
Chaining Optimization Methodology: A New SHA-3 Implementation on Low-End Microcontrollers



Abstract
:1. Introduction
1.1. The Contribution of This Paper Is as Follows:
- Proposing an efficient reduced memory access method for Fast SHA-3 implementationIn this article, we analyze the SHA-3 algorithm in detail from an implementation point of view. We propose a new method to reduce memory access to the internal state of SHA-3 by calculating the number of memory accesses and analyzing the characteristics of each process while the f-function is operating. Our technique of combining the three processes performs the f-function efficiently without breaking the security of SHA-3. Moreover, our method is a generic method that can be applied to low and high-end processors such as 8-bit AVR, 32-bit ARM, CPU, and GPGPU.
- Presenting chaining optimization methodology on 8-bit AVR MCUsWe present a new SHA-3 implementation methodology called the chaining optimization methodology. Through the chaining optimization methodology, the , , and processes of f-function are combined into one, and, by using this, the memory access to the internal state of SHA-3 is reduced to the maximum. Based on the chaining optimization methodology, our SHA-3 software implements the process implicitly using registers efficiently. This shows a performance improvement of up to 26.1% over the previous best implementation. In addition, our software achieves the fastest performance in an 8-bit AVR microcontroller as far as we know.
- Presenting optimized Hash_DRBG on 8-bit AVR environmentWe prove the applicability of our SHA-3 software by using Hash_DRBG in an 8-bit AVR MCUs. In addition, we propose an optimized implementation of Hash_DRBG to reduce the performance gap with the existing SHA-2 implementation in the AVR environment. three operations are omitted from the first loop of the f-function through the input data used repeatedly in the derivation function of Hash_DRBG. The proposed lookup table is only 160 bytes and has the advantage that it can be created during SHA-3 operation. By using this, the proposed Hash_DRBG implementation achieves the fastest performance among Hash_DRBG using SHA-3.
1.2. Hash Function for Service Sustainability in Embedded Systems
1.3. Extended Version of ICISC’20
2. Background
2.1. Overview of SHA-3
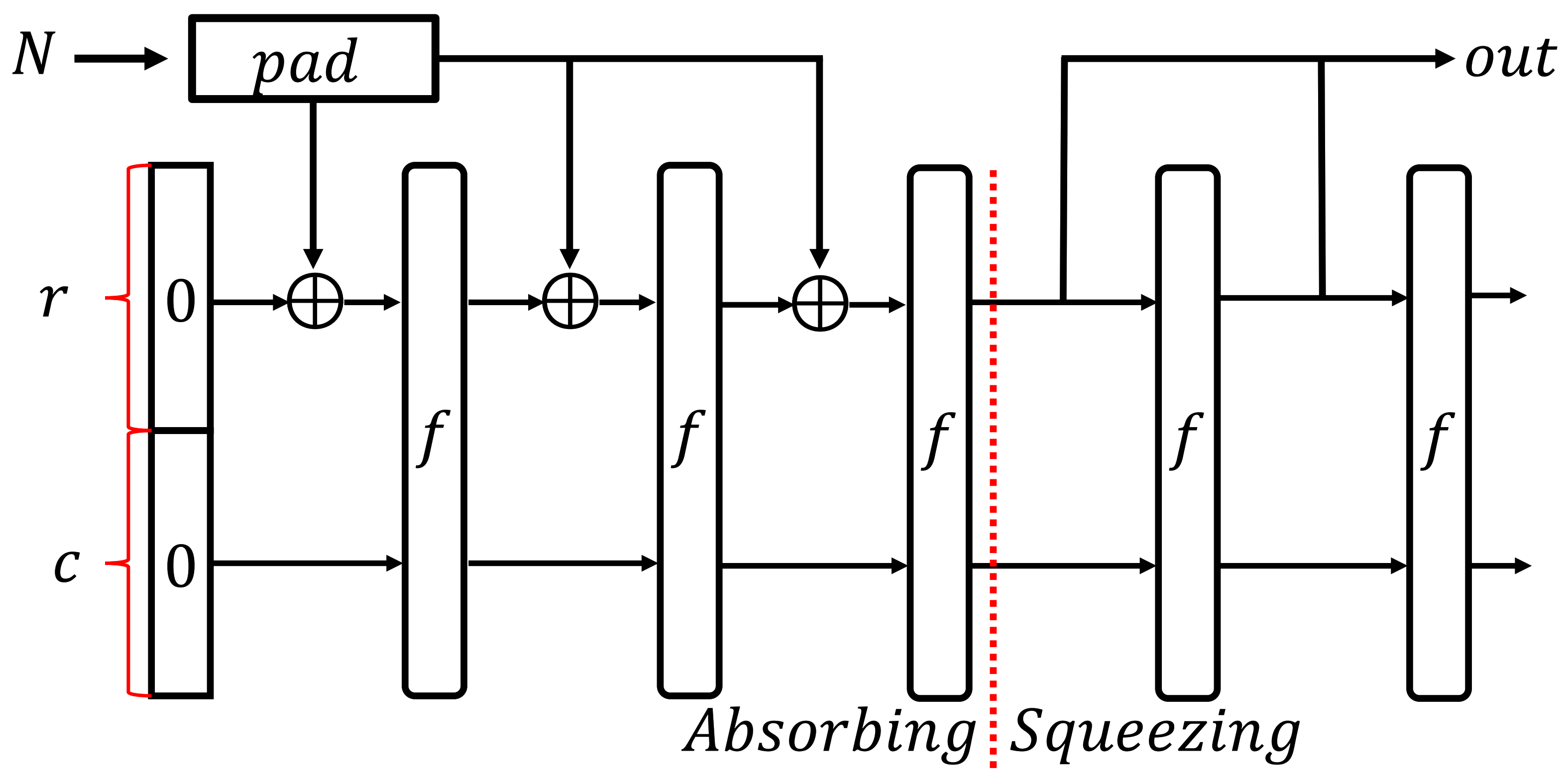
2.1.1. Sponge Structure
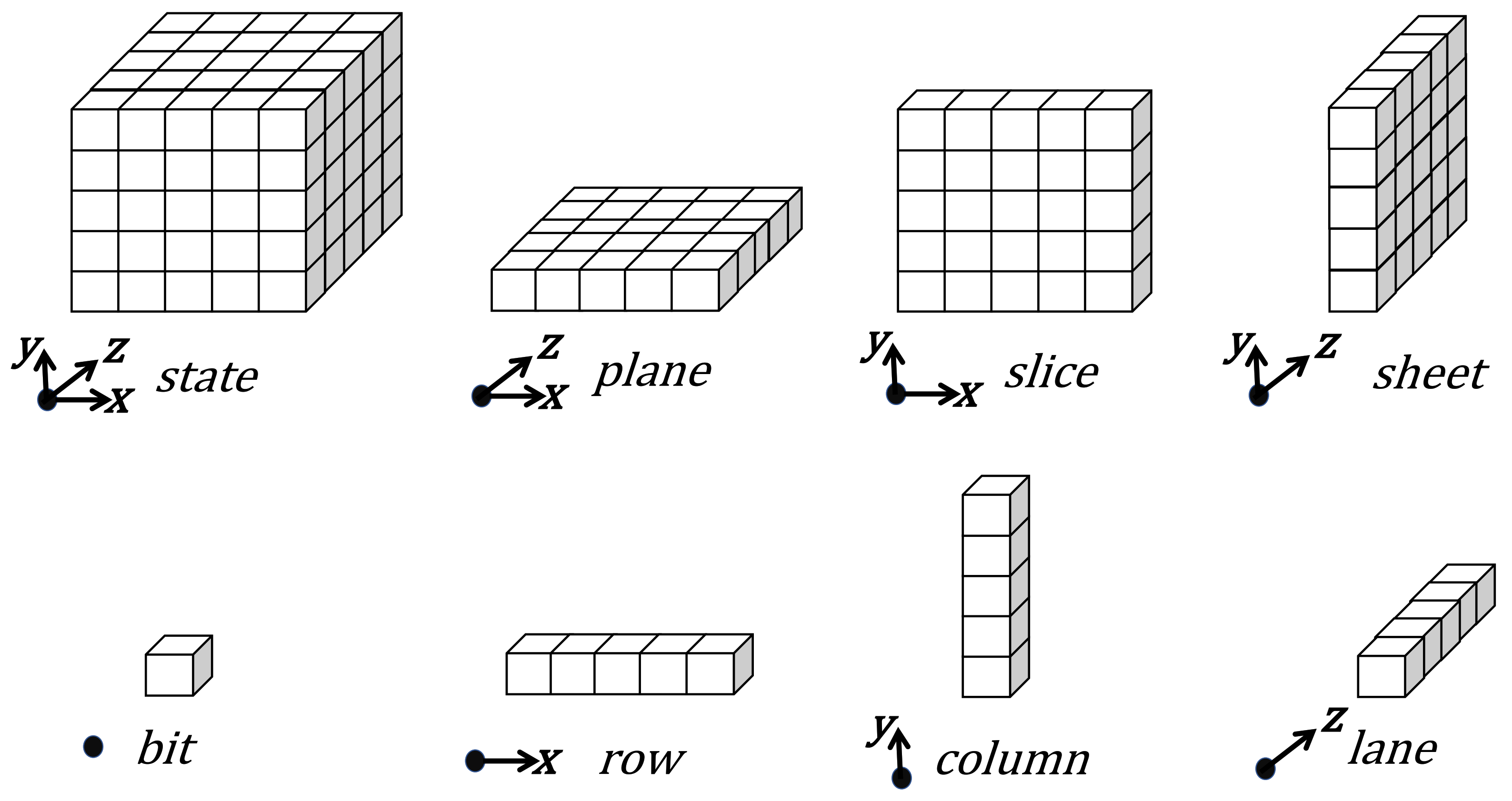
2.1.2. State of SHA-3
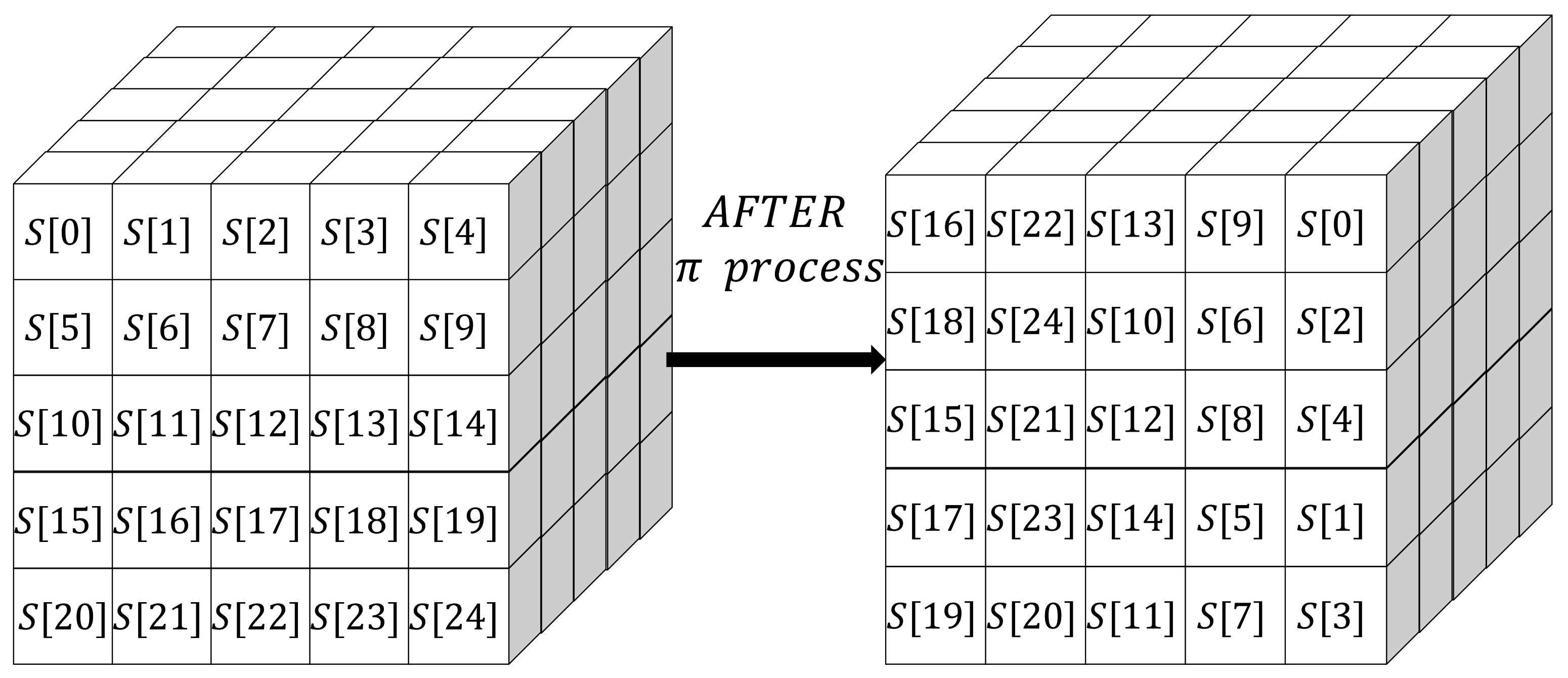
2.1.3. f-Function
| Algorithm 1 Process [12] |
| Require: state A |
| Ensure: state |
| 1: For all pairs(x, z) such that 0 ≤ x < 5 and 0 ≤ z < w |
| C[x, z] = A[x, 0, z] ⊕A[x, 1, z] ⊕A[x, 2, z] ⊕A[x, 3, z] ⊕A[x, 4, z]; |
| 2: For all pairs(x, z) such that 0 ≤ x < 5 and 0 ≤ z < w |
| //This step is initial |
| D[x, z] = C[(x - 1) 5, z] ⊕C[(x + 1) 5, (z − 1) w]; |
