
Comparative Evaluation of Crash Hotspot Identification Methods: Empirical Bayes vs. Potential for Safety Improvement Using Variants of Negative Binomial Models

 , ,
, ,  and
and 
Abstract
:1. Introduction
1.1. Hotspot Identification
1.2. Hotspot Identification Methods
1.3. Performance of Different HSID Methods
1.4. Criteria for Evaluation of HSID Methods
1.5. Crash Prediction Models/Safety Performance Functions
1.6. Problem Statement
2. Material and Method
2.1. Crash Prediction Models
2.1.1. Negative Binomial Model
2.1.2. Random Parameter NB Model
2.2. Hotspot Identification Methods
2.2.1. Empirical Bayes Method
2.2.2. Potential for Safety Improvement (PSI)
2.3. Evaluation of HSID Methods
3. Data
4. Results
4.1. Crash Prediction Models
4.2. Hotspot Identification Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Haddak, M.M.; Lefèvre, M.; Havet, N. Willingness-to-Pay for Road Safety Improvement. Transp. Res. Part Policy Pract. 2016, 87, 1–10. [Google Scholar] [CrossRef]
- Corben, B.; Peiris, S.; Mishra, S. The Importance of Adopting a Safe System Approach—Translation of Principles into Practical Solutions. Sustainability 2022, 14, 2559. [Google Scholar] [CrossRef]
- United Nations. Improving Global Road Safety; United Nations: New York, NY, USA, 2020. [Google Scholar]
- United Nations. The UN Sustainable Development Goals; United Nations: New York, NY, USA, 2016. [Google Scholar]
- European Commission EU Strategic Action Plan on Road Safety; European Commission: Brussels, Belgium, 2018.
- European Commission. EU Road Safety Policy Framework 2021–2030—Next Steps towards Vision Zero; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- Highway Safety Manual (HSM); AASHTO, American Association of State and Highway Transportation Officials: Washington DC, USA, 2010; ISBN 978-1-56051-477-0.
- Road Safety Manual; Technical Committee on Road Safety C13; World Road Association: London, UK, 2019.
- Global Status Report on Road Safety 2023; World Health Organization: Geneva, Switzerland, 2023; ISBN 92-4-156506-3.
- Montella, A. A Comparative Analysis of Hotspot Identification Methods. Accid. Anal. Prev. 2010, 42, 571–581. [Google Scholar] [CrossRef] [PubMed]
- Elvik, R. A Survey of Operational Definitions of Hazardous Road Locations in Some European Countries. Accid. Anal. Prev. 2008, 40, 1830–1835. [Google Scholar] [CrossRef] [PubMed]
- Cheng, W.; Washington, S.P. Experimental Evaluation of Hotspot Identification Methods. Accid. Anal. Prev. 2005, 37, 870–881. [Google Scholar] [CrossRef]
- Laughland, J.C.; Haefner, L.E.; Hall, J.W.; Clough, D.R. Methods for Evaluating Highway Safety Improvements; Transportation Research Board: Washington, DC, USA, 1975. [Google Scholar]
- Hauer, E.; Persaud, B.N. Problem of Identifying Hazardous Locations Using Accident Data. Transp. Res. Rec. 1984, 975, 36–43. [Google Scholar]
- Hauer, E. Observational before/after Studies in Road Safety. Estimating the Effect of Highway and Traffic Engineering Measures on Road Safety; Elsevier Science Inc.: Tarrytown, NY, USA, 1997; ISBN 978-0-08-043053-9. [Google Scholar]
- Cheng, W.; Washington, S. New Criteria for Evaluating Methods of Identifying Hot Spots. Transp. Res. Rec. 2008, 2083, 76–85. [Google Scholar] [CrossRef]
- Lord, D.; Mannering, F. The Statistical Analysis of Crash-Frequency Data: A Review and Assessment of Methodological Alternatives. Transp. Res. Part Policy Pract. 2010, 44, 291–305. [Google Scholar] [CrossRef]
- Wang, K.; Zhao, S.; Ivan, J.N.; Ahmed, I.; Jackson, E. Evaluation of Hot Spot Identification Methods for Municipal Roads. J. Transp. Saf. Secur. 2020, 12, 463–481. [Google Scholar] [CrossRef]
- Li, J.; Wang, X. Hotspot Identification on Urban Arterials at the Meso Level. Accid. Anal. Prev. 2022, 169, 106632. [Google Scholar] [CrossRef]
- Wan, Y.; He, W.; Zhou, J. Urban Road Accident Black Spot Identification and Classification Approach: A Novel Grey Verhuls–Empirical Bayesian Combination Method. Sustainability 2021, 13, 11198. [Google Scholar] [CrossRef]
