


Integrated Energy System Based on Isolation Forest and Dynamic Orbit Multivariate Load Forecasting
 ,
,
Abstract
:1. Introduction
- A new anomaly data detection method is proposed. Based on the iForest algorithm, the extreme values and some outliers of the high-dimensional data matrix are identified.
- A new abnormal data correction method is proposed. The dynamic orbit method is used to analyze and repair the abnormal data hidden in the time series. If the abnormal value data are found, the system triggers an alarm, enters the behavior analysis link of the news surface, visualizes the separation window, and distinguishes the type of abnormal value.
- To determine the dependencies between multiple loads. The correlation analysis of the multivariate load and its weather data is carried out by an autoregressive (AR) method and maximal information coefficient (MIC) method, and a high-dimensional feature matrix is constructed.
- A new load forecasting structure is proposed. Based on the TCN-MMoL (multi-gate mixture-of-experts of LSTM) multi-task training network, the predicted value of the multi-load is output.
2. Related Work
2.1. The Isolation Forest
- Randomly select a feature and choose a split point within the range of the feature values.
- Use the selected feature and split point as the splitting rule to divide the data points into two subsets.
- Recursively repeat steps one and two until each subset contains only one data point or reaches the maximum depth defined in advance for the tree.
- Construct multiple random trees and form a random forest.
- For each data point, calculate its path length in the random forest, which is the average number of edges from the root node to the data point.
- The anomaly score of a data point is measured by its path length. A shorter path length indicates an outlier that is easily isolated, while a longer path length indicates a normal point.
- Finally, by setting a threshold, the path lengths can be compared with the probability of abnormal points to determine which data points should be classified as anomalies.
