Effective Fusion of Multi-Modal Remote Sensing Data in a Fully Convolutional Network for Semantic Labeling

Abstract
:1. Introduction
2. Related Work
2.1. FCN for Images
2.2. FCN for Multi-Modal Data
3. Multi-Resolution Model and Fusion Framework
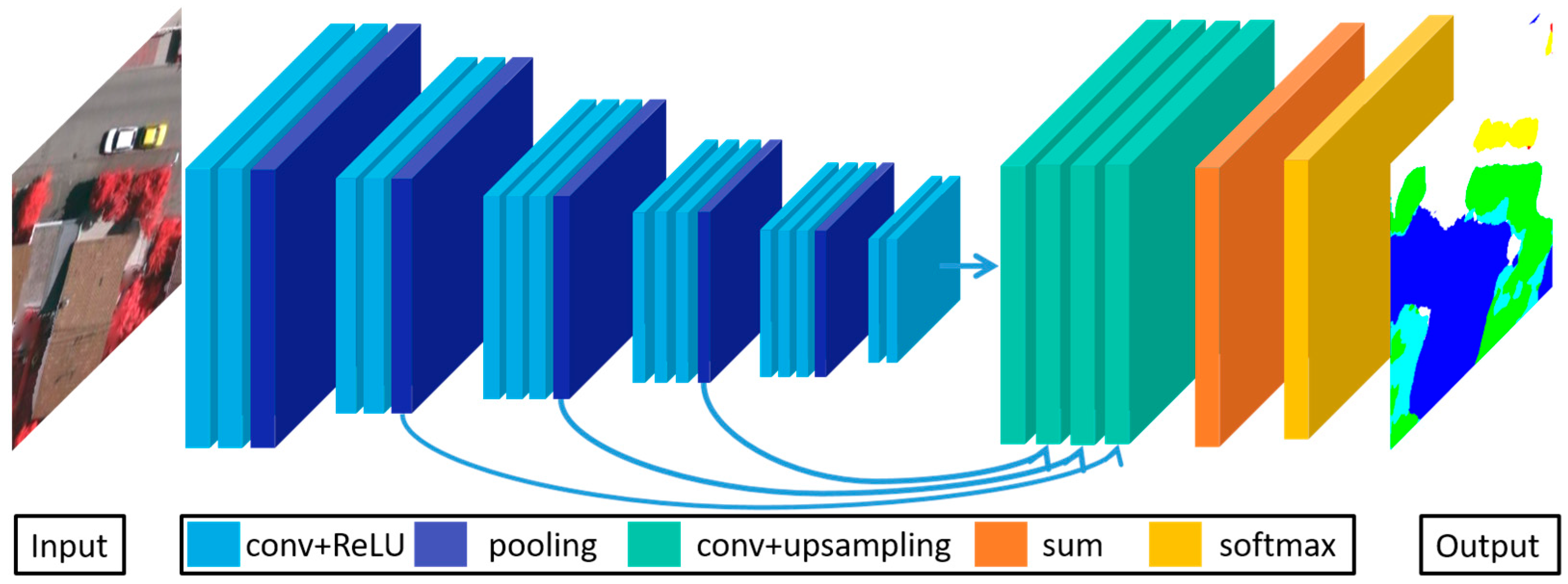
3.1. Multi-Resolution Model
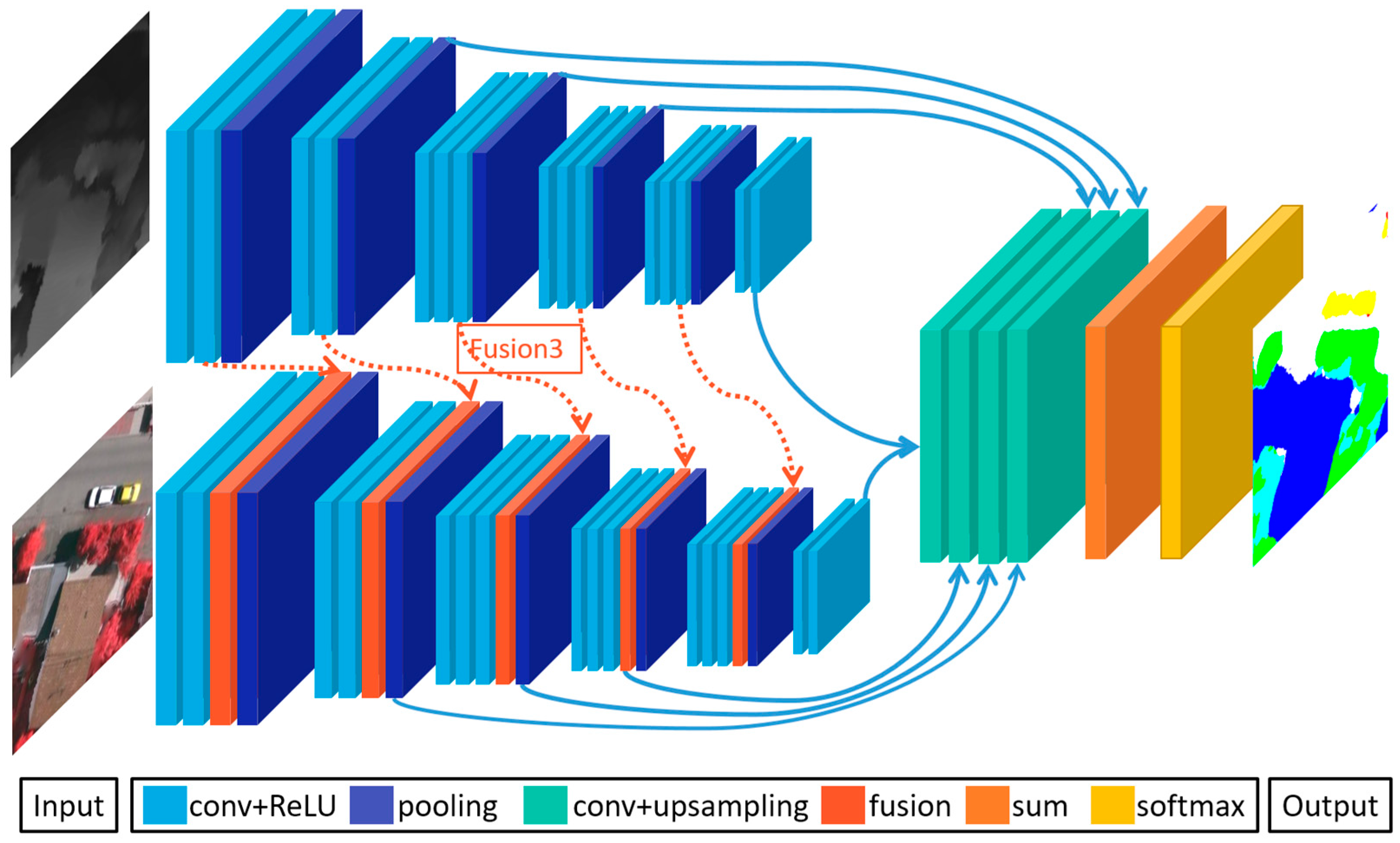
3.2. Fusion Strategy
3.3. Fusion Model
4. Experiments
4.1. Datasets
4.2. Training
4.2.1. Multi-resolution model training
