2.3.1. CLUE-S Model
The CLUE-S model requires parameterization of the following components: land use requirements (demand), location characteristics, land use type conversion characteristics, and spatial policies and restrictions [
7,
16].
(1) Land Use Requirements (Demand)
The demands of different land use types determine the actual area of each land use type, allocated by the CLUE-S model [
9]. Land use demands are calculated at the aggregate level (the level of the Luanhe River Basin as a whole) as part of a specific scenario, which constrain the simulation by defining the total required change in land use [
6]. In this study, land use requirements of the Luanhe River Basin were calculated by an extrapolation of trends [
6,
14].
(2) Location Characteristics
Location characteristics imply that a series of factors impact the land use change. These factors determine the relative suitability of a location for the different land use types [
6,
14], which are chosen to analyze the probable location of six land use types in this study area.
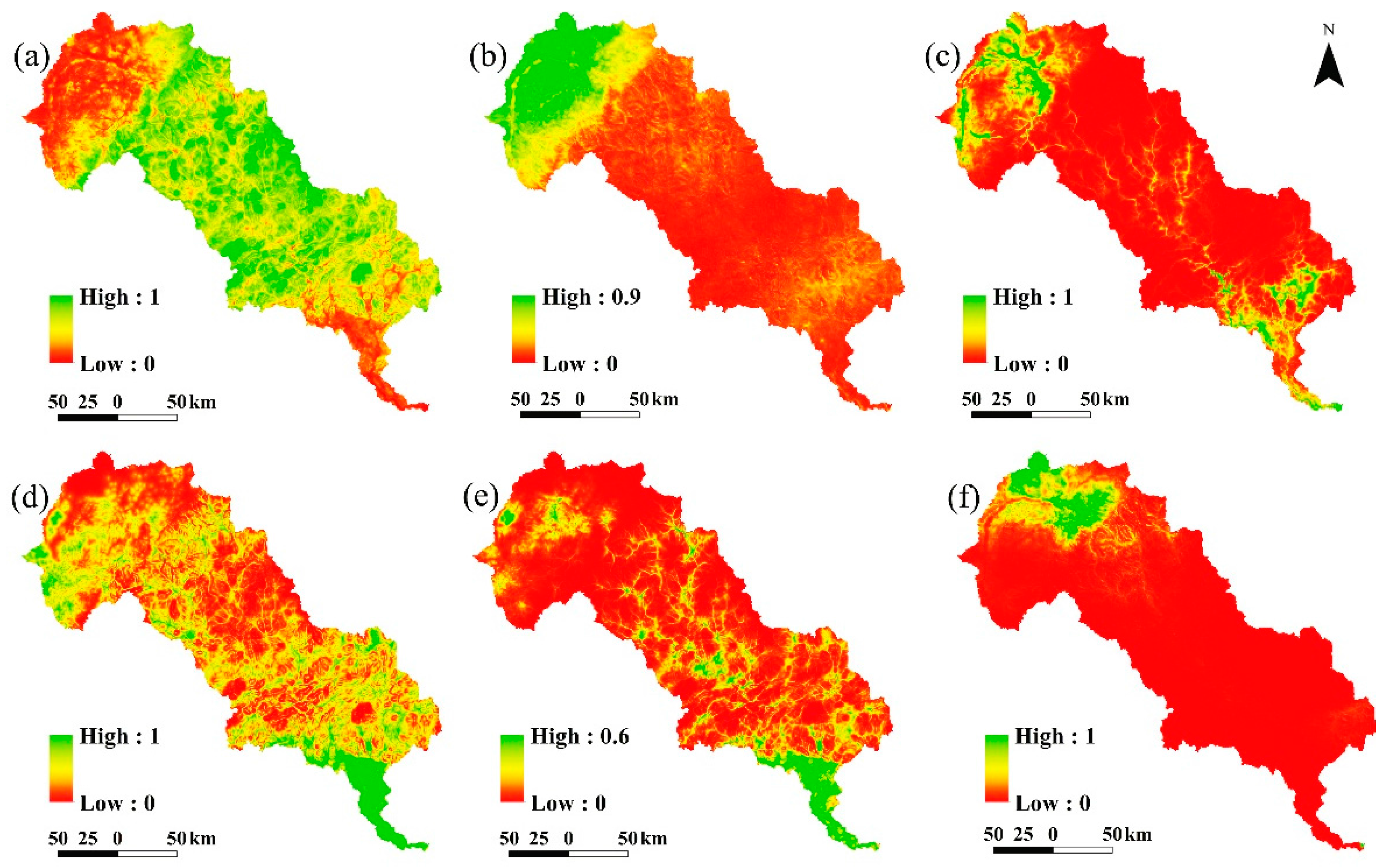
These driving factors can be divided into two categories: bio-physical factors and socio-economic factors, which were used for the analysis in the logistic regression and the CLUE-S model [
7,
19]. In this study, based on related previous researches and the actual situation of the Luanhe River Basin [
8,
9,
14,
20], 19 driving factors were chosen, including 9 bio-physical factors (elevation, slope, aspect, annual mean temperature, annual mean precipitation, solar radiation, soil texture, soil organic matter, and distance to river) and 10 socio-economic factors (population density, GDP, distance to city center, distance to town center, distance to rural settlement, distance to railway, distance to high way, distance to national road, distance to provincial road, and distance to county road). In this study, slope, aspect, and elevation were created from the DEM by ArcGIS 9.3. The above driving factors related to distance were calculated using spatial analysis tools of ArcGIS 9.3 based on the transport vector map of 2009. Annual mean temperature, precipitation and solar radiation are attained by the spatial interpolation of meteorological data from 1970 to 2010. We used SPSS 13.0 to make the collinearity diagnostics to prevent the correlation of driving factors.
