
A Traffic Parameter Extraction Model Using Small Vehicle Detection and Tracking in Low-Brightness Aerial Images

Abstract
:1. Introduction
- (1)
- Data enhancement. This paper extends the low-brightness aerial image dataset by using data enhancement strategies, such as the slicing-aided hyper inference (SAHI) algorithm, coordinate correction matrix, HSV perturbation, and brightness enhancement, which enhance the robustness and generalization ability of the model in detecting small targets with complex backgrounds.
- (2)
- Model optimization. In this paper, an improved YOLOX-IM vehicle detection algorithm is proposed. In order to balance the detection efficiency and accuracy, the model incorporates the ultra-lightweight subspace attention module (ULSAM) in the path aggregation network (PAN). In addition, in order to achieve a lightweight model, the boundary regression loss function is optimized, and the SIoU loss function is used to optimize the model, making the boundary regression faster and more accurate.
- (3)
- Field experiment verification. The YOLOX-IM object detection model is connected with the DeepSort target tracking model, and then a vehicle speed estimation algorithm is fused to construct a UAV-based traffic parameter extraction model. In this study, experimental vehicles equipped with global navigation satellite systems (GNSS) and on-board diagnostics (OBD) in particular are used, to collect real traffic parameters to verify the accuracy and applicability of the proposed model. In addition, the effect of UAV flight altitudes on traffic parameter extraction accuracy is analyzed.
2. Baseline Model and Dataset Processing