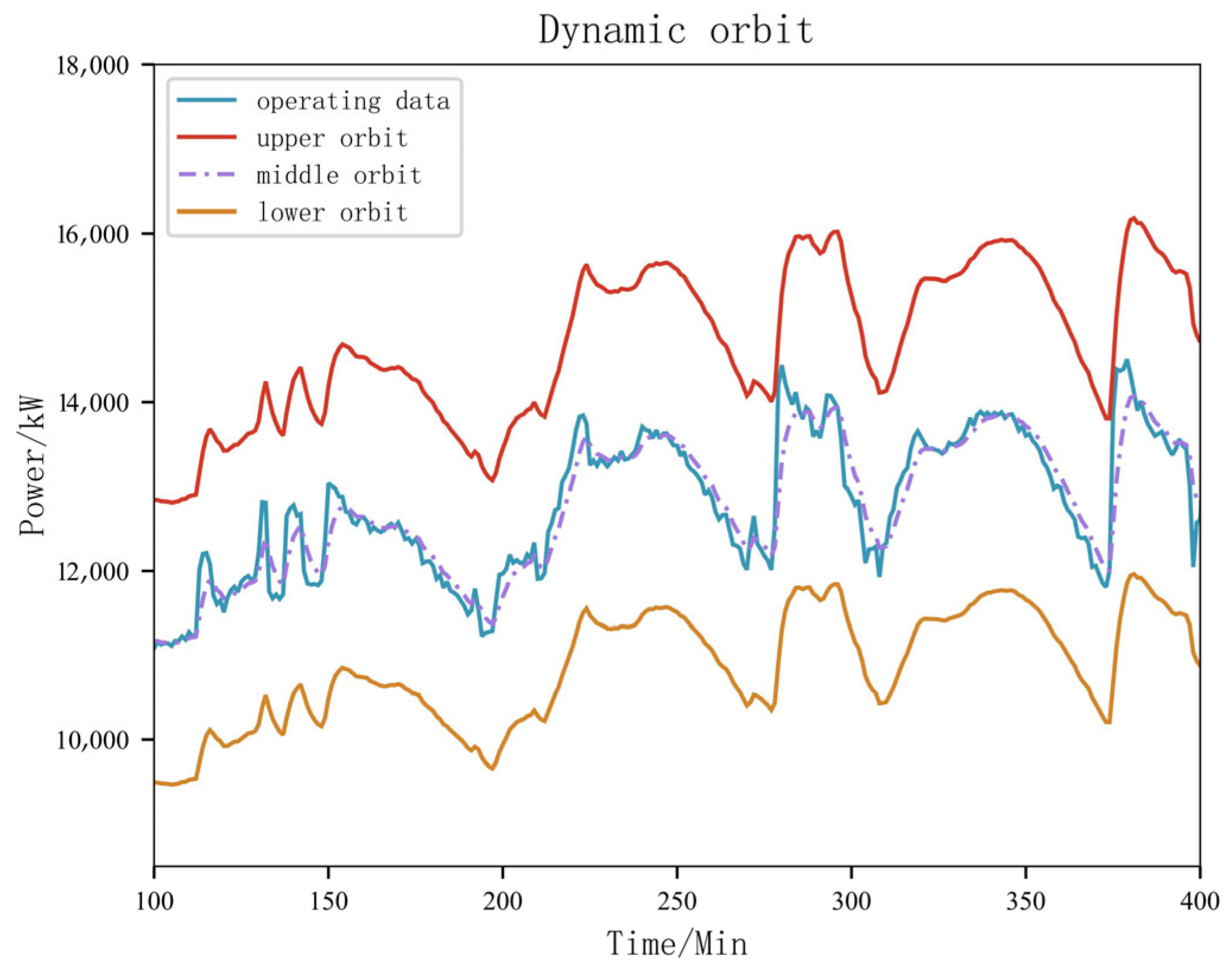
2.2. Dynamic Orbit
Simple Moving Average
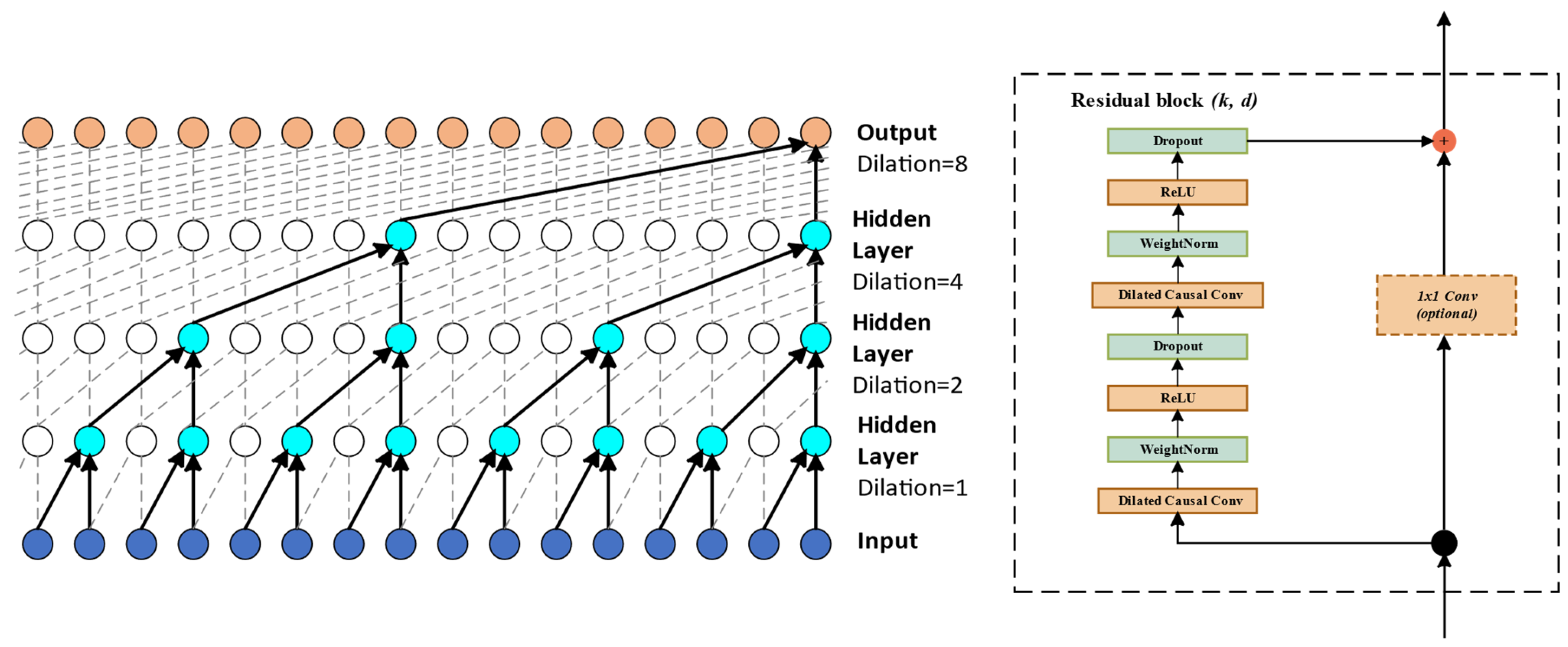
2.3. Temporal Convolutional Neural Network
- Causal Convolution: TCN utilizes a unique form of causal convolution, which preserves the causality of the input sequence, prevents leakage of future data, and expands the receptive field. The entire network’s perception range and information length are the same as the input sequence, ensuring that the sequence influences the deep network as a whole.
- Dilated Convolution: To address the problem of information overlap, TCN employs dilated convolution. Unlike regular convolution, the convolutional kernel of dilated convolution reads data through interval sampling. This sampling technique allows TCN to acquire a larger receptive field for sequence feature extraction and preserve more historical information. The output of dilated convolution is obtained by accumulating the element-wise multiplication of the convolutional kernel and the input.
- Residual Module: To address the problem of gradient vanishing caused by convolutional degradation, TCN introduces the residual module, which consists of two dilated causal convolutions, batch normalization, dropout, and ReLU activation function, among others. The advantage of the residual module is that it prevents excessive information loss during feature extraction. By adding the features extracted to the input data using causal convolutions, the final output is obtained. Additionally, a 1 × 1 convolutional layer is added to maintain the same scale of output as the input.
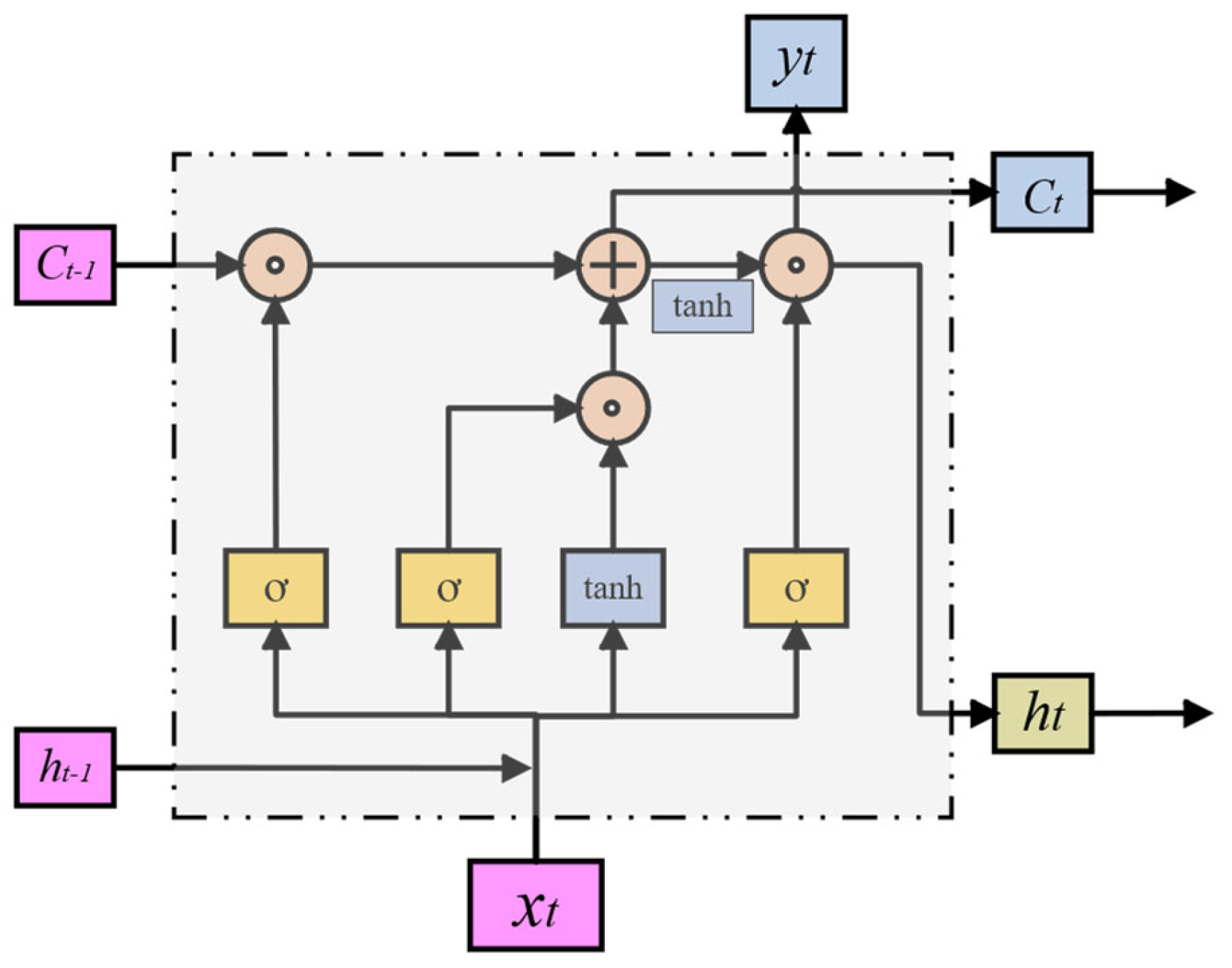
2.4. Long Short-Term Memory
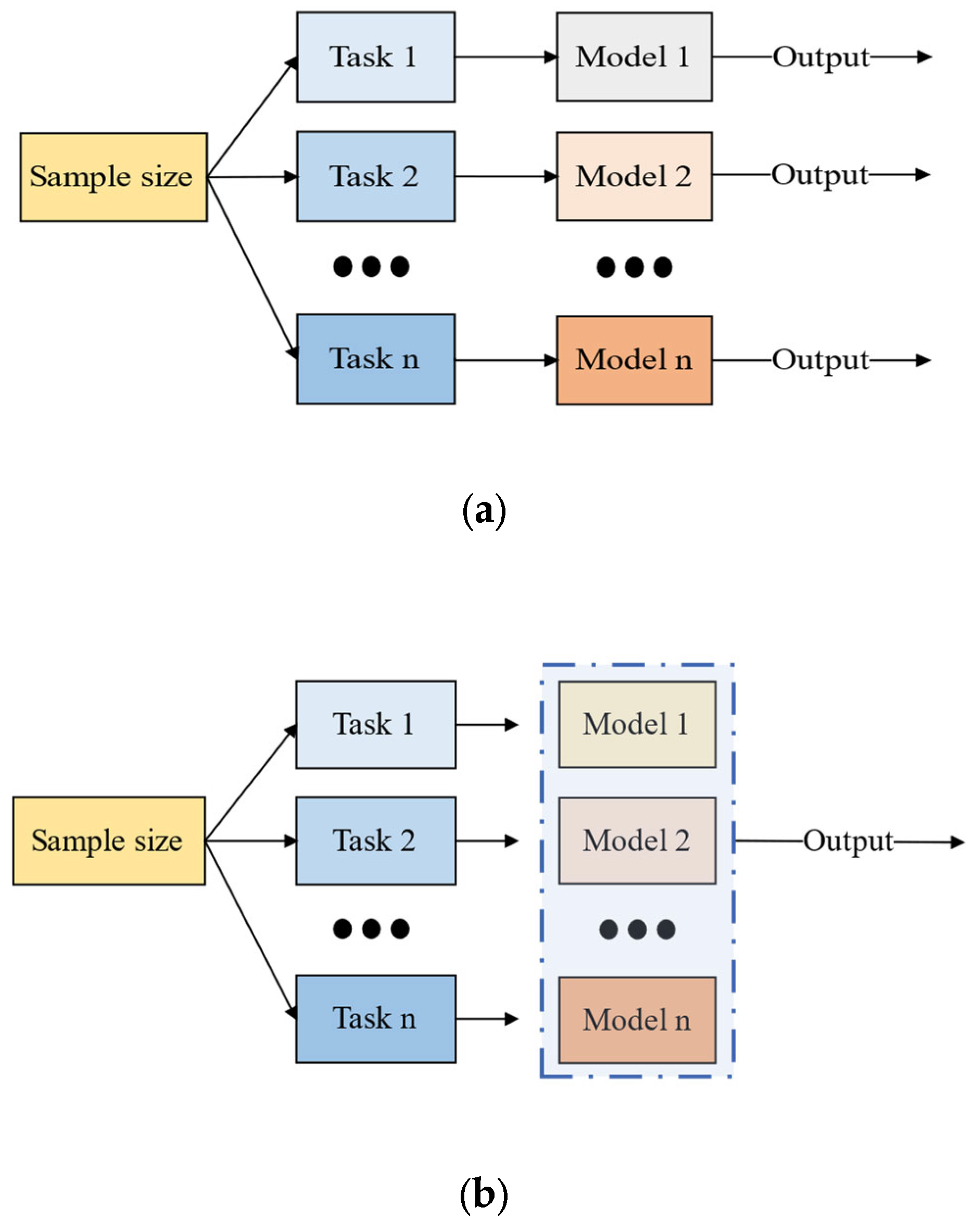
2.5. The Multi-Task Learning Mechanism
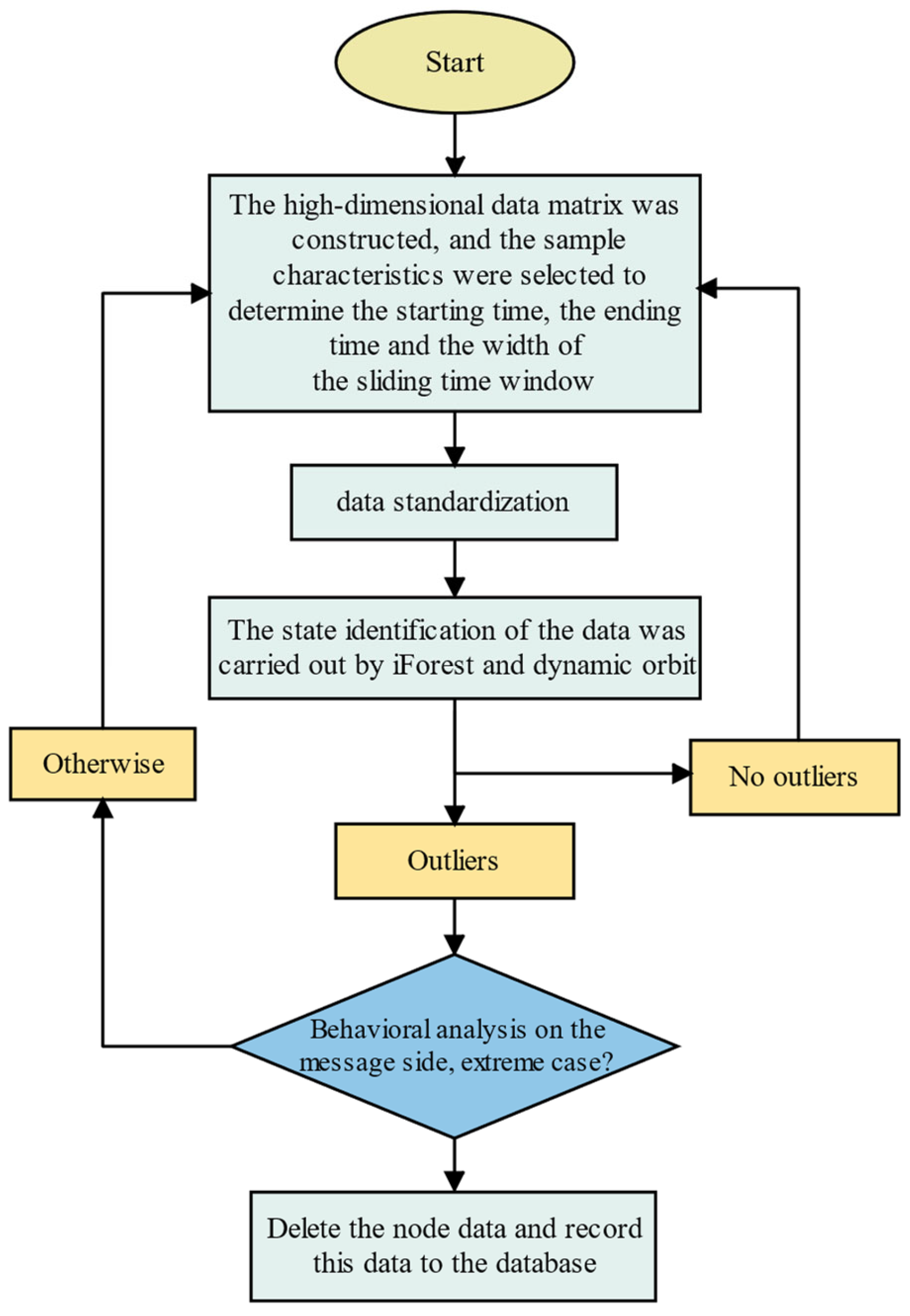
3. Data Feature Preprocessing
3.1. Construction of High-Dimensional Data Matrices
3.2. Data Standardization
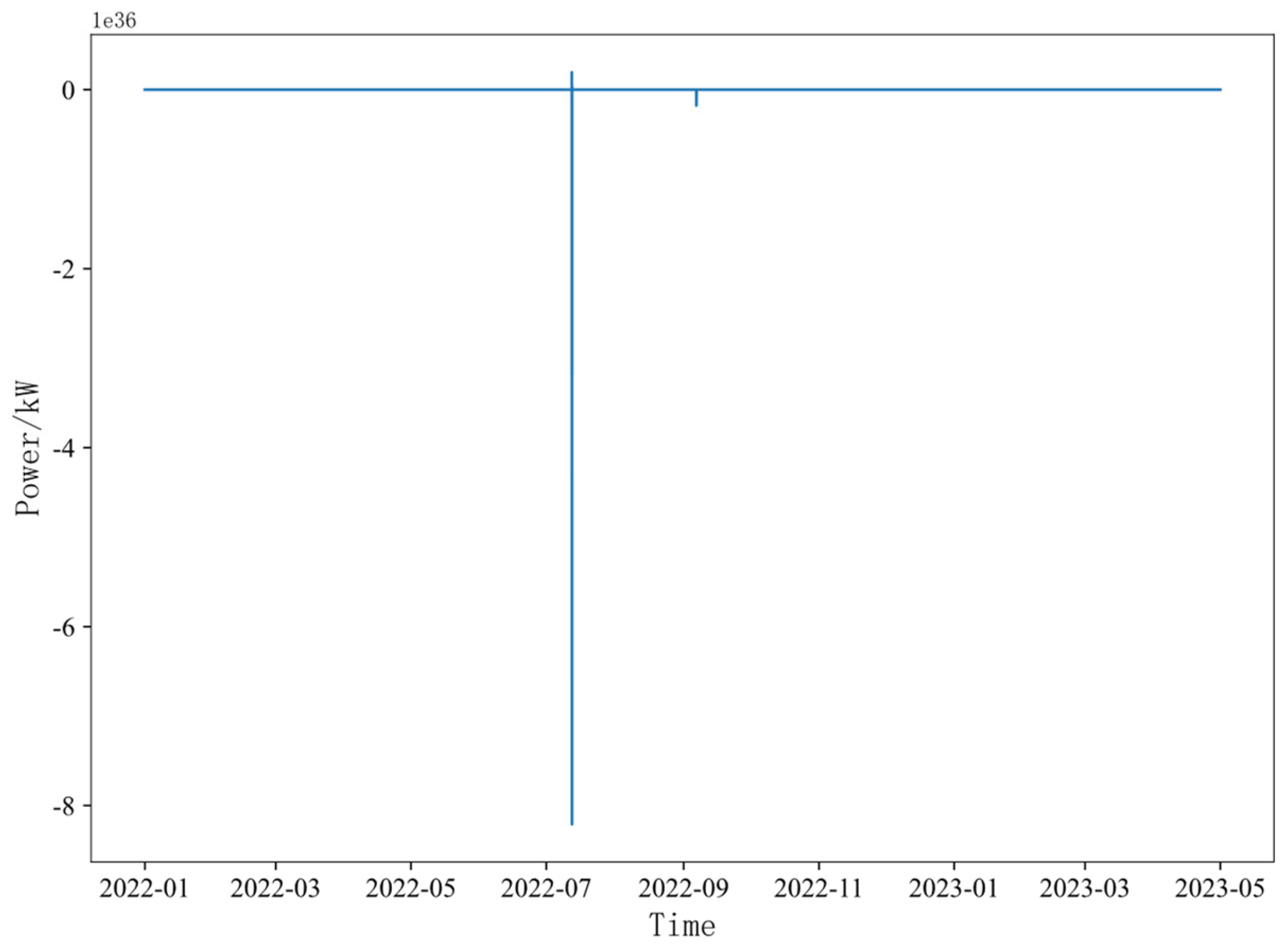
3.3. Data Outlier Recognition and Correction
4. Construction of Input Feature Set and Multi-Load Prediction Model
4.1. Correlation Analysis of Multi-Loads
