1. Introduction
Digitalization has revolutionized education, leading to profound changes in the production and delivery of learning materials. Today’s learners have an unparalleled array of resources and strategies at their disposal, allowing them to tailor their educational journey to their individual needs [
1]. They can choose which resources to use, how to use them, and when to use them. This paradigm shift is evident in the popularity of artificial intelligence (AI)-backed intelligent tutoring systems [
2] or in novel pedagogical models that involve flipped classrooms [
3,
4] and/or collaboration between students [
5]. However, technology has also increased the number of possible distracting factors that hinder student engagement and their ability to learn effectively [
6].
The impact of technology on student learning and performance is a contentious topic in research. Advocates for technology-enhanced learning (TEL) assert that technology can bolster both teaching and learning. This is echoed by Dror [
7], who posits that technology provides a less cognitively taxing method of delivering materials, thereby fostering greater student engagement and, ultimately, enhanced learning. Conversely, some researchers highlight potential drawbacks, such as the decline in students’ reading and writing skills [
8], a tendency to rely solely on recorded materials rather than attending live classes [
9], and an overall decrease in the time dedicated to learning activities [
10]. An especially pressing cause for concern stems from the fact that the negative effects of technology are disproportionately felt by underperforming students who lack the necessary skills to make full use of the educational tools at their disposal [
11,
12]. Given the ongoing trend towards digitalization in education, it is increasingly important to employ technology in ways that are beneficial to all students.
Students have reported that a greater personalization of learning materials and interactions with their instructor are among the most effective strategies to promote student engagement, be it for high-resource contexts [
13] or in underserved communities [
14]. While the positive relationship between personalization and student performance is well established [
15], its implementation in the classroom has not fully realized this potential. Technology, and more specifically, generative artificial intelligence (AI), may play a pivotal role in the creation of materials usable for more personalized, almost individualized, purposes [
16].
The rise of artificial intelligence has already introduced a vast array of new teaching and learning methodologies that are either undergoing testing or are already implemented. That makes it the ideal time to gather early data from these new approaches and improve them during the feedback cycle loop. With education for sustainable development (ESD) becoming more popularized by initiatives like the sustainable development goals (SDGs), these actions will contribute toward better, equitable, and high-quality education for all [
17]. This is in line with the sustainable development goal 4 which, as defined by the United Nations, stands for “ensuring inclusive and equitable quality education and promote lifelong learning opportunities for all”. Moreover, it is expected to be accomplished by 2030 [
18]. For this to happen, educational institutions have to integrate sustainable values in all areas including management, research, and teaching [
19]. Researchers are already working on this field, like Abulibdeh et al. [
20], who have examined the possibilities for integrating AI tools into an educational context and within the ESD paradigm. Devy and Rroy [
21] have examined the possibilities of AI for sustainable teaching specifically in higher education institutions and Klasnja-Milicevic and Ivanovic [
22] have identified more segments in e-learning systems that can utilize AI toward the sustainable development of educational practices. The current study contributes toward the same sustainable goal, with documenting, implementing, and evaluating an approach for creating and delivering learning materials that are inclusive and can be personalized for every person.
The launch of OpenAI’s ChatGPT in late 2022 marked a significant milestone in the field of artificial intelligence, as its ability to generate coherent, human-like text across a wide range of topics set the stage for discussion among educators and researchers of how generative AI can be integrated into educational settings [
23,
24]. In particular, researchers have argued that the integration of large language models (LLMs) can contribute to a plethora of pedagogical applications ranging from automatic question generation (AGQ) [
25] to the creation of more personalized learning readings and materials [
26], with a possible end goal being the creation of fully personalized learning experiences taught by an avatar of a real or fictional character [
16]. This aligns with Bill Gates’ assessment that the future of education will rely on a personalized approach. In their words, if a student loves Minecraft, it could be used to teach them about shape volume or area. If students are fans of Taylor Swift, her lyrics could be used to teach storytelling [
27].
In this work, we present the results of an exploratory form of using Generative AI to create tutoring characters for a programming course taught at a software engineering college to address the following research questions:
How can an LLM be used to create different tutoring personas?
Personalized and adaptive learning have been identified as gaps in the educational process which may now be addressed thanks to technological advancements. To date, personalized learning has encompassed the practice of recommending different educational resources to students based on their existing knowledge. LLMs provide an opportunity to enhance the personalization of the student experience by providing learning materials in various styles, tailored to the individual tastes and interests of students. This study investigates the feasibility of achieving augmentation through the utilization of large language models and their integration into existing learning management systems, an aim that was previously unattainable.
How are AI tutors received by students attending the course?
This question investigates the acceptance and reception of AI-generated content by students. Its importance lies in analyzing the perceptions, attitudes, and satisfaction levels towards interacting with AI-generated content, after delivering an initial version of the hereby proposed method to freshman college students.
By addressing these questions, we are highlighting an innovative use-case for artificial intelligence in education. As noted by Kunicina et al. [
28], sustainable development in education is only to be achieved through creating innovative technologies and products. In this paper, we aim to take a step in that direction by proposing a sustainable solution for making education more engaging for everyone through generative AI. Furthermore, Bond et al. [
29], in the recent systematic review of artificial intelligence in higher education, stated that available literature on how AI is used at the postgraduate level remains limited, besides the fast development of AI models, tools, and solutions. This paper is a step forward in overcoming this limitation.
The remainder of this paper is structured as follows: The following section outlines how technology and generative AI have been used in support of teaching. The third section presents the data and methodology adopted. The fourth and fifth sections show and discuss the key results of our approach and their most relevant implications. The sixth and final section concludes.
