
Stacking Model for Optimizing Subjective Well-Being Predictions Based on the CGSS Database


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Construction of the Stacking Model
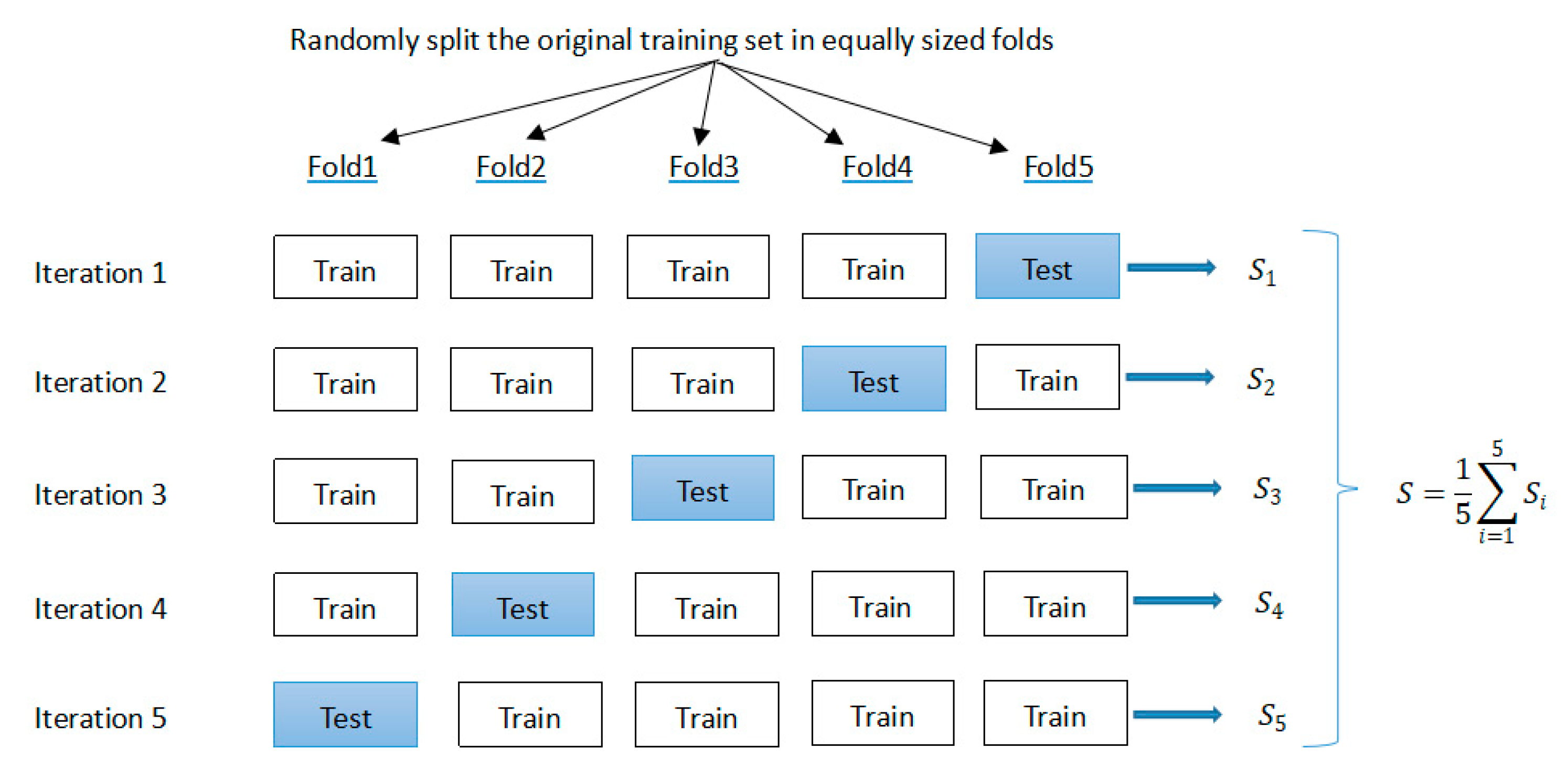
3.2. The Evaluation Index of a Model
- (1)
- Accuracy, precision, and F1 score. In the binary classification algorithm model, accuracy is the proportion of all accurate classifications to the number of all samples. Precision is the proportion of positive samples correctly predicted out of all samples predicted as positive. Recall is the proportion of positive samples correctly predicted out of all the positive samples. The F1 score is the harmonic average of precision and recall.
