
Using Explainable Artificial Intelligence to Identify Key Characteristics of Deep Poverty for Each Household

Abstract
:1. Introduction
- (1)
- A deep poverty identification model based on the latest XAI technologies is proposed. This model can provide higher identification performance and better explainability than traditional AI technologies.
- (2)
- A method that can identify important household characteristics associated with deep poverty for each rural household is developed.
- (3)
- Taking all poor households into consideration, common important characteristics that can be used to identify deeply poor households are specified, which include household income, disability, village attributes, lack of funds, labor force, disease, and number of household members,
- (4)
- A recent and validated dataset obtained from the field monitoring and investigation of poor households in 25 Chinese provinces in 2019 is prepared and utilized.
2. Related Work
2.1. Multidimensional Poverty
2.2. Traditional Poverty Identification Methods
2.3. Deep Poverty Identification
2.4. Explainable Artificial Intelligence (XAI) Technology
3. Materials and Methods
3.1. Data
3.2. Variables
- (1)
- There were four types of village attributes in this study: non-poor villages, out-of-poverty villages, poor villages, and extremely poor villages.
- (2)
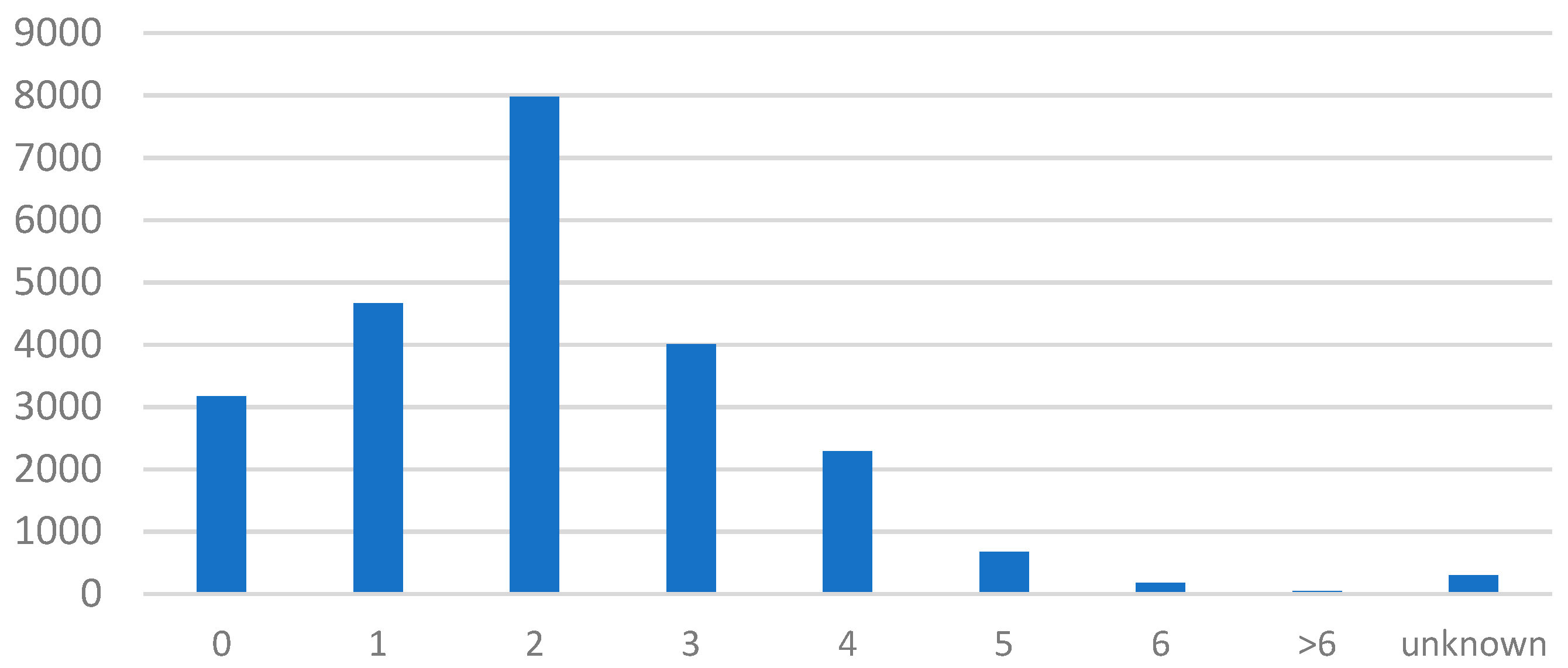
- Based on the number of household members, poor households were divided into four types of households: 1–2 persons, 3–4 persons, 5–6 persons, and households with more than 6 persons, with four-person households accounting for the largest proportion at 20.67%.
