
Thematic Analysis as a New Culturomic Tool: The Social Media Coverage on COVID-19 Pandemic in Italy

 , , , and
, , , and
Abstract
:1. Introduction
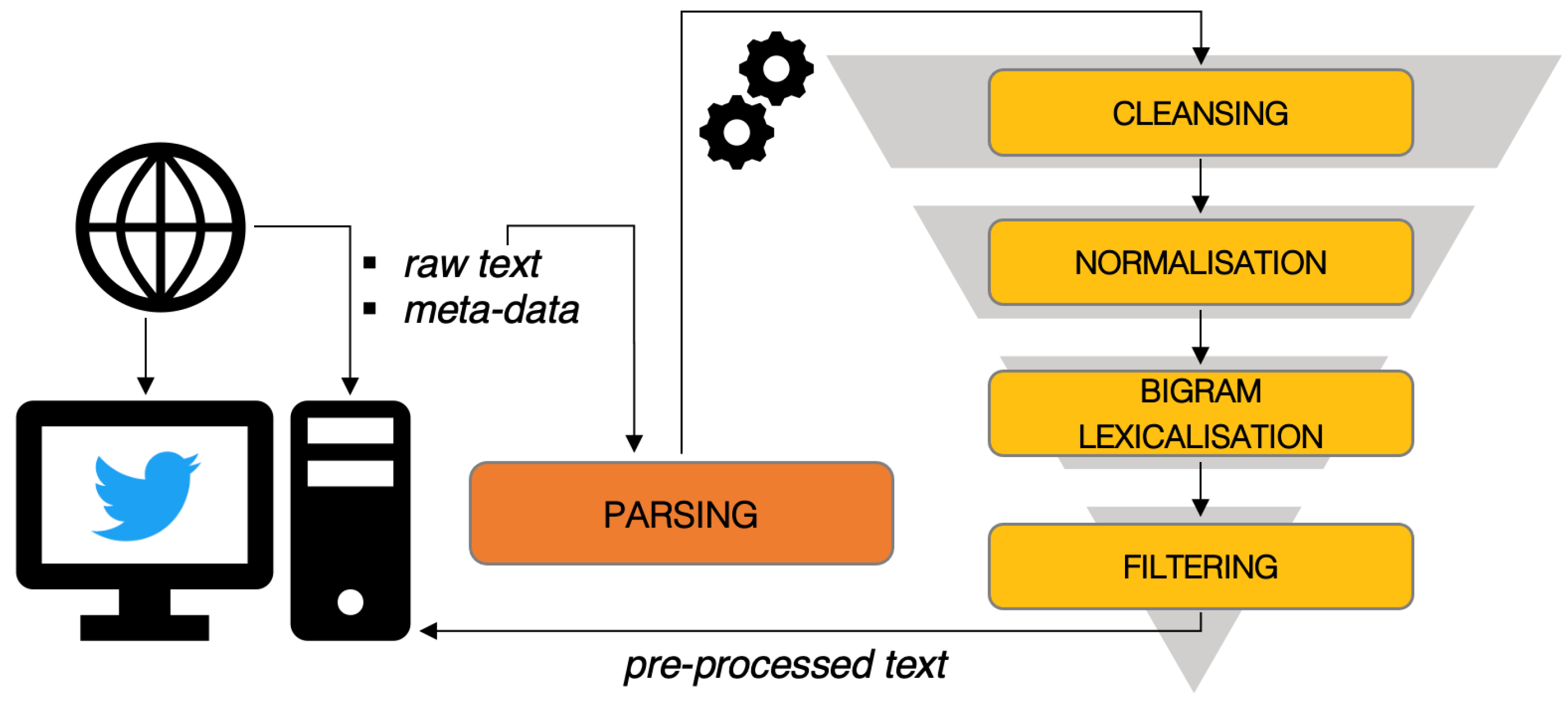
2. From Words to Figures and Back Again: A Statistical Approach to Topic Detection
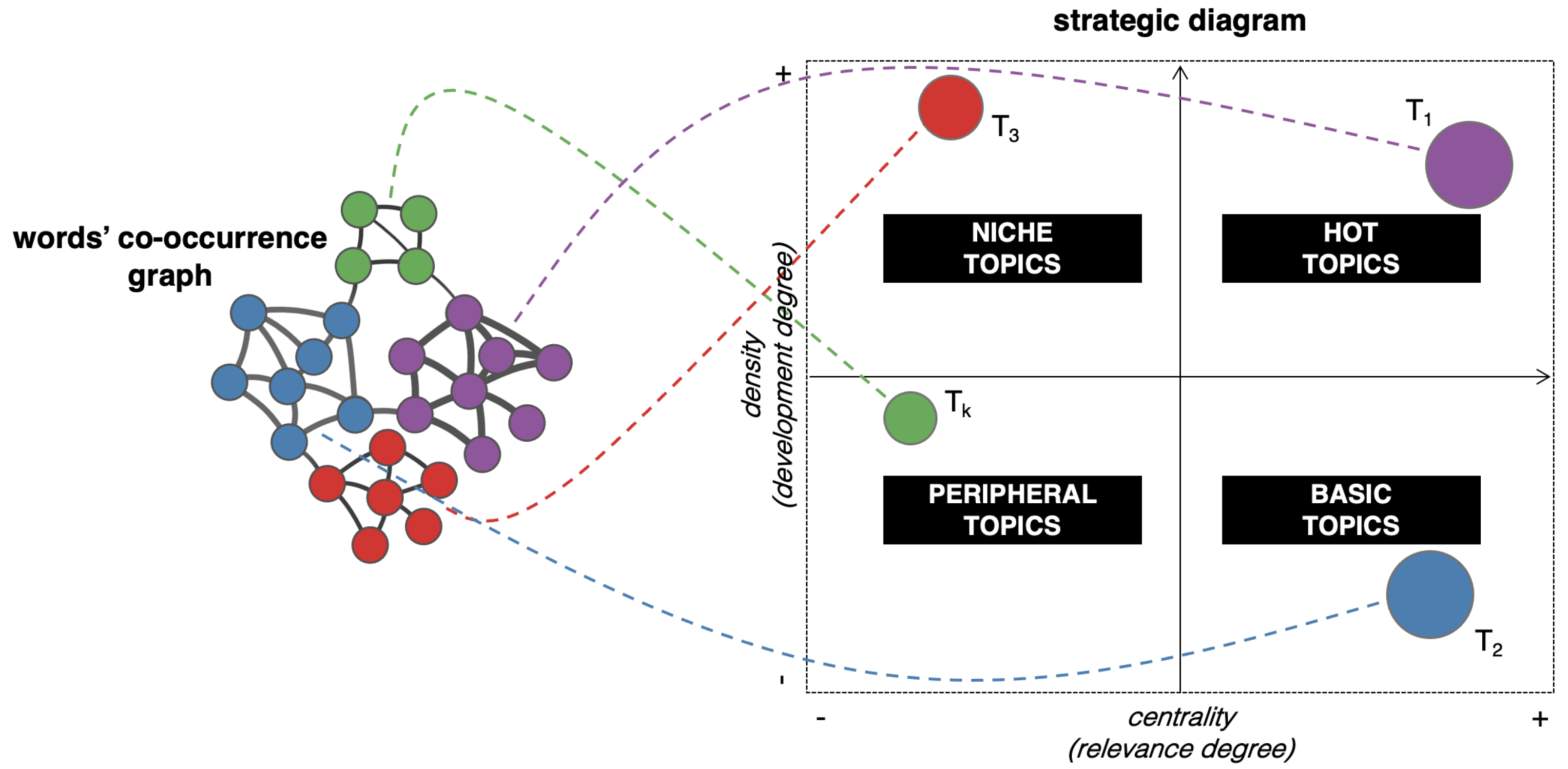
The Thematic Analysis Approach
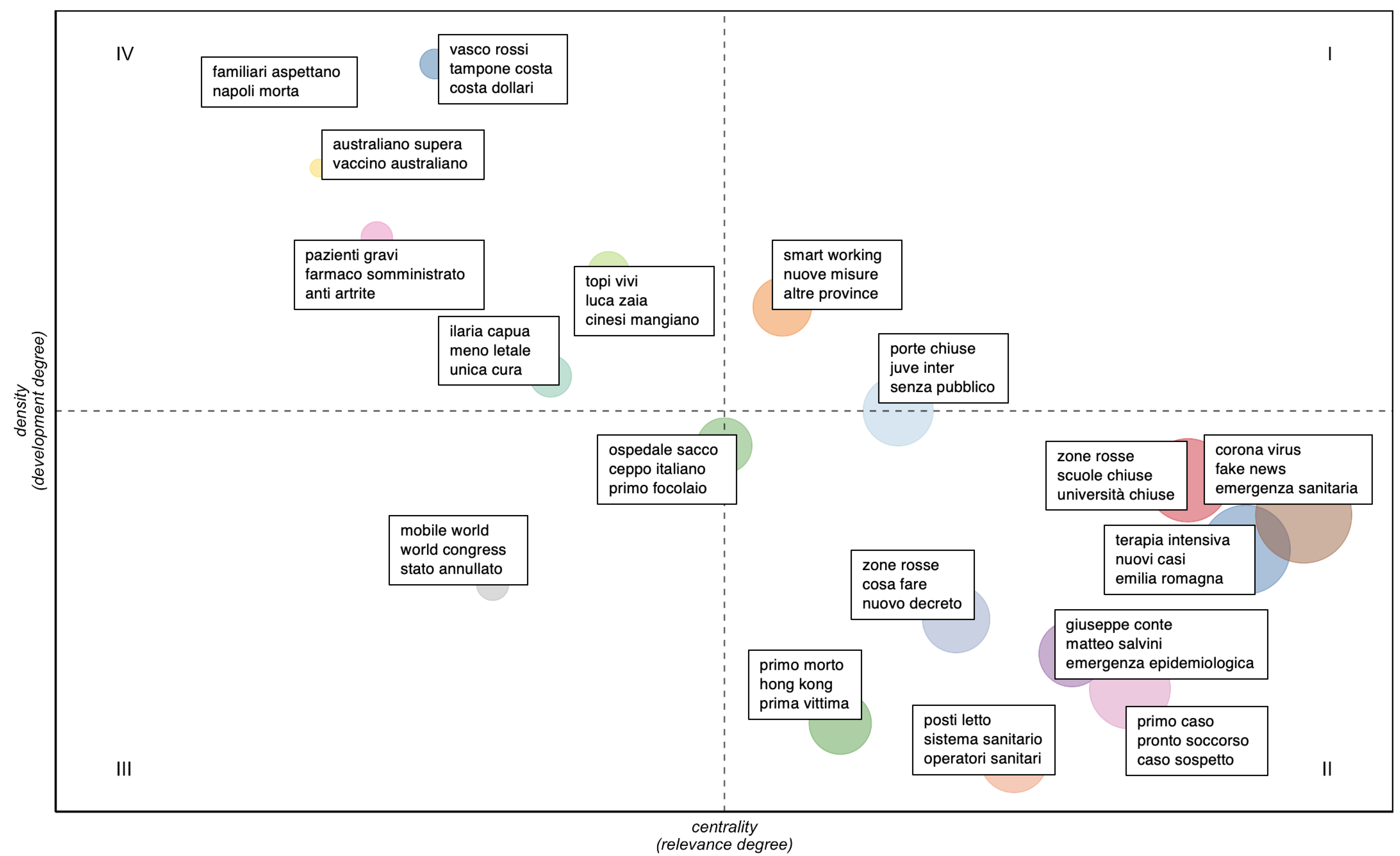
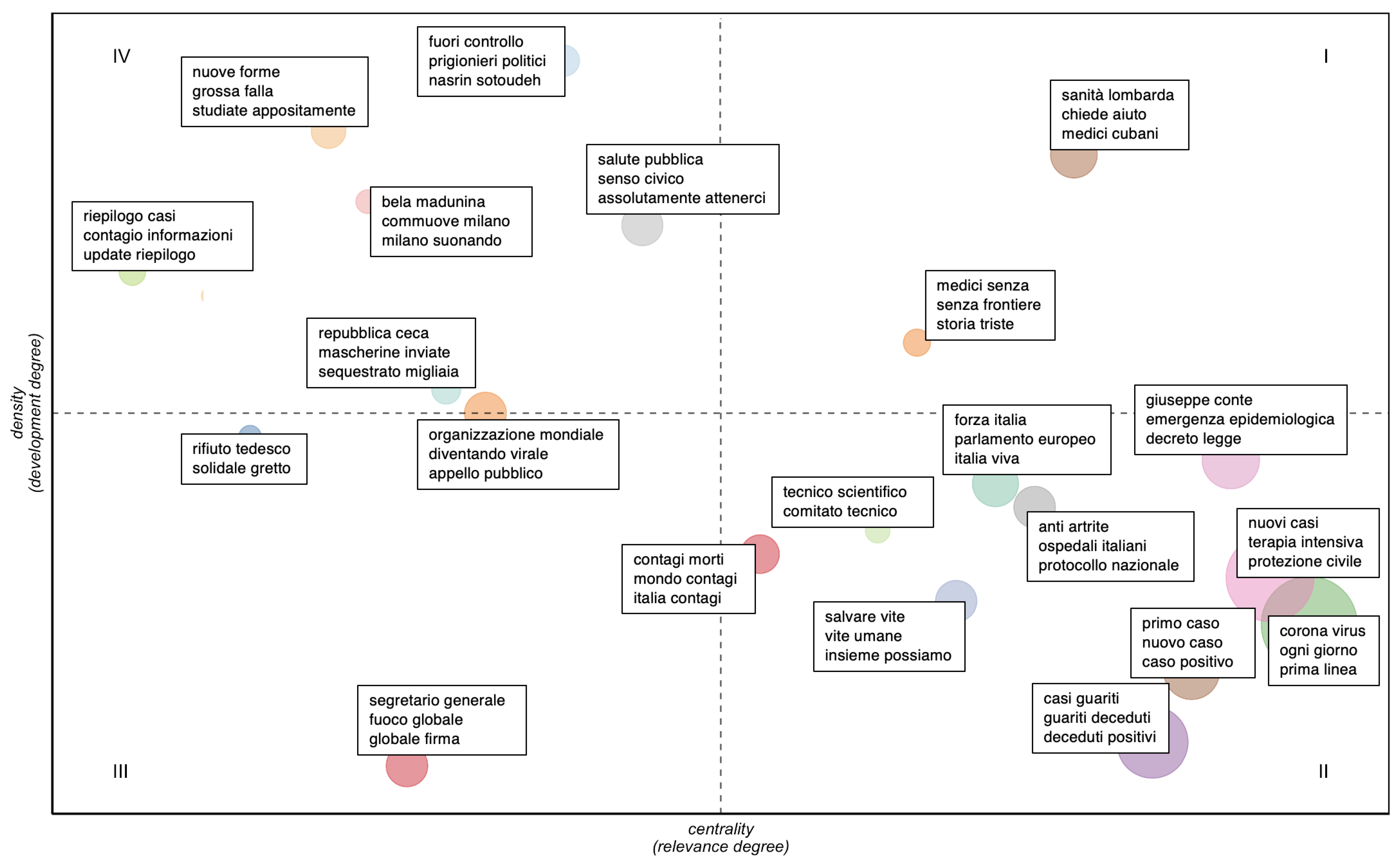
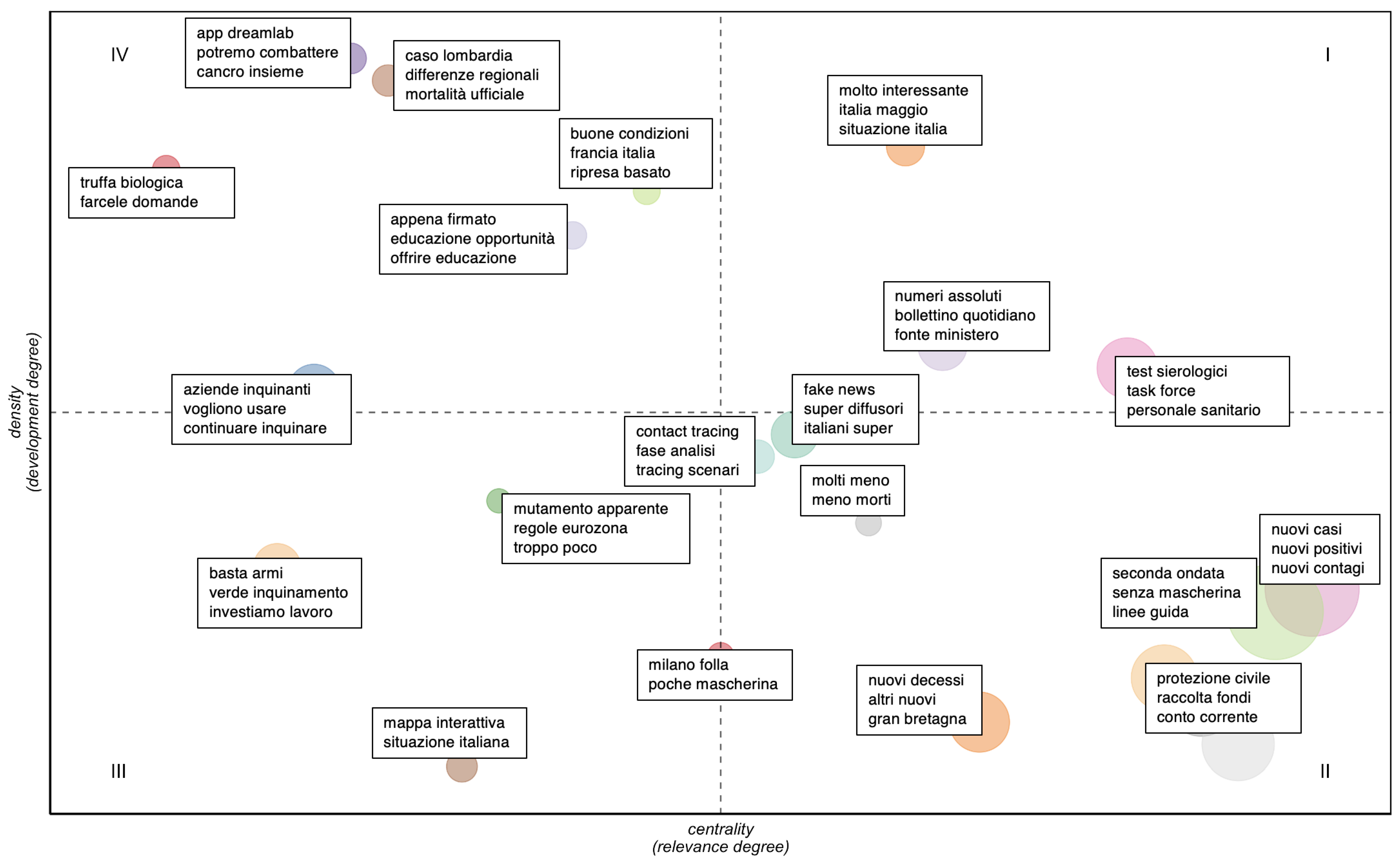
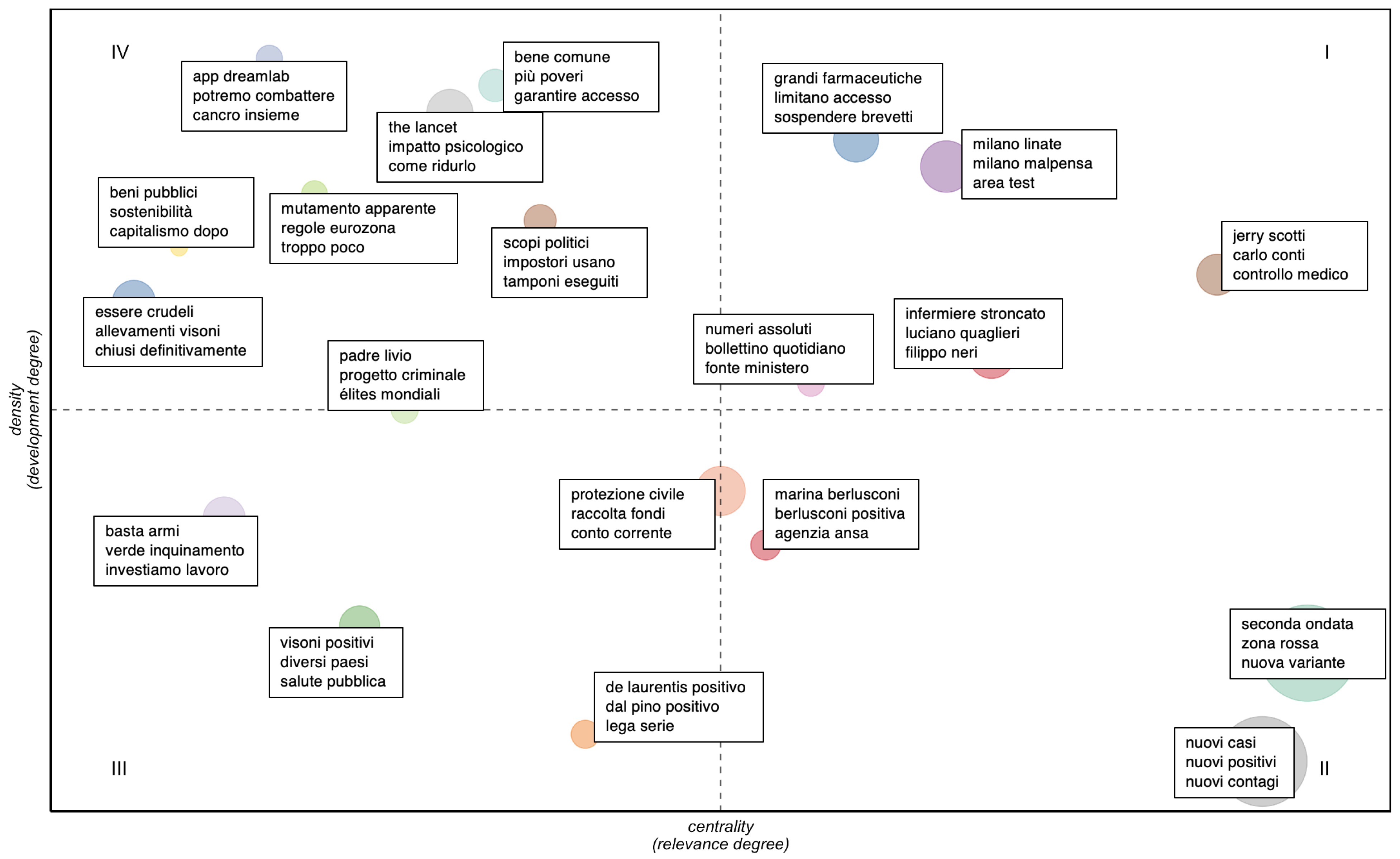
- higher values of centrality and density define the hot topics, well developed and relevant for structuring the conceptual framework of the domain;
- higher values of centrality and lower values of density define the basic topics, significant for the domain and cross-cutting to its different areas;
- lower values of centrality and density define peripheral topics, not fully developed or marginally interesting for the domain;
- lower values of centrality and higher values of density define niche topics, strongly developed but still marginal for the domain under investigation.
| Script: Thematic Analysis |
 |
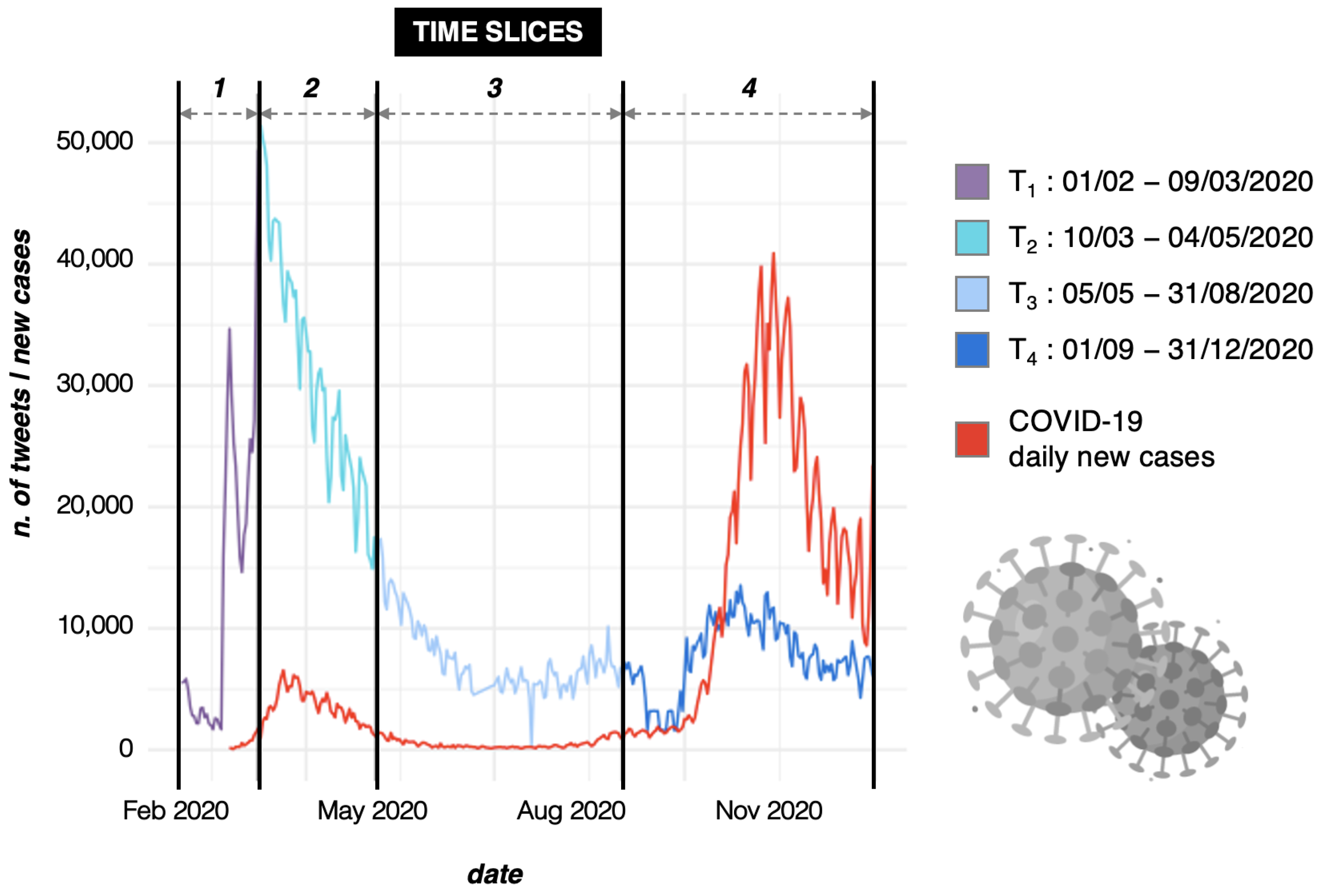
3. Analysis Setup and Main Findings of the Study
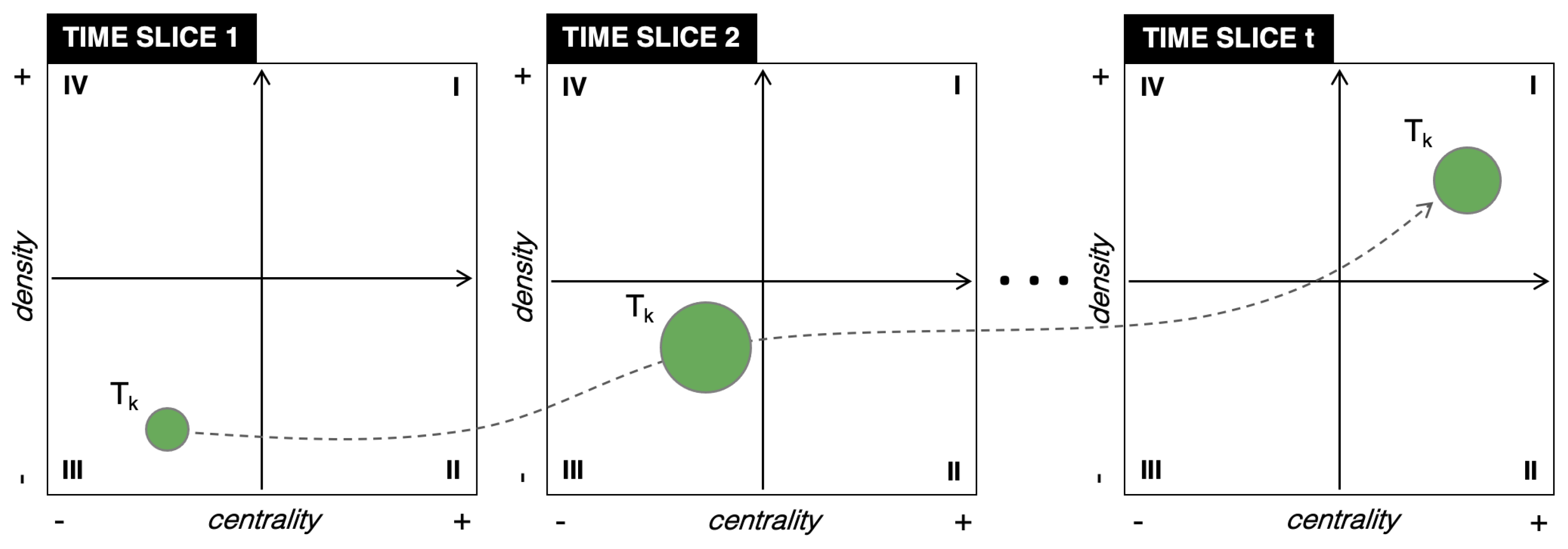
Mapping COVID-19 Topics and Tracking Their Evolution over 2020
4. Discussion
5. Conclusions and Final Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quadrant | Labels | |
|---|---|---|
| Italian | English | |
| I (hot topics) | smart working | smart working |
| nuove misure | new measures | |
| altre province | other provinces | |
| II (basic topics) | porte chiuse | closed-doors |
| juve inter | Juve Inter | |
| senza pubblico | without audience | |
| zona rossa | red zone | |
| scuole chiuse | closed schools | |
| università chiuse | closed universities | |
