1. Introduction
In the past, computers were primarily used for human–machine interaction, and communication was performed through keyboard and mouse. Automatic speech recognition (ASR) systems were developed to make them entirely usable for humans to communicate with computers through speech quickly [
1]. Real-life applications of ASR systems can be found in Amazon Alexa and Apple’s Siri [
2]. A variety of techniques have been used to build ASR systems today. In the ASR systems, the accuracy of the words is dependent on a variety of factors. These attributes include the speaker’s speech style, emotional state, age, male and female pitch, and the language’s international and regional accent [
3].
A low resource automatic speech recognition (ASR) system is beneficial for future sustainable native language interface development, emphasizing cultural and social sustainability. The research highlights, which include research questions (RQs) and the outcomes of the proposed work, are as mentioned below:
RQ1: How to develop an ASR system for a low resource database that makes efficient use of a native language-based system?
Outcome: This proposed work has contributed to building an ASR system for a native language (Punjabi) spoken in the northern region of India. The collected corpus helped in the development of a children’s ASR system.
RQ2: How to reduce the data scarcity issue that occurs due to less availability of training data?
Outcome: The data scarcity problem was solved by using an artificial data augmentation approach to enrich the training data while preserving default test data. Synthesized speech was augmented with an actual speech corpus. The artificial corpus enhancement is a solution for better computing performance of native language interface systems.
RQ3: How to identify key parameters that generate robust features in developing a children’s ASR system?
Outcome: This work employed MFCC feature extraction along with prosodic features to construct an efficient ASR system for children’s Punjabi speech using a Mel filter bank. The experiments were performed to verify the performance of the hybrid prosodic features applied on discriminative training models for Punjabi children’s speech to overcome the variability in children’s speech.
The first step in developing an ASR method is feature extraction, also known as the front-end technique, followed by acoustic modeling, which involves classification using language models as feedback [
4]. The fundamentals of ASR focus on the treatment of speech signals as stochastic patterns (after feature extraction) and stochastic pattern recognition techniques to generate hypothesis word sequences with the same probability as the input signal [
5]. In this machine learning approach, such as the Hidden Markov Model (HMM) (based on pattern recognition), only reference classes are included in the training processes, and they are treated separately [
6]. Despite these approaches, discriminative training methods include competing and reference classes. Class boundaries are more important to consider when optimizing classes. Due to the inherited groups’ sequence composition, implementing discriminative training to enforce ASR is a challenging problem. Discriminative approaches boost consistency in execution and analytical comparison [
7].
Along with discriminative techniques, improving the efficiency of the ASR systems, the front end is vital, as feature extraction is a necessary step that requires informative word parameters [
8]. In ASR, various feature-extraction techniques are available [
9]. Different speakers have different spoken utterance styles, or the language can be tonal where the tone on a syllable can change the meaning of the whole word [
10]. Prosodic features are extracted in addition to Mel Frequency Cepstral Coefficient (MFCC) features to catch pitch and tone-based features. The hybrid prosody features are voice probability, pitch (F0 gradient), intensity (energy), and loudness. Researchers have constructed children’s ASR systems to catch huge acoustic fluctuations. These prosodic features also capture psychological qualities, speaking style, and inter-speaker variances, whereas traditional feature-extraction algorithms capture phonetic components of a speech signal. Pitch features are essential in extracting the tonal aspects of a languages’ characteristics [
11].
