



Hybrid Feature Extraction for Multi-Label Emotion Classification in English Text Messages
 , ,
, , 
Abstract
:1. Introduction
- Extract features based on the linguistic context of a word in a sentence, semantic, or syntactic similarity by employing Word2Vec embedding features.
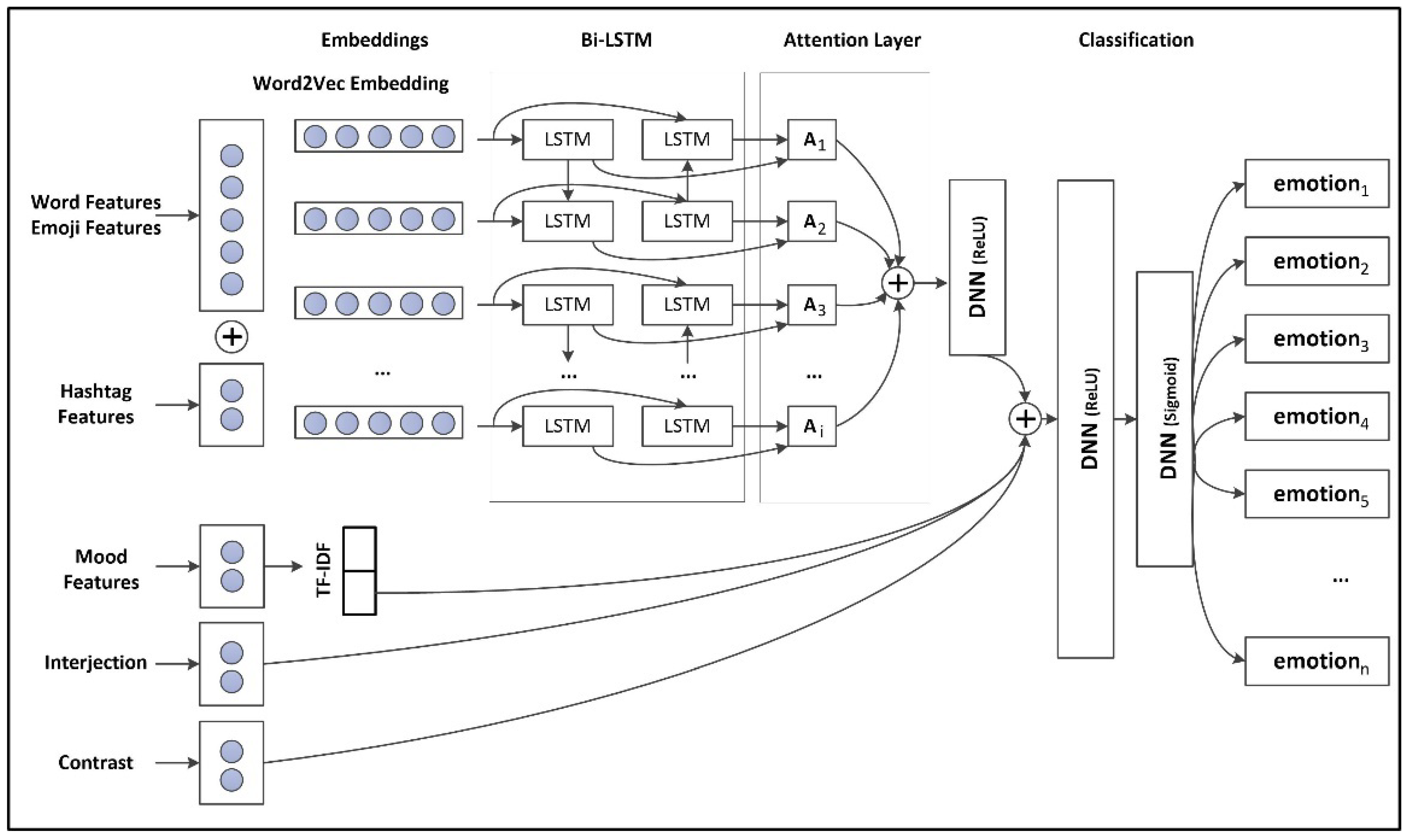
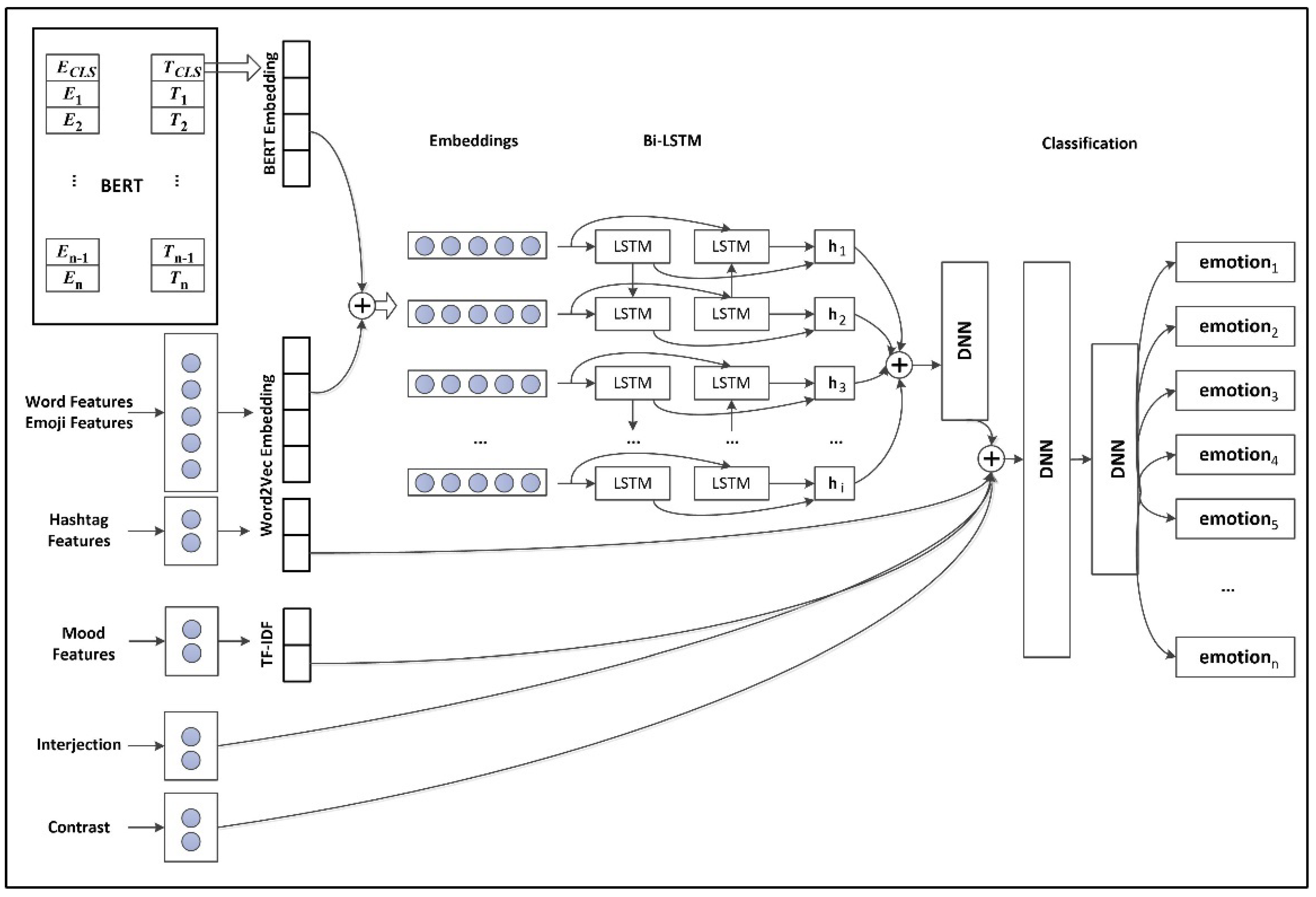
- Propose a model that incorporates hybrid features, including Word2Vec based word embedding, human-engineered features, and Twitter specific features (emoji and hashtag), and that deploys a deep learning algorithm (Bi-LSTM) and a Transformer model (BERT) to classify emotions using context information.