3. Materials and Methods
This section will be split into four subsections, each describing a distinct part of the complete research. The first subsection explains the environment in which the experiment was performed and the methods used; the second one explains how generative AI was utilized for creating different content variants; the third one explains the data collection process; and the fourth one contains information about how the analysis was performed.
3.1. Methods
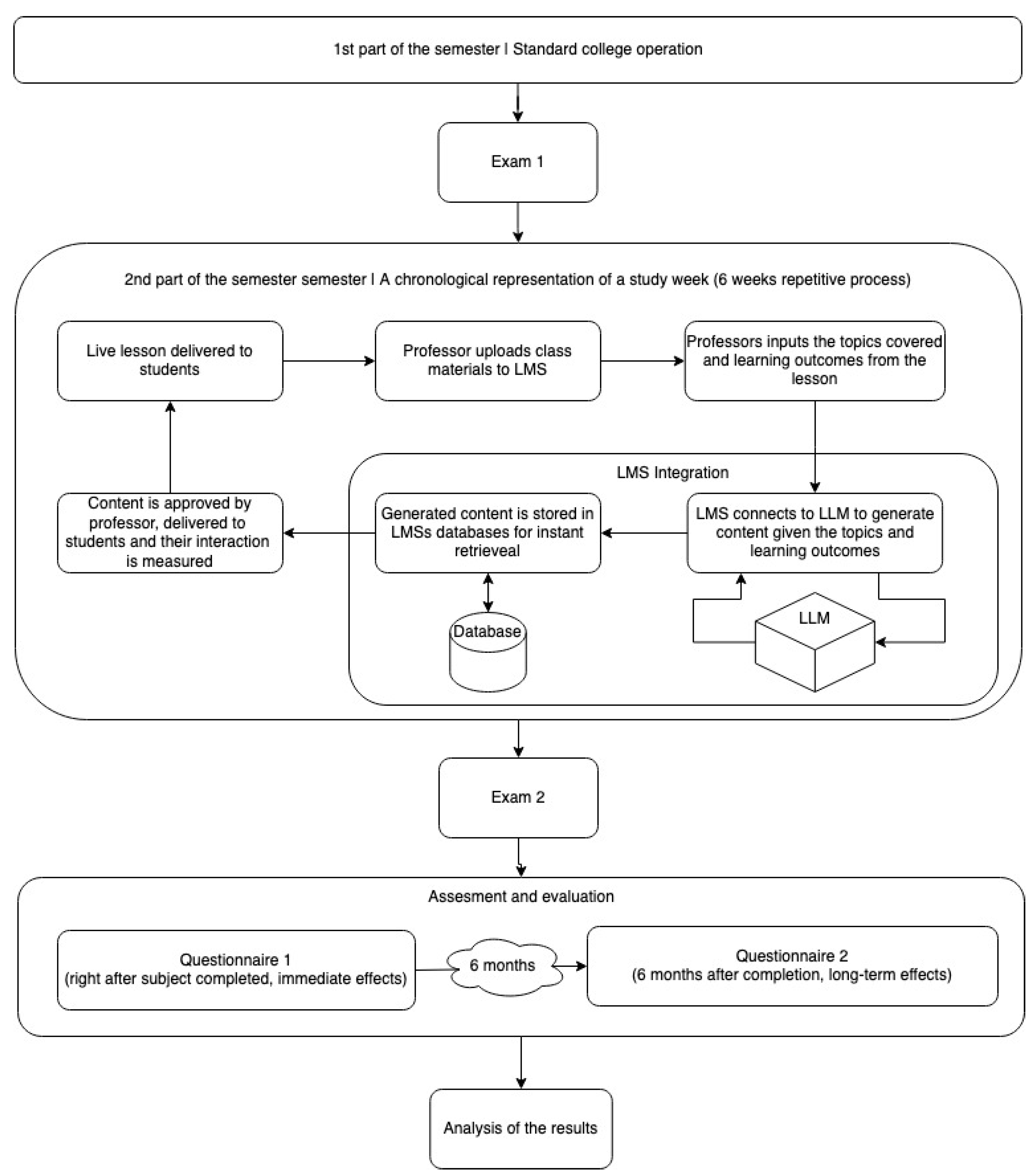
The experiment was performed during the second semester of freshman year students studying software engineering at a European university. A total of 47 students were actively enrolled in the second semester, when the experiment was conducted. Participation in the study was optional and on a voluntary basis. Out of the total of 47 enrolled students, a group of 20 students, all representatives of Generation Z and born between 2001 and 2003, joined the experiment. These participants not only varied in gender, with 15 males and 5 females, but also showed a diverse academic performance, with their GPAs at the end of the academic year spanning the full spectrum. This representation allows for a nuanced understanding of the research’s impact across a broad academic achievement range. The subject which supported the experiment is object-oriented programming (OOP). The subject is divided into two equal parts which are assessed independently. The first part of the subject introduced the object-oriented programming paradigm to students. It lasted for 6 weeks, during which the student’s main learning material was a book on OOP. A partial exam was carried out after the 6 teaching weeks. During the second part of the subject, which lasted for another 6 weeks, an OOP framework was taught and another partial exam was carried out. During this second part of the subject, as study material, the students had a book for the framework and an AI-generated learning resource. This learning resource constituted of AI-generated versions of the lessons in three distinct formats. After each class, the professor would go to the LMS to upload class materials. Besides that, the professor would add the title of the lesson, the content covered and the learning outcomes. After providing that information, the LMS would connect to OpenAI API to automatically generate learning content to help students achieve the learning outcomes. The first variant in which this content was generated was as it was written by a computer science teacher. The other two variants were inspired by pop-culture characters, selected by students, Batman and Wednesday Addams. The students could switch between different variants and their interaction with each one was being measured. The visual overview of the complete experiment is given in
Figure 1.