| 3: For all triples(x, y, z) such that 0 ≤ x, y < 5 and 0 ≤ z < w |
| [x, y, z] = A[x, y, z] ⊕D[x, z]; |
| 4: return |
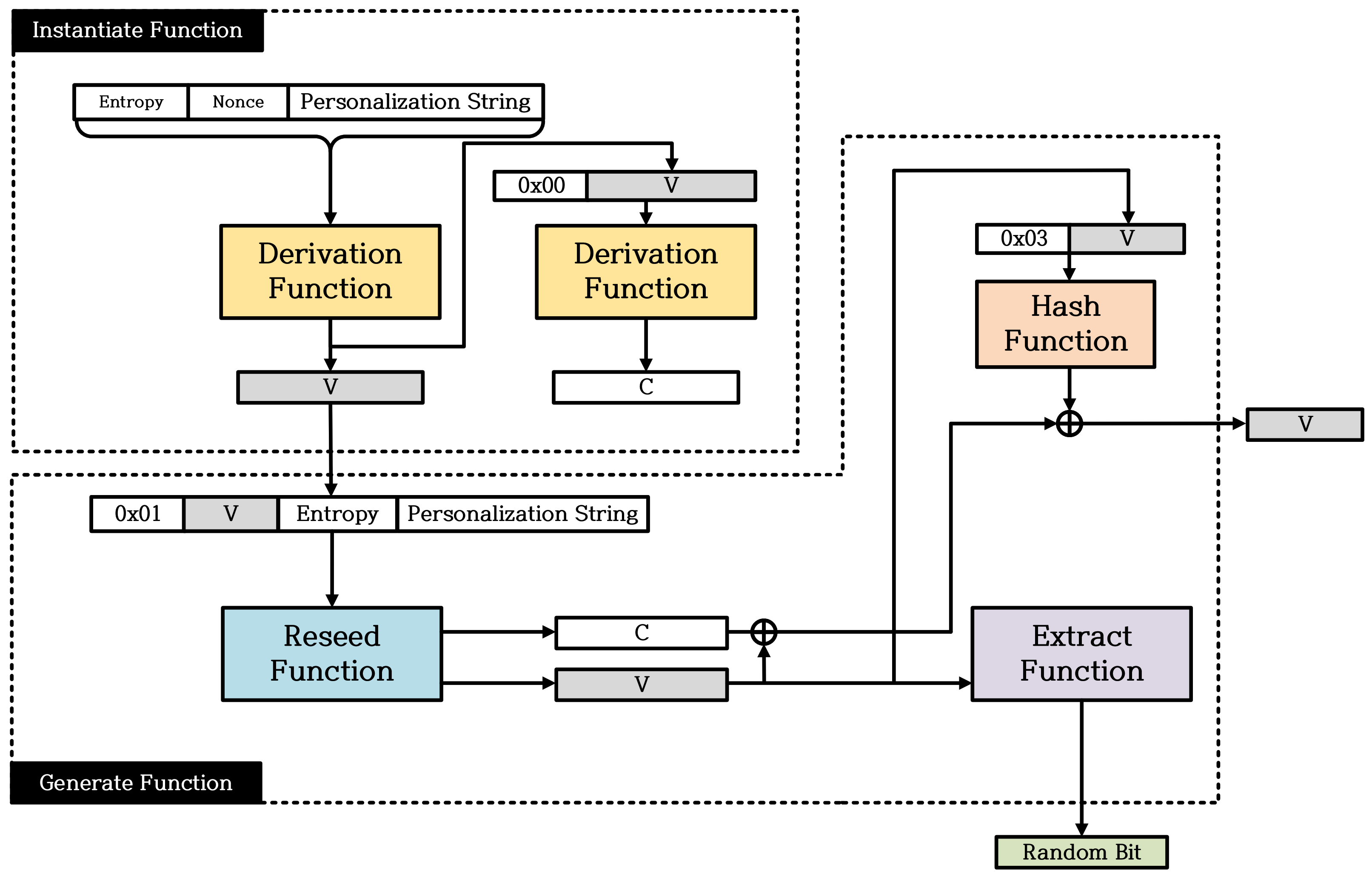
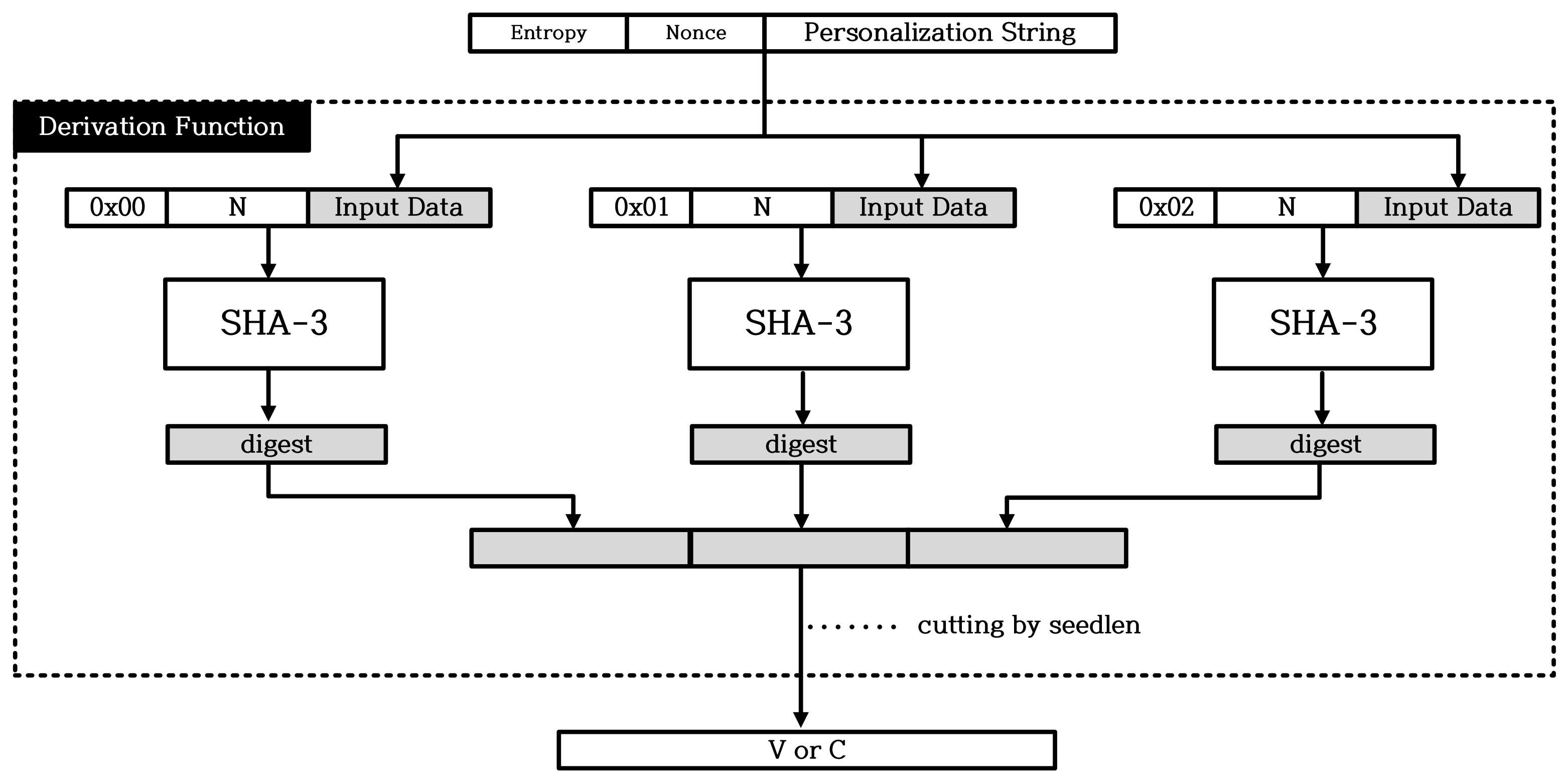
2.2. Overview of Hash_DRBG
2.3. Overview of 8-Bit AVR MCUs
3. Analysis of Previous Hash Softwares on 8-Bit AVR Microcontrollers
3.1. Related Works of SHA-3 Implementation on 8-Bit AVR Environment
3.2. Related Works of DRBG Implementation on 8-Bit AVR Environment
4. Proposed Technique for Efficient SHA-3 Implementations in 8-Bit AVR MCUs
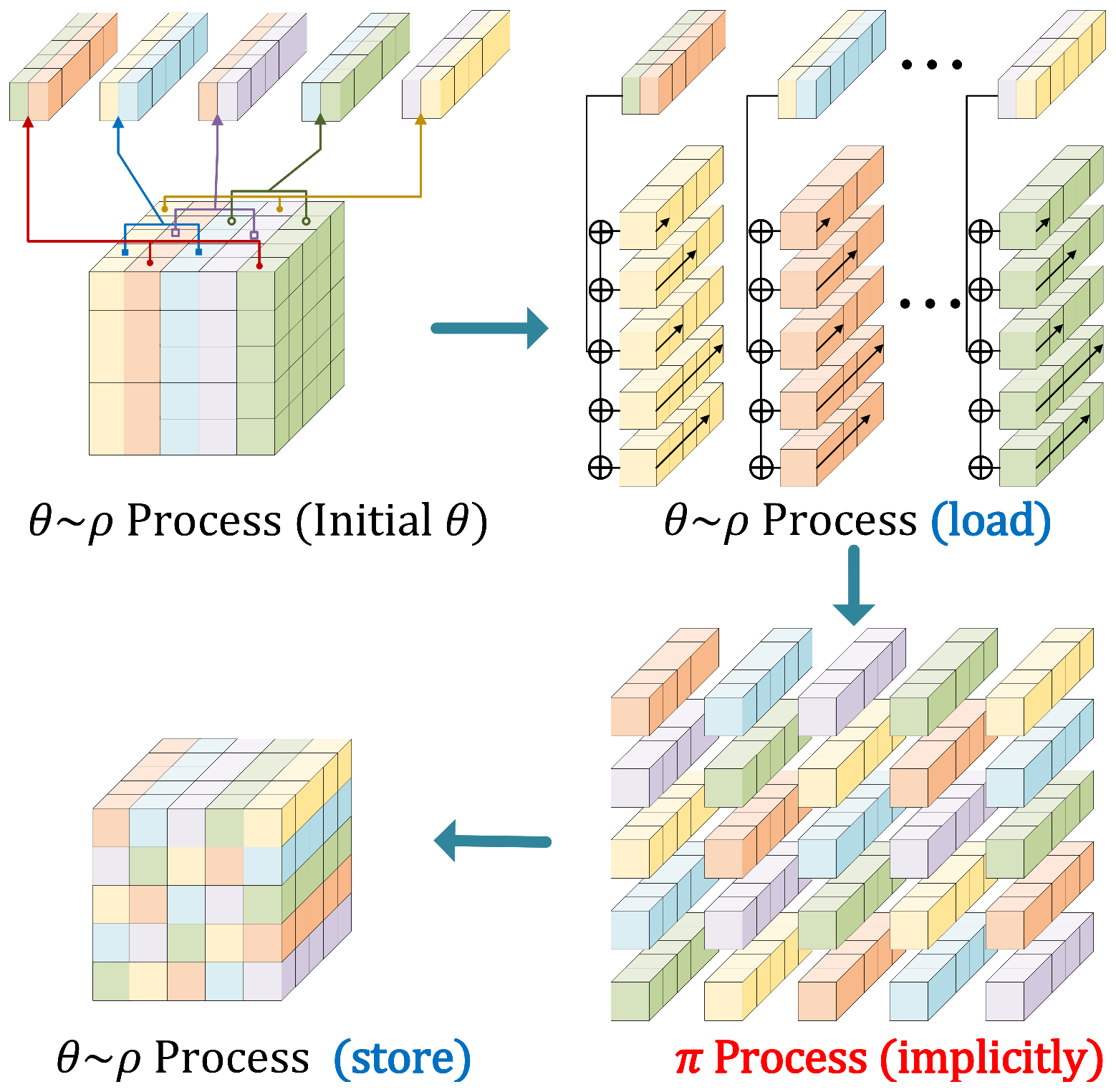
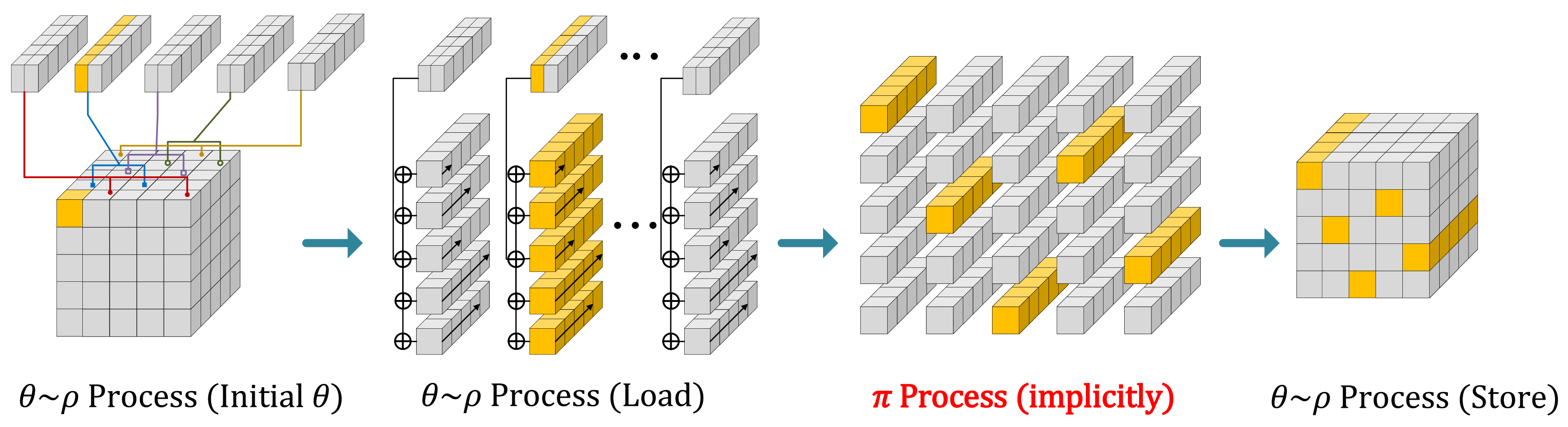
4.1. Main Idea
4.2. Proposed Implementation Technique on 8-Bit AVR MCUs
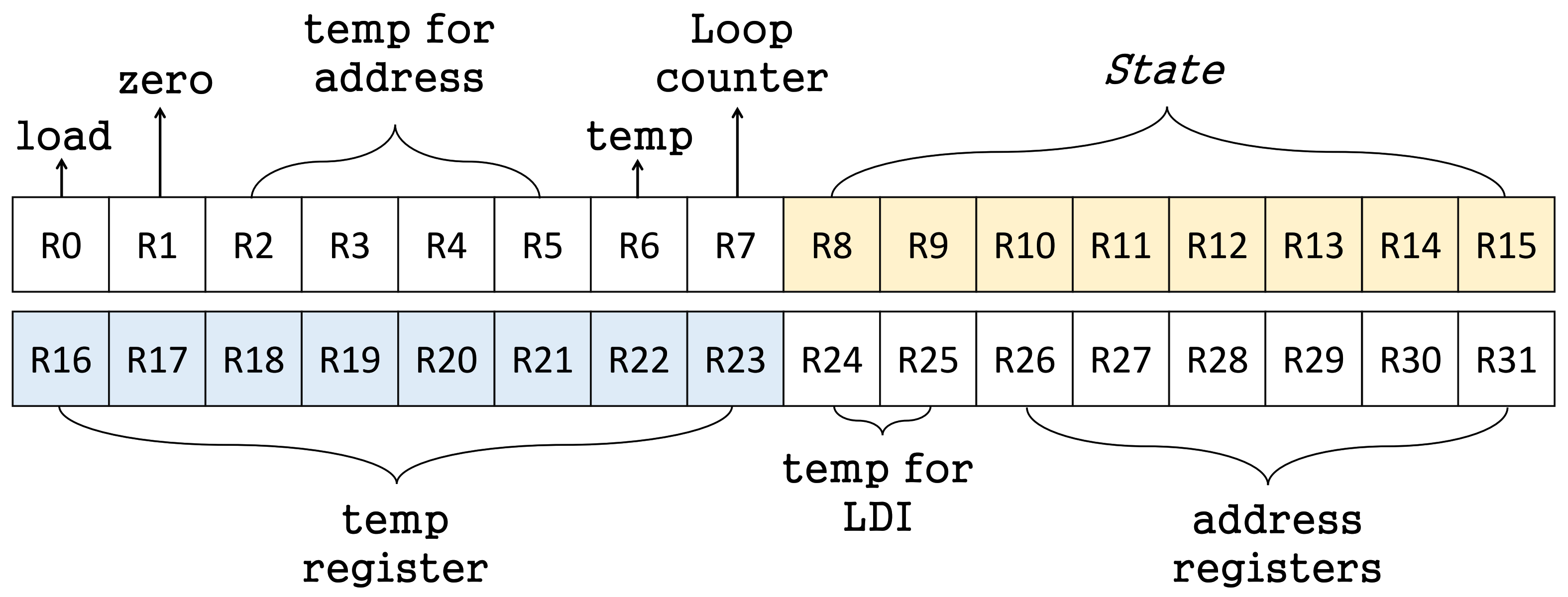
4.3. Proposed Assembly Code on 8-Bit AVR MCUs
| Algorithm 2 AVR Assembly Codes for proposed combined process for implicitly executing process with initial five lane. : of initial , . : 64-bit data of one lane of state. : 64-bit data with process calculated, : 64-bit data with and process calculated, . | |
| load S[0] | S[17][14] computation |
| 1: EOR R24 | 17: LDI // S[17] |
| 2: EOR R25 | 18: LDI // D[2] |
| 3: LD_state //R8-15 : [0]←(S[0][0]) | 19: LD_temp //R16-R23 : [17]←(S[17][2]) |
| 4: ROR_3bit_state//[0][0] | 20: LDI // S[17] |
| 21: ST_ROR2bytes_state //S[17][14] | |
| S[4][0] computation | |
| 5: LDI // S[4] | S[15][17] computation |
| 6: LDI // D[4] | 22: LDI // S[15] |
