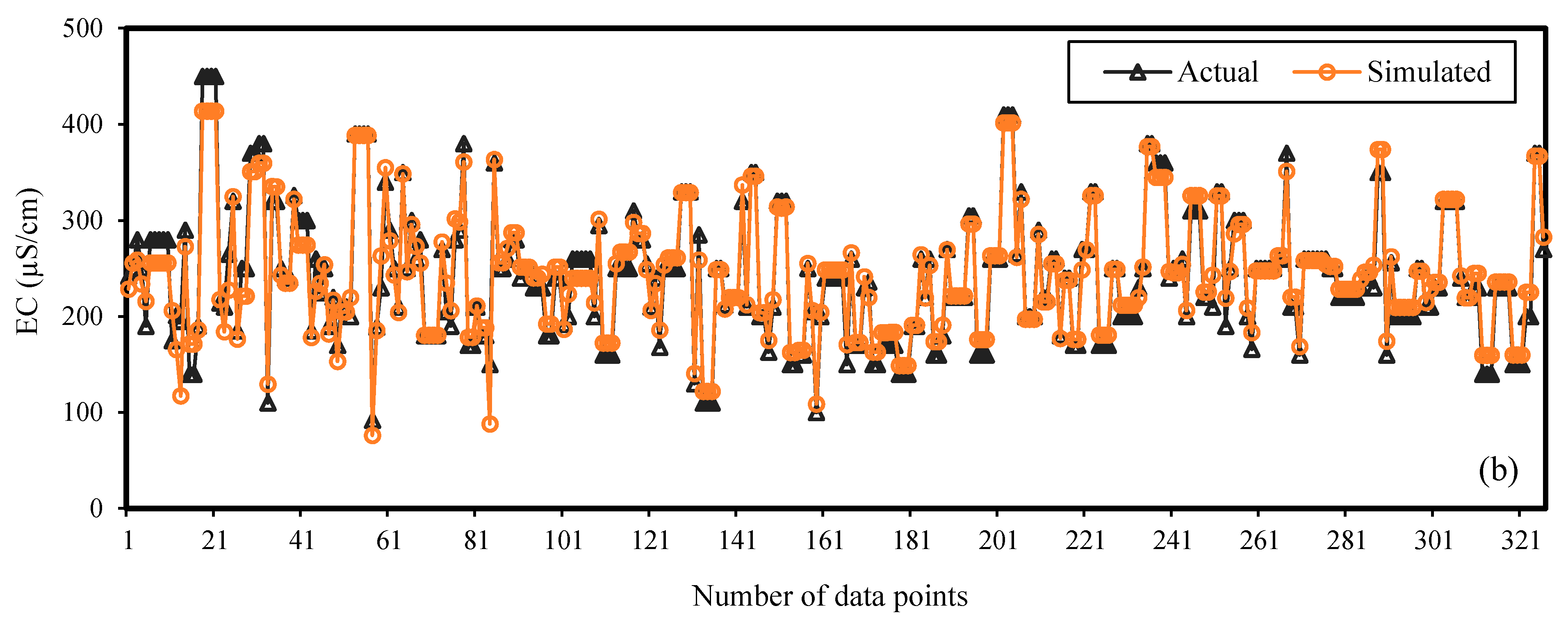{kind=link}
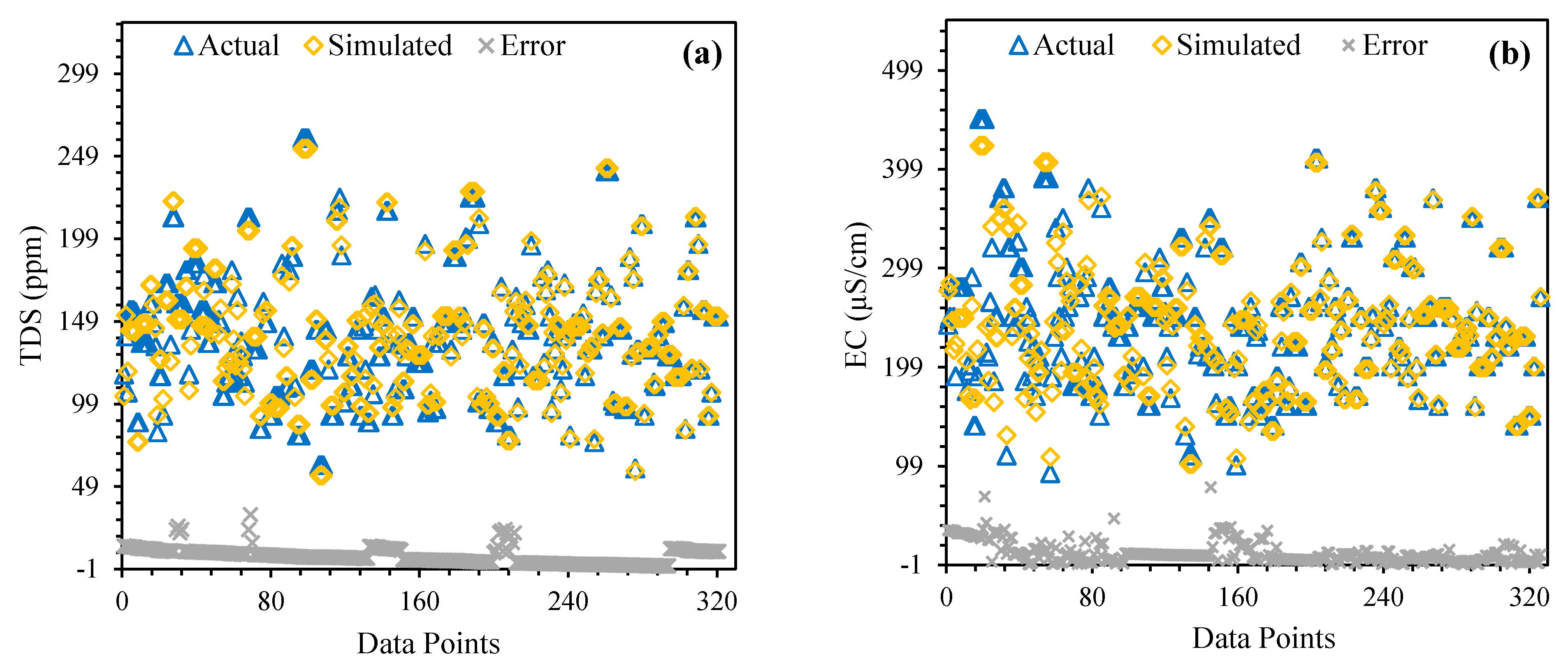{kind=link}
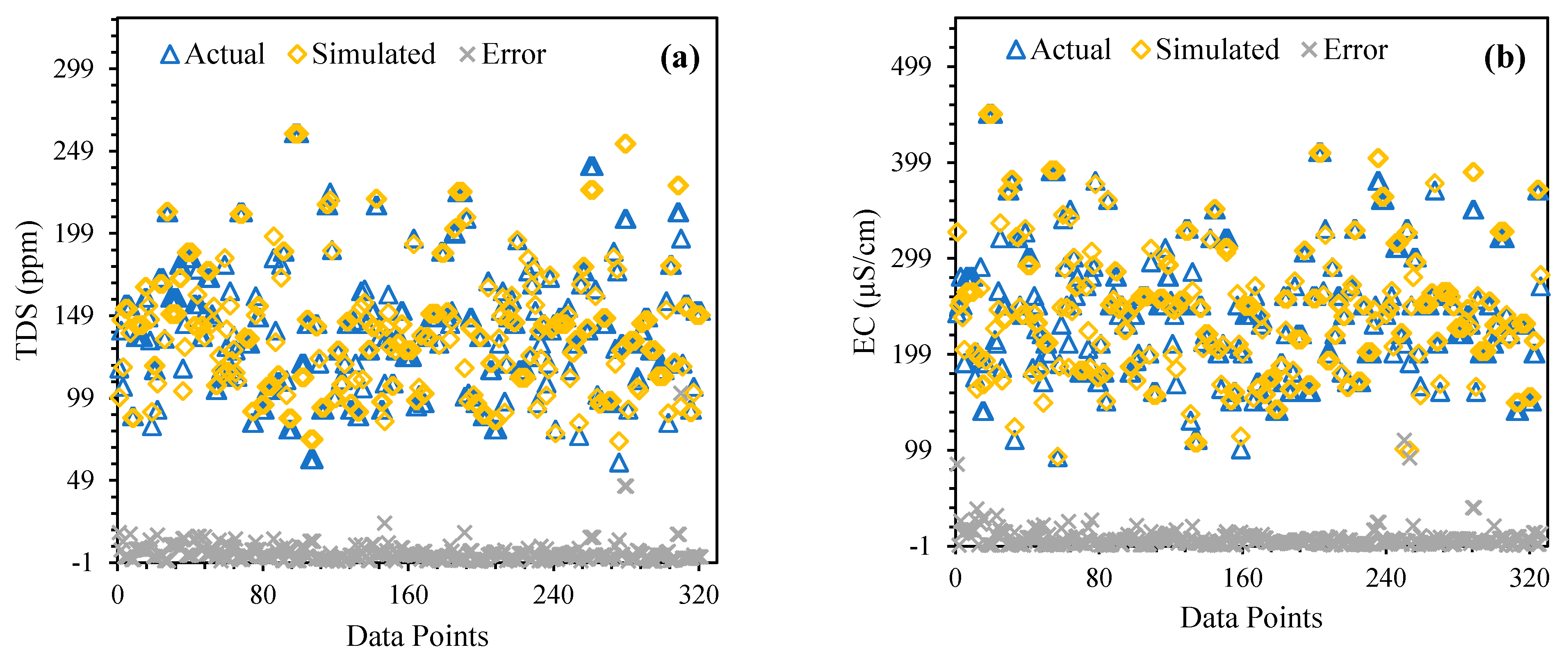{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Setting |
|---|---|
| Number of Chromosomes | 30 |
| Number of Genes | 4 |
| Head size | 10 |
| Gene size | 26 |
| Linking function | Addition |
| Function set | + , ̶ , × , ÷ , ^2 , 3√ |
| Mutation rate | 0.0138 |
| Inversion rate | 0.00546 |
| Constants per gene | 10 |
| Maximum complexity | 10 |
| Data type | Floating type |
| Lower bound | −10 |
| Upper bound | 10 |
| Parameter | Fitted Value | |
|---|---|---|
| TDS | EC | |
| Training dataset | 252 (70%) | 252 (70%) |
| Testing dataset | 108 (30%) | 108 (30%) |
| General | ||
| Network type | Feed forward neural network | |
| Data division | Random | |
| Number of hidden neurons | 10 | |
| Training algorithm | Levenberg-Marquardt | |
| Transfer function for hidden layer | TANSIG | |
| Transfer function for output layer | PURELIN | |
| Number of nonlinear parameters | 18 | |
| Number of epochs | 35 | |
| Learning rate | 0.01 | |
| Variable | Unit | Range | SD | Mean | Minimum | Maximum | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|
| INPUTS | ||||||||
| Calcium (Ca) | meq/L | 1.80 | 0.31 | 1.49 | 0.65 | 2.45 | 0.94 | 3.01 |
