On Statistical Approaches to Generate Level 3 Products from Satellite Remote Sensing Retrievals


Abstract
:
1. Introduction
2. Spatio-Temporal Prediction from Retrievals
2.1. Observation Space vs. Process Space
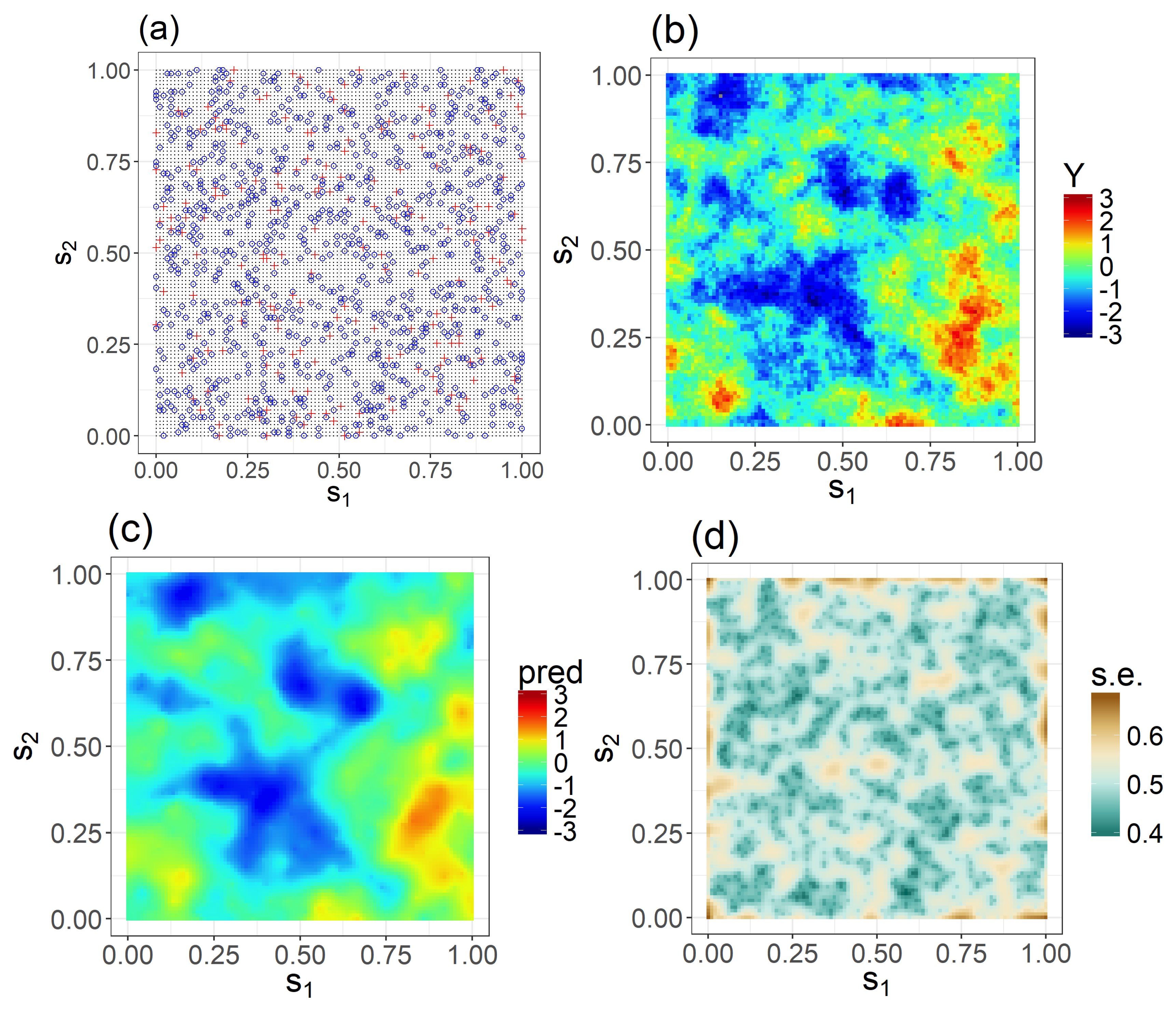
2.2. Level 3 Maps Generated Using Statistical Techniques Will Appear Smooth
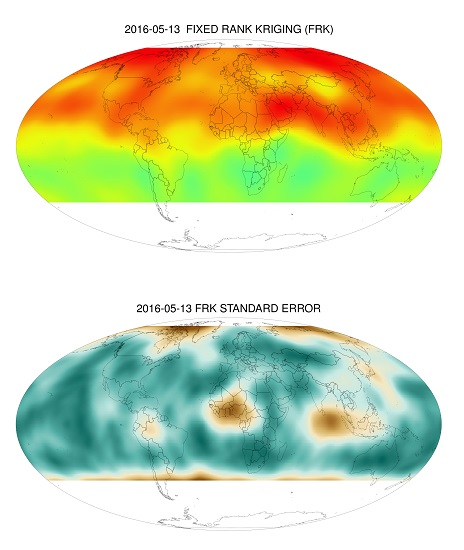
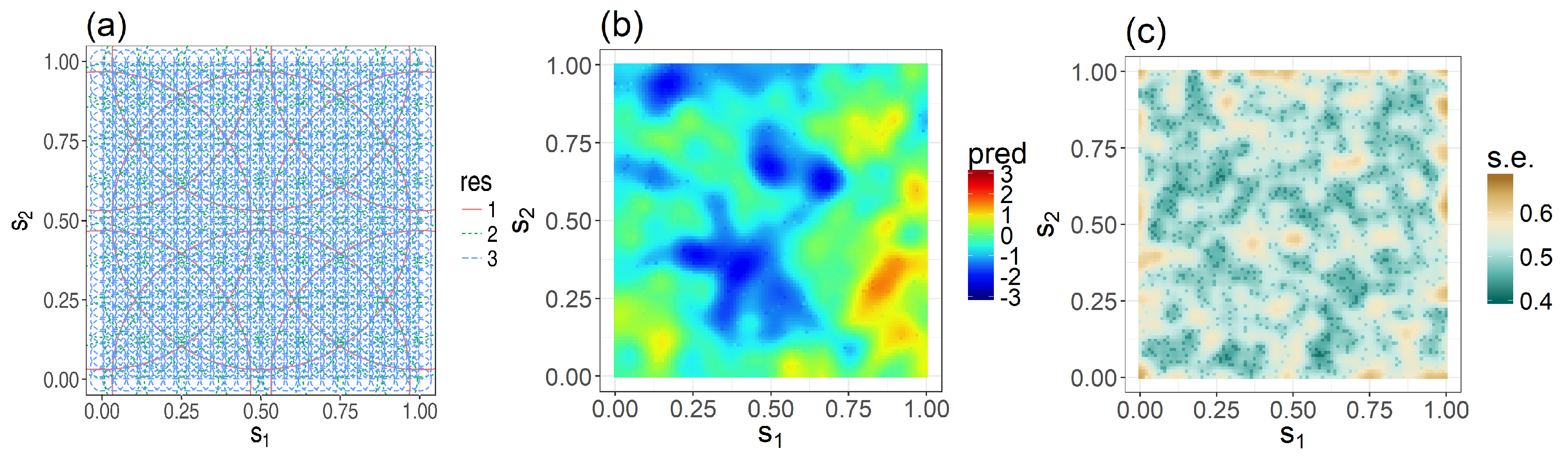
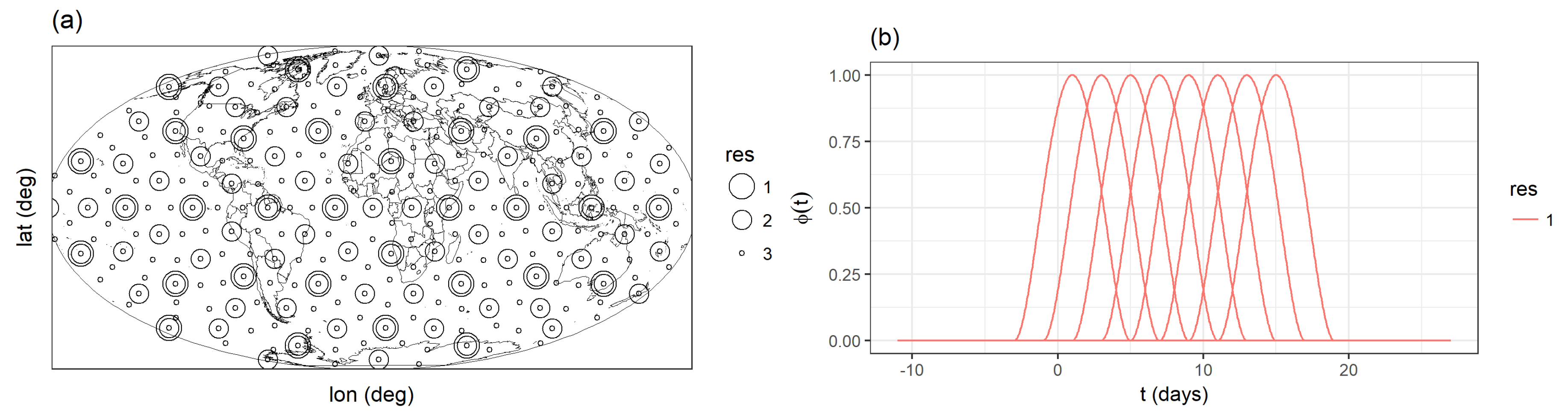
2.3. Fixed Rank Kriging
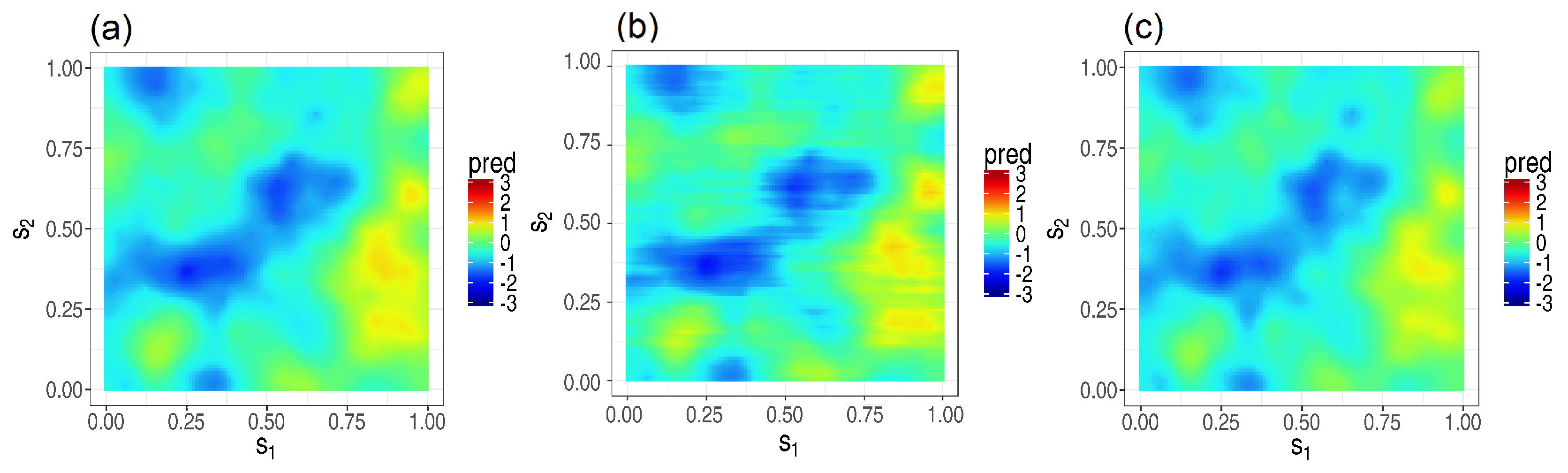
2.4. Fixed-Window and Moving-Window Local Space-Time Kriging
2.5. Local Prediction and Signal-To-Noise Ratio
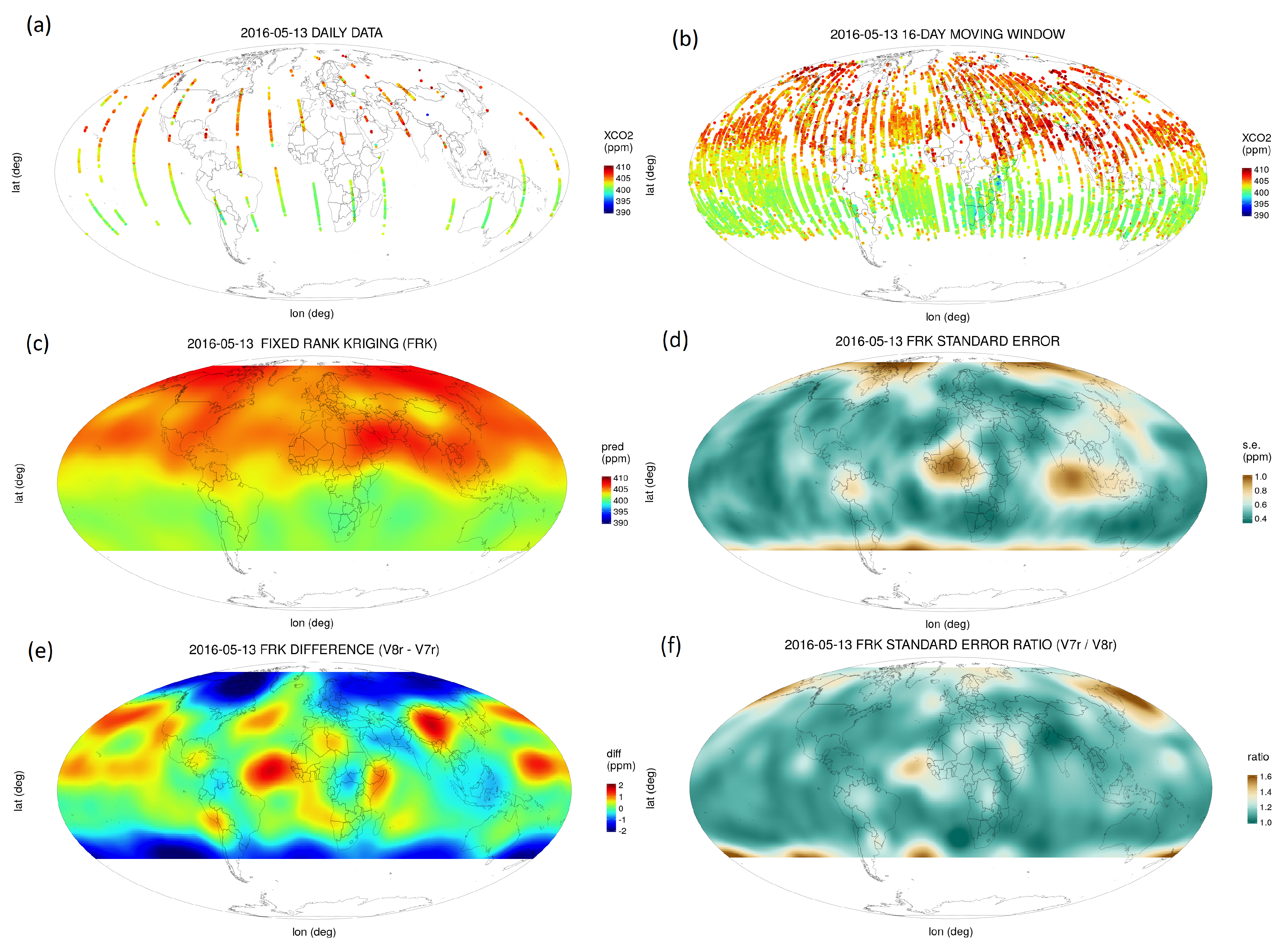
3. OCO-2 Level 3 Products from V7r and V8r Lite Files
3.1. OCO-2 Data Preprocessing
3.2. Implementation Details for FRK
3.3. A Coverage Diagnostic in the Presence of Measurement Bias
3.4. Comparison to TCCON Data
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| CO | carbon dioxide |
| FRK | fixed rank kriging |
| GOSAT | Greenhouse gases Observing SATellite |
| MAPE | mean absolute prediction error |
| MPE | mean prediction error |
| OCO-2 | Orbiting Carbon Observatory-2 |
| RMSPE | root-mean-squared prediction error |
| SNR | signal-to-noise ratio |
| TCCON | Total Carbon Column Observing Network |
| XCO | column-averaged carbon dioxide |
Appendix A
Appendix A.1. Variance Reduction of the Smoother
Appendix A.2. Recovering the Optimal Predictor with FRK
Appendix A.3. Predictor ‘Smoothness’ Increases with Measurement-Error Variance
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station Name | N | MPE (Bias) | MAPE | RMSPE | Slope | 95% Cov. | |
|---|---|---|---|---|---|---|---|
| Eureka | 5 | −1.49 | 1.49 | 1.72 | 0.98 | 0.996 | 0.60 |
| Ny Ålesund | 31 | 1.15 | 1.30 | 1.57 | 0.92 | 1.003 | 0.81 |
