
Using Clean Energy Satellites to Interpret Imagery: A Satellite IoT Oriented Lightweight Object Detection Framework for SAR Ship Detection

 ,
,
Abstract
:1. Introduction
- 1.
- This paper analyzes the state of the art of the novel on-orbit remote sensing interpretation paradigm architecture. Compared with traditional interpretation methods, The scheme proposed in this paper helps to build a novel real-time, eco-friendly and sustainable remote sensing image interpretation mode.
- 2.
- We study the fusion performance of the vision transformer module under the reduced YOLO framework. Choosing a suitable position to integrate the vision transformer module can improve mAP and reduce false alarms;
- 3.
- We compared the model size and performance of classic YOLOv5 models through experiments at different scales. Reducing the number of input channels of the network and adequately controlling the model depth has little effect on detection performance for SAR ship detection tasks. The YOLO-ViTSS has good detection performance and achieves 96.77% with a lightweight parameter of 1.3 MB; this is more streamlined than the methods proposed in those articles [26,27,28,29,30];
- 4.
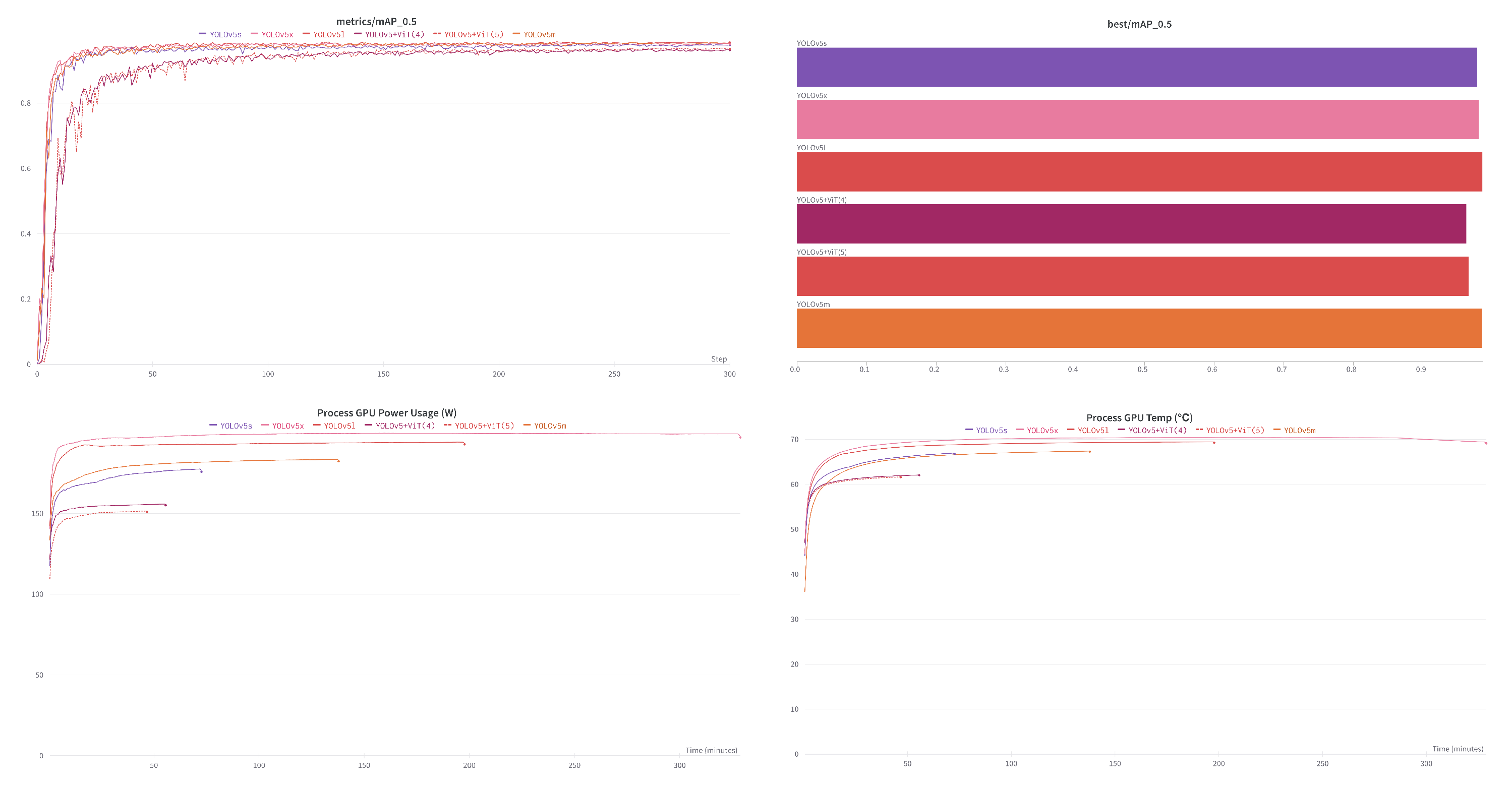
- We calculated computational complexity and energy consumption. The energy consumption of YOLO-ViTSS is only 1/7 of YOLOv5X. Furthermore, it has only an average training power consumption of 151W which means a 0.7-square-meter satellite solar array can meet the power supply requirement; it has excellent potential to port to satellite platforms for on-orbit reasoning and online training, providing a green solution for online IoT access of satellite remote sensing data.