3.2. LMS Integration and AI-Powered Content Generation
A novel AI-driven content generation mechanism was integrated into the learning management system (LMS) that was used by the students. The new feature leverages OpenAI’s GPT, a state-of-the-art language model, to create diverse instructional content tailored to different pedagogical styles and personas. Having identified the research gap outlined in the previous section, the idea to generate content in the style of pop-culture characters was deployed. The students voted and chose two variations that they want to see: the first one being Batman and the second one being Wednesday Addams. Among other mentioned characters were as follows: Harry Potter, Yoda, Wonder Woman, Homer Simpson, Eric Cartman, and James Bond. Batman was mostly voted probably because he is not only a fictional character but a cultural artifact per se [
80], and Wednesday Addams was second most voted, probably because Wednesday was a trending show on one of the popular streaming services at the time of the experiment. Additionally, a third variant of automatically generated content was added, that one being in the style of a computer science teacher. The reason for limiting the variants to three is the pricing of OpenAI’s API usage at the time of the experiment.
The goal of this approach is to offer the students a more diverse set of learning resources. Everything they learned during the class was made available for reading and studying in the three formats with automatically generated content. The complete process is performed seamlessly for both the students and the professors. The content for students was generated, checked, and approved by the professor right after each class, meaning that it was not generated on demand. This approach guarantees the controlled generative environment and final proof check by the professor, mitigating the ethical challenges that come with generative AI, as discussed previously. The students can easily switch between the different variants, either for fun or to experience different instructional approaches and grasp the material looking at it from different viewpoints. The complete step-by-step integration process is described in the following part of the methodology.
3.2.1. Input and Content Personalization Process
Inside the LMS, in the resource upload section, a new option was shown to professors: the AI content generator. When selected, the professors were asked to fill 3 fields representing the 3 core teaching elements: the lesson’s title, the content or the topics covered in the lesson, and the learning outcomes.
When the form was submitted, the LMS performed 3 API calls to the OpenAI API, with the parameters shown in
Table 1.
The system message, which instructed the GPT-4 model which role to take and is used to fine-tune the desired outputs of the model, differed in the three separate API calls. The system messages that were used are given in
Table 2.
Supposing the professor is teaching recursion in programming and they entered the following data:
Title: recursion;
Contents: explain what recursion in computer programming is using the PHP programming language for the examples;
Learning outcomes: students should understand the concept of recursion, should know when to use it, and should be able to write simple recursive functions.
The complete request sent to OpenAI API to generate the Batman variant is shown in
Figure 2. The same is repeated two more times for the other two variants, only changing the system message with the messages shown in
Table 2.
3.2.2. AI-Generated Outputs
The OpenAI API always responded with the exact data format as requested in the system message. The JSON format for the questions ensures the seamless integration and storage within the LMS architecture, allowing for the efficient retrieval and display to students. The sample response received for the query presented in
Figure 2 is shown in
Figure 3.
After receiving the response, the LMS is programmed to insert the new learning material and questions into its database, thus making them available for the students. To do so, the LMS splits the content by the selected separator consisting of five hashtags—“#####” and stores the first part as the topic content. The second part is first decoded from JSON and then each question with each answer is stored in the LMS’s database. The LMS is developed to show content and quiz questions, regardless of whether they were created manually or automatically, by reading the available data from the database. The integration part includes getting the content from OpenAI’s API and storing it in the LMS’s database.
3.3. Data Collection
The LMS measured the number of sessions each student started, the time each student spent on each lesson variant, and the feedback grade and comment each student left. To measure these variables, the LMS was adapted so that every time the student opened any resource—not just AI-generated resource—a record was stored into database and new requests were made every 5 s while the student had the resource opened. We do send these requests for a more precise measure of student interaction. If a student leaves the tab open, but navigates away from it, it is deemed a background tab by modern browsers and requests will stop executing regularly. On the contrary, if we only mark the time a user closes the tab, we risk having students leave the tab open for a long time and thus making the data unreliable. Students were aware that the complete content was AI-generated and were encouraged to report any illogicalities in the course’s comment box. For each student, the dataset contains info about the time spent on each variant, the number of sessions started, the average number of time per session for each content variant, points before introducing the AI-generated content variant feature and points after its introduction. The dataset variables directly extracted from the LMS are shown in
Table 3.
After the subject was completed and the students had the second exam, a questionnaire was sent to each participating student to evaluate their experience with the introduction of this novel approach towards creating and delivering learning materials to students. Ten students answered the questionnaire. Six months after course completion, a new questionnaire was sent out to all students in order to evaluate the long-term effect that our proposed instrument has on student experience. A total of 13 students responded to the second questionnaire. The questions on both questionnaires are different and are presented in
Table 4.
3.4. Data Analysis
Before analyzing the data collected from the students, all data underwent an anonymi-zation process in order to make the results of individual students indistinguishable under observation. As a preparatory step preceding the analysis, we removed one outlier student whose time spent on the LMS was more than three standard deviations away from the class’s mean value, leaving 19 students for further analysis.