| corona virus | corona virus | |
| fake news | fake news | |
| emergenza sanitaria | health-care emergency | |
| terapia intensiva | critical care | |
| nuovi casi | new cases | |
| emilia romagna | Emilia Romagna | |
| zone rosse | red zones | |
| cosa fare | what to do | |
| nuovo decreto | new decree-law | |
| giuseppe conte | Giuseppe Conte | |
| matteo salvini | Matteo Salvini | |
| emergenza epidemiologica | epidemiological emergency | |
| primo morto | first death | |
| hong kong | Hong Kong | |
| prima vittima | first victim | |
| primo caso | first case | |
| pronto soccorso | emergency room | |
| caso sospetto | suspected case | |
| posti letto | beds | |
| sistema sanitario | health-care system | |
| operatori sanitari | health professionals | |
| III (peripheral topics) | ospedale sacco | Sacco Hospital |
| ceppo italiano | italian strain | |
| primo focolaio | first outbreak | |
| mobile world | Mobile World | |
| world congress | world congress | |
| stato annullato | been canceled | |
| IV (niche topics) | ilari capua | Ilaria Capua |
| meno letale | less-lethal | |
| unica cura | only cure | |
| topi vivi | live mice | |
| luca zaia | Luca Zaia | |
| cinesi mangiano | Chinese eat | |
| pazienti gravi | seriously ill patients | |
| farmaco somministrato | administered drug | |
| anti artrite | anti-arthritis | |
| australiano supera | Australian passed (the tests) | |
| vaccino australiano | Australian vaccine | |
| familiari aspettano | relatives are waiting | |
| napoli morta | Naples dead | |
| vasco rossi | Vasco Rossi | |
| tampone costa | swab expensive | |
| costa dollari | costs dollars | |
| Quadrant | Labels | |
|---|---|---|
| Italian | English | |
| I (hot topics) | sanità lombarda | Lombard health-care |
| chiede aiuto | ask for help | |
| medici cubani | Cuban doctors | |