2. Materials and Methods
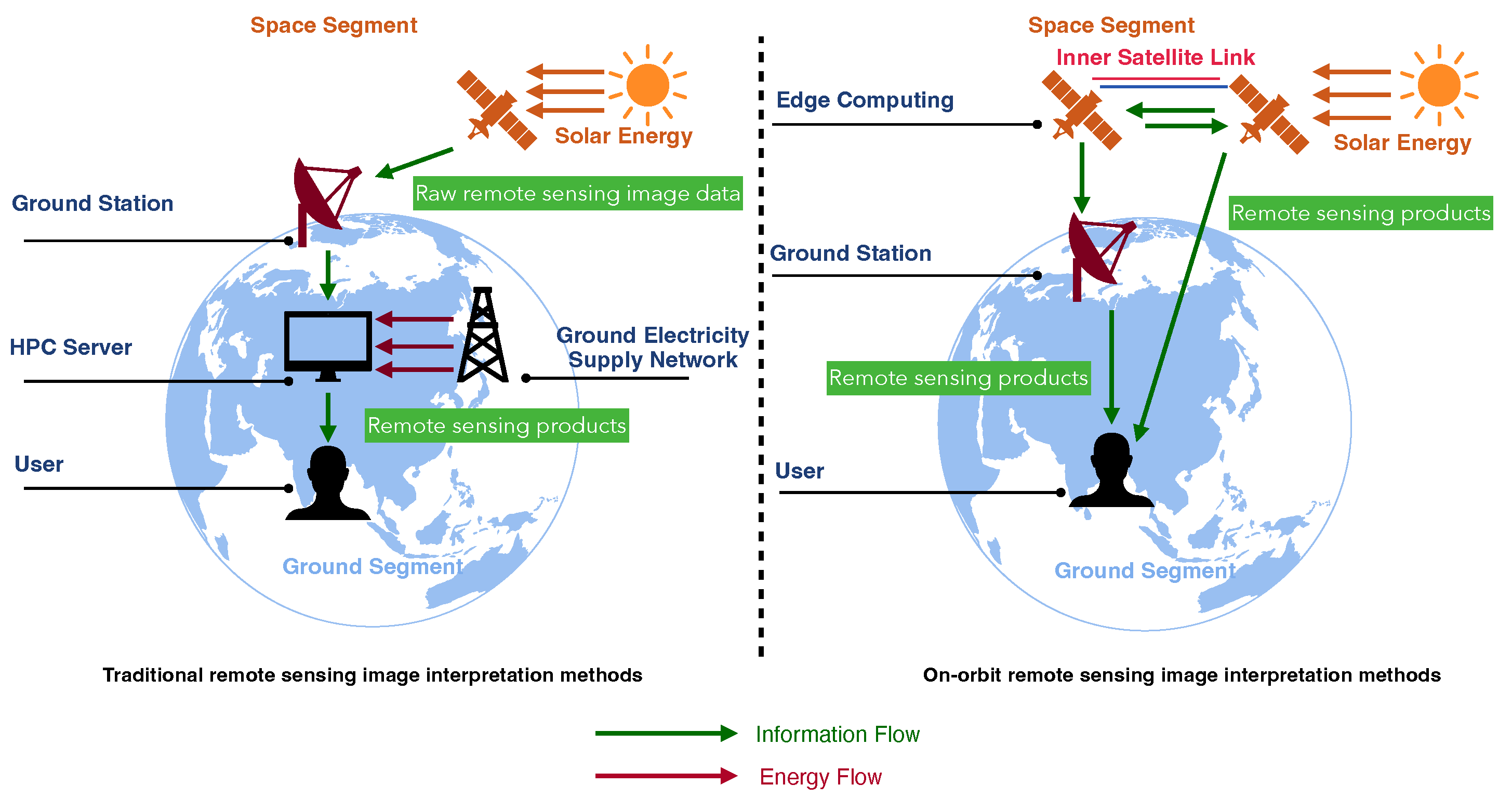
2.1. A New Paradigm for Remote Sensing Image Interpretation
- 1.
- More environmentally friendly: The satellite uses solar energy. Compared with computing on the ground which consumes the electronic resources on the earth, on-orbit computing uses clean energy provided by satellites to saves the electronic resources on the earth.
- 2.
- More timeliness: The remote sensing satellite are the front end of perception. On-orbit interpretation can complete the early discovery and continuous tracking of the target information of interest.
- 3.
- Easier access to IoT: Only transmitting meaningful semantic information instead of raw remote sensing data could reduce the bandwidth occupied by the inter-satellite link, making it easier to realize the collaborative work of multiple satellites.
- 4.
- Automatically improves the recognition performance of satellites in orbit: On-orbit semi-supervised training of intelligent models could be performed in real orbital work scenarios to improve performance.
- 1.
- Compared with high-performance servers on the ground, the computing power and storage resources on satellites are more limited, so a more lightweight target detection algorithm is required, that is, a neural network model algorithm with lower computational energy consumption and less storage space.
- 2.
- To achieve enough high precision requirements.