For the quantitative analysis, we compared the time students spent on each variant and their results on the first exam, the second exam, and the difference in the points between the two exams to identify a possible correlation between these two. The dataset of 19 students is sparse for getting beneficial insights by performing statistical analysis, so no specific statistical tests were employed since the results would be insignificant before more data become available. First, students were categorized into two distinct groups based on their engagement time with the platform. This engagement time was quantified by summing the durations recorded in each content variant for each student. The median value of these aggregate times served as the threshold for classification. Students whose total engagement time exceeded the median were labeled as ’more active’, indicating that their usage was above the median level of engagement for the cohort. Conversely, students whose engagement time was equal to or less than the median were classified as ’less active’, reflecting a level of platform interaction that was at or below the median engagement of their peers. This time-on-task measurement approach is heavily used in educational contexts, particularly for predicting students’ success [
81]. Another approach would be to apply machine learning algorithms like K-means or decision tree classifiers [
82], but the sample size is not fit for cluster analysis [
83]. The median-based division provides a means to categorizing students into relative levels of activity, facilitating the comparative analysis of behavioral patterns and outcomes associated with differing degrees of platform engagement, and still enabling the comparison—even with a sparse dataset.
For the qualitative part of the analysis, we looked at the results from both questionnaires. Qualitative questionnaires have been reported as a successful method for information studies [
84]. The first questionnaire mostly consisted of Likert-scale-type questions. To analyze these results, the ratings were coded into three categories: high satisfaction (ratings 4–5), medium satisfaction (ratings 2–3), and low satisfaction (rating 1). This dimensionality reduction from five to three categories was performed as a consequence of the sparse dataset, even though the 7-point Likert scale was reported to provide the best results [
85]. A future work on this topic with more students should consider delivering the questionnaires in different manners. The analysis focused on identifying patterns within these categories, particularly looking for correlations between high engagement and satisfaction ratings.
For the second questionnaire, which mostly consisted of open-ended questions, the answers were manually coded in the following categories: appreciated the quizzes, appreciated the characters, preferred the AI content, preferred traditional approach, and skeptical. These categories were identified after analyzing the students’ answers. Each student can be classified in multiple categories. The change in recommendation preferences and preferred variants was recorded and analyzed where possible.
4. Results
The results section will be subdivided into two sections containing the quantitative and qualitative results. The quantitative results serve to give us a general overview of the platform usage by students and will help determine whether there is a preferred variant for learning. A total of 20 students interacted with the AI-generated learning materials throughout the subject duration. Among the 20 students, one was identified as an outlier and removed from the dataset. After the subject was complete the aggregate results of the AI content usage were collected, surveys were conducted, and the results from the analysis are presented in the following subsections.
4.1. Quantitative Results
The results presented in this section showcase how the initial introduction of the gamified role-based instruction method reflects on student learning.
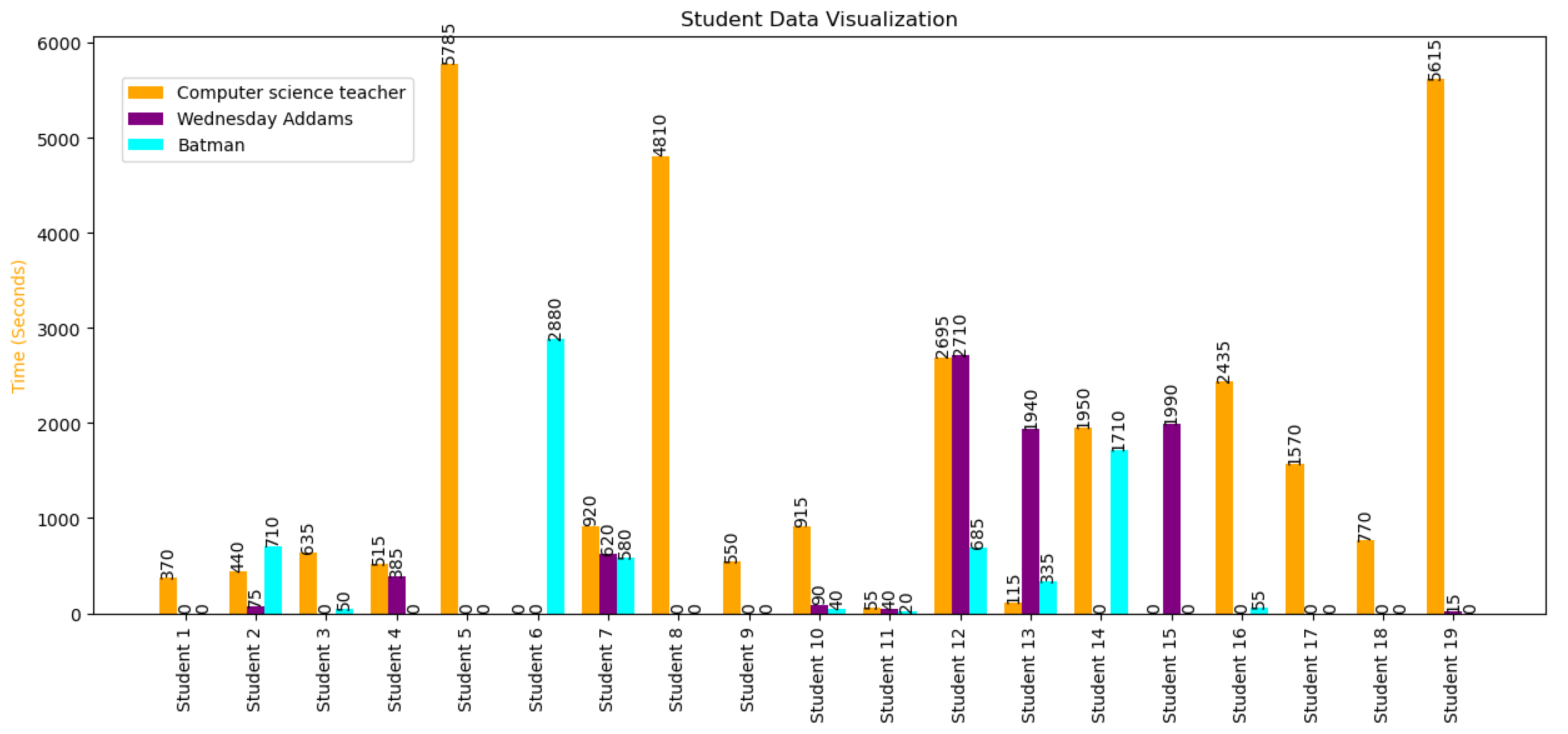
Figure 4 contains the results for all of the 19 students who interacted with the AI-generated content after outliers were removed and the time they spent on each content variant. The bar charts represent the total amount of time in seconds that each student spent on a given variant.