| medici senza | doctors without | |
| senza frontiere | without borders | |
| storia triste | brief history | |
| II (basic topics) | giuseppe conte | Giuseppe Conte |
| emergenza epidemiologica | epidemiological emergency | |
| decreto legge | decree-law | |
| forza italia | Forza Italia | |
| parlamento europeo | European Parliament | |
| italia viva | Italia Viva | |
| tecnico scientifico | technical scientific | |
| comitato tecnico | technical committee | |
| anti artrite | anti-arthritis | |
| ospedali italiani | Italian hospitals | |
| protocollo nazionale | national protocol | |
| contagi morti | infection deaths | |
| mondo contagi | world infections | |
| italia contagi | Italy infections | |
| nuovi casi | new cases | |
| terapia intensiva | critical care | |
| protezione civile | civil protection | |
| salvare vite | save lives | |
| vite umane | human lives | |
| insieme possiamo | together we can | |
| primo caso | first case | |
| nuovo caso | new case | |
| caso positivo | positive case | |
| II (basic topics) | corona virus | corona virus |
| ogni giorno | every day | |
| prima linea | frontline | |
| casi guariti | recovered cases | |
| guariti deceduti | recovered deaths | |
| deceduti positivi | positive deaths | |
| III (peripheral topics) | segretario generale | Secretary General |
| fuoco globale | global fire | |
| globale firma | global signature | |
| rifiuto tedesco | german refusal | |
| solidale gretto | supportive petty | |
| organizzazione mondiale | world organisation | |
| diventando virale | becoming viral | |
| appello pubblico | public appeal | |
| IV (niche topics) | repubblica ceca | Czech Republic |
| mascherine inviate | face mask shipped | |
| sequestrato migliaia | seized thousands | |
| riepilogo casi | case summary | |
| contagio informazioni | infection information | |