| Sodankylä | 112 | 2.08 | 2.08 | 2.28 | 0.94 | 1.005 | 0.29 |
| Bialystok | 106 | 1.22 | 1.25 | 1.46 | 0.94 | 1.003 | 0.62 |
| Bremen | 23 | 1.28 | 1.45 | 1.61 | 0.93 | 1.003 | 0.70 |
| Karlsruhe | 103 | 1.05 | 1.17 | 1.42 | 0.92 | 1.003 | 0.66 |
| Paris | 81 | 0.06 | 1.14 | 1.40 | 0.84 | 1.000 | 0.84 |
| Orleans | 146 | 0.96 | 1.09 | 1.31 | 0.90 | 1.002 | 0.71 |
| Garmisch | 101 | 1.14 | 1.25 | 1.47 | 0.89 | 1.003 | 0.59 |
| Parkfalls | 190 | 0.51 | 0.82 | 1.08 | 0.91 | 1.001 | 0.87 |
| Rikubetsu | 56 | 0.29 | 0.86 | 1.11 | 0.91 | 1.001 | 0.86 |
| Lamont | 342 | −0.11 | 0.59 | 0.76 | 0.93 | 1.000 | 0.99 |
| Anmeyondo | 48 | 0.33 | 1.22 | 1.43 | 0.84 | 1.001 | 0.73 |
| Tsukuba | 137 | −0.25 | 0.96 | 1.29 | 0.72 | 0.999 | 0.87 |
| Edwards | 337 | −0.03 | 0.79 | 0.97 | 0.85 | 1.000 | 0.92 |
| Pasadena | 443 | −1.82 | 1.98 | 2.32 | 0.71 | 0.995 | 0.44 |
| Saga | 76 | −0.86 | 1.09 | 1.36 | 0.89 | 0.998 | 0.86 |
| Izana | 17 | −1.08 | 1.08 | 1.23 | 0.90 | 0.997 | 0.71 |
| Manaus | 38 | −0.05 | 0.66 | 0.85 | 0.47 | 1.000 | 0.97 |
| Ascension | 210 | 0.32 | 0.68 | 0.91 | 0.79 | 1.001 | 0.99 |
| Darwin | 284 | −0.06 | 0.49 | 0.63 | 0.92 | 1.000 | 1.00 |
| Reunion | 243 | 0.23 | 0.58 | 0.71 | 0.91 | 1.001 | 0.94 |
| Wollongong | 201 | 0.54 | 1.02 | 1.26 | 0.69 | 1.001 | 0.82 |
| Lauder | 180 | 0.71 | 0.84 | 1.15 | 0.83 | 1.002 | 0.82 |
| Station Name | N | MPE (Bias) | MAPE | RMSPE | Slope | 95% Cov. | |
|---|---|---|---|---|---|---|---|
| Eureka | 5 | −1.48 | 1.59 | 2.00 | 0.73 | 0.996 | 0.40 |
| Ny Ålesund | 31 | 0.60 | 1.22 | 1.64 | 0.83 | 1.002 | 0.71 |
| Sodankylä | 112 | 0.77 | 0.96 | 1.23 | 0.94 | 1.002 | 0.70 |
| Bialystok | 106 | 0.18 | 0.60 | 0.76 | 0.95 | 1.000 | 0.94 |
| Bremen | 23 | 0.18 | 0.86 | 1.12 | 0.91 | 1.000 | 0.87 |
| Karlsruhe | 103 | 0.33 | 0.76 | 1.01 | 0.92 | 1.001 | 0.82 |
