1. Introduction
Automated knowledge extraction has a two-dimensional technique such as autonomous extraction of shallow knowledge from massive document collections, and, then, cumulative statistics of mechanically collected superficial understanding suggest more semantics [
1]. Furthermore, traditional information extraction, semantic annotation, linguistic annotation in natural language processing (NLP), and ontology-based data extraction might help in automatic knowledge extraction and NLP for the lexicography of lower resource languages [
2,
3]. The involvement of people in an online social network (OSN) surged at the time of the COVID-19 pandemic since normal activities moved online [
4]. Several usages of OSN (i.e., individuals utilize OSN to express their thoughts, interact with relatives, have online meetings, and so on.) were shown [
5,
6]. Like other OSNs, the usage of the famous microblogging service Twitter also has an impact. It is the most popular social networking platform for interacting with common people and creates awareness of public health at the time of health crises [
7]. As a result, individuals generally spend time on Twitter, and users are very active at any time [
8]. Their participations rise during the time of lockdown to receive the latest news relating to COVID-19. Meanwhile, they share their feelings and opinions with their friends. Thus, Twitter data analysis pulls a massive interest from research scholars in this pandemic [
9,
10].
Political communication at the time of the COVID-19 epidemic called for crucial, strong, and efficient sense-making of the crisis [
11]. The language utilized by the leaders acts as a significant role in framing a chaotic and ambiguous crisis such that it could boost the deteriorating public spirit into a collective hope [
12]. Researchers have concentrated on the crisis-in-the-moment, wherein the roles and duties of the leaders are taken to be well-defined, and the unit of study is the progression of the crisis itself—that is, how the crisis is unfolding. However, the COVID-19 pandemic was not transitory but rather an ongoing reality requiring both retrospective and prospective sense-making of the situation by the leaders. It is necessary to create an emotionally charged situation where particular negative emotions (such as frustration, anxiety, shock, etc.) rise very soon, generating a challenging issue for decision-making [
13].
The mass media users were rising and the data volume was also rising; this concentrated on the utilization of natural language processing (NLP) having distinct methods of Artificial Intelligence (AI) for extracting meaningful data effectively [
14]. NLP and their applications resulted in a substantial influence on mass media classification and text analysis; however, the difficulties in determination of content’s inherent significance utilizing NLP approaches, such as contextual words and phrases and uncertainty in speech or text, mandate the usage of machine learning (ML)-related methods. Sentiment analysis (SA) includes executing some mathematical computations for examining people’s sentiments against a particular aspect or individual. Sentiment classification, subjectivity analysis, and opinion mining were other related terminologies in the literature [
15].
SA is performed by a lexicon-related technique such as linguistic inquiry word count (LIWC), SentiStrength, affective norms for English words (ANEW), Senti Word Net, an ML technique namely multinomial Naïve Bayes (MNB), Naïve Bayes (NB), multi-layer perceptron (MLP), Maximum Entropy, random forest (RF), support vector machine (SVM), or a hybrid technique which utilizes ML as well as a lexicon-based technique [
8]. ML computes sentiment polarity via statistical methods which are highly reliable on the dataset size and are ineffectual in dealing with intensifying and negative sentences and execute poorly in various fields. The lexicon-based method, contrarily, needs manual input of sentiment lexicons and is well-executed in any field but fails to encounter entire informal lexicons. The hybrid method will help overcome the limits of both methods, therefore improving scalability, performance, and efficiency [
15]. The study has proven that employing a hybrid technique hastens precision, sustains stabilities, and offers superior outcomes than utilizing one standard tool or one technique.
Recently, deep learning (DL) models are found useful for the sentiment classification process. Although several ML and DL models for sentiment classification are available in the literature, it is still needed to enhance the classification performance. Due to the incessant deepening of the model, the number of parameters involved in the DL models gets raised rapidly which leads to model overfitting. At the same time, different hyperparameters have a significant impact on the efficiency of the DL models. Particularly, hyperparameters such as epoch count, batch size, and learning rate selection are essential to attain effectual outcomes. Since the trial and error method for hyperparameter tuning is a tedious and erroneous process, metaheuristic algorithms can be applied. Therefore, in this work, we employ the marine predator optimization (MPO) algorithm for the parameter selection (i.e., learning rate, batch size, and number of epochs) of the BiRNN model.
