An Explanatory Model Approach for the Spatial Distribution of Free-Floating Carsharing Bookings: A Case-Study of German Cities



Abstract
:1. Introduction
2. Literature Review
3. Description of the Case Study Data
3.1. Booking Data
3.2. Explanatory Variables
- Census data;
- Election behavior;
- Density of points of interest (POI);
- Centrality.
3.2.1. Census Data
- Residents data: % gender, % age (categories), % foreigners;
- Household data: % households with 1, 2, 3 or more children, purchasing power of households in average (index), % single, % yuppies (young urban professionals), % DINKS (double income no kids), rent (per sqm), automobile density, quality of buildings, social class;
- Number of companies: # services, # hotels, # wholesale markets, # clinics, # administrative offices, # retail, # manufacturers, # insurances, # mechanics;
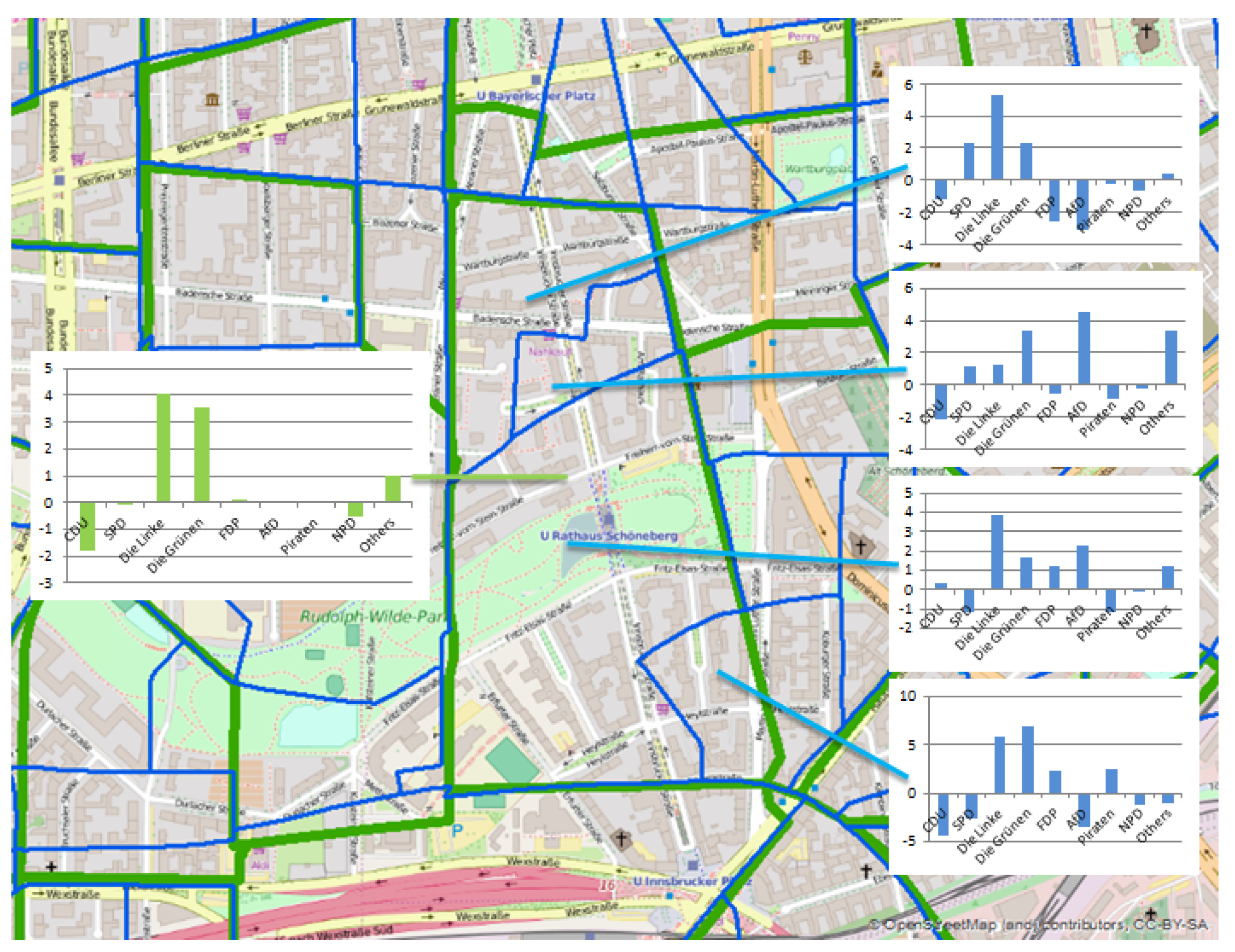
3.2.2. Election Behavior
3.2.3. Density of POIs
3.2.4. Centrality
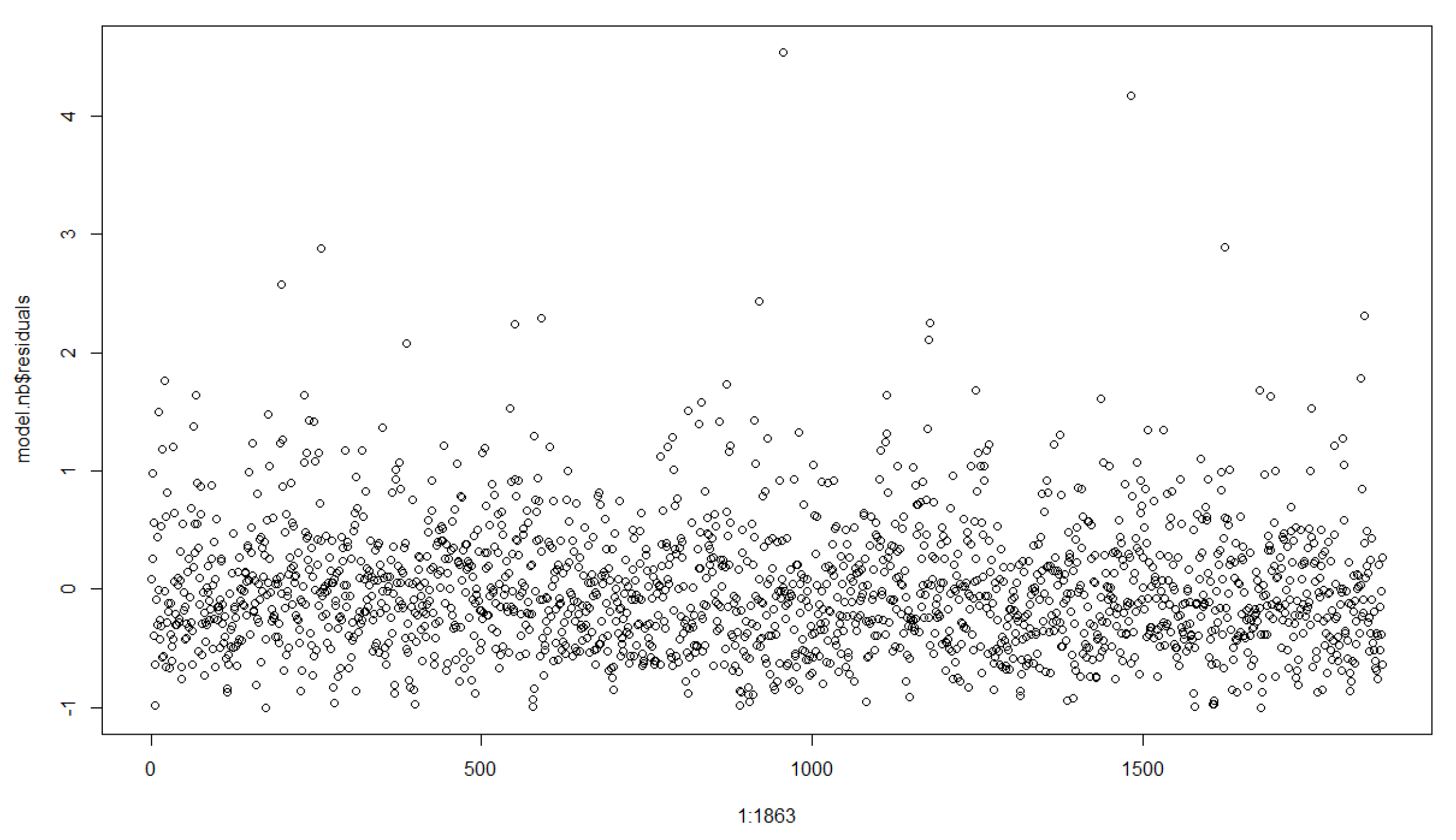
4. Count Data Modeling
| the number of bookings (is the FFCS booking starts from the dataset), | |
| i | the number of the cell of the district grid, |
| p | total number of cells in the district grid (Berlin: 1863), |
| dispersion parameter. |
| values of the explanatory variables in the i-th district, | |
| parameter for the j-th explanatory variable, | |
| j | the number of the explanatory variable, |
| q | the total number of explanatory variables (here: 354). |
5. Results and Interpretation
5.1. Redundancy Check
- population: age distribution: several age groups (∞)
- number of companies: several specifications (∞)
- economy: purchasing power for consumption, for daily goods (∞)
- vehicles: registered vehicles, automobiles, motorcycles, private vehicles (∞)
- households: double income no kids (384.3491), households, yuppies (62.91652), population, affinity for leasing (index) (8.571255)
- election results: CDU (Conservatives), second vote (169.109), Die Grünen (Greens), second vote (22.05291), first vote (10.75966), Die Linke (far-left), second vote (15.70378), NPD (far-right), second vote (13.6863), FDP (Liberals), second vote (8.09295)
5.2. Significance Check
5.3. Interpretation of the Variables’ Effect
- Open-mindedness;
- Type of car user;
- Financial situation;
- Centrality;
- Parking availability;
- Family situation.
5.4. Transfer of the Berlin Model to Munich and Cologne