| Paris | 81 | −0.63 | 1.22 | 1.55 | 0.82 | 0.998 | 0.72 |
| Orleans | 146 | 0.31 | 0.79 | 0.97 | 0.89 | 1.001 | 0.79 |
| Garmisch | 101 | 0.50 | 0.85 | 1.06 | 0.89 | 1.001 | 0.80 |
| Parkfalls | 190 | −0.13 | 0.71 | 0.93 | 0.91 | 1.000 | 0.94 |
| Rikubetsu | 56 | 0.00 | 0.90 | 1.07 | 0.91 | 1.000 | 0.91 |
| Lamont | 342 | −0.22 | 0.59 | 0.75 | 0.93 | 0.999 | 0.99 |
| Anmeyondo | 48 | −0.30 | 1.10 | 1.42 | 0.85 | 0.999 | 0.85 |
| Tsukuba | 137 | −0.56 | 1.08 | 1.40 | 0.72 | 0.999 | 0.84 |
| Edwards | 337 | 0.15 | 0.60 | 0.77 | 0.91 | 1.000 | 0.97 |
| Pasadena | 443 | −1.77 | 1.86 | 2.15 | 0.79 | 0.996 | 0.44 |
| Saga | 76 | −1.20 | 1.25 | 1.52 | 0.91 | 0.997 | 0.78 |
| Izana | 17 | −0.92 | 0.96 | 1.08 | 0.88 | 0.998 | 0.65 |
| Manaus | 38 | −0.35 | 0.62 | 0.77 | 0.69 | 0.999 | 1.00 |
| Ascension | 210 | 0.36 | 0.69 | 0.89 | 0.82 | 1.001 | 1.00 |
| Darwin | 284 | −0.17 | 0.51 | 0.61 | 0.94 | 1.000 | 1.00 |
| Reunion | 243 | 0.00 | 0.51 | 0.62 | 0.93 | 1.000 | 0.99 |
| Wollongong | 201 | 0.12 | 0.70 | 0.86 | 0.84 | 1.000 | 0.94 |
| Lauder | 180 | 0.16 | 0.43 | 0.61 | 0.92 | 1.000 | 1.00 |
References
- Chevallier, F.; Broquet, G.; Pierangelo, C.; Crisp, D. Probabilistic global maps of the CO2 column at daily and monthly scales from sparse satellite measurements. J. Geophys. Res. Atmos. 2017, 122, 7614–7629. [Google Scholar] [CrossRef]
- Tiwari, Y.K.; Gloor, M.; Engelen, R.J.; Chevallier, F.; Rödenbeck, C.; Körner, S.; Peylin, P.; Braswell, B.H.; Heimann, M. Comparing CO2 retrieved from Atmospheric Infrared Sounder with model predictions: Implications for constraining surface fluxes and lower-to-upper troposphere transport. J. Geophys. Res. Atmos. 2006, 111. [Google Scholar] [CrossRef]
- Hammerling, D.M.; Michalak, A.M.; O’Dell, C.; Kawa, S.R. Global CO2 distributions over land from the Greenhouse Gases Observing Satellite (GOSAT). Geophys. Res. Lett. 2012, 39. [Google Scholar] [CrossRef]