This study develops a new Marine Predator Optimization with Natural Language Processing for Twitter Sentiment Analysis (MPONLP-TSA) for the COVID-19 pandemic. The presented MPONLP-TSA model primarily undergoes data pre-processing to convert the data into a useful format. In addition, the BERT model is used to derive word vectors. To detect and classify sentiments, a bidirectional recurrent neural network (BiRNN) model is utilized. At last, the MPO technique can be exploited for optimal hyperparameter tuning process, and it assists in enhancing the overall classification performance. The MPO algorithm is mainly inspired by the different foraging strategies of marine predators and the optimal encounter rate strategies between predators and prey. The experimental validation of the MPONLP-TSA approach can be tested utilizing the COVID-19 tweet dataset from the Kaggle repository.
2. Related Works
Mostafa [
16] suggests an SA model, which analyzes the sentiments of students during the learning procedure during the pandemic utilizing ML techniques and Word2vec approaches. The SA method commenced with processing the sentiments of students and choosing the features by words embedded after employing 3 ML classifiers that were SVM, decision tree (DT), and NB. In their study, [
17] introduce a structure which employs deep learning (DL)-based language methods through long short-term memory (LSTM) for SA at the time of the upsurge of COVID-19 cases in India. The structure features the LSTM language method, a recent Bidirectional Encoder Representations from Transformers (BERT) language method, and global vector embedding. Mohan et al. [
18] suggested a Prophet model and hybrid autoregressive integrated moving average (ARIMA) for predicting daily cumulative and confirmed cases. The auto ARIMA function has been initially utilized for selecting the optimum hyperparameter value of the ARIMA method. Afterwards, the altered ARIMA method has been utilized for finding the optimal fit among the test and predicting data for finding the optimal method parameter combinations.
Alkhaldi et al. [
19] offer a novel sunflower optimization with DL-driven SA and classification (SFODLD-SAC) on COVID-19 tweets. The suggested method aims to identify the sentiments of people at the time of the COVID-19 pandemic. For establishing this, SFODLD-SAC methodology formerly preprocessed the tweets in different means such as link punctuations, stemming, usernames, numerals, and removal of stopwords. Additionally, the TF-IDF method can be implied for valuable features extracted from the pre-processed data. Furthermore, the cascaded recurrent neural network (CRNN) method can be used for analyzing and classifying sentiments. In [
20], NLP techniques were used for opinion mining to derive positive and negative tweets or sentiments on COVID-19. The authors also examine NLP-related SA with the use of the recurrent neural network (RNN) method with LSTMs. Hossain et al. [
21] suggested a DL architecture based on Bidirectional Gated Recurrent Unit (BiGRU) for accomplishing this objective. Then, they advanced two distinct corpora from labeled and unlabeled COVID-19 tweets and employed the unlabeled corpus to construct an enhanced labelled corpus.
3. The Proposed Model
In this study, a novel MPONLP-TSA method is presented for the recognition of sentiments that exist in Twitter data during the COVID-19 pandemic. The presented MPONLP-TSA model performed data pre-processing to convert the data into a useful format. Following, the BERT model is used to derive word vectors. To detect and classify sentiments, the MPO algorithm with the BiRNN model is utilized.
Figure 1 exemplifies the overall working process of the MPONLP-TSA method.
3.1. Data Pre-Processing
Initially, the presented method pre-processed tweets in dissimilar ways, namely stemming, removing usernames, stopwords, numerals, and link punctuations.
Removing links and usernames on Twitter that do not affect SA.
Removal of punctuation marks such as hashtags and conversion to lower case
Removal of numerals and stopwords
Additionally, stemming is carried out for reducing the term to the root form. Furthermore, the procedure of minimizing the term assists in reducing the complication of the text feature. Next, the TextBlob method is utilized for determining the sentimental scores. Then, the BERT method is performed for generating a set of feature vectors. The BERT method is employed for useful feature extraction from the pre-processed information in this study.
3.2. BERT Model
The BERT model is used to derive word vectors once the twitter data is pre-processed. On the standard NLP tasks, the words in text data are commonly demonstrated as discrete values such as One-Hot encoded. The One-Hot encoded model integrates every word from the lexicon [
22]. The dimensional of the vector was equivalent to the number of words from the lexicon. A major benefit of One-Hot encoded is that it can be easy. However, the One-Hot vector of all the words is independent and could not reflect the connection among words. Furthermore, if the number of words from the lexicon was huge, the dimensional of word vectors (WVs) are very big, and a dimension disaster is taking place.