- (3)
- Based on the number of labor force participants in each family, poor households were divided into five types of households: 0 labor force, 1–2 labor force, 3–4 labor force, more than 4 labor force, and unknown, with two-laborer families accounting for the highest proportion at 34.24%.
- (4)
- According to the annual household income, poor households were divided into six types of families: less than CNY 10,000 (Chinese Yuan, 1 Chinese Yuan = 0.154 American Dollar), CNY 10,000–20,000, CNY 20,000–30,000, CNY 30,000–40,000, CNY 40,000–60,000, and more than CNY 60,000 income families.
- (5)
- From the reasons for being in poverty of poverty, we extracted thirteen recorded poverty factors, including death, marriage, study, disability, disaster, illness, lack of land, lack of technology, lack of water, lack of funds, inconvenient transportation, lack of self-development motivation, and other reasons.
3.3. The XAI-Based Model
3.3.1. Dependence Plot
3.3.2. Summary Bar Chart
3.3.3. Decision Plot
3.4. The Logistic Regression-Based Model and the Income-Based Model
3.5. Mutual Information
3.6. Receiver Operating Characteristic Curve (ROC Curve)
4. Results
4.1. Identification Accuracy of Our XAI-Based Model
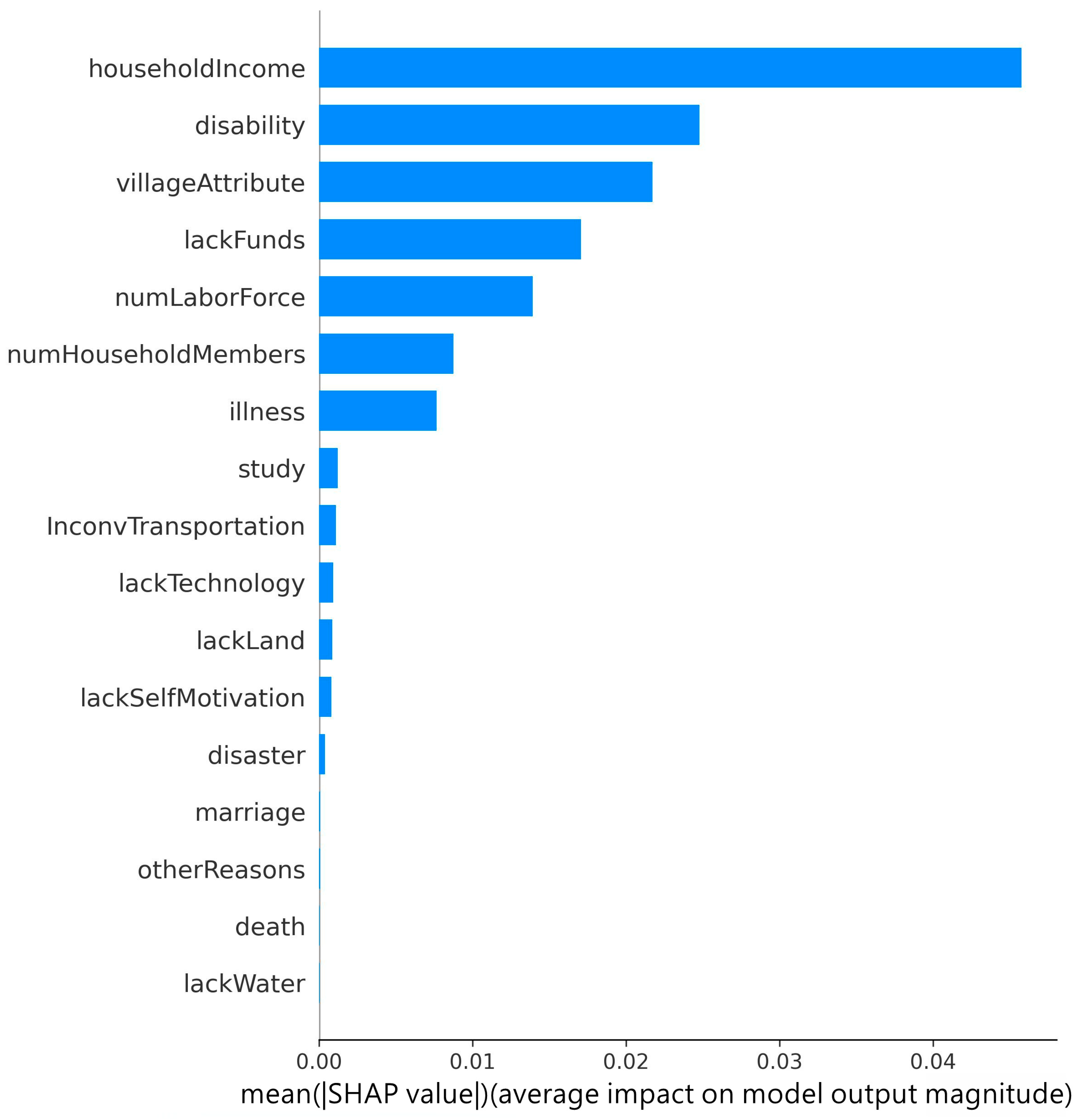
4.2. Common Important Household Characteristics Associated with Deep Poverty
4.3. The Impact of Different Values of Each Feature Variable on Deep Poverty Identification
4.3.1. Total Household Income
4.3.2. Disability
4.3.3. Village Attributes
4.3.4. Lack of Funds
4.3.5. Number of Labor Force Participants
4.3.6. Number of Household Members
4.3.7. Illness
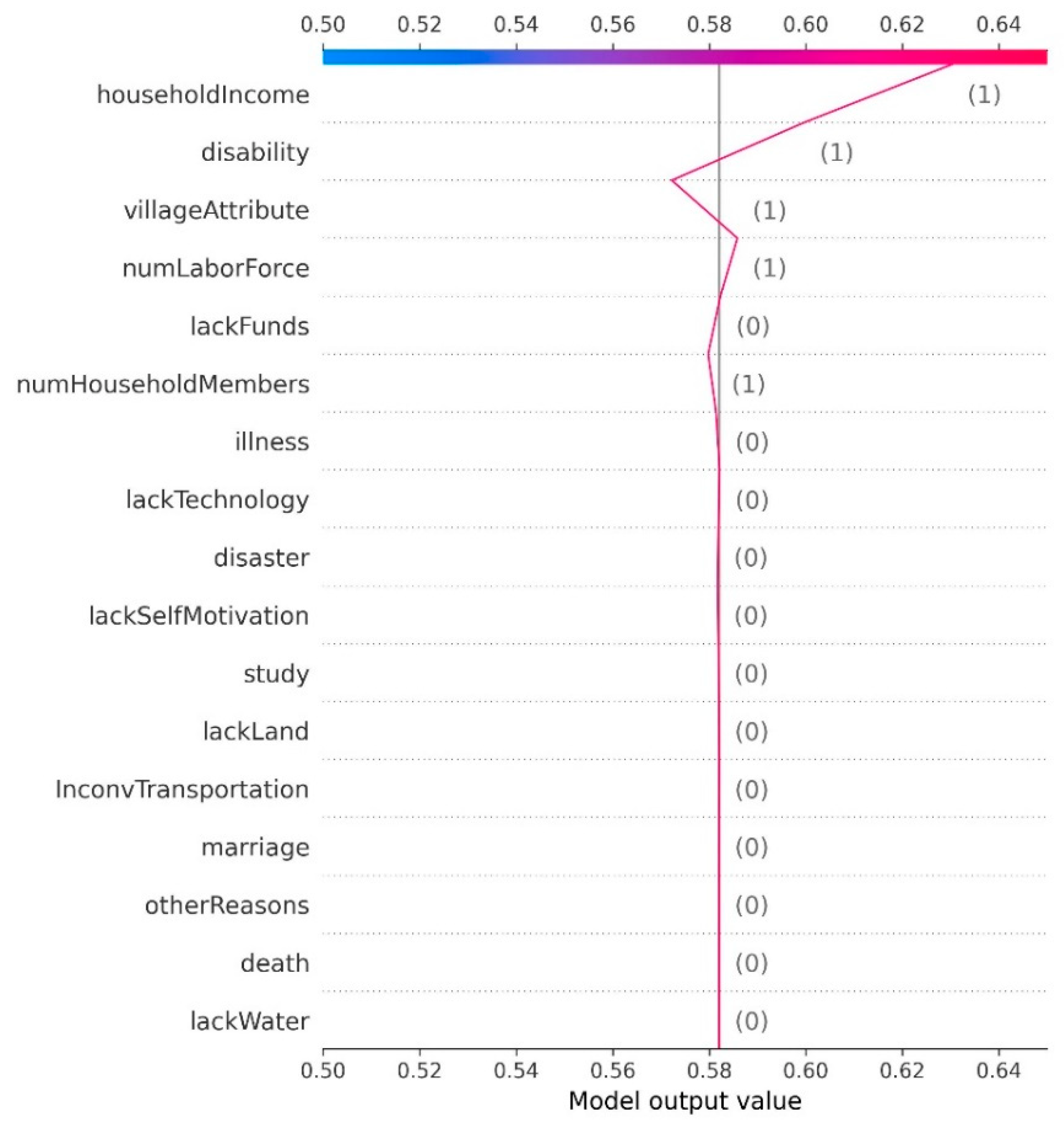
4.4. Key Characteristics Associated with Deep Poverty for Each Household
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- The United Nations Development Programme and Oxford Poverty and Human Development Initiative. Charting Pathways Out of Multidimensional Poverty: Achieving the SDGs; University of Oxford: Oxford, UK, 2020. [Google Scholar]
- Zhu, M.; Li, S. The Key to precise poverty alleviation rests in the precise identification of impoverished populations—An Analysis of the targeting effectiveness of China’s rural Dibao Program. Soc. Sci. China 2019, 40, 60–76. [Google Scholar]
- Golan, J.; Sicular, T.; Umapathi, N. Unconditional cash transfers in China: Who benefits from the rural minimum living standard guarantee (Dibao) program? World Dev. 2017, 93, 316–336. [Google Scholar] [CrossRef]