| 7: LD_temp //R16-R23 : [4]←(S[4][4]) | 23: LD_state //R8-R15 : [15]←(S[15][0]) |
| 8: ROL_2bit_temp//[4][4] | 24: ROR_4bit_state//[15]←[15] |
| 9: LDI // S[4] | 25: LDI // S[15] |
| 10: ST_ROR5bytes_state //S[4]←[0] | 26: ST_ROR7bytes_temp //S[15][17] |
| S[14][4] computation | S[10][15] computation |
| 11: LDI // S[14] | 27: LDI // S[10] |
| 12: LDI // D[4] | 28: LD_temp //R16-R23 : [10]←(S[10][0]) |
| 13: LD_state //R8-R15 : [14]←(S[14][14]) | 29: ROR_4bit_temp//[10]←[10] |
| 14: ROR_2bit_state//[4][4] | 30: LDI // S[10] |
| 15: LDI // S[14] | 31: ST_ROR3bytes_state //S[10][15] |
| 16: ST_ROR0bytes_temp //S[14][4] | |
| Algorithm 3 AVR Assembly macro codes of LD_state | ||
| .macro LD_state | ||
| 12: ADD R28, R25 | 23: LDD R0,Y + 5 | |
| 1: ADD R26, R24 | 13: LDD R0,Y + 0 | 24: EOR R13, R0 |
| 2: LD R8, X+ | 14: EOR R8, R0 | 25: LDD R0,Y + 6 |
| 3: LD R9, X+ | 15: LDD R0,Y + 1 | 26: EOR R14, R0 |
| 4: LD R10, X+ | 16: EOR R9, R0 | 27: LDD R0,Y + 7 |
| 5: LD R11, X+ | 17: LDD R0,Y + 2 | 28: EOR R15, R0 |
| 6: LD R12, X+ | 18: EOR R10, R0 | 29: SUB R28, R25 |
| 7: LD R13, X+ | 19: LDD R0,Y + 3 | |
| 8: LD R14, X+ | 20: EOR R11, R0 | .endm |
| 9: LD R15, X+ | 21: LDD R0,Y + 4 | |
| 10: ADD R24, R7 | 22: EOR R12, R0 | |
| 11: SUB R26, R24 | ||
5. Proposed Technique for Efficient Hash_DRBG Implementations Using SHA-3
6. Performance Analysis
6.1. Performance Analysis of SHA-3 Implementation