While ASR systems for international languages are well established, establishing ASR systems for native languages remains a difficult challenge due to limited resources and a lack of corpora for these languages. Punjabi is a native language whose ASR system is in the development phase, and adult speech has been implemented for the Punjabi ASR system. No data are available for children’s Punjabi speech. The collection of manual data is a time-consuming and challenging task. Hence, a competent approach for artificial enhancement of the Punjabi speech corpus should be employed [
12]. In-domain augmentation occurs when the parameters of a speech corpus are altered using pitch modulation or time modulation and a new speech corpus is integrated with an existing corpus. The out- domain data augmentation occurs when speech is generated using a different technique or method and merged with the existing corpus [
13,
14]. Tacotron is a text-to-speech (TTS) system that takes text as input and produces synthesized speech that seems natural. Tacotron can be used to create a new speech corpus, enabling us to develop an augmented corpus [
15]. Tacotron is a single model that manages everything. Tacotron has four parts: the first is a front end for extracting linguistic parameters, the next is an acoustic prediction model, the part following is a duration model, and the last is a signal processing vocoder [
16].
Our Contribution: Much research has been conducted on English, but only Tamil and Hindi ASR systems have been developed for national languages. Since the speech corpus is still in its infancy, native language ASR systems are underdeveloped. Although Punjabi is one of India’s 22 national languages, and since the people of northern India speak Punjabi, there is a need for a Punjabi ASR system so that a more significant number of ASR applications can be available in Punjabi. In recent years, researchers have actively proposed adult ASR systems. The adult Punjabi speech corpus has been submitted to the research community. However, the children’s speech data corpus is still in the early stages of development; implementing and improving the performance of children’s ASR systems is a difficult task due to the variability in children’s speech. This work has contributed to the collection of a Punjabi children’s speech corpus to deploy Punjabi ASR for children. The collection of the speech corpus was carried out at various schools, which is a time-consuming process, and calculating utterances is a challenging task.
Further, the artificial corpus enhancement was performed using data augmentation techniques. This work employed MFCC feature extraction with prosodic features to construct an ASR system for children’s Punjabi speech. The MFCC and prosodic features were obtained, and the retrieved features were subsequently subjected to discriminative techniques. In order to satisfy the scarcity of speech corpus, new speech was synthesized using Tacotron, which was augmented with the children’s Punjabi speech corpus, and experiments were carried out by extracting prosodic features from the new augmented corpus.
The state-of-the-art on ASR and discriminative methodology is included in
Section 2. The theoretical history of prosodic features and discriminative strategies is covered in
Section 3. In
Section 4, the experimental setup is defined.
Section 5 describes the system overview, followed by the results, discussion, and comparison with the state-of-the-art in this domain in
Section 6.
Section 7 finally concludes.
2. Literature Review
In speech recognition, Dreyfus Graf of France represented the output of a six-band pass filter, and for determining transcription of the input signal, he traced the band filter output [
17]. Later in 1952, the Bell laboratory of the USA constructed the first ASR system. The system recognized telephonic digits when spoken regularly [
16]. In the 1960s, Japanese laboratories were fully active in speech recognition and constructed vowel recognition, phoneme recognizer, and digit recognizer systems [
18]. The implementations of word recognition were pushed off the rails in the 1980s, and people started to emphasize machine learning algorithms. The Defense Advanced Research Project Agency (DARPA) financed the research on speech interpretation in the United States. Carnegie Mellon University (CMU) developed a speech recognition technology in 1973 that could identify 1011 vocabulary words in a dataset. Algorithms of numerous forms were formulated and applied, such as template-based pattern recognition or explicit pattern recognition and later statistical modeling architectures in the 1980s. HMM models were used to perform rigorous statistical simulations. HMM has a double stochastic process, which includes several stochastic processes; hence, the term hidden is used in HMM name. In the 1990s, the HMM technique became popular.
B.H. Juang and L.R. Rabiner [
19] (1991) reviewed the statistical HMM model, and a consistent statistical framework was provided. The authors highlighted several aspects of the general HMM approach. In contrast, it demands further consideration to improve results in various applications, such as modeling parameters, especially the issue of minimal classification error, integration of new features and prior linguistic awareness, modeling of state durations, and their usage in speech recognition. A continuous-based and speaker-independent ASR system was introduced on SPHINX by Kai-Fu Lee et al. [
20]. The authors utilized the TRIM dataset provided by Texas Instruments, which utilized 80 teaching speakers and 40 research speakers, with 85 men and 35 women. The authors employed LPC function extraction and HMM acoustic simulation techniques. Word-based phone modeling and triphone modeling was performed. This work achieved an accuracy of 71%, 94%, and 96% on grammar, word pair grammar, and bigram grammar, which can be improved further. Xuedong Huang et al. [
21] designed SPHINX-II to cope with speaker and environment heterogeneity. SPHINX-II extracted speaker-normalized features from the corpus along with dynamic features. Authors utilized between-word triphone models, semi-continuous HMM models, and senons, and the overall model achieved better accuracy than SPHINX.
