Applications of High-Resolution Imaging for Open Field Container Nursery Counting


Abstract
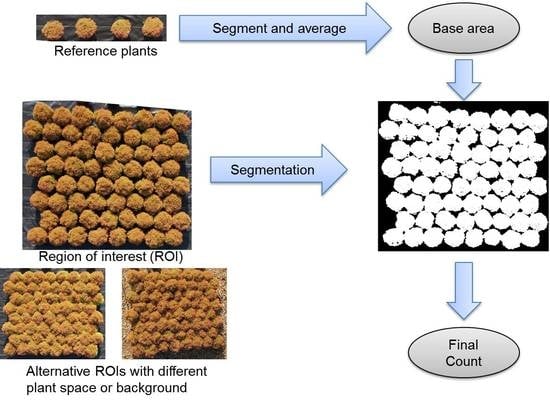
:
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.1.1. Dataset 1. Evaluation of the Effect of Image Resolution and Plant Spacing of Perennial Peanut on Plant Count
2.1.2. Dataset 2. Evaluation of the Effect of a Partially Filled Block on Plant Count
2.1.3. Dataset 3. Exploring the Effect of Flight Altitude, Plant Spacing and Ground Cover for Fire ChiefTM Arborvitae
2.2. Image Segmentation
2.2.1. Green Plant Segmentation
2.2.2. Yellow Plant Segmentation
2.2.3. Flower Plant Segmentation
2.3. Classification Evaluation
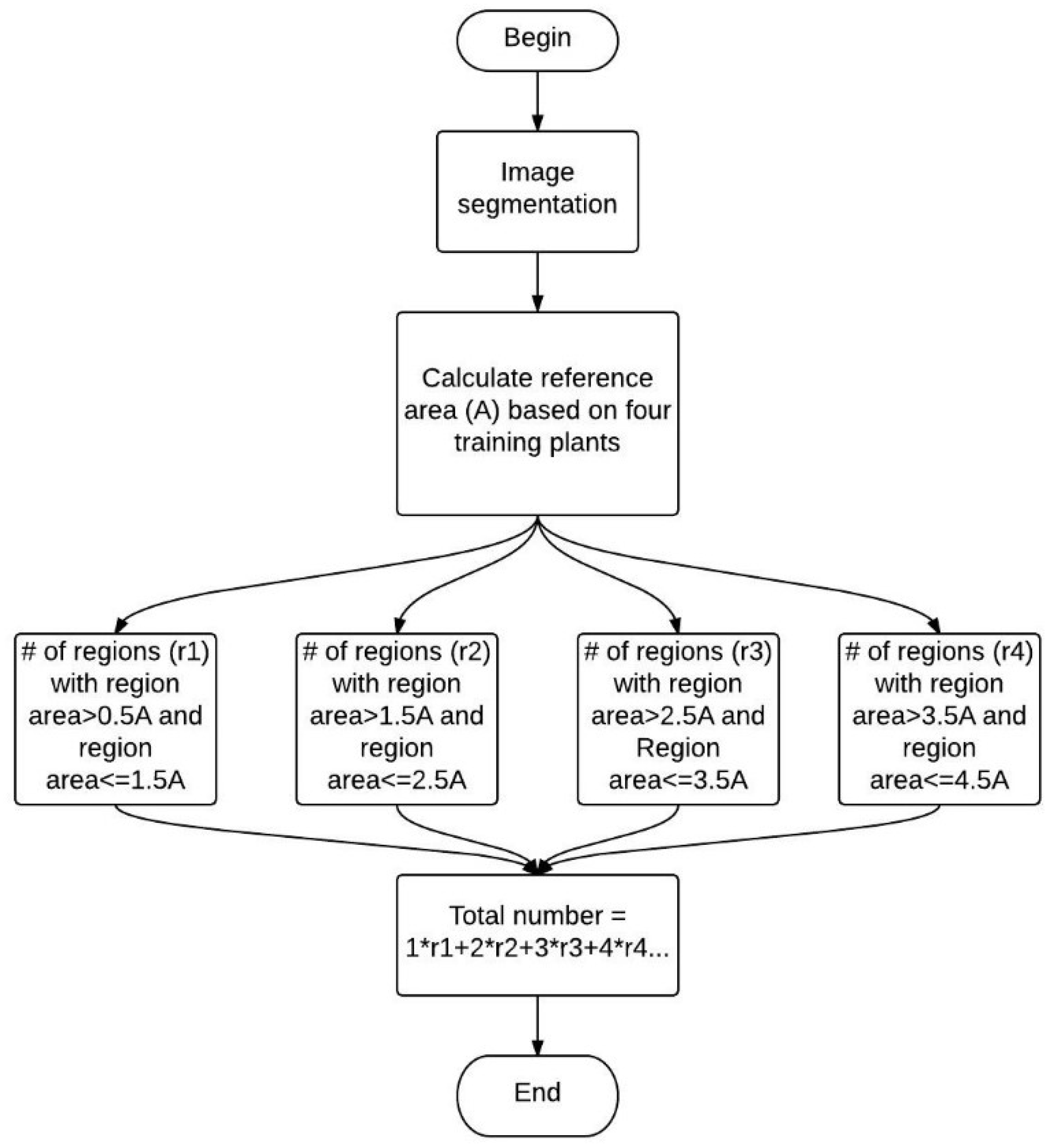
2.4. Counting Scheme
2.4.1. Hypothesis
2.4.2. Counting
3. Results and Discussion
3.1. Classification Results
3.2. Validation of Counting Hypothesis
3.3. Counting Results
3.3.1. Dataset 1. Effect of Height and Container Interval for Perennial Peanut
3.3.2. Dataset 2. Sparse Container Block
3.3.3. Dataset 3. Effect of Height, Canopy Interval and Ground Cover for Fire ChiefTM Arborvitae
3.3.4. Dataset 4. Effect of Nursery Canopy Shape and Effect of Presence of Flowers
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lu, J.; Wu, L.; Newman, J.; Faber, B.; Gan, J. Degradation of pesticides in nursery recycling pond waters. J. Agric. Food Chem. 2006, 54, 2658–2663. [Google Scholar] [CrossRef] [PubMed]
- Hale, M. Designing the Bend Nursery Tree Inventory System; USDA Forest Service general technical report INT; Intermountain Forest and Range Experiment Station: Washington, DC, USA, 1985; Volume 18, pp. 58–66.