Logistic regression is an essential step in the simulation process, which aims to examine the relationships between location factors and different land use types [
4]. The stepwise procedure can help to select the relevant driving factors that are assumed to influence the land use pattern. If variables have no significant contribution to the explanation of land use pattern, they will be excluded from the final regression equation [
7]. In this study, a binary logistic regression model is used to investigate the effects of selected driving factors on the probability of land use transition and to calculate maps of the relative suitability for the different land use types. The logistic regression model [
7] is as follows:
where
Pi is the probability of a grid cell for the occurrence of the considered landuse type
i;
X is the driving factor; β is estimated through logistic regression using the actual land use pattern as a dependent variable. The dependent variable is a binary vector coded as 1 (changed) or 0 (no change) [
19]. Landuse categories and driving factors for each raster cell are determined by ArcGIS 9.3 and transformed into ASCII data, which are further analyzed by binary logistic regression in SPSS 13.0 to determine the relationship between each landuse type and its influence factors [
43]. Finally, the beta values of logistic regression (β), Exp(β) and ROC (relative operating characteristic) can be obtained. Exp(β) values indicate the change in odds upon a one-unit change in the independent variable. When Exp(β) > 1, the probability increases upon an increase in the value of the independent variable; when Exp(β) < 1, the probability decreases [
7,
8]. The Relative Operating Characteristic (ROC) was applied to evaluate the good fit of the logistic regression model [
7]. A ROC value of 0.5 indicates complete randomness and a ROC value of 1 indicates a perfect fit [
6,
44].