- Meng, Y.; Wu, L.; Ma, C.; Guo, X.; Wang, X. (Bruce) A Comparative Analysis of Intersection Hotspot Identification: Fixed vs. Varying Dispersion Parameters in Negative Binomial Models. J. Transp. Saf. Secur. 2020, 14, 305–322. [Google Scholar] [CrossRef]
- Manepalli, U.R.R.; Bham, G.H. An Evaluation of Performance Measures for Hotspot Identification. J. Transp. Saf. Secur. 2016, 8, 327–345. [Google Scholar] [CrossRef]
- Zou, Y.; Lord, D.; Zhang, Y.; Peng, Y. Comparison of Sichel and Negative Binomial Models in Estimating Empirical Bayes Estimates. Transp. Res. Rec. 2013, 2392, 11–21. [Google Scholar] [CrossRef]
- Kononov, J.; Durso, C.; Lyon, C.; Allery, B. Level of Service of Safety Revisited. Transp. Res. Rec. 2015, 2514, 10–20. [Google Scholar] [CrossRef]
- Cafiso, S.; Di Silvestro, G. Performance of Safety Indicators in Identification of Black Spots on Two-Lane Rural Roads. Transp. Res. Rec. 2011, 2237, 78–87. [Google Scholar] [CrossRef]
- Washington, S.; Haque, M.M.; Oh, J.; Lee, D. Applying Quantile Regression for Modeling Equivalent Property Damage Only Crashes to Identify Accident Blackspots. Accid. Anal. Prev. 2014, 66, 136–146. [Google Scholar] [CrossRef]
- Karamanlis, I.; Nikiforiadis, A.; Botzoris, G.; Kokkalis, A.; Basbas, S. Towards Sustainable Transportation: The Role of Black Spot Analysis in Improving Road Safety. Sustainability 2023, 15, 14478. [Google Scholar] [CrossRef]
- Maher, M.J.; Mountain, L.J. The Identification of Accident Blackspots: A Comparison of Current Methods. Accid. Anal. Prev. 1988, 20, 143–151. [Google Scholar] [CrossRef]
- Khodadadi, A.; Tsapakis, I.; Shirazi, M.; Das, S.; Lord, D. Derivation of the Empirical Bayesian Method for the Negative Binomial-Lindley Generalized Linear Model with Application in Traffic Safety. Accid. Anal. Prev. 2022, 170, 106638. [Google Scholar] [CrossRef]
- Huang, H.; Chin, H.C.; Haque, M.M. Hotspot Identification: A Full Bayesian Hierarchical Modeling Approach. In Transportation and Traffic Theory 2009: Golden Jubilee: Papers Selected for Presentation at ISTTT18, a Peer Reviewed Series Since 1959; Lam, W.H.K., Wong, S.C., Lo, H.K., Eds.; Springer: Boston, MA, USA, 2009; pp. 441–462. ISBN 978-1-4419-0820-9. [Google Scholar]
- Guo, X.; Wu, L.; Lord, D. Generalized Criteria for Evaluating Hotspot Identification Methods. Accid. Anal. Prev. 2020, 145, 105684. [Google Scholar] [CrossRef] [PubMed]
- Mendes, O.B.B.; Larocca, A.P.C.; Rodrigues Silva, K.; Pirdavani, A. Assessing the Performance of Highway Safety Manual (HSM) Predictive Models for Brazilian Multilane Highways. Sustainability 2023, 15, 10474. [Google Scholar] [CrossRef]
- Zou, Y.; Ash, J.E.; Park, B.-J.; Lord, D.; Wu, L. Empirical Bayes Estimates of Finite Mixture of Negative Binomial Regression Models and Its Application to Highway Safety. J. Appl. Stat. 2018, 45, 1652–1669. [Google Scholar] [CrossRef]
- Champahom, T.; Jomnonkwao, S.; Banyong, C.; Nambulee, W.; Karoonsoontawong, A.; Ratanavaraha, V. Analysis of Crash Frequency and Crash Severity in Thailand: Hierarchical Structure Models Approach. Sustainability 2021, 13, 10086. [Google Scholar] [CrossRef]
- Khattak, M.W.; Pirdavani, A.; De Winne, P.; Brijs, T.; De Backer, H. Estimation of Safety Performance Functions for Urban Intersections Using Various Functional Forms of the Negative Binomial Regression Model and a Generalized Poisson Regression Model. Accid. Anal. Prev. 2021, 151, 105964. [Google Scholar] [CrossRef] [PubMed]
- Mićić, S.; Vujadinović, R.; Amidžić, G.; Damjanović, M.; Matović, B. Accident Frequency Prediction Model for Flat Rural Roads in Serbia. Sustainability 2022, 14, 7704. [Google Scholar] [CrossRef]
- Tang, H.; Gayah, V.V.; Donnell, E.T. Evaluating the Predictive Power of an SPF for Two-Lane Rural Roads with Random Parameters on out-of-Sample Observations. Accid. Anal. Prev. 2019, 132, 105275. [Google Scholar] [CrossRef] [PubMed]
- Intini, P.; Berloco, N.; Coropulis, S.; Gentile, R.; Ranieri, V. The Use of Macro-Level Safety Performance Functions for Province-Wide Road Safety Management. Sustainability 2022, 14, 9245. [Google Scholar] [CrossRef]