For solving the issue of One-Hot coded, the researcher presented the encoded of WVs. The basic concept is for representing words as lower-dimension continuous dense vectors, and words with the same meanings are mapped for identical places from the vector space. Generally utilized WV execution methods were BERT, Glove, Word2Vec, and ELMo.
Google introduced a BERT method which is a novel pre-trained language method utilizing the domain of NLP. It can be a process that truly executes a bi-directional language and is more optimum efficient than other WV methods.
This method can utilize the BERT system for training WVs. All the words
in
have been transformed to WV
utilizing a BERT method, whereas
is a 768-dimension vector. Afterwards, the WV is weighted utilizing sentiment weight.
The weighted WV matrix can be utilized as the resultant of the embedding layer.
3.3. Sentiment Analysis Using the BiRNN Model
The BiRNN model is utilized to identify and classify sentiments. RNN is a variant of neural networks (NN) that makes use of sequential datasets and maintains its features with the help of the middle layer [
23]. It is capable of processing sequence length by utilizing the memory and backpropagation mechanism. The variable length sentence vector is mapped to a static length sentence vector by filling or truncating the sequences. RNN presents a time (state)-based convolutional model that enables RNN to be considered as many convolution layers of a similar network at diverse time steps. All the neurons transmit the presently upgraded outcomes to the neuron at the following time step. Hence, the RNN layer can be utilized for extracting the temporal feature and long-term dependency from the text sequence.
In
the word embedding vector is placed into the step-by-step recurrent layers.
and
, word vectors that present the hidden layer of the preceding steps, are the input series of
time. The hidden layer of
time,
, refers to the output.
, and
denote the weighted matrixes. The RNN is established based on the input. As a result, we used the LSTM model to avoid the gradual disappearing gradient by controlling the flow of the data. Additionally, the long-term dependency could be captured very easily. LSTM is a complicated system from the recurrent layer that makes use of four distinct layers for controlling data communication. LSTM designs a ‘gate’ storage unit to increase or remove data. Firstly, the ‘forget gate’ defines that data must be excluded from the cell.
Next, enter
as the ‘input gate’ to define the data to be upgraded, and generate a novel candidate value vector
via the
layers.
While the
older cell state is multiplied by
, useless data is excluded, and add the product of
and
. The novel candidate value is computed for updating the older cell state.
At last, the output value is defined as
cell state. Firstly, the sigmoid gate is utilized for determining that part of the cell state as outcome, and the cell state has been handled by the
gate as well as multiplied with the outcome of sigmoid gates. Lastly, the output part was defined.
The weight matrix can be represented by the term
;
signifies the bias;
characterize the weight value of the forget, input, and output of LSTM;
and
characterize the hyperbolic tangent and sigmoid functions;
and
represent the hidden layer and memory representations of LSTM at
time. The quantity of data attained by the hidden layer was imbalanced in the distinct time steps of the recurrent layer. The previously hidden layer attains the lesser vector computation, whereby the last hidden layer achieves further vector computation. The presented method is further expanded to mitigate the problem of data imbalance through the bi-directional recurrent layer, and it comprises two opposite recurrent layers that returned two hidden layer sequences in the backward and forward directions:
Consequently, the document is denoted by
3.4. Hyperparameter Tuning
Like other metaheuristics (MH) methods, the MPO [
24] begins with the assignment of random value to several solutions based on the searching space, and it can be expressed by the following equation:
Let
and
be the lower and upper boundaries in the solution;
represents the arbitrary integer. Considers the predator and prey as searching agents while once the predator finds the prey, they search for the food. Hence, the elite (matrixes of a top predator) would be upgraded after every generation. The equation of prey (
X) and elite is represented by
The following step is to upgrade the location of prey which is implemented by three phases according to the ratio of velocity concurrently emulating the whole relationship between predator and prey. In the subsequent sections, every phase is deliberated in detail.
During this phase, the predator moves very fast compared to
in the exploration stage, in addition to it taking place in the first third of the overall amount of generations
. Consequently, the prey
is upgraded by the subsequent formula.