4.1.1. Autoregressive System Analysis
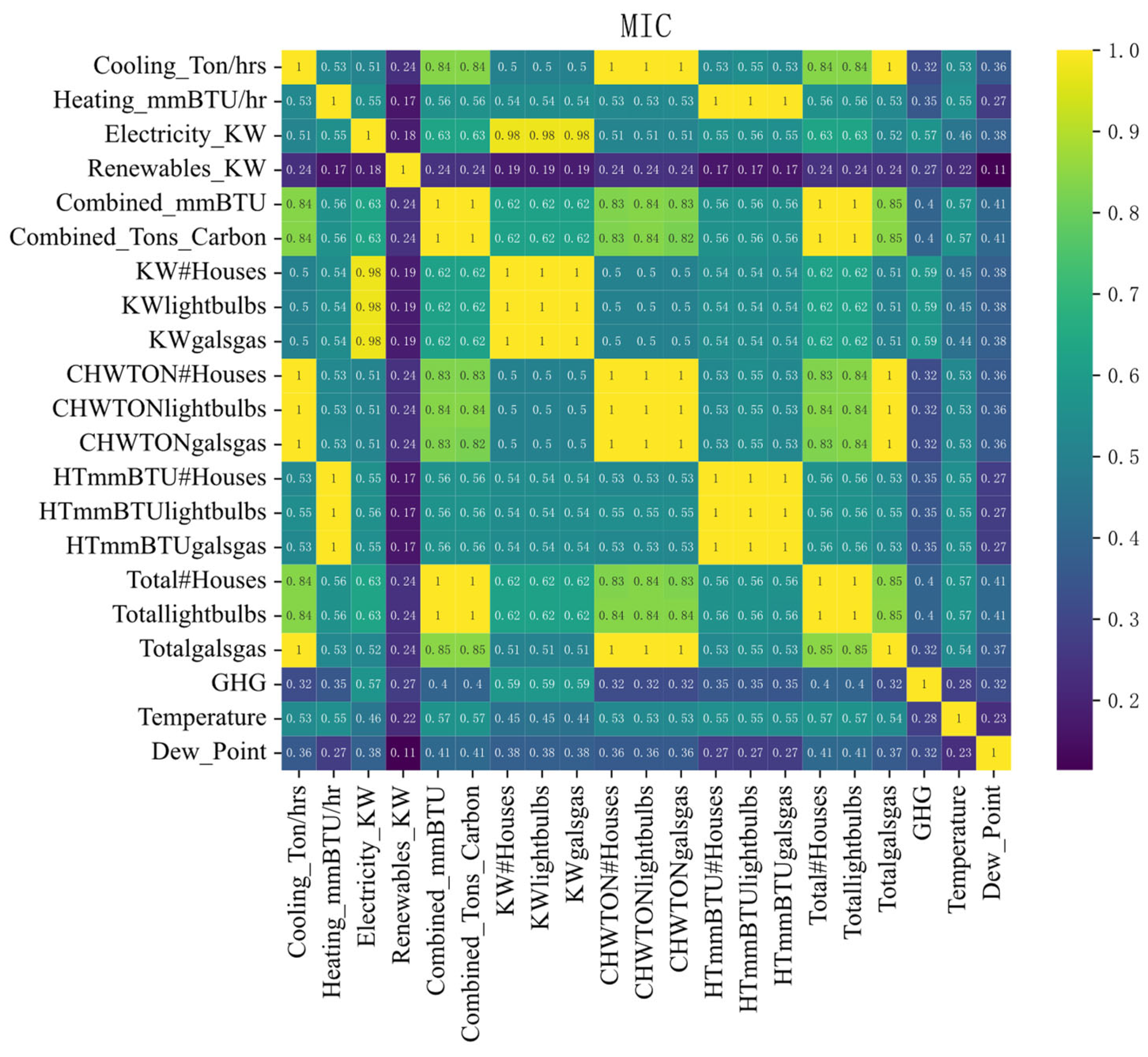
4.1.2. Maximal Information Coefficient Analysis
4.2. Construction of Input Feature Set
4.3. Multi-Load Prediction Model
4.3.1. Model Framework
4.3.2. Evaluation Metrics
5. Experiment Analysis
5.1. Experiment Description
5.2. Analysis of the Necessity of Global Use of the iForest Algorithm
5.3. Super Parameter Settings
5.4. Performance Analysis of Different Prediction Models
- Based on iForest-TCN-MMoL multiple load forecasting model (ITMMoL model).
- Based on iForest-Dynamic Orbit-CNN-LSTM multivariate load forecasting model (IDCLSTM model).
- Based on iForest-Dynamic Orbit-TCN-MMoL multiple load forecasting model (IDTMMoL model).
5.4.1. Validity Analysis of Data Preprocessing
5.4.2. Analysis of the Effectiveness of the Model Optimization Strategy
6. Conclusions
- The Lonely Forest algorithm can deal with the outlier problem in high-dimensional big data and has the characteristics of high processing accuracy and fast calculation speed.
- The dynamic orbit method can effectively eliminate the hidden outliers in the time series, and the cleaning effect is good, which provides a good foundation for the neural network prediction model.
- The coupling relationship between load data in the integrated energy system is complex. The AR method can analyze the time series characteristics of the load, and the MIC method can mine the spatial characteristics between the loads and construct a high-dimensional feature matrix with strong correlation, which lays a foundation for improving the accuracy of the prediction model.
- Through the reasonable design of the TCN-MMoL network structure, the coupling characteristics of historical data are better learned from the three aspects of data feature capture, learning, and multi-task allocation, and the prediction accuracy is improved, which proves the effectiveness of the algorithm in the time series feature sequence.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, Z.; Liu, D.; Shen, X.; Wang, G.; Yu, P.; Li, Z. A review of research on operation optimization techniques for integrated energy systems. Electr. Power Constr. 2022, 43, 3–14. [Google Scholar]
- Xi, D.; Xiaoyan, Z.; Shenghan, W.; Chutong, W.; Houbao, X.; Chuangxin, G. Low-carbon planning of regional integrated energy system considering the optimal construction timing under the dual-carbon goal. High-Volt. Technol. 2022, 48, 2584–2596. [Google Scholar]
- Zhou, Q.; Sun, Y.; Lu, H.; Wang, K. Learning-based green workload placement for energy internet in smart cities. J. Mod. Power Syst. Clean Energy 2022, 10, 91–99. [Google Scholar] [CrossRef]
- Dong, Y.; Shan, X.; Yan, Y.; Leng, X.; Wang, Y. Architecture, key technologies and applications of load dispatching in China power grid. J. Mod. Power Syst. Clean Energy 2022, 10, 316–327. [Google Scholar] [CrossRef]
- Chen, L.; Xu, Q.; Yang, Y.; Gao, H.; Xiong, W. Community integrated energy system trading: A comprehensive review. J. Mod. Power Syst. Clean Energy 2022, 10, 1445–1458. [Google Scholar] [CrossRef]
- Pan, X.; Wenlong, F.; Qipeng, L.; Shihai, Z.; Renming, W.; Jiaxin, M. Stability analysis of hydro-turbine governing system with sloping ceiling tailrace tunnel and upstream surge tank considering nonlinear hydro-turbine characteristics. Renew. Energy 2023, 210, 556–574. [Google Scholar]
- Peng, L.; Fan, Z.; Xiyuan, M.; Senjing, Y.; Zhuolin, Z.; Ping, Y.; Zhuoli, Z.; Sing, L.C.; Lei, L.L. Multi-Time Scale Economic Optimization Dispatch of the Park Integrated Energy System. Front. Energy Res. 2021, 9, 743619. [Google Scholar]
- Guo, X.; Lou, S.; Wu, Y.; Wang, Y. Low-carbon operation of combined heat and power integrated plants based on solar-assisted carbon capture. J. Mod. Power Syst. Clean Energy 2021, 10, 1138–1151. [Google Scholar] [CrossRef]
- Sobhan, D.; Masoud, R.; Farshad, F.A.S.; Amir, A.; Reza, S.M. An integrated model for citizen energy communities and renewable energy communities based on clean energy package: A two-stage risk-based approach. Energy 2023, 277, 127727. [Google Scholar]
- Zhu, J.; Liu, H.; Ye, H. Summary of research on optimal operation of integrated energy system in the park. High Volt. Technol. 2022, 48, 2469–2482. [Google Scholar]
- Yan, C.; Bie, Z.; Liu, S.; Urgun, D.; Singh, C.; Xie, L. A reliability model for integrated energy system considering multi-energy correlation. J. Mod. Power Syst. Clean Energy 2021, 9, 811–825. [Google Scholar] [CrossRef]
- Zhang, Y.; Xie, X.; Chen, X.; Hu, S.; Zhang, L.; Xia, Y. An Optimal Combining Attack Strategy Against Economic Dispatch of Integrated Energy System. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 246–250. [Google Scholar] [CrossRef]
- Jizhong, Z.; Hanjiang, D.; Shenglin, L.; Ziyu, C.; Tengyan, L. Review of data-driven load forecasting for integrated energy systems. Chin. J. Electr. Eng. 2021, 41, 7905–7924. [Google Scholar]
- Chandrahas, M.L.D.G. Deep Machine Learning and Neural Networks: An Overview. IAES Int. J. Artif. Intell. 2017, 6, 66–73. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Ping, F.; Wenlong, F.; Kai, W.; Dongzhen, X.; Kai, Z. A compositive architecture coupling outlier correction, EWT, nonlinear Volterra multi-model fusion with multi-objective optimization for short-term wind speed forecasting. Appl. Energy 2022, 307, 118191. [Google Scholar]
- Shi, J.; Tan, T.; Guo, J. Multivariate load forecasting of park-type integrated energy system based on deep structure multi-task learning. Grid Technol. 2018, 42, 698–707. [Google Scholar]
- Wang, S.; Wang, S.; Chen, H.; Gu, Q. Multi-energy load forecasting for regional integrated energy systems considering temporal dynamic and coupling characteristics. Energy 2020, 195, 116964. [Google Scholar] [CrossRef]
- Yang, N.; Yang, C.; Wu, L.; Shen, X.; Jia, J.; Li, Z.; Chen, D.; Zhu, B.; Liu, S. Intelligent Data-Driven Decision-Making Method for Dynamic Multisequence: An E-Seq2Seq-Based SCUC Expert System. IEEE Trans. Ind. Inform. 2021, 18, 3126–3137. [Google Scholar] [CrossRef]
- Tan, Z.; De, G.; Li, M.; Lin, H.; Yang, S.; Huang, L. Combined electricity-heat-cooling-gas load forecasting model for integrated energy system based on multi-task learning and least square support vector machine. J. Clean. Prod. 2020, 248, 119252. [Google Scholar] [CrossRef]
- Zhou, D.; Ma, S.; Hao, J.; Han, D.; Huang, D.; Yan, S.; Li, T. An electricity load forecasting model for Integrated Energy System based on BiGAN and transfer learning. Energy Rep. 2020, 6, 3446–3461. [Google Scholar] [CrossRef]
- Long, C.; Zhongyang, H.; Jun, Z.; Wei, W. Review of data-driven integrated energy system operation optimization methods. Control Decis.-Mak. 2021, 36, 283–294. [Google Scholar]
- Nan, Y.; Tao, Q.; Lei, W.; Yu, H.; Yuehua, H.; Chao, X.; Lei, Z.; Binxin, Z. A multi-agent game based joint planning approach for electricity-gas integrated energy systems considering wind power uncertainty. Electr. Power Syst. Res. 2021, 204, 107673. [Google Scholar]
- Zihan, M.; Shouxiang, W.; Qianyu, Z.; Zhijie, Z.; Liang, F. Reliability evaluation of electricity-gas-heat multi-energy consumption based on user experience. Int. J. Electr. Power Energy Syst. 2021, 130, 106926. [Google Scholar]
- Smiti, A. A critical overview of outlier detection methods. Comput. Sci. Rev. 2020, 38, 100306. [Google Scholar] [CrossRef]
- Xu, S.; Li, Y.; Yuan, Q. A combined pruning method based on reinforcement learning and 3σ criterion. J. Zhejiang Univ. (Eng. Ed.) 2023, 57, 486–494. [Google Scholar]
- Kai, M.; Rencai, Z.; Jie, Y.; Debao, S. Collaborative optimization strategy of integrated energy system considering demand response. Renew. Energy 2023, 41, 676–684. [Google Scholar]
- Yulong, Y.; Xinge, W.; Ziye, Z.; Rong, J.; Chong, Z.; Songyuan, L.; Pengyu, Y. Integrated energy optimization scheduling considering extended carbon emission flow and carbon trading bargaining model. Power Syst. Autom. 2023, 47, 34–46. [Google Scholar]
- Caicedo, J.E.; Agudelo Martínez, D.; Rivas Trujillo, E.; Meyer, J. A systematic review of real-time detection and classification of power quality disturbances. Prot. Control Mod. Power Syst. 2023, 8, 3. [Google Scholar] [CrossRef]
- Xinyu, W.; Ke, L. LF Ant Colony Clustering Algorithm with Global Memory. J. Comput. Eng. Appl. 2019, 55, 52–57+113. [Google Scholar]
- Xiong, K.; Ding, Q.; Zhu, H. Fault detection of chillers based on isolated forest and KDE-LOF. Comput. Appl. Softw. 2023, 40, 84–89. [Google Scholar]
- Shaolan, L.; Huawei, W.; Zhaoguo, H.; Lingzi, C. Unmanned Aerial Vehicle Anomaly Detection Algorithm Based on Ensemble Isolation Forest. Radio Eng. 2022, 52, 1375–1385. [Google Scholar]
- Feilu, H.; Wei, G.; Hexiong, C.; Zhenhong, Z.; Dongyang, Y. Traffic anomaly detection based on iForest and LOF. Comput. Appl. Res. 2022, 39, 3119–3123. [Google Scholar]
- Lesouple, J.; Baudoin, C.; Spigai, M. Generalized isolation forest for anomaly detection. Pattern Recognit. Lett. 2021, 149, 109–119. [Google Scholar] [CrossRef]
- Mikhail, T.; Paweł, K. A probabilistic generalization of isolation forest. Inf. Sci. 2022, 584, 433–449. [Google Scholar]
- Huichun, X.; Yuan, N.; Jiangong, Z.; Yanzhao, W.; Yemao, Z.; Zheyuan, G. Discrimination of measured outliers of ground synthetic electric field of DC transmission lines based on ARIMA and exponential smoothing method. High Volt. Technol. 2023, 49, 2161–2170. [Google Scholar]
- Su, Y.; Cui, C.; Qu, H. Time series prediction based on self-attention moving average. J. Nanjing Univ. (Nat. Sci.) 2022, 58, 649–657. [Google Scholar]
- Reza, M.M.; Salman, B. Modeling the stochastic mechanism of sensor using a hybrid method based on seasonal autoregressive integrated moving average time series and generalized estimating equations. ISA Trans. 2021, 125, 300–305. [Google Scholar]
- Surria, N.; Muhammad, A.U.N.; Muhammad, M.; Ahmed, A. Hybrid exponentially weighted moving average control chart using Bayesian approach. Commun. Stat.-Theory Methods 2022, 51, 3960–3984. [Google Scholar]
- Pengfei, Z.; Bo, H.; Jinsong, H.; Zhanshuo, H.; Hengyu, L.; Yubo, L. Short-term spatial load forecasting method based on spatio-temporal graph convolutional network. Power Syst. Autom. 2023, 47, 78–85. [Google Scholar]
- Xiaojian, W.; Yihua, W.; Aichun, W.; Yao, L.; Ruixue, Z. LSTM-GRU vehicle trajectory prediction based on Dropout and attention mechanism. J. Hunan Univ. (Nat. Sci. Ed.) 2023, 50, 65–75. [Google Scholar]
- Zhonglin, L.; Jie, G.; Lu, M. Short-term load forecasting of integrated energy system based on coupling characteristics and multi-task learning. Power Syst. Autom. 2022, 46, 58–66. [Google Scholar]
- Xurui, H.; Fengyuan, Y.; Bo, Y.; Jun, P.; Qin, X. Electric-thermal short-term load forecasting method of park integrated energy system based on Transformer network and multi-task learning. China South. Power Grid Technol. 2023, 17, 152–160. [Google Scholar]
- Haixiang, Z.; Ruiqi, X.; Jingxuan, L.; Yuwei, C.; Zhinong, W.; Guoqiang, S. Multi-Task Short-Term Load Forecasting for Users Based on Multi-Dimensional Fusion Features and Convolutional Neural Network. Autom. Electr. Power Syst. 2023, 47, 69–77. [Google Scholar]
- Wang, B.; Bai, Y.; Xing, H. A joint prediction method for ultra-short-term power of regional multi-photovoltaic power stations based on STL and MMoE multi-task learning. J. Power Syst. Autom. 2022, 34, 17–23+31. [Google Scholar]
- Li, C.; Li, G.; Wang, K. A multi-energy load forecasting method based on parallel architecture CNN-GRU and transfer learning for data deficient integrated energy systems. Energy 2022, 259, 124967. [Google Scholar] [CrossRef]