- Montella, A.; Marzano, V.; Mauriello, F.; Vitillo, R.; Fasanelli, R.; Pernetti, M.; Galante, F. Development of Macro-Level Safety Performance Functions in the City of Naples. Sustainability 2019, 11, 1871. [Google Scholar] [CrossRef]
- Pirdavani, A.; Brijs, T.; Bellemans, T.; Kochan, B.; Wets, G. Application of Different Exposure Measures in Development of Planning-Level Zonal Crash Prediction Models. Transp. Res. Rec. 2012, 2280, 145–153. [Google Scholar] [CrossRef]
- Hauer, E. Overdispersion in Modelling Accidents on Road Sections and in Empirical Bayes Estimation. Accid. Anal. Prev. 2001, 33, 799–808. [Google Scholar] [CrossRef]
- Cafiso, S.; Di Silvestro, G.; Persaud, B.; Begum, M.A. Revisiting Variability of Dispersion Parameter of Safety Performance for Two-Lane Rural Roads. Transp. Res. Rec. 2010, 2148, 38–46. [Google Scholar] [CrossRef]
- Khodadadi, A.; Tsapakis, I.; Das, S.; Lord, D.; Li, Y. Application of Different Negative Binomial Parameterizations to Develop Safety Performance Functions for Non-Federal Aid System Roads. Accid. Anal. Prev. 2021, 156, 106103. [Google Scholar] [CrossRef] [PubMed]
- Lord, D.; Park, P.Y.-J. Investigating the Effects of the Fixed and Varying Dispersion Parameters of Poisson-Gamma Models on Empirical Bayes Estimates. Accid. Anal. Prev. 2008, 40, 1441–1457. [Google Scholar] [CrossRef] [PubMed]
- Anastasopoulos, P.C.; Mannering, F.L. A Note on Modeling Vehicle Accident Frequencies with Random-Parameters Count Models. Accid. Anal. Prev. 2009, 41, 153–159. [Google Scholar] [CrossRef] [PubMed]
- Lord, D.; Persaud, B.N. Accident Prediction Models With and Without Trend: Application of the Generalized Estimating Equations Procedure. Transp. Res. Rec. 2000, 1717, 102–108. [Google Scholar] [CrossRef]
- Shankar, V.N.; Albin, R.B.; Milton, J.C.; Mannering, F.L. Evaluating Median Crossover Likelihoods with Clustered Accident Counts: An Empirical Inquiry Using the Random Effects Negative Binomial Model. Transp. Res. Rec. 1998, 1635, 44–48. [Google Scholar] [CrossRef]
- Mitra, S.; Washington, S. On the Nature of Over-Dispersion in Motor Vehicle Crash Prediction Models. Accid. Anal. Prev. 2007, 39, 459–468. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.; Huo, X.; Tarko, A.P.; Leng, J. Comparative Analysis of Alternative Random Parameters Count Data Models in Highway Safety. Anal. Methods Accid. Res. 2021, 30, 100158. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis, 4th ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 2007; pp. 201–215. [Google Scholar]
- Bhat, C.R. Simulation Estimation of Mixed Discrete Choice Models Using Randomized and Scrambled Halton Sequences. Transp. Res. Part B Methodol. 2003, 37, 837–855. [Google Scholar] [CrossRef]
- Xu, P.; Zhou, H.; Wong, S.C. On Random-Parameter Count Models for out-of-Sample Crash Prediction: Accounting for the Variances of Random-Parameter Distributions. Accid. Anal. Prev. 2021, 159, 106237. [Google Scholar] [CrossRef] [PubMed]
- Persaud, B.; Lyon, C.; Nguyen, T. Empirical Bayes Procedure for Ranking Sites for Safety Investigation by Potential for Safety Improvement. Transp. Res. Rec. 1999, 1665, 7–12. [Google Scholar] [CrossRef]
- Hauer, E. Lane Width and Safety. Literature. 2000. Available online: https://www.academia.edu/21401042/Lane_width_and_safety_Literature (accessed on 11 December 2023).
- Pirdavani, A.; Bellemans, T.; Brijs, T.; Wets, G. Application of Geographically Weighted Regression Technique in Spatial Analysis of Fatal and Injury Crashes. J. Transp. Eng. 2014, 140, 04014032. [Google Scholar] [CrossRef]
- Brijs, T.; Pirdavani, A. Urban and Suburban Arterials. In Safe Mobility: Challenges, Methodology and Solutions; Lord, D., Washington, S., Eds.; Transport and Sustainability; Emerald Publishing Limited: Bingley, UK, 2018; Volume 11, pp. 85–106. ISBN 978-1-78635-223-1. [Google Scholar]
- Swennen, B. Antwerp’s Cycling Policy Plan 2015–2019—A Lot of Ambition and a Good Plan! Available online: https://www.ecf.com/news-and-events/news/antwerps-cycling-policy-plan-2015-2019-lot-ambition-and-good-plan (accessed on 16 November 2022).
