


Soil Erosion Status Prediction Using a Novel Random Forest Model Optimized by Random Search Method
 ,
,  , , , and
, , , and 
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
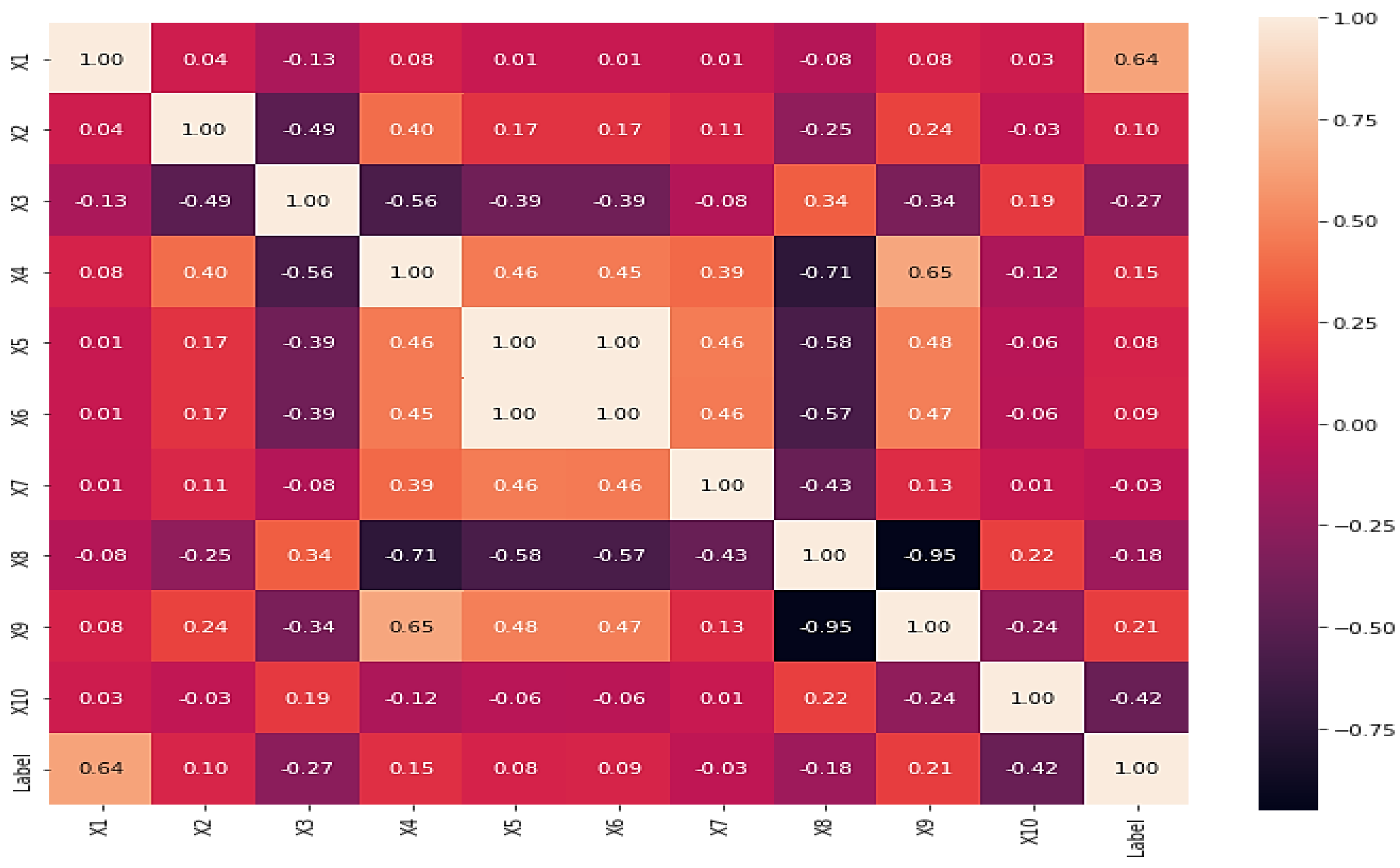
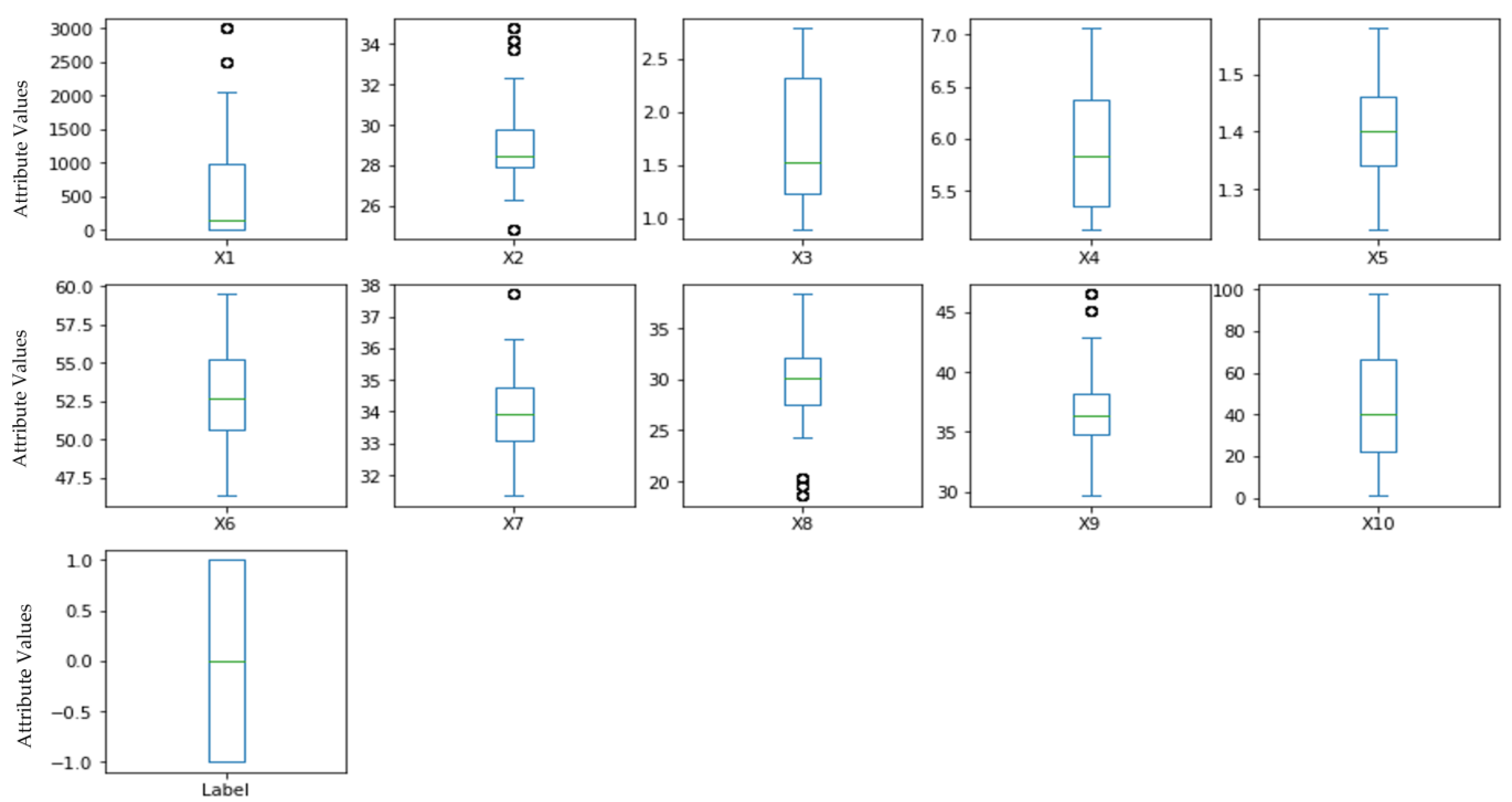
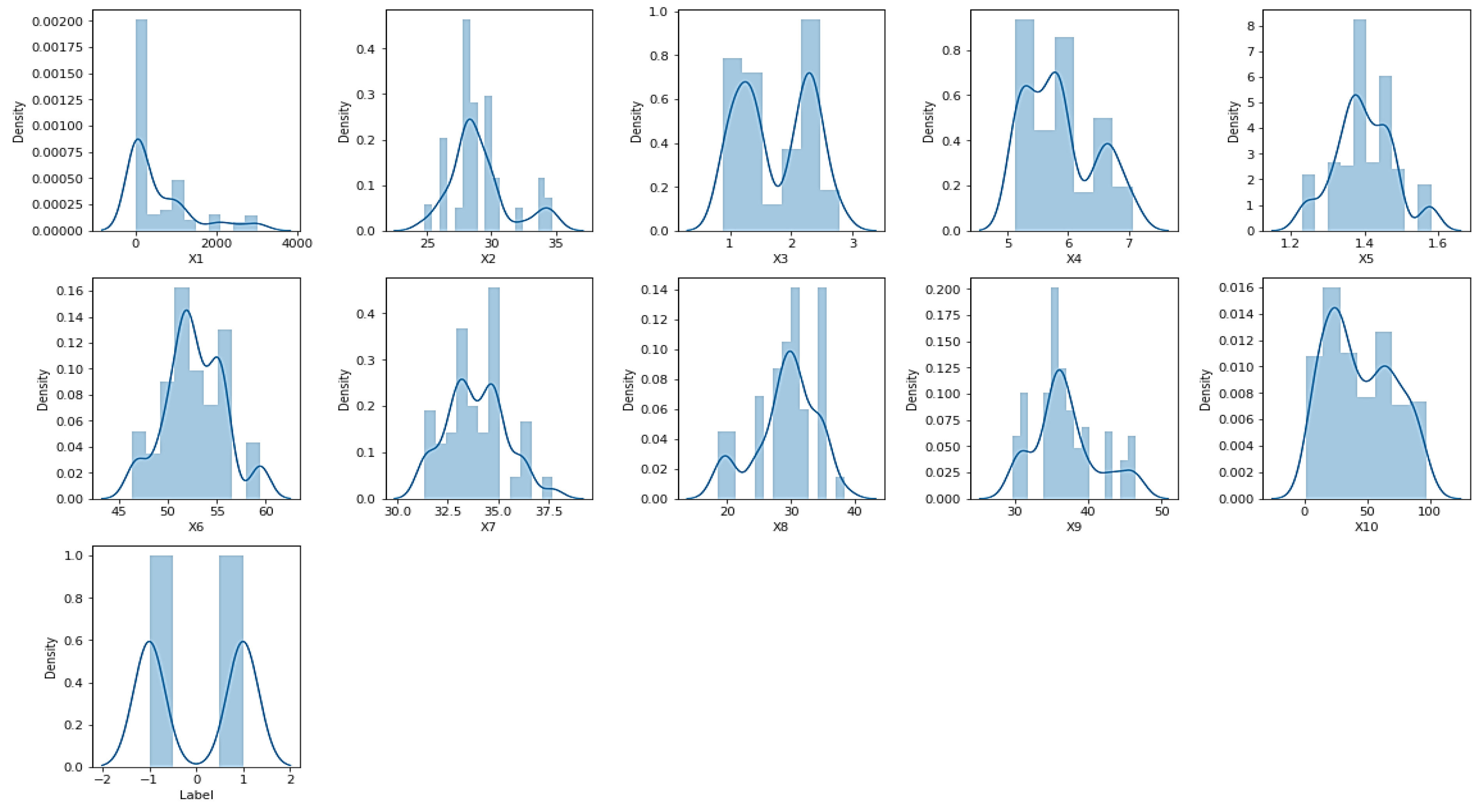
3.1. Dataset Description
3.2. Machine Learning Models
3.2.1. Random Forest (RF) Model
| Algorithm 1 Pseudocode of RF Algorithm |
| To construct Ti, randomly sample the training data T using replacement. Generate a root node Ni, that contains containing Ti If N >1, Pick x% at random from the potential dividing features in N. Determine the information gain using Equation (1). Choose the feature F that has the most information gain value. Generate f child nodes of N, N1,…,Nf, where F has f potential values (F1,….,Ff) For i from 1 to f do Put the contents of Ni to Ti, as Ti contains all instances that match Fi in N Repeat steps 3 through 9 for N times to create a forest of N trees. End for End if |
3.2.2. Naïve Bayes (NB) Model
| Algorithm 2 Pseudocode of NB Model |
| Input: Training sample set N Output: A class of testing dataset.