- Li, Y.; Bu, F.; Gao, J.; Li, G. Considering the low-carbon optimal operation of the integrated energy system of solar thermal power station and LAES. Electr. Meas. Instrum. 2022, 378, 134540. [Google Scholar]
- Wu, C.; Yao, J.; Xue, G. Load forecasting of integrated energy system based on MMoE multi-task learning and long short-term memory network. Power Autom. Equip. 2022, 42, 33–39. [Google Scholar]
- Qian, K.; Lv, T.; Yuan, Y. Integrated energy system planning optimization method and case analysis based on multiple factors and a three-level process. Sustainability 2021, 13, 7425. [Google Scholar] [CrossRef]
- Rui, H.; Lingli, Z.; Feng, G. Short-term Power Load Forecasting Method Based on Variational Modal Decomposition for Convolutional Long-short-term Memory Network. Mod. Electr. Power 2023. [Google Scholar] [CrossRef]
- Jiang, C.; Ai, X. A review of collaborative planning methods for integrated energy systems in industrial parks. Glob. Energy Internet 2019, 2, 255–265. [Google Scholar]
- Liu, Y.; Huang, Y.; Tan, H. Online prediction method of wing flexible baseline based on autoregressive model. J. Beijing Univ. Aeronaut. Astronaut. 2022, 48. [Google Scholar] [CrossRef]
- Cen, L.; Li, J.; Lin, C.; Wang, X. Approximate query processing method based on deep autoregressive model. Comput. Appl. 2023, 43, 2034. [Google Scholar]
- Shuliang, W.; Surapunt, T. Bayesian Maximal Information Coefficient (BMIC) to reason novel trends in large datasets. Appl. Intell. 2022, 52, 10202–10219. [Google Scholar] [CrossRef]
- Ling, Q.; Zhang, Q.; Zhang, J. Prediction of landslide displacement using multi-kernel extreme learning machine and maximum information coefficient based on variational mode decomposition: A case study in Shaanxi, China. Nat. Hazards 2021, 108, 925–946. [Google Scholar] [CrossRef]
- Lawrence Berkeley National Laboratory. EnergyPlus-Engineering Documentation: The Reference to EnergyPlus Calculations; University of Illinois: Chicago, IL, USA; Ernest Orlando Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2001.
- Yue, W.; Liu, Q. Multivariate load forecasting of integrated energy system based on PCC-LSTM-MTL. J. Shanghai Electr. Power Univ. 2022, 38, 483–487+494. [Google Scholar]
- Wang, Y.; Liu, E.; Huang, Y. Data-driven short-term multi-load forecasting of integrated energy systems. Comput. Eng. Des. 2022, 43, 1435–1442. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Specification | |
|---|---|---|
| Input feature | Cooling load | The power value of the cooling load |
| Heating load | The power value of the heating load | |
| Electric load | The power value of the electric load | |
| Temperature | Temperature of the record | |
| Dew point | Dew point of the record | |
| Cooling houses | Number of buildings using cooling load | |
| Heating houses | Number of buildings using heating load | |
| Electric houses | Number of buildings using electric load |
| Description of Parameters | Hyperparameters | Numerical Values/Types | |
|---|---|---|---|
| Dynamic Orbit | M1 | 15% | |
| M2 | 15% | ||
| TCN layer | Filters | 43 | |
| Kernel size | 4 | ||
| Stacks | 1 | ||
| Dilation rate | [1, 2, 4, 8, 16] | ||
| Dropout rate | 0.2 | ||
| MMoL layer | LSTM1 | Filters | 32 |
| Dropout | 0.02 | ||
| Return sequences | True | ||
| LSTM2 | Filters | 26 | |
| Dropout | 0.02 | ||
| Return sequences | True | ||
| LSTM3 | Filters | 16 | |
| Dropout | 0.02 | ||
| Return sequences | / | ||
| MMoE | Hidden units | 43 | |
| Expert | 5 | ||
| Task | 3 | ||
| Output network | Dense | ||
| Optimization parameters | Loss function | MAE | |
| Epoch | 100 | ||
| Optimizer | Adam | ||
| Batch size | 256 | ||
| Callbacks | Early Stopping | / | |
| Model Checkpoint | / | ||
| Model | Cooling Load | Heating Load | Electric Load | |||
|---|---|---|---|---|---|---|
| Mape / % | Mae / (Ton/h) | Mape / % | Mae / (mmBTU/h*1000) | Mape / % | Mae / kW | |
| ITMMoL | 6.37 | 432.08 | 5.54 | 350 | 3.29 | 356.02 |
| IDCLSTM | 6.98 | 472.61 | 6.35 | 390 | 3.79 | 428.7 |
| IDTMMoL | 3.80 | 404.74 | 5.43 | 330 | 2.80 | 324.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Ma, H.; Alharbi, A.M.; Wang, B.; Xiong, L.; Zhu, S.; Qin, L.; Wang, G. Integrated Energy System Based on Isolation Forest and Dynamic Orbit Multivariate Load Forecasting. Sustainability 2023, 15, 15029. https://doi.org/10.3390/su152015029
Wu S, Ma H, Alharbi AM, Wang B, Xiong L, Zhu S, Qin L, Wang G. Integrated Energy System Based on Isolation Forest and Dynamic Orbit Multivariate Load Forecasting. Sustainability. 2023; 15(20):15029. https://doi.org/10.3390/su152015029
Chicago/Turabian StyleWu, Shidong, Hengrui Ma, Abdullah M. Alharbi, Bo Wang, Li Xiong, Suxun Zhu, Lidong Qin, and Gangfei Wang. 2023. "Integrated Energy System Based on Isolation Forest and Dynamic Orbit Multivariate Load Forecasting" Sustainability 15, no. 20: 15029. https://doi.org/10.3390/su152015029
APA StyleWu, S., Ma, H., Alharbi, A. M., Wang, B., Xiong, L., Zhu, S., Qin, L., & Wang, G. (2023). Integrated Energy System Based on Isolation Forest and Dynamic Orbit Multivariate Load Forecasting. Sustainability, 15(20), 15029. https://doi.org/10.3390/su152015029