- Hartmann, C.S.; Claiborne, L.T. Fundamental limitations on reading range of passive IC-based RFID and SAW-based RFID. In Proceedings of the IEEE International Conference on RFID, Grapevine, TX, USA, 26–28 March 2007; pp. 41–48. [Google Scholar]
- Leiva, J.N. Use of Remote Imagery and Object-Based Image Methods to Count Plants in an Open-Field Container Nursery; University of Arkansas: Fayetteville, AR, USA, 2014; p. 123. [Google Scholar]
- Torres-Sánchez, J.; López-Granados, F.; Peña, J.M. An automatic object-based method for optimal thresholding in UAV images: Application for vegetation detection in herbaceous crops. Comput. Electron. Agric. 2015, 114, 43–52. [Google Scholar] [CrossRef] [Green Version]
- Torres-Sánchez, J.; López-Granados, F.; Serrano, N.; Arquero, O.; Peña, J.M. High-Throughput 3-D Monitoring of Agricultural-Tree Plantations with Unmanned Aerial Vehicle (UAV) Technology. PLoS ONE 2015, 10, e0130479. [Google Scholar] [CrossRef]
- Severtson, D.; Callow, N.; Flower, K.; Neuhaus, A.; Olejnik, M.; Nansen, C. Unmanned Aerial Vehicle Canopy Reflectance Data Detects Potassium Deficiency and Green Peach Aphid Susceptibility in Canola. Precis. Agric. 2016, 17, 659–677. [Google Scholar] [CrossRef]
- Samiappan, S.; Turnage, G.; Hathcock, L.; Casagrande, L.; Stinson, P.; Moorhead, R. Using Unmanned Aerial Vehicles for High-Resolution Remote Sensing to Map Invasive Phragmites Australis in Coastal Wetlands. Int. J. Remote Sens. 2017, 38, 2199–2217. [Google Scholar] [CrossRef]
- Garcia-Ruiz, F.; Sankaran, S.; Maja, J.M.; Lee, W.S.; Rasmussen, J.; Ehsani, R. Comparison of two aerