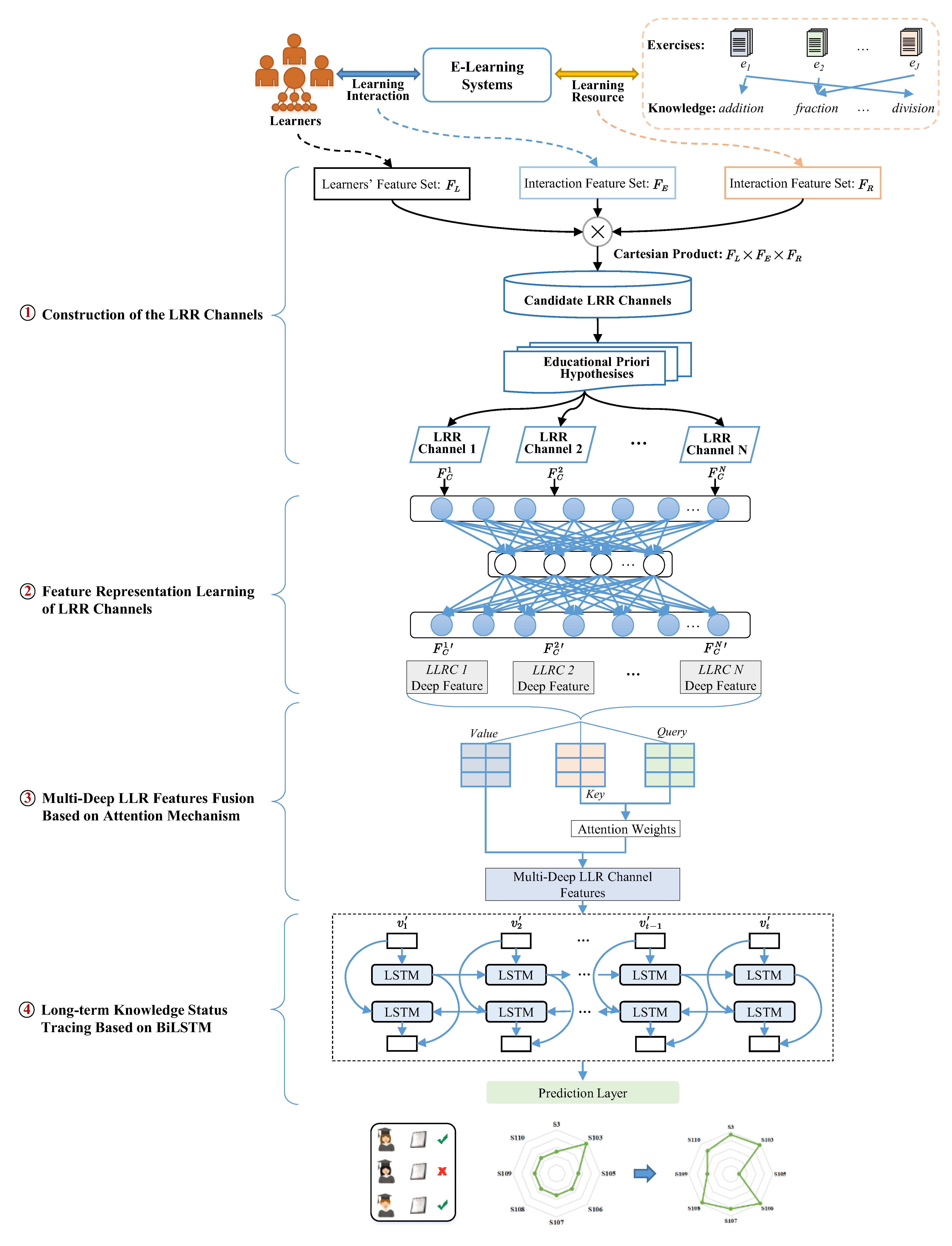
4.1. Construction of the LRR Channels
This subsection consists of two parts: (1) acquisition of learning features and (2) construction of LRR channels.