|
3.2.3. Logistic Regression (LR) Model
3.2.4. K-Nearest Neighbor (KNN) Model
3.2.5. Support Vector Machine (SVM) Model
| Algorithm 3 Pseudocode of the SVM Model |
|
3.2.6. Linear Discriminant Analysis (LDA) Model
3.2.7. Stochastic Gradient Descent (SGD) Model
| Algorithm 4 Pseudo-code for Stochastic Gradient Descent (SGD) |
 |
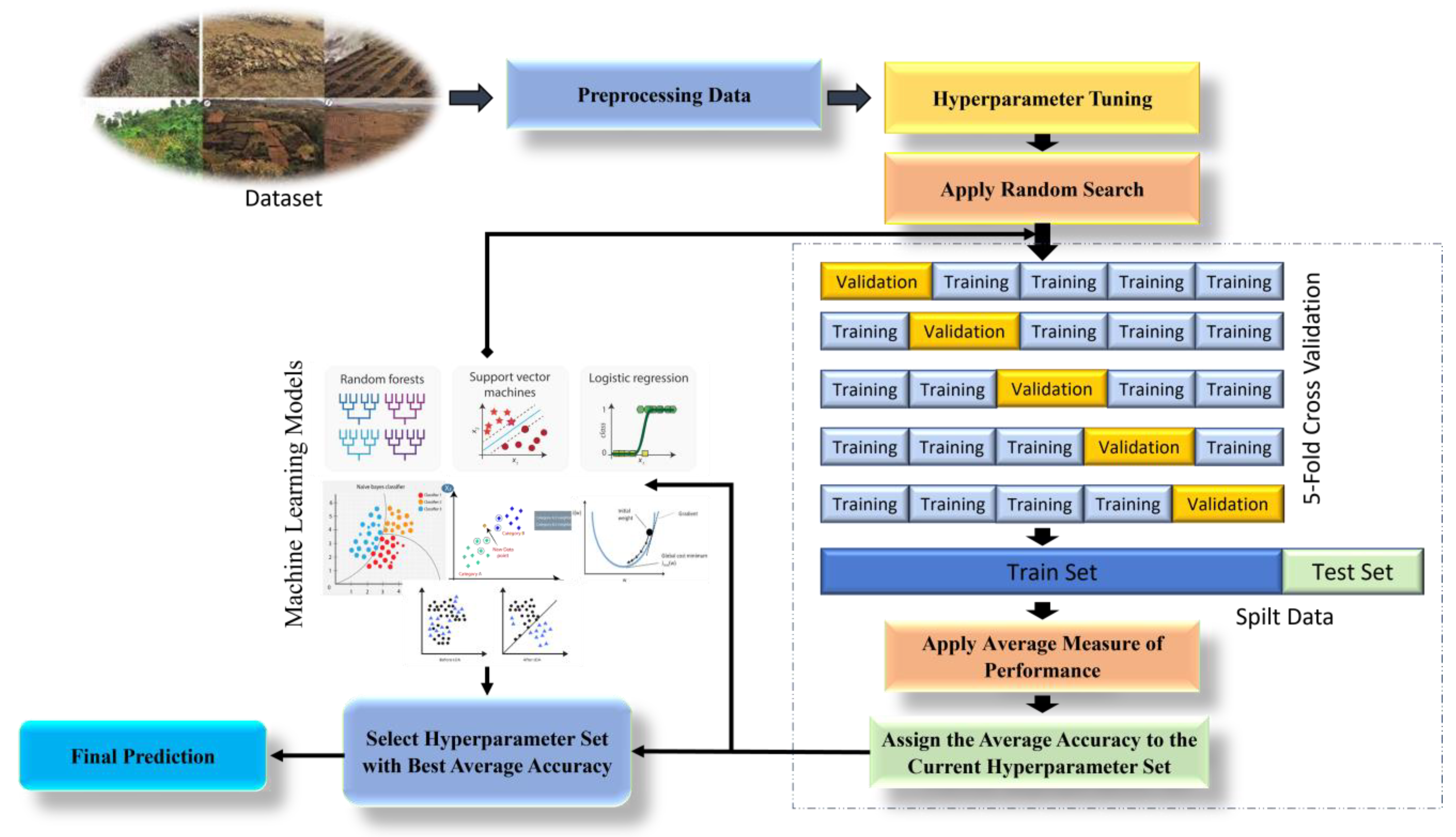
3.3. The Proposed RS-RF for Soil Erosion Status Prediction
3.3.1. Data Normalization
3.3.2. Random Search (RS)
3.3.3. Proposed Methodology
| Algorithm 5 Pseudocode of the proposed Random Search-Random Forest (RS-RF) |
|
3.4. Evaluation Metrics
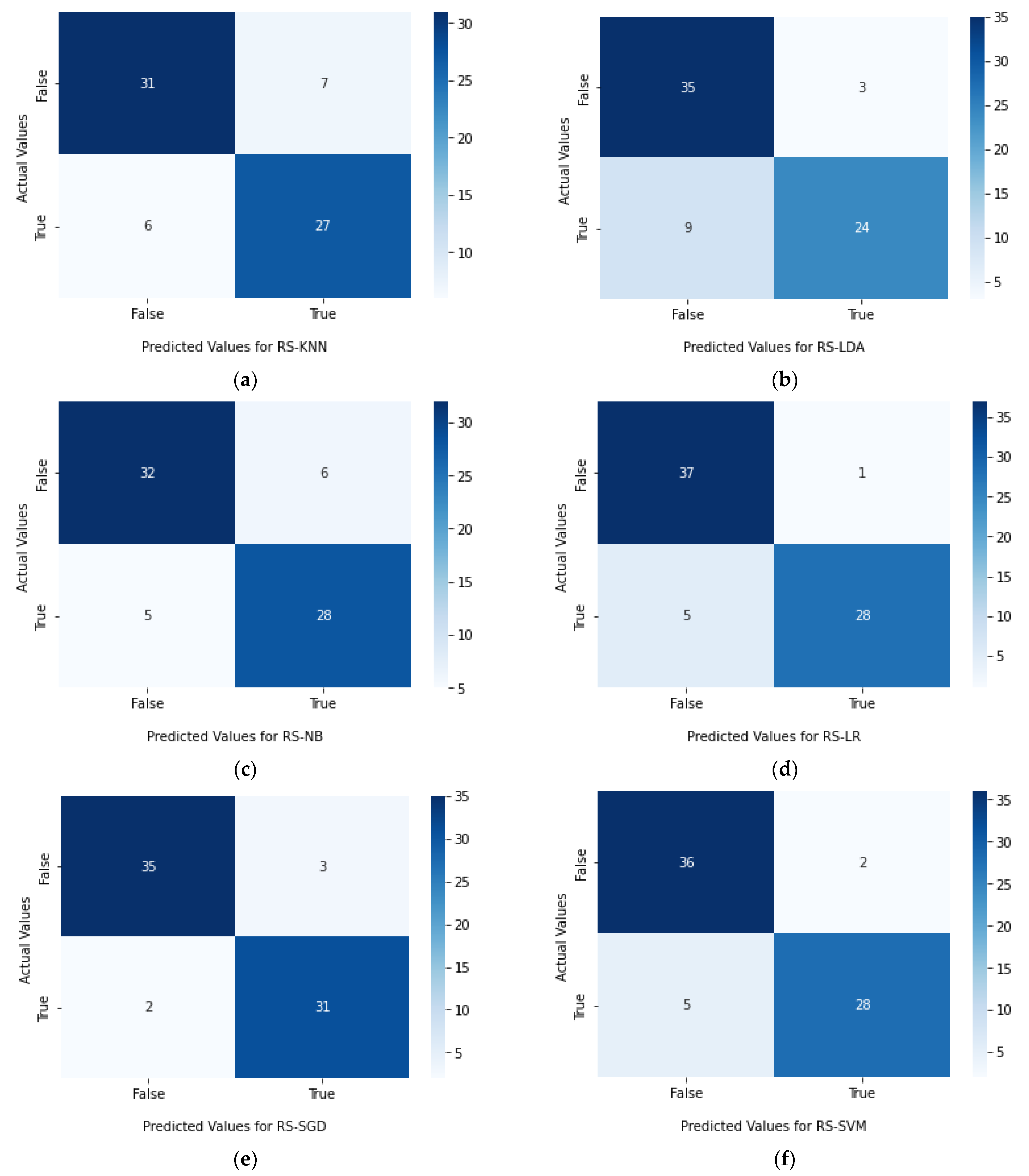
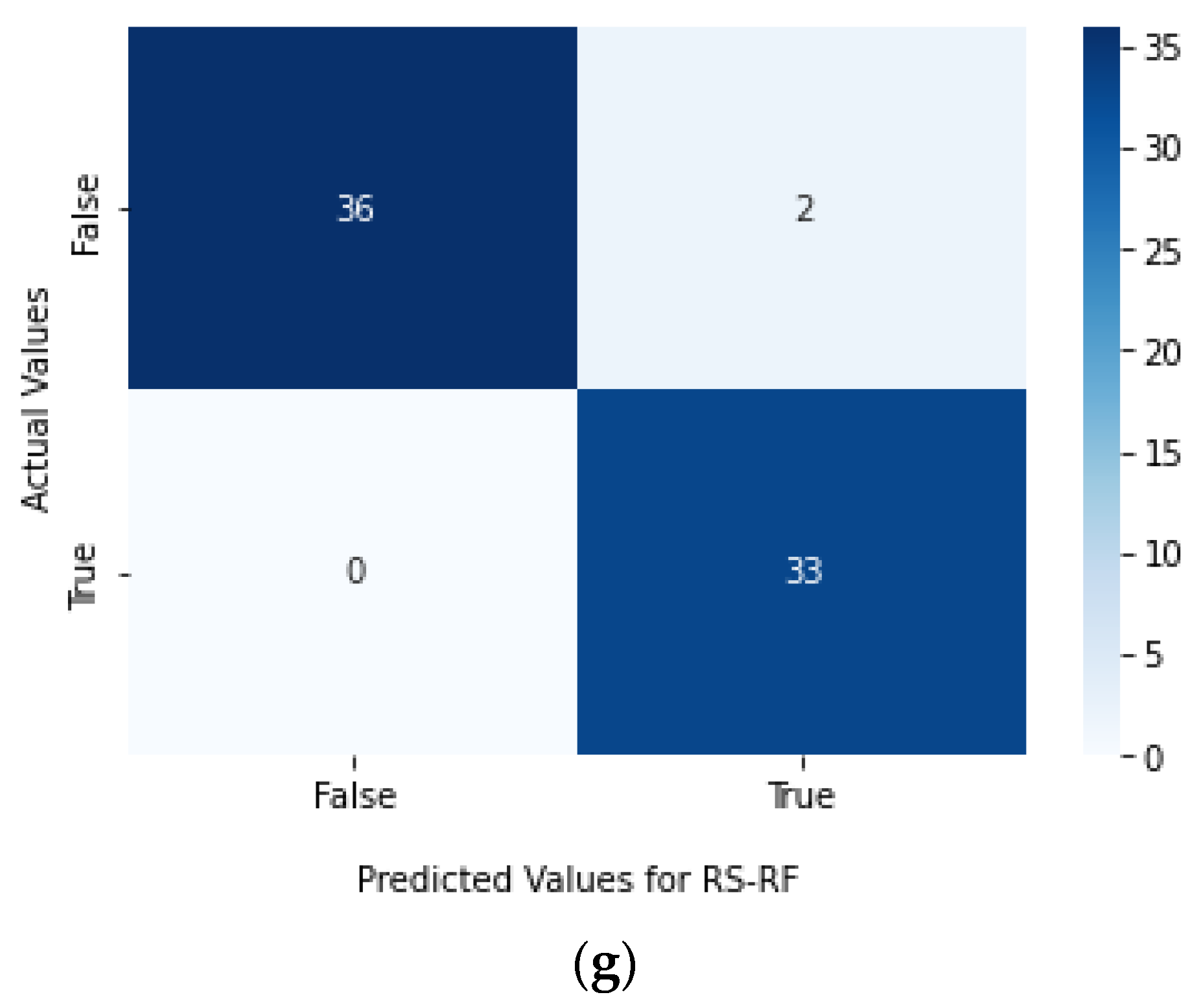
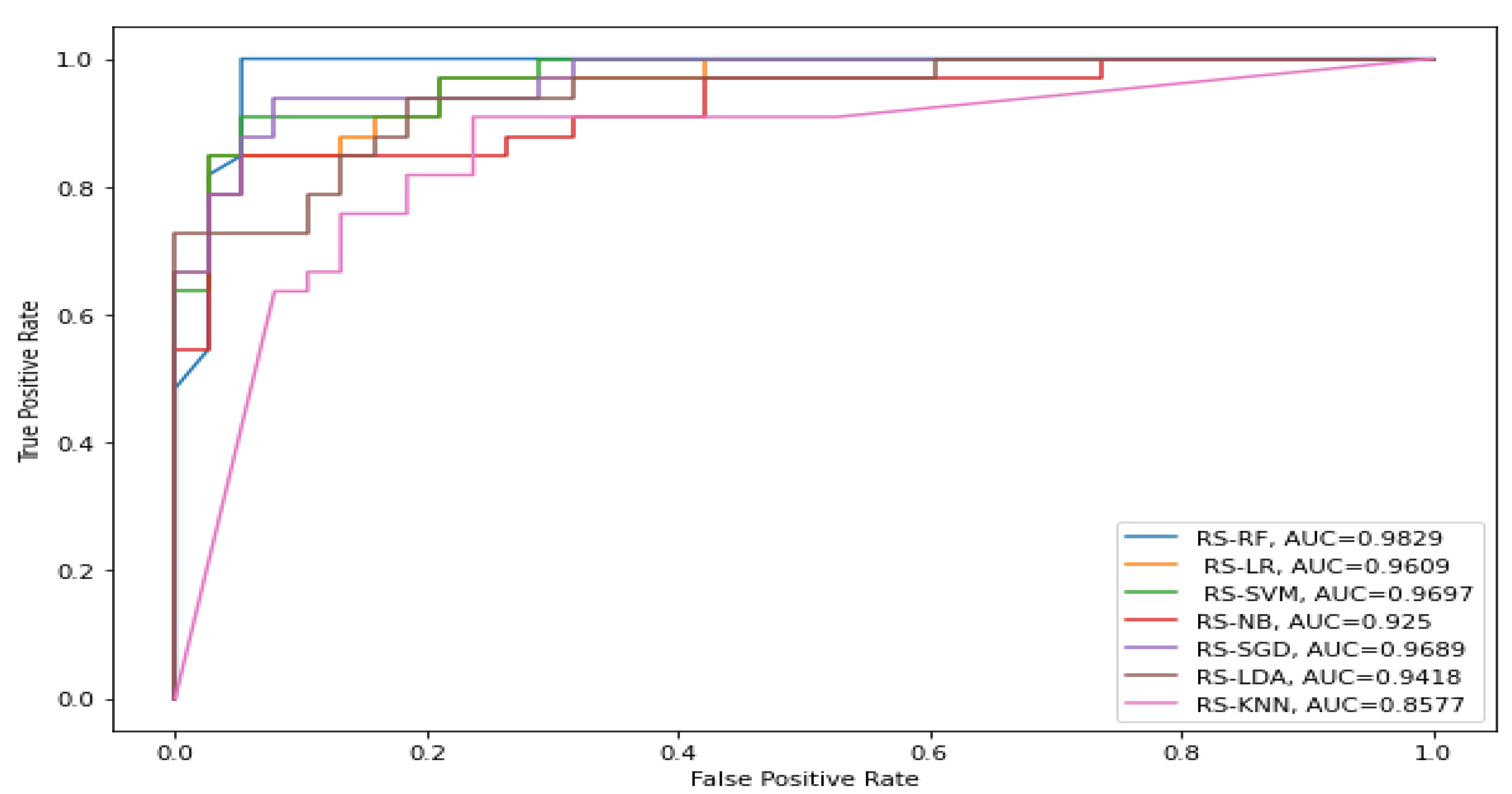
4. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nearing, M.A.; Lane, L.J.; Lopes, V.L. Modeling Soil Erosion. In Soil Erosion Research Methods; Routledge: Oxford, UK, 2017; pp. 127–158. ISBN 0-203-73935-3. [Google Scholar]
- Batista, P.V.; Davies, J.; Silva, M.L.; Quinton, J.N. On the Evaluation of Soil Erosion Models: Are We Doing Enough? Earth-Sci. Rev. 2019, 197, 102898. [Google Scholar] [CrossRef]
- Wang, J.; Zhen, J.; Hu, W.; Chen, S.; Lizaga, I.; Zeraatpisheh, M.; Yang, X. Remote Sensing of Soil Degradation: Progress and Perspective. Int. Soil Water Conserv. Res. 2023; in press. [Google Scholar] [CrossRef]
- AbdelRahman, M.A. An Overview of Land Degradation, Desertification and Sustainable Land Management Using GIS and Remote Sensing Applications. Rend. Lincei. Sci. Fis. Nat. 2023, 1–42. [Google Scholar] [CrossRef]
- Kryuchkov, S.N.; Solonkin, A.V.; Solomentseva, A.S.; Zholobova, O.O. Elements of the Technology of Reproduction of Robinia Pseudoacacia L. for Protective Afforestation under Conditions of Land Degradation and Desertification. Arid Ecosyst. 2023, 13, 83–91. [Google Scholar] [CrossRef]
- Osman, K.T. Soil Degradation, Conservation and Remediation; Springer: Dordrecht, The Netherlands, 2014; Volume 820. [Google Scholar]
- Nosair, A.M.; Shams, M.Y.; AbouElmagd, L.M.; Hassanein, A.E.; Fryar, A.E.; Abu Salem, H.S. Predictive Model for Progressive Salinization in a Coastal Aquifer Using Artificial Intelligence and Hydrogeochemical Techniques: A Case Study of the Nile Delta Aquifer, Egypt. Environ. Sci. Pollut. Res. 2022, 29, 9318–9340. [Google Scholar] [CrossRef]
- Mills, S.C.; Socolar, J.B.; Edwards, F.A.; Parra, E.; Martínez-Revelo, D.E.; Ochoa Quintero, J.M.; Haugaasen, T.; Freckleton, R.P.; Barlow, J.; Edwards, D.P. High Sensitivity of Tropical Forest Birds to Deforestation at Lower Altitudes. Ecology 2023, 104, e3867. [Google Scholar] [CrossRef]
- Tang, H.; Shi, P.; Fu, X. An Analysis of Soil Erosion on Construction Sites in Megacities Using Analytic Hierarchy Process. Sustainability 2023, 15, 1325. [Google Scholar] [CrossRef]