| update riepilogo | update summary | |
| bela madunina | Bela Madunina | |
| commuove milano | touched Milan | |
| milano suonando | Milan performing | |
| salute pubblica | public health | |
| senso civico | citizenship | |
| assolutamente attenerci | adhere strictly | |
| nuove forme | new forms | |
| grossa falla | big gap | |
| studiate appositamente | specially designed | |
| fuori controllo | out of control | |
| prigionieri politici | political prisoner | |
| nasrin sotoudeh | Nasrin Sotoudeh | |
| Quadrant | Labels | |
|---|---|---|
| Italian | English | |
| I (hot topics) | molto interessante | very interesting |
| italia maggio | Italy May | |
| situazione italia | Italy situation | |
| numeri assoluti | absolute numbers | |
| bollettino quotidiano | daily bulletin | |
| fonte ministero | source ministry | |
| test sierologici | serology tests | |
| task force | task force | |
| personale sanitario | medical staff | |
| II (basic topics) | fake news | fake news |
| super diffusori | super spreader | |
| italiani super | Italians super | |
| contact tracing | contact tracing | |
| fase analisi | screening step | |
| tracing scenario | tracing scenario | |
| molti meno | many less | |
| meno morti | fewer deaths | |
| nuovi casi | new cases | |
| nuovi positivi | new infections | |
| nuovi contagi | new positives | |
| seconda ondata | second wave | |
| senza mascherina | without mask | |
| linee guida | guidelines | |
| nuovi decessi | new deaths | |
| altri nuovi | other new | |
| gran bretagna | Great Britain | |
| protezione civile | civil protection | |
| raccolta fondi | fundraising | |
| conto corrente | bank account | |
| III (peripheral topics) | milano folla | Milan crowd |
| poche mascherina | few masks | |
| mappa interattiva | interactive map | |
| situazione italiana | Italy situation | |