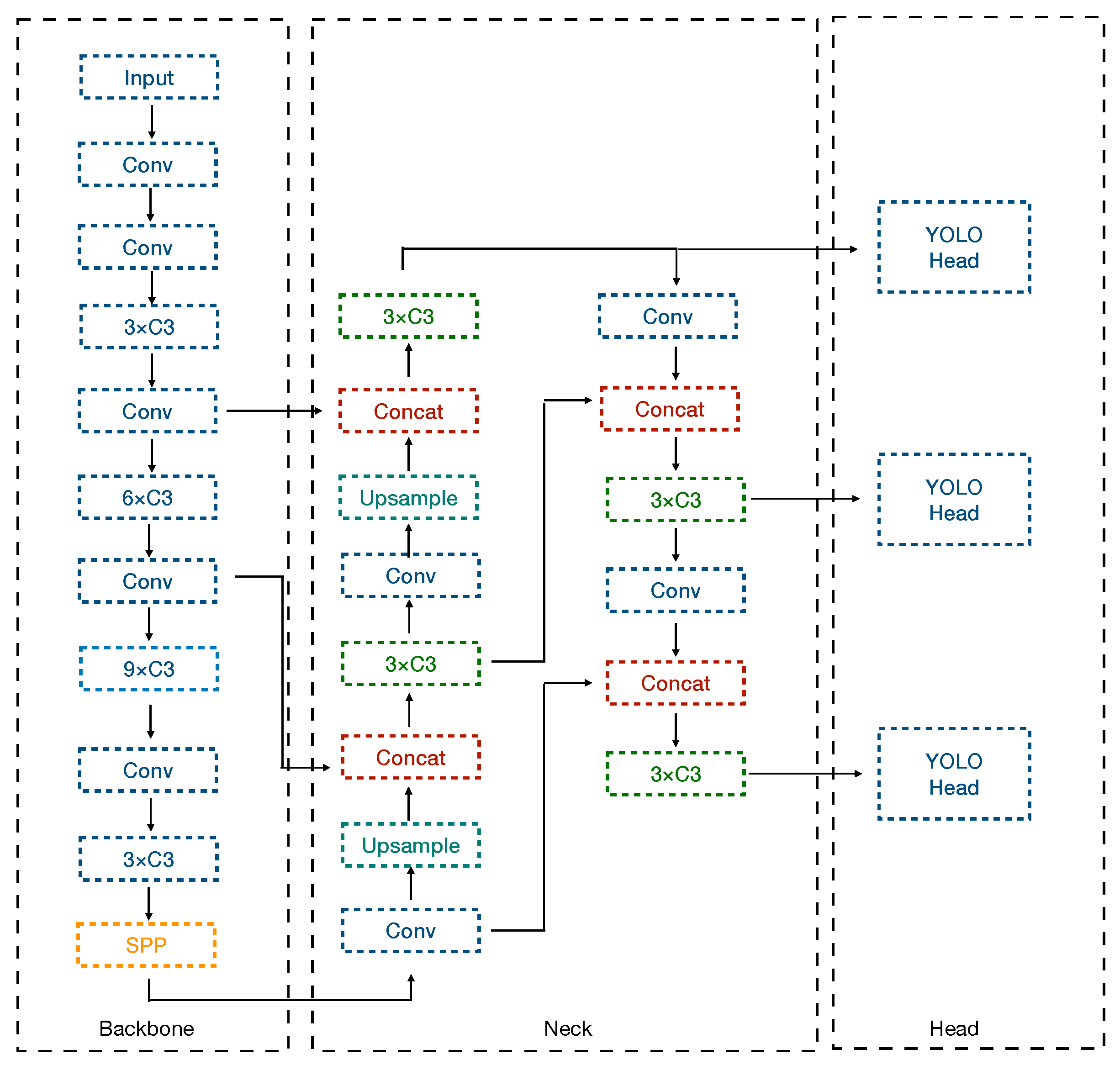
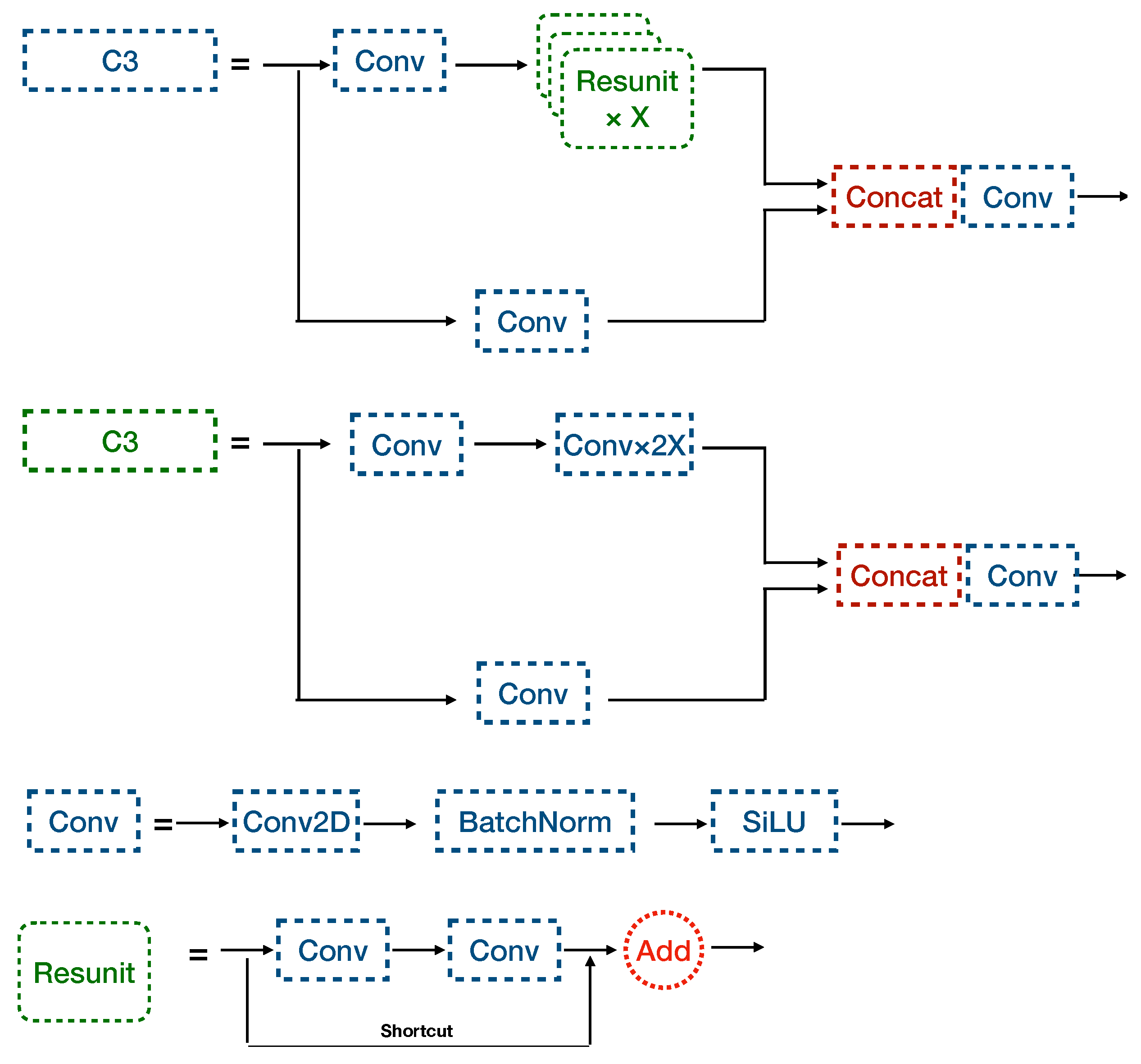
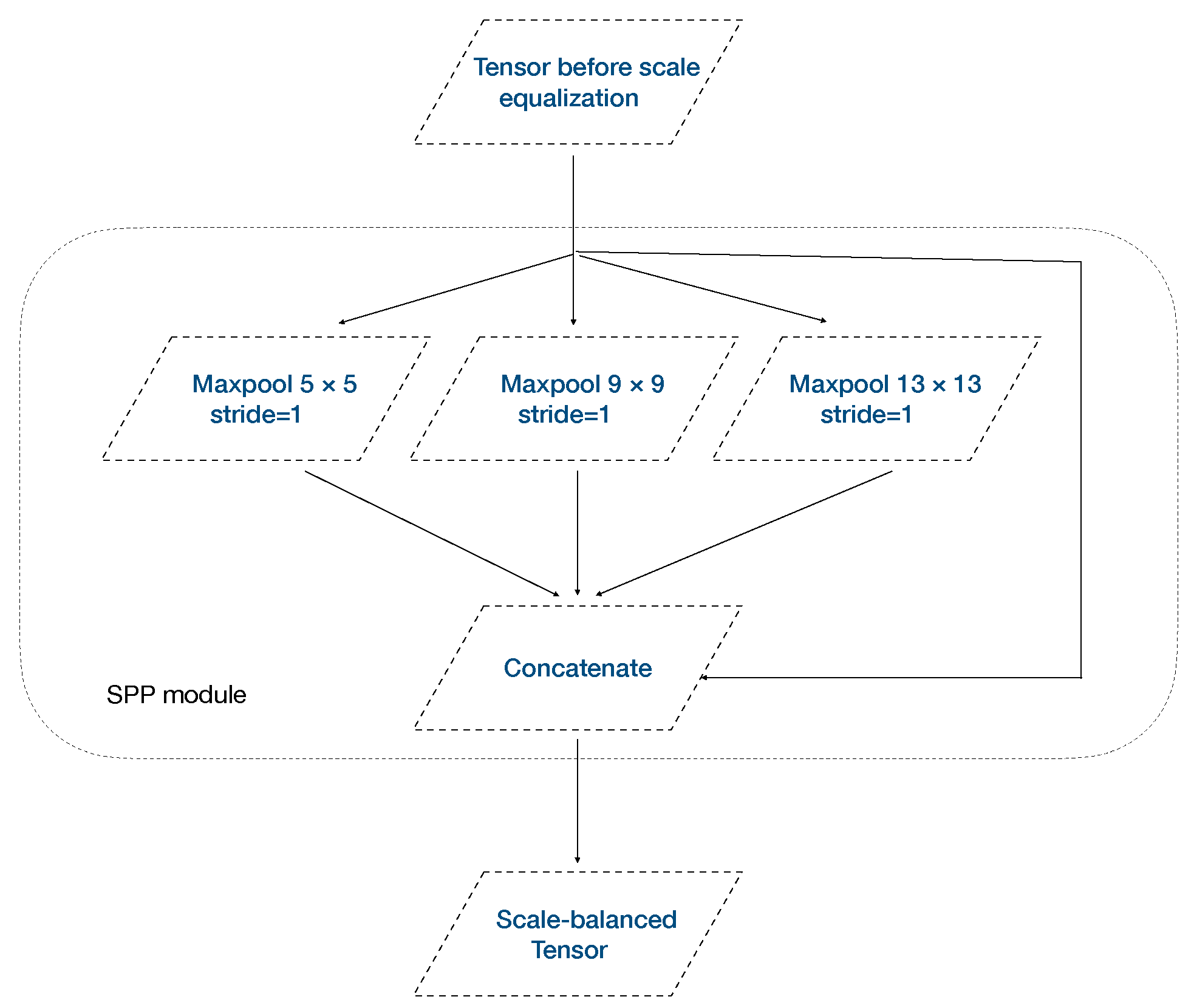
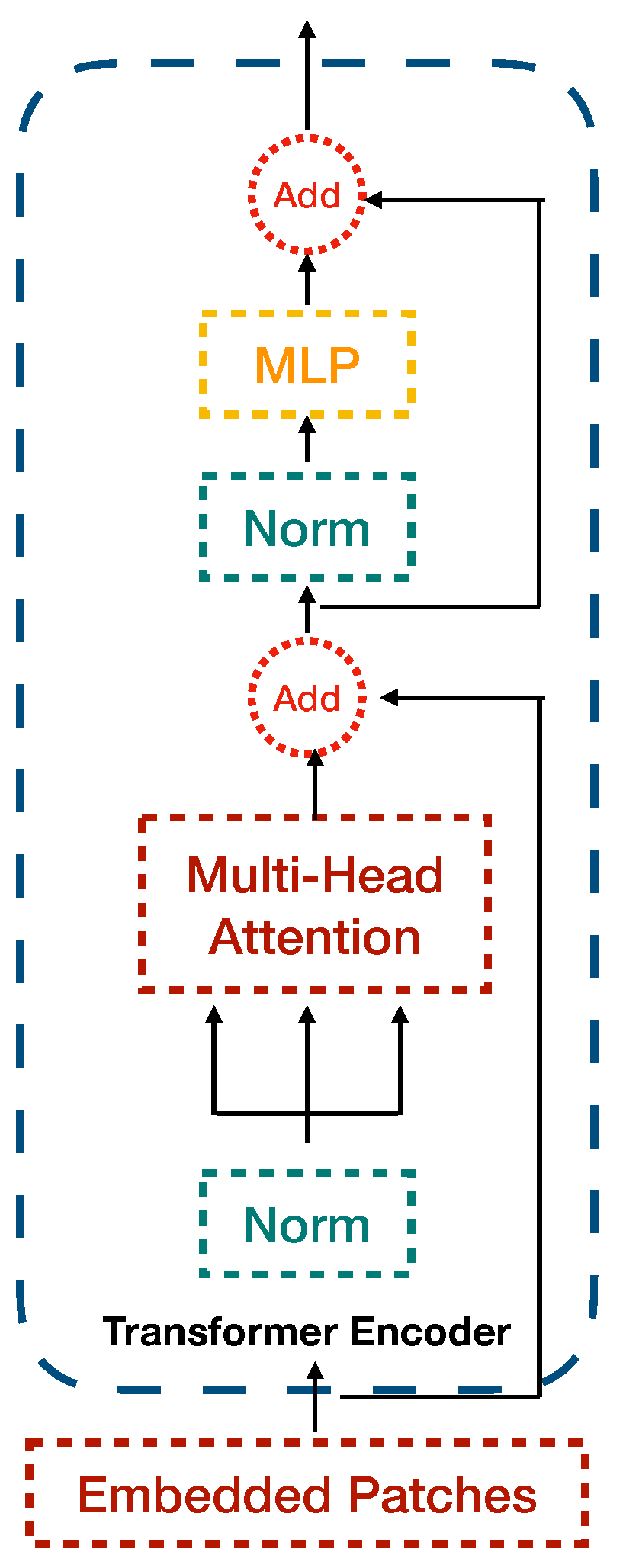
2.2. YOLOv5 Object Detection Framework
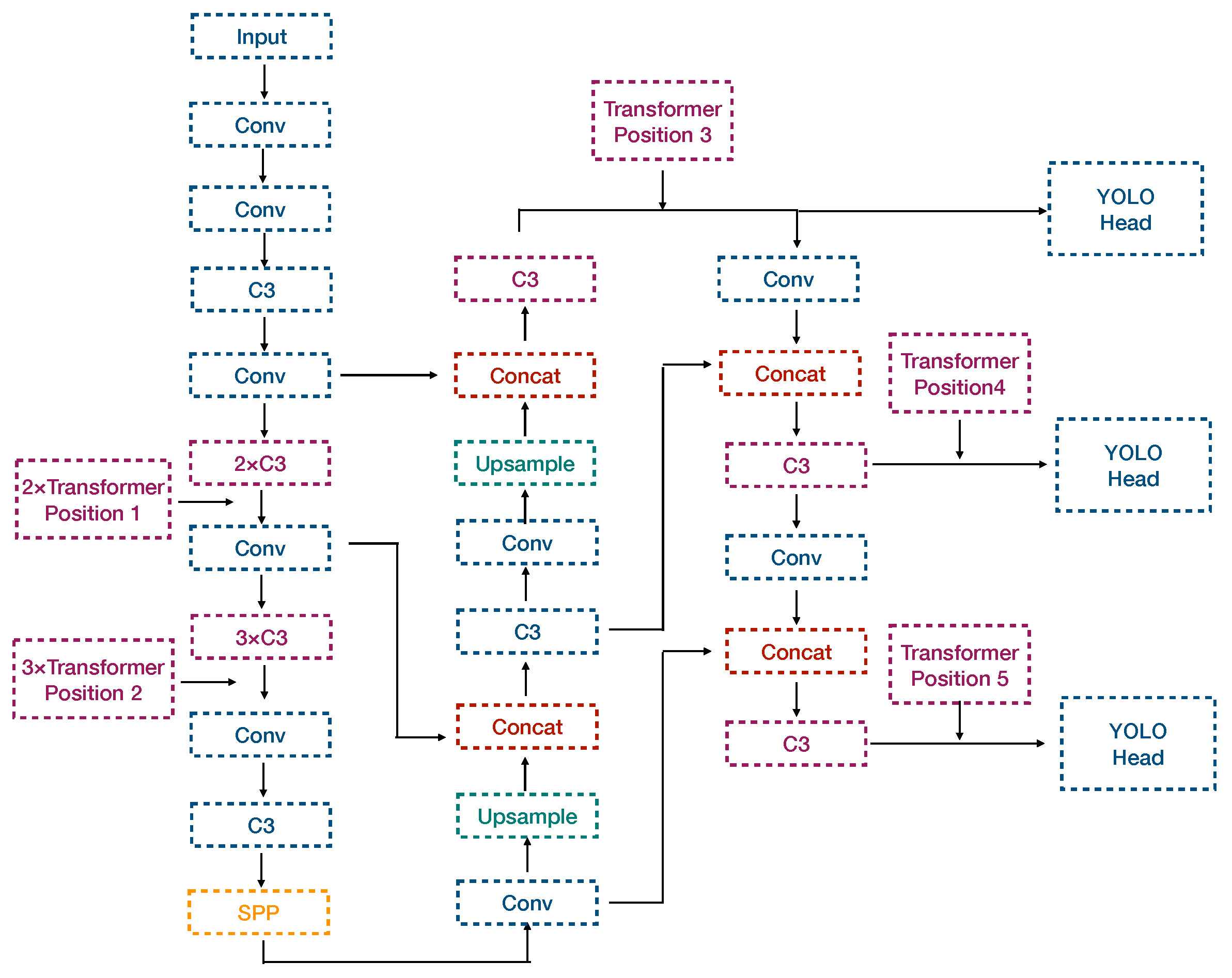
2.3. Proposed Method
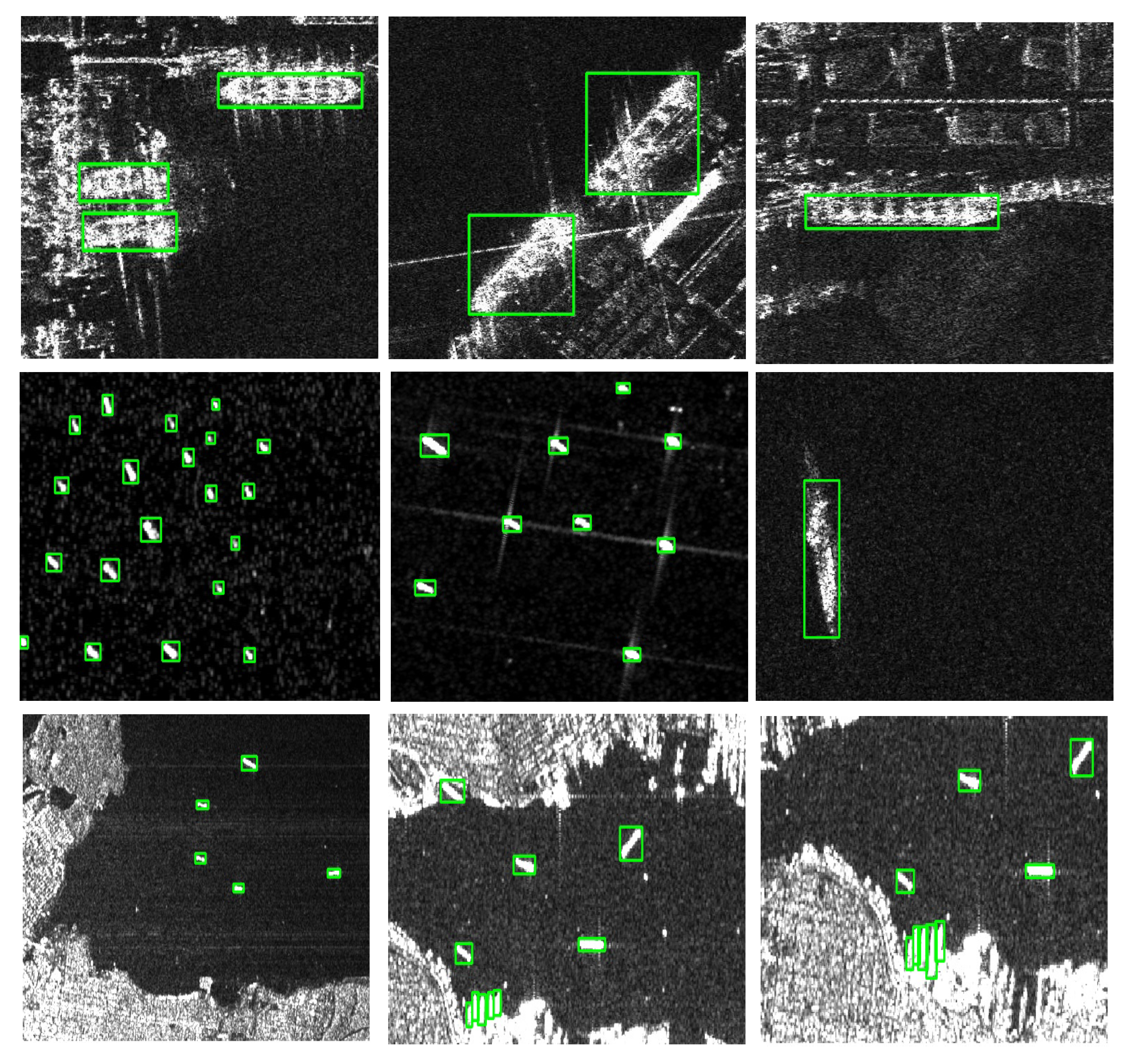
2.4. Dataset
3. Results
3.1. Evaluation Methods
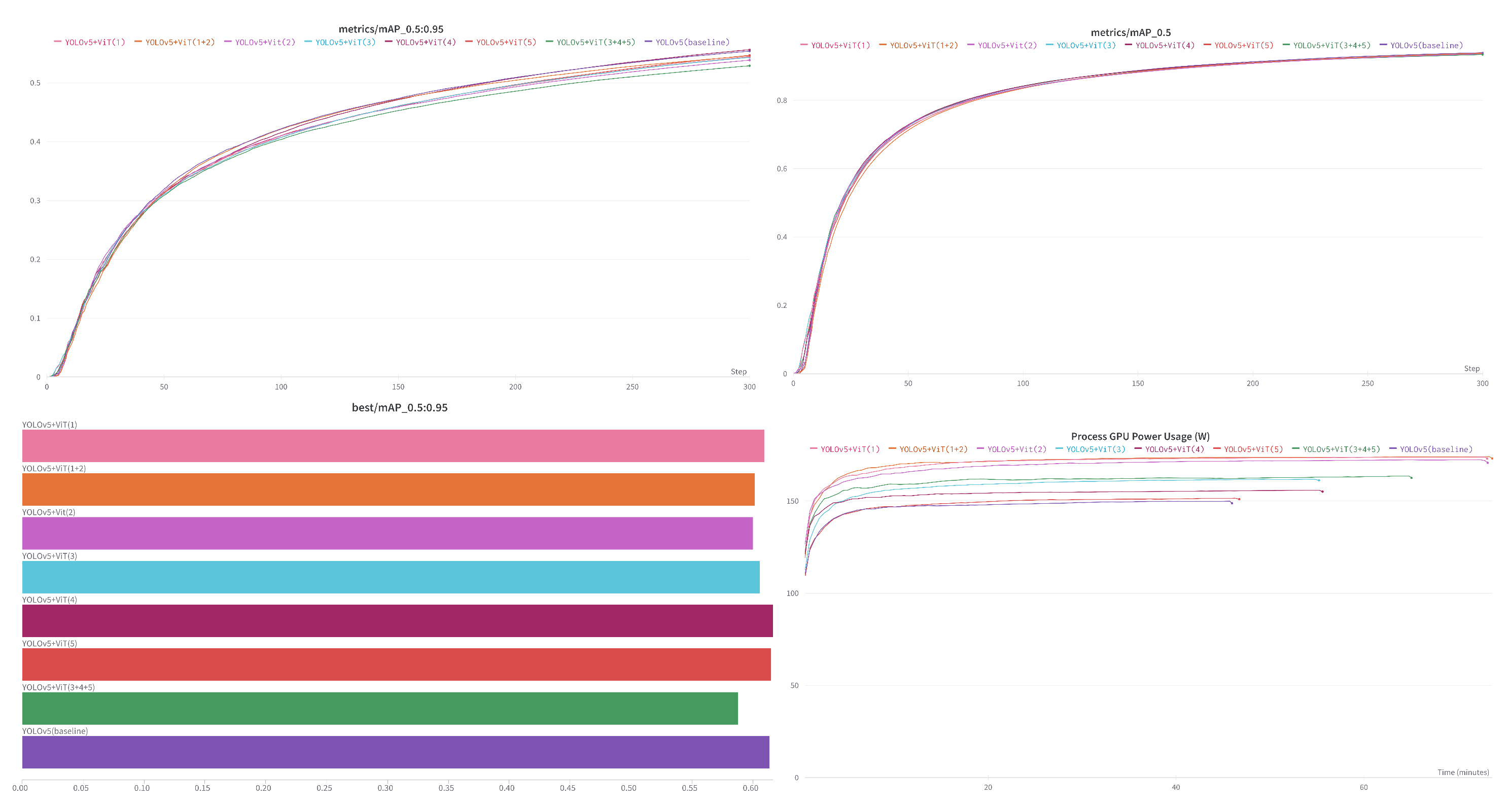
3.2. Experiment 1: Fusion Configuration Research
3.3. Experiment 2: Module Scale Research
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, W.; Awais, M.; Ru, W.; Shi, W.; Ajmal, M.; Uddin, S.; Liu, C. Review