In this section, the study area and the methodological phases will be described.
2.3. Socioeconomic Classification of the Spanish Peninsular Municipalities
The following classification of municipalities is proposed [
45]. R, which is a programming language and software environment for statistical computing support, was used. Data belonging to the municipality and the districts within it were added to the polygonal graphic entities mentioned (
Table 1). The variables were selected after consulting a wide range of literature on the determination of socioeconomic conditions characterizing the dynamics of various municipalities under study [
46,
47,
48,
49].
This information is public and officially available online. Nonetheless, to avoid outliers, to reduce the dimensionality and so that the obtained classification would be easily interpreted and understood, the following procedures were carried out.
The 11 variables were normalized to obtain similar weight in the socioeconomic classification of municipalities. Then, the relationship or dependence between the variables was analyzed by using Spearman’s rank correlation coefficient (
Table 2). It was found with this coefficient that there was a strong correlation between the numbers of variables: (1) population and market share per capita; (2) industrial average per capita and second homes; (3) market share per capita and industrial average per capita; and (4) population employed in the primary sector and population employed in the secondary sector.
Next, a principal component analysis (PCA) was performed in order to avoid extraneous data, keeping the most relevant information. In this sense, the data are projected onto a lower dimension while retaining most of the data required for the reconstruction of data with an acceptable level. It was found that by using seven components, it was possible to collect 85% of the original variance. This statistical synthesis technique is used to reduce the size, that is the number of variables, losing the least amount of data possible. Thus, the new major derived components are a linear combination of the original variables and are also independent of each other.
After the reduction to seven components, an independent component analysis (ICA) was conducted. In this regard, ICA is a statistical generative model. It is basically a proper probabilistic formulation of the ideas underpinning sparse coding [
54]. To estimate the ICA basis from data, we need to collect samples (patches) from the data to model. The collected patches are used to build a data matrix
X, which is the input to the FastICA [
55] algorithm. In this algorithm, input data are centered first by subtracting the mean of each column of the data matrix
X. The data matrix is then whitened (PCA) by projecting the data onto its principal component directions using a pre-whitening matrix (
K). The number of components (features) to extract is selected a priori. The ICA algorithm then estimates an un-mixing matrix
W, so that
XKW = S, being
S the estimated sources matrix. Using the previous notation,
being the data associated with a previously centered datum, we can obtain the feature vector (
) that characterizes the region of interest as
.
Once the PCA was completed, the correlation between the main components was verified to test their independence. Furthermore, the correlation between the seven components and the eleven original variables (
Table 3) was simultaneously studied.
All municipalities were then classified using seven independent components grouped through the method of self-organizing maps (SOM), like an unsupervised classification. This methodology, used in neural networks to reduce the dimensionality of the data, is highlighted for its ability to represent the most significant vectors [
56]. It also consists of two layers, an input and an output layer, which are interconnected. Thus, each neuron/element in the input layer has a connection with one neuron/element in the output layer. Each connection is in turn linked to a weight. Each output neuron is linked to a weight vector whose components are the connection weights with the neurons of the input layer. These weights are updated during the training process, which is the ultimate goal of learning. The main advantage of SOM is that the data are easily interpreted and understood. The reduction of dimensionality and grid clustering makes it easy to observe similarities in the data. In this sense, SOM is capable of handling several types of classification problems while providing a useful, interactive and intelligible summary of the data. According to [
57], Kohonen stated that, I just wanted an algorithm that would effectively map similar patterns onto contiguous locations in the output space.
Recently, the SOM has been applied in the spatial and social sciences, because of the benefits of SOM, including: exploring the structures and uncovering hidden patterns of large and highly dimensional datasets about socioeconomic characteristics, making no assumptions about the underlying population distribution of the dataset, presenting the visualization of data and the complex entities in an understandable way [
58].
Nonetheless, the major disadvantage of SOM is that it requires necessary and sufficient data in order to develop meaningful clusters. Lack of data or extraneous data will add randomness to the groupings. The ability to determine a good dataset is a deciding factor in determining whether to use an SOM or not [
56,
57]. Precisely in order to avoid extraneous data, previously-described statistical phases were carried out. In addition, after applying these statistics, phases’ dimensionality remained high, and also, a large quantity of data remains. Therefore, SOM was applied in the final phase.