4.2.2. Fusion model training
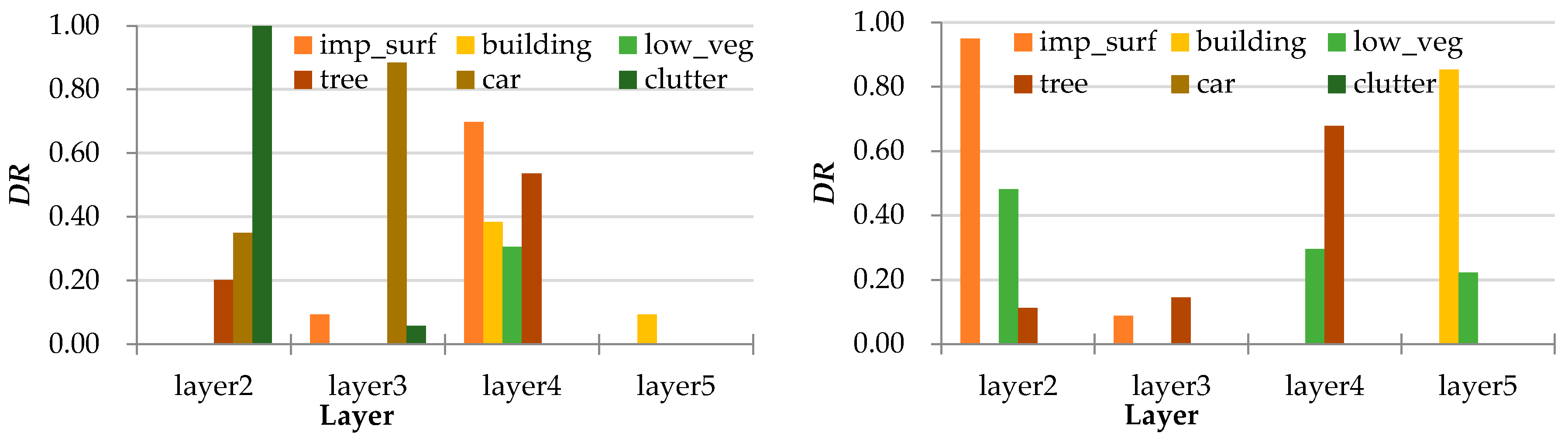
4.3. Evaluation of Experimental Results
4.4. Quantitative Results
4.5. Fusion Model Results
5. Discussion
6. Conclusions
- (i)
- For multi-modal data, the modes have different contributions to specific classes. The performance can be improved by avoiding conflicts between layers, i.e., different sensitivities to specific classes. By this means, we can, thus, design adaptive models suitable for semantic labeling tasks.