6.2. Performance Analysis of Hash_DRBG Based on SHA-3 Implementation
7. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Park, S.E.; Hwang, C.G.; Park, D.C. Internet of Things(IoT) ON system implementation with minimal Arduino based appliances standby power using a smartphone alarm in the environment. JKIECS 2015, 10, 1175–1182. [Google Scholar]
- Stevens, M.; Bursztein, E.; Karpman, P.; Albertini, A.; Markov, Y. The First Collision for Full SHA-1. In Advances in Cryptology—CRYPTO 2017, Proceedings of the 37th Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 2017; Springer: Berlin, Germany, 2017; Volume 10401, pp. 570–596. [Google Scholar]
- Wang, X.; Yin, Y.L.; Yu, H. Finding Collisions in the Full SHA-1. In Advances in Cryptology—CRYPTO 2005, Proceedings of the 25th Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2005; Springer: Berlin, Germany, 2005; Volume 3621, pp. 17–36. [Google Scholar]
- Rijmen, V.; Oswald, E. Update on SHA-1. IACR Cryptol. ePrint Arch. 2005, 2005, 10. [Google Scholar]
- Cannière, C.D.; Rechberger, C. Finding SHA-1 Characteristics: General Results and Applications. In Advances in Cryptology—ASIACRYPT 2006, Proceedings of the 12th International Conference on the Theory and Application of Cryptology and Information Security, Shanghai, China, 3–7 December 2006; Springer: Berlin, Germany, 2006; Volume 4284, pp. 1–20. [Google Scholar]