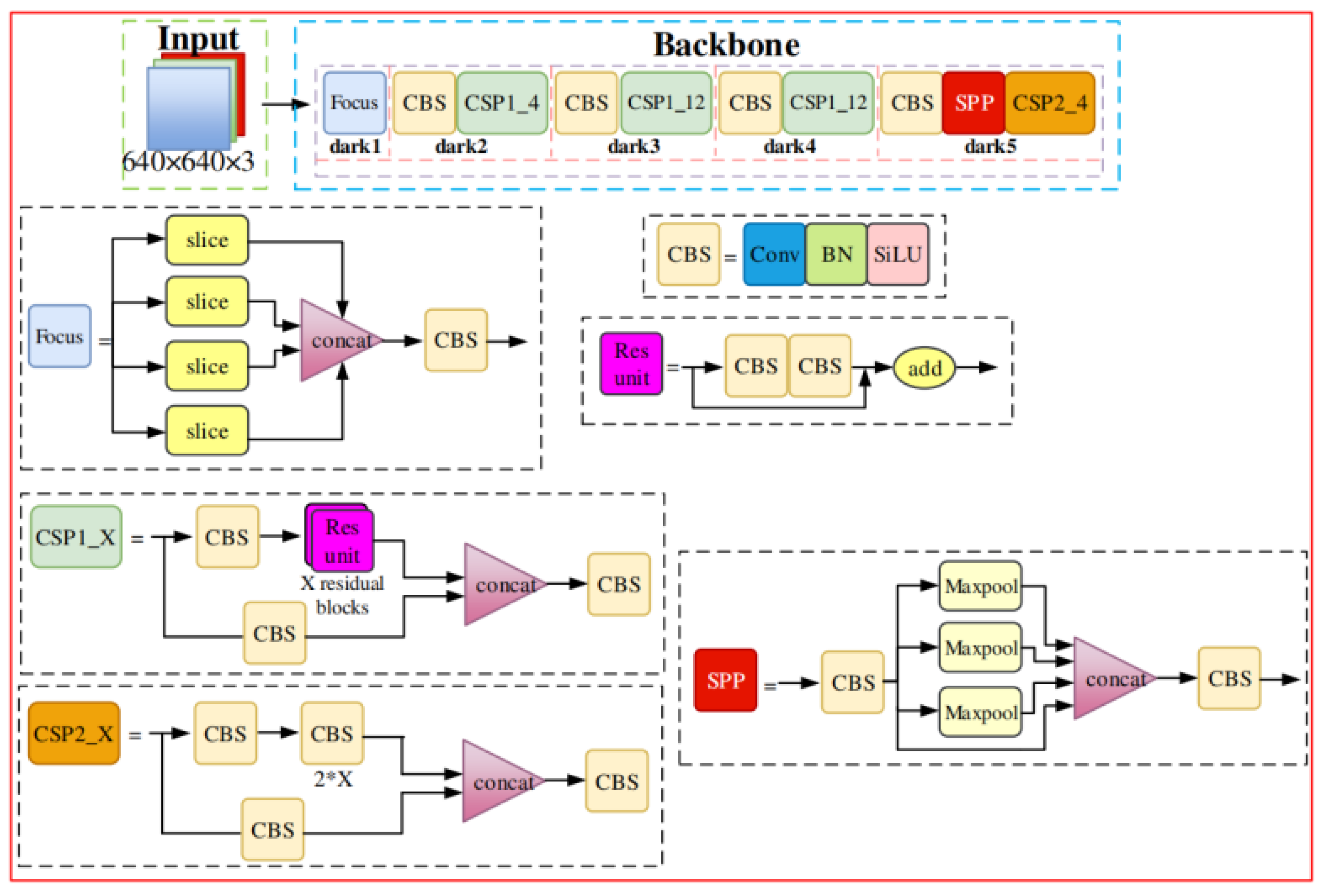
2.1. YOLOX-s Model
2.2. Processing Strategy for Aerial Image Dataset
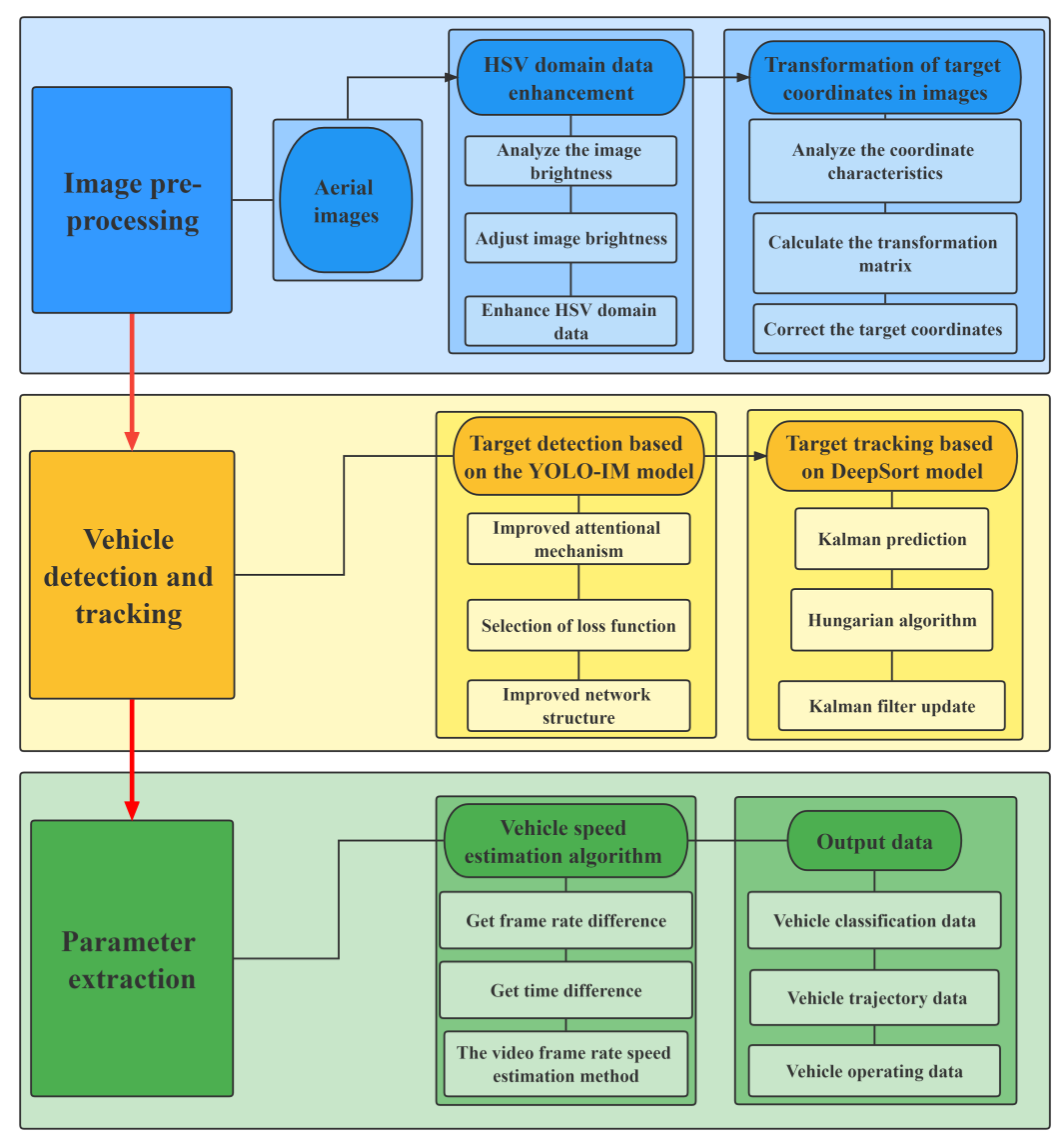
3. Traffic Parameter Extraction Methods and Material
3.1. Image Pre-Processing
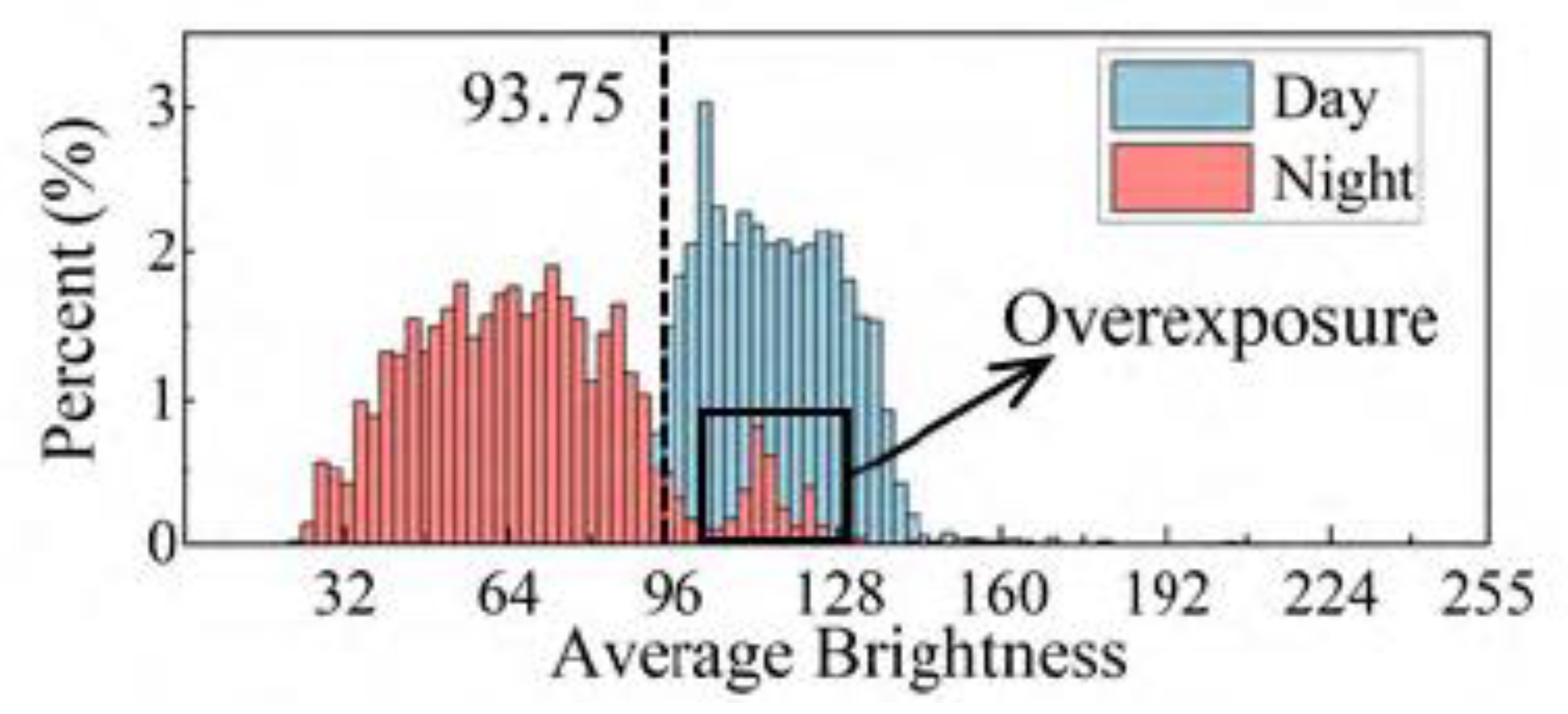
3.1.1. HSV Domain Data Enhancement
3.1.2. Transformation of Target Coordinates in Images
3.1.3. Small Target Data Enhancement Strategy
3.2. Improvement in Object Detection Model
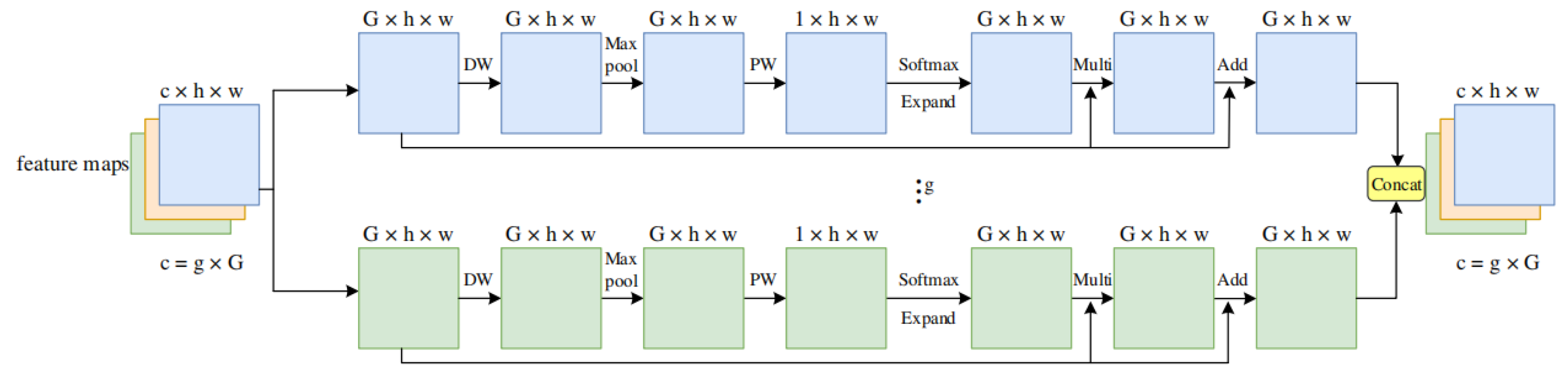
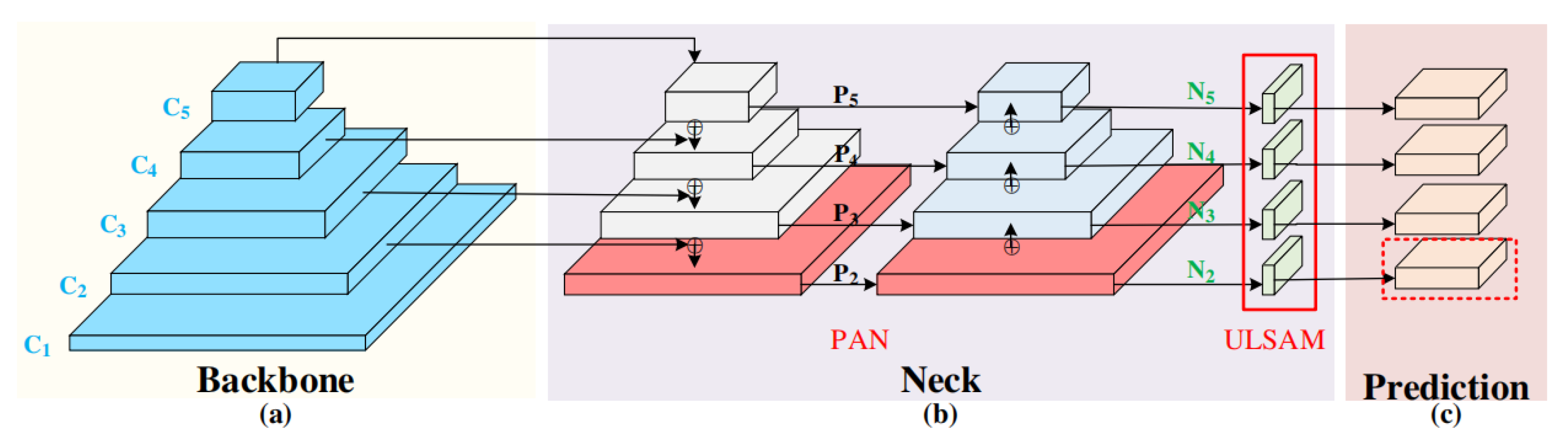
3.2.1. Improved Attentional Mechanism
3.2.2. Loss Function Selection
3.2.3. Improvement in Network Structure
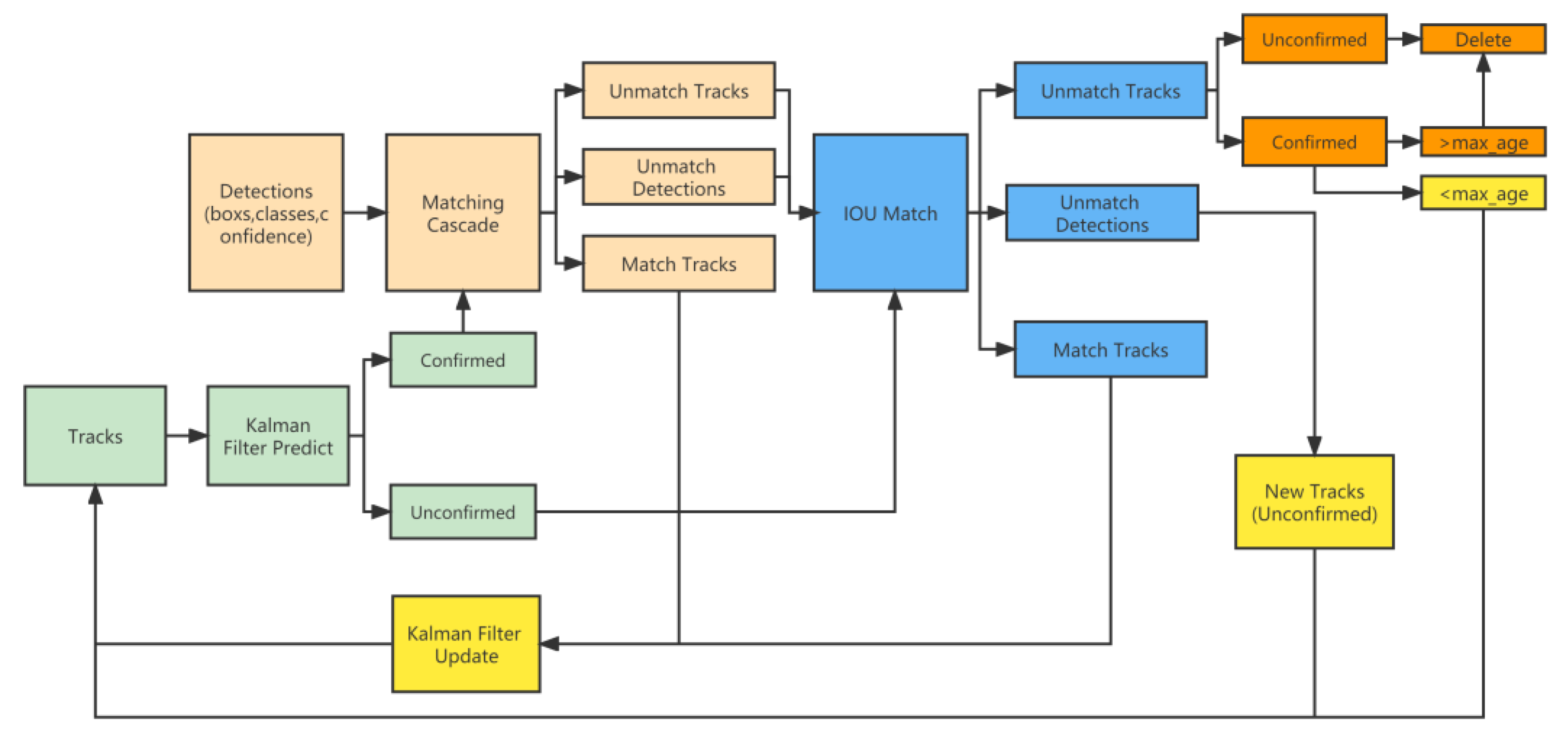
3.3. Target Tracking Algorithm
3.4. Output Data
4. Experiments and Results
4.1. Experimental Design
4.2. Comparison Experiments
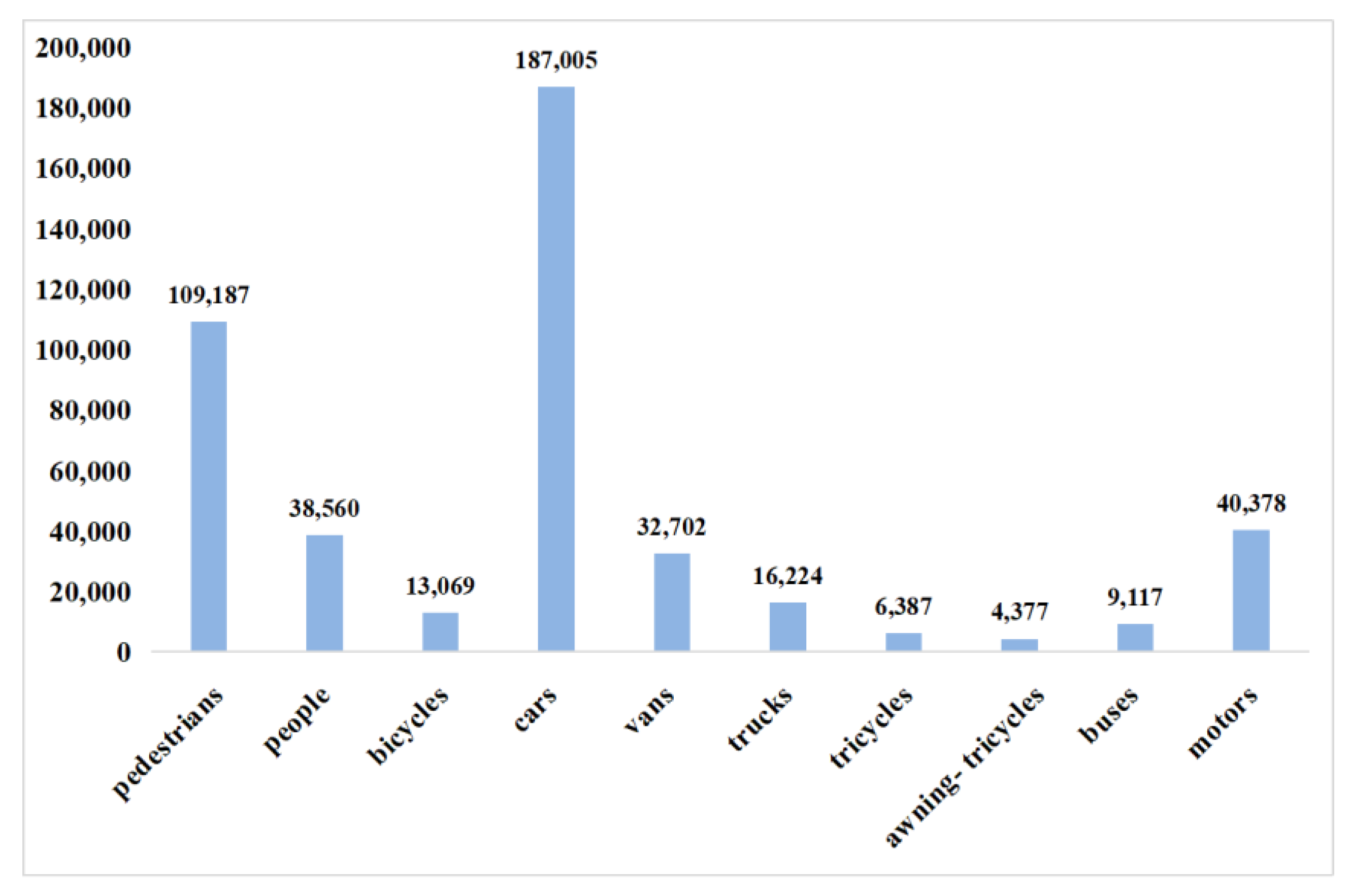
4.2.1. Dataset Description
4.2.2. Experimental Environment
4.2.3. Ablation Experiment
4.2.4. Comparison of Object Detection Algorithms
4.2.5. Comparison of Target-Tracking Algorithms
4.3. Control Experiments
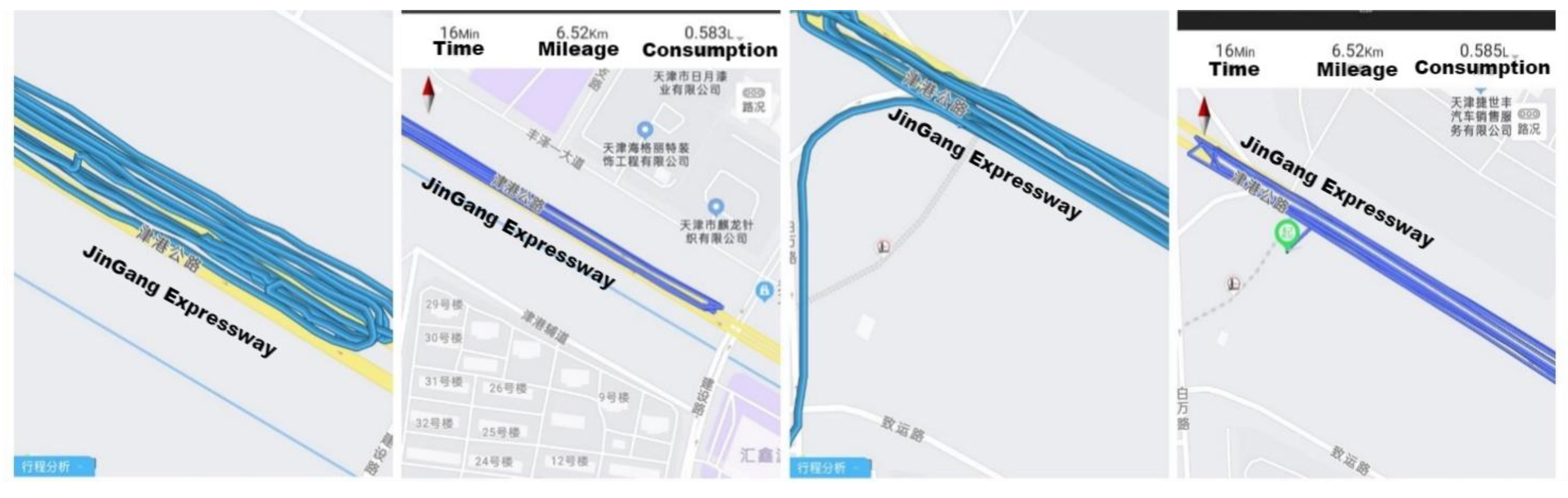
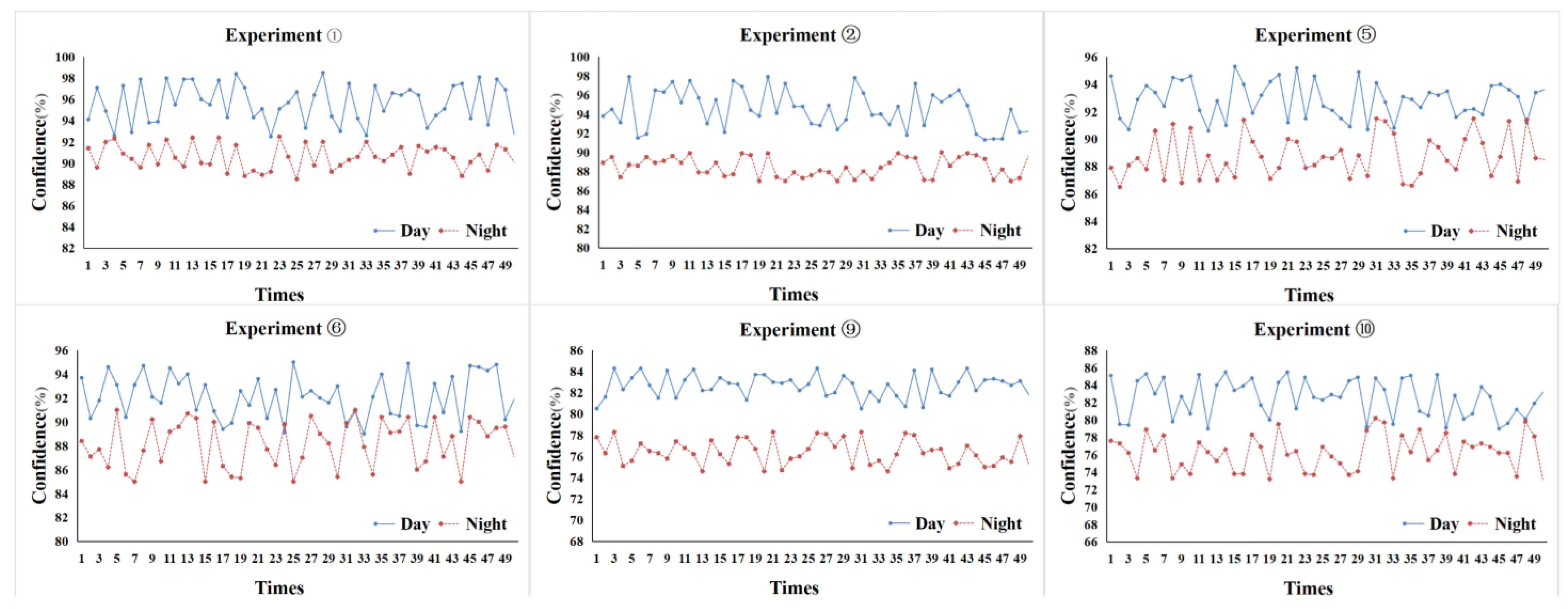
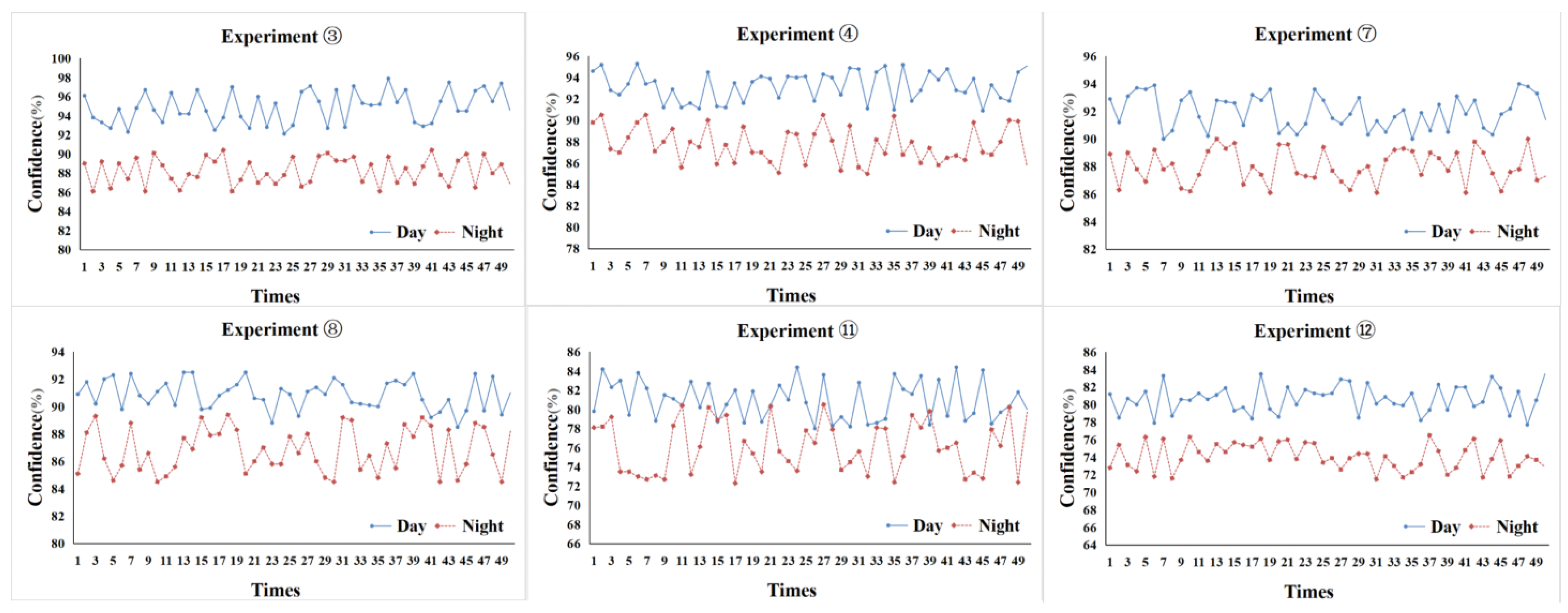
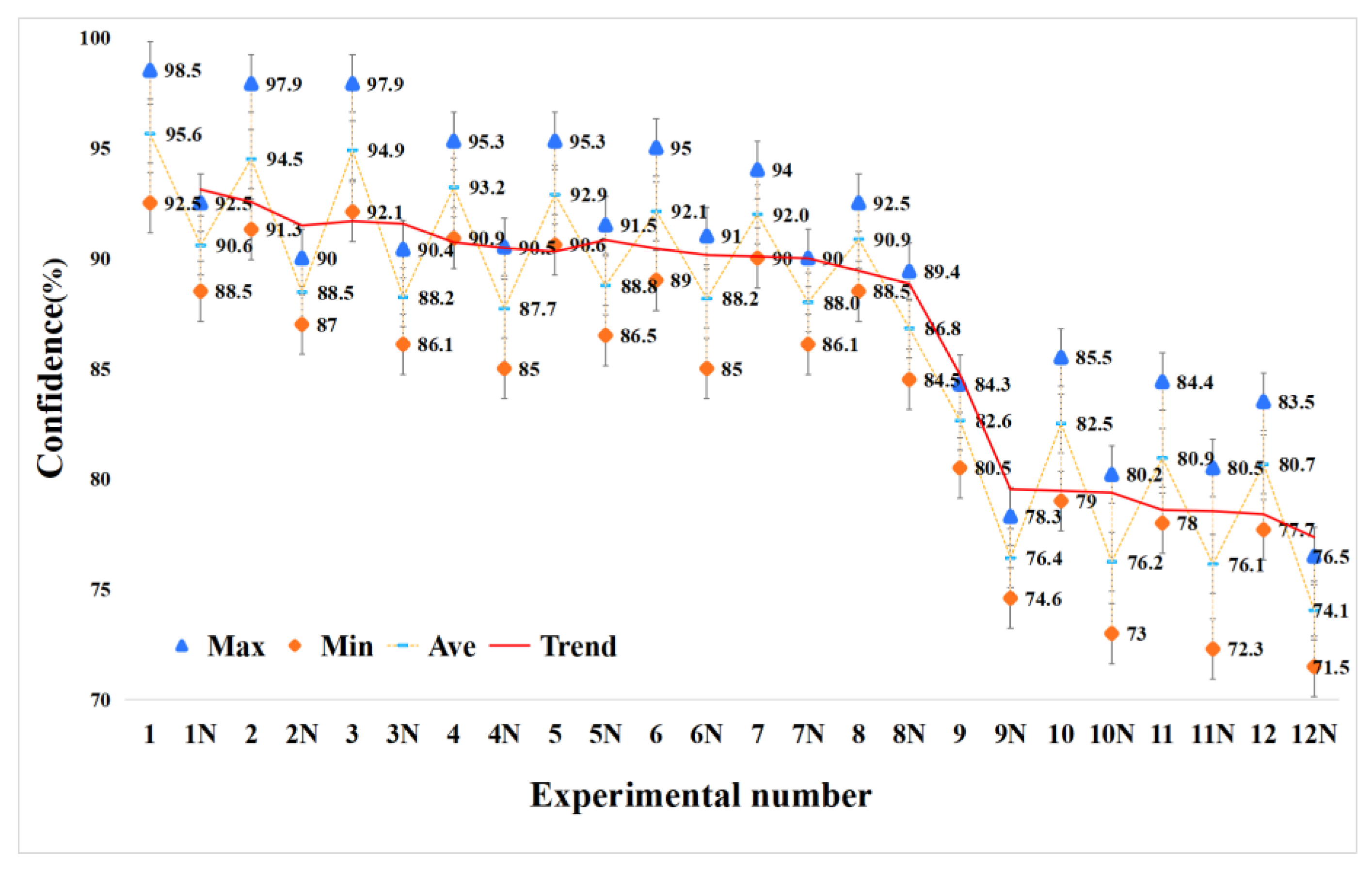
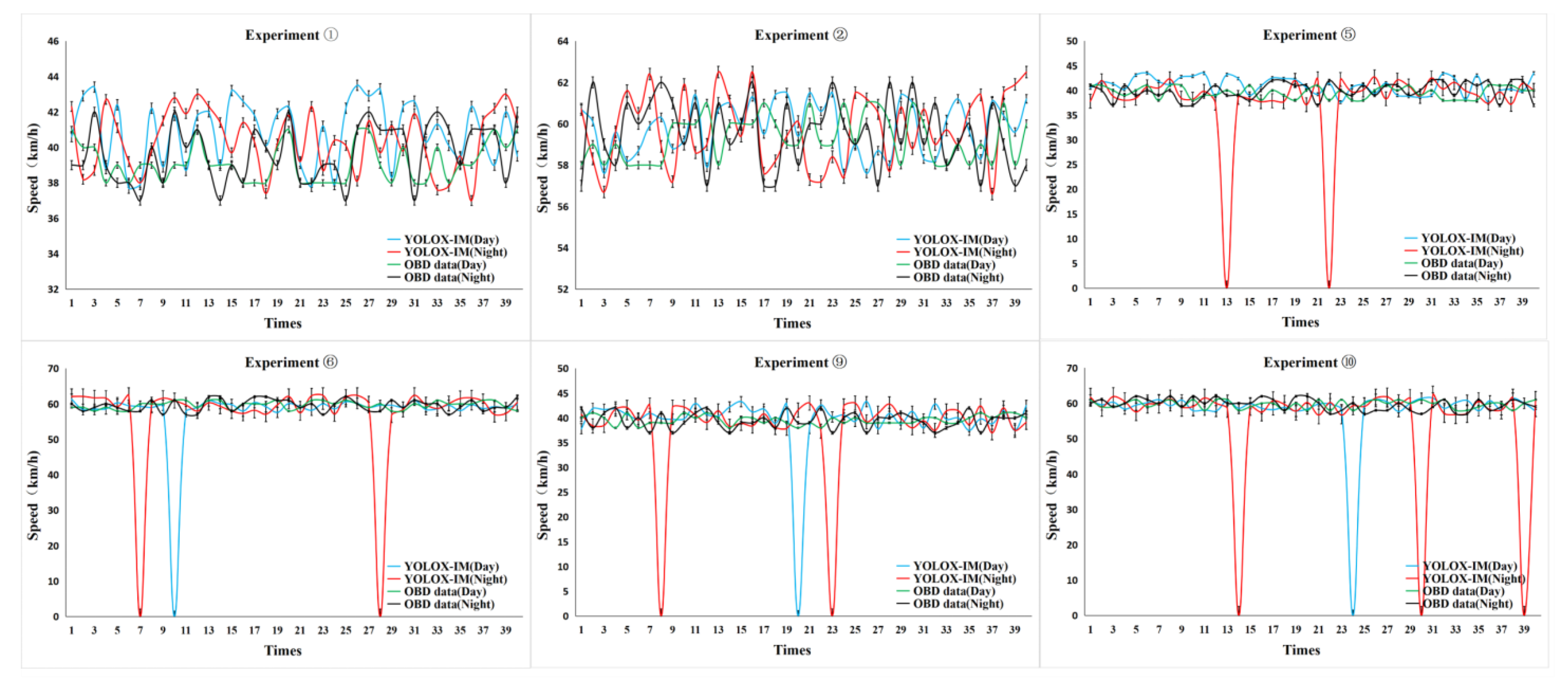
4.3.1. Field Experiments
4.3.2. Accuracy Analysis of Vehicle Speed Extraction
5. Conclusions
6. Discussions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Peng, Z.R.; Zhang, L.Y.; Chen, Q. Real-time and coordinated UAV path planning for road traffic surveillance: A penalty-based boundary intersection approach. Int. J. Control. Autom. Syst. 2022, 20, 2655–2668. [Google Scholar] [CrossRef]