- Inoue, M.; Morino, I.; Uchino, O.; Miyamoto, Y.; Yoshida, Y.; Yokota, T.; Machida, T.; Sawa, Y.; Matsueda, H.; Sweeney, C.; et al. Validation of XCO2 derived from SWIR spectra of GOSAT TANSO-FTS with aircraft measurement data. Atmos. Chem. Phys. 2013, 13, 9771–9788. [Google Scholar] [CrossRef]
- Butz, A.; Guerlet, S.; Hasekamp, O.; Schepers, D.; Galli, A.; Aben, I.; Frankenberg, C.; Hartmann, J.M.; Tran, H.; Kuze, A.; et al. Toward accurate CO2 and CH4 observations from GOSAT. Geophys. Res. Lett. 2011, 38. [Google Scholar] [CrossRef]
- Katzfuss, M.; Cressie, N. Spatio-temporal smoothing and EM estimation for massive remote-sensing data sets. J. Time Ser. Anal. 2011, 32, 430–446. [Google Scholar] [CrossRef]
- Zeng, Z.C.; Lei, L.; Strong, K.; Jones, D.B.A.; Guo, L.; Liu, M.; Deng, F.; Deutscher, N.M.; Dubey, M.K.; Griffith, D.W.T.; et al. Global land mapping of satellite-observed CO2 total columns using spatio-temporal geostatistics. Int. J. Digit. Earth 2017, 10, 426–456. [Google Scholar] [CrossRef]
- Nguyen, H.; Osterman, G.; Wunch, D.; O’Dell, C.; Mandrake, L.; Wennberg, P.; Fisher, B.; Castano, R. A method for colocating satellite XCO2 data to ground-based data and its application to ACOS-GOSAT and TCCON. Atmos. Meas. Tech. 2014, 7, 2631–2644. [Google Scholar] [CrossRef]
- Jing, Y.; Shi, J.; Wang, T.; Sussmann, R. Mapping global atmospheric CO2 concentration at high spatiotemporal resolution. Atmosphere 2014, 5, 870–888. [Google Scholar] [CrossRef]
- Tadić, J.; Qiu, X.; Yadav, V.; Michalak, A. Mapping of satellite Earth observations using moving window block kriging. Geosci. Model Dev. 2015, 8, 3311–3319. [Google Scholar] [CrossRef]