| Magnesium (Mg) | meq/L | 2.60 | 0.33 | 0.66 | 0.04 | 2.64 | 0.44 | 0.51 |
| Sodium (Na) | meq/L | 8.95 | 0.67 | 0.51 | 0.05 | 9.0 | 2.10 | 3.92 |
| Chloride (Cl) | meq/L | 4.15 | 0.20 | 0.27 | 0.05 | 4.2 | 1.43 | 3.15 |
| Sulphate (SO4) | meq/L | 3.11 | 0.34 | 0.51 | 0.1 | 3.2 | 0.83 | 0.55 |
| Bicarbonate (HCO3) | meq/L | 7.10 | 0.61 | 1.82 | 0.3 | 7.4 | 0.76 | 0.89 |
| PH | - | 1.22 | 0.65 | 7.83 | 7.08 | 8.3 | −0.47 | 0.23 |
| OUTPUTS | ||||||||
| TDS | ppm | 200 | 38.64 | 138.17 | 60 | 260 | 0.86 | 1.19 |
| EC | µS/cm | 358 | 67.49 | 244.65 | 92 | 450 | 0.71 | 0.91 |
| Parameters | Ca | Mg | Na | HCO3 | Cl | SO4 | PH | TDS |
|---|---|---|---|---|---|---|---|---|
| Ca | 1 | |||||||
| Mg | 0.0194 | 1 | ||||||
| Na | −0.0037 | 0.4712 | 1 | |||||
| HCO3 | 0.0363 | 0.5324 | 0.7414 | 1 | ||||
| Cl | 0.0239 | 0.5035 | 0.7041 | 0.5296 | 1 | |||
| SO4 | 0.0212 | 0.5415 | 0.4853 | 0.2749 | 0.3698 | 1 | ||
| PH | 0.0025 | 0.0737 | 0.0415 | 0.0545 | 0.0561 | −0.0445 | 1 | |
| TDS | 0.7452 | 0.7001 | 0.8629 | 0.8176 | 0.7411 | 0.6297 | 0.6210 | 1 |
| Parameters | Ca | Mg | Na | HCO3 | Cl | SO4 | PH | EC |
|---|---|---|---|---|---|---|---|---|
| Ca | 1 | |||||||
| Mg | 0.0194 | 1 | ||||||
| Na | −0.0037 | 0.4712 | 1 | |||||
