1. Introduction
The interpretation of synthetic aperture radar (SAR) images has important meanings for both civilian and military applications [
1,
2,
3,
4,
5]. SAR images are interpreted for sea ice monitoring and classification in [
2]. Gao et al. examined the change detection in SAR images based on deep learning [
3]. Bai et al. analyzed SAR images to map earthquake-induced damages [
4] and recognized regional tsunami damages [
5] using machine learning techniques. This study focused on the automatic target recognition (ATR) of SAR images [
1], which aims to determine the target type of an SAR image with unknown label by matching the information in the input SAR image with that in the training samples. Generally, the information can be divided into three categories: discriminative information, confusing information and redundant information [
6,
7]. The discriminative information indicates the portion shared by the same target class and different from other classes. The confusing information often varies in the same class or shares much resemblance with other targets. The redundant information only contains redundancy and has little meanings from the aspect of target recognition. Therefore, to improve the SAR ATR performance, the discriminative information in SAR images should be fully exploited. Meanwhile, the confusing and redundant information must be suppressed.
After preprocessing steps such as clutter rejection and denoising [
8,
9], a typical SAR image of a ground target can be divided into three components: target region, shadow and background [
10]. The target region describes the electromagnetic scattering characteristics of the target. The shadow reflects the target’s geometrical information such as physical sizes and shape. The background pixels represent the responses of the background. Therefore, the background mainly contains the redundant information, which has little meanings from the aspect of target recognition. Both target region and shadow contain discriminative information. They also contain some confusing information because of the similarity shared by different targets. To improve the ATR performance, the discriminative information should be decoupled for matching. There are two typical methods to decouple the discriminative information in literatures: image segmentation and feature extraction. In image segmentation, some methods [
11,
12,
13,
14,
15] conduct target segmentation first, and only the target region is used for target recognition. The operation indeed eliminates most of the redundant information (background) and confusing information in the shadow. However, the discriminative information in the shadow is also neglected. Moreover, SAR target segmentation remains difficult problem because of the unclear target contour in SAR images [
10,
11]. Therefore, the target segmentation may also lose some discriminative information in the original target region because of possible segmentation errors. Some researchers use the shadow [
16,
17] for target recognition. Although they have achieved good results, the discriminability of shadow is assumed to be notably limited particularly with the increase of candidate targets [
18]. In feature extraction, various kinds of features [
19,
20,
21,
22,
23,
24,
25,
26,
27] have been applied to SAR images including geometrical features, projection features and scattering center features. Typical geometrical features are physical sizes [
11], shape [
13,
14,
15], target contour [
16], etc. They intuitively describe the targets and are discriminative for target recognition. The projection features can be efficiently extracted by multiplying the original image with a projection matrix. The principle component analysis (PCA) [
19], non-negative matrix factorization (NMF) [
20], random projection [
21], etc. are notably effective to reduce the high dimensionality of original SAR images while retaining the discriminative information for target recognition. The scattering center features reflect the electromagnetic scattering characteristics of the target. Because of the rich physically relevant descriptions, the attributed scattering centers have been effectively used for SAR ATR [
25,
26,
27,
28,
29]. However, most of these features aim to reduce the redundancy in the original SAR images and can hardly reduce the confusing information.
An SAR ATR method is proposed to exploit the discriminative information in SAR images based on information-decoupled representations in this study. As stated above, the discriminative information is contained in the target region and shadow. Under standard operating condition (SOC) [
1], where the test images are captured under similar conditions with the training samples, both target region and shadow contain discriminative information and tend to form consistent decisions. Hence, the joint use of the two components will contribute to better recognition results. However, under some extended operating conditions (EOCs) [
1], the target region or shadow may be corrupted. Then, the corrupted part should not be used or weighted less in the recognition. Under these conditions, the image segmentation is preferred to thoroughly remove the confusing part (target region or shadow).