- Olszewski, P.; Szagała, P.; Rabczenko, D.; Zielińska, A. Investigating Safety of Vulnerable Road Users in Selected EU Countries. J. Saf. Res. 2019, 68, 49–57. [Google Scholar] [CrossRef]
- Mohammed, H. The Influence of Road Geometric Design Elements on Highway Safety. Int. J. Civ. Eng. Technol. 2013, 4, 146–162. [Google Scholar]
- Noland, R.B.; Oh, L. The Effect of Infrastructure and Demographic Change on Traffic-Related Fatalities and Crashes: A Case Study of Illinois County-Level Data. Accid. Anal. Prev. 2004, 36, 525–532. [Google Scholar] [CrossRef] [PubMed]



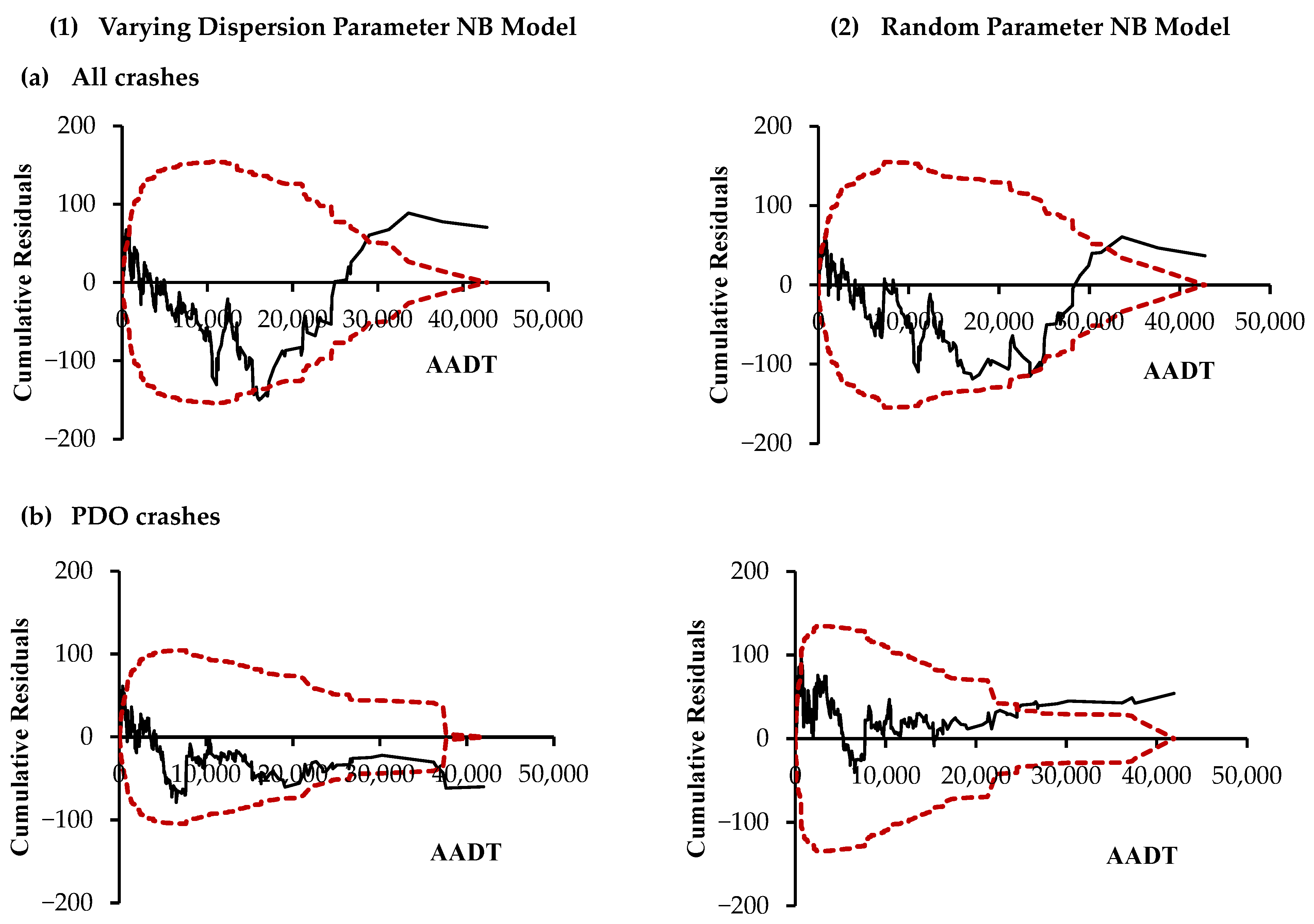{kind=link}
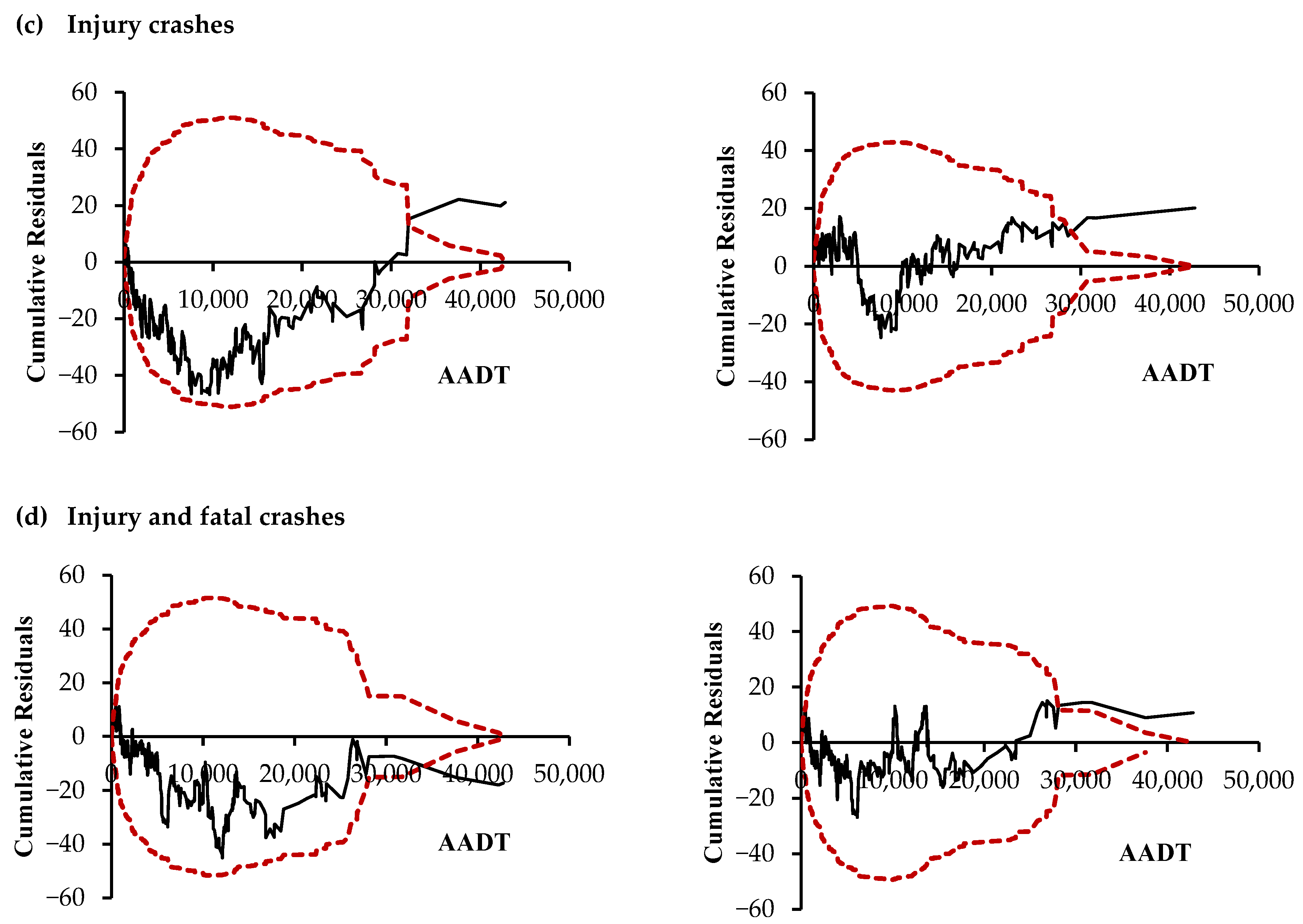{kind=link}
| Traffic and Road Segment Variables | ||||
|---|---|---|---|---|
| Variables | Minimum | Maximum | Mean | Std. Dev. |
| AADT (veh/day) | 22 | 42,783 | 4842 | 6543 |
| Segment length (km) | 0.06 | 1.557 | 0.109 | 0.104 |
| Lane width (m) | 2.50 | 5.00 | 3.51 | 0.50 |
| No. of Lanes 1 | 1 = 749, 2 = 1054, 3 = 664 | |||
| Parking Type 2 | 0 = 738 sites, 1 = 1565 sites, 2 = 164 sites | |||
| Parking Arrangement 3 | 0 = 740 sites, 1 = 719 sites, 2 = 949 sites, 3 = 59 sites | |||
| Crash Frequency | ||||
| Minimum | Maximum | Mean | Std. Dev. | |
| All crashes 4 (six years: 2010–2015) | 0 | 90 | 7.52 | 10.28 |
| (P1: 2010–2011) | 0 | 28 | 2.38 | 3.078 |
| (P2: 2012–2013) | 0 | 33 | 2.58 | 3.290 |
| (P3: 2014–2015) | 0 | 19 | 2.16 | 2.761 |
| Fatal and injury crashes (six years: 2010–2015) | 0 | 44 | 2.01 | 4.421 |
| (P1: 2010–2011) | 0 | 12 | 0.58 | 1.222 |
| (P2: 2012–2013) | 0 | 14 | 0.66 | 1.302 |
| (P3: 2014–2015) | 0 | 10 | 0.57 | 1.132 |
| Injury crashes (six years: 2010–2015) | 0 | 43 | 1.99 | 4.402 |
| (P1: 2010–2011) | 0 | 12 | 0.65 | 1.339 |
| (P2: 2012–2013) | 0 | 11 | 0.70 | 1.344 |
| (P3: 2014–2015) | 0 | 10 | 0.65 | 1.177 |
| PDO crashes (six years: 2010–2015) | 0 | 67 | 5.51 | 6.937 |
| (P1: 2010–2011) | 0 | 20 | 1.85 | 2.499 |
| (P2: 2012–2013) | 0 | 22 | 1.99 | 2.577 |
| (P3: 2014–2015) | 0 | 15 | 1.65 | 2.099 |
| All Crashes | PDO Crashes | Injury Crashes | Injury and Fatal Crashes | |