| HCO3 | 0.0363 | 0.5324 | 0.7414 | 1 | ||||
| Cl | 0.0239 | 0.5035 | 0.7041 | 0.5296 | 1 | |||
| SO4 | 0.0212 | 0.5415 | 0.4853 | 0.2749 | 0.3698 | 1 | ||
| PH | 0.0025 | 0.0737 | 0.0415 | 0.0545 | 0.0561 | −0.0445 | 1 | |
| EC | 0.7539 | 0.8632 | 0.7672 | 0.8545 | 0.8951 | 0.7954 | 0.6202 | 1 |
| Output | Model | Training | Testing | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NSE | R2 | MAE | RMSE | NSE | R2 | MAE | RMSE | ||
| TDS | GEP | 0.96 | 0.96 | 6.58 | 7.10 | 0.99 | 0.99 | 1.38 | 1.57 |
| ANN | 0.95 | 0.94 | 4.80 | 6.37 | 0.85 | 0.88 | 5.50 | 13.1 | |
| LRM | 0.97 | 0.93 | 5.22 | 6.69 | 0.90 | 0.91 | 3.83 | 10.8 | |
| EC | GEP | 0.96 | 0.97 | 12.2 | 14.4 | 0.99 | 0.99 | 1.51 | 1.74 |
| ANN | 0.93 | 0.95 | 6.67 | 10.81 | 0.90 | 0.90 | 13.1 | 13.5 | |
| LRM | 0.95 | 0.92 | 11.93 | 16.37 | 0.94 | 0.92 | 11.0 | 26.70 | |
| S. No. | Equation | Criteria | Technique | Value | Suggested by |
|---|---|---|---|---|---|
| 1 | R > 0.8 | GEP | 0.96 | [60] | |
| ANN | 0.98 | ||||
| LRM | 0.97 | ||||
| 2 | 0.85 < k < 1.15 | GEP | 1.004 | [61] | |
| ANN | 0.997 | ||||
| L | 0.992 | ||||
| 3 | 0.85 < k′ < 1.15 | GEP | 0.995 | [61] | |
| ANN | 1.002 | ||||
| LRM | 1.007 | ||||
| 4 | Rm > 0.5 | GEP | 0.799 | [62] | |
| ANN | 0.820 | ||||
| LRM | 0.811 | ||||