Based on the data presented in
Figure 4, it is evident that the computer science teacher version is the most frequently viewed content variant. Although the students voted and decided which fictional characters would be made available, they were more interested in the most traditional style of the content. Upon analyzing the cumulative amount of time allocated to each variation by all the participating students in this study, we obtained the findings presented in
Table 5.
If we assume that the computer science teacher variant is the equivalent of a book-like material, then the introduction of role-based variants of the same content doubled the time that the students spent studying. This claim has to be confirmed by studies using larger sample sizes. A strong catalyst for this reported behavior of students is the seamless integration of LLMs in the existing LMSs, thus abstracting away any fears or misconceptions students may be having regarding artificial intelligence. LMSs can still remain the one-stop shops for managing the learning process as discussed in the background section.
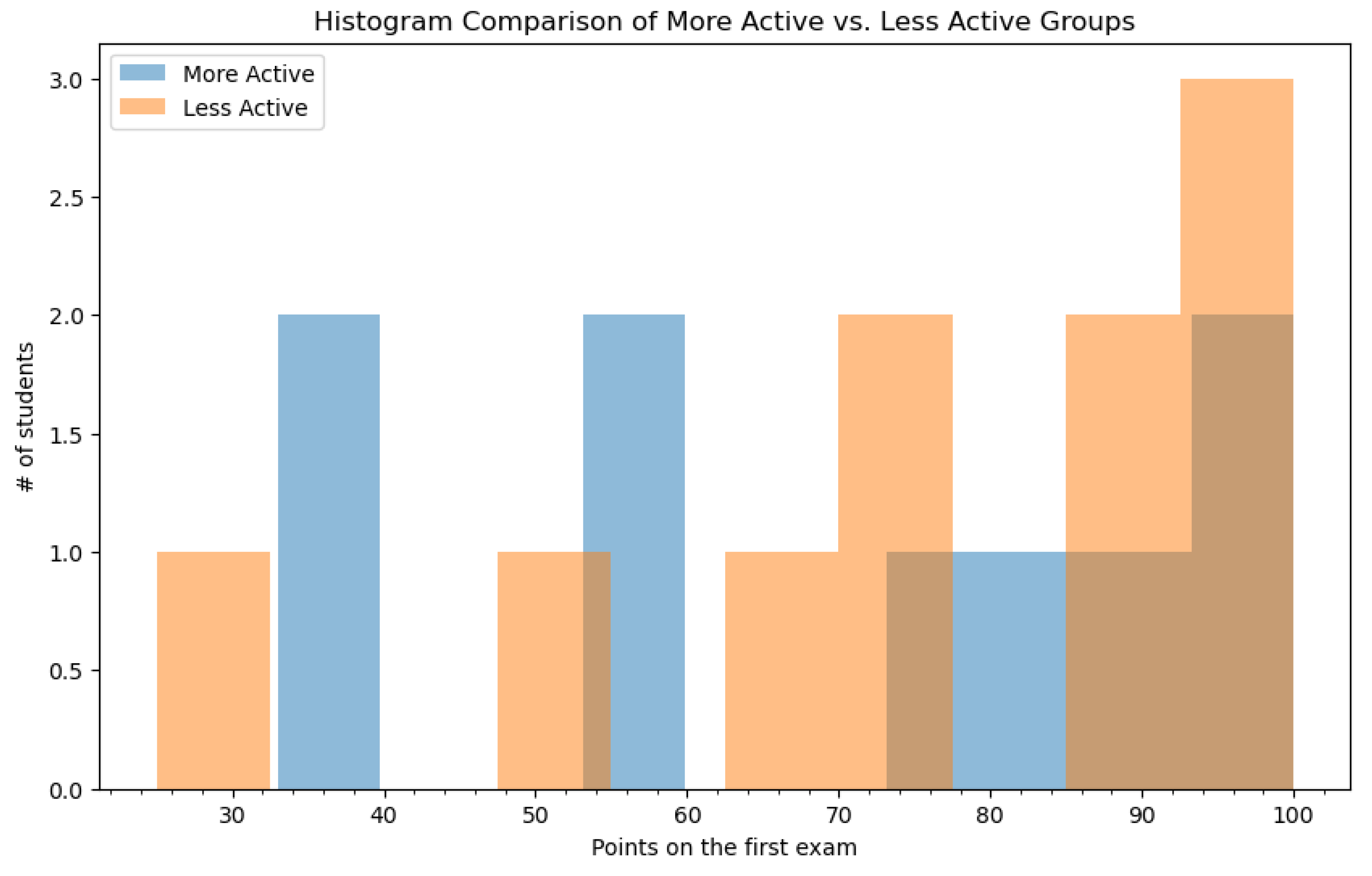
Regarding student achievement,
Figure 5 and
Figure 6 show the distribution of points on exams before and after the introduction of the new feature, after splitting the students into more active and less active groups using the median of the platform time usage as a cutoff. In
Figure 5, we compare the results on the first exam of students who would later belong in either the less active or the more active group, after introducing the AI-generated content variants. We use this approach in order to spot patterns in student achievement and to look for evident changes in student performance before and after introducing the proposed approach for automatic AI generation of learning materials. In
Figure 5, we see that, on the first exam, more students with higher points will later belong to the less active group.