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AfD | Alternative für Deutschland |
| AIC | Akaike’s Information Criterion |
| API | Application Programming Interface |
| CDU | Christlich Demokratische Union Deutschlands |
| FDP | Freie Demokratische Partei |
| FFCS | free-floating carsharing |
| ICT | information and communication technology |
| NB | negative-binomial |
| NPD | Nationaldemokratische Partei Deutschlands |
| SPD | Sozialdemokratische Partei Deutschlands |
| VIF | variance inflation factor |
| POI | point of interest |
References
- Seign, R. Model-Based Design of Free-Floating Carsharing Systems. Doctoral Thesis, University of the Federal Armed Forces Munich, Neubiberg, Germany, 2015. [Google Scholar]
- Batty, M.; Axhausen, K.W.; Giannotti, F.; Pozdnoukhov, A.; Bazzani, A.; Wachowicz, M.; Ouzounis, G.; Portugali, Y. Smart cities of the future. Eur. Phys. J. Spec. Top. 2012, 214, 481–518. [Google Scholar] [CrossRef]
- Neirotti, P.; De Marco, A.; Cagliano, A.C.; Mangano, G.; Scorrano, F. Current trends in Smart City initiatives: Some stylised facts. Cities 2014, 38, 25–36. [Google Scholar] [CrossRef]
- Chourabi, H.; Nam, T.; Walker, S.; Gil-Garcia, J.R.; Mellouli, S.; Nahon, K.; Pardo, T.A.; Scholl, H.J. Understanding smart cities: An integrative framework. In Proceedings of the IEEE 2012 45th Hawaii International Conference on System Science (HICSS 2012), Maui, HI, USA, 4–7 January 2012; pp. 2289–2297. [Google Scholar]
- Midgley, P. The role of smart bike-sharing systems in urban mobility. Journeys 2009, 2, 23–31. [Google Scholar]
- Benevolo, C.; Dameri, R.P.; D’Auria, B. Smart mobility in smart city. In Empowering Organizations; Springer: Berlin, Germany, 2016; pp. 13–28. [Google Scholar]
- Pinna, F.; Masala, F.; Garau, C. Urban Policies and Mobility Trends in Italian Smart Cities. Sustainability 2017, 9, 494. [Google Scholar] [CrossRef]
- Garau, C.; Masala, F.; Pinna, F. Cagliari and smart urban mobility: Analysis and comparison. Cities 2016, 56, 35–46. [Google Scholar] [CrossRef]
- Brockmeyer, F.; Frohwerk, S.; Weigele, S. Free-Floating-Carsharing: Urbane Mobilitaet im Umbruch-Herausforderungen und Chancen fuer den oeffentlichen Verkehr/Free-Floating-Carsharing: Change of urban mobility. NAHVERKEHR 2014, 32, 13–18. (In German) [Google Scholar]