| GEP | 0.999 | ||||
| ANN | 0.999 | ||||
| LRM | 099 | ||||
| GEP | 0.999 | ||||
| ANN | 0.999 | ||||
| LRM | 999 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, M.I.; Alaloul, W.S.; Alqahtani, A.; Aldrees, A.; Musarat, M.A.; Javed, M.F. Predictive Modeling Approach for Surface Water Quality: Development and Comparison of Machine Learning Models. Sustainability 2021, 13, 7515. https://doi.org/10.3390/su13147515
Shah MI, Alaloul WS, Alqahtani A, Aldrees A, Musarat MA, Javed MF. Predictive Modeling Approach for Surface Water Quality: Development and Comparison of Machine Learning Models. Sustainability. 2021; 13(14):7515. https://doi.org/10.3390/su13147515
Chicago/Turabian StyleShah, Muhammad Izhar, Wesam Salah Alaloul, Abdulaziz Alqahtani, Ali Aldrees, Muhammad Ali Musarat, and Muhammad Faisal Javed. 2021. "Predictive Modeling Approach for Surface Water Quality: Development and Comparison of Machine Learning Models" Sustainability 13, no. 14: 7515. https://doi.org/10.3390/su13147515
APA StyleShah, M. I., Alaloul, W. S., Alqahtani, A., Aldrees, A., Musarat, M. A., & Javed, M. F. (2021). Predictive Modeling Approach for Surface Water Quality: Development and Comparison of Machine Learning Models. Sustainability, 13(14), 7515. https://doi.org/10.3390/su13147515