- Han, H.; Gao, Q. Protective effectiveness of Dibao in rural China: Empirical evidence from China panel studies. J. Public Manag. 2017, 14, 81–96. [Google Scholar]
- Wang, S.; Wang, T.; Wang, P. Identification of rural poor families in China. Agric. Tech. Econ. 2007, 1, 20–31. [Google Scholar]
- Peng, Q.; Xiao, R.; Chen, H. Targeted poverty alleviation and poverty identification—Based on the framework of signal game theory. Lan Zhou Xue Kan 2020, 12, 201–208. [Google Scholar]
- Chen, H.; Zhang, Q.H. Study on the accurate identification of poverty and accurate poverty alleviation based on multidimensional poverty measurement with the mountain area of Northern Guangdong as an example. J. Guangdong Univ. Financ. Econ. 2016, 3, 64–71. [Google Scholar]
- Lei, T.; Zhang, H. Multidimensional Poverty Measurement and Structural Decomposition in rural China—Empirical research Based on CFPS 2018. Soc. Secur. Stud. 2021, 4, 78–86. [Google Scholar]
- Li, X.; Gao, Q.; Tang, J. Who are identified as poor in rural China’s Targeted Poverty Alleviation Strategy? Applying the multidimensional capability approach. J. Chin. Political Sci. 2022, 2, 221–246. [Google Scholar] [CrossRef]
- Han, H.; Gao, Q. Community-based welfare targeting and political elite capture: Evidence from rural China. World Dev. 2019, 115, 145–159. [Google Scholar] [CrossRef]
- Khudri, M.M.; Chowdhury, F. Evaluation of socio-economic status of households and identifying key determinants of poverty in Bangladesh. Eur. J. Soc. Sci. 2017, 37, 377–387. [Google Scholar]
- Alkire, S.; Foster, J. Counting and multidimensional poverty. In OPHI Research in Progress 1a; University of Oxford: Oxford, UK, 2007. [Google Scholar]
- Gao, M. What kind of rural households are more prone to poverty—A multi-dimensional accurate identification of poverty from the perspective of family structure. Mod. Econ. Res. 2018, 2, 100–107. [Google Scholar]
- Azcarraga, A.; Setiono, R. Neural network rule extraction for gaining insight into the characteristics of poverty. Neural Comput. Appl. 2018, 30, 2795–2806. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Hoffman, R.R.; Klein, G. Explaining Explanation, Part 1: Theoretical Foundations. IEEE Intell. Syst. 2017, 32, 68–73. [Google Scholar] [CrossRef]
- Hoffman, R.R.; Mueller, S.T.; Klein, G. Explaining Explanation, Part 2: Empirical Foundations. IEEE Intell. Syst. 2017, 32, 78–86. [Google Scholar] [CrossRef]
- Liu, H.; Wang, C. On the Chinese rural poverty identification: Based on the hierarchical Logistic regression model. J. Agrotech. Econ. 2018, 2, 130–140. [Google Scholar]
- Tran, T.Q.; Thi Nguyen, H.T.; Hoang, Q.N.; Van Nguyen, D. The influence of contextual and household factors on multidimensional poverty in rural Vietnam: A multilevel regression analysis. Int. Rev. Econ. Financ. 2022, 78, 390–403. [Google Scholar] [CrossRef]
- Amartya, S. Inequality Reexamined; Oxford University Press: Oxford, UK, 1992. [Google Scholar]
- Amartya, S. Commodities and Capabilities, 2nd ed.; Oxford University Press: Oxford, UK, 1999. [Google Scholar]
- Alkire, S.; Santos, M.E. Measuring Acute Poverty in the Developing World: Robustness and Scope of the Multidimensional Poverty Index. World Dev. 2014, 59, 251–274. [Google Scholar] [CrossRef]
- World Bank. Poverty and Shared Prosperity 2018: Piecing Together the Poverty Puzzle; World Bank: Washington, DC, USA, 2018. [Google Scholar]
- Chen, K. Subjective poverty, deprivation, and the subjective well-being of children and young people: A multilevel growth curve analysis in Taiwan. Child. Youth Serv. Rev. 2020, 114, 105–145. [Google Scholar] [CrossRef]
- Deng, D.S.; Wang, Z.W. Targeting the object of minimum standard of living in the countryside under “Hard System” and “Soft Environment” background: A study based on data of rural residents in 33 county level cities and counties of 10 provinces. Chin. J. Popul. Sci. 2008, 5, 18–25+95. [Google Scholar]
- Handayani, L.; Rais, F.P. Analysis of factors affecting the level of poverty in Central Sulawesi. J. Phys. Conf. Ser. 2021, 1763, 012050. [Google Scholar] [CrossRef]
- Yeh, C.; Perez, A.; Driscoll, A.; Azzari, G.; Tang, Z.; Lobell, D.; Ermon, S.; Burke, M. Using publicly available satellite imagery and deep learning to understand economic well-being in Africa. Nat. Commun. 2020, 11, 2583. [Google Scholar] [CrossRef]
- Jalali, A.; Lonsdale, H.; Do, N.; Peck, J.; Gupta, M.; Kutty, S.; Ghazarian, S.R.; Jacobs, J.P.; Rehman, M.; Ahumada, L.M. Deep Learning for Improved Risk Prediction in Surgical Outcomes. Sci. Rep. 2020, 10, 9289. [Google Scholar] [CrossRef] [PubMed]