- The proposed model was evaluated through various extensive experiments on two benchmark datasets, and, according to the results, the proposed technique that incorporates hybrid features outperformed the baseline models for emotion classification.
2. Related Work
3. Methodology
3.1. Data Preprocessing
3.2. Data Augmentation
3.3. Human-Engineered Features (HEF)
3.3.1. Sentiment of Sentence
| Algorithm 1: Rule-based conversion for Sentiment Contrast Score (SCS) generation |
| Input: A sentence with M words, {w1, w2, . . . , wM }, POS tags POSw, Sentiment values sw using SentiWordNet. Output: Sentence-level sentiment contrast score (SCS) 1: Initialization: Vector of ps, constant c. 2: for each affective word in the sentence do 3: if a particle appears then 4: wx = particle word 5: wx + 1 = word that comes after particle 6: pol_scorew_x = polarity (sw_x) ϵ −1,0,+1 7: if POSw_x + 1 = verb or adj then 8: pol_scorew_x + 1 = polarity (sw_x + 1) ϵ −1,0,+1 9: score = abs(sent+ − sent−)× pol_scorew_x + 1 × pol_scorew_x 10: ps+ = score 11: if POSw = verb or adj or noun, and no particle appears before it then 12: pol_scorew = polarity (sw) ϵ −1,0,+1 13: score = abs(sent+ − sent−) × pol_scorew 14: ps+ = score 15: end for 16: SCS ← Normalize (ps); 17: return SCS |
3.3.2. Syntactic Feature
3.3.3. Domain-Specific Features
3.4. Deep Learning-Based Features (DLF)
3.4.1. Word2Vec Word Embedding
3.4.2. Hashtag Feature Embedding
3.4.3. Emoji Feature Embedding
3.5. Emotion Classification Based on Bidirectional Encoder Representations from Transformers (BERT)
3.6. Classification Using Long-Short Term Memory (Bi-LSTM)
4. Experiments and Results
4.1. Datasets
4.2. Evaluation Measures
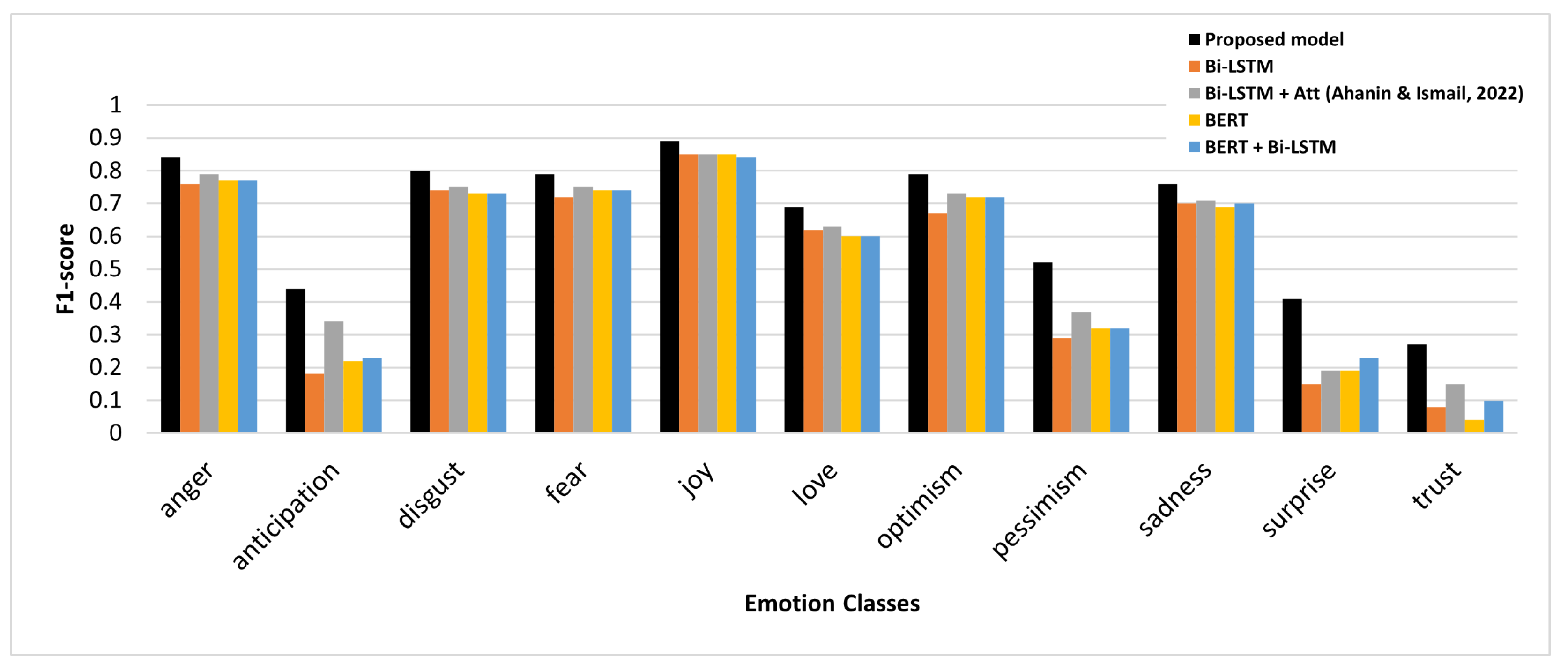
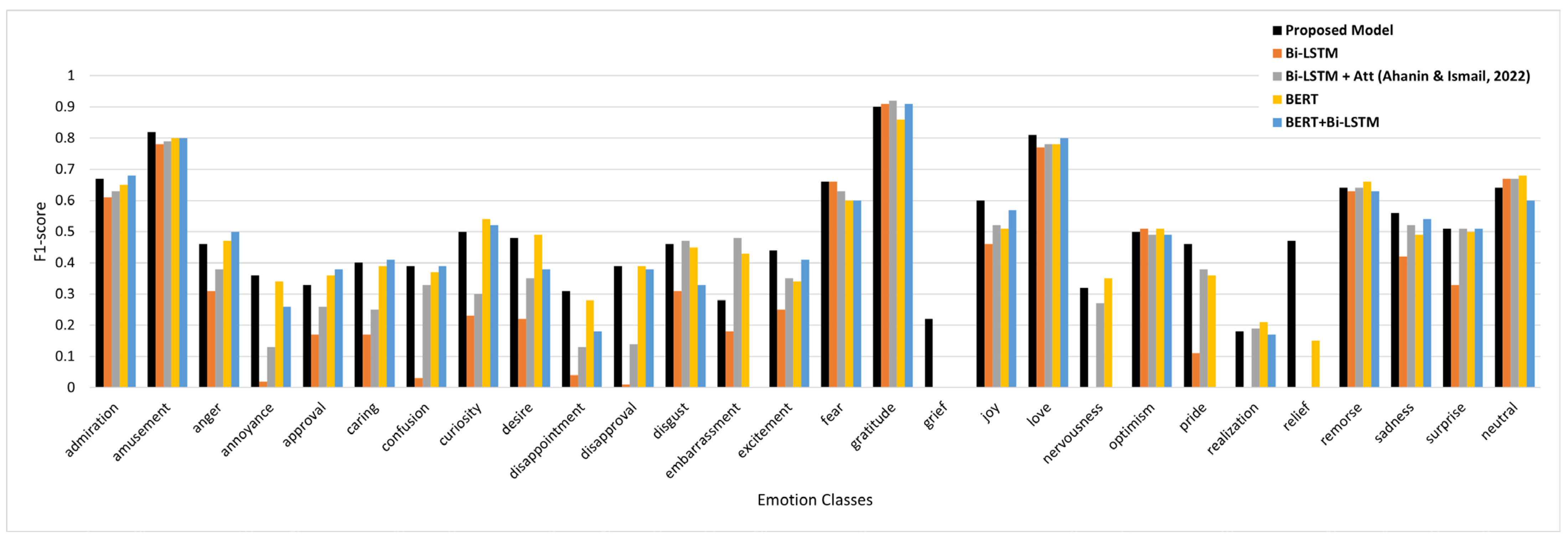
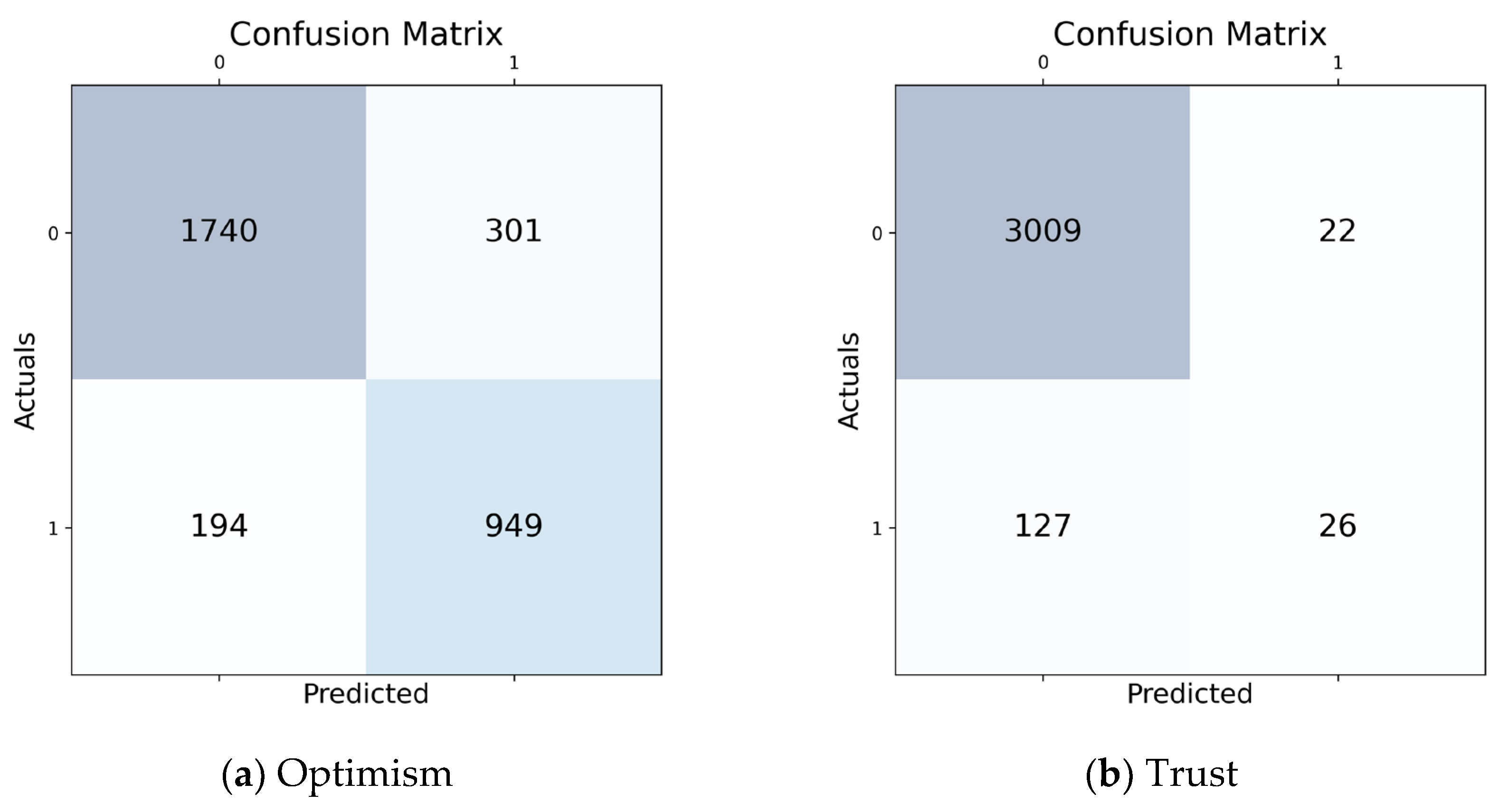
4.3. Results and Discussion
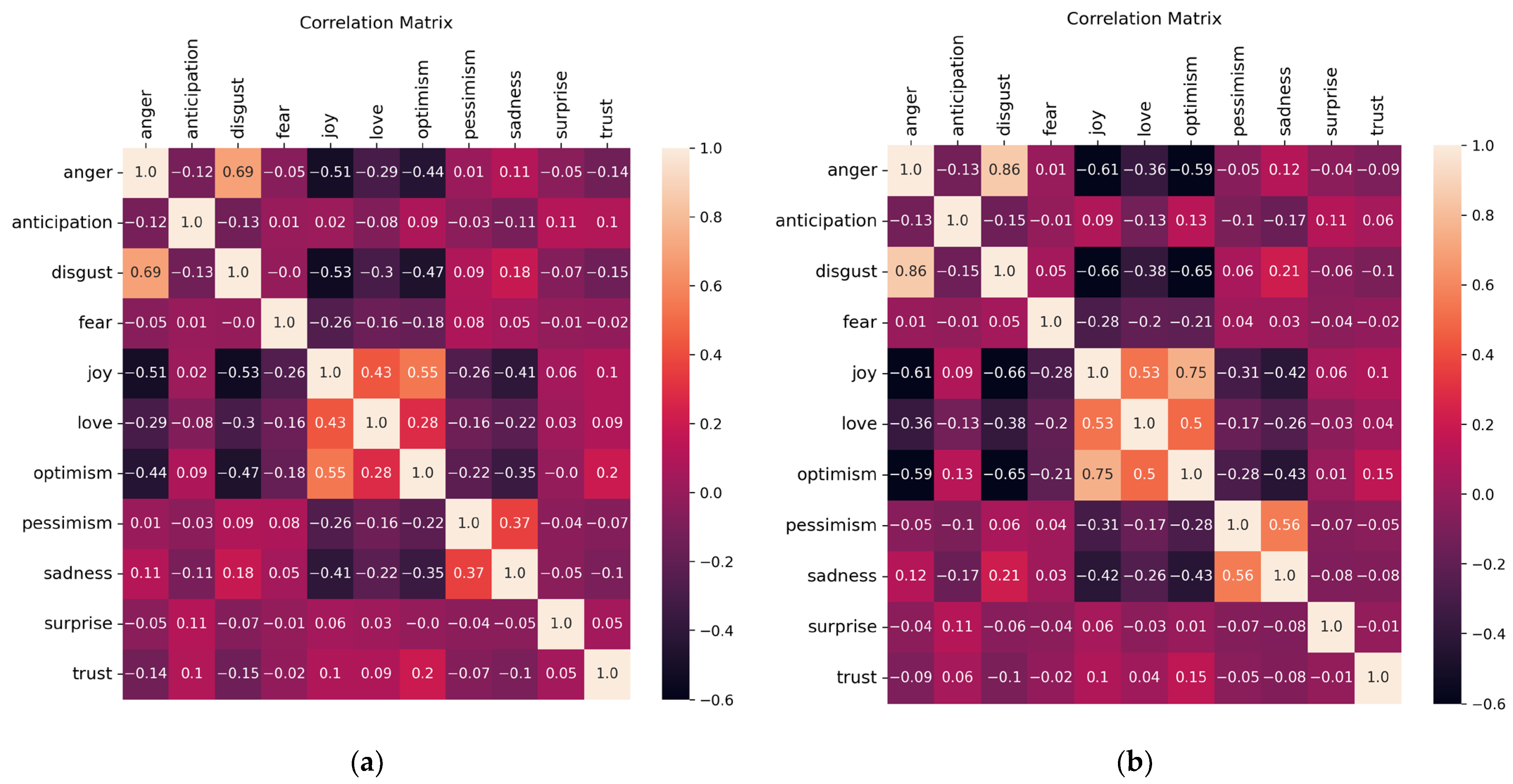
4.4. Correlation Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahanin, E.; Bakar Sade, A.; Tat, H.H. Applications of Artificial Intelligence and Voice Assistant in Healthcare. Int. J. Acad. Res. Bus. Soc. Sci. 2022, 12, 2545–2554. [Google Scholar] [CrossRef] [PubMed]
- Fernández, A.P.; Leenders, C.; Aerts, J.M.; Berckmans, D. Emotional States versus Mental Heart Rate Component Monitored via Wearables. Appl. Sci. 2023, 13, 807. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Hand Movements. J. Commun. 1972, 22, 353–374. [Google Scholar] [CrossRef]
- Parrott, W.G. Emotions in Social Psychology: Essential Readings; Psychology Press: East Sussex, UK, 2001; ISBN 0863776833. [Google Scholar]
- Plutchik, R.; Kellerman, H. Emotion, Theory, Research, and Experience; Academic Press: Cambridge, MA, USA, 1980. [Google Scholar]
- Cambria, E.; Livingstone, A.; Hussain, A. The Hourglass of Emotions. In Proceedings of the Cognitive Behavioural Systems; Esposito, A., Esposito, A.M., Vinciarelli, A., Hoffmann, R., Müller, V.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 144–157. [Google Scholar]
- Susanto, Y.; Livingstone, A.G.; Ng, B.C.; Cambria, E. The Hourglass Model Revisited. IEEE Intell. Syst. 2020, 35, 96–102. [Google Scholar] [CrossRef]
- Ren, G.; Hong, T. Investigating Online Destination Images Using a Topic-Based Sentiment Analysis Approach. Sustainability 2017, 9, 1765. [Google Scholar] [CrossRef]
- Adamu, H.; Lutfi, S.L.; Malim, N.H.A.H.; Hassan, R.; di Vaio, A.; Mohamed, A.S.A. Framing Twitter Public Sentiment on Nigerian Government COVID-19 Palliatives Distribution Using Machine Learning. Sustainability 2021, 13, 3497. [Google Scholar] [CrossRef]
- Huang, Y.; Bo, D. Emotion Classification and Achievement of Students in Distance Learning Based on the Knowledge State Model. Sustainability 2023, 15, 2367. [Google Scholar] [CrossRef]
- Zhang, X.; Yan, Z.; Wu, Q.; Wang, K.; Miao, K.; Wang, Z.; Chen, Y. Community Governance Based on Sentiment Analysis: Towards Sustainable Management and Development. Sustainability 2023, 15, 2684. [Google Scholar] [CrossRef]
- Liang, K.; He, J.; Wu, P. Trust Evaluation Method of E-Commerce Enterprises with High-Involvement Experience Products. Sustainability 2022, 14, 15562. [Google Scholar] [CrossRef]
- Ahanin, Z.; Ismail, M.A. A Multi-Label Emoji Classification Method Using Balanced Pointwise Mutual Information-Based Feature Selection. Comput. Speech Lang. 2022, 73, 101330. [Google Scholar] [CrossRef]
- Liu, Y.; Li, P.; Hu, X. Combining Context-Relevant Features with Multi-Stage Attention Network for Short Text Classification. Comput. Speech Lang. 2022, 71, 101268. [Google Scholar] [CrossRef]
- Mustafa Hilal, A.; Elkamchouchi, D.H.; Alotaibi, S.S.; Maray, M.; Othman, M.; Abdelmageed, A.A.; Zamani, A.S.; Eldesouki, M.I. Manta Ray Foraging Optimization with Transfer Learning Driven Facial Emotion Recognition. Sustainability 2022, 14, 14308. [Google Scholar] [CrossRef]
- Kumar, L.A.; Renuka, D.K.; Rose, S.L.; Priya, M.C.S.; Wartana, I.M. Deep Learning Based Assistive Technology on Audio Visual Speech Recognition for Hearing Impaired. Int. J. Cogn. Comput. Eng. 2022, 3, 24–30. [Google Scholar] [CrossRef]
- Weng, Z.; Qin, Z.; Tao, X.; Pan, C.; Liu, G.; Li, G.Y. Deep Learning Enabled Semantic Communications with Speech Recognition and Synthesis. IEEE Trans. Wirel. Commun. 2023. [Google Scholar] [CrossRef]
- Ameer, I.; Bölücü, N.; Siddiqui, M.H.F.; Can, B.; Sidorov, G.; Gelbukh, A. Multi-Label Emotion Classification in Texts Using Transfer Learning. Expert Syst. Appl. 2023, 213, 118534. [Google Scholar] [CrossRef]
- Eke, C.I.; Norman, A.A.; Shuib, L. Context-Based Feature Technique for Sarcasm Identification in Benchmark Datasets Using Deep Learning and BERT Model. IEEE Access 2021, 9, 48501–48518. [Google Scholar] [CrossRef]
- Waheeb, S.A.; Khan, N.A.; Shang, X. An Efficient Sentiment Analysis Based Deep Learning Classification Model to Evaluate Treatment Quality. Malays. J. Comput. Sci. 2022, 35, 1. [Google Scholar] [CrossRef]
- Priyadarshini, I.; Cotton, C. A Novel LSTM-CNN-Grid Search-Based Deep Neural Network for Sentiment Analysis. J. Supercomput. 2021, 77, 13911–13932. [Google Scholar] [CrossRef]
- Ahanin, Z.; Ismail, M.A. Feature Extraction Based on Fuzzy Clustering and Emoji Embeddings for Emotion Classification. Int. J. Technol. Manag. Inf. Syst. 2020, 2, 102–112. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Baziotis, C.; Athanasiou, N.; Chronopoulou, A.; Kolovou, A.; Paraskevopoulos, G.; Ellinas, N.; Narayanan, S.; Potamianos, A. Ntua-Slp at Semeval-2018 Task 1: Predicting Affective Content in Tweets with Deep Attentive Rnns and Transfer Learning. arXiv 2018, arXiv:1804.06658. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Sakata, W.; Tanaka, R.; Shibata, T.; Kurohashi, S. FAQ Retrieval Using Query-Question Similarity and BERT-Based Query-Answer Relevance. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; Association for Computing Machinery, Inc.: New York, NY, USA, 2019; pp. 1113–1116. [Google Scholar]
- Qu, C.; Yang, L.; Qiu, M.; Croft, W.B.; Zhang, Y.; Iyyer, M. BERT with History Answer Embedding for Conversational Question Answering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; ACM: New York, NY, USA, 2019; pp. 1133–1136. [Google Scholar]
- Singh, P.K.; Paul, S. Deep Learning Approach for Negation Handling in Sentiment Analysis. IEEE Access 2021, 9, 102579–102592. [Google Scholar] [CrossRef]
- Jianqiang, Z.; Xiaolin, G.; Xuejun, Z. Deep Convolution Neural Networks for Twitter Sentiment Analysis. IEEE Access 2018, 6, 23253–23260. [Google Scholar] [CrossRef]
- Li, Z.; Xie, H.; Cheng, G.; Li, Q. Word-Level Emotion Distribution with Two Schemas for Short Text Emotion Classification. Knowl. Based Syst. 2021, 227, 107163. [Google Scholar] [CrossRef]
- Huang, C.; Trabelsi, A.; Zaïane, O.R. ANA at SemEval-2019 Task 3: Contextual Emotion Detection in Conversations through Hierarchical LSTMs and BERT. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; Association for Computational Linguistics (ACL): Minneapolis, MI, USA, 2019; pp. 49–53. [Google Scholar]
- Zhang, X.; Li, W.; Ying, H.; Li, F.; Tang, S.; Lu, S. Emotion Detection in Online Social Networks: A Multilabel Learning Approach. IEEE Internet Things J. 2020, 7, 8133–8143. [Google Scholar] [CrossRef]
- Bollen, J.; Mao, H.; Pepe, A. Modeling Public Mood and Emotion: Twitter Sentiment and Socio-Economic Phenomena. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 450–453. [Google Scholar]
- Asghar, M.Z.; Khan, A.; Bibi, A.; Kundi, F.M.; Ahmad, H. Sentence-Level Emotion Detection Framework Using Rule-Based Classification. Cogn. Comput. 2017, 9, 868–894. [Google Scholar] [CrossRef]
- Ileri, I.; Karagoz, P. Detecting User Emotions in Twitter through Collective Classification. In Proceedings of the 8th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2016), Porto, Portugal, 9–11 November 2016; Science and Technology Publications: North York, ON, Canada, 2016; pp. 205–212. [Google Scholar]
- Tocoglu, M.A.; Ozturkmenoglu, O.; Alpkocak, A. Emotion Analysis from Turkish Tweets Using Deep Neural Networks. IEEE Access 2019, 7, 183061–183069. [Google Scholar] [CrossRef]
- Ameer, I.; Ashraf, N.; Sidorov, G.; Adorno, H.G. Multi-Label Emotion Classification Using Content-Based Features in Twitter. Comput. Y Sist. 2020, 24, 1159–1164. [Google Scholar] [CrossRef]
- Miriam, P.-A.F.; Martín-Valdiviaa, M.T.; Ureña-Lópeza, L.A.; Mitkov, R. Improved Emotion Recognition in Spanish Social Media through Incorporation of Lexical Knowledge. Future Gener. Comput. Syst. 2020, 110, 1000–1008. [Google Scholar]
- Jabreel, M.; Moreno, A. A Deep Learning-Based Approach for Multi-Label Emotion Classification in Tweets. Appl. Sci. 2019, 9, 1123. [Google Scholar] [CrossRef]
- Alhuzali, H.; Ananiadou, S. SpanEmo: Casting Multi-Label Emotion Classification as Span-Prediction. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Kyiv, Ukraine, 19–23 April 2021; pp. 1573–1584. [Google Scholar]
- Zygadło, A.; Kozłowski, M.; Janicki, A. Text-Based Emotion Recognition in English and Polish for Therapeutic Chatbot. Appl. Sci. 2021, 11, 10146. [Google Scholar] [CrossRef]