From the equation, and represent a vector of uniform arbitrary number and a constant value; correspondingly, characterizes a random vector that applies to Brownian motion. specifies the procedure of component-wise multiplication.
During this phase, prey and predator move in the same region, and then the movement mimics the procedure of finding the food or prey. Moreover, this represents the procedure of shifting the position of MPO from exploration to exploitation [
25]. Both have equal opportunities to take place in this phase. Next, the predator implements exploration, whereas the prey can carry out exploitation. It is considered that Brownian motion and Lévy flight represents the predator and prey movements, correspondingly, and it is expressed as if
:
From the expression,
denotes a random number after a Lévy distribution. The abovementioned equations are employed for an initial half of the population, which signifies the exploitations:
Given that represents the variable that controls the step size of motion to predator, and denotes the overall amount of generations.
This phase was the final procedure in an optimization technique that takes place if the predator’s motion is very fast compared to the prey. This indicates the exploitation stage if
, and this is expressed by
There exists an issue with the atmosphere which affects the performance of marine predators, namely fish aggregating devices (FAD), and it can be expressed as follows:
In Equation (21), , and refers to a binary solution; then, it is carried out by randomly producing a solution, later converting them to a dual solution with the thresholding value of 0.2. indicates an arbitrary number. and represent the prey indices.
The marine predator contains a memory that remembers the best place that has been attained. Generally, compare the fitness value of all the solutions with a preceding fitness value, and the optimal one can be stored in the memory.
The MPO technique is derived from FF for reaching superior classifier performance. It fixes a positive integer for denoting a superior outcome of the candidate solution. The reduction of classifier error rate was taken as FF, as follows.
4. Performance Validation
The proposed model is simulated using Python 3.6.5 tool on PC i5-8600k, GeForce 1050Ti 4GB, 16GB RAM, 250GB SSD, and 1TB HDD. The parameter settings are given as follows: learning rate: 0.01; dropout: 0.5; batch size: 5; epoch count: 50; and activation: ReLU. The experimental validation of the MPONLP-TSA method is tested under the COVID-19 tweets dataset from the Kaggle repository [
26]. For ease of simulation process, a set of 2750 samples are chosen from the dataset with 11 class labels as depicted in
Table 1.
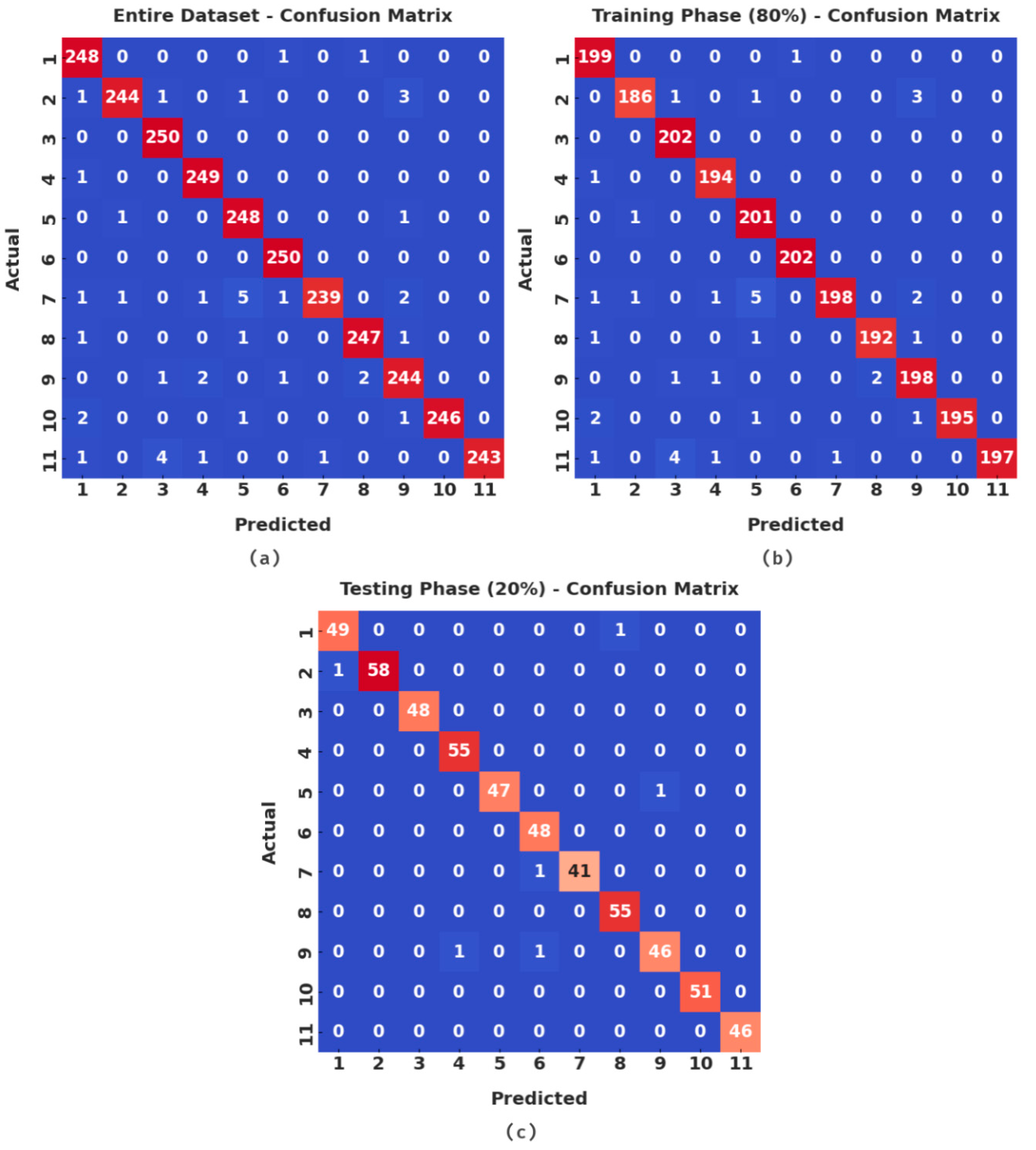
Figure 2 demonstrates the brief set of confusion matrices formed by the MPONLP-TSA technique under entire, 70% of training (TR), and 30% of testing (TS) data. The figures show that the MPONLP-TSA method has accomplished effectual classification results under all datasets.