of sensor network-based irrigation systems using IoT and remote sensing. Adv. Meteorol. 2020, 2020, 8396164. [Google Scholar]
- Guilhot, D.; Hoyo, T.; Bartoli, A.; Ramakrishnan, P.; Leemans, G.; Houtepen, M.; Salzer, J.; Metzger, J.; Maknavicius, G. Internet-of-Things-Based Geotechnical Monitoring Boosted by Satellite InSAR Data. Remote. Sens. 2021, 13, 2757. [Google Scholar] [CrossRef]
- Wei, W.; Gao, Z.; Gao, S.; Jia, K. A SINS/SRS/GNS Autonomous Integrated Navigation System Based on Spectral Redshift Velocity Measurements. Sensors 2018, 18, 1145. [Google Scholar]
- Stasolla, M.; Mallorqui, J.; Margarit, G.; Santamaria, C.; Walker, N. A comparative study of operational vessel detectors for maritime surveillance using satellite-borne synthetic aperture radar. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2016, 9, 2687–2701. [Google Scholar] [CrossRef] [Green Version]
- Ben-Larbi, M.; Pozo, K.; Haylok, T.; Choi, M.; Grzesik, B.; Haas, A.; Krupke, D.; Konstanski, H.; Schaus, V.; Fekete, S.; et al. Towards the automated operations of large distributed satellite systems. Part 1: Review and paradigm shifts. Adv. Space Res. 2016, 67, 3598–3619. [Google Scholar]