- Liu, X.; Ma, J.; Chen, D.; Zhang, L.Y. Real-time unmanned aerial vehicle cruise route optimization for road segment surveillance using decomposition algorithm. Robotica 2021, 39, 1007–1022. [Google Scholar] [CrossRef]
- Brooks, R.R.; Ramanathan, P.; Sayeed, A.M. Distributed target classification and 13 tracking in sensor networks. Proc. IEEE 2003, 91, 1163–1171. [Google Scholar] [CrossRef]
- Zhang, J.; Tao, C.; Zou, Z.; Pan, H. A vehicle detection method taking shadow 15 areas into account for high resolution aerial imagery. In Proceedings of the 2016 16 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 669–672. [Google Scholar]
- Ke, R.; Li, Z.; Kim, S.; Ash, J.; Cui, Z.; Wang, Y. Real-time bidirectional traffic 19 flow parameter estimation from aerial videos. IEEE Trans. Intell. Transp. Syst. 2016, 18, 890–901. [Google Scholar] [CrossRef]
- Tsai, L.W.; Hsieh, J.W.; Fan, K.C. Vehicle detection using normalized color and edge map. IEEE Trans. Image Process. 2007, 16, 850–864. [Google Scholar] [CrossRef] [PubMed]
- Geng, Q.T.; Yu, F.H.; Wang, Y.T. A new algorithm for model detection based on feature fusion. J. Jilin Univ. 2018, 48, 929–935. [Google Scholar]
- Wen, X.; Shao, L.; Fang, W. Efficient feature selection and classification for vehicle detection. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 508–517. [Google Scholar]
- Tang, Y.; Zhang, C.; Gu, R. Vehicle detection and recognition for intelligent traffic surveillance system. Multimed. Tools Appl. 2015, 76, 5817–5832. [Google Scholar] [CrossRef]