- (2)
- AUC (Area Under ROC Curve) value is a number that ranges from 0 to 1, which measures the area under the ROC (Receiver Operating Characteristic) curve. The higher the AUC value obtained, the better the classification model performs.
- (3)
- KS (Kolmogrov–Smirnov) value represents the ability of the model to segment samples. The greater the KS value is, the stronger the ability.
3.3. Datasets and Features
3.4. Empirical Process
4. Results
4.1. SWB Prediction Based on Single Models
4.1.1. LR
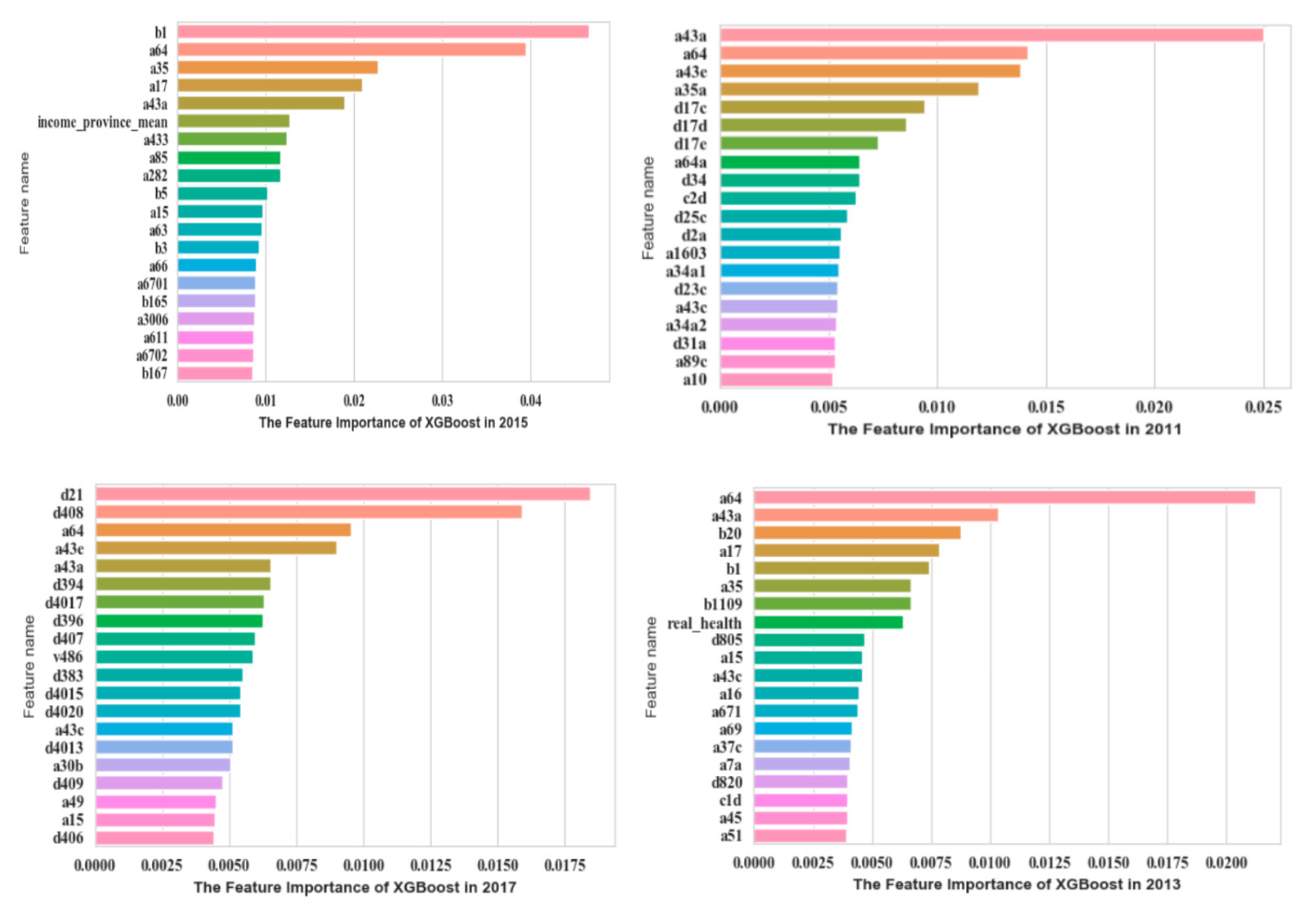
4.1.2. XGBoost
4.1.3. CatBoost
4.1.4. LightGBM
4.1.5. ANN
4.1.6. CNN
4.2. SWB Prediction Based on a Stacking Model
4.3. Statistical Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SWB | Subjective Well-Being |
| CGSS | Chinese General Social Survey |
| LR | Logistic Regression |
| SES | Socio-economic Status |
| SVM | Support Vector Machine |
| DT | Decision Tree |
| KNN | K-Nearest Neighbor |
| GBDT | Gradient Boosting Decision Tree |
| XGBoost | Extreme Gradient Boosting |
| LightGBM | Light Gradient Boosting Machine |
| Catboost | Category Boosting |
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural Network |
| MLR | Multiple Linear Regression |
| ROC | Receiver Operating Characteristic |
| AUC | Area Under ROC Curve |
| KS | Kolmogrov-Smirnov |