- Mkhize, X.; Mthembu, B.E.; Napier, C. Transforming a Local Food System to Address Food and Nutrition Insecurity in an Urban Informal Settlement Area: A Study in Umlazi Township in Durban, South Africa. J. Agric. Food Res. 2023, 12, 100565. [Google Scholar] [CrossRef]
- Pimentel, D. Soil Erosion: A Food and Environmental Threat. Environ. Dev. Sustain. 2006, 8, 119–137. [Google Scholar] [CrossRef]
- Montgomery, D.R. Soil Erosion and Agricultural Sustainability. Proc. Natl. Acad. Sci. USA 2007, 104, 13268–13272. [Google Scholar] [CrossRef]
- Chalise, D.; Kumar, L.; Kristiansen, P. Land Degradation by Soil Erosion in Nepal: A Review. Soil Syst. 2019, 3, 12. [Google Scholar] [CrossRef]
- Toy, T.J.; Foster, G.R.; Renard, K.G. Soil Erosion: Processes, Prediction, Measurement, and Control; John Wiley & Sons: Hoboken, NJ, USA, 2002; ISBN 0-471-38369-4. [Google Scholar]
- Lal, R.; Moldenhauer, W.C. Effects of Soil Erosion on Crop Productivity. Crit. Rev. Plant Sci. 1987, 5, 303–367. [Google Scholar] [CrossRef]
- Pimentel, D.; Burgess, M. Soil Erosion Threatens Food Production. Agriculture 2013, 3, 443–463. [Google Scholar] [CrossRef]
- Momeni, E.; Armaghani, D.J.; Hajihassani, M.; Amin, M.F.M. Prediction of Uniaxial Compressive Strength of Rock Samples Using Hybrid Particle Swarm Optimization-Based Artificial Neural Networks. Measurement 2015, 60, 50–63. [Google Scholar] [CrossRef]
- Shahin, M.A. State-of-the-Art Review of Some Artificial Intelligence Applications in Pile Foundations. Geosci. Front. 2016, 7, 33–44. [Google Scholar] [CrossRef]
- Bunawan, A.R.; Momeni, E.; Armaghani, D.J.; Rashid, A.S.A. Experimental and Intelligent Techniques to Estimate Bearing Capacity of Cohesive Soft Soils Reinforced with Soil-Cement Columns. Measurement 2018, 124, 529–538. [Google Scholar] [CrossRef]
- Mohanty, R.; Suman, S.; Das, S.K. Prediction of Vertical Pile Capacity of Driven Pile in Cohesionless Soil Using Artificial Intelligence Techniques. Int. J. Geotech. Eng. 2018, 12, 209–216. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Pham, B.T.; Bin Ahmad, B.; Tien Bui, D. A Novel Hybrid Approach of Bayesian Logistic Regression and Its Ensembles for Landslide Susceptibility Assessment. Geocarto Int. 2019, 34, 1427–1457. [Google Scholar] [CrossRef]
- Chan, H.; Chang, C.C.; Chen, P.; Lee, J.T. Using Multinomial Logistic Regression for Prediction of Soil Depth in an Area of Complex Topography in Taiwan. Catena 2019, 176, 419–429. [Google Scholar] [CrossRef]
- Moayedi, H.; Gör, M.; Khari, M.; Foong, L.K.; Bahiraei, M.; Bui, D.T. Hybridizing Four Wise Neural-Metaheuristic Paradigms in Predicting Soil Shear Strength. Measurement 2020, 156, 107576. [Google Scholar] [CrossRef]
- Azizi, A.; Gilandeh, Y.A.; Mesri-Gundoshmian, T.; Saleh-Bigdeli, A.A.; Moghaddam, H.A. Classification of Soil Aggregates: A Novel Approach Based on Deep Learning. Soil Tillage Res. 2020, 199, 104586. [Google Scholar] [CrossRef]