- Ji, W.; Tang, L.; Li, D. Video-based construction vehicles detection and its application in intelligent monitoring system. CAAI Trans. Intell. Technol. 2016, 1, 162–172. [Google Scholar] [CrossRef]
- Weng, M.; Huang, G.; Da, X. A new interframe difference algorithm for moving target detection. Int. Congr. Image Signal Process. 2010, 1, 285–289. [Google Scholar]
- Liu, Y.; Wang, H.H.; Xiang, Y.L.; Lu, P. A vehicle detection method based on improved Adaboost algorithm and frame difference method. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2013, 41, 379–382. [Google Scholar]
- Zhang, X.; Izquierdo, E.; Chandramouli, K. Dense and small object detection in uav vision based on cascade network. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Tian, G.; Liu, J.; Yang, W. A dual neural network for object detection in uav images. Neurocomputing 2021, 443, 292–301. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and se-mantic segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: To-wards real-time object detection with region proposal networks. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 779–788. [Google Scholar]
- Li, X.; Liu, Y.; Li, P. A multi-objective vehicle detection method based on YOLO v2 algorithm in Darknet framework. Transp. J. Transp. Eng. 2018, 18, 146–162. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Van Etten, A. You only look twice: Rapid multi-scale object detection in satellite imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Rajput, S.K.; Patni, J.C.; Alshamrani, S.S.; Chaudhari, V.; Dumka, A.; Singh, R.; Rashid, M.; Gehlot, A.; AlGhamdi, A.S. Automatic Vehicle Identification and Classification Model Using the YOLOv3 Algorithm for a Toll Management System. Sustainability 2022, 14, 9163. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Z.; Wu, J.; Tian, Y.; Tang, H.; Guo, X. Real-Time Vehicle Detection Based on Improved YOLO v5. Sustainability 2022, 14, 12274. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Ultralytics: Yolov5. [EB/OL]. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 November 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, C.Y.; Liao HY, M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Drone Dataset. [EB/OL]. Available online: http://dronedataset.icg.tugraz.at/ (accessed on 25 January 2019).
- Visdrone Dataset. [EB/OL]. Available online: https://github.com/VisDrone (accessed on 13 January 2021).
- Yao, Y.; Zheng, L.; Yang, X.; Naphade, M.; Gedeon, T. Simulating Content Consistent Vehicle Datasets with Attribute Descent; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Qi, C.Y. Research on Vehicle Detection and Distance at Night Based on Monocular Vision; Jilin University: Changchun, China, 2021. [Google Scholar]
- Liu, J.P.; Shan, D.F.; Guo, Z.Y.; Luo, Z.B.; Zhang, Z.W. Traffic parameter extraction method and validation of UAV video. Highw. Traffic Technol. 2021, 38, 149–158. [Google Scholar]
- Umbaugh, S.E. Digital Image Processing and Analysis: Human and Computer Vision Applications with CVIP Tools; CRC Press: BocaRaton, FL, USA, 2010. [Google Scholar]
- Babenko, B.; Yang, M.H.; Belongie, S. Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1619–1632. [Google Scholar] [CrossRef]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection. arXiv 2022, arXiv:2202.06934. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Saini, R.; Jha, N.K.; Das, B.; Mittal, S.; Mohan, C.K. Ulsam: Ultra-lightweight subspace attention module for compact convolutional neural networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1627–1636. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Gevorgyan, Z. Siou loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Dong, M.L.; Ren, A.H. Research on highway traffic event detection based on deep learning. Foreign Electron. Meas. Technol. 2021, 40, 108–116. [Google Scholar] [CrossRef]
- Jia, C.M. Rearch on vehicle speed measurement using cameras above lane. Opt. Tech. 2021, 47, 608–612. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-Identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Albaba, B.M.; Ozer, S. Synet: An ensemble network for object detection in uav images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: New York, NY, USA, 2021; pp. 10227–10234. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. Science 2018, 18, 67–74. [Google Scholar]
- Liu, Y.; Ding, Z.; Cao, Y.; Chang, M. Multi-scale feature fusion uav image object detection method based on dilated convolution and attention mechanism. In Proceedings of the 2020 the 8th International Conference on Information Technology: IoT and Smart City, Xi’an, China, 25–27 December 2020; pp. 125–132. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE Internation al Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016; pp. 234–244. [Google Scholar]
- Zhang, J. Resolution of Parameter Estimation Methods for Linear Regression Models; Wuhan University of Technology: Wuhan, China, 2020. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