|---|---|---|---|---|
| Coef. 1 (Std. Err.) | Coef. (Std. Err.) | Coef. (Std. Err.) | Coef. (Std. Err.) | |
| (a). VDPNB | ||||
| Intercept | 1.513 *** (0.251) | 1.940 *** (0.250) | −1.883 *** (0.405) | −1.814 *** (0.394) |
| Seg. Length | 0.641 *** (0.034) | 0.673 *** (0.018) | 0.585 *** (0.050) | 0.608 *** (0.049) |
| Traffic Vol. | 0.293 *** (0.018) | 0.246 *** (0.034) | 0.522 *** (0.029) | 0.538 *** (0.029) |
| No. of Lanes | ||||
| Two lanes vs. one lane | −0.260 *** (0.061) | −0.361 *** (0.061) | - | - |
| Three or more lanes vs. one lane | −0.166 ** (0.083) | −0.343 *** (0.085) | - | - |
| Lane width | −0.125 *** 0.047 | −0.204 *** 0.049 | −0.145 * (0.075) | −0.156 ** (0.074) |
| Parking Type | ||||
| Parallel parking vs. no parking | 0.371 *** (0.055) | 0.476 *** (0.056) | 0.127 * (0.072) | 0.084 ** (0.073) |
| Other parking types 2 vs. no parking | 0.549 ** (0.095) | 0.796 *** (0.101) | 0.013 (0.130) | 0.070 (0.120) |
| Dispersion parameter | ||||
| Intercept | 0.397 (0.584) | 0.116 (0.622) | 2.096 ** 0.991 | 2.202 ** (0.973) |
| Seg. Length | 0.140 ** (0.070) | 0.324 *** (0.075) | 0.254 ** (0.111) | 0.239 ** (0.108) |
| AADT | −0.180 *** (0.040) | −0.094 ** (0.043) | −0.265 *** (0.071) | −0.347 *** (0.067) |
| No. of Lanes | ||||
| Two lanes vs. one lane | 0.511 *** (0.154) | 0.511 *** (0.166) | - | - |
| Three or more lanes vs. one lane | 0.892 *** (0.188) | 0.847 *** (0.201) | - | - |
| Parking Type | ||||
| Parallel parking vs. no parking | −0.546 *** (0.111) | −0.601 *** (0.119) | −0.679 *** (0.154) | −0.718 *** (0.155) |
| Other parking types vs. no parking | −0.359 * (0.188) | −0.218 * (0.194) | −0.938 ** (0.381) | −1.302 ** (0.418) |
| Log-likelihood | −5373.247 | −4918.777 | −3031.631 | −3047.820 |
| AIC | 10,770.500 | 9861.600 | 6087.300 | 6119.600 |
| (b). RPNB Model | ||||
| Intercept | 1.463 *** (0.228) | 1.637 *** (0.231) | −2.159 *** (0.346) | −2.156 *** (0.349) |
| SD of intercept | 0.194 * (0.018) | 0.017 * (0.018) | 0.022 * (0.026) | 0.064 ** (0.026) |