- Manuel, S. Classification and generation of disturbance vectors for collision attacks against SHA-1. Des. Codes Cryptogr. 2011, 59, 247–263. [Google Scholar] [CrossRef] [Green Version]
- Khovratovich, D.; Rechberger, C.; Savelieva, A. Bicliques for Preimages: Attacks on Skein-512 and the SHA-2 Family. In Fast Software Encryption, Proceedings of the 19th International Workshop, FSE 2012, Washington, DC, USA, 19–21 March 2012; Canteaut, A., Ed.; Springer: Berlin, Germany, 2012; Volume 7549, pp. 244–263. [Google Scholar]
- Lamberger, M.; Mendel, F. Higher-Order Differential Attack on Reduced SHA-256. IACR Cryptol. ePrint Arch. 2011, 2011, 37. [Google Scholar]
- Mendel, F.; Nad, T.; Schläffer, M. Improving Local Collisions: New Attacks on Reduced SHA-256. In Advances in Cryptology—EUROCRYPT 2013, Proceedings of the 32nd Annual International Conference on the Theory and Applications of Cryptographic Techniques, Athens, Greece, 26–30 May 2013; Springer: Berlin, Germany, 2013; Volume 7881, pp. 262–278. [Google Scholar]
- Dobraunig, C.; Eichlseder, M.; Mendel, F. Analysis of SHA-512/224 and SHA-512/256. IACR Cryptol. ePrint Arch. 2016, 2016, 374. [Google Scholar]
- Sasaki, Y.; Wang, L.; Aoki, K. Preimage Attacks on 41-Step SHA-256 and 46-Step SHA-512. IACR Cryptol. ePrint Arch. 2009, 2009, 479. [Google Scholar]
- Morris, J.D. SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions. 2015. Available online: https://doi.org/10.6028/NIST.FIPS.202 (accessed on 2 February 2021).