(3) Land Use Type Specific Conversion Conditions
Land use types have specific characteristics that influence their conversion and cause the differences in their spatio-temporal behaviors [
9]. Each land use type needs a value to be specified that represents the relative elasticity of change, ranging from 0 (easy conversion) to 1 (irreversible change) [
6]. The conversion elasticity reflects the relative elasticity of change from one land use type to any other land use type in the CLUE-S model [
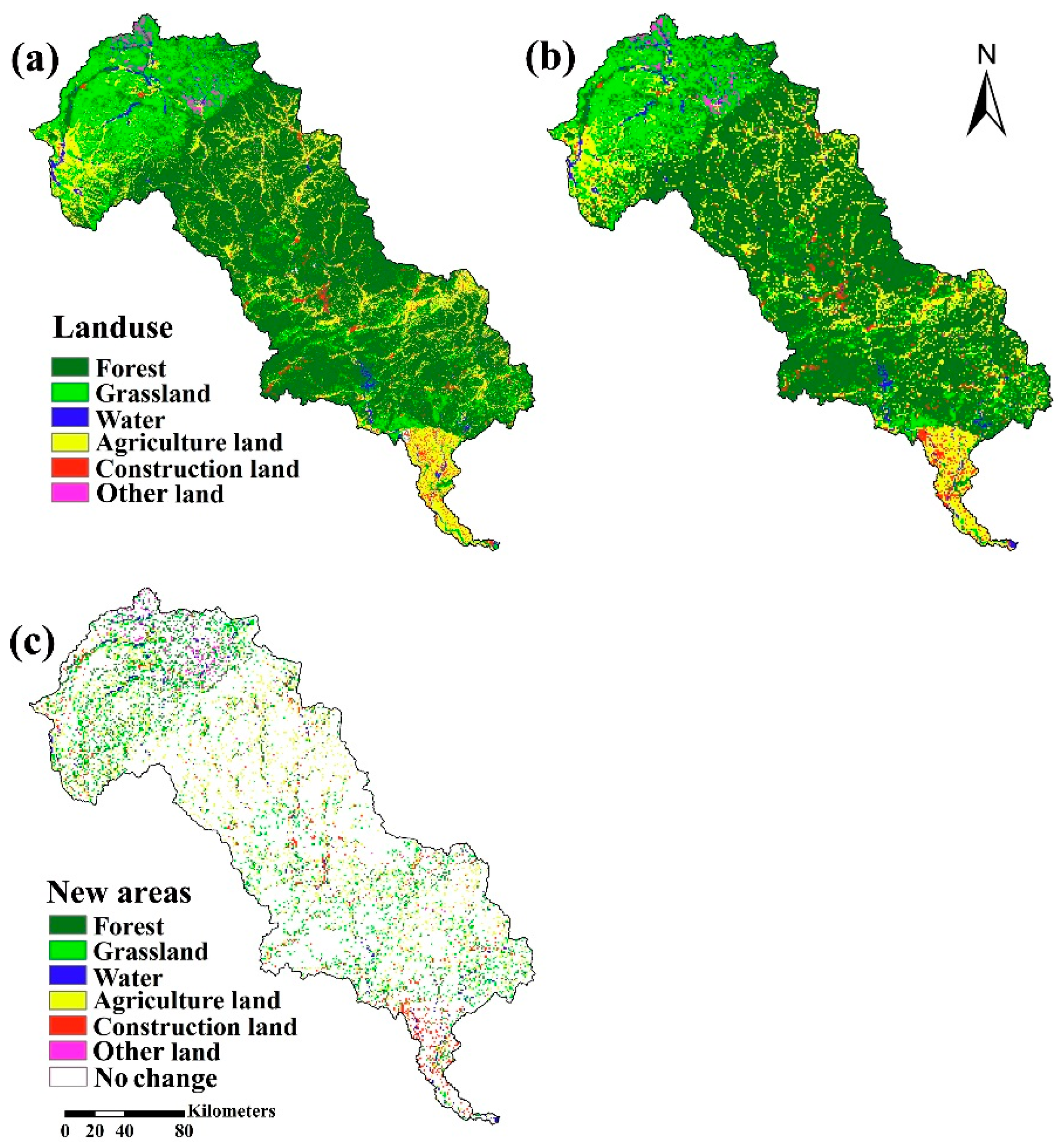
7]. In this study, the conversion elasticity is obtained from the experience of experts and from repeatedly modifying the calibration of the model in order to achieve the optimal simulating effect. Finally, the conversion elasticity values of forest, grassland, water area, agriculture land, construction land and other land are 0.9, 0.2, 0.8, 0.2, 0.9 and 0.9 respectively.
(4) Spatial Policies and Restrictions
The CLUE-S model provides the definition of land use policies and areas restricted from land use conversions [
38]. In this study, based on the actual situation of the Luanhe River Basin, there are no special restriction zones or regions on land conversion within the study area.
(5) Model Validation
Kappa is generally used to evaluate the validity of resulted land use map from the CLUE-S model, which is more reliable than simple percent agreement calculation because it considers chance agreement [
4]. In this study, the simulated land use in 2010 of the Luanhe River Basin that is based on land use in 2000 by the CLUE-S model is compared to land use in 2010. The general equation for
Kappa is as follows:
where
P0 is the observed correct proportion,
Pc is the expected correct proportion due to chance, and
Pp is the correct proportion when classification is perfect [
45]. When
Kappa = 1, the two comparing maps are in complete agreement; when
Kappa > 0.8, the two comparing maps are in strong agreement; when 0.6 <
Kappa < 0.8, the two comparing maps are in high agreement; when 0.4 <
Kappa < 0.6, the two comparing maps are in moderate agreement; and when
Kappa < 0.4, the agreement is poor [
46].