| Seg. Length | 0.656 *** (0.026) | 0.657 *** (0.027) | 0.529 *** (0.040) | 0.522 *** (0.040) |
| AADT | 0.300 *** (0.015) | 0.241 *** (0.016) | 0.553 *** (0.025) | 0.549 *** (0.025) |
| SD of AADT | 0.027 *** (0.002) | 0.046 *** (0.002) | 0.009 *** (0.003) | 0.010 *** (0.003) |
| No. of Lanes | ||||
| Two lanes vs. one lane | −0.317 *** (0.062) | −0.399 *** (0.062) | - | - |
| Three or more lanes vs. one lane | −0.283 ** (0.075) | −0.369 *** (0.077) | - | - |
| Lane width | −0.205 *** (0.047) | −0.221 *** (0.047) | −0.211 *** (0.071) | −0.200 *** (0.072) |
| SD of lane width | 0.014 *** (0.005) | 0.019 *** (0.005) | 0.123 *** (0.007) | 0.114 *** (0.007) |
| Parking Type | ||||
| Parallel parking vs. no parking | 0.472 *** (0.045) | 0.611 ** (0.046) | 0.181 *** (0.061) | 0.162 *** (0.062) |
| Other parking types vs. no parking | 0.623 ** (0.077) | 0.842 *** (0.078) | - | - |
| Dispersion parameter | 2.233 *** (0.102) | 2.361 *** (0.121) | 2.054 ** (0.171) | 1.953 ** (0.158) |
| Log-likelihood | −5216.016 | −4738.422 | −2958.796 | −2987.567 |
| AIC | 10,464.030 | 9508.844 | 5949.591 | 6007.135 |
| HCCT | VDPNB | RPNB | VDPNB | RPNB | |||||
|---|---|---|---|---|---|---|---|---|---|
| EB | PSI | EB | PSI | EB | PSI | EB | PSI | ||
| P1 *, P2–P3 | P2 *, P3 | ||||||||
| All crashes | |||||||||
| τ = 2.5% | 172 | 153 | 184 | 164 | 170 | 163 | 196 | 180 | |
| τ = 5.0% | 304 | 267 | 326 | 290 | 294 | 278 | 310 | 289 | |
| τ = 7.5% | 433 | 349 | 430 | 398 | 392 | 355 | 401 | 373 | |
| τ = 10.0% | 516 | 448 | 520 | 477 | 451 | 416 | 477 | 442 | |
| PDO crashes | |||||||||
| τ = 2.5% | 125 | 97 | 136 | 134 | 113 | 89 | 120 | 131 | |
| τ = 5.0% | 192 | 147 | 201 | 195 | 186 | 144 | 186 | 186 | |
| τ = 7.5% | 254 | 199 | 263 | 244 | 234 | 183 | 246 | 234 | |
| τ = 10.0% | 302 | 228 | 319 | 311 | 282 | 210 | 298 | 281 | |
| Injury crashes | |||||||||
| τ = 2.5% | 64 | 82 | 83 | 58 | 67 | 74 | 83 | 65 | |
| τ = 5.0% | 121 | 120 | 131 | 98 | 106 | 100 | 122 | 102 | |
| τ = 7.5% | 149 | 139 | 170 | 118 | 131 | 125 | 145 | 112 | |
| τ = 10.0% | 178 | 153 | 197 | 136 | 156 | 142 | 169 | 133 | |