In [
22], feature extraction was performed in three stages: static feature extraction, normalization, and temporal information inclusion. The cepstral unconstrained monophony test revealed that MFCC outperformed PLP, cepstral mean subtraction. A comparative study of different feature-extraction techniques has been presented by Gupta and Gupta [
23]. The authors presented MFCC, Relative Spectral (RASTA), and Linear Predictive Coding (LPC), where MFCC outperformed the others. After MFCC feature extraction, Wang et al. [
24] used prosodic details and normalized feature parameters for tone- and pitch-related features to train a 3-layer feed-forward neural network and introduced the Parallel Phoneme Recognition followed by Language Modeling (PPRLM) system. The PPRLM system achieved an 86 percent classification rate. Furthermore, in [
25], the authors used the Gaussian Mixture Model (GMM) for classification and utilized various levels of speech features, such as phonetic, acoustic, and prosody. The authors presented tonal and non-tonal classifiers, including pitch extraction, pitch trimming, pitch smoothening, pitch shifting, and pitch speed measuring. The work was focused on the data collection problems; Tacotron, a text-to-speech synthesizer, was deployed to reduce data scarcity. Wang et al. [
15] proposed an end-to-end methodology that generated synthetic speech. The authors represented critical approaches for generic strategies, and the system obtained a 3.82 Mean Opinion Score (MOS) on a scale of 5. Skerry-Ryan et al. [
26] introduced an expanded Tacotron with latent embedding space of prosody. The output produced by the Tacotron represented prosodic information such as pitch and loudness. Shen et al. [
27] demonstrated a Tacotron system, a neural model. The authors used a recurrent network and predicted the Mel spectrogram of a given text. The system scored 4.53 MOS. Tacotron 2 was proposed by Yasuda et al. [
28], and it outperformed traditional systems. Self-attention was added to Tacotron 2, which captured pitch-related dependencies and improved the audio quality. Later in 2021, Hasija et al. [
14] presented the work on the Punjabi ASR system for children by extending the corpus of children’s speech by pre synthesizing new speech using a Tacotron text-to-speech model. The original corpus was combined with pre-synthesized speech, and it was fed into the ASR system, which exhibited a RI of 9% to 12%.
2.1. Discriminative Techniques Based ASR Systems
Researchers have developed ways to help ASR systems perform better in the recent past. Povey and Woodland [
29] researched discriminative techniques using a large vocabulary dataset. The authors defined and compared Lattice-based Maximum Mutual Information Estimation (MMIE) training to Frame Discrimination (FD). The effectiveness of MMIE and Maximum Likelihood Estimation (MLE) were also evaluated, and MMIE outperformed MLE. Povey and Woodland again [
30] conducted a study on the Minimum Word Error (MWE) and Minimum Phone Error (MPE) criteria for discriminative HMM training after the publication of MMIE. Further, the authors used I-smoothing and performed discriminative training. The Switchboard/Call Home telecommunications corpora were used in the experiments. The proposed method described a relative improvement of 4.8 percent.