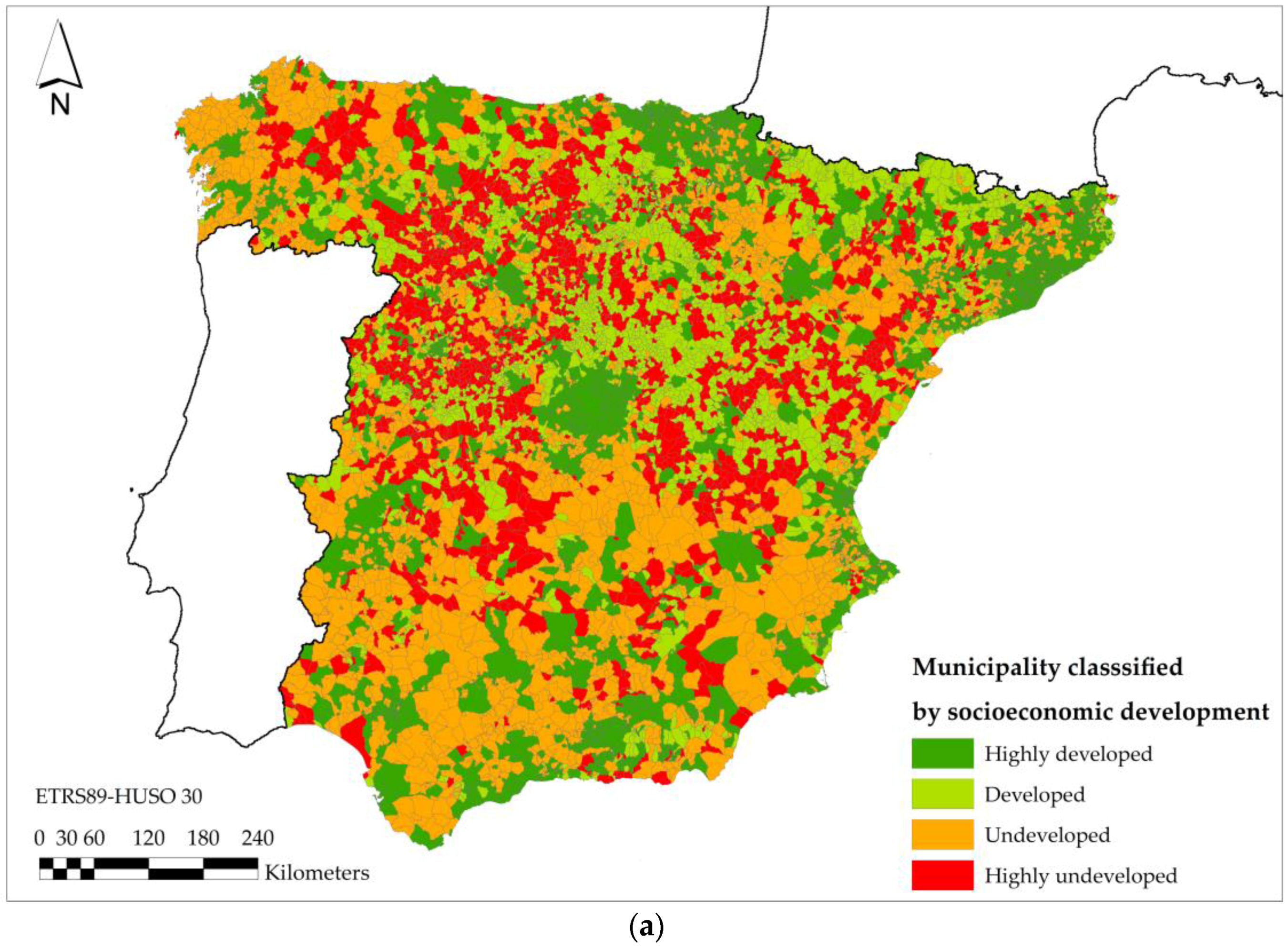
SOM generated four classes, depending on the values representing the original variables in them. They were reclassified according to social cohesion as follows: highly developed, developed, undeveloped and highly undeveloped.
Once the municipalities were classified, they were characterized statistically, by arithmetic mean and standard deviation, in the 11 original variables (
Table 4).