| basta armi | stop guns | |
| verde inquinamento | green pollution | |
| investiamo lavoro | investing employment | |
| mutamento apparente | apparent change | |
| regole eurozona | Eurozone rules | |
| troppo poco | too little | |
| IV (niche topics) | aziende inquintanti | polluting industries |
| vogliono usare | plan to use | |
| continuare inquinare | continue polluting | |
| appena firmato | just signed | |
| educazione opportunità | education opportunity | |
| offrire educazione | offer education | |
| truffa biologica | biological fraud | |
| farcele domande | asking us questions | |
| buone condizioni | good condition | |
| francia italia | France Italy | |
| ripresa basato | recovery based | |
| caso lombardia | Lombardy case | |
| differenze regionali | regional differences | |
| mortalità ufficiale | official mortality | |
| app dreamlab | dreamlab app | |
| potremo combattere | we could fight | |
| cancro insieme | cancer together | |
| Quadrant | Labels | |
|---|---|---|
| Italian | English | |
| I (hot topics) | grandi farmaceutiche | big pharmaceutical |
| limitano accesso | limit access | |
| sospendere brevetti | suspend patents | |
| milano linate | Milan Linate | |
| milano malpensa | Milan Malpensa | |
| area test | area test | |
| jerry scotti | Jerry Scotti | |
| carlo conti | Carlo Conti | |
| controllo medico | medical check | |
| infermiere stroncato | nurse struck | |
| luciano quaglieri | Luciano Quagliari | |
| filippo neri | Filippo Neri | |
| numeri assoluti | absolute numbers | |
| bollettino quotidiano | daily bulletin | |
| fonte ministero | source ministry | |
| II (basic topics) | marina barlusconi | Marina Berlusconi |
| berlusconi positiva | Berlusconi positive | |
| agenzia ansa | ANSA agency | |
| seconda ondata | second wave | |
| zona rossa | red zone | |