- Lenz, B.; Bogenberger, K. WiMobil—Wirkung von E-CarSharing-Systemen auf Mobilität und Umwelt in Urbanen Räumen. Halbzeitkonferenz zur Nutzung von E-Carsharing-Systemen am Beispiel von car2go, DriveNow und Flinkster, 2014. Available online: http://www.erneuerbar-mobil.de/sites/default/files/2016-10/Abschlussbericht_WiMobil.pdf (accessed on 17 June 2017).
- Rat für nachhaltige Entwicklung. Nutzt Carsharing? Warum zwei Studien zu Unterschiedlichen Ergebnissen Kommen; Rat für nachhaltige Entwicklung: Berlin, Germany, 2015. (In German) [Google Scholar]
- Wagner, S.; Brandt, T.; Neumann, D. Data analytics in free-floating carsharing: Evidence from the city of Berlin. In Proceedings of the IEEE 2015 48th Hawaii International Conference on System Sciences (HICSS 2015), Grand Hyatt, HI, USA, 5–8 January 2015; pp. 897–907. [Google Scholar]
- Kortum, K.; Machemehl, R.B. Free-Floating Carsharing Systems: Innovations in Membership Prediction, Mode Share, and Vehicle Allocation Optimization Methodologies; Technical report; Southwest Region University Transportation Center, Center for Transportation Research, University of Texas at Austin: Austin, TX, USA, 2012. [Google Scholar]
- De Lorimier, A.; El-Geneidy, A.M. Understanding the factors affecting vehicle usage and availability in carsharing networks: A case study of Communauto carsharing system from Montréal, Canada. Int. J. Sustain. Transp. 2013, 7, 35–51. [Google Scholar] [CrossRef]
- Kang, J.; Hwang, K.; Park, S. Finding Factors that Influence Carsharing Usage: Case Study in Seoul. Sustainability 2016, 8, 709. [Google Scholar] [CrossRef]
- Cervero, R. City CarShare: First-year travel demand impacts. Transp. Res. Rec. J. Transp. Res. Board 2003, 1839, 159–166. [Google Scholar] [CrossRef]
- Cervero, R.; Tsai, Y. San Francisco City CarShare: Second-Year Travel Demand and Car Ownership Impacts. In Proceedings of the Transportation Research Board 2004 Annual Meeting, Washington, DC, USA, 12–16 January 2003. [Google Scholar]
- Morency, C.; Habib, K.M.N.; Grasset, V.; Islam, M.T. Understanding members’ carsharing (activity) persistency by using econometric model. J. Adv. Transp. 2012, 46, 26–38. [Google Scholar] [CrossRef]
- Kawgan-Kagan, I. Early adopters of carsharing with and without BEVs with respect to gender preferences. Eur. Transp. Res. Rev. 2015, 7, 33. [Google Scholar] [CrossRef]
- Celsor, C.; Millard-Ball, A. Where does carsharing work?: Using geographic information systems to assess market potential. Transp. Res. Rec. J. Transp. Res. Board 2007, 1992, 61–69. [Google Scholar] [CrossRef]