Further, Povey et al. [
31] proposed a new approach called feature MPE (fMPE), which applied various functions on a feature to train millions of parameters. The authors implemented fMPE process in various phases, such as generation of high-dimensional features, an extension of the acoustic context, projection of features, and training of the feature matrix. The authors proved that it is a unique method for training feature matrixes. In [
31], the authors provided further improvements by releasing a new version of the MMI feature, which improved accuracy [
32] and probability routes with higher phone error owing to proper transcription enhanced in lattices. Additionally, it led to I-smoothing, which replaced I-smoothing to the maximum probability estimate to the preceding iteration’s frequency. These derived features were subjected to Vocal Tract Length Normalization (VTLN) and feature–space maximum likelihood linear regression (FMLLR), which improved the performance. The authors proved that the enhanced MMI approach produced more accurate results than the MPE technique.
2.2. Hybrid Front End Approach-Based Discriminative Techniques
In [
33], McDermott et al. applied the benefits of discriminative approaches, utilized the Minimum Classification Error (MCE) discriminative technique on HMM models, and proved a reduction of 7% to 20% in the error rate. Later, Vesely et al. [
34] developed frame-based cross-entropy and sequence discriminative MMI on DNN models [
29]. It was proved that the system was improved by 8% to 9% compared with prior studies. In [
35], Dua et al. reported their work on heterogeneous feature vectors, wherein the two feature-extraction approaches (MFCC and PLP) were hybridized, and signal features were retrieved using the MF-PLP methodology. MMIE and MPE methods were used to train acoustic models. The authors concluded that MF-PLP combined with MPE outperformed the other heterogeneous features and discriminative combinations. In [
36], Dua et al. investigated Differential Evaluation (DE) on Gammatone Frequency Cepstral Coefficient (GFCC) features and used discriminative approaches on acoustic models of datasets. The outcomes of discriminative approaches in clean and noisy environments were compared using MFCC and GFCC features. The authors concluded that the DE-based GFCC feature-extraction method combined with MPE training methodology produced better results in clean and noisy situations. After successfully using these methods for ASR in the Hindi language, the researchers were inspired to study discriminative methods on the Punjabi corpus. In [
37], Kaur and Kadyan presented their work on the Punjabi speech corpus and the implemented BMMI, fMMI, and fBMMI on a corpus, which resulted in a relative improvement of 26%. The work on discriminative methods for ASR systems is summarized in
Table 1.