- Licznar, P.; Nearing, M.A. Artificial Neural Networks of Soil Erosion and Runoff Prediction at the Plot Scale. Catena 2003, 51, 89–114. [Google Scholar] [CrossRef]
- Kim, M.; Gilley, J.E. Artificial Neural Network Estimation of Soil Erosion and Nutrient Concentrations in Runoff from Land Application Areas. Comput. Electron. Agric. 2008, 64, 268–275. [Google Scholar] [CrossRef]
- Albaradeyia, I.; Hani, A.; Shahrour, I. WEPP and ANN Models for Simulating Soil Loss and Runoff in a Semi-Arid Mediterranean Region. Environ. Monit. Assess. 2011, 180, 537–556. [Google Scholar] [CrossRef] [PubMed]
- Yusof, M.F.; Azamathulla, H.M.; Abdullah, R. Prediction of Soil Erodibility Factor for Peninsular Malaysia Soil Series Using ANN. Neural Comput. Appl. 2014, 24, 383–389. [Google Scholar] [CrossRef]
- de Farias, C.A.S.; Santos, C.A.G. The Use of Kohonen Neural Networks for Runoff–Erosion Modeling. J. Soils Sediments 2014, 14, 1242–1250. [Google Scholar] [CrossRef]
- Rizeei, H.M.; Saharkhiz, M.A.; Pradhan, B.; Ahmad, N. Soil Erosion Prediction Based on Land Cover Dynamics at the Semenyih Watershed in Malaysia Using LTM and USLE Models. Geocarto Int. 2016, 31, 1158–1177. [Google Scholar] [CrossRef]
- Arif, N.; Danoedoro, P. Hartono Analysis of Artificial Neural Network in Erosion Modeling: A Case Study of Serang Watershed. IOP Conf. Ser. Earth Environ. Sci. 2017, 98, 012027. [Google Scholar] [CrossRef]
- Ojha, V.K.; Abraham, A.; Snášel, V. Metaheuristic Design of Feedforward Neural Networks: A Review of Two Decades of Research. Eng. Appl. Artif. Intell. 2017, 60, 97–116. [Google Scholar] [CrossRef]
- Sadowski, Ł.; Nikoo, M.; Nikoo, M. Hybrid Metaheuristic-Neural Assessment of the Adhesion in Existing Cement Composites. Coatings 2017, 7, 49. [Google Scholar] [CrossRef]
- Ngo, P.-T.T.; Hoang, N.-D.; Pradhan, B.; Nguyen, Q.K.; Tran, X.T.; Nguyen, Q.M.; Nguyen, V.N.; Samui, P.; Tien Bui, D. A Novel Hybrid Swarm Optimized Multilayer Neural Network for Spatial Prediction of Flash Floods in Tropical Areas Using Sentinel-1 SAR Imagery and Geospatial Data. Sensors 2018, 18, 3704. [Google Scholar] [CrossRef] [PubMed]
- Sadowski, Ł.; Nikoo, M.; Shariq, M.; Joker, E.; Czarnecki, S. The Nature-Inspired Metaheuristic Method for Predicting the Creep Strain of Green Concrete Containing Ground Granulated Blast Furnace Slag. Materials 2019, 12, 293. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.-Y.; Guh, R.-S.; Shiue, Y.-R. Effective Recognition of Control Chart Patterns in Autocorrelated Data Using a Support Vector Machine Based Approach. Comput. Ind. Eng. 2011, 61, 1123–1134. [Google Scholar] [CrossRef]
- Vu, D.T.; Tran, X.-L.; Cao, M.-T.; Tran, T.C.; Hoang, N.-D. Machine Learning Based Soil Erosion Susceptibility Prediction Using Social Spider Algorithm Optimized Multivariate Adaptive Regression Spline. Measurement 2020, 164, 108066. [Google Scholar] [CrossRef]