- Demszky, D.; Movshovitz-Attias, D.; Ko, J.; Cowen, A.; Nemade, G.; Ravi, S. GoEmotions: A Dataset of Fine-Grained Emotions. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4040–4054. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V.; et al. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Advances in Neural Information Processing Systems: Vancouver, BC, Canada, 2019. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar] [CrossRef]
- Barbon, R.S.; Akabane, A.T. Towards Transfer Learning Techniques-BERT, DistilBERT, BERTimbau, and DistilBERTimbau for Automatic Text Classification from Different Languages: A Case Study. Sensors 2022, 22, 8184. [Google Scholar] [CrossRef]
- Alswaidan, N.; El, M.; Menai, B. A Survey of State-of-the-Art Approaches for Emotion Recognition in Text. Knowl. Inf. Syst. 2020, 62, 2937–2987. [Google Scholar] [CrossRef]
- Gee, G.; Wang, E. PsyML at SemEval-2018 Task 1: Transfer Learning for Sentiment and Emotion Analysis. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 369–376. [Google Scholar]
- Qin, Y.; Shi, Y.; Hao, X.; Liu, J. Microblog Text Emotion Classification Algorithm Based on TCN-BiGRU and Dual Attention. Information 2023, 14, 90. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 6382–6388. [Google Scholar]
- Kobayashi, S. Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics (ACL), New Orleans, LA, USA, 6 June 2018; Volume 2, pp. 452–457. [Google Scholar]
- Cambria, E.; Poria, S.; Hazarika, D.; Kwok, K. SenticNet 5: Discovering Conceptual Primitives for Sentiment Analysis by Means of Context Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: New Orleans, LA, USA, 2018; Volume 32, pp. 1795–1802. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30; Guyon, I., Von Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishanathan, S., Garnett, R., Eds.; Neural Info Process: San Diego, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Mohammad, S.; Bravo-Marquez, F.; Salameh, M.; Kiritchenko, S. Semeval-2018 Task 1: Affect in Tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 1–17. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Language | Features/Model | Evaluation |
|---|---|---|---|---|
| Ameer et al. [18] | 2023 | English | RoBERTa is used and a multiple-attention mechanism is added to the output of the RoBERTa | Micro F1-score, Macro F1-score, Jaccard Index score |
| Ahanin and Ismail [13] | 2022 | English | Word embedding (NTUA) and emoji embedding are used as features to the encoder module (Bi-LSTM + attention mechanism) | Micro F1-score, Macro F1-score, Jaccard index score |
| Alhuzali and Ananiadou [41] | 2021 | English | Emotion classes and input sentence are fed to encoder BERT | Micro F1-score, Macro F1-score Jaccard Index score |
| Demszky et al. [43] | 2020 | English | Created the largest human annotated dataset on Reddit comments, and employed BERT-based model | Precision, Recall, Macro average F1-score |
| Alswaidan and Menai [48] | 2020 | Arabic | Combined human-engineered features and deep learning features | Micro F1-score, Macro F1-score, Jaccard Index score |
| Ameer et al. [38] | 2020 | English | Unigram word features are used as input in BR and RF classifiers | Micro F1-score, Macro F1-score, Hamming Loss, Accuracy |
| Jabreel and Moreno [40] | 2019 | English | Pre-trained word embedding (GloVe) and trainable word embedding are used to create word representations and Bi-GRU is used in encoder module | Micro F1-score, Macro F1-score, Jaccard Index score |