- Shrikumar, A.; Greenside, P.; Shcherbina, A.; Kundaje, A. Not just a black box: Learning important features through propagating activation differences. arXiv 2016, arXiv:1605.01713. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 10–14 December 2017. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Sundararajan, M.; Najmi, A. The many Shapley values for model explanation. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Janzing, D.; Minorics, L.; Blbaum, P. Feature relevance quantification in explainable AI: A causal problem. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 26–28 August 2020. [Google Scholar]
- Zhang, W.; Gong, Y.; Wu, Y. Targetedness Assessment of Assistance Measures based on Poverty Causes. Public Manag. Policy Rev. 2021, 4, 26–35. [Google Scholar]
- Zhang, M.H.; Dou, S.L. The Reproduction logic and comprehensive governance of deep poverty. Chin. Public Adm. 2018, 4, 44–50. [Google Scholar]
- Roth, A.E. The Shapley Value: Essays in Honor of Lloyd S. Shapley; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar]
- Shannon, C.E.; Weaver, W.; Wiener, N. The Mathematical Theory of Communication. Phys. Today 1950, 3, 31–32. [Google Scholar] [CrossRef]
- Swets, J.A. Measuring the accuracy of diagnostic systems. Science 1988, 240, 1285–1293. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, Y.; Gong, Y. Risk Prediction of Returning to Poverty and Analysis of Risk Factors for the Registered Poor Households: Based on the Data Obtained from the On-site Monitoring and Investigation of the Registered Poor Households in the 25 Provinces in 2019. Reform 2020, 12, 110–120. [Google Scholar]
- Tomašev, N.; Cornebise, J.; Hutter, F.; Mohamed, S.; Picciariello, A.; Connelly, B.; Belgrave, D.C.M.; Ezer, D.; Van Der Haert, F.C.; Mugisha, F.; et al. AI for social good: Unlocking the opportunity for positive impact. Nat. Commun. 2020, 11, 2468. [Google Scholar] [CrossRef] [PubMed]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Zhang, W. Targeting and identifying minimum Livelihood Guarantee families in poor rural areas. Impact Sci. Soc. 2010, 3, 36–39. [Google Scholar]
- Han, H.; Xu, Y. The Anti-poverty effectiveness of the minimum Living Standard Assistance Policy in rural China: Evidence from five central and western provinces. Econ. Rev. 2014, 55, 63–77. [Google Scholar]
- Babu, S.C.; Gajanan, S.N. Measurement and Determinants of Poverty—Application of Logistic Regression Models; Academic Press: San Diego, CA, USA, 2022. [Google Scholar]