- (ii)
- Summation fusion after the ReLU layer is applied in layer fusion. This preserves more information about features and strengthens the activation. The deeper layers are sensitive to objects which have a more complex texture and occupy a larger parts of the scene.
- (iii)
- The skip architecture in the fusion allows to utilize the shallow as well as the deep features. Combining all these components, the multi-modal fusion model incorporates heterogeneous data precisely and effectively.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Längkvist, M.; Kiselev, A.; Alirezaie, M.; Loutfi, A. Classification and segmentation of satellite orthoimagery using convolutional neural networks. Remote Sens. 2016, 8, 329. [Google Scholar] [CrossRef]
- Zhang, M.; Hu, X.; Zhao, L.; Lv, Y.; Luo, M.; Pang, S. Learning dual multi-scale manifold ranking for semantic segmentation of high-resolution images. Remote Sens. 2017, 9, 500. [Google Scholar] [CrossRef]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. arXiv, 2016; arXiv:1606.00915. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating depth into semantic segmentation via fusion-based CNN architecture. In Proceedings of the Asian Conference on Computer Vision ACCV, Taipei, Taiwan, 20–24 November 2016; Volume 2. [Google Scholar]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNSS. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 473–480. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv, 2016; arXiv:1606.02585. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Ning, F.; Delhomme, D.; LeCun, Y.; Piano, F.; Bottou, L.; Barbano, P.E. Toward automatic phenotyping of developing embryos from videos. IEEE Trans. Image Process. 2005, 14, 1360–1371. [Google Scholar] [CrossRef] [PubMed]
- Pinheiro, P.H.O.; Collobert, R. Recurrent convolutional neural networks for scene parsing. arXiv, 2013; arXiv:1306.2795. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Zintgraf, L.M.; Cohen, T.S.; Adel, T.; Welling, M. Visualizing deep neural network decisions: Prediction difference analysis. arXiv, 2017; arXiv:1702.04595. [Google Scholar]
- Zhang, W.; Huang, H.; Schmitz, M.; Sun, X.; Wang, H.; Mayer, H. A multi-resolution fusion model incorporating color and elevation for semantic segmentation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-1/W1, 513–517. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for scene segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv, 2015; arXiv:1511.00561. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.-B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Audebert, N.; Saux, B.L.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. arXiv, 2016; arXiv:1609.06846. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 345–360. [Google Scholar]
- Gerke, M.; Rottensteiner, F.; Wegner, J.D.; Sohn, G. ISPRS semantic labeling contest. In Proceedings of the Photogrammetric Computer Vision—PCV, Zurich, Switzerland, 5–7 September 2014. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Recall | Imp_Surf | Building | Low_Veg | Tree | Car | Clutter |
|---|---|---|---|---|---|---|
| Layers-all | 0.86 | 0.86 | 0.72 | 0.84 | 0.43 | 0.52 |
| Layer-2 | 0.19 | 0.04 | 0 | 0.69 | 0.6 | 0.91 |
| Layers-345 | 0.84 | 0.88 | 0.84 | 0.67 | 0.28 | 0 |
| Layer-3 | 0.59 | 0.03 | 0.01 | 0.01 | 0.86 | 0.66 |
