2.1. Data
The reported diaries are taken from the
Mobilität in Deutschland (MiD, Mobility in Germany) time series report [
6]. This report is an adaptation of the MiD surveys of 2002 [
3], 2008 [
4] and 2017 [
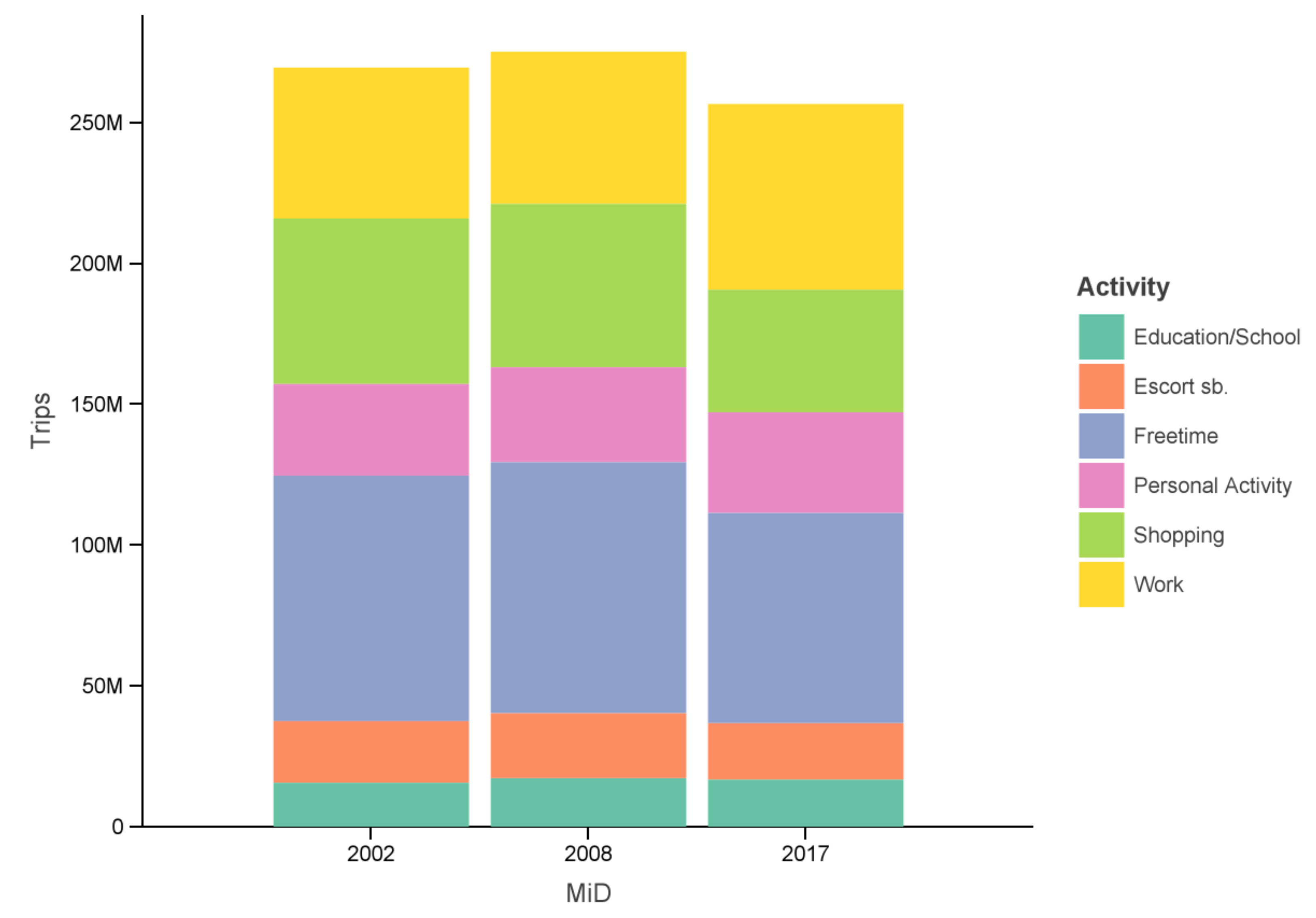
5] with data weight recalibration for better comparison. Some diaries were removed during preprocessing because of missing necessary information. The first two surveys were vastly smaller than the one from 2017 with the latter roughly five times bigger (see
Table 1).
Each detailed diary report
d consists of a set of trips
with
.
Table 2 presents exemplary data for two typical diaries in the MiD.