| BMI | Body Mass Index |
References
- Wilson, W.R. Correlates of avowed happiness. Psychol. Bull. 1967, 67, 294–306. [Google Scholar] [CrossRef]
- Diener, E. The Science of Well-Being; Springer: Dordrecht, The Netherlands, 2009. [Google Scholar] [CrossRef]
- Diener, E.; Suh, E.M.; Lucas, R.E.; Smith, H.L. Subjective well-being: Three decades of progress. Psychol. Bull. 1999, 125, 276–302. [Google Scholar] [CrossRef]
- Diener, E.; Oishi, S.; Tay, L. Advances in subjective well-being research. Nat. Hum. Behav. 2018, 2, 253–260. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Cheng, C.; Zhang, K. Income Gap, Housing Property Rights and the Urban Residents’ Happiness: Based on Empirical Research of CGSS2003 and CGSS2013. Northwest Popul. J. 2018, 39, 11–29. (In Chinese) [Google Scholar]
- Ferrer-I-Carbonell, A.; Gowdy, J.M. Environmental degradation and happiness. Ecol. Econ. 2007, 60, 509–516. [Google Scholar] [CrossRef]
- Zhang, N.; Liu, C.; Chen, Z.; An, L.; Ren, D.; Yuan, F.; Yuan, R.; Ji, L.; Bi, Y.; Guo, Z.; et al. Prediction of adolescent subjective well-being: A machine learning approach. Gen. Psychiatry 2019, 32, e100096. [Google Scholar] [CrossRef] [PubMed]
- Chinese National Survey Data Archive. Available online: http://cnsda.ruc.edu.cn/index.php?r=site/datarecommendation (accessed on 4 January 2021).