| Injury and fatal crashes | |||||||||
| τ = 2.5% | 55 | 43 | 63 | 59 | 59 | 54 | 68 | 61 | |
| τ = 5.0% | 94 | 71 | 111 | 85 | 90 | 77 | 105 | 82 | |
| τ = 7.5% | 125 | 91 | 133 | 114 | 116 | 92 | 125 | 99 | |
| τ = 10.0% | 137 | 103 | 161 | 129 | 132 | 101 | 147 | 109 | |
| CSCT | VDPNB | RPNB | VDPNB | RPNB | |||||
|---|---|---|---|---|---|---|---|---|---|
| EB | PSI | EB | PSI | EB | PSI | EB | PSI | ||
| P1 *, P2–P3 | P2 *, P3 | ||||||||
| All crashes | |||||||||
| τ = 2.5% | 9 | 5 | 10 | 6 | 10 | 9 | 12 | 11 | |
| τ = 5.0% | 18 | 14 | 21 | 18 | 18 | 18 | 23 | 19 | |
| τ = 7.5% | 32 | 23 | 34 | 28 | 31 | 27 | 33 | 29 | |
| τ = 10.0% | 44 | 32 | 49 | 36 | 43 | 31 | 45 | 34 | |
| PDO crashes | |||||||||
| τ = 2.5% | 7 | 5 | 9 | 7 | 10 | 7 | 9 | 8 | |
| τ = 5.0% | 15 | 10 | 17 | 14 | 15 | 9 | 17 | 14 | |
| τ = 7.5% | 20 | 15 | 25 | 18 | 18 | 20 | 28 | 19 | |
| τ = 10.0% | 26 | 19 | 34 | 26 | 27 | 24 | 35 | 24 | |
| Injury crashes | |||||||||
| τ = 2.5% | 5 | 4 | 9 | 6 | 9 | 5 | 9 | 5 | |
| τ = 5.0% | 16 | 11 | 24 | 12 | 18 | 10 | 24 | 14 | |
| τ = 7.5% | 29 | 16 | 37 | 16 | 24 | 16 | 36 | 18 | |
| τ = 10.0% | 39 | 19 | 48 | 20 | 37 | 25 | 49 | 26 | |
| Injury and fatal crashes | |||||||||
| τ = 2.5% | 5 | 3 | 10 | 5 | 8 | 5 | 11 | 6 | |
| τ = 5.0% | 15 | 9 | 26 | 10 | 14 | 8 | 23 | 11 | |
| τ = 7.5% | 27 | 12 | 37 | 17 | 25 | 16 | 37 | 19 | |
| τ = 10.0% | 31 | 18 | 51 | 23 | 30 | 22 | 48 | 26 | |
| ARDT | VDPNB | RPNB | VDPNB | RPNB | |||||
|---|---|---|---|---|---|---|---|---|---|
| EB | PSI | EB | PSI | EB | PSI | EB | PSI | ||
| P1 *, P2–P3 | P2 *, P3 | ||||||||
| All crashes | |||||||||
| τ = 2.5% | 224 | 996 | 268 | 821 | 246 | 1135 | 394 | 1150 | |
| τ = 5.0% | 436 | 2578 | 754 | 2321 | 549 | 2447 | 690 | 2623 | |
| τ = 7.5% | 835 | 4936 | 1237 | 4932 | 834 | 4711 | 1848 | 4952 | |
| τ = 10.0% | 1402 | 6405 | 2404 | 6569 | 1369 | 7603 | 2833 | 6964 | |
| PDO crashes | |||||||||
| τ = 2.5% | 452 | 7528 | 911 | 1402 | 691 | 1431 | 793 | 1796 | |
| τ = 5.0% | 1242 | 12,748 | 2241 | 3363 | 1246 | 1038 | 1737 | 3319 | |