- Lee, H.; Hong, D.; Kim, H.; Seo, C.; Park, K. An Implementation of an SHA-3 Hash Function Validation Program and Hash Algorithm on 16bit-UICC. J. Korea Inst. Inf. Sec. Cryptol. 2014, 41, 885–891. [Google Scholar] [CrossRef]
- Kang, M.; Lee, H.w.; Hong, D.; Seo, C. Implementation of SHA-3 Algorithm Based On ARM-11 Processors. J. Korea Inst. Inf. Sec. Cryptol. 2015, 25, 749–757. [Google Scholar] [CrossRef] [Green Version]
- AVR-Crypto-Lib. 2015. Available online: https://wiki.das-labor.org/w/-AVR-Crypto-Lib/en (accessed on 2 February 2021).
- Balasch, J.; Ege, B.; Eisenbarth, T.; Gérard, B.; Gong, Z.; Güneysu, T.; Heyse, S.; Kerckhof, S.; Koeune, F.; Plos, T.; et al. Compact Implementation and Performance Evaluation of Hash Functions in ATtiny Devices. In Smart Card Research and Advanced Applications, Proceedings of the 11th International Conference, CARDIS 2012, Graz, Austria, 28–30 November 2012; Springer: Berlin, Germany, 2012; Volume 7771, pp. 158–172. [Google Scholar]
- Team, K. Extended Keccack Code Package. 2018. Available online: https://keccak.team/index.html (accessed on 2 February 2021).
- KISA. SHA-3 Source Code Manual. 2020. Available online: https://seed.kisa.or.kr//kisa/kcmvp/EgovVerification.do (accessed on 2 February 2021).
- Team, K. The eXtended Keccak Code Package (Open-Source Implementations of the Cryptographic Schemes Defined by the Keccak Team). Available online: https://github.com/XKCP/XKCP (accessed on 2 February 2021).
- Korea Internet & Security Agency Open Cryptography Algorithms. Available online: https://seed.kisa.or.kr/kisa/reference/EgovSource.do (accessed on 2 February 2021).
- Basso, A.; Mera, J.M.B.; D’Anvers, J.P.; Karmakar, A.; Roy, S.S.; Beirendonck, M.V.; Vercauteren, F. SABER: Mod-LWR Based KEM (Round 3 Submission). 2020. Available online: https://www.esat.kuleuven.be/cosic/pqcrypto/saber/index.html (accessed on 2 February 2021).
- Avanzi, R.; Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Kyber Algorithm Specifications And Supporting Documentation. 2020. Available online: https://pq-crystals.org/ (accessed on 2 February 2021).
- Bai, S.; Ducas, L.; Kiltz, E.; Lepoint, T.; Schwabe, P.; Seiler, G.; Stehle, D. CRYSTALS-Dilithium Algorithm Specifications And Supporting Documentation. 2020. Available online: https://pq-crystals.org/ (accessed on 2 February 2021).
- Fouque, P.A.; Hoffstein, J.; Kirchner, P.; Lyubashevsky, V.; Thomas, T.P.; Ricosset, P.T.; Seiler, G.; Whyte, W.; Zhang, Z. Falcon: Fast-Fourier Lattice-based Compact Signatures over NTRU. 2020. Available online: https://falcon-sign.info (accessed on 2 February 2021).
- Kim, Y.; Choi, H.; Seo, S.C. Efficient Implementation of SHA-3 Hash Function on 8-bit AVR-based Sensor Nodes. In The 23rd Annual International Conference on Information Security and Cryptology; Springer: Berlin, Germany, 2020. [Google Scholar]
- Barker, E.; Kelsey, J. Recommendation for Random Number Generation Using Deterministic Random Bit Generators. 2015. Available online: https://csrc.nist.gov/publications/detail/sp/800-90a/rev-1/final (accessed on 2 February 2021).
- Kim, Y.; Kwon, H.; An, S.; Seo, H.; Seo, S.C. Efficient Implementation of ARX-Based Block Ciphers on 8-Bit AVR Microcontrollers. Mathematics 2020, 8, 1837. [Google Scholar] [CrossRef]
- Kim, Y.; Seo, S.C. An Efficient Implementation of AES on 8-bit AVR-based Sensor Nodes. In The 21th World Conference on Information Security Applications; Springer: Berlin, Germany, 2020. [Google Scholar]
- Liu, Z.; Seo, H.; Großschädl, J.; Kim, H. Efficient Implementation of NIST-Compliant Elliptic Curve Cryptography for 8-bit AVR-Based Sensor Nodes. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1385–1397. [Google Scholar] [CrossRef]
- Atmel. AVR Instruction Set Manual. 2012. Available online: http://ww1.microchip.com/downloads/en/devicedoc/atmel-0856-avr-instruction-set-manual.pdf (accessed on 2 February 2021).
- Kwon, H.; Kim, H.; Choi, S.J.; Jang, K.; Park, J.; Kim, H.; Seo, H. Compact Implementation of CHAM Block Cipher on Low-End Microcontrollers. In The 21th World Conference on Information Security Applications; Springer: Berlin, Germany, 2020. [Google Scholar]
- Fair and Comprehensive Performance Evaluation of 14 Second Round SHA-3 ASIC Implementations. Available online: https://www.semanticscholar.org/paper/Fair-and-Comprehensive-Performance-Evaluation-of-14-Guo/0a1eeac2c74ef77127bbd926b87a13805eb61b6b (accessed on 2 February 2021).