- Haas, T.C. Local prediction of a spatio-temporal process with an application to wet sulfate deposition. J. Am. Stat. Assoc. 1995, 90, 1189–1199. [Google Scholar] [CrossRef]
- Cressie, N.; Johannesson, G. Fixed Rank Kriging for very large spatial data sets. J. R. Stat. Soc. Ser. B 2008, 70, 209–226. [Google Scholar] [CrossRef]
- Nguyen, H.; Cressie, N.; Braverman, A. Spatial statistical data fusion for remote sensing applications. J. Am. Stat. Assoc. 2012, 107, 1004–1018. [Google Scholar] [CrossRef]
- Nguyen, H.; Katzfuss, M.; Cressie, N.; Braverman, A. Spatio-temporal data fusion for very large remote sensing datasets. Technometrics 2014, 56, 174–185. [Google Scholar] [CrossRef]
- Alkhaled, A.A.; Michalak, A.M.; Kawa, S.R.; Olsen, S.C.; Wang, J.W. A global evaluation of the regional spatial variability of column integrated CO2 distributions. J. Geophys. Res. Atmos. 2008, 113. [Google Scholar] [CrossRef]
- Engelen, R.J.; Serrar, S.; Chevallier, F. Four-dimensional data assimilation of atmospheric CO2 using AIRS observations. J. Geophys. Res. Atmos. 2009, 114. [Google Scholar] [CrossRef]
- Cressie, N. Statistics for Spatial Data; John Wiley & Sons: New York, NY, USA, 1993. [Google Scholar]
- Eldering, A.; O’Dell, C.W.; Wennberg, P.O.; Crisp, D.; Gunson, M.R.; Viatte, C.; Avis, C.; Braverman, A.; Castano, R.; Chang, A.; et al. The Orbiting Carbon Observatory-2: First 18 months of science data products. Atmos. Meas. Tech. 2017, 10, 549–563. [Google Scholar] [CrossRef]
- OCO-2 Science Team; Gunson, M.; Eldering, A. OCO-2 Level 2 Bias-Corrected XCO2 and Other Select Fields from the Full-Physics Retrieval Aggregated as Daily Files, Retrospective Processing V7r; Goddard Earth Sciences Data and Information Services Center (GES DISC): Greenbelt, MD, USA, 2015. Available online: https://disc.gsfc.nasa.gov/datasets/OCO2_L2_Lite_FP_V7r/summary (accessed on 20 January 2018).