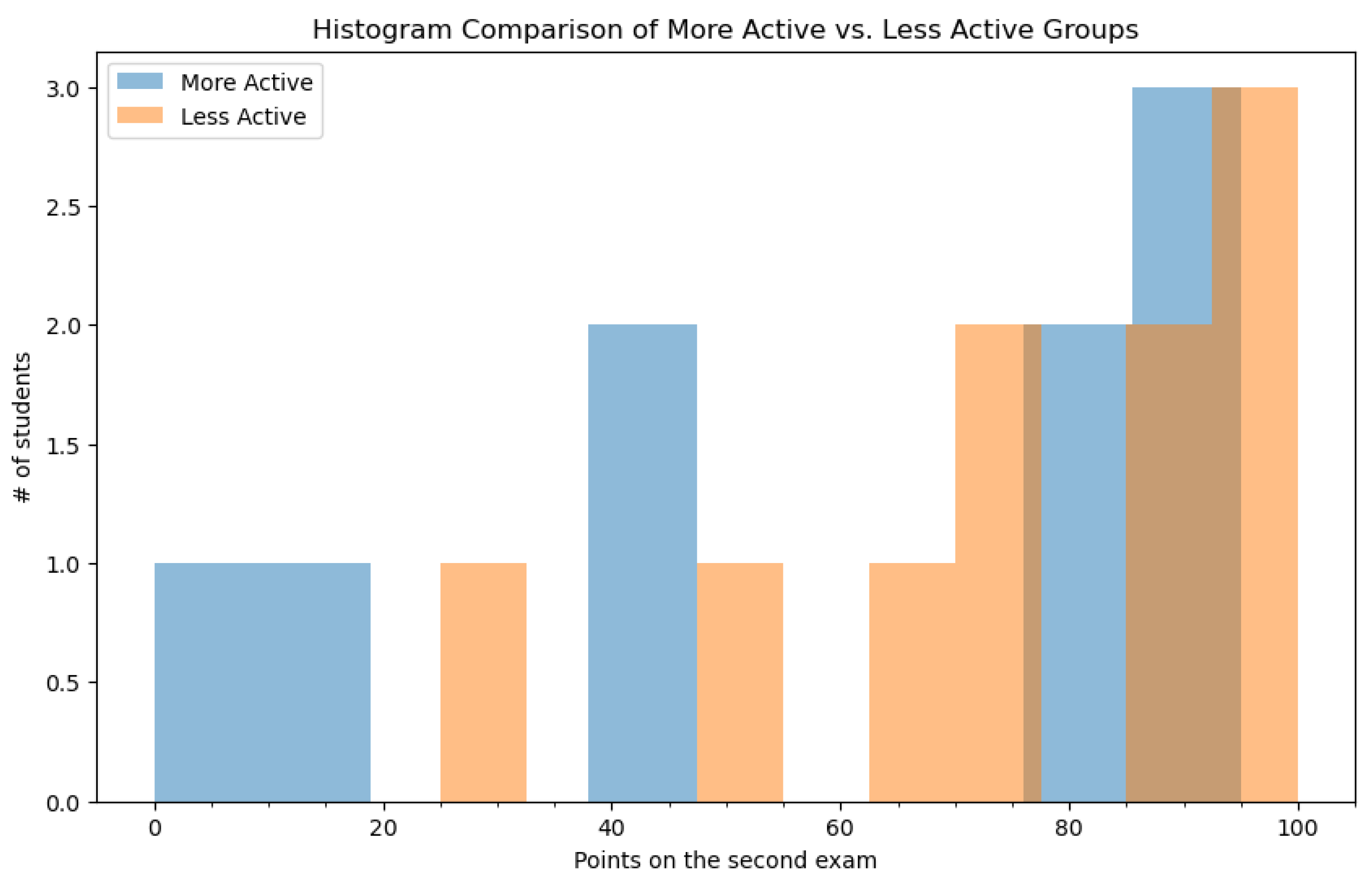
Figure 6 contains the results that students obtained on the second exam, after introducing the proposed approach. The more active and less active groups comprise the same students for reasons previously discussed. The data shown in this figure suggest that there is a slight improvement in points for students belonging to the more active group. The number of students who score over 80 points on the second exam is equal between the two groups in contrast to the first exam. On the other side, there are students from the more active group who scored poorly on the second exam, despite using access to proposed tool.
As justified earlier, the sparse dataset does not allow for bringing strong decisions from quantitative analysis, but the skew toward a greater amount of points for students who spent more time on the character-based AI-generated materials looks promising for further investigation.