- Michailidis, E.; Potirakis, S.; Kanatas, A. AI-Inspired Non-Terrestrial Networks for IIoT. Rev. Enabling Technol. Appl. IoT 2016, 1, 3598–3619. [Google Scholar]
- Lin, Y.; Fan, Y.; Jiang, C.; Wang, Z.; Shao, W. MIMO SAR Using Orthogonal Coding: Design, Performance Analysis, and Verifications. Int. J. Antennas Propag. 2015, 3, 1–10. [Google Scholar]
- Gao, X.; Roy, S.; Xing, G. MIMO-SAR: A hierarchical high-resolution imaging algorithm for mmWave FMCW radar in autonomous driving. IEEE Trans. Veh. Technol. 2021, 70, 7322–7334. [Google Scholar] [CrossRef]
- Younis, M.; Krieger, G.; Moreira, A. MIMO SAR techniques and trades. In Proceedings of the European Radar Conference (EuRAD), Nuremberg, Germany, 9–11 October 2013. [Google Scholar]
- Wang, W.Q. MIMO SAR imaging: Potential and challenges. Aerospace and Electronic Systems Magazine. Aerosp. Electron. Syst. Mag. 2013, 28, 18–23. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 1 May 2022). [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf (accessed on 1 May 2022). [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 2 February 2022).