Out of the many attributes of each trip the following attributes are of major interest to our research: Person attributes, such as
For the filtering the dataset to investigate more specific cases, e.g., a typical work day in bigger cities:
Additionally, for categorizing the diaries we use
This gives us for each diary d:
A set of trips, we write for the trips ;
An activity of a trip
t is denoted by
a or
with
denotes the diary group of diary d; and
denotes the person group to which the reporting person of diary d belongs.
The set of diaries is denoted by D. is the set of diary groups and is the set of person groups. Where applicable, we write , , for the diary sets of the respective MiD survey or D and for diaries without specifying the year.
We used a synthetic population of Berlin with 3,604,320 citizens created by Synthesizer [
14]— an internal tool from the DLR Transport Research institute. The population is based on data from the
Mikrozensus 2015 [
15],
Zahlen–Daten–Fakten Berufliche Schulen from the Senatsverwaltung für Bildung, Jugend, Familie Berlin [
16], Nexiga Demography and Households 2017 [
17,
18],
Rentenatlas 2018 [
19], and
Statistisches Jahrbuch Berlin-Brandenburg [
20].
2.2. Synthetic Population and Weighting
There are two main reasons for changes in travel behavior (compare [
11]):
Changes in the population, i.e., increase in younger or older people, changes in employment etc.; and
Changes in individual travel behavior like working less, having more free time or e-commerce replacing some amount of shopping trips.
We want to remove the first reason from our consideration and only investigate the changes in individual travel behavior. For a better representation of the German population, the MiD assigns a weight to each diary according to the attributes of the reporting person. These weights correspond to the respective population of the years of the MiD survey (2002, 2008, and 2017). To remove the differences in trips and activities due to population changes, we give each MiD a new set of weights and ignore the weights from the MiD altogether. For the new weighting we use our synthetic population of Berlin with roughly 3.6 million people. Each person belongs to one of 34 person groups.
Figure 2 details the distribution of the person groups. The status like student, working or pupil defines the first split into several group segments. The numbers specify the age range, e.g., from 25 to under 45. The sex is stated by male or female. For groups where the gender is not of importance we write m/f or omit it entirely. “
W/(o) car” indicates the car ownership. Sex, age, and car attributes are omitted if it is not of significance for the person group, like pupils, students, and trainees. We decided on this group division by analyzing the available input data and forming homogeneous user groups of interest. The age classes are chosen to reflect certain periods of life, like first job (<25), young professionals (25–45), senior professionals (45–65), young retirees (65–75) and old retirees (>75). Doing so we had to meet two external constraints: The group size must not drop to less than 100 diaries. Separation between male and female is only necessary, if the frequency of activities in their diaries differ more than 1%.
One can immediately see the smaller share of unemployed people or the higher share of retired women compared to men. The attributes from
Section 2.1 are used to classify a person to a person group like students or working women between 45 and (excluding) 65 without a car. Therefore (as seen as in
Table 2), each diary
d is assigned to a person group. We write
or only
if it is obvious to which diary it refers to or if the diary is not of importance. For the weighting we considered two diary filters:
Filter 1 represents an average of the whole week over all regions but with the population distribution of Berlin. This may be no realistic image but suffices for research purposes. For Filter 1, we write the set of diaries as . Filter 2 models a typical workday in a metropolitan area. This case may be transferable to other larger cities in Germany, such as Hamburg, Munich or Cologne, but further attention to the respective population is needed. For Filter 2, we write .
To adapt the diaries we gave each diary
d with person group
a weight
depending on the filter. Because each diary within one person group and MiD set will have the same weight, we can write
. The weight of a specific person group
is defined as
where
is the shorthand notation of the number of people in person group
from the synthetic population.
D is a placeholder for
and
, where
.
is the number of people in Berlin.
denotes the cardinality of set
X as usual.