The research in this paper aimed at elevating the infancy of children’s Punjabi speech corpus. A four-hour speech corpus was manually gathered, and artificial methods were used to enhance the corpus. Later, prosodic features were extracted to improve the system’s performance, as MFCC features alone were insufficient for capturing the variety of variations in children’s speech. Seven prosodic features were retrieved, and their impacts were investigated using discriminative techniques on a speech corpus. Integrated prosodic features were tested on a speech corpus afterward, results were analyzed, and performance was evaluated.
5. System Overview
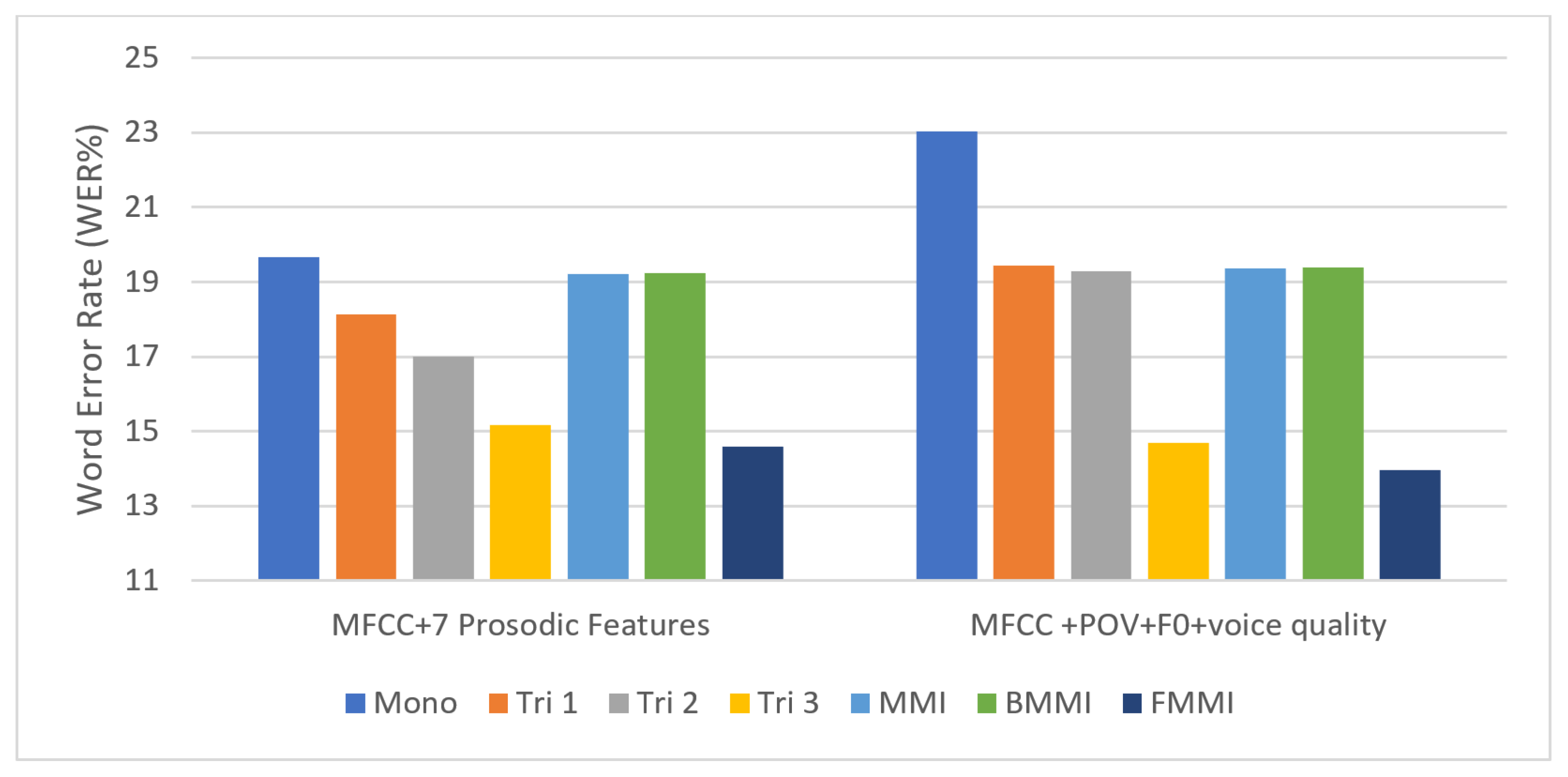
In the proposed system initially, the children’s speech corpus was fed into the feature-extraction module, which extracted MFCC features from the input signal. Using the MFCC technique, each frame’s energy parameters were collected, yielding 13 function coefficients. Each frame took 25 milliseconds to complete, with a 10-millisecond frameshift. Frame extraction used a Hamming window and a 23-channel Mel filter bank. After that, function coefficients were calculated using logarithm and DCT. MFCC features defined the instantaneous and spectral envelope shapes of a speech signal. Since MFCC features were insufficient, prosodic features were extracted as well. OpenSmile Toolkit and MATLAB were used to extract prosodic features. The extracted prosodic features were the probability of voicing (POV) (P1), F0 (P2), intensity (P3), loudness (P4), voice quality (P5), F0 raw (P6), and F0 envelope (P7). The extracted prosodic features were merged with MFCC features one by one and in combinations. These were fed to the ASR system, which employed discriminative techniques. MMI, BMMI, and FMMI are some of the discriminative methods used. Monophone (HMM) modeling was achieved when features were initially fed into the ASR framework. In Monophone modeling, acoustic vectors were incoming sequences; a word sequence W had to be found using probability P(W|A) and had to include constraints imposed by grammar. The Bayesian theorem was applied, and probability was calculated as shown in Equation (10):
The probability of a sequence of acoustic vector A to the given word sequence (referred to as an acoustic model trained on training input data) is represented by P(A|W). The second P(W) is the probability of word sequence given by the language model (LM). The language model is a text corpus that includes 1000 or 10,000 words. P(W|A) is a pattern recognition approach, and a number of techniques were used to compute the acoustic model of given input training data [
6]. Dynamic features of speech include MFCC feature trajectories over time. These trajectories were then estimated and combined with MFCC and prosodic coefficients to improve ASR results. Delta features were characteristics of trajectory paths. Following Monophone, delta features were utilized to achieve triphone modeling (tri 1). Delta features were computed as shown in Equation (11):
where
stands for delta coefficients computed on frame t,
and
for static coefficients, and N equals 2. Triphone simulation is achieved again for delta features, this time with delta-delta features, which are the time variant component of delta features (tri 2) and formula of computation, as mentioned in Equation (12):