4.2. Qualitative Results
For performing the qualitative analysis, we look at the data from the two questionnaires independently, after which we compare the related data on both questionnaires. The data from the first questionnaire mostly consist of Likert-scale-type questions which use three categories, as described in the methodology section. The data do not reveal much since there is only one student who expressed medium satisfaction with the conclusions that role-based teaching positively contributed to the learning experience and made lessons more memorable. All students would recommend this method to a friend, and regarding the preferred variant, five students chose the traditional computer science teacher, four students chose Batman, and one student chose Wednesday Addams. An overview of the preferred versions of both questionnaires is given in
Table 6.
The second questionnaire, sent to students 6 months after subject completion to evaluate the possible long-term effects of the proposed approach, mostly consisted of open-ended questions. After analyzing the answers, five categories were identified where all students belong. The first one is for students who appreciate the quizzes. Out of the 13 students who answered the survey, 4 identified the quizzes as the best part of the AI-generated content since it helped them evaluate their knowledge. The next one is for students who appreciated the characters, where four students identified themselves as advocates because they engaged with the roles. Two students found the platform more effective for accomplishing their learning goals and another two students enjoyed the traditional way better. Only one student expressed skepticism about this approach and questioned the content’s reliability.
Regarding the recommendation preferences, while on the first questionnaire, all students responded that they were likely to recommend the approach to a friend; in the second questionnaire, one student identified as not willing to recommend the carried approach. Probably the most interesting change is noticed in the preferred variant version shown in
Table 6, with students equally divided between fictional characters and the traditional way on the first questionnaire, while six months later, 10 students identified the traditional computer science teacher as their preferred variant, compared to only two students identifying the fictional character style as such.
5. Discussion
5.1. LLMS for Developing Tutoring Personas
The approach suggested in this paper for achieving a sustainable delivery of engaging learning materials to students relies on utilizing generative artificial intelligence for content generation that will seamlessly be integrated into the learning management systems that most educational organizations are already utilizing. The step-by-step instructions for seamlessly inter-operating a given system with OpenAI’s, presented in this paper, contributes toward bridging the gap between cutting-edge artificial intelligence and current educational frameworks [
59,
60]. In the integration process, two primary types of messages facilitate the communication between the OpenAI model and the LMS: system messages and user messages. System messages originate from the LMS, should not be changed by the client, or in our case, the teacher accessing the LMS and it instructs the model how to behave. The user message contains the actual query and can be generated from the inputs provided by the teacher within the LMS, which are then processed by the OpenAI model to generate content. This dual-message communication enables the effortless incorporation of AI-generated materials into the standard operational workflow and expands the current state of available research in educational technology [
63,
64].
The innovative part proposed is that, rather than sole automatic content generation, it can be achieved in different variants in an effort to personalize the experience for each student. By customizing the system’s message to reflect a given user’s choice, the LLM can be tailored to give different results, which is exactly how this study was conducted. One of the main benefits of this proposition is that it is fully automated and does not introduce any additional overheads neither for the teachers nor for the students. In contrast to Morze et al. [
61], whose findings were discussed in the background section, our proposed approach takes the burden off teachers and offers a time-saving and efficient methodology for bringing AI, and especially adaptive learning, to the classroom.
Pop-culture-inspired fictional characters were used in the current iteration of the experiment with content delivered in the style of Batman and Wednesday Addams alongside the traditional teacher style. Customizable lesson creation was already identified as a key driver for advancing improvements of the educational process by multiple researchers outlined in the background section. The reason why there were only three variants offered is the cost of using the OpenAI’s API at the time of performing the experiment. At the moment of writing, this paper, a new developer-friendly pricing opens opportunities to offer the content in many more variants and even make this functionality on an on-demand basis.
The current method utilizes a workaround to obtain the content followed by a JSON-formatted array of questions which requires additional validation on the receiving side to validate the data. In the latest OpenAI API version, there is an option to instruct the model to only communicate using the JSON format using the { “type”: “json_object” } parameter which should further simplify the integration process.
5.2. Student’s Engagement with AI-Tutors
Certain amounts of insightful information came up while performing the analysis. Firstly, the experiment was well received by the students. They actively participated in the process of selecting which characters would be included in the role-based teaching, and all but one answered that they are likely to recommend the role-based teaching approach with AI-generated content to a friend or colleague. Students also responded that they would like to see the proposed method implemented in more classes, which advocates for the effectiveness of the proposed solution. The finding that the introduction of the AI tool was well received by students is again in line with the exploratory experiments from the background section that also reported the good acceptance of novelty approaches in the classroom [
25,
49,
50].
The data from the second questionnaire reveal that students mostly appreciated the automatically generated questions with immediate feedback since, prior to that, they did not have an easy means of checking their knowledge. This is valuable information, especially knowing that the frequent testing of student knowledge has been proven to improve student scores and knowledge in general [
86,
87]. This finding is only drawn from automating assessment in its most primitive form—by offering multiple choice questions. Not only can AI models help students with assessing them this way, but they offer a broader spectrum of possibilities including generating feedback and explanations on open-ended questions, enabling multiple attempts with unique content, as well as providing personalized learning materials in accordance with the students’ activity on the self-assessments. Considering this, the finding is important since it justifies further research in this field and exploring more opportunities and improvements.
A surprising change is observed in the preferred content variant. During the six months between the two surveys, the students’ preference shifted towards the style of the traditional teacher. Although the content of all three variants was completely AI-generated, students on the first questionnaire were divided when preferring either the traditional or fictional option, while six months after subject completion, the traditional way was a clear winner. This is a probable indication that fictional characters are good for short-term engagement and keeping students entertained while learning, while for long-term success, the traditional approach is still the preferred variant.