- Stillwater, T.; Mokhtarian, P.L.; Shaheen, S. Carsharing and the Built Environment: A GIS-Based Study of One US Operator; UC Davis: Davis, CA, USA, 2008. [Google Scholar]
- Hinkeldein, D.; Schoenduwe, R.; Graff, A.; Hoffmann, C. Who Would Use Integrated Sustainable Mobility Services–And Why? In Sustainable Urban Transport; Emerald Group Publishing Limited: Bingley, UK, 2015; pp. 177–203. [Google Scholar]
- Jorge, D.; Correia, G. Carsharing systems demand estimation and defined operations: A literature review. Eur. J. Transp. Infrastruct. Res. 2013, 13, 201–220. [Google Scholar]
- De Almeida Correia, G.H.; de Abreu e Silva, J.; Viegas, J.M. Using latent attitudinal variables estimated through a structural equations model for understanding carpooling propensity. Transp. Plan. Technol. 2013, 36, 499–519. [Google Scholar] [CrossRef]
- Barnett, E.; Halverson, J. Local increases in coronary heart disease mortality among blacks and whites in the United States, 1985–1995. Am. J. Public Health 2001, 91, 1499–1506. [Google Scholar] [CrossRef] [PubMed]
- Schmöller, S.; Weikl, S.; Müller, J.; Bogenberger, K. Empirical analysis of free-floating carsharing usage: The Munich and Berlin case. Transp. Res. Part C Emerg. Technol. 2015, 56, 34–51. [Google Scholar] [CrossRef]
- O’brien, R.M. A caution regarding rules of thumb for variance inflation factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- McFadden, D. Conditional Logit Analysis of Qualitative Choice Behavior in Frontiers in Econometrics; Academic Press: Cambridge, MA, USA, 1974; pp. 105–142. [Google Scholar]
- Beck, M. Collinearity and Stepwise VIF Selection. Available online: https://beckmw.wordpress.com/2013/02/05/collinearity-and-stepwise-vif-selection/ (accessed on 15 April 2016).
- Lee, D. A comparison of choice-based landscape preference models between british and korean visitors to national parks. Life Sci. J. 2013, 10, 2028–2036. [Google Scholar]
- Mueller, J.; Schmoeller, S.; Giesel, F. Identifying Users and Use of (Electric-) Free-Floating Carsharing in Berlin and Munich. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems (ITSC 2015), Canary Islands, Spain, 15–18 September 2015; pp. 2568–2573. [Google Scholar]
- Jorge, D.; Correia, G.H.; Barnhart, C. Comparing optimal relocation operations with simulated relocation policies in one-way carsharing systems. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1667–1675. [Google Scholar] [CrossRef]