- Alhakami, H.; Kamal, M.; Sulaiman, M.; Alhakami, W.; Baz, A. A Machine Learning Strategy for the Quantitative Analysis of the Global Warming Impact on Marine Ecosystems. Symmetry 2022, 14, 2023. [Google Scholar] [CrossRef]
- Alrayes, F.S.; Maray, M.; Gaddah, A.; Yafoz, A.; Alsini, R.; Alghushairy, O.; Mohsen, H.; Motwakel, A. Modeling of Botnet Detection Using Barnacles Mating Optimizer with Machine Learning Model for Internet of Things Environment. Electronics 2022, 11, 3411. [Google Scholar] [CrossRef]
- Mengash, H.; Alzahrani, J.; Eltahir, M.; Al-Wesabi, F.; Mohamed, A.; Hamza, M.; Marzouk, R. Search and Rescue Optimization with Machine Learning Enabled Cybersecurity Model. Comput. Syst. Sci. Eng. 2022, 45, 1393–1407. [Google Scholar] [CrossRef]
- Rathore, F.A.; Khan, H.S.; Ali, H.M.; Obayya, M.; Rasheed, S.; Hussain, L.; Kazmi, Z.H.; Nour, M.K.; Mohamed, A.; Motwakel, A. Survival Prediction of Glioma Patients from Integrated Radiology and Pathology Images Using Machine Learning Ensemble Regression Methods. Appl. Sci. 2022, 12, 10357. [Google Scholar] [CrossRef]
- Mujeeb, S.; Alghamdi, T.A.; Ullah, S.; Fatima, A.; Javaid, N.; Saba, T. Exploiting Deep Learning for Wind Power Forecasting Based on Big Data Analytics. Appl. Sci. 2019, 9, 4417. [Google Scholar] [CrossRef]
- Elshewey, A.M.; Shams, M.Y.; Elhady, A.M.; Shohieb, S.M.; Abdelhamid, A.A.; Ibrahim, A.; Tarek, Z. A Novel WD-SARIMAX Model for Temperature Forecasting Using Daily Delhi Climate Dataset. Sustainability 2023, 15, 757. [Google Scholar] [CrossRef]
- Hassan, N.Y.; Gomaa, W.H.; Khoriba, G.A.; Haggag, M.H. Supervised Learning Approach for Twitter Credibility Detection. In Proceedings of the 2018 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018; pp. 196–201. [Google Scholar]
- Shams, M.Y.; Tarek, Z.; Elshewey, A.M.; Hany, M.; Darwish, A.; Hassanien, A.E. A Machine Learning-Based Model for Predicting Temperature Under the Effects of Climate Change. In The Power of Data: Driving Climate Change with Data Science and Artificial Intelligence Innovations; Hassanien, A.E., Darwish, A., Eds.; Studies in Big Data; Springer Nature Switzerland: Cham, Switzerland, 2023; pp. 61–81. ISBN 978-3-031-22456-0. [Google Scholar]
- Lv, Y.; Le, Q.-T.; Bui, H.-B.; Bui, X.-N.; Nguyen, H.; Nguyen-Thoi, T.; Dou, J.; Song, X. A Comparative Study of Different Machine Learning Algorithms in Predicting the Content of Ilmenite in Titanium Placer. Appl. Sci. 2020, 10, 635. [Google Scholar] [CrossRef]
- Saputra, M.F.A.; Widiyaningtyas, T.; Wibawa, A.P. Illiteracy Classification Using K Means-Naïve Bayes Algorithm. JOIV Int. J. Inform. Vis. 2018, 2, 153–158. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, L. Comparison of Spatial and Non-Spatial Logistic Regression Models for Modeling the Occurrence of Cloud Cover in North-Eastern Puerto Rico. Appl. Geogr. 2013, 37, 52–62. [Google Scholar] [CrossRef]