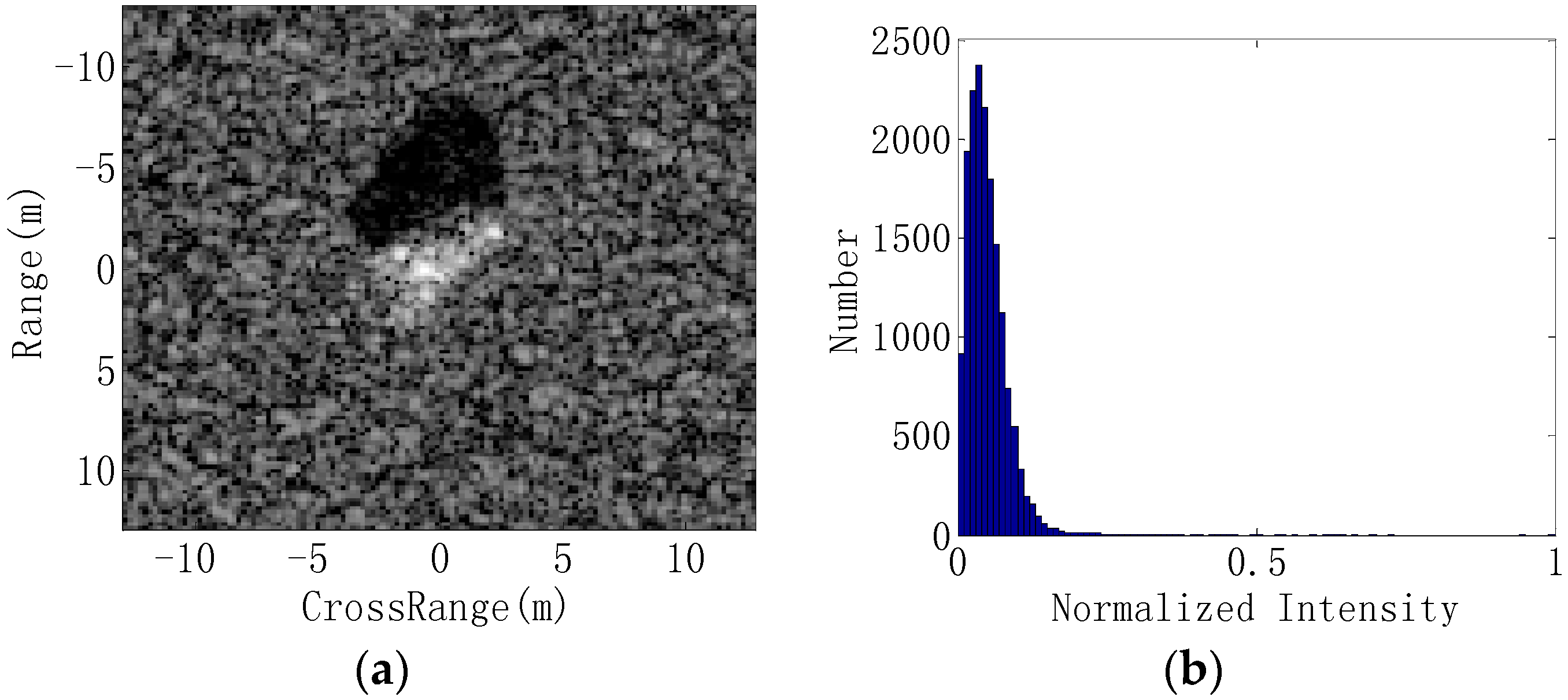
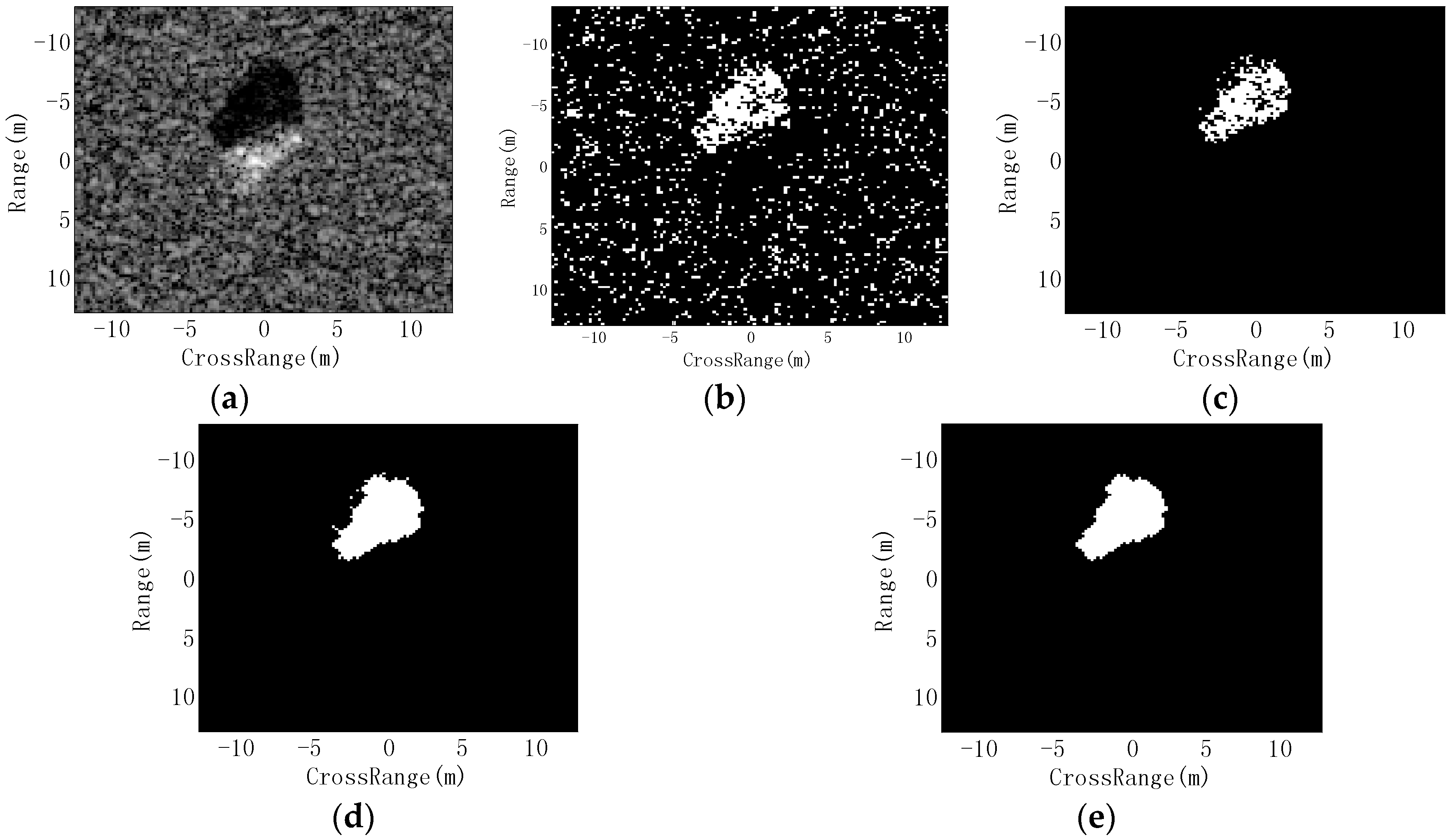
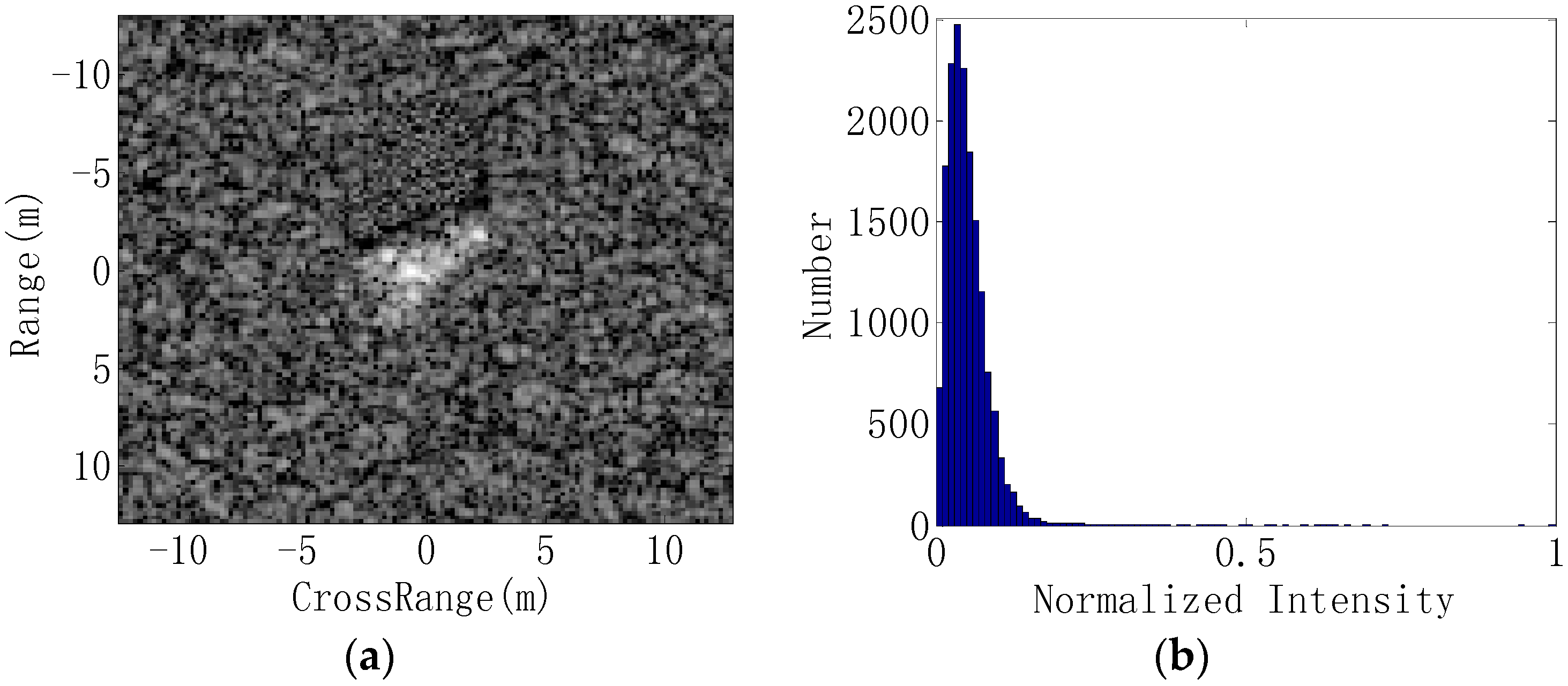
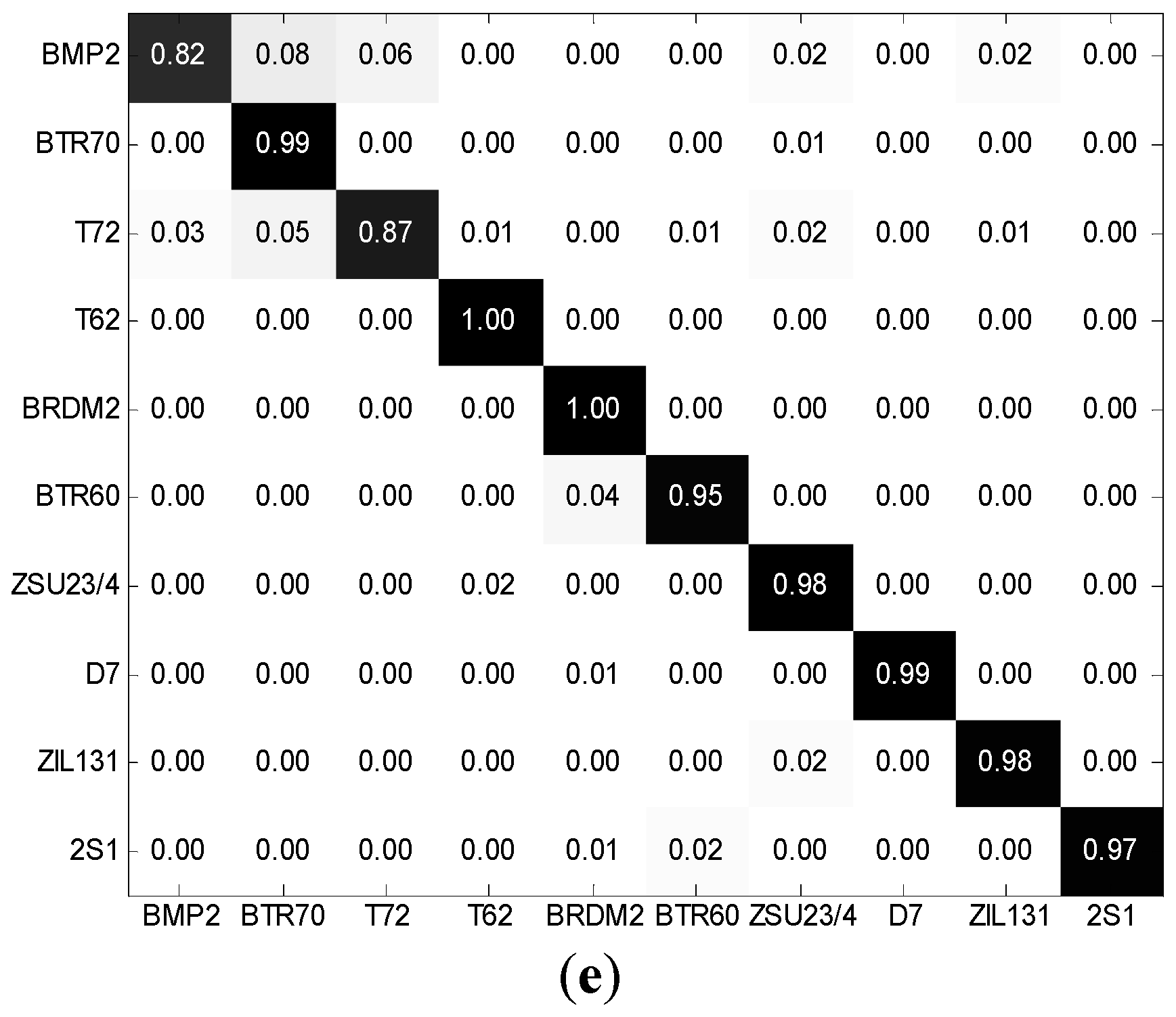
In this study, the original SAR images are used to generate three information-decoupled representations: target image, shadow image and target–shadow image. Because of the outstanding properties of the shadow, which always contains much lower intensity values [
15], the shadow segmentation is much simpler than the segmentation of target region. Moreover, the inaccurateness of the shadow segmentation will result in a smaller loss of discriminative information. First, the shadow is first separated from the original SAR image as a binary region. By replacing the shadow region with randomly