- Cheng, H.; Dinu, D.; Großschädl, J. Efficient Implementation of the SHA-512 Hash Function for 8-Bit AVR Microcontrollers. In Innovative Security Solutions for Information Technology and Communications, Proceedings of the 11th International Conference, SecITC 2018, Bucharest, Romania, 8–9 November 2018; Springer: Berlin, Germany, 2018; Volume 11359, pp. 273–287. [Google Scholar]
- KIM, Y.; SEO, S.C. Efficient Implementation of AES and CTR_DRBG on 8-bit AVR-based Sensor Nodes. IEEE Access 2021, 1. [Google Scholar] [CrossRef]
- KISA. KCMVP Manual for Cryptography. 2020. Available online: https://seed.kisa.or.kr/kisa/Board/79/detailView.do (accessed on 2 February 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| b (bit) | 25 | 50 | 100 | 200 | 400 | 800 | 1600 |
| w (bit) | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
| l | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| x = 3 | x = 4 | x = 0 | x = 1 | x = 2 | |
| y = 2 | 153 | 231 | 3 | 10 | 171 |
| y = 1 | 55 | 276 | 36 | 300 | 6 |
| y = 0 | 28 | 91 | 0 | 1 | 190 |
| y = 4 | 120 | 78 | 210 | 66 | 253 |
| y = 3 | 21 | 136 | 105 | 45 | 15 |
| SHA3-256 | SHA3-384 | SHA3-512 | |
|---|---|---|---|
| highest supported security strength | |||
| digest (out length of hash function) | 256-bit | 384-bit | 512-bit |
| len_seed | 2 | 3 | 3 |
| seedlen | 440-bit | 888-bit | |
| Asm | Operands | Description | Operation | cc |
|---|---|---|---|---|
| ADD | Rd, Rr | Add without Carry | Rd ← Rd+Rr | 1 |
| ADC | Rd, Rr | Add with Carry | Rd ← Rd+Rr+C | 1 |
| MOV | Rd, Rr | Copy Register | Rd ← Rr | 1 |
| EOR | Rd, Rr | Exclusive OR | Rd ← Rd⊕Rr | 1 |
| LSL | Rd | Logical Shift Left | C∣Rd ← Rd<<1 | 1 |
| LSR | Rd | Logical Shift Right | Rd∣C ← 1>>Rd | 1 |
| ROL | Rd | Rotate Left Through Carry | C∣Rd ← Rd<<1C | 1 |
| ROR | Rd | Rotate Right Through Carry | Rd∣C ← C1>>Rd | 1 |
| BST | Rd, b | Bit store from Bit in Reg to T Flag | T ← Rd(b) | 1 |
| BLD | Rd, b | Bit load from T Flag to a Bit in Reg | Rd(b) ← T | 1 |
| LDI | Rd, K | Load Immediate | Rd ← K | 1 |
| LD | Rd, X | Load Indirect | Rd ← (X) | 2 |
| ST | Z, Rr | Store Indirect | (Z) ← Rr | 2 |
| Standard Method | Initial | Process | Process | Process | Total Access |
|---|---|---|---|---|---|
| Load | ◯ | ◯ | ◯ | ◯ | |
| Store | ◯ | ◯ | ◯ |
| Standard Method | Initial | Process | Process | Process | Total Access |
|---|---|---|---|---|---|
| Load | ◯ | ◯ | ◯ | ◯ | |
| Store | ◯ | ◯ | ◯ | ||
| Proposed Method | Initial | Process | Process | Process | Total Access |
| Load | ◯ | ◯ | (Implied) | ◯ | |
| Store | ◯ | (Implied) | ◯ |
| fROR_1bit_state | ROL_1bit_state | ST_ROR1bytes_state | ST_ROR3bytes_state |
|---|---|---|---|
| BST R15, 0 ROR R8 ROR R9 ROR R10 ROR R11 ROR R12 ROR R13 ROR R14 ROR R15 BLD R8, 7 | LSL R15 ROL R14 ROL R13 ROL R12 ROL R11 ROL R10 ROL R9 ROL R8 ADC R15, R1 | ADD R26, R24 ST X+, R15 ST X+, R8 ST X+, R9 ST X+, R10 ST X+, R11 ST X+, R12 ST X+, R13 ST X+, R14 ADD R24, R7 SUB R26, R24 | ADD R26, R24 ST X+, R13 ST X+, R14 ST X+, R15 ST X+, R8 ST X+, R9 ST X+, R10 ST X+, R11 ST X+, R12 ADD R24, R7 SUB R26, R24 |
| 10 cycles | 9 cycles | 19 cycles | 19 cycles |
| Reference | Algorithm | Language | Length of Message Byte | ||
|---|---|---|---|---|---|
| 50 Byte | 100 Byte | 500 Byte | |||
| This Paper | SHA-3(256-bit) | Asm | 2646 | 1326 | 1066 |
| (+25.6%) | (+26.1%) | (+25.5%) | |||
| Otte et al. [15] | SHA-3 (256-bit) | C | 12,854 | 6427 | 5142 |
| Balasch et al. [16] | SHA-3 (256-bit) | Asm | 3560 (−) | 1795 (−) | 1432 (−) |
| Balasch et al. [16] | SHA-256 | Asm | 672 | 668 | 532 |
| Balasch et al. [16] | Blake (256-bit) | Asm | 714 | 708 | 562 |
| Balasch et al. [16] | Grstl (256-bit) | Asm | 1220 | 1012 | 686 |
| Balasch et al. [16] | Photon (256-bit) | Asm | 9723 | 7982 | 4788 |
| Reference | DRBG | Algorithm | Language | Extracted Random Byte | ||
|---|---|---|---|---|---|---|
| 50 Byte | 100 Byte | 500 Byte | ||||
| This Paper | Hash | SHA-3(256-bit) | Asm | 917,600 | 1,182,200 | 1,579,100 |
| (+26.5%) | (+26.3%) | (+26.1%) | ||||
| Balasch et al. [16] | Hash | SHA-3 (256-bit) | Asm | 1,248,100 | 1,604,100 | 2,138,100 |
| (−) | (−) | (−) | ||||
| Balasch et al. [16] | Hash | SHA-256 | Asm | 247,100 | 317,100 | 422,100 |
| Otte et al. [15] | Hash | SHA-3 (256-bit) | C | 4,501,000 | 5,786,400 | 7,714,500 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.B.; Youn, T.-Y.; Seo, S.C. Chaining Optimization Methodology: A New SHA-3 Implementation on Low-End Microcontrollers. Sustainability 2021, 13, 4324. https://doi.org/10.3390/su13084324
Kim YB, Youn T-Y, Seo SC. Chaining Optimization Methodology: A New SHA-3 Implementation on Low-End Microcontrollers. Sustainability. 2021; 13(8):4324. https://doi.org/10.3390/su13084324
Chicago/Turabian StyleKim, Young Beom, Taek-Young Youn, and Seog Chung Seo. 2021. "Chaining Optimization Methodology: A New SHA-3 Implementation on Low-End Microcontrollers" Sustainability 13, no. 8: 4324. https://doi.org/10.3390/su13084324
APA StyleKim, Y. B., Youn, T. -Y., & Seo, S. C. (2021). Chaining Optimization Methodology: A New SHA-3 Implementation on Low-End Microcontrollers. Sustainability, 13(8), 4324. https://doi.org/10.3390/su13084324