- Boateng, E.Y.; Abaye, D.A. A Review of the Logistic Regression Model with Emphasis on Medical Research. J. Data Anal. Inf. Process. 2019, 7, 190–207. [Google Scholar] [CrossRef]
- Lin, G.; Lin, A.; Gu, D. Using Support Vector Regression and K-Nearest Neighbors for Short-Term Traffic Flow Prediction Based on Maximal Information Coefficient. Inf. Sci. 2022, 608, 517–531. [Google Scholar] [CrossRef]
- Pisner, D.A.; Schnyer, D.M. Support Vector Machine. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 101–121. [Google Scholar]
- Elshewey, A.M.; Shams, M.Y.; El-Rashidy, N.; Elhady, A.M.; Shohieb, S.M.; Tarek, Z. Bayesian Optimization with Support Vector Machine Model for Parkinson Disease Classification. Sensors 2023, 23, 2085. [Google Scholar] [CrossRef] [PubMed]
- Alloghani, M.; Aljaaf, A.; Hussain, A.; Baker, T.; Mustafina, J.; Al-Jumeily, D.; Khalaf, M. Implementation of Machine Learning Algorithms to Create Diabetic Patient Re-Admission Profiles. BMC Med. Inform. Decis. Mak. 2019, 19, 253. [Google Scholar] [CrossRef]
- Hoang, N.-D.; Nguyen, Q.-L.; Tran, X.-L. Automatic Detection of Concrete Spalling Using Piecewise Linear Stochastic Gradient Descent Logistic Regression and Image Texture Analysis. Complexity 2019, 2019, 5910625. [Google Scholar] [CrossRef]
- Anyanwu, G.O.; Nwakanma, C.I.; Lee, J.-M.; Kim, D.-S. Falsification Detection System for IoV Using Randomized Search Optimization Ensemble Algorithm. IEEE Trans. Intell. Transp. Syst. 2023, 24, 4158–4172. [Google Scholar] [CrossRef]
- Bettinger, P.; Graetz, D.; Boston, K.; Sessions, J.; Chung, W. Eight Heuristic Planning Techniques Applied to Three Increasingly Difficult Wildlife Planning Problems. Silva Fenn. 2002, 36, 561–584. [Google Scholar] [CrossRef]
- Sabanci, K.; Aslan, M.F.; Ropelewska, E.; Unlersen, M.F. A Convolutional Neural Network-based Comparative Study for Pepper Seed Classification: Analysis of Selected Deep Features with Support Vector Machine. J. Food Process Eng. 2022, 45, e13955. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Notation | Count | Mean | Std | Min | 50% | Max |
|---|---|---|---|---|---|---|---|
| EI30 | X1 | 236 | 573.64 | 814.70 | 0 | 144.72 | 3008.93 |
| Slope (degree) | X2 | 236 | 29.05 | 2.32 | 24.83 | 28.47 | 34.77 |
| Organic carbon top soil (%) | X3 | 236 | 1.75 | 0.58 | 0.89 | 1.53 | 2.79 |
| pH top soil | X4 | 236 | 5.87 | 0.58 | 5.13 | 5.83 | 7.06 |
| Bulk density (g/cm3) | X5 | 236 | 1.40 | 0.08 | 1.23 | 1.40 | 1.58 |
| Total pore volume (%) | X6 | 236 | 52.76 | 3.02 | 46.34 | 52.69 | 59.48 |
| Soil texture-silk (%) | X7 | 236 | 33.90 | 1.49 | 31.35 | 33.93 | 37.71 |
| Soil texture-clay (%) | X8 | 236 | 29.14 | 4.81 | 18.61 | 30.15 | 38.35 |
| Soil texture-sand (%) | X9 | 236 | 36.95 | 4.38 | 29.66 | 36.37 | 46.51 |