- OCO-2 Science Team; Gunson, M.; Eldering, A. OCO-2 Level 2 Bias-Corrected XCO2 and Other Select Fields from the Full-Physics Retrieval Aggregated as Daily Files, Retrospective Processing V8r; Goddard Earth Sciences Data and Information Services Center (GES DISC): Greenbelt, MD, USA, 2017. Available online: https://disc.gsfc.nasa.gov/datasets/OCO2_L2_Lite_FP_V8r/summary (accessed on 20 January 2018).
- Wunch, D.; Toon, G.C.; Blavier, J.F.L.; Washenfelder, R.A.; Notholt, J.; Connor, B.J.; Griffith, D.W.; Sherlock, V.; Wennberg, P.O. The Total Carbon Column Observing Network. Philos. Trans. R. Soc. Lond. A Math. Phys. Eng. Sci. 2011, 369, 2087–2112. [Google Scholar] [CrossRef] [PubMed]
- Wunch, D.; Toon, G.C.; Sherlock, V.; Deutscher, N.M.; Liu, C.; Feist, D.G.; Wennberg, P.O. Documentation for the 2014 TCCON Data Release. 2017. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.documentation.r0/1221662 (accessed on 20 January 2018).
- Cressie, N.; Wikle, C.K. Statistics for Spatio-Temporal Data; John Wiley and Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Zhang, J.; Craigmile, P.F.; Cressie, N. Loss function approaches to predict a spatial quantile and its exceedance region. Technometrics 2008, 50, 216–227. [Google Scholar] [CrossRef]
- Gneiting, T.; Katzfuss, M. Probabilistic forecasting. Annu. Rev. Stat. Appl. 2014, 1, 125–151. [Google Scholar] [CrossRef]
- Aldworth, J.; Cressie, N. Prediction of nonlinear spatial functionals. J. Stat. Plan. Inference 2003, 112, 3–41. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, Volume 1, 2nd ed.; Wiley: New York, NY, USA, 1994. [Google Scholar]
- Wikle, C.K. Low-rank representations for spatial processes. In Handbook of Spatial Statistics; Gelfand, A.E., Diggle, P., Guttorp, P., Fuentes, M., Eds.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2010; pp. 107–118. [Google Scholar]
- Zammit-Mangion, A.; Cressie, N. FRK: An R package for spatial and spatio-temporal prediction with large datasets. arXiv, 2017; arXiv:1705.08105. [Google Scholar]
- Lindgren, F.; Rue, H.; Lindström, J. An explicit link between Gaussian fields and Gaussian Markov random fields: The stochastic partial differential equation approach. J. R. Stat. Soc. Ser. B 2011, 73, 423–498. [Google Scholar] [CrossRef]
- Nychka, D.; Bandyopadhyay, S.; Hammerling, D.; Lindgren, F.; Sain, S. A multiresolution Gaussian process model for the analysis of large spatial datasets. J. Comput. Graph. Stat. 2015, 24, 579–599. [Google Scholar] [CrossRef] [Green Version]
- Stein, M.L. Limitations on low rank approximations for covariance matrices of spatial data. Spat. Stat. 2014, 8, 1–19. [Google Scholar] [CrossRef]
- Ma, P.; Kang, E.L. Fused Gaussian process for very large spatial data. arXiv, 2017; arXiv:1702.08797. [Google Scholar]
- Zammit-Mangion, A.; Sanguinetti, G.; Kadirkamanathan, V. Variational estimation in spatiotemporal systems from continuous and point-process observations. IEEE Trans. Signal Process. 2012, 60, 3449–3459. [Google Scholar] [CrossRef]
- Katzfuss, M. A multi-resolution approximation for massive spatial datasets. J. Am. Stat. Assoc. 2017, 112, 201–214. [Google Scholar] [CrossRef]
- Wikle, C.K.; Cressie, N. A dimension-reduced approach to space-time Kalman filtering. Biometrika 1999, 86, 815–829. [Google Scholar] [CrossRef]
- Stroud, J.R.; Müller, P.; Sansó, B. Dynamic models for spatiotemporal data. J. R. Stat. Soc. Ser. B 2001, 63, 673–689. [Google Scholar] [CrossRef]
- Watanabe, H.; Hayashi, K.; Saeki, T.; Maksyutov, S.; Nasuno, I.; Shimono, Y.; Hirose, Y.; Takaichi, K.; Kanekon, S.; Ajiro, M.; et al. Global mapping of greenhouse gases retrieved from GOSAT Level 2 products by using a kriging method. Int. J. Remote Sens. 2015, 36, 1509–1528. [Google Scholar] [CrossRef]