| Layers-245 | 0.78 | 0.88 | 0.74 | 0.86 | 0.05 | 0.49 |
| Layer-4 | 0.83 | 0.83 | 0.65 | 0.88 | 0.01 | 0 |
| Layers-235 | 0.26 | 0.53 | 0.5 | 0.39 | 0.5 | 0.91 |
| Layer-5 | 0 | 0.99 | 0.23 | 0 | 0 | 0 |
| Layers-234 | 0.88 | 0.78 | 0.45 | 0.93 | 0.66 | 0.47 |
| Recall | Imp_Surf | Building | Low_Veg | Tree | Car | Clutter |
|---|---|---|---|---|---|---|
| Layers-all | 0.79 | 0.68 | 0.27 | 0.62 | 0 | 0 |
| Layer-2 | 0.92 | 0 | 0.07 | 0.52 | 0 | 0.01 |
| Layers-345 | 0.04 | 0.84 | 0.14 | 0.55 | 0 | 0 |
| Layer-3 | 0.98 | 0 | 0 | 0.24 | 0 | 0 |
| Layers-245 | 0.72 | 0.8 | 0.34 | 0.53 | 0 | 0 |
| Layer-4 | 0.59 | 0.51 | 0.11 | 0.8 | 0 | 0 |
| Layers-235 | 0.85 | 0.8 | 0.19 | 0.2 | 0 | 0 |
| Layer-5 | 0 | 1 | 0.04 | 0 | 0 | 0 |
| Layers-234 | 0.87 | 0.1 | 0.21 | 0.65 | 0 | 0 |
| Color-D | Fusion1 | Fusion2 | Fusion3 | Fusion4 | Fusion5 | Color | Elevation | |
|---|---|---|---|---|---|---|---|---|
| OA (%) | 79.77 | 81.79 | 82.21 | 82.69 | 81.75 | 81.70 | 81.86 | 60.53 |
| F1 | 0.80 | 0.81 | 0.82 | 0.83 | 0.81 | 0.81 | 0.81 | 0.58 |
| F1 | Imp_Surf | Building | Low_Veg | Tree | Car | Clutter |
|---|---|---|---|---|---|---|
| Color-D | 0.82 | 0.86 | 0.69 | 0.81 | 0.56 | 0.59 |
| Fusion1 | 0.85 | 0.88 | 0.72 | 0.83 | 0.5 | 0.54 |
| Fusion2 | 0.85 | 0.89 | 0.72 | 0.82 | 0.47 | 0.58 |
| Fusion3 | 0.85 | 0.9 | 0.72 | 0.84 | 0.56 | 0.57 |
| Fusion4 | 0.85 | 0.89 | 0.71 | 0.82 | 0.51 | 0.58 |
| Fusion5 | 0.84 | 0.89 | 0.7 | 0.83 | 0.55 | 0.62 |
| Color | 0.84 | 0.87 | 0.72 | 0.84 | 0.54 | 0.66 |
| Elevation | 0.69 | 0.71 | 0.34 | 0.59 | 0 | 0 |
| RGB-D | Fusion1 | Fusion2 | Fusion3 | Fusion4 | Fusion5 | RGB | Elevation | |
|---|---|---|---|---|---|---|---|---|
| OA (%) | 79.21 | 80.35 | 80.99 | 81.64 | 81.78 | 81.80 | 78.31 | 63.16 |
| F1 | 0.79 | 0.78 | 0.78 | 0.79 | 0.80 | 0.80 | 0.78 | 0.48 |
| F1 | Imp_Surf | Building | Low_Veg | Tree | Car | Clutter |
|---|---|---|---|---|---|---|
| RGB-D | 0.80 | 0.86 | 0.74 | 0.69 | 0.70 | 0.50 |
| Fusion1 | 0.80 | 0.85 | 0.74 | 0.64 | 0.55 | 0.29 |
| Fusion2 | 0.81 | 0.88 | 0.75 | 0.68 | 0.68 | 0.45 |
| Fusion3 | 0.82 | 0.89 | 0.76 | 0.71 | 0.74 | 0.52 |
| Fusion4 | 0.83 | 0.90 | 0.77 | 0.72 | 0.74 | 0.51 |
| Fusion5 | 0.83 | 0.90 | 0.77 | 0.72 | 0.74 | 0.51 |
| RGB | 0.81 | 0.85 | 0.76 | 0.71 | 0.77 | 0.50 |
| Elevation | 0.56 | 0.80 | 0.16 | 0.47 | 0 | 0 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Huang, H.; Schmitz, M.; Sun, X.; Wang, H.; Mayer, H. Effective Fusion of Multi-Modal Remote Sensing Data in a Fully Convolutional Network for Semantic Labeling. Remote Sens. 2018, 10, 52. https://doi.org/10.3390/rs10010052
Zhang W, Huang H, Schmitz M, Sun X, Wang H, Mayer H. Effective Fusion of Multi-Modal Remote Sensing Data in a Fully Convolutional Network for Semantic Labeling. Remote Sensing. 2018; 10(1):52. https://doi.org/10.3390/rs10010052
Chicago/Turabian StyleZhang, Wenkai, Hai Huang, Matthias Schmitz, Xian Sun, Hongqi Wang, and Helmut Mayer. 2018. "Effective Fusion of Multi-Modal Remote Sensing Data in a Fully Convolutional Network for Semantic Labeling" Remote Sensing 10, no. 1: 52. https://doi.org/10.3390/rs10010052
APA StyleZhang, W., Huang, H., Schmitz, M., Sun, X., Wang, H., & Mayer, H. (2018). Effective Fusion of Multi-Modal Remote Sensing Data in a Fully Convolutional Network for Semantic Labeling. Remote Sensing, 10(1), 52. https://doi.org/10.3390/rs10010052