| Soil cover rate (%) | X10 | 236 | 44.28 | 26.74 | 1.05 | 40.42 | 97.64 |
| Label | Label | 236 | 0 | 1 | −1 | 0 | 1 |
| Models | Tuning Parameters | Best Parameters |
|---|---|---|
| RF | N_estimators = [50, 100, 150, 200, 250], criterion = [‘gini’, ‘entropy’]. | N_estimators = 150, criterion = gini. |
| KNN | N_neighbors = [5, 10, 15, 20, 25, 30], weights = [‘uniform’, ‘distance’]. | N_neighbors = 15, weights = distance. |
| LDA | N_components = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]. | N_components = 1. |
| NB | Alpha = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]. | Alpha = 0.6. |
| LR | Penalty = [l1′, ‘l2′, ‘elasticnet’], solver = [‘lbfgs’, ‘liblinear’, ‘saga’]. | Penalty = l2, solver = lbfgs. |
| SGD | Loss = [‘hinge’, ‘log_loss’, ‘log’], penalty = [l1′, ‘l2′, ‘elasticnet’]. | Loss = log, penalty = l1. |
| SVM | Kernel = [‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’], regularization parameter (C) = [0.1, 0.2, 0.3, 0.4]. | Kernel = rbf, C = 0.2. |
| Models | Accuracy | MCC | F1 Score | Recall | Precision | AUC |
|---|---|---|---|---|---|---|
| RS-KNN | 81.60% | 63.20% | 81.70% | 81.60% | 81.70% | 0.8577 |
| RS-LDA | 83.10% | 66.60% | 82.80% | 83.10% | 83.80% | 0.9418 |
| RS-NB | 84.50% | 68.90% | 84.50% | 84.50% | 84.60% | 0.925 |
| RS-LR | 91.50% | 83.40% | 91.40% | 91.50% | 92.00% | 0.9609 |
| RS-SGD | 92.90% | 85.90% | 92.90% | 92.90% | 93.00% | 0.9689 |
| RS-SVM | 90.10% | 80.30% | 90.10% | 90.10% | 90.30% | 0.9697 |
| RS-RF | 97.40% | 95.10% | 97.30% | 97.30% | 97.50% | 0.9829 |
| Studies | Model | Accuracy |
|---|---|---|
| Ref. [37] | SSAO-MARS | 96.00% |
| Proposed RS-RF | Random search with random forest | 97.40% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tarek, Z.; Elshewey, A.M.; Shohieb, S.M.; Elhady, A.M.; El-Attar, N.E.; Elseuofi, S.; Shams, M.Y. Soil Erosion Status Prediction Using a Novel Random Forest Model Optimized by Random Search Method. Sustainability 2023, 15, 7114. https://doi.org/10.3390/su15097114
Tarek Z, Elshewey AM, Shohieb SM, Elhady AM, El-Attar NE, Elseuofi S, Shams MY. Soil Erosion Status Prediction Using a Novel Random Forest Model Optimized by Random Search Method. Sustainability. 2023; 15(9):7114. https://doi.org/10.3390/su15097114
Chicago/Turabian StyleTarek, Zahraa, Ahmed M. Elshewey, Samaa M. Shohieb, Abdelghafar M. Elhady, Noha E. El-Attar, Sherif Elseuofi, and Mahmoud Y. Shams. 2023. "Soil Erosion Status Prediction Using a Novel Random Forest Model Optimized by Random Search Method" Sustainability 15, no. 9: 7114. https://doi.org/10.3390/su15097114
APA StyleTarek, Z., Elshewey, A. M., Shohieb, S. M., Elhady, A. M., El-Attar, N. E., Elseuofi, S., & Shams, M. Y. (2023). Soil Erosion Status Prediction Using a Novel Random Forest Model Optimized by Random Search Method. Sustainability, 15(9), 7114. https://doi.org/10.3390/su15097114