| Gee and Wang [49] | 2018 | English | Pre-trained word embedding, and lexicon vectors are the inputs to the sub-models (LSTM, Bi-LSTM + attention mechanism) | Micro F1-score, Macro F1-score, Jaccard Index score |
| Baziotis et al. [25] | 2018 | English | Pre-trained word embedding (NTUA) was incorporated with Bi-LSTM and a multi-layer self-attention mechanism | Micro F1-score, Macro F1-score, Jaccard Index score |
| Dataset | Pre-Processing Status | Sentence |
|---|---|---|
| SemEval-2018 | Before Pre-processing | This man doesn’t even look for his real family 🙄😂 |
| After Pre-processing | this man does not even look for his real family 🙄😂 | |
| Data augmentation | this man does not even await for his real family 🙄 | |
| GoEmotions | Before Pre-processing | Hardly surprising. Now they also lost their coach… |
| After Pre-processing | hardly surprising now they also lost their coach | |
| Data augmentation | long finished now have also lost our coach |
| Parameter | Bi-LSTM + DLF + HEF | BERTbase | Bi-LSTM + Att [13] |
|---|---|---|---|
| Batch size | 32 | 8 (semEval-2018) 16 (GoEmotions) | 32 |
| Epochs | 30 | 8 | 30 |
| Learning rate | 0.001 | 0.001 | |
| Loss function | BinaryCrossentropy | BinaryCrossentropy | BinaryCrossentropy |
| Optimizer | Adam | Adam | Adam |
| Dropout rate | 0.3 | 0.3 |
| Dataset | Number of Instances |
|---|---|
| SemEval-2018 Task 1: E-C | Train (6838), Development (886), Test (3259) |
| GoEmotions | Train (43,410), Development (5426), Test (5427) |
| Dataset | Emotion | Number of Instances | Emotion | Number of Instances | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Dev | Test | Total | Train | Dev | Test | Total | |||
| Semval-2018 | Anger | 2544 | 315 | 1101 | 3960 | Optimism | 1984 | 307 | 1143 | 3434 |
| Anticipation | 978 | 124 | 425 | 1527 | Pessimism | 795 | 100 | 375 | 1270 | |
| Disgust | 2602 | 319 | 1099 | 4020 | Sadness | 2008 | 265 | 960 | 3233 | |
| Fear | 1242 | 121 | 485 | 1848 | Surprise | 361 | 35 | 170 | 566 | |
| Joy | 2477 | 400 | 1442 | 4319 | Trust | 357 | 43 | 153 | 553 | |
| Love | 700 | 132 | 516 | 1348 | ||||||
| GoEmotions | Admiration | 4130 | 488 | 504 | 5122 | Fear | 596 | 90 | 78 | 764 |
| Amusement | 2328 | 303 | 264 | 2895 | Gratitude | 2662 | 358 | 352 | 3372 | |
| Anger | 1567 | 195 | 198 | 1960 | Grief | 77 | 13 | 6 | 96 | |
| Annoyance | 2470 | 303 | 320 | 3093 | Joy | 1452 | 172 | 161 | 1785 | |
| Approval | 2939 | 397 | 351 | 3687 | Love | 2086 | 252 | 238 | 2576 | |
| Caring | 1087 | 153 | 135 | 1375 | Nervousness | 164 | 21 | 23 | 208 | |
| Confusion | 1368 | 152 | 153 | 1673 | Optimism | 1581 | 209 | 186 | 1976 | |
| Curiosity | 2191 | 248 | 284 | 2723 | Pride | 111 | 15 | 16 | 142 | |
| Desire | 641 | 77 | 83 | 801 | Realization | 1110 | 127 | 145 | 1382 | |
| Disappointment | 1269 | 163 | 151 | 1583 | Relief | 153 | 18 | 11 | 182 | |
| Disapproval | 2022 | 292 | 267 | 2581 | Remorse | 545 | 68 | 56 | 669 | |
| Disgust | 793 | 97 | 123 | 1013 | Sadness | 1326 | 156 | 143 | 1625 | |
| Embarrassment | 303 | 35 | 37 | 375 | Surprise | 1060 | 141 | 129 | 1330 | |
| Excitement | 853 | 96 | 103 | 1052 | Neutral | 14,219 | 1787 | 1766 | 17,772 | |
| SemEval-2018 | GoEmotions | ||||||
|---|---|---|---|---|---|---|---|
| Emotion | Train | Emotion | Train | Emotion | Train | Emotion | Train |