| τ = 7.5% | 2153 | 18,420 | 5464 | 3876 | 1963 | 3316 | 3876 | 5726 | |
| τ = 10.0% | 3012 | 24,155 | 5469 | 8318 | 3015 | 4211 | 5487 | 8218 | |
| Injury crashes | |||||||||
| τ = 2.5% | 164 | 3695 | 640 | 3350 | 147 | 2320 | 286 | 2472 | |
| τ = 5.0% | 432 | 6674 | 1238 | 6660 | 297 | 5265 | 979 | 6176 | |
| τ = 7.5% | 714 | 10,233 | 2357 | 9378 | 612 | 8829 | 2602 | 10,155 | |
| τ = 10.0% | 1096 | 13,915 | 2894 | 13,995 | 1058 | 12,275 | 3386 | 13,266 | |
| Injury and fatal crashes | |||||||||
| τ = 2.5% | 167 | 3284 | 510 | 786 | 144 | 2681 | 510 | 876 | |
| τ = 5.0% | 332 | 7539 | 1528 | 2836 | 311 | 6410 | 1528 | 2967 | |
| τ = 7.5% | 604 | 11,111 | 2857 | 4415 | 754 | 8986 | 2857 | 5260 | |
| τ = 10.0% | 1019 | 15,152 | 4315 | 7297 | 1097 | 11,301 | 4315 | 8394 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khattak, M.W.; De Backer, H.; De Winne, P.; Brijs, T.; Pirdavani, A. Comparative Evaluation of Crash Hotspot Identification Methods: Empirical Bayes vs. Potential for Safety Improvement Using Variants of Negative Binomial Models. Sustainability 2024, 16, 1537. https://doi.org/10.3390/su16041537
Khattak MW, De Backer H, De Winne P, Brijs T, Pirdavani A. Comparative Evaluation of Crash Hotspot Identification Methods: Empirical Bayes vs. Potential for Safety Improvement Using Variants of Negative Binomial Models. Sustainability. 2024; 16(4):1537. https://doi.org/10.3390/su16041537
Chicago/Turabian StyleKhattak, Muhammad Wisal, Hans De Backer, Pieter De Winne, Tom Brijs, and Ali Pirdavani. 2024. "Comparative Evaluation of Crash Hotspot Identification Methods: Empirical Bayes vs. Potential for Safety Improvement Using Variants of Negative Binomial Models" Sustainability 16, no. 4: 1537. https://doi.org/10.3390/su16041537
APA StyleKhattak, M. W., De Backer, H., De Winne, P., Brijs, T., & Pirdavani, A. (2024). Comparative Evaluation of Crash Hotspot Identification Methods: Empirical Bayes vs. Potential for Safety Improvement Using Variants of Negative Binomial Models. Sustainability, 16(4), 1537. https://doi.org/10.3390/su16041537