Delta and delta-delta features were extracted, also known as the first and second derivatives of the speech signal. Following that, triphone simulation using the Maximum Likely Linear Transform (MLLT) and Linear Discriminative Analysis (LDA) was performed (tri 3). Linear Discriminative Analysis (LDA) was applied to the output of tri 2 to transform smaller volumes of acoustically distinct units, reducing the coefficient to a manageable 40 dimensions. Following the likelihood estimation, a new set of inputs was assigned to the new class, and the output class with the highest probability was chosen. The scatter matrix is computed in LDA as shown in Equation (13):
where sample class is represented by
,
represents the mean of ith class,
is the global mean, and T is the transpose of
[
38,
45]. The next step was to calculate the Maximum Likelihood Linear Transformation (MLLT), which was computed over utterances and excluded speaker-specific information. The system’s tri 3 modeling is LDA + MLLT [
46]. The tri 3 output was then used to evaluate MMI, BMMI, and fMMI. The dataset was trained using the MMI function, and then decoding was performed for two rounds. The BMMI implementation was achieved by adding a 0.5 boosting factor to the MMI. The learning rate factor was given a value of 0.0025, and the boosting factor was given a value of 0.1 during the implementation of fMMI. Discriminatively trained modules were then sent for decoding. Decoding is the process of identifying recorded test samples based on auditory features of words. For precise voice recognition, it uses training, acoustic, and language models. It decodes the feature vectors, same as the training module, to determine the most likely word sequence.
Figure 1 shows a block diagram of the implementation of discriminative techniques on the Punjabi children’s speech corpus using prosodic features.
The step-by-step procedure for the implementation of prosodic features on the discriminative technique is explained below, and the illustration of this methodology is shown in
Figure 2.
- Step 1:
Collection of original children’s Punjabi speech data (male/female of age group 7 to 13 years) corpus.
- Step 2:
Initialize: Segmentation and transcription of audios.
training_data = 1885 utterances from 2370 utterances
testing_data = 485 utterances from 2370 utterances
- Step 3:
Extraction of MFCC and prosody features from training and testing datasets as:
- A
mfcc(training_data) and mfcc(testing_data)
The Mel filter bank can process speech signals with linear or nonlinear distributions at various frequencies.
Additionally, f(t,i) (Fast Fourier Transformation) is computed as:
where i 0, 1, 2, 3, …, (N/2) − 1.
- B
prosody(training_data)and prosody(testing_data)
Applying prosodic feature extraction on the utterances of training and testing data set:
- i
To calculate the cue of F0 feature, autocorrelation function was used in the discrete function x[n] of speech signal on each 25 ms frame.
where
is the feature value of F0 raw at i frame of given speech utterance.
- ii
Cross-correlation function of two consecutive discrete function x[n] and y[n] of speech signal at each 25 ms frame is F0.
is the feature value of fundamental frequency at i frame of given speech utterance.