- Jorge, D.; Barnhart, C.; de Almeida Correia, G.H. Assessing the viability of enabling a round-trip carsharing system to accept one-way trips: Application to Logan Airport in Boston. Transp. Res. Part C Emerg. Technol. 2015, 56, 359–372. [Google Scholar] [CrossRef]
- De Almeida Correia, G.H.; Antunes, A.P. Optimization approach to depot location and trip selection in one-way carsharing systems. Transp. Res. Part E Logist. Transp. Rev. 2012, 48, 233–247. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Estimate | Std. Error | Significance |
|---|---|---|---|
| Intercept | 8.92 | 2.70 | *** |
| Census | |||
| population, percentage, foreigners | −4.212 × 10 | 1.574 × 10 | ** |
| household size, average | 4.981 × 10 | 1.609 × 10 | ** |
| population, density (per sqkm) | −2.977 × 10 | 2.117 × 10 | *** |
| population, percentage, 03–05 years | −2.294 × 10 | 6.804 × 10 | *** |
| population, percentage, 10–14 years | 1.205 × 10 | 4.465 × 10 | ** |
| # companies: retail, medium | 3.254 × 10 | 1.453 × 10 | * |
| # companies: hotels, big | −3.681 × 10 | 1.756 × 10 | * |
| # companies: density (per sqkm) | 5.676 × 10 | 2.818 × 10 | * |
| # companies: insurances, big | 3.126 × 10 | 1.367 × 10 | * |
| buildings, percentage, poor quality | −4.604 × 10 | 1.007 × 10 | *** |
| buildings, percentage, very high quality | −2.879 × 10 | 8.699 × 10 | *** |
| # buildings | −2.063 × 10 | 7.436 × 10 | ** |
| households, percentage, >=3 persons | −2.956 × 10 | 7.228 × 10 | *** |
| # households, net income: 900–1500 EUR | 5.914 × 10 | 6.555 × 10 | *** |
| # households, characteristic: down-to-earth | −7.626 × 10 | 2.503 × 10 | ** |
| households, social class: low | −2.869 × 10 | 9.675 × 10 | ** |
| registered vehicles, index | −4.778 × 10 | 8.988 × 10 | *** |
| population, profit-oriented, index | −6.026 × 10 | 2.672 × 10 | * |
| population, telecommunication type: analogous | −1.007 × 10 | 4.890 × 10 | * |
| rent | 1.377 × 10 | 2.158 × 10 | *** |
| automobiles, percentage, private | −3.374 × 10 | 1.720 × 10 | * |
| street length | 2.400 × 10 | 1.943 × 10 | *** |
| district size | 2.979 × 10 | 1.266 × 10 | * |
| Election | |||
| SPD (socialists), 2nd vote | −2.807 × 10 | 9.913 × 10 | ** |
| Piratenpartei (Pirates), 1st vote | −5.645 × 10 | 2.219 × 10 | * |
| Piratenpartei (Pirates), 2nd vote | 5.311 × 10 | 1.943 × 10 | ** |
| NPD (far-right), 1st vote | −2.043 × 10 | 3.856 × 10 | *** |