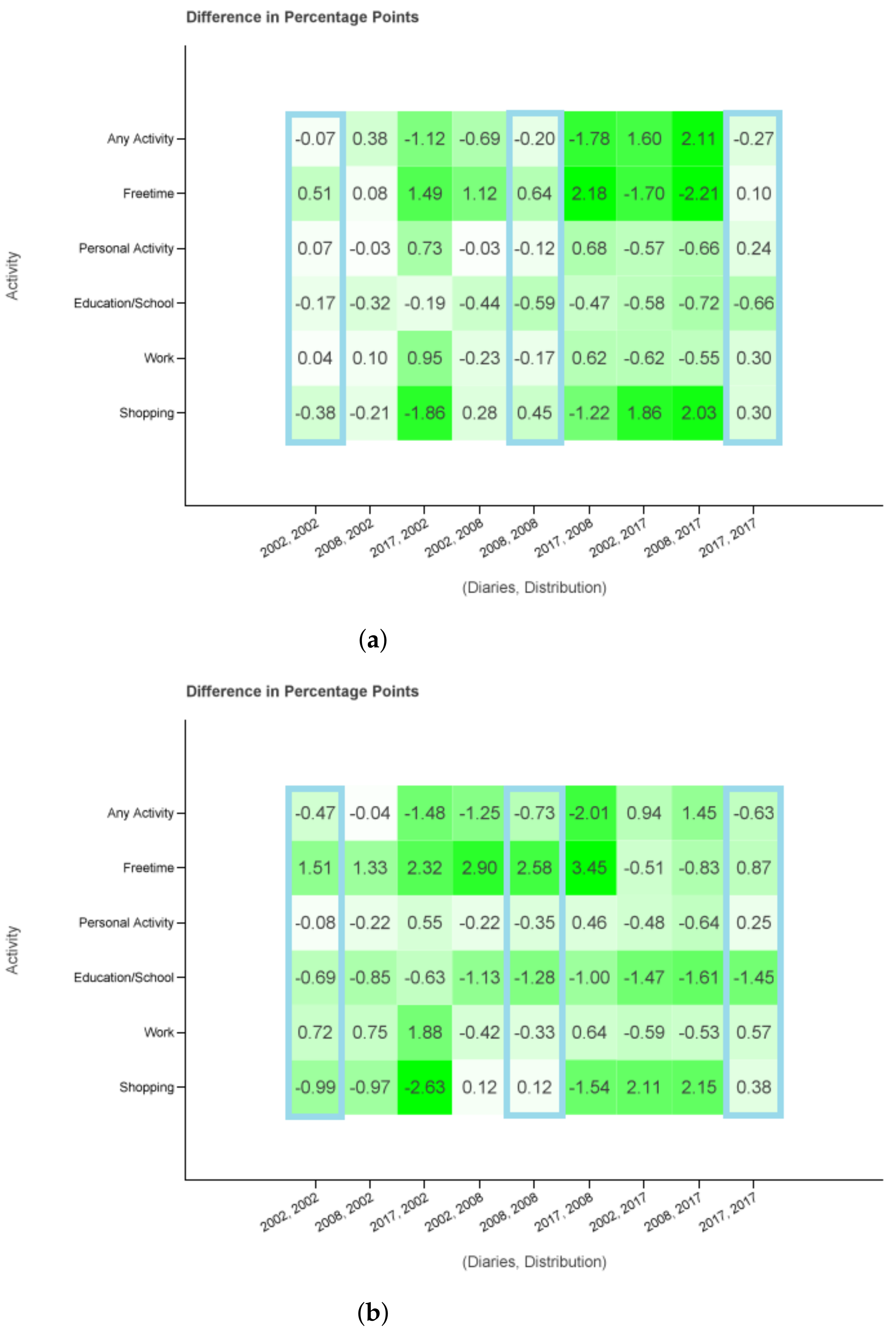
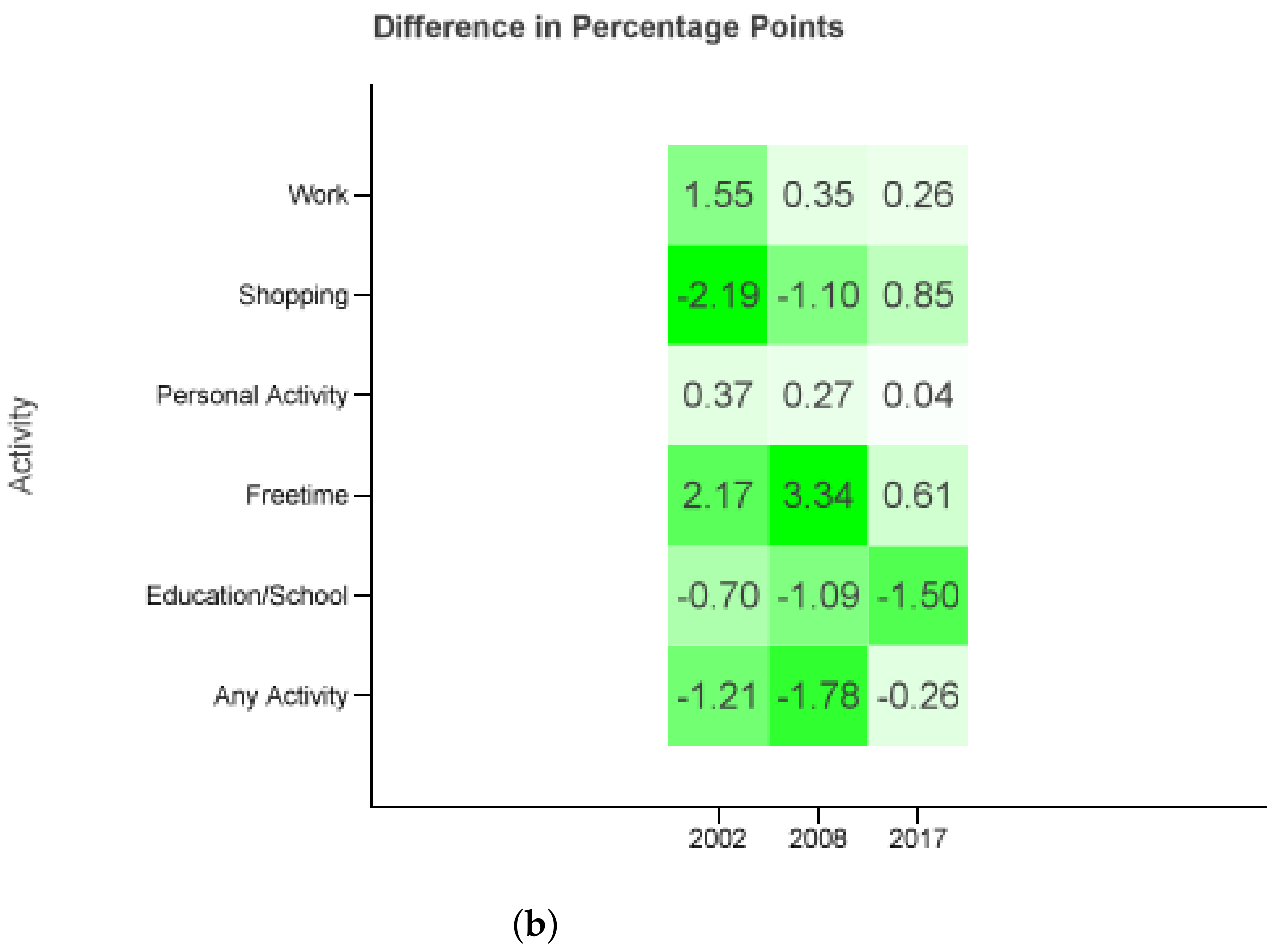
2.3. Diary Classes and Probability Distributions
For a microscopic agent-based simulation of the activity travel behavior of a population one could be satisfied with a single division into person groups. Each person (i.e., agent) takes a reported diary of its person group. This leads to problems due to a lack of reported diaries in specific person groups. For example the person group of non-working under 25-year-olds without a car reported only 39, 32, and 56 diaries in 2002, 2008, and 2017, respectively. This further decreases if someone wants to use the diaries of metropolitan regions during the middle week days to get an image of a typical work day in bigger cities like Berlin. In this case only 3, 5, and 6 diaries are reported respectively.
Because of this, we use diary groups which assign to each diary a specific group with a special commonality between all diaries within a group. Hertkorn et al. [
12,
13] uses sequence alignment and clustering algorithms to classify diary groups. We use a different and simpler classification of diary groups with a more straight forward way of assigning the diaries by its activities. We discuss the uncertainties of this approach later in
Section 4.
Table 3 presents the diary groups we used. Note that, despite escort trips defining some diary groups we will later conflate escort trips into any activity.