- Zhao, H.; Zhou, Y.; Zhang, L.; Peng, Y.; Hu, X.; Peng, H.; Cai, X. Mixed YOLOv3-LITE: A lightweight real-time object detection method. Sensors 2020, 20, 1861. [Google Scholar] [CrossRef] [Green Version]
- Jia, Y.-F.; Chen, G.; Jiang, Z.; Yang, M.; Xing, L.-Y.; Cui, Y. A lightweight fast object detection method. J. Netw. Intell. 2022, 7, 209–221. [Google Scholar]
- Lapegna, M. A GPU-Parallel Image Coregistration Algorithm for InSar Processing at the Edge. Sensors 2021, 21, 5916. [Google Scholar]
- Zhong, R. On-Board Real-Time Ship Detection in HISEA-1 SAR Images Based on CFAR and Lightweight Deep Learning. Remote. Sens. 2021, 13, 1995. [Google Scholar]
- Xu, X.; Zhang, X.; Zhang, T. Lite-YOLOv5: A Lightweight Deep Learning Detector for On-Board Ship Detection in Large-Scene Sentinel-1 SAR Images. Remote. Sens. 2022, 14, 1018. [Google Scholar] [CrossRef]
- Chang, Y.L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.Y.; Lee, W.H. Ship detection based on YOLOv2 for SAR imagery. Remote. Sens. 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Huyan, L.; Bai, Y.; Li, Y.; Jiang, D.; Zhang, Y.; Zhou, Q.; Wei, J.; Liu, J.; Zhang, Y.; Cui, T. A Lightweight Object Detection Framework for Remote Sensing Images. Remote Sens. 2021, 13, 683. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liang, J.; Homayounfar, N.; Ma, W.C.; Xiong, Y.; Hu, R.; Urtasun, R. Polytransform: Deep polygon transformer for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9131–9140. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Agarap, A. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, N.; Jones, J.; Gomez, L.; Kaiser, A.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 3 May 2022).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; p. 30. [Google Scholar]
- Space Product Literature. Available online: https://www.baesystems.com/en-us/our-company/inc-businesses/electronic-systems/product-sites/space-products-and-processing/radiation-hardened-electronics (accessed on 7 May 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision (%) | Recall (%) | mAP (%) | mAP (%) | Training Time(min) | Consumption (W) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLOv5 + ViT(1) | 96.88 | 91.94 | 96.49 | 60.95 | 73.1 | 172.9 | 1.1 |
| YOLOv5 + ViT(2) | 95.50 | 93.04 | 96.60 | 60.03 | 73.1 | 171.6 | 1.1 |
| YOLOv5 + ViT(3) | 97.60 | 91.00 | 96.73 | 60.59 | 55.2 | 161.5 | 1.1 |
| YOLOv5 + ViT(4) | 94.71 | 91.58 | 96.26 | 62.04 | 55.6 | 155.7 | 1.1 |
| YOLOv5 + ViT(5) | 98.76 | 90.84 | 96.60 | 61.52 | 46.7 | 151.9 | 1.1 |
| YOLOv5 + ViT(1+2) | 95.59 | 91.58 | 96.77 | 60.20 | 73.6 | 172.9 | 1.1 |
| YOLOv5 + ViT(3+4+5) | 95.52 | 91.21 | 96.17 | 58.80 | 64.8 | 162.1 | 1.1 |
| Baseline | 95.28 | 92.67 | 96.62 | 61.38 | 45.9 | 148.7 | 1.1 |
| Method | Precision (%) | Recall (%) | mAP (%) | Parameters (Byte) | Training Time(min) | Consumption (W) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| YOLOv5x | 98.30 | 95.24 | 98.05 | 86.2 M | 328.9 | 202.1 | 204.3 |
| YOLOv5l | 97.24 | 96.88 | 98.56 | 46.1 M | 197.0 | 192.2 | 107.8 |
| YOLOv5m | 97.41 | 96.33 | 98.50 | 20.9 M | 136.1 | 183.2 | 47.9 |
| YOLOv5s | 95.98 | 96.15 | 97.81 | 7.00 M | 72.6 | 174.5 | 15.9 |
| YOLOv5 + ViT(4) | 94.71 | 91.58 | 96.26 | 1.31 M | 55.6 | 155.7 | 1.1 |
| YOLOv5 + ViT(5) | 98.76 | 90.84 | 96.60 | 1.31 M | 46.7 | 151.9 | 1.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, F.; Luo, H.; Li, S.; Liu, Y.; Lin, B. Using Clean Energy Satellites to Interpret Imagery: A Satellite IoT Oriented Lightweight Object Detection Framework for SAR Ship Detection. Sustainability 2022, 14, 9277. https://doi.org/10.3390/su14159277
Xie F, Luo H, Li S, Liu Y, Lin B. Using Clean Energy Satellites to Interpret Imagery: A Satellite IoT Oriented Lightweight Object Detection Framework for SAR Ship Detection. Sustainability. 2022; 14(15):9277. https://doi.org/10.3390/su14159277
Chicago/Turabian StyleXie, Fang, Hao Luo, Shaoqian Li, Yingchun Liu, and Baojun Lin. 2022. "Using Clean Energy Satellites to Interpret Imagery: A Satellite IoT Oriented Lightweight Object Detection Framework for SAR Ship Detection" Sustainability 14, no. 15: 9277. https://doi.org/10.3390/su14159277
APA StyleXie, F., Luo, H., Li, S., Liu, Y., & Lin, B. (2022). Using Clean Energy Satellites to Interpret Imagery: A Satellite IoT Oriented Lightweight Object Detection Framework for SAR Ship Detection. Sustainability, 14(15), 9277. https://doi.org/10.3390/su14159277