In order to more comprehensively evaluate the validity of simulated land use map, Kstandard (standard kappa), Kno (alternative kappa), Klocation (location kappa), and Kquantity (quantity kappa) were specially developed based on Kappa. A more detailed description of these special Kappa statistics are given by Pontius (2000), which could distinguish between quantification error and location error [
45].
(6) Scenario Assumptions
Regarding the development of future land use, scenarios are envisaged according to the approximation of possible future development plans [
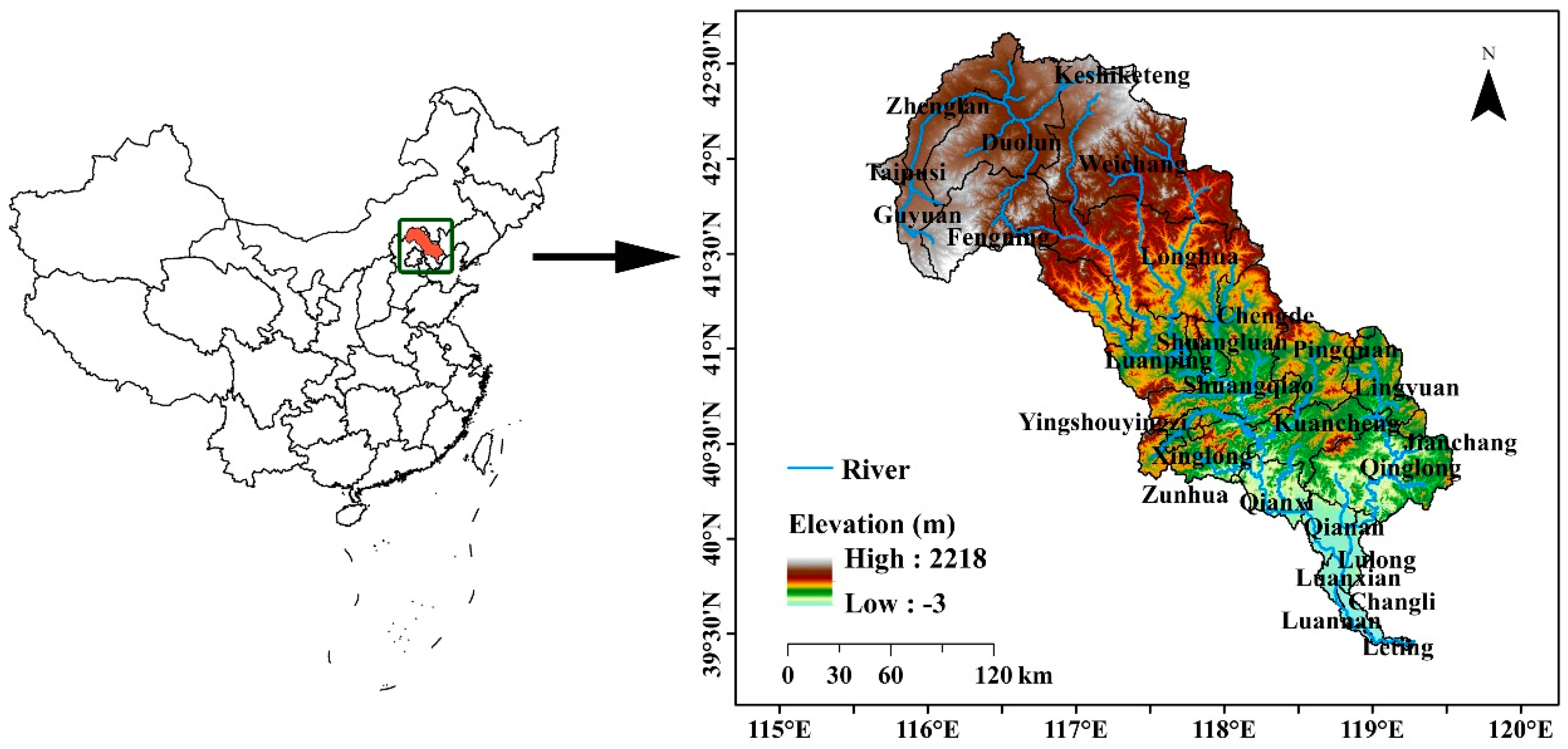
11]. On the one hand, about 82% area of the Luanhe River Basin is located in the northeastern of Hebei Province so that we pay more attention to the future development goals and strategies of “General Land Use Planning in Hebei Province (2006–2020)”. The major goals on the future land use in this study are protecting the