Table 2 shows a detailed result analysis of the MPONLP-TSA methodology on distinct datasets. The experimental value shows that the MPONLP-TSA approach has outperformed effective outcomes in all aspects. For example, in the entire dataset, the MPONLP-TSA process has gained an average
value of 99.72%. Eventually, in 80% of TR data, the MPONLP-TSA methodology has attained an average
value of 99.70%. Meanwhile, in 20% of TS data, the MPONLP-TSA technique has reached an average
value of 99.80%.
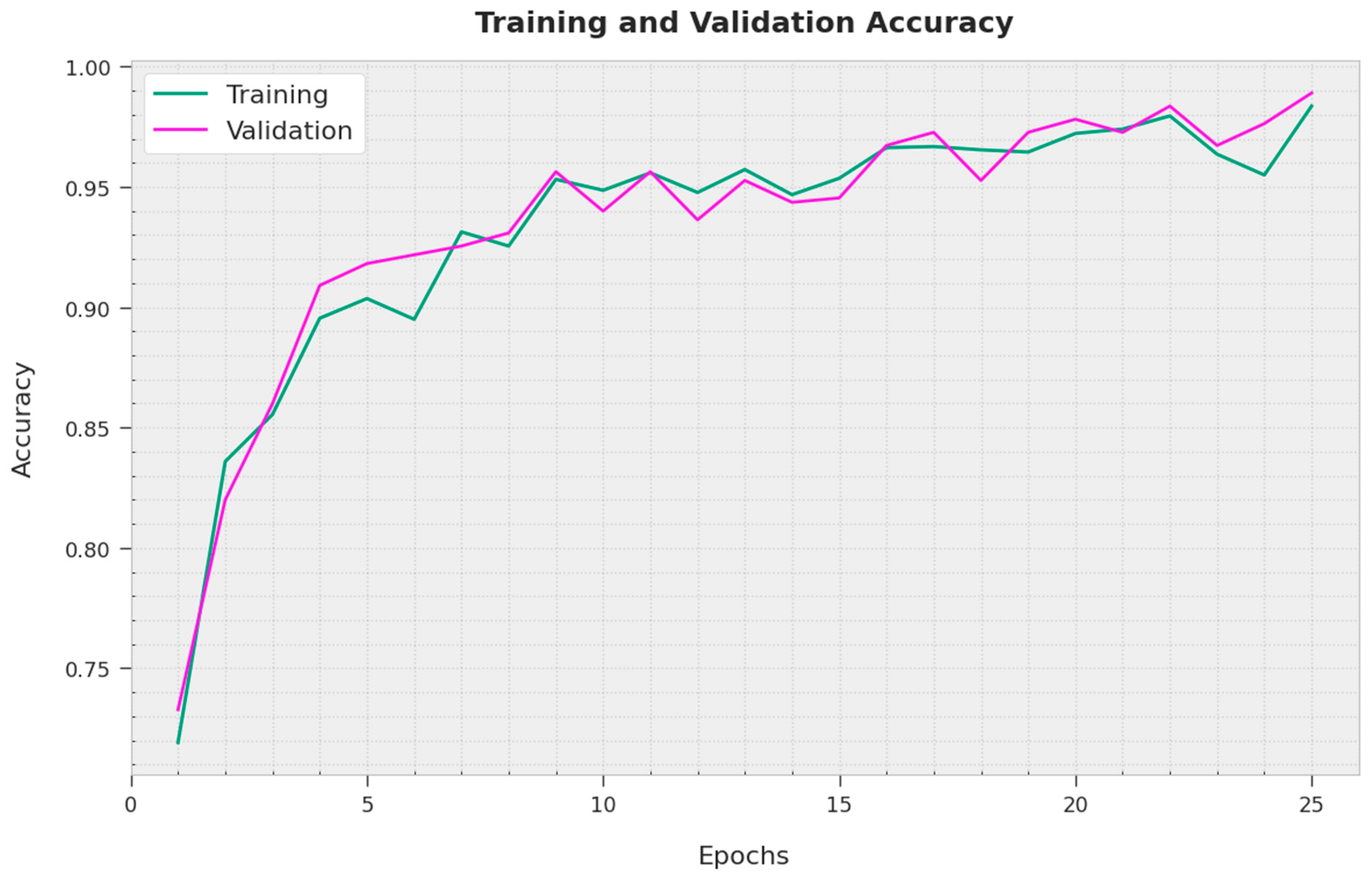
The training accuracy (TA) and validation accuracy (VA) attained using the MPONLP-TSA method on the test dataset are demonstrated in
Figure 3. The outcomes showed the MPONLP-TSA methodology has attained maximum values of TA and VA. In particular, the VA is greater than TA.
The training loss (TL) and validation loss (VL) acquired using the MPONLP-TSA technique on the test dataset are displayed in
Figure 4. The outcomes denoted the MPONLP-TSA technique has accomplished the least values of TL and VL. To be specific, the VL is lower than TL.
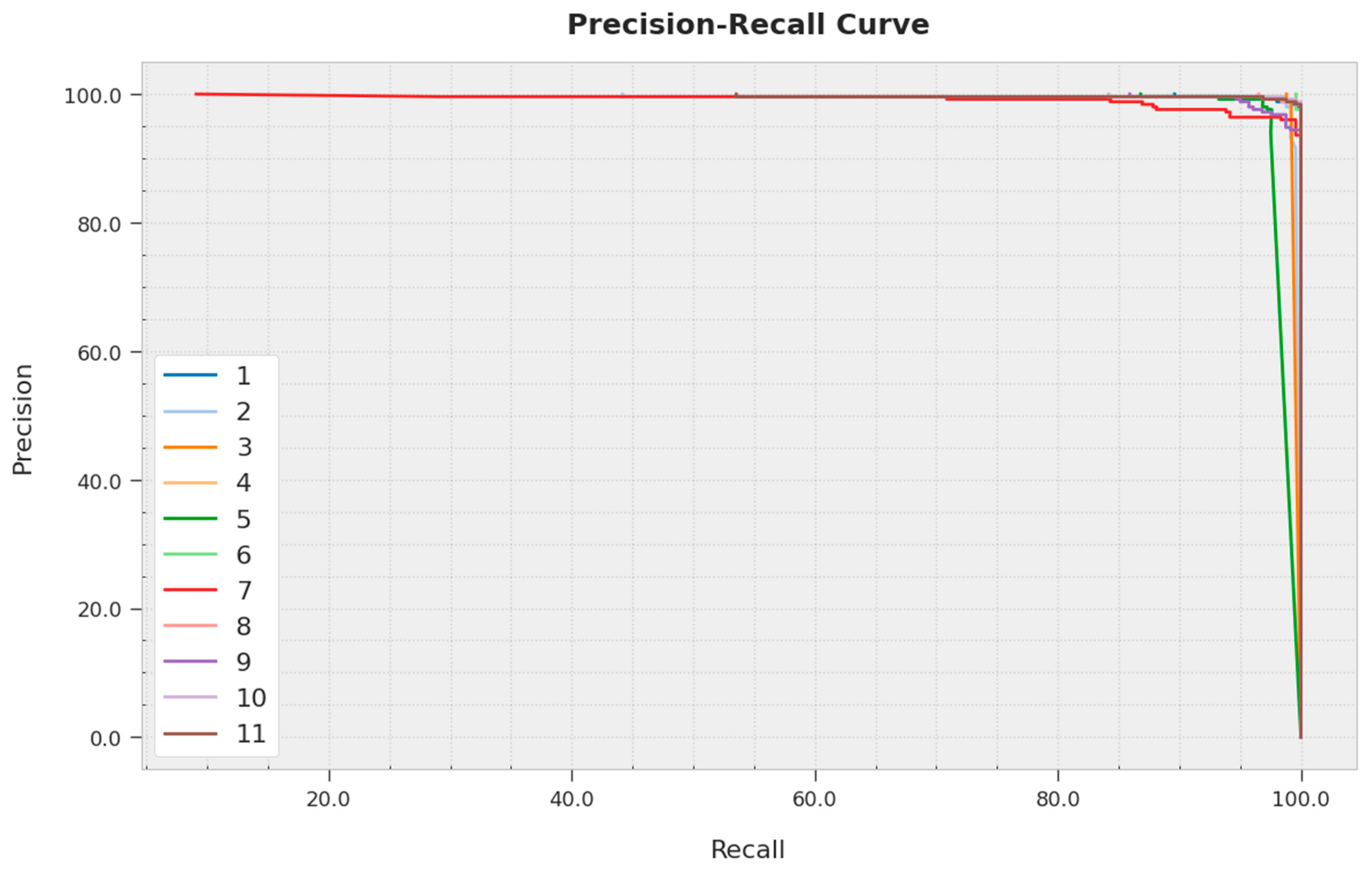
A clear precision–recall analysis of the MPONLP-TSA algorithm on the test dataset is depicted in
Figure 5. The figure represented the MPONLP-TSA methodology has resulted in enhanced values of precision–recall values under all classes.
A detailed ROC analysis of the MPONLP-TSA system on the test dataset is represented in
Figure 6. The outcome indicated that the MPONLP-TSA method has shown its ability in classifying dissimilar classes on the test dataset.