selected background pixels, the target image is generated. Thus, the target image only contains the target backscattering and background. The target–shadow image is directly represented by the original SAR image, which is coupled by the target backscattering, shadow and background. The three components may have different advantages for target recognition. Under SOC, both target region and shadow contain more discriminability than confusion and tend to share similar similarity patterns over the training samples. Therefore, their joint usage, i.e., the original image, is preferred to best embody the discriminative information and suppress the confusing information. Under some EOCs, the discriminative information in the target image or shadow is weakened, and the confusing information increases. It is predictable that better results should be achieved when the shadow or target image is not used or weighted less.
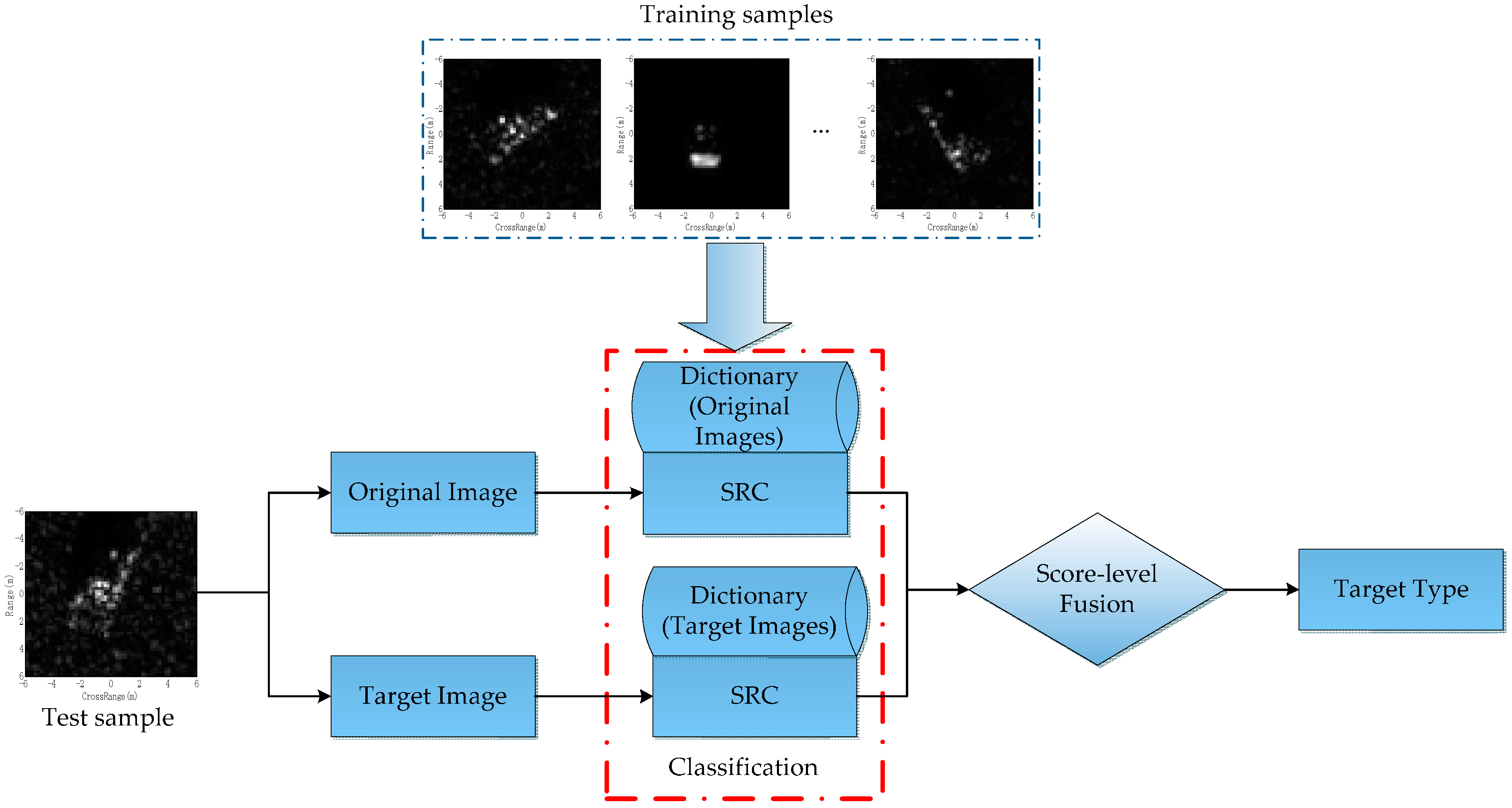
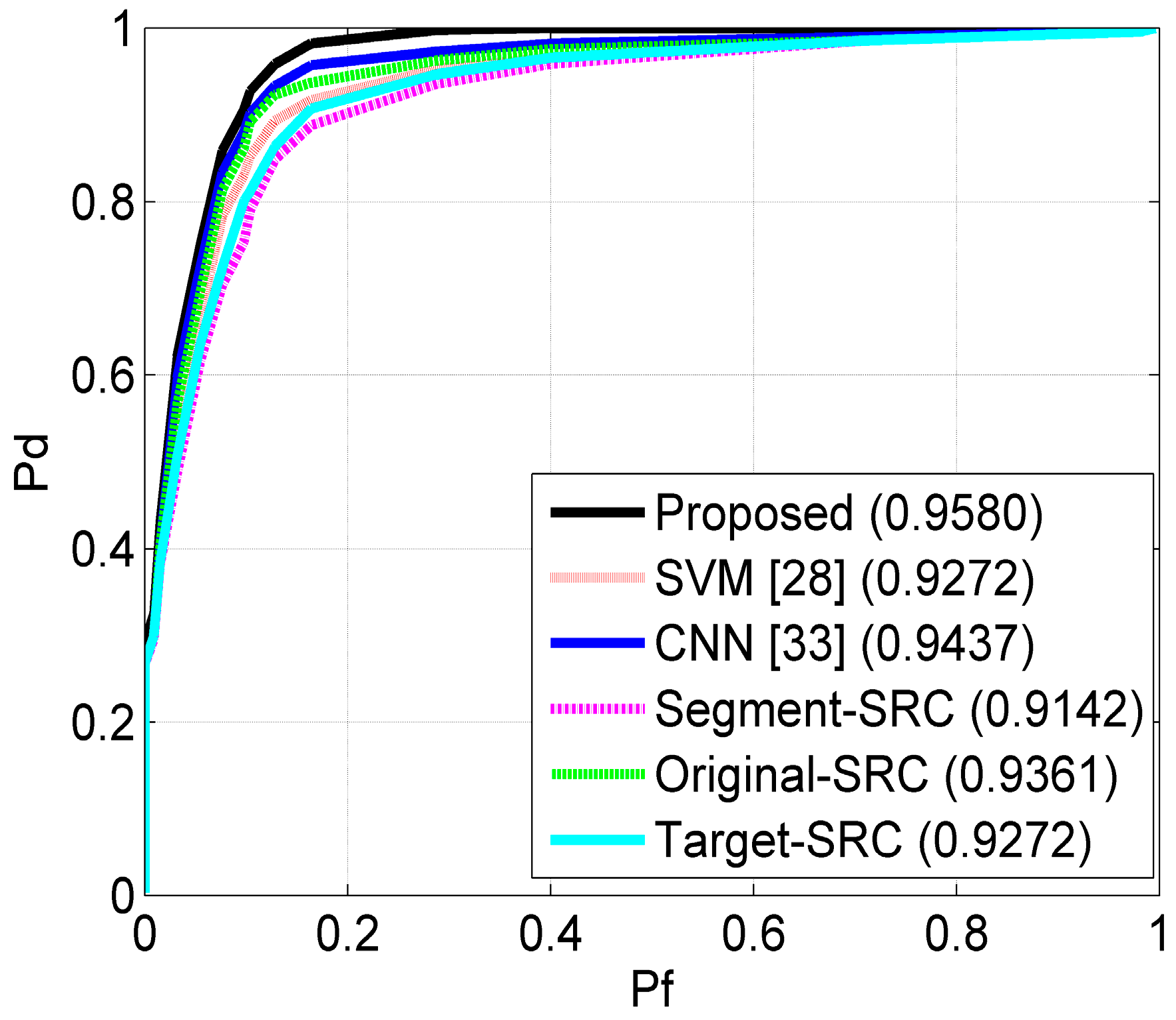
For a particular feature, the decision engine should be carefully designed to exploit its discriminability to improve the ATR performance [
13]. With the fast development of pattern recognition and machine learning techniques, many advanced classifiers [
30,
31,
32,
33,
34,
35,
36,
37] have been successfully applied to SAR ATR, such as the support vector machine (SVM) [
28,
29], sparse representation-based classification (SRC) [
21,
31,
32,
33], convolutional neural network (CNN) [
35], adaptive boosting (Adaboost) [