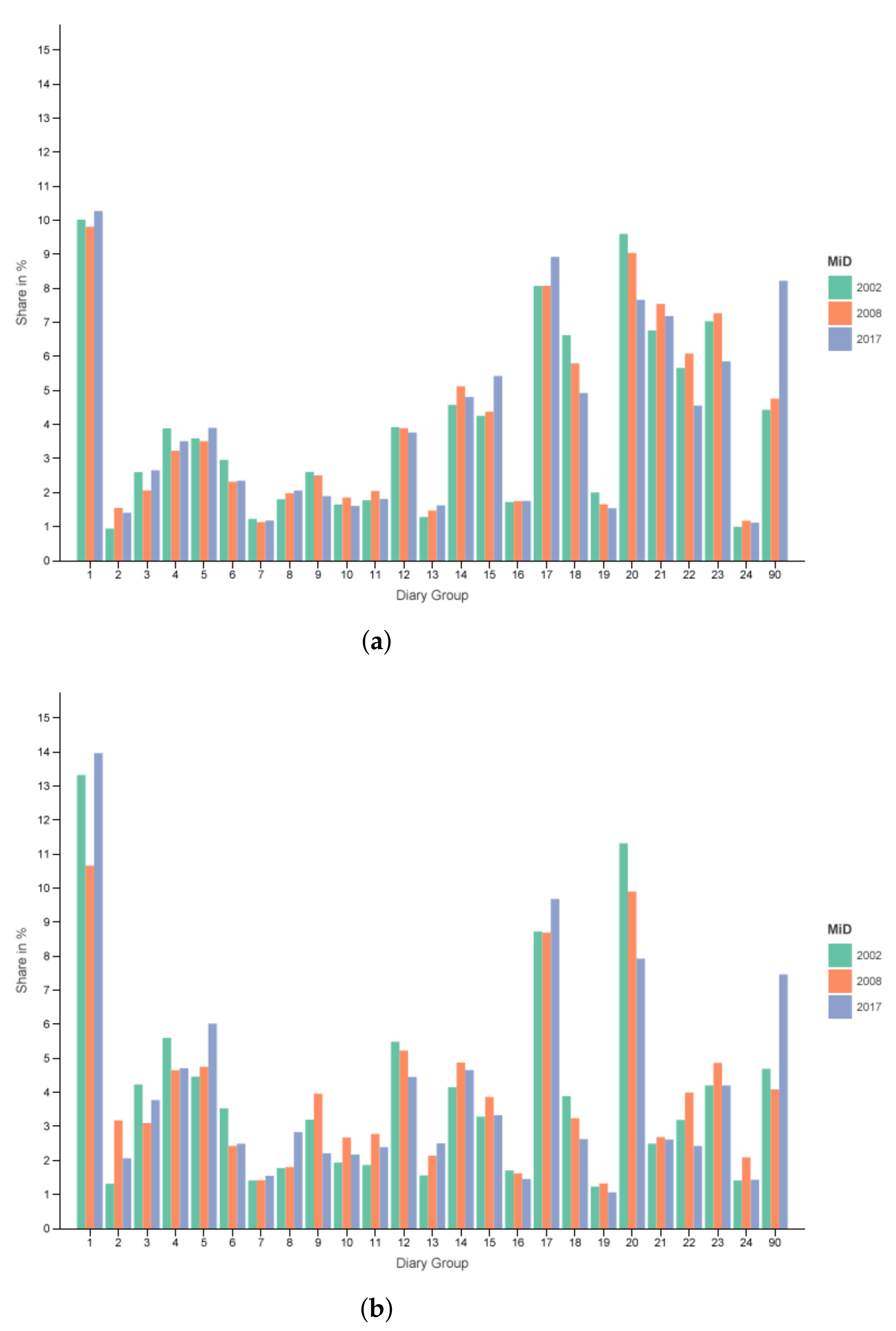
The distribution for all regions and all days can be seen in
Figure 3a and for metropolitan regions from Tuesday to Thursday in
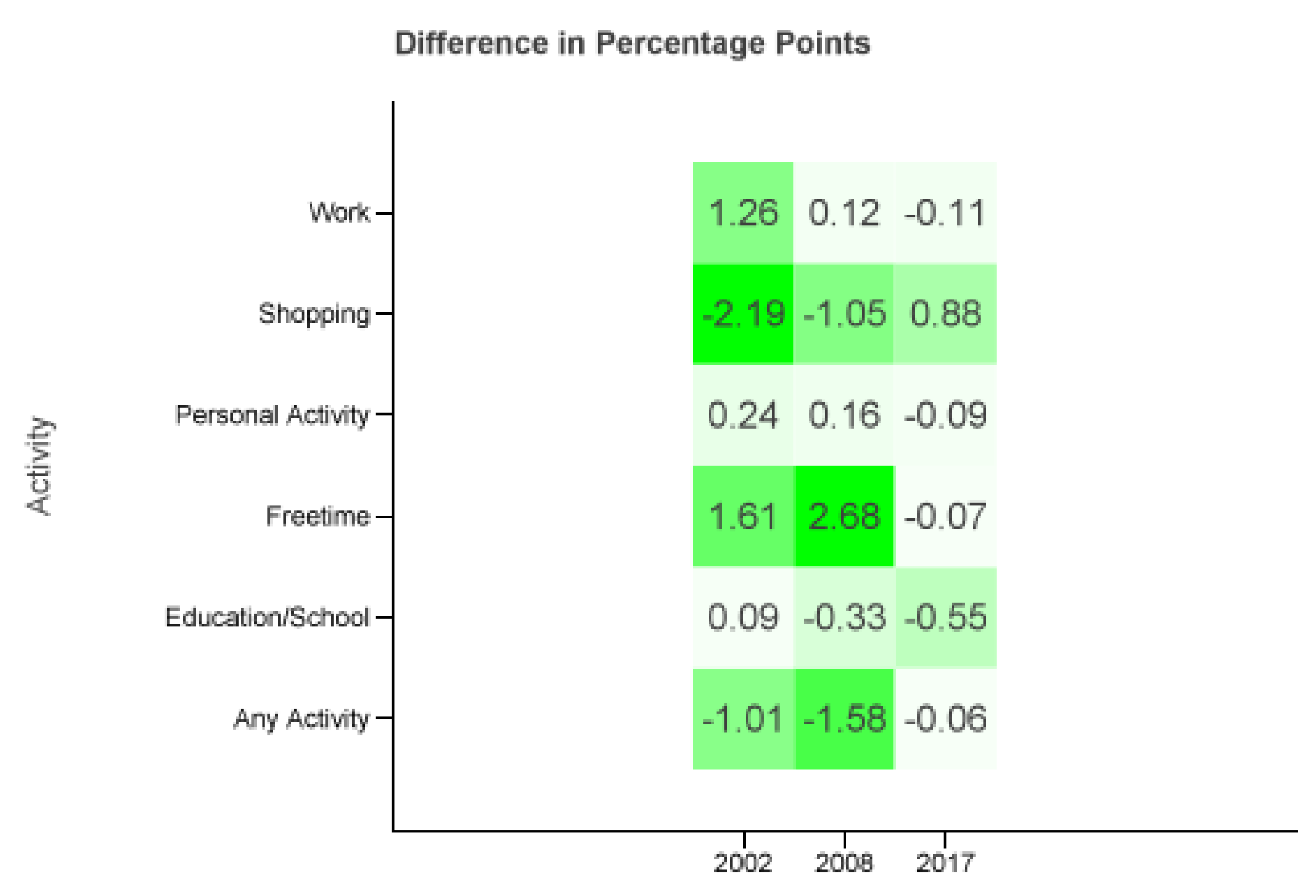
Figure 3b. One can see that share of working (1–10) and educational (11–13, 24) diaries is higher for the core weekdays. Furthermore, a drastic decrease in free time diaries of persons who (usually) work (21) or go to an educational institution (22) with a smaller reduction for non-working people (23) is visible when comparing the two filters.
Note that, the diary groups have in our case different priorities. The highest priorities are educational diaries for specific groups like children, pupils, students and trainees. Educational trips by working or non-working people—such as going to a language class in the evening—are of lowest priority. Other than that it goes roughly in the order of its numbering. The exceptions are
(1) which comes after (2), (3), (4), (5); and
(6) which comes after (7), (8), (9), (10)
For example if a diary of a student is reporting a trip to the university it will belong to diary group (11) no matter if the student is going to do its students job on the same day. Another example: If an employee is not going to work on the day of the report but goes shopping and to their yoga class (free time), the diary will belong to group (18), but not (21), because (18) has the higher priority over (21).
The purpose of these diary groups is to have a greater pool of available diaries for the person groups and introduce less homogeneity. Considering the example of a student, it may be the case that the student is going to the university and, hence, diary group (11) is chosen. Nevertheless, a student may behave on a single day like a typical full time worker and doing their 8-hour shift of their students job. In case of a full-time work day the person chooses a diary of group (1)–(5) or for part-time work group (6)–(10).
This leads to a probability distribution where
denotes the probability of a person in person group
choosing a diary in diary group
.
where
D is again a placeholder for
and
. Furthermore, we specifically write
and
. It holds
where
(
in our case) is the set of diary groups. For a person
p of group
, instead of only using the diaries belonging to the person group
this approach enables us to possibly assign any diary in the diary groups with
.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}