| nuova variante | new variant | |
| nuovi casi | new cases | |
| nuovi positivi | new positives | |
| nuovi contagi | new infections | |
| III (peripheral topics) | protezione civile | civil protection |
| raccolta fondi | fundraising | |
| conto corrente | bank account | |
| de laurentis positivo | De Laurentis positive | |
| del pino positivo | Del Pino positive | |
| lega serie | League serie | |
| visioni positivi | positive minks | |
| diversi paesi | several countries | |
| salute pubblica | public health | |
| basta armi | stop guns | |
| verde inquinamento | green pollution | |
| investiamo lavoro | investing employment | |
| IV (niche topics) | padre livio | Father Livio |
| progetto criminale | crime design | |
| élites mondiali | world elite | |
| essere crudeli | be cruel | |
| allevamenti visioni | mink farms | |
| chiusi definitivamente | permanently closed | |
| scopi politici | political ends | |
| impostori usano | impostors use | |
| tamponi eseguiti | performed swabs | |
| mutamento apparente | apparent change | |
| regole eurozona | Eurozone rules | |
| troppo poco | too little | |
| IV (niche topics) | beni pubblici | public goods |
| sostenibilità | sustainability | |
| capitalismo dopo | capitalism after | |
| the lancet | The Lancet | |
| impatto psicologico | psychological impact | |
| come ridurlo | how to reduce it | |
| bene comune | common good | |
| più poveri | more poor | |
| garantire accesso | ensure access | |
| app dreamlab | dreamlab app | |
| potremo combattere | we could fight | |
| cancro insieme | cancer together | |
References
- World Health Organization. WHO Director-General’s Opening Remarks at the Media Briefing on COVID-19. Available online: https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19---11-march-2020 (accessed on 15 January 2022).