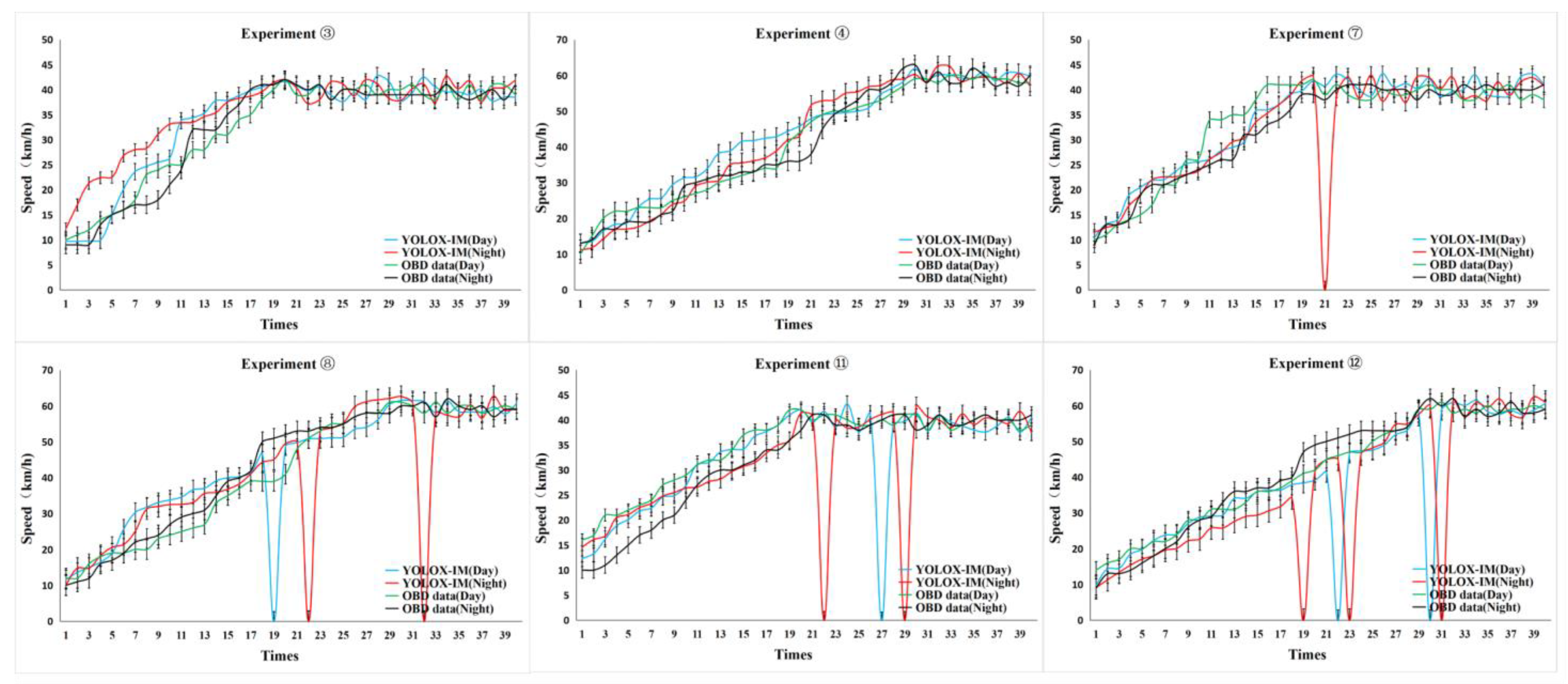{kind=link}
| Experimental No. | Average Recording Time of Drone Aerial Photography (s) | Speed of the Experimental Vehicle (km/h) | Height of the Drone (m) | Length of Experimental Road (m) | |
|---|---|---|---|---|---|
| Day | Night | ||||
| 1 | 15 | 18 | 40 | 30 | 50 |
| 2 | 10 | 15 | 60 | 30 | 50 |
| 3 | 23 | 25 | 10~40 | 30 | 50 |
| 4 | 18 | 25 | 10~60 | 30 | 50 |
| 5 | 19 | 27 | 40 | 50 | 75 |
| 6 | 13 | 20 | 60 | 50 | 75 |
| 7 | 27 | 35 | 10~40 | 50 | 75 |
| 8 | 21 | 30 | 10~60 | 50 | 75 |
| 9 | 27 | 30 | 40 | 100 | 150 |
| 10 | 24 | 35 | 60 | 100 | 150 |
| 11 | 33 | 40 | 10~40 | 100 | 150 |
| 12 | 28 | 34 | 10~60 | 100 | 150 |
| Baseline Model (YOLOX-s) | Data Enhancement | C2 | ULSAM | SIoU | Volume (MB) | mAP50 | AP-Small | AP-Mid | Ap-Large |
|---|---|---|---|---|---|---|---|---|---|
| √ | 13.85 | 36.62% | 0.103 | 0.312 | 0.422 | ||||
| √ | √ | 13.85 | 38.74% | 0.113 | 0.329 | 0.476 | |||
| √ | √ | √ | 6.7 | 41.98% | 0.124 | 0.341 | 0.495 | ||
| √ | √ | √ | √ | 8.2 | 44.13% | 0.136 | 0.364 | 0.488 | |
| √ | √ | √ | √ | √ | 4.55 | 44.75% | 0.142 | 0.366 | 0.506 |
| Model | Resolution | mAP | Pedestrian | People | Bicycle | Car | Van | Truck | Tricycle | Awning-Tricycle | Bus | Motor |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CenterNet | - | 26.60% | 0.23 | 0.21 | 0.15 | 0.6 | 0.24 | 0.21 | 0.2 | 0.17 | 0.38 | 0.24 |
| YOLOv3 | 768 × 768 1120 × 1120 | 41.35% 45.64% | - 0.44 | - 0.28 | - 0.23 | - 0.85 | - 0.53 | - 0.54 | - 0.31 | - 0.27 | - 0.65 | - 0.46 |
| D-A-FS SSD | - | 36.70% | - | - | - | - | - | - | - | - | - | - |