36] and discriminative graphical models [
37]. Among these classifiers, SRC is notably robust to EOCs such as noise corruption and partial occlusion [
38]. Therefore, SRC is used to classify the original and target images. Then, the classification results are combined using a score-level fusion [
10,
39,
40] for the target recognition. The shadow image is not used because of its lower discriminability and possible segmentation errors. The advantages of the score-level fusion can be analyzed from two aspects. On the one hand, it is difficult to decide the operating conditions of the test image in practical applications. Then, little prior information can be used to select the component for recognition. However, the decision fusion of these components can effectively improve the robustness of the ATR method to various EOCs. On the other hand, some test samples under SOC may also have different shadows with the training samples and other samples under EOCs may have similar shadow with the training samples because of the effects of uncertain factors. Then, the original image and target image complement each other during the score-level fusion to improve the effectiveness and robustness of the proposed method to both SOC and various EOCs. To evaluate the proposed method, extensive experiments are conducted on the Moving and Stationary Target Acquisition and Recognition (MSTAR) [
41] dataset under SOC and typical EOCs, i.e., configuration variance and depression angle variance. Moreover, the proposed method is tested with possible shadow segmentation errors and outlier confusion. By comparing with several state-of-the-art SAR ATR methods, we demonstrate that the proposed method is more effective and robust.
The remainder of this paper is organized as follows.
Section 2 introduces the information model of SAR image and detailed procedure to generate the information-decoupled representations. Then, in
Section 3, the principle of SRC is explained. The detailed implementation of the proposed target recognition method is also illustrated. Extensive experiments are conducted on the MSTAR dataset under SOC and typical EOCs to evaluate the performance of the proposed method in
Section 4.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}