- Wunch, D.; Wennberg, P.O.; Osterman, G.; Fisher, B.; Naylor, B.; Roehl, C.M.; O’Dell, C.; Mandrake, L.; Viatte, C.; Kiel, M.; et al. Comparisons of the Orbiting Carbon Observatory-2 (OCO-2) XCO2 measurements with TCCON. Atmos. Meas. Tech. 2017, 10, 2209–2238. [Google Scholar] [CrossRef]
- Hobbs, J.; Braverman, A.; Cressie, N.; Granat, R.; Gunson, M. Simulation-based uncertainty quantification for estimating atmospheric CO2 from satellite data. SIAM/ASA J. Uncertain. Quantif. 2017, 5, 956–985. [Google Scholar] [CrossRef]
- Nguyen, H.; Cressie, N.; Braverman, A. Multivariate spatial data fusion for very large remote sensing datasets. Remote Sens. 2017, 9, 142. [Google Scholar] [CrossRef]
- Sherlock, V.; Connor, B.; Robinson, J.; Shiona, H.; Smale, D.; Pollard, D. TCCON Data from Lauder, New Zealand, 125HR, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.lauder02.R0/1149298 (accessed on 20 January 2018).
- Griffith, D.W.T.; Velazco, V.A.; Deutscher, N.; Murphy, C.; Jones, N.; Wilson, S.; Macatangay, R.; Kettlewell, G.; Buchholz, R.R.; Riggenbach, M. TCCON Data from Wollongong, Australia, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.wollongong01.R0/1149291 (accessed on 20 January 2018).
- De Maziere, M.; Sha, M.K.; Desmet, F.; Hermans, C.; Scolas, F.; Kumps, N.; Metzger, J.M.; Duflot, V.; Cammas, J.P. TCCON Data from Reunion Island (La Reunion), France, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.reunion01.R0/1149288 (accessed on 20 January 2018).
- Griffith, D.W.T.; Deutscher, N.; Velazco, V.A.; Wennberg, P.O.; Yavin, Y.; Aleks, G.K.; Washenfelder, R.; Toon, G.C.; Blavier, J.F.; Murphy, C.; et al. TCCON Data from Darwin, Australia, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.darwin01.R0/1149290 (accessed on 20 January 2018).
- Feist, D.G.; Arnold, S.G.; John, N.; Geibel, M.C. TCCON Data from Ascension Island, Saint Helena, Ascension and Tristan da Cunha, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.ascension01.R0/1149285 (accessed on 20 January 2018).
- Dubey, M.; Henderson, B.; Green, D.; Butterfield, Z.; Keppel-Aleks, G.; Allen, N.; Blavier, J.F.; Roehl, C.; Wunch, D.; Lindenmaier, R. TCCON Data from Manaus, Brazil, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.manaus01.R0/1149274 (accessed on 20 January 2018).
- Blumenstock, T.; Hase, F.; Schneider, M.; Garcia, O.; Sepulveda, E. TCCON Data from Izana, Tenerife, Spain, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.izana01.R0/1149295 (accessed on 20 January 2018).
- Kawakami, S.; Ohyama, H.; Arai, K.; Okumura, H.; Taura, C.; Fukamachi, T.; Sakashita, M. TCCON Data from Saga, Japan, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.saga01.R0/1149283 (accessed on 20 January 2018).
- Wennberg, P.O.; Wunch, D.; Roehl, C.; Blavier, J.F.L.; Toon, G.C.; Allen, N. TCCON Data from California Institute of Technology, Pasadena, California, USA, Release GGG2014R1; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.pasadena01.R1/1182415 (accessed on 20 January 2018).
- Iraci, L.; Podolske, J.; Hillyard, P.; Roehl, C.; Wennberg, P.O.; Blavier, J.F.; Landeros, J.; Allen, N.; Wunch, D.; Zavaleta, J.; et al. TCCON Data from Armstrong Flight Research Center, Edwards, CA, USA, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.edwards01.R0/1149289 (accessed on 20 January 2018).
- Morino, I.; Matsuzaki, T.; Shishime, A. TCCON Data from Tsukuba, Ibaraki, Japan, 125HR, Release GGG2014R1; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.tsukuba02.R1/1241486 (accessed on 20 January 2018).
- Goo, T.Y.; Oh, Y.S.; Velazco, V.A. TCCON Data from Anmeyondo, South Korea, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.anmeyondo01.R0/1149284 (accessed on 20 January 2018).
- Wennberg, P.O.; Wunch, D.; Roehl, C.; Blavier, J.F.; Toon, G.C.; Allen, N.; Dowell, P.; Teske, K.; Martin, C.; Martin., J. TCCON Data from Lamont, Oklahoma, USA, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.lamont01.R0/1149159 (accessed on 20 January 2018).