Table 3 reports a comparative study of the MPONLP-TSA method with recent techniques [
19]. The results implied that the SVM and DT techniques have shown lower
values of 90.78% and 90.66%, correspondingly.
Meanwhile, the RF, extreme gradient boosting (XGboost), and ensemble methods have reported moderately closer of 91.04%, 91.22%, and 93.03%, correspondingly. Moreover, the sunflower optimization with deep-learning-driven sentiment analysis and classification (SFODLD-SAC) model has obtained a reasonable of 99.50%. However, the MPONLP-TSA model has shown enhanced results with a higher of 99.80%.
In order to further validate the performance of the MPONLP-TSA model, another dataset of COVID-19 tweets from Kaggle repository is used (
https://www.kaggle.com/gpreda/covid19-tweets, accessed on 11 December 2022). The dataset has 170k tweets with 3 class labels, namely positive, neutral, and negative. The comparison results of the MPONLP-TSA model with other models [
27] on the COVID-19 tweets dataset are reported in
Table 4. The experimental results indicate that the RF and SVM models reached poor performance. Although the hybrid LSTM-RNN model reaches somewhat improved results, the proposed model outperformed the other existing models with a maximum
of 97.59%,
of 97.79%,
of 98.64%, and
of 97.45%. From the detailed discussion and results, it is assumed that the MPONLP-TSA model has gained maximal classification result over other techniques.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}