| RetinaNet | - | 35.59% | 0.27 | 0.13 | 0.14 | 0.59 | 0.50 | 0.54 | 0.25 | 0.30 | 0.59 | 0.24 |
| YOLOX-s (Baseline Model) | 640 × 640 | 36.62% | 0.31 | 0.21 | 0.15 | 0.78 | 0.41 | 0.46 | 0.22 | 0.19 | 0.58 | 0.36 |
| YOLOX-IM (Ours) | 640 × 640 | 47.20% | 0.45 | 0.32 | 0.26 | 0.85 | 0.51 | 0.56 | 0.32 | 0.28 | 0.69 | 0.48 |
| FasterR-CNN | - | 33.60% | - | - | - | - | - | - | - | - | - | - |
| CascadeR-CNN | - | 43.70% | 0.43 | 0.33 | 0.21 | 0.80 | 0.49 | 0.44 | 0.32 | 0.22 | 0.62 | 0.43 |
| Tracking Algorithm | MOTA | MOTP | IDSW |
|---|---|---|---|
| SORT | 60.9 | 79.5 | 164 |
| Deep-Sort | 61.2 | 81.3 | 99 |
| YOLOv3 + Deep-Sort | 65.8 | 84.4 | 71 |
| YOLOX-IM + Deep-Sort | 71.3 | 85.9 | 53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Liu, X.; Chen, Q.; Niu, S. A Traffic Parameter Extraction Model Using Small Vehicle Detection and Tracking in Low-Brightness Aerial Images. Sustainability 2023, 15, 8505. https://doi.org/10.3390/su15118505
Liu J, Liu X, Chen Q, Niu S. A Traffic Parameter Extraction Model Using Small Vehicle Detection and Tracking in Low-Brightness Aerial Images. Sustainability. 2023; 15(11):8505. https://doi.org/10.3390/su15118505
Chicago/Turabian StyleLiu, Junli, Xiaofeng Liu, Qiang Chen, and Shuyun Niu. 2023. "A Traffic Parameter Extraction Model Using Small Vehicle Detection and Tracking in Low-Brightness Aerial Images" Sustainability 15, no. 11: 8505. https://doi.org/10.3390/su15118505
APA StyleLiu, J., Liu, X., Chen, Q., & Niu, S. (2023). A Traffic Parameter Extraction Model Using Small Vehicle Detection and Tracking in Low-Brightness Aerial Images. Sustainability, 15(11), 8505. https://doi.org/10.3390/su15118505