| Anger | 3502 | Admiration | 4167 | Disgust | 812 | Realization | 1135 |
| Anticipation | 2485 | Amusement | 2352 | Embarrassment | 914 | Relief | 308 |
| Disgust | 3743 | Anger | 1586 | Excitement | 861 | Remorse | 563 |
| Fear | 2983 | Annoyance | 2500 | Fear | 672 | Sadness | 1412 |
| Joy | 4195 | Approval | 2959 | Gratitude | 2682 | Surprise | 1073 |
| Love | 1613 | Caring | 1111 | Grief | 235 | Neutral | 14,277 |
| Optimism | 3442 | Confusion | 1377 | Joy | 1473 | ||
| Pessimism | 1927 | Curiosity | 2218 | Love | 2094 | ||
| Sadness | 3287 | Desire | 643 | Nervousness | 497 | ||
| Surprise | 967 | Disappointment | 1311 | Optimism | 1613 | ||
| Trust | 969 | Disapproval | 2039 | Pride | 224 | ||
| Model | Accuracy (Jaccard) | F1macro | F1micro |
|---|---|---|---|
| Proposed model (Bi-LSTM + DLF + HEF) | 68.40 | 65.77 | 78.55 |
| Bi-LSTM | 57.30 | 52.25 | 68.53 |
| BERT | 57.21 | 53.28 | 69.16 |
| BERT + Bi-LSTM | 56.88 | 53.71 | 69.05 |
| Ahanin and Ismail (Bi-LSTM + Att) [13] | 60.53 | 56.4 | 71.1 |
| Ameer et al. (RoBERTa + MA) [18] | 62.4 | 60.3 | 74.2 |
| Alhuzali and Ananiadou (BERT) [41] | 60.1 | 57.8 | 71.3 |
| Ameer et al. (RF + BR) [38] | 45.2 | 55.9 | 57.3 |
| Jabreel and A. Moreno (GRU) [40] | 59.0 | 56.4 | 69.2 |
| Baziotis et al. (Bi-LSTM) [25] | 58.8 | 52.8 | 70.1 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| Proposed model (Bi-LSTM + DLF + HEF) | 79.11 | 83.34 | 80.49 |
| Bi-LSTM | 72.79 | 62.70 | 66.04 |
| BERT | 71.92 | 64.26 | 67.03 |
| BERT + Bi-LSTM | 70.66 | 65.34 | 67.31 |
| Ahanin and Ismail (Bi-LSTM + Att) [13] | 70.22 | 70.31 | 69.41 |
| Model | Accuracy (Jaccard) | Precisionmacro | Recallmacro | F1macro |
|---|---|---|---|---|
| Proposed model (BERT + DLF + HEF) | 53.45 | 54% | 46% | 49% |
| Bi-LSTM | 46.34 | 61% | 27% | 31% |
| BERT + Bi-LSTM | 49.87 | 51% | 36% | 41% |
| Demszky et al. (BERT) [43] | 40% | 63% | 46% | |
| Ahanin and Ismail (Bi-LSTM + Att) [13] | 50.2 | 63% | 35% | 41% |
| Emotion | Precision | Recall | F1-Score | Emotion | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|---|
| Admiration | 65% | 68% | 67% | Fear | 68% | 64% | 66% |
| Amusement | 79% | 84% | 82% | Gratitude | 92% | 88% | 90% |
| Anger | 51% | 42% | 46% | Grief | 33% | 17% | 22% |
| Annoyance | 39% | 34% | 36% | Joy | 64% | 57% | 60% |
| Approval | 33% | 34% | 33% | Love | 78% | 83% | 81% |
| Caring | 43% | 39% | 40% | Nervousness | 4% | 26% | 32% |
| Confusion | 36% | 42% | 39% | Optimism | 54% | 46% | 50% |
| Curiosity | 51% | 49% | 50% | Pride | 60% | 38% | 46% |
| Desire | 57% | 41% | 48% | Realization | 24% | 14% | 18% |
| Disappointment | 38% | 26% | 31% | Relief | 67% | 36% | 47% |
| Disapproval | 41% | 37% | 39% | Remorse | 59% | 7% | 64% |
| Disgust | 52% | 41% | 46% | Sadness | 62% | 51% | 56% |
| Embarrassment | 40% | 22% | 28% | Surprise | 57% | 46% | 51% |
| Excitement | 51% | 39% | 44% | Neutral | 66% | 61% | 64% |
| Emotion | Accuracy |
|---|---|
| Anger | 89.82 |
| Anticipation | 88.69 |
| Disgust | 86.93 |
| Fear | 94.69 |
| Joy | 90.70 |
| Love | 89.91 |
| Optimism | 84.45 |
| Pessimism | 90.10 |
| Sadness | 87.53 |
| Surprise | 95.54 |
| Trust | 95.32 |
| Emotion | Accuracy | Emotion | Accuracy |
|---|---|---|---|
| Admiration | 82.68 | Fear | 97.24 |
| Amusement | 90.46 | Gratitude | 87.80 |
| Anger | 93.55 | Grief | 99.83 |
| Annoyance | 89.79 | Joy | 94.56 |