cultivated land, effectively controlling the construction land, and increasing the forest coverage rate. On the other hand, “The Sandification Combating Project Phase II for areas in the vicinity of Beijing and Tianjin (2013–2022)” is implemented across the entire basin. The major goal of the project is improving the eco-environment and realizing the sustainable development by returning the grain plots to forestry, afforestation, restoring degenerative grasslands [
47]. In this study, based on land use spatial policies and planning (“General Land Use Planning in Hebei Province (2006–2020)” and “The Sandification Combating Project Phase II for areas in the vicinity of Beijing and Tianjin (2013–2022)”) in the near future, three main predictions regarding the possible development of scenarios for land use types are made about the Luanhe River Basin, spanning the period from 2010 to 2030. In the following, the scenarios used for the land use development are described in more detail.
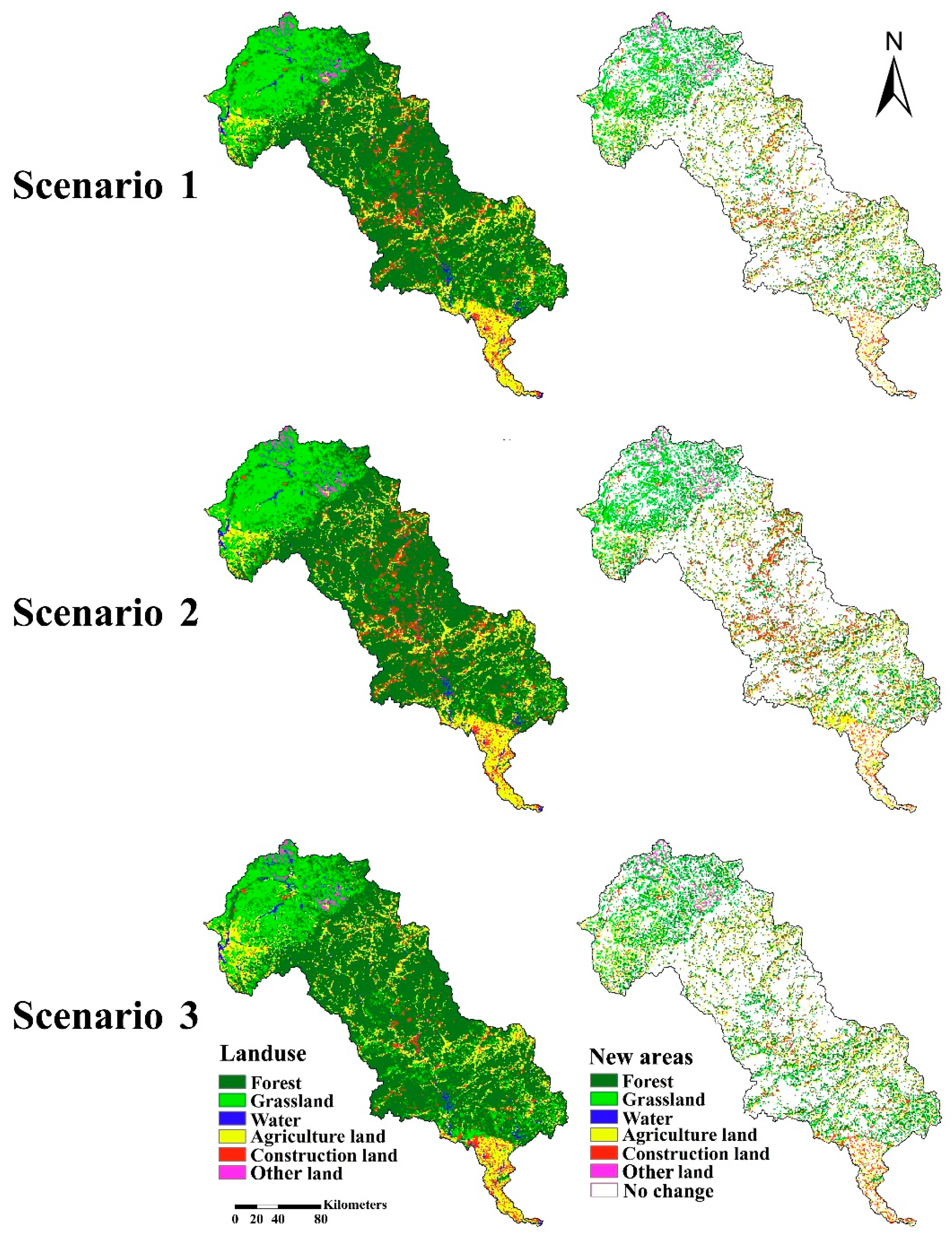
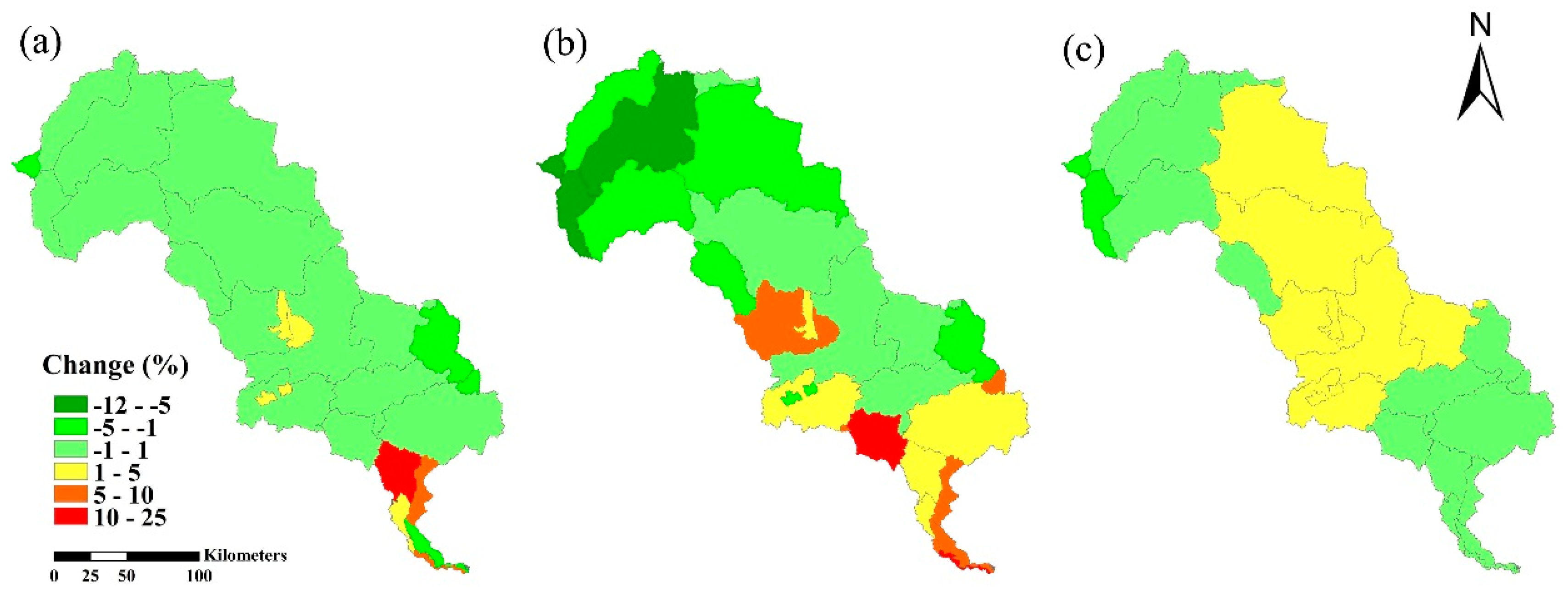
Scenario 1: Trend Scenario
In this scenario, land use demand for the year 2030 is formulated based on the historical statistics of land use change from 2000 and 2010 by a linear interpolation of total area of each land use type. The trends show that the area of forest, grassland and construction land increases slowly by 0.75%, 1.4%, and 25.5%, respectively. On the contrary, the area of other land use types reduces continuously. The area of agriculture land, water and “other land” decreases by 5.8%, 3.5% and 19.5%, respectively. Therefore, assuming this scenario, by 2030, the area of forest, grassland and construction land will have increased by 1.5%, 2.8% and 51%, respectively; the area of agriculture land, water and “other land” will have decreased by 11.6%, 7%, and 39% respectively.