- Platto, S.; Wang, Y.; Zhou, J.; Carafoli, E. History of the COVID-19 pandemic: Origin, explosion, worldwide spreading. Biochem. Biophys. Res. Commun. 2021, 538, 14–23. [Google Scholar] [CrossRef] [PubMed]
- Taylor, L.H.; Latham, S.M.; Woolhouse, M.E. Risk factors for human disease emergence. Philos. Trans. R. Soc. Lond. B: Biol. Sci 2001, 356, 983–989. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, A.L. On the origins of SARS-CoV-2. Nat. Med. 2021, 27, 9. [Google Scholar] [CrossRef] [PubMed]
- Westerman, D.; Spence, P.R.; Van Der Heide, B. Social Media as information source: Recency of updates and credibility of information. J. Comput.-Mediat. Commun. 2014, 19, 171–183. [Google Scholar] [CrossRef] [Green Version]
- Pulido, C.M.; Ruiz-Eugenio, L.; Redondo-Sama, G.; Villarejo-Carballido, B. A New Application of Social Impact in Social Media for Overcoming Fake News in Health. Int. J. Environ. Res. Public Health 2020, 17, 2430. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cinelli, M.; Quattrociocchi, W.; Galeazzi, A.; Valensise, C.M.; Brugnoli, E.; Schmidt, A.L.; Zola, P.; Zollo, F.; Scala, A. The COVID-19 social media infodemic. Sci. Rep. 2020, 10, 16598. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Liu, W.; Yoganathan, V.; Osburg, V.-S. COVID-19 information overload and generation Z’s social media discontinuance intention during the pandemic lockdown. Technol. Forecast. Soc. Chang. 2021, 166, 120600. [Google Scholar] [CrossRef] [PubMed]
- Aiden, E.; Michel, J.-B. Uncharted: Big Data as a Lens on Human Culture; Riverhead Books: New York, NY, USA, 2013. [Google Scholar]
- Michel, J.-B.; Shen, Y.K.; Aiden, A.P.; Veres, A.; Gray, M.K.; Pickett, J.P.; Hoiberg, D.; Clancy, D.; Norvig, P.; Orwant, J.; et al. Quantitative analysis of culture using millions of digitized books. Science 2011, 331, 176–182. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boyd, D.; Crawford, K. Critical Questions for Big Data: Provocations for a Cultural, Technological, and Scholarly Phenomenon. Inf. Commun. Soc. 2012, 15, 662–679. [Google Scholar] [CrossRef]
- Ibrahim, R.; Elbagoury, A.; Kamel, M.S.; Karray, F. Tools and approaches for topic detection from Twitter streams: Survey. Knowl. Inf. Syst. 2018, 54, 511–539. [Google Scholar] [CrossRef]
- Misuraca, M.; Spano, M. Unsupervised analytic strategies to explore large document collections. In Text Analytics. Advances and Challenges; Iezzi, D.F., Mayaffre, D., Misuraca, M., Eds.; Springer: Heidelberg, Germany, 2020; pp. 17–28. [Google Scholar]
- Sayyadi, H.; Raschid, L. A graph analytical approach for topic detection. ACM Trans. Internet Technol. 2013, 13, 1–23. [Google Scholar] [CrossRef]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. An approach for detecting, quantifying, and visualising the evolution of a research field: A practical application to the fuzzy sets theory field. J. Infometr. 2011, 5, 146–166. [Google Scholar] [CrossRef]
- Loh, S.; Palazzo, M.; de Oliveira, J.; Leite Gastal, F. Knowledge discovery in textual documentation: Qualitative and quantitative analyses. J. Doc. 2001, 57, 577–590. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Asher, N. Discourse topic. Theor. Ling. 2004, 30, 163–201. [Google Scholar] [CrossRef]
- Wartena, C.; Brussee, R. Topic Detection by Clustering Keywords. In Proceedings of the 19th International Workshop on Database and Expert Systems Applications, Turin, Italy, 1–5 September 2008; pp. 54–58. [Google Scholar]
- Balbi, S.; Misuraca, M.; Spano, M. A Two-Step Strategy for Improving Categorisation of Short Texts. In Proceedings of the 14th International Conference on Statistical Analysis of Textual Data, Rome, Italy, 12–15 June 2018; pp. 60–67. [Google Scholar]
- Benzécri, J. Histoire et Préhistoire de L’analyse des Données; Dunod: Paris, France, 1982. [Google Scholar]
- Lebart, L.; Salem, A.; Berry, L. Exploring Textual Data; Kluwer: Dordrecht, The Netherlands, 1988. [Google Scholar]
- Deerwester, S.; Dumais, S.; Furnas, G.; Landauer, T.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Arabie, P.; Hubert, L. Advances in Cluster Analysis Relevant to Marketing Research. In From Data to Knowledge. Studies in Classification, Data Analysis, and Knowledge Organization; Gaul, W., Pfeifer, D., Eds.; Springer: Heidelberg, Germany, 1996; pp. 3–19. [Google Scholar]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Yan, X.; Guo, J.; Lan, Y.; Cheng, X. A Biterm Topic Model for Short Texts. In Proceedings of the 22nd International Conference on World Wide Web, Rio De Janeiro, Brazil, 13–17 May 2013; pp. 1445–1456. [Google Scholar]
- Griffiths, T.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 5228–5235. [Google Scholar] [CrossRef] [Green Version]
- Carley, K. Network Text Analysis: The network position of concepts. In Text Analysis For The Social Sciences; Roberts, C.W., Ed.; Routledge: New York, NY, USA, 1997; pp. 79–102. [Google Scholar]
- Popping, R. Computer-Assisted Text Analysis; Sage: London, UK, 2000. [Google Scholar]
- Lim, K.; Karunasekera, S.; Harwood, A. ClusTop: A clustering-based topic modelling algorithm for twitter using word networks. In Proceedings of the 2017 IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017; pp. 2009–2018. [Google Scholar]
- Misuraca, M.; Scepi, G.; Spano, M. A network-based concept extraction for managing customer requests in a social media care context. Int. J. Inf. Manag. 2020, 51, 101956. [Google Scholar] [CrossRef]
- Agüero-Torales, M.M.; Vilares, D.; López-Herrera, A.G. Discovering topics in Twitter about the COVID-19 outbreak in Spain. Proces. Leng. Nat. 2021, 66, 177–190. [Google Scholar]
- Comito, C. How COVID-19 information spread in US The Role of Twitter as Early Indicator of Epidemics. IEEE Trans. Serv. Comput. 2021, 1–12. [Google Scholar] [CrossRef]
- Jang, H.; Rempel, E.; Roth, D.; Carenini, G.; Janjua, N.Z. Tracking COVID-19 Discourse on Twitter in North America: Infodemiology Study Using Topic Modeling and Aspect-Based Sentiment Analysis. J. Med. Internet Res. 2021, 23, e25431. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez, I.; Guevara, J.A.; Gómez, D.; Castro, J.; Espínola, R. Community Detection Problem Based on Polarization Measures: An Application to Twitter: The COVID-19 Case in Spain. Mathematics 2021, 9, 443. [Google Scholar] [CrossRef]
- Lamsal, R. Design and analysis of a large-scale COVID-19 tweets dataset. Appl. Intell. 2021, 51, 2790–2804. [Google Scholar] [CrossRef] [PubMed]
- van Eck, N.; Waltman, L. How to normalise co-occurrence data? An analysis of some well-known similarity measures. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 1635–1651. [Google Scholar]
- Egghe, L. On the relation between the association strength and other similarity measures. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 1502–1504. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Algesheimer, R.; Tessone, C.J. A comparative analysis of community detection algorithms on artificial networks. Sci. Rep. 2016, 6, 30750. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Callon, M.; Courtial, J.P.; Laville, F. Co-word analysis as a tool for describing the network of interactions between basic and technological research—The case of polymer chemistry. Scientometrics 1991, 22, 155–205. [Google Scholar] [CrossRef]
- Basile, V.; Caselli, T. 40twita 1.0: A Collection of Italian Tweets during the COVID-19 Pandemic. Available online: http://twita.di.unito.it/dataset/40wita (accessed on 10 December 2021).