4.1.1. Acquisition of Learning Features
Psychometric theory suggests that learners’ inherent potential can be inferred by analyzing their external responses. The objective of knowledge tracing is to track changes in learners’ knowledge states based on their historical responses to resources and predict their subsequent responses. However, traditional knowledge tracing approaches typically define the external response solely as the learner’s response to an exercise, which does not fully capture the complexity of real learning scenarios. For instance, learners with longer response times to a resource may indicate weaker mastery compared to those with shorter response times. Therefore, in this work, we aim to collect and analyze learners’ learning logs from online learning platforms, which contain valuable information about learners’ responses to various resources. These logs are divided into three primary categories: learner features, resource features, and response features, as shown in
Table 2. Learner features encompass personal and cognitive information about the learners, while resource features include information about the resources and derived information from them. Response features capture the learners’ behaviors resulting from their interactions with the resources. These features have a significant impact on tracing changes in learners’ knowledge states and predicting their performance. Thus, in our subsequent work, we endeavor to incorporate multiple features, including learner features, resource features, and response features, to enhance the knowledge tracing process.
Deep knowledge tracing models that incorporate multiple learning features have gained attention for their ability to consider various factors that influence learners’ knowledge states and performance. However, these models often treat these features as randomly matched or uniformly processed, leading to a lack of interpretability within the educational domain and overlooking the intrinsic connections between the features. For instance, KTMFF [
26] utilizes a multi-headed attention mechanism to integrate learning features such as knowledge point difficulty, learner ability, and response duration. While the model is data-driven and effective, it fails to provide an explanation for the underlying connections between these different learning features.
Item response theory, on the other hand, suggests that subjects’ responses and performance on test items are specifically related to their underlying features, highlighting the inherent link between features. In order to establish this intrinsic link, we have developed a LRR channel based on item response theory. However, we believe that the learners’ potential knowledge states are not solely determined by their responses to a given resource. Instead, they are also influenced by additional tapping information about the resource, as well as the learners’ personal and cognitive characteristics. Furthermore, the responses themselves should not be limited to simply correct or incorrect answers to exercises.
4.1.2. Construction of LRR Channels Based on Educational Hypotheses
To enhance the understandability and training effectiveness of the model, we perform feature engineering on the factors influencing learners’ knowledge states and performance before constructing LRR channels. This process involves transforming these features into categorical features, which we refer to as class features. The main objective of class features is to discretize the input learner features, resource features, and interaction features into numerical intervals, simplifying the complexity of the model input.
For instance, consider response duration time, which is a continuous variable. By dividing it into intervals and categorizing it into six classes, we create class features for response duration time. This approach aligns with the actual learning scenarios. During data collection, when recording response times of learners answering exercises, we observe significant differences in response times, ranging from 10 to 100 s. However, a mere 1 s difference between a learner who took 10 s and another who took 9 s may not necessarily indicate varying levels of knowledge mastery. There might be an underlying similarity between them. Therefore, we consider response times within specific ranges as categories and transform them into class features. Similar treatment can be applied to the remaining features listed in
Table 2 to transform them into class features. This approach effectively reduces the complexity of the input learning features, facilitating a more manageable representation of the educational data.
Guided by the two educational a priori hypotheses derived from psychometric theory and item response theory, we select feature sets from the Cartesian product of the transformed learner features, resource features, and response features. These feature sets represent individual LRR channels, aligned with the hypotheses.
By leveraging feature engineering and the categorization of features into class features, we simplify the representation of complex input features, ensuring a more interpretable and effective learning model. These steps contribute to the overall understandability and training efficiency of the model, aligning with educational theories and enhancing its applicability in real-world learning scenarios.
4.2. Feature Representation Learning of LRR Channels
As discussed in the previous subsection, the LRR channels proposed in this paper incorporate a diverse range of features that influence learners’ knowledge states and performance. However, these LRR channels often contain redundant and irrelevant information at the feature level. Additionally, as the number of features increases, problems such as high-dimensional input feature vectors, longer training times, increased parameters, and higher computational costs arise. These challenges can make it difficult for the model to converge to the global optimum and can adversely affect prediction accuracy. Therefore, finding an effective approach to extract low-dimensional embeddings from LRR channels and increase their density is crucial.
The introduction of stacked auto-encoders (SAEs) provides an ideal solution to this problem. An auto-encoder is an unsupervised feature learning algorithm that trains an artificial neural network to reconstruct the input data itself. It generates a compact representation of the main features contained in the input data. A stacked auto-encoder consists of multiple individual auto-encoders, allowing for the learning of embedding feature vectors at different dimensions and levels from complex and high-dimensional input data. The training process of stacked auto-encoders consists of two steps: pre-training and fine-tuning. In the pre-training step, each individual auto-encoder is trained using unsupervised methods. The output of one layer becomes the input for the next layer, and this process continues until all the hidden layers are trained. The fine-tuning step involves training the entire stacked auto-encoder and optimizing the weights and biases using error back-propagation. In summary, each hidden layer in the stacked auto-encoder provides an alternative representation of the input feature values, capturing different dimensions and levels of embedding feature vectors from complex and high-dimensional input data without losing important information. Furthermore, it reduces the dimensionality of the input data, enabling deep feature extraction. Therefore, we utilize stacked auto-encoders to obtain low-dimensional embedding representations for each LRR channel.