- Voukelatou, V.; Gabrielli, L.; Miliou, I.; Cresci, S.; Sharma, R.; Tesconi, M.; Pappalardo, L. Measuring objective and subjective well-being: Dimensions and data sources. Int. J. Data Sci. Anal. 2020, 11, 279–309. [Google Scholar] [CrossRef]
- Veenhoven, R. Happiness: Also Known as “Life Satisfaction” and “Subjective Well-Being”. In Handbook of Social Indicators and Quality of Life Research; Land, K., Michalos, A., Sirgy, M., Eds.; Springer: Dordrecht, The Netherlands, 2012. [Google Scholar] [CrossRef] [Green Version]
- Shi, H.; Yi, M. Environmental Governance, High-quality Development and Residents’ Happiness—Empirical Study Based on CGSS (2015) Micro Survey Data. Manag. Rev. 2020, 32, 18–33. (In Chinese) [Google Scholar]
- Pan, H.; Chen, H. Empirical Research on the Effect Mechanism of Ecological Environment on Residents’ Happiness in China. Chin. J. Environ. Manag. 2021, 13, 156–161, 148. (In Chinese) [Google Scholar]
- Clark, A.E.; Frijters, P.; Shields, M.A. Relative Income, Happiness, and Utility: An Explanation for the Easterlin Paradox and Other Puzzles. J. Econ. Lit. 2008, 46, 95–144. [Google Scholar] [CrossRef] [Green Version]
- Esping-Andersen, G.; Nedoluzhko, L. Inequality equilibria and individual well-being. Soc. Sci. Res. 2017, 62, 24–28. [Google Scholar] [CrossRef]
- Johnson, W.; Krueger, R.F. How money buys happiness: Genetic and environmental processes linking finances and life satisfaction. J. Pers. Soc. Psychol. 2006, 90, 680–691. [Google Scholar] [CrossRef]
- Tan, J.J.X.; Kraus, M.W.; Carpenter, N.C.; Adler, N.E. The association between objective and subjective socioeconomic status and subjective well-being: A meta-analytic review. Psychol. Bull. 2020, 146, 970–1020. [Google Scholar] [CrossRef]
- Molina, M.; Garip, F. Machine Learning for Sociology. Annu. Rev. Sociol. 2019, 45, 27–45. [Google Scholar] [CrossRef] [Green Version]
- Samuel, A.L. Some Studies in Machine Learning Using the Game of Checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Saputri, T.R.D.; Lee, S.-W. A Study of Cross-National Differences in Happiness Factors Using Machine Learning Approach. Int. J. Softw. Eng. Knowl. Eng. 2015, 25, 1699–1702. [Google Scholar] [CrossRef]
- Jaques, N.; Taylor, S.; Azaria, A.; Ghandeharioun, A.; Sano, A.; Picard, R. Predicting students’ happiness from physiology, phone, mobility, and behavioral data. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 222–228. [Google Scholar] [CrossRef] [Green Version]
- Marinucci, A.; Kraska, J.; Costello, S. Recreating the Relationship between Subjective Wellbeing and Personality Using Machine Learning: An Investigation into Facebook Online Behaviours. Big Data Cogn. Comput. 2018, 2, 29. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. Ensemble Methods in Machine Learning; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.L.; Wu, D.P. An imbalanced data classification method based on probability threshold Bagging. Comput. Eng. Sci. 2019, 41, 1086–1094. (In Chinese) [Google Scholar]
- Tuysuzoglu, G.; Birant, D. Enhanced Bagging (eBagging): A Novel Approach for Ensemble Learning. Int. Arab. J. Inf. Technol. 2019, 17, 515–528. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 6639–6649. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Ting, K.M.; Witten, I. Issues in Stacked Generalization. J. Artif. Intell. Res. 1999, 10, 271–289. [Google Scholar] [CrossRef] [Green Version]
- Sigletos, G.; Paliouras, G.; Spyropoulos, C.D.; Hatzopoulos, M. Combining Information Extraction Systems Using Voting and Stacked Generalization. J. Mach. Learn. Res. 2005, 6, 1751–1782. [Google Scholar]