| POI | |||
| Bars | 2.895 × 10 | 9.387 × 10 | ** |
| Centrality | |||
| Distance to the city center | −1.036 × 10 | 1.563 × 10 | *** |
| Model I (95 % significant, non-redundant variables) | |||
| Null deviance: 6057.5 on 1862 degrees of freedom | |||
| Residual deviance: 1979.5 on 1833 degrees of freedom | |||
| AIC: 27,328 | |||
| Theta: 3.0955 | |||
| Std. Err.: 0.0980 | |||
| McFadden: 0.07701861 | |||
| Model II (99.9 % significant, non-redundant variables) | |||
| Null deviance: 5350.8 on 1862 degrees of freedom | |||
| Residual deviance: 1988.4 on 1851 degrees of freedom | |||
| AIC: 27,545 | |||
| Theta: 2.7314 | |||
| Std. Err.: 0.0858 | |||
| McFadden 0.06846484 | |||
| Variable Name | Estimate | Std. Error | Significance |
|---|---|---|---|
| Intercept | 2.439 | 1.809 | |
| Census | |||
| household size, average | −1.057 | 3.952 × 10 | ** |
| population, density (per sqkm) | −3.052 × 10 | 2.168 × 10 | *** |
| population, percentage, 00–14 years | 2.063 × 10 | 9.289 × 10 | * |
| population, percentage, 06–09 years | −4.411 × 10 | 1.447 × 10 | ** |
| population, percentage, 25–29 years | −1.517 × 10 | 7.317 × 10 | * |
| population, percentage, 25–49 years | 1.694 × 10 | 6.931 × 10 | * |
| population, percentage, 35–39 years | −3.386 × 10 | 8.212 × 10 | *** |
| population, percentage, 40–44 years | −3.635 × 10 | 1.107 × 10 | ** |
| # companies: government agencies, big | −3.566 × 10 | 1.555 × 10 | * |
| # companies, density (per sqkm) | 5.850 × 10 | 2.951 × 10 | * |
| buildings, absolute | −1.699 × 10 | 8.526 × 10 | * |
| households, percentage, 1 person | 3.800 × 10 | 1.209 × 10 | ** |
| households, percentage, 2 persons | 4.744 × 10 | 1.832 × 10 | ** |
| # households, characteristic: active middle class | 4.266 × 10 | 1.999 × 10 | * |
| vehicles, density, index | −3.246 × 10 | 9.370 × 10 | *** |
| liquid purchasing power, per person | −4.581 × 10 | 1.979 × 10 | * |
| decisive criteria for purchasing: brand, as index | 6.431 × 10 | 2.677 × 10 | * |
| population, affinity to environment, index | 5.675 × 10 | 2.009 × 10 | ** |
| automobiles, density per inhabitant | −2.075 × 10 | 8.051 × 10 | ** |
| automobiles, percentage, commercial | 3.794 × 10 | 1.717 × 10 | * |
| Distance: airport | 1.796 × 10 | 6.665 × 10 | ** |
| Distance: long-distance train station | −4.689 × 10 | 1.649 × 10 | ** |
| Distance: motorway | −2.939 × 10 | 1.377 × 10 | * |