Before being fed into the SAE, the LRR channels undergo cross-feature processing. In the 2010 KDD Cup competition [
55], it was observed that cross-featured representations improved model prediction performance, while separate feature representations showed a decline in performance. The cross-feature processing method is defined as follows:
where
represents the interaction among learners at moment
t within an LRR channel composed of learner feature
l, resource feature
e, and response feature
r, which adheres to a specific educational domain hypothesis. For instance, if
, then
denotes the learner’s ability at moment
t,
represents the learner’s practice response at moment
t,
indicates whether the learner answered correctly at moment
t,
signifies the maximum value among the data for all ability features,
denotes the maximum value among the data for all practice features, and
symbolizes the crossover feature. Subsequently, the LRR channels undergo one-hot encoding to produce a fixed-length vector, which represents a feature vector of LRR channels following the educational domain rules encompassing learner feature
l, resource feature
e, and response feature
r. This encoding process is achieved using the following formula:
Here, represents the one-hot encoding, and represents the feature vector that contains the LRR channels formed by the learner’s interaction with the exercise at moment t.
In the knowledge tracing task, the learner interacts with the exercise from moment 1 to t, resulting in the generation of feature vectors that consist of N different LRR channels. Specifically, represents the feature vector for the Nth LRR channel from moments 1 to t. These feature vectors, containing distinct LRR channels, are then individually fed into the SAEs to extract low-dimensional embedding representations of these LRR channels, thereby enhancing the density of each LRR channel. We will use as an example to illustrate the functioning of the SAE.
The first auto-encoder of the SAEs takes
as input and produces the output
using the following equations:
Here, represents the hidden layer of the first encoder, is the weight matrix connecting the input layer and the hidden layer of the first encoder, and and are the corresponding bias vectors. The activation function tanh is used in these equations.
The feature
obtained from the first auto-encoder serves as the input for the second auto-encoder of the SAE. The output
is generated by the second auto-encoder using the following equations:
In these equations, represents the hidden layer of the second encoder, is the weight matrix connecting the output layer of the first encoder and the hidden layer of the second encoder, and and are the corresponding bias vectors. The activation function tanh is used as well.
Since the SAE is trained jointly with the Bi-LSTM as mentioned later, fine-tuning the SAE weights increases the number of parameters and thus provides a better fit. Therefore, the SAE is pre-trained separately. The weights of the parameters are updated using the Adam method, and the objective function for optimization is the squared reconstruction error:
Here, represents the actual output, and represents the expected output. The output of the hidden layer of the second auto-encoder, obtained from the trained SAE, serves as the low-dimensional embedding representation vector of the LRR channel.
4.3. Multi-Deep LLR Features Fusion Based on Attention Mechanism
Upon reviewing existing studies on knowledge tracing using multi-feature analysis, we observed that most researchers either treat each feature equally or introduce an attention mechanism after modeling the learner’s interaction sequence. However, the former overlooks the varying degrees of influence that different features may have on learner performance, while the latter lacks interpretability regarding feature importance. Additionally, the inclusion of an attention mechanism often primarily increases the temporal dependence between sequential elements, without directly extracting the importance of different features. In this paper, to enhance the specificity and effectiveness of LRR channels, we propose incorporating an attention mechanism to assign different weights to each LRR channel before inputting them into the RNNs model. This approach allows the model to concentrate on crucial information and to learn to absorb it fully, thereby facilitating the comprehensive integration and deep correlation of features.
As described in the preceding subsection, the low-dimensional embedding representation vector of LRR channels, obtained through SAE, serves as the input for the attention mechanism. Consequently, the input feature vector for the attention mechanism at time
t is given by:
Here, represents the feature vector containing N LRR channels generated at time t, and denotes the input feature vector for the attention mechanism, encompassing N LRR channels at time t. signifies the pre-trained weight of SAE, while represents the corresponding bias vector. Notably, since SAE is trained separately, the weights employed for constructing the attention mechanism feature vectors remain unchanged and rely on the pre-trained weights.
Following the feature input, the attention distribution
for the LRR channel is computed as:
Here, corresponds to the weight of the attention module, while represents the associated bias vector. and tanh denote the activation functions.