- Wang, B.; Luo, Q.; Chen, G.; Zhang, Z.; Jin, P. Differences and dynamics of multidimensional poverty in rural China from multiple perspectives analysis. J. Geogr. Sci. 2022, 32, 1383–1404. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Province | Households |
|---|---|
| Shandong | 792 |
| Liaoning | 677 |
| Fujian | 318 |
| Hebei | 711 |
| Shanxi | 1093 |
| Inner Mongolia | 459 |
| Jilin | 333 |
| Heilongjiang | 463 |
| Anhui | 1068 |
| Jiangxi | 753 |
| Henan | 959 |
| Hubei | 1526 |
| Hunan | 1349 |
| Guangxi | 2143 |
| Hainan | 474 |
| Chongqing | 326 |
| Sichuan | 1329 |
| Guizhou | 1893 |
| Yunnan | 2062 |
| Shaanxi | 986 |
| Gansu | 1337 |
| Qinghai | 455 |
| Xinjiang | 1016 |
| Ningxia | 574 |
| Tibet | 211 |
| Feature Variables | Feature Values | Non-Deeply Poor Households | Deeply Poor Households |
|---|---|---|---|
| Number of household members | 1–2 | 3888 (66.90%) | 1924 (33.10%) |
| 3–4 | 7046 (80.32%) | 1726 (19.68%) | |
| 5–6 | 5488 (80.32%) | 1345 (19.68%) | |
| More than 6 | 1443 (76.35%) | 447 (23.65%) | |
| Number of labor force participants | 0 | 1858 (58.65%) | 1310 (41.35%) |
| 1–2 | 9651 (76.33%) | 2992 (23.67%) | |
| 3–4 | 5390 (85.53%) | 912 (14.47%) | |
| More than 4 | 748 (83.58%) | 147 (16.42%) | |
| unknown | 218 (72.91%) | 81 (27.09%) | |
| Disability | yes | 1,737 (60.15%) | 1151 (39.85%) |
| no | 16,128 (78.99%) | 4291 (21.01%) | |
| Lack of land | yes | 620 (72.94%) | 230 (27.06%) |
| no | 17,245 (76.79%) | 5212 (23.21%) | |
| Illness | yes | 5419 (71.70%) | 2139 (28.30%) |
| no | 12,446 (79.03%) | 3303 (20.97%) | |
| Lack of self-development motivation | yes | 1828 (78.42%) | 503 (21.58%) |
| no | 16,037 (76.45%) | 4939 (23.55%) | |
| Lack of technology | yes | 8459 (80.58%) | 2039 (19.42%) |
| no | 9406 (73.43%) | 3403 (26.57%) | |
| Inconvenient transportation | yes | 1736 (78.80%) | 467 (21.20%) |
| no | 16,129 (76.43%) | 4975 (23.57%) | |
| Study | yes | 2551 (80.93%) | 601 (19.07%) |
| no | 15,314 (75.98%) | 4841 (24.02%) | |
| Death | yes | 11 (68.75%) | 5 (31.25%) |
| no | 17,854 (76.66%) | 5437 (23.34%) | |
| Other reasons | yes | 122 (80.26%) | 30 (19.74%) |
| no | 17,743 (76.63%) | 5412 (23.37%) | |
| Disaster | yes | 451 (82.00%) | 99 (18.00%) |
| no | 17,414 (76.52%) | 5343 (23.48%) | |
| Lack of funds | yes | 6521 (84.43%) | 1203 (15.57%) |
| no | 11,344 (72.80%) | 4239 (27.20%) | |