- iii
The POV is calculated from the pitch mean subtraction formula.
where ‘a’ is the F0 value of the frame. Approximation value of POV is:
- Step 4:
The extracted prosodic features are in matrix form and stored in a .xls file. There is one .xls file for each utterance, and features are extracted at every 25 ms frame. The MFCC features are combined with Prosodic features to form a single matrix using MATLAB. Later on, this single matrix is converted in .htk format for the Kaldi toolkit to proceed further.
[ml,f]=MFCC(ado,fs,‘z0Mp’,12,23,20e−3*fs,10e−3*fs, 0,0.5,0.97); //MFCC feature Matrix
PROm=dlmread(pro_f_name); // prosodic feature matrix where pro_f_name is prosody file name extracted using OpenSmile toolkit
MFPro=[ml Pros]; //New matrix having all features of MFCC and prosody
writehtk(output,MFPro,0.010,8198); // writing the file in .htk format which is kaldi supportive.
- Step 5:
-
Conduct monophone training (mono) and align monophone results using kaldi toolkit.
steps/train_mono.sh --nj $num_jobs --cmd $train_decode_cmd $taining_directory $language_directory exp/mono
where $num_jobs is the number of jobs of training data set,
$train_decode_cmd is run.pl file
$taining_directory is the training where the training utterances and training transcription is stored
$language_directory is the language model directory
exp/mono is the directory where the training model and the results of recognition are saved.
- Step 6:
-
Conduct delta training (tri 1) and align their phones.
steps/train_deltas.sh --cmd $train_decode_cmd 600 7000 $taining_directory $language_directory exp/mono_ali exp/tri1
where 600 is the number of senons and 7000 is the number of leaves used by train_delta.sh file for tri 1 modeling.
- Step 7:
-
Perform delta + delta training (tri 2) and also align their triphones.
steps/train_deltas.sh --cmd $train_decode_cmd 500 5000 $taining_directory $language_directory exp/tri1_ali exp/tri2
- Step 8:
-
Training of LDA + MLLT training (tri 3) on tri 2 output and aligning of their phones.
steps/train_lda_mllt.sh --cmd $train_decode_cmd 600 8000 $taining_directory $language_directory exp/tri2_ali/ exp/tri3
steps/align_fmllr.sh --nj “$train_nj” --cmd “$train_decode_cmd” $taining_directory $language_directory exp/tri3 exp/tri3_ali || exit 1
- Step 9:
-
Perform MMI training on tri 3 output.
steps/train_mmi.sh $taining_directory $language_directory exp/tri3_ali exp/tri3_denlats exp/tri3_mmi
- Step 10:
-
Perform BMMI training on tri 3.
steps/train_mmi.sh --boost 0.5 $taining_directory $language_directory r exp/tri3_ali exp/tri3_denlats exp/tri3_bmmi_0.5
- Step 11:
-
Conduct fMMI training on tri 3.
steps/train_mmi_fmmi.sh --learning-rate 0.0025 --boost 0.1 --cmd $train_decode_cmd $taining_directory $language_directory exp/tri3_ali exp/dubm3b exp/tri3_denlats exp/tri3b_fmmi_b
- Step 12:
-
Repeat steps 4 to 11 for each prosodic feature.
- Step 13:
-
Finally, performance is analyzed after comparing the results of three discriminative techniques on the number of prosody features combined with MFCC.
Further, the speech corpus was enhanced by artificially expanding the training dataset to improve the performance of both systems. The Punjabi children corpus was subjected to out-domain data augmentation. The ASR system received pre-synthesized speech from Tacotron, which was augmented with children’s speech. After augmenting, a speech corpus of 2032 utterances was produced. Prosodic features and MFCC features were also retrieved from the new enhanced corpus, and experiments were repeated for individual prosodic and integrated prosodic performance analysis. The scarcity of training data was removed by using an expanded corpus. This led to considerable performance improvement, as evidenced by experimental results. Furthermore, increasing the training complexity increased the training time while maintaining the original processing time.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}