Firstly, the highest values of population (V1), market share per capita (V2), industrial index (V4) and percentage of population employed in the tertiary sector (V10) correspond to Class 1. In addition, this class has the lowest values of the rate of vehicles per capita (V3), unemployment rate (V5), dependency ratio (V6), percentage of population employed in the primary sector (V8) and construction (V11). Therefore, this class contains the municipalities with greater socioeconomic dynamism.
Secondly, Class 2 contains municipalities that have the second highest values of population (V1), market share per capita (V2), industrial index (V4) and percentage of population employed in the tertiary sector (V10). Additionally, they have the second lowest values of the rate of vehicles per capita (V3), unemployment rate (V5), dependency ratio (V6) and percentage of population employed in the primary sector (V8) and construction (V11). Consequently, these municipalities also have a great socioeconomic dynamism, though this is lower than the previous ones.
Thirdly, Class 3 has the highest rate of vehicles per capita (V3), unemployment rate (V5) and percentage of population employed in the secondary sector (V9) and the construction industry (V11). Besides, these municipalities have the lowest rates of market share per capita (V2), industrial average per capita (V4) and percentage of second homes (V7). This class represents municipalities that have based their economies on the conjectural growth of sectors affected by the economic crisis in Spain from 2007. For this reason, this class represents the municipalities that currently have structural deficiencies in employment.
Lastly, Class 4 consists of municipalities with the highest average of dependency ratios (V6), proportion of second homes (V7) and percentage of population employed in the primary sector (V8). However, these municipalities have the lowest populations (V1) and the lowest proportions of people employed in the secondary (V9) and tertiary sectors (V10). Undoubtedly, these municipalities have the greatest demographic and geographic disadvantages in mainland Spain.
2.5. Estimating the Effect of the Potential Accessibility Variation in Social Cohesion
Once the municipalities are classified according to their socioeconomic structures, the difference between future accessibility and current accessibility
is calculated for each municipality. Again, like the classification of municipalities according to their relative levels of accessibility and according to Federal Ministry of Transport, Building and Housing [
73], the municipalities are classified into four classes, (0%–25%, 25%–50%, 50%–75% and 75%–100%). The maximum value of the potential accessibility variation in all calculated municipalities is established as 100% and the minimum as 0%. The value of 50% corresponds to the arithmetic mean value of all of the calculated values. Furthermore, the value of 25% corresponds to the difference between the minimum value (0%) and the arithmetic mean value (50%) divided by two, adding up to the minimum value. The value of 75% corresponds to the difference between the maximum value (100%) and the arithmetic mean value (50%) divided by two added to the arithmetic mean value (
Figure 3). Again, the range of values was divided into four intervals whose length is unequal, since the data are not ideally distributed. These four classes of socioeconomic development are related to the difference between the future accessibility and the current accessibility of each municipality (
Table 6). In this regard, if the increase in relative accessibility is understood to be the development opportunities for residents in the territories: (1) those territories that are less developed should receive the largest increases in accessibility, since a greater social cohesion will be achieved; (2) the opposite should happen in more developed territories. For this reason, it is considered that the potential impact of accessibility in social cohesion is going to be positive, if undeveloped or highly undeveloped municipalities receive accessibility increases greater than the value of the arithmetic mean
obtained in the total group of municipalities analyzed. In the same way, it is considered that the impact is going to be negative, if highly developed or developed municipalities obtain accessibility increases greater than the value of the arithmetic mean
, since they are going to receive better opportunities for development themselves and they may become socioeconomic poles. In addition, depending on the interval of the potential accessibility increase (four classes) for each municipality, the impact could be high, medium or low (
Table 6).
Nonetheless, there is the possibility of reducing the number of combinations in
Table 6; in this sense, if we reduce either the number of classes for the categorization of the socioeconomic development of municipalities or for the categorization of the relative levels of accessibility. In this case, this number of classes was maintained. Thus, a more detailed classification of the municipalities is achieved according to the impact produced by the new infrastructures on social cohesion. This classification is not intended to be either exclusive or excluding. However, it will potentially inform decision-makers, policy-makers and social agents if regions are likely to improve or worsen their social cohesion, even before the construction of new infrastructures.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}