Scenario 2: High Economic Growth
This scenario assumes the economy of the Luanhe River Basin will continue growing at a high speed. This scenario type is characterized by an acceleration of rapid urbanization. By 2030, in this scenario, the area of construction land will have increased by 90%, and forest area will have increased by 1%. In addition, the area of agriculture land, grassland, water and “other land” will have decreased by 15%, 0.5%, 5%, and 40%, respectively.
Scenario 3: Ecological Security
There is an emphasis on the development of higher ecological awareness in the Luanhe River Basin. This implies that the expansion of construction land is slow. The area of forest, by comparison, is growing strongly. The agriculture land is protected, and land use types with high ecosystem service value such as grassland and water area are also protected. By 2030, in this scenario, the area of forest and construction land will have slowly increased by 2% and 10%, respectively. The area of agriculture land, grassland, and water will not have changed significantly. Meanwhile, “other land” area will have decreased by 50%.
2.3.3. Landscape Ecological Risk Index Method
In this research, landscape ecological risk of the Luanhe River Basin is analyzed using the landscape ecological risk index method, which can quantitatively evaluate the spatial and temporal distribution characteristics of landscape ecological risk based on landscape disturbance index and landscape fragility [
48]. A more detailed description of the method is given as follows:
(1) Landscape ecological risk index (ERI)
where
ERIi is the
ith risk area’s ecological risk index,
Aki is the
ith landscape’s area in the
kth region.
Ak is the area of
kth region,
Ei is the landscape disturbance degree index of
ith landscape,
Fi is the fragile index of
ith landscape [
23]. The detailed calculation methods of
Ei and
Fi are given in
Table 2 [
48].
Table 2.
Calculation methods for landscape pattern indices.
Table 2.
Calculation methods for landscape pattern indices.
| Name | Calculation Methods |
|---|
| Landscape Fragmentation Index (Ci) | |
| Landscape Isolation Index (Si) | |
| Landscape Dominance Index (DOi) | |
| Landscape Disturbance Index (Ei) | |
| Landscape Fragility Index (Fi) | other land (0.7), water (0.6), agriculture land (0.5), grassland (0.4), forest land (0.3), and construction land (0.2) [49,50] |
In
Table 2, the weights (
a,
b,
c) of land use landscape indices in four periods (2000, 2010, 2020, and 2030) are obtained by the entropy weight method. This method can resolve the problem of many indices not having unique standard and reduce the disturbance of subjectivity in the assessment process in order to more objectively reflect the contribution of each index to ecological risk of this study area [
51]. According to the entropy weight method, the weights of landscape indices in four periods (2000, 2010, 2020, and 2030) are respectively
a = 0.2711,
b = 0.6445,
c = 0.0844 in 2000;
a = 0.2707,
b = 0.646,
c = 0.0833 in 2010;
a = 0.2911,
b = 0.6183,
c = 0.0906 in 2020; and
a = 0.2923,
b = 0.6182,
c = 0.0895 in 2030.