- Basile, V.; Lai, M.; Sanguinetti, M. Long-term Social Media Data Collection at the University of Turin. In Proceedings of the Fifth Italian Conference on Computational Linguistics, Turin, Italy, 10–12 December 2018; Available online: http://ceur-ws.org/Vol-2253/paper48.pdf (accessed on 10 December 2021).
- Pelagatti, M.; Maranzano, P. Assessing the effectiveness of the Italian risk-zones policy during the second wave of COVID-19. Health Policy 2021, 125, 1188–1199. [Google Scholar] [CrossRef] [PubMed]
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Aria, M.; Misuraca, M.; Spano, M. Mapping the evolution of social research and data science on 30 years of Social Indicators Research. Soc. Indic. Res. 2020, 149, 803–831. [Google Scholar] [CrossRef]
- Bull, M. The Italian government response to Covid-19 and the making of a prime minister. Contemp. Ital. Politics 2021, 13, 149–165. [Google Scholar] [CrossRef]
- Zammitti, A.; Imbrogliera, C.; Russo, A.; Zarbo, R.; Magnano, P. The Psychological Impact of Coronavirus Pandemic Restrictions in Italy. The Mediating Role of the Fear of COVID-19 in the Relationship between Positive and Negative Affect with Positive and Negative Outcomes. Eur. J. Investig. Health Psychol. Educ. 2021, 11, 697–710. [Google Scholar] [CrossRef]
- Boccia Artieri, G.; Greco, F.; La Rocca, G. The construction of the meanings of #coronavirus on Twitter: An analysis of the initial reactions of the Italian people. Int. Rev. Sociol. 2021, 31, 287–309. [Google Scholar]
- De Santis, E.; Martino, A.; Rizzi, A. An Infoveillance System for Detecting and Tracking Relevant Topics From Italian Tweets During the COVID-19 Event. IEEE Access 2020, 8, 132527–132538. [Google Scholar] [CrossRef]
- Entman, R.M. Framing: Towards clarification of a fractured paradigm. J. Commun. 1993, 43, 51–58. [Google Scholar] [CrossRef]
- López-Rabadán, P. Framing Studies Evolution in the Social Media Era. Digital Advancement and Reorientation of the Research Agenda. Soc. Sci. 2022, 11, 9. [Google Scholar] [CrossRef]
- Valenzuela, S.; Piña, M.; Ramírez, J. Behavioral Effects of Framing on Social Media Users: How Conflict, Economic, Human Interest, and Morality Frames Drive News Sharing. J. Commun. 2017, 67, 803–826. [Google Scholar] [CrossRef]
- Tahamtan, I.; Potnis, D.; Mohammadi, E.; Miller, L.E.; Singh, V. Framing of and Attention to COVID-19 on Twitter: Thematic Analysis of Hashtags. J. Med. Internet Res. 2021, 23, e30800. [Google Scholar] [CrossRef] [PubMed]
- Wicke, P.; Bolognesi, M.M. Framing COVID-19: How we conceptualize and discuss the pandemic on Twitter. PLoS ONE 2020, 15, e0240010. [Google Scholar] [CrossRef]
- Ophir, Y.; Walter, D.; Arnon, D.; Lokmanoglu, A.; Tizzoni, M.; Carota, J.; D’Antiga, L.; Nicastro, E. The Framing of COVID-19 in Italian Media and Its Relationship with Community Mobility: A Mixed-Method Approach. J. Health Commun. 2021, 26, 161–173. [Google Scholar] [CrossRef]
- Wang, D.; Mao, Z. From risks to catastrophes: How Chinese Newspapers framed the Coronavirus Disease 2019 (COVID-19) in its early stage. Health Risk Soc. 2021, 23, 93–110. [Google Scholar] [CrossRef]
- Caldarelli, G.; De Nicola, R.; Petrocchi, M.; Pratelli, M.; Saracco, F. Flow of online misinformation during the peak of the COVID-19 pandemic in Italy. EPJ Data Sci. 2021, 10, 34. [Google Scholar] [CrossRef] [PubMed]
- Guarino, S.; Pierri, F.; Di Giovanni, M.; Celestini, A. Information disorders during the COVID-19 infodemic: The case of Italian Facebook. Online Soc. Netw. Media 2021, 22, 100124. [Google Scholar] [CrossRef] [PubMed]
- Posetti, J.; Bontcheva, K. Disinfodemic. Deciphering COVID-19 Disinformation. Policy Brief 1, UNESCO. Available online: https://en.unesco.org/sites/default/files/disinfodemic_deciphering_covid19_disinformation.pdf (accessed on 24 January 2022).
- Autorità per le Garanzie nelle Comunicazioni. Osservatorio Sulle Comunicazioni n. 1/2021. Available online: https://www.agcom.it/documents/10179/22666659/Documento+generico+22-04-2021/30bb16e2-adb6-4de0-b1f5-4a4df2d8ec24?08February2022version=1.1 (accessed on 24 January 2022).
- Datareportal. Digital 2020: Italy. Available online: https://datareportal.com/reports/digital-2020-italy (accessed on 24 January 2022).








| Time Slice | N. of Tweets | Avg. Tweets per Day | Relative Std. Deviation |
|---|---|---|---|
| : 1/2/2020–9/3/2020 | 517,508 | 13,619 | 0.927 |
| : 10/3/2020–4/5/2020 | 1,744,975 | 30,614 | 0.314 |
| : 5/5/2020–31/8/2020 | 845,484 | 7617 | 0.393 |
| : 1/9/2020–31/12/2020 | 938,338 | 7629 | 0.381 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aria, M.; Cuccurullo, C.; D’Aniello, L.; Misuraca, M.; Spano, M. Thematic Analysis as a New Culturomic Tool: The Social Media Coverage on COVID-19 Pandemic in Italy. Sustainability 2022, 14, 3643. https://doi.org/10.3390/su14063643
Aria M, Cuccurullo C, D’Aniello L, Misuraca M, Spano M. Thematic Analysis as a New Culturomic Tool: The Social Media Coverage on COVID-19 Pandemic in Italy. Sustainability. 2022; 14(6):3643. https://doi.org/10.3390/su14063643
Chicago/Turabian StyleAria, Massimo, Corrado Cuccurullo, Luca D’Aniello, Michelangelo Misuraca, and Maria Spano. 2022. "Thematic Analysis as a New Culturomic Tool: The Social Media Coverage on COVID-19 Pandemic in Italy" Sustainability 14, no. 6: 3643. https://doi.org/10.3390/su14063643
APA StyleAria, M., Cuccurullo, C., D’Aniello, L., Misuraca, M., & Spano, M. (2022). Thematic Analysis as a New Culturomic Tool: The Social Media Coverage on COVID-19 Pandemic in Italy. Sustainability, 14(6), 3643. https://doi.org/10.3390/su14063643