In the quantitative analysis part, we saw a skew toward a higher amount of points for students who were actively using the part of the LMS with AI-generated content. The students who scored good results on the first exam, before introducing AI-generated variants, did not spend much time on this novel approach to delivering learning materials. Still, the students who actively used it improved the overall score of the group, which leads us to the implication that the different variants of the learning materials are most beneficial for students who have not mastered the topic otherwise. Looking at the amount spent on each variant, it can be noted that the amount of time students spent on reading fictional character-based content is equal to the amount of time spent on reading the traditional format. This can be considered a huge win for the proposed approach, although we do not know whether the students who spent time learning from fictional characters would have spent the time on the traditional variant if the former ones did not exist. Although this finding requires additional validation through studies with bigger sample sizes, it is especially important considering previous research reports about students spending less time reading [
10,
88].
5.3. Limitations
The current study has two main limitations: the small sample size and the fixed amount of available variants, both of which are easily addressable and suitable for future research.
The first one is the sparse dataset and the low amount of students who participated in the experiment. The experiment was performed with only 19 students, which makes drawing clear conclusions difficult and risky. Although the proposed methodology does not have any consequences and risks, as can be seen from the analysis of the current students, a larger population is needed in order to confirm the improvements from using the proposed approach, including the fact that it supports individual instruction, enables self-paced learning and immediate feedback, improves students’ success, increases time spent learning, and makes learning more fun and engaging.
The second limitation is that the number of available variants of learning materials was limited to three. We wonder and are set to explore whether having an unlimited amount of variants will further increase the time that students spend with the learning material. For this, we are working on implementing an on-demand feature for variant creation, where students can access the learning material, ask for it to be presented in a certain way, and obtain the results back automatically and immediately.
6. Conclusions
The educational experience of students varies greatly from school to school, depending on the learning and teaching methodologies adopted by each school. Still, increasing student engagement stands out as the obvious action for improving student success and as a solution to Bloom’s two-sigma problem [
15]. The personalization of the educational journey to meet the needs of each and every student has been identified as the most likely action to help increase student engagement. Still, until recently, achieving a completely personalized learning environment was only conceptualized and difficult to implement in the physical classroom. The introduction of generative artificial intelligence to the general public and its increasing accessibility and affordability offer a way to overcome this obstacle and possibly disrupt the established educational process. In this paper, we suggested and tested an approach with AI-generated content in different variants for achieving personalized learning experiences, which results in several implications for both theory and practice.
6.1. Implications for Theory
The results presented in this study showed no negative implications for students in terms of their access to automatically generated content, and only a positive impact on low-performing students when such access is granted. The availability of different content variants for students, to support them in their learning, was proved to have positive impact on their performance. The suggested approach led to an increase in the students’ learning time, whether it happened out of need or curiosity and with it contributed towards the creation of new pedagogical methods that will drive the education of the future.
One other finding of the current experiment is that the students who used AI-generated content the most were not the best students, but rather the students who would otherwise probably have difficulties with the subject. This inspired us to consider delivering different levels of learning materials to different students. Students who have not fully grasped an adequate comprehension of the material would also benefit, besides from delivering more variants and in different formats, from more thorough and detailed learning materials. On the contrary, for highly proficient students who do not require several versions or methods of distribution to understand the content, an alternative strategy should be contemplated. This involves selecting more precise and even advanced subject matter, regardless of the format or media used. LLMs are well positioned to make this possible by customizing the approach proposed in this experiment to tailor the content for each student or group of students. Undoubtedly, taking these kinds of actions can lead to a future education that is more sustainable, personalized, and engaging.
With the accessibility and the capabilities of AI in the coming years set to grow at a fast pace, this paper contributes toward narrowing the identified gap in research on utilizing large language models in the educational context. Apart from generating only text, new models are able to generate images, illustrations, and even videos, which will open a huge field for further research and improvement. With companies like SoulMachine [
89] already offering the creation of GPT-powered digital people, which are extremely suitable for incorporating in the classroom setting, personalized learning finally seems achievable, while at the same time fighting some of the problems of the current education like teacher shortages [
90], high dropout rates [
91], and inequality in education [
92].
6.2. Implications for Practice
As discussed in the background section when identifying research gaps, one of the main gaps for generative AI adoption in education is the scarcity of empirical studies. Very few studies feature learning material creation using AI and even fewer bring this kind of generated content to the classroom to measure its effectiveness. This study helps fill these gaps with a sophisticated and fully documented approach, from its inception to the evaluation of its results.
The complete steps for reproducing the study and mirroring the API requests to OpenAI’s API were provided in the previous sections, making it fully reproducible. We expect this study to inspire other researchers and decision-makers in educational institutions to consider following our approach and to implement similar features in order to improve the students’ study experience.
As we look forward, our research will expand to examine various mediums of content delivery beyond text-based lessons. The increasing affordability and accessibility of video content generation and text-based LLMs offer fertile ground for extending our research. We aim to explore a broader spectrum of content variants and incorporate more frequent AI-generated knowledge assessments, thereby enriching the educational landscape with innovative and effective learning tools. Additionally, we will adopt the hereby proposed approach to multiple subjects, which will engage more students and will help fight the current limitations in the form of the sparse dataset. These actions will help us to have more precise results, draw better conclusions, and confirm the findings of the current study with greater certainty.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}