(2) Sampling Method
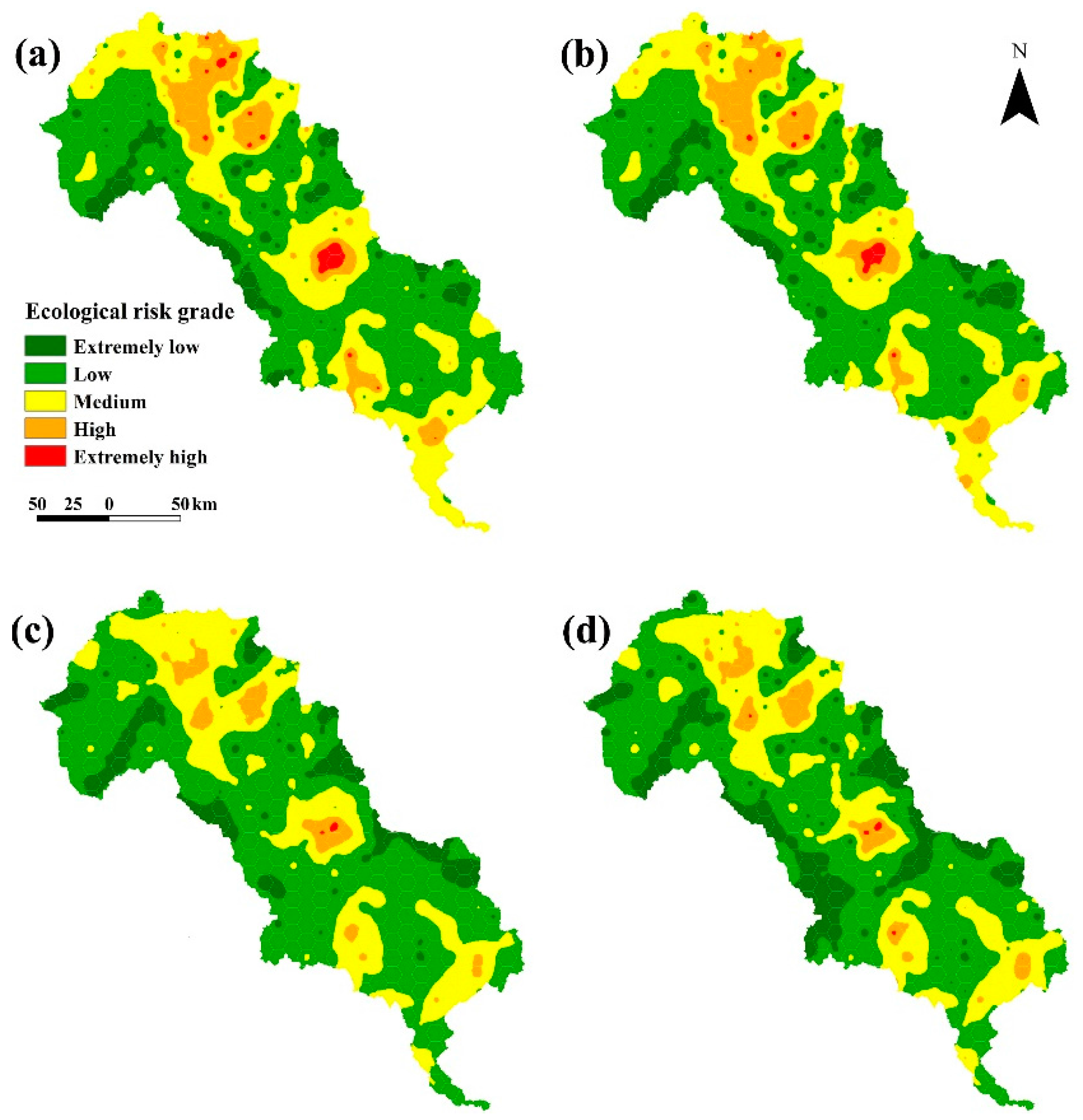
In this study area, according to the scope of the study area and workload, the hexagonal grid sampling method is used to obtain 405 units with an area of 115 km2. Based on the above ERI method, the landscape ecological risk index was calculated for each sampling unit, and the result in each sampling unit was considered the ecological risk value of the central point of the sampling unit.
(3) Spatial Analysis Method
The regional ecological risk index can be analyzed by the geostatistics method to show the law of heterogeneity [
23]. The semivariogram analysis is an essential component of geostatistics, which can describe and identify the spatial structure and is also applied to spatial interpolation (Kriging) [
49]. The equation for Space Analysis [
43] is as follows:
where, γ(
h) is the variation function,
h is the step length, the matching of sampling space distance,
N(
h) is the interval distance of the sample logarithm,
Z(
xi) and
Z(
xi +
h) are the observed values of the ecological risk index on the spatial location of
xi and
x + hi,
i = 1, 2,…,
N(h).
According to the experiences of other studies and ERI values, ecological risk regions were divided into five classifications in the study area: regions with extremely low ecological risk, low ecological risk, moderate ecological risk, high ecological risk and extremely high ecological risk respectively.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