Upon obtaining the attention distribution for the LRR channel, the input feature vector of the attention mechanism is encoded to produce the feature vector
carrying the attention weights:
4.4. Long-Term Knowledge Status Tracing Based on Bi-LSTM
The conventional deep knowledge tracing method relies on RNN, which effectively handles temporal data and has been widely employed by researchers in knowledge tracing tasks. However, RNN encounters difficulties when dealing with information spanning long time intervals. During training, it is susceptible to issues such as gradient disappearance and gradient explosion. To overcome these limitations, researchers have turned to LSTM, a variant of RNN. LSTM addresses the problem of long-term dependency by incorporating three carefully designed gates: the forgetting gate, the input gate, and the output gate. The forgetting gate determines the importance of information from the previous hidden layer state, the input gate determines the importance of information from the current state, and the output gate determines the next hidden layer state. Consequently, researchers have increasingly utilized LSTM and other RNN variants such as GRU in knowledge tracing tasks to predict learners’ future performance.
However, online learning platforms often accumulate learners’ learning logs over extended periods, resulting in exceedingly long sequences of learning interactions that surpass the capabilities of LSTM to handle prolonged time sequences. Moreover, existing approaches only consider the influence of memory factors accumulated during past learning on learners’ future performance, overlooking the dynamic nature of learners’ knowledge state and performance, shaped by both memory and forgetting factors. According to the learning curve theory [
56], continuous practice enables learners to eventually master the relevant knowledge. German psychologist Ebbinghaus discovered that forgetting begins immediately after learning and increases over time. Therefore, the occurrence of forgetting during the learning process significantly affects learners’ knowledge states and performance.
This challenge can be addressed by leveraging Bi-LSTM [
22], which is an extension of traditional LSTM. As shown in
Figure 1, the Bi-LSTM introduced for modeling consists of two LSTMs superimposed on each other: one processes the input sequence in the forward direction, while the other processes it in the backward direction. The output is determined by combining the states of both LSTMs. At each time step, six distinct weights are employed, corresponding to the input to the forward and backward hidden layers
, the hidden layer to itself
, and the forward and backward hidden layers to the output layer
. Notably, there is no information flow between the forward and backward hidden layers, ensuring an acyclic unfolding graph. As shown in
Figure 1, the forward layer is computed in the forward direction from time steps 1 to
t, with the output of the forward hidden layer saved at each time step. Similarly, the backward layer calculates the output of the backward hidden layer by traversing the time steps from
t to 1. Finally, the results of the forward and backward layers at corresponding time steps are combined to obtain the final output.
We select bidirectional LSTM to model learners’ knowledge states and predict their future performance for two primary reasons:
Learners’ learning processes are gradual and evolve slowly, necessitating a comprehensive tracking of their knowledge states that takes into account the influence of time series on prediction results. Bidirectional LSTM exhibits heightened sensitivity to long-term temporal information.
Learning processes are influenced by both memory and forgetting factors. While considering the impact of learners’ memory accumulation on knowledge states, as reflected by past response information, it is crucial to also account for the influence of learners’ forgetting degree on knowledge states, as indicated by forward response information. Bidirectional LSTM effectively leverages both past and forward response information, better characterizing learners’ learning processes.
In the proposed approach, the feature vector containing attention weights serves as the input to the Bi-LSTM model. The model is trained to effectively capture the learner’s knowledge state and to predict their response at moment through the following steps:
4.4.1. Processing of the First Layer
At moment t, the input to the first layer of the LSTM model determines the handling of information:
- Step 1:
Identify information to discard:
- Step 2:
Determine values to update:
- Step 3:
Decide which information to update:
- Step 4:
- Step 5:
Output information related to the learner’s knowledge acquisition:
In the above equations, represent weight matrices, and correspond to bias vectors. The activation functions and tanh are employed.
4.4.2. Processing of the Second Layer
Subsequently, the output from the first layer is passed to the second layer of the LSTM model to obtain the learner’s knowledge mastery output:
Similarly, are weight matrices, and represent bias vectors. The activation functions and tanh are utilized.
The learner’s final knowledge mastery is obtained by considering the knowledge mastery outputs from both layers of the LSTM model. Thus, the potential knowledge mastery formed by the learner’s past learning trajectory at moment
t can be expressed as:
Once the learner’s knowledge mastery is acquired, the prediction of the learner’s response
is accomplished by integrating the learner’s interaction with the provided resource at moment
. This is achieved using the following equation:
Here, and denote weight matrices, and represents the corresponding bias vector. The activation function is applied to produce the final predicted response.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}