- Cao, Z.; Yu, D.; Shi, J.; Zong, S. The Two-layer Classifier Model and its Application to Personal Credit Assessment. Control. Eng. China 2019, 26, 2231–2234. (In Chinese) [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biol. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Egilmez, G.; Erdil, N.; Arani, O.M.; Vahid, M. Application of artificial neural networks to assess student happiness. Int. J. Appl. Decis. Sci. 2019, 12, 115. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2020, 17, 168–192. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W. A Comparative Performance Assessment of Ensemble Learning for Credit Scoring. Mathematics 2020, 8, 1756. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Class | Name | Description | Measures |
|---|---|---|---|
| Time Feature | Age | survey time-birth | =0 if 18 ≤ age ≤ 29 =7 if 86 ≤ age ≤ 95 |
| Income Features | National income level | Classifying the variable a8a (personal annual income) according to the national per-capita income | =1 if a8a ≥ the national per-capita income =0 otherwise |
| Provincial income level | Comparing a8a (personal annual income) with per-capita income in the province | =1 if a8a ≥ per-capita income in the province =0 otherwise | |
| Financial Features | income_diff (The difference between family income and individual income) | Variable a62 (annual household income)-variable a8a (personal annual income) | |
| income_debt (personal burden) | Divided according to the variable income_diff (the difference between personal income and household income) | =1 if income_diff > 0, indicating that there is debt. =0 otherwise, means there is no debt. | |
| income_percent (the proportion of personal income in household income) | Variable a8a (personal annual income)/variable a62 (family annual income) | ||
| much_stress (personal financial burden) | Divided according to the variable income_percent (the proportion of personal income in household income) | =1 if income_percent ≥ 0.8, it means the burden is heavier. =0 otherwise, indicating that the burden is acceptable. | |
| Health Features | BMI group (Body Mass Index type) | According to WHO standards, | =1 if 20 ≤ BMI ≤ 25, which means healthy. =0 otherwise, indicating unhealthy. |
| real health (real health condition) | Divided according to the variable a15 (health condition) | =1 if a15 ≥ 4, which means healthy. =0 otherwise, indicating unhealthy. | |
| Social security Features | basic social security | Divided according to variable a611, a612 (social security participation) | =1 if a611&a612 = 1, indicating that there is basic social security. =0 otherwise, which means that there is no basic social security. |
| commercial insurance | Divided according to variable a613, a614 (participation in commercial insurance) | =1 if a613, a614 = 1, which means there is commercial insurance. =0 otherwise, which means there is no commercial insurance. | |
| Other Features | area_per | Variable a11 (floor area)/variable a63 (family members) |
| LR | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| Accuracy | 0.7450 | 0.7541 | 0.8167 | 0.7395 |
| Precision | 0.7708 | 0.7500 | 0.8153 | 0.7325 |
| F1_score | 0.7437 | 0.7531 | 0.8232 | 0.7401 |
| AUC | 0.7458 | 0.7542 | 0.8163 | 0.7397 |
| KS | 0.5075 | 0.5115 | 0.6333 | 0.4958 |
| XGBoost | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| Accuracy | 0.7600 | 0.7958 | 0.8300 | 0.7916 |
| Precision | 0.7723 | 0.7800 | 0.8503 | 0.7695 |
| F1_score | 0.7647 | 0.7991 | 0.8306 | 0.7976 |
| AUC | 0.8561 | 0.8608 | 0.8971 | 0.8584 |
| KS | 0.5493 | 0.6008 | 0.6826 | 0.5968 |
| CatBoost | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| Accuracy | 0.7650 | 0.7500 | 0.8000 | 0.7563 |
| Precision | 0.7800 | 0.7500 | 0.8133 | 0.7300 |
| F1_score | 0.7685 | 0.7468 | 0.8026 | 0.7665 |
| AUC | 0.8478 | 0.8341 | 0.8754 | 0.8289 |
| KS | 0.5499 | 0.5258 | 0.6300 | 0.5288 |
| LightGBM | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| Accuracy | 0.7850 | 0.7854 | 0.8200 | 0.7875 |
| Precision | 0.8333 | 0.7824 | 0.8289 | 0.7742 |
| F1_score | 0.7772 | 0.7841 | 0.8235 | 0.7901 |
| AUC | 0.8587 | 0.8441 | 0.8845 | 0.8645 |
| KS | 0.5893 | 0.5797 | 0.6833 | 0.5802 |