- Morino, I.; Yokozeki, N.; Matzuzaki, T.; Shishime, A. TCCON Data from Rikubetsu, Hokkaido, Japan, Release GGG2014R1; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.rikubetsu01.R1/1242265 (accessed on 20 January 2018).
- Wennberg, P.O.; Roehl, C.; Wunch, D.; Toon, G.C.; Blavier, J.F.; Washenfelder, R.; Keppel-Aleks, G.; Allen, N.; Ayers, J. TCCON Data from Park Falls, Wisconsin, USA, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.parkfalls01.R0/1149161 (accessed on 20 January 2018).
- Sussmann, R.; Rettinger, M. TCCON Data from Garmisch, Germany, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.garmisch01.R0/1149299 (accessed on 20 January 2018).
- Warneke, T.; Messerschmidt, J.; Notholt, J.; Weinzierl, C.; Deutscher, N.; Petri, C.; Grupe, P.; Vuillemin, C.; Truong, F.; Schmidt, M.; et al. TCCON Data from Orleans, France, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.orleans01.R0/1149276 (accessed on 20 January 2018).
- Te, Y.; Jeseck, P.; Janssen, C. TCCON Data from Paris, France, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.paris01.R0/1149279 (accessed on 20 January 2018).
- Hase, F.; Blumenstock, T.; Dohe, S.; Gross, J.; Kiel, M. TCCON Data from Karlsruhe, Germany, Release GGG2014R1; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.karlsruhe01.R1/1182416 (accessed on 20 January 2018).
- Notholt, J.; Petri, C.; Warneke, T.; Deutscher, N.; Buschmann, M.; Weinzierl, C.; Macatangay, R.; Grupe, P. TCCON Data from Bremen, Germany, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.bremen01.R0/1149275 (accessed on 20 January 2018).
- Deutscher, N.; Notholt, J.; Messerschmidt, J.; Weinzierl, C.; Warneke, T.; Petri, C.; Grupe, P.; Katrynski, K. TCCON Data from Bialystok, Poland, Release GGG2014R1; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.bialystok01.R1/1183984 (accessed on 20 January 2018).
- Kivi, R.; Heikkinen, P.; Kyro, E. TCCON Data from Sodankylä, Finland, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.sodankyla01.R0/1149280 (accessed on 20 January 2018).
- Notholt, J.; Warneke, T.; Petri, C.; Deutscher, N.M.; Weinzierl, C.; Palm, M.; Buschmann, M. TCCON Data from Ny Ålesund, Norway, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.nyalesund01.R0/1149278 (accessed on 20 January 2018).
- Strong, K.; Mendonca, J.; Weaver, D.; Fogal, P.; Drummond, J.; Batchelor, R.; Lindenmaier, R. TCCON Data from Eureka, Canada, Release GGG2014R0; Carbon Dioxide Information Analysis Center, Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2014. Available online: http://dx.doi.org/10.14291/tccon.ggg2014.eureka01.R0/1149271 (accessed on 20 January 2018).
- Liang, A.; Gong, W.; Han, G.; Xiang, C. Comparison of satellite-observed XCO2 from GOSAT, OCO-2, and ground-based TCCON. Remote Sens. 2017, 9, 1033. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Banerjee, S.; Gelfand, A.E.; Finley, A.O.; Sang, H. Gaussian predictive process models for large spatial data sets. J. R. Stat. Soc. Ser. B 2008, 70, 825–848. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]










| Validating against | Empirical Coverage in Process Space (Nominal Is 90%) | Empirical Coverage in Observation Space (Nominal Is 90%) |
|---|---|---|
| (Simulated) process | 0.89 | 1.00 |
| Left-out retrievals | 0.51 | 0.93 |
| N | MPE (Bias) | MAPE | RMSPE | Slope | 95% Cov. | ||
|---|---|---|---|---|---|---|---|
| Total v7r | 3510 | 0.08 | 1.02 | 1.36 | 0.80 | 1.000 | 0.80 |
| Total v7r (w/o Pas.) | 3067 | 0.35 | 0.88 | 1.15 | 0.85 | 1.001 | 0.85 |
| Total v8r | 3510 | −0.22 | 0.85 | 1.16 | 0.86 | 0.999 | 0.86 |
| Total v8r (w/o Pas.) | 3067 | 0.01 | 0.71 | 0.94 | 0.89 | 1.000 | 0.92 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zammit-Mangion, A.; Cressie, N.; Shumack, C. On Statistical Approaches to Generate Level 3 Products from Satellite Remote Sensing Retrievals. Remote Sens. 2018, 10, 155. https://doi.org/10.3390/rs10010155
Zammit-Mangion A, Cressie N, Shumack C. On Statistical Approaches to Generate Level 3 Products from Satellite Remote Sensing Retrievals. Remote Sensing. 2018; 10(1):155. https://doi.org/10.3390/rs10010155
Chicago/Turabian StyleZammit-Mangion, Andrew, Noel Cressie, and Clint Shumack. 2018. "On Statistical Approaches to Generate Level 3 Products from Satellite Remote Sensing Retrievals" Remote Sensing 10, no. 1: 155. https://doi.org/10.3390/rs10010155
APA StyleZammit-Mangion, A., Cressie, N., & Shumack, C. (2018). On Statistical Approaches to Generate Level 3 Products from Satellite Remote Sensing Retrievals. Remote Sensing, 10(1), 155. https://doi.org/10.3390/rs10010155