| street length | 2.767 × 10 | 2.075 × 10 | *** |
| district area | 3.602 × 10 | 1.351 × 10 | ** |
| Election | |||
| CDU (Conservatives), 2nd vote | 6.598 × 10 | 2.116 × 10 | ** |
| SPD (Socialist), 1st vote | 2.708 × 10 | 9.623 × 10 | ** |
| FDP (Liberals), 2nd vote | 1.568 × 10 | 2.808 × 10 | *** |
| Die Gruenen (Greens), 2nd vote | 8.129 × 10 | 1.791 × 10 | *** |
| Piratenpartei (Pirates), 1st vote | 7.201 × 10 | 2.072 × 10 | *** |
| Piratenpartei (Pirates), 2nd vote | 7.835 × 10 | 2.756 × 10 | ** |
| AfD (right-populists), 1st vote | 1.142 × 10 | 3.915 × 10 | ** |
| NPD (far-right), 1st vote | −1.594 × 10 | 8.038 × 10 | * |
| POI | |||
| Bars | 2.241 × 10 | 9.731 × 10 | * |
| Centrality | |||
| Distance to the city center | −9.840 × 10 | 1.923 × 10 | *** |
| Model III (95% significant variables) | |||
| Null deviance: 5664.6 on 1862 degrees of freedom | |||
| Residual deviance: 1984.1 on 1827 degrees of freedom | |||
| AIC: 27,477 | |||
| Theta: 2.8930 | |||
| Std. Err.: 0.0912 | |||
| McFadden 0.07240754 | |||
| −4 | −3 | −2 | −1 | 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|---|---|---|---|
| Berlin | 0.00 | 0.82 | 5.83 | 21.41 | 45.48 | 18.74 | 6.54 | 1.09 | 0.11 |
| Munich | 2.11 | 4.02 | 8.85 | 17.30 | 31.29 | 21.23 | 10.97 | 3.72 | 0.50 |
| Cologne | 0.16 | 1.63 | 7.48 | 20.00 | 37.24 | 20.81 | 9.43 | 2.60 | 0.65 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Müller, J.; Correia, G.H.d.A.; Bogenberger, K. An Explanatory Model Approach for the Spatial Distribution of Free-Floating Carsharing Bookings: A Case-Study of German Cities. Sustainability 2017, 9, 1290. https://doi.org/10.3390/su9071290
Müller J, Correia GHdA, Bogenberger K. An Explanatory Model Approach for the Spatial Distribution of Free-Floating Carsharing Bookings: A Case-Study of German Cities. Sustainability. 2017; 9(7):1290. https://doi.org/10.3390/su9071290
Chicago/Turabian StyleMüller, Johannes, Gonçalo Homem de Almeida Correia, and Klaus Bogenberger. 2017. "An Explanatory Model Approach for the Spatial Distribution of Free-Floating Carsharing Bookings: A Case-Study of German Cities" Sustainability 9, no. 7: 1290. https://doi.org/10.3390/su9071290
APA StyleMüller, J., Correia, G. H. d. A., & Bogenberger, K. (2017). An Explanatory Model Approach for the Spatial Distribution of Free-Floating Carsharing Bookings: A Case-Study of German Cities. Sustainability, 9(7), 1290. https://doi.org/10.3390/su9071290