| ANN | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| Accuracy | 0.7500 | 0.7792 | 0.7933 | 0.7729 |
| Precision | 0.7572 | 0.7598 | 0.7840 | 0.7529 |
| F1_score | 0.7573 | 0.7846 | 0.8038 | 0.7789 |
| AUC | 0.8186 | 0.8413 | 0.8482 | 0.8446 |
| KS | 0.5190 | 0.5810 | 0.5990 | 0.5826 |
| CNN | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| Accuracy | 0.7500 | 0.7271 | 0.8433 | 0.7750 |
| Precision | 0.7789 | 0.7098 | 0.8452 | 0.7826 |
| F1_score | 0.7475 | 0.7342 | 0.8479 | 0.7692 |
| AUC | 0.8263 | 0.8338 | 0.8989 | 0.8438 |
| KS | 0.5044 | 0.4987 | 0.6928 | 0.5711 |
| Model/Year | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| LR | 0.7458 | 0.7542 | 0.8163 | 0.7397 |
| XGBoost | 0.8561 | 0.8608 | 0.8971 | 0.8584 |
| CatBoost | 0.8478 | 0.8341 | 0.8754 | 0.8289 |
| LightGBM | 0.8587 | 0.8441 | 0.8845 | 0.8645 |
| ANN | 0.8186 | 0.8413 | 0.8482 | 0.8446 |
| CNN | 0.8263 | 0.8338 | 0.8989 | 0.8438 |
| Stacking model (Meta model: LightGBM) | 0.8675 | 0.8957 | 0.9154 | 0.8913 |
| Model/Year | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| LR | 1.3886 | 2.1804 | 2.9632 | 3.3175 |
| XGBoost | 18.3136 | 12.8114 | 16.7020 | 22.7456 |
| CatBoost | 5.0844 | 7.9637 | 12.4173 | 14.4290 |
| LightGBM | 3.2126 | 4.7697 | 3.5627 | 5.3835 |
| ANN | 6.5451 | 8.1510 | 6.1897 | 10.1718 |
| CNN | 20.2413 | 18.3413 | 22.2424 | 24.3242 |
| Stacking model (Meta model: LightGBM) | 7.8618 | 8.4403 | 8.9045 | 9.4586 |
| Meta Model/Year | 2011 | 2013 | 2015 | 2017 |
|---|---|---|---|---|
| XGBoost | 0.8618 | 0.8632 | 0.9045 | 0.8631 |
| LR | 0.8066 | 0.8197 | 0.8842 | 0.8227 |
| LightGBM | 0.8675 | 0.8957 | 0.9154 | 0.8913 |
| CatBoost | 0.8634 | 0.8967 | 0.9049 | 0.8896 |
| ANN | 0.7962 | 0.8133 | 0.8567 | 0.8303 |
| Year | Features | Description |
|---|---|---|
| 2011 | a35a | Fairness of current living standards compared with your efforts |
| d34 | The degree of life freedom | |
| d17 | Frequency of depression in the past four weeks | |
| a8a | Personal annual income in 2010 | |
| a64a | Changes in family economic status in the past 5 years | |
| a43e | Self-perceived social class compared to contemporaries | |
| 2013 | a35 | Self-perceived social equity |
| a43a | Self-perceived social class at present | |
| a11 | The building area of the respondent’s current house | |
| income_ percent | The proportion of respondents’ personal income in household income | |
| a8a | Personal annual income in 2010 | |
| b119 | The situation where the respondent considers their life to be comfortable and at ease | |
| a17 | Frequency of depression in the past four weeks | |
| 2015 | a35 | Self-perceived social equity |
| b16-5 | Respondents’ satisfaction with employment | |
| 2017 | a43c | Self-perceived social class in 10 years |
| a31b | Frequency of social entertainment with friends | |
| a43a | Self-perceived social class at present | |
| d21 | Satisfaction with current living conditions | |
| d407 | Self-sufficiency compared with people around | |
| d4017 | Discontentment compared with people around |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ke, N.; Shi, G.; Zhou, Y. Stacking Model for Optimizing Subjective Well-Being Predictions Based on the CGSS Database. Sustainability 2021, 13, 11833. https://doi.org/10.3390/su132111833
Ke N, Shi G, Zhou Y. Stacking Model for Optimizing Subjective Well-Being Predictions Based on the CGSS Database. Sustainability. 2021; 13(21):11833. https://doi.org/10.3390/su132111833
Chicago/Turabian StyleKe, Na, Guoqing Shi, and Ying Zhou. 2021. "Stacking Model for Optimizing Subjective Well-Being Predictions Based on the CGSS Database" Sustainability 13, no. 21: 11833. https://doi.org/10.3390/su132111833
APA StyleKe, N., Shi, G., & Zhou, Y. (2021). Stacking Model for Optimizing Subjective Well-Being Predictions Based on the CGSS Database. Sustainability, 13(21), 11833. https://doi.org/10.3390/su132111833