| Approval | 87.64 | Love | 91.39 |
| Caring | 95.38 | Nervousness | 99.30 |
| Confusion | 94.03 | Optimism | 93.94 |
| Curiosity | 90.44 | Pride | 99.52 |
| Desire | 97.44 | Realization | 95.80 |
| Disappointment | 95.41 | Relief | 99.69 |
| Disapproval | 91.10 | Remorse | 97.83 |
| Disgust | 96.04 | Sadness | 94.80 |
| Embarrassment | 98.99 | Surprise | 95.38 |
| Excitement | 96.72 | Neutral | 58.02 |
| Sentence | Label(s) | Prediction | ||
| Ours | Baseline (Bi-LSTM) | Baseline (BERT) | ||
| [Case #1] #Deppression is real. Partners w/ #depressed people truly dont understand the depth in which they affect us. Add in #anxiety & makes it worse | Fear, Sadness | Fear, Sadness | Sadness | Joy |
| [Case #2] Some people just need to learn how to #smile 😁 and #laugh 😂😂 #live #life | Joy, Love, optimism | Joy, Love, Optimism | Joy, Love, Optimism | Anticipation, Optimism, |
| [Case #3] We may have reasons to disagree but that in itself is no reason to hate. Our resentment is more a reflection of ourselves than others. | Anger, Optimism, Trust | Anger, Optimism, Trust | Anger, Disgust, Sadness | Anticipation |
| [Case #4] Life is too short to hide your feelings. Don’t be afraid to say what you feel. | Fear, Optimism | Fear, Optimism | Fear | Sadness |
| [Case # 5] Can’t sleep!! Maybe #worry !!!!!! Or Maybe I need to Chang my pillow !! Maybe..!😏 | Fear, Sadness | Fear, Sadness | None | Sadness |
| Sentence | Label(s) | Prediction | ||
|---|---|---|---|---|
| Ours | Baseline (Bi-LSTM) | Baseline (BERT) | ||
| [Case #6] Comparing yourself to others is one of the root causes for feelings of unhappiness and depression. | Sadness | Sadness, Pessimism | Sadness | Anger, Disgust |
| [Case #7] Scared to leave the routine but excited to break out the mould 😖 #scared #confused #happy #undecided #excited | Fear, Joy | Fear, Joy Optimism | Fear, Joy | Fear, Sadness |
| [Case #8] You hold my every moment you calm my raging seas you walk with me through fire and heal all my disease 💕💕💕❤❤ | Joy, Love, Optimism | Anger, Disgust, Love | Joy, Love, Optimism | Anger, Disgust |
| [Case #9] What makes you feel #joyful? | Joy | Joy, Love, Optimism | Joy, Love, Optimism | Joy |
| [Case #10] suddenly I want to be in the middle of chaos, feel the #wonderful sense of sound; my feet are tired of these long stretched silences | Joy, Optimism | Sadness | Sadness | Joy, optimism |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahanin, Z.; Ismail, M.A.; Singh, N.S.S.; AL-Ashmori, A. Hybrid Feature Extraction for Multi-Label Emotion Classification in English Text Messages. Sustainability 2023, 15, 12539. https://doi.org/10.3390/su151612539
Ahanin Z, Ismail MA, Singh NSS, AL-Ashmori A. Hybrid Feature Extraction for Multi-Label Emotion Classification in English Text Messages. Sustainability. 2023; 15(16):12539. https://doi.org/10.3390/su151612539
Chicago/Turabian StyleAhanin, Zahra, Maizatul Akmar Ismail, Narinderjit Singh Sawaran Singh, and Ammar AL-Ashmori. 2023. "Hybrid Feature Extraction for Multi-Label Emotion Classification in English Text Messages" Sustainability 15, no. 16: 12539. https://doi.org/10.3390/su151612539
APA StyleAhanin, Z., Ismail, M. A., Singh, N. S. S., & AL-Ashmori, A. (2023). Hybrid Feature Extraction for Multi-Label Emotion Classification in English Text Messages. Sustainability, 15(16), 12539. https://doi.org/10.3390/su151612539