| Lack of water | yes | 122 (84.14%) | 23 (15.86%) |
| no | 17,743 (76.60%) | 5419 (23.40%) | |
| Marriage | yes | 36 (90.00%) | 4 (10.00%) |
| no | 17,829 (76.63%) | 5438 (23.34%) | |
| Village attributes | Non-poor | 3041 (71.81%) | 1194 (28.19%) |
| Out-of-poverty | 4072 (87.93%) | 559 (12.07%) | |
| Poor | 10,703 (74.39%) | 3685 (25.61%) | |
| Extremely poor | 49 (92.45%) | 4 (7.55%) | |
| Total household income (CNY) | 1–10,000 | 1986 (59.43%) | 1356 (40.57%) |
| 10,001–20,000 | 4762 (71.54%) | 1894 (28.46%) | |
| 20,001–30,000 | 4415 (79.68%) | 1126 (20.32%) | |
| 30,001–40,000 | 2905 (84.52%) | 532 (15.48%) | |
| 40,001–60,000 | 2514 (86.93%) | 378 (13.07%) | |
| >60,000 | 1283 (89.16%) | 156 (10.84%) |
| Mutual Information | Rankings | Household Characteristics |
|---|---|---|
| 0.0335043 | 1 | Total household income |
| 0.0260108 | 2 | number of labor forces |
| 0.0149508 | 3 | village attributes |
| 0.0139923 | 4 | disability |
| 0.0127047 | 5 | lack of funds |
| 0.0125976 | 6 | number of household members |
| 0.0051454 | 7 | lack of technology |
| 0.0046409 | 8 | illness |
| 0.0012021 | 9 | study |
| 0.0002953 | 10 | disaster |
| 0.0002031 | 11 | lack of land |
| 0.0001986 | 12 | inconvenient transportation |
| 0.0001542 | 13 | lack of water |
| 0.000148 | 14 | marriage |
| 0.0001427 | 15 | lack of self-development motivation |
| 0.0000359 | 16 | other reasons |
| 0.0000161 | 17 | death |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Lei, T.; Gong, Y.; Zhang, J.; Wu, Y. Using Explainable Artificial Intelligence to Identify Key Characteristics of Deep Poverty for Each Household. Sustainability 2022, 14, 9872. https://doi.org/10.3390/su14169872
Zhang W, Lei T, Gong Y, Zhang J, Wu Y. Using Explainable Artificial Intelligence to Identify Key Characteristics of Deep Poverty for Each Household. Sustainability. 2022; 14(16):9872. https://doi.org/10.3390/su14169872
Chicago/Turabian StyleZhang, Wenguang, Ting Lei, Yu Gong, Jun Zhang, and Yirong Wu. 2022. "Using Explainable Artificial Intelligence to Identify Key Characteristics of Deep Poverty for Each Household" Sustainability 14, no. 16: 9872. https://doi.org/10.3390/su14169872
APA StyleZhang, W., Lei, T., Gong, Y., Zhang, J., & Wu, Y. (2022). Using Explainable Artificial Intelligence to Identify Key Characteristics of Deep Poverty for Each Household. Sustainability, 14(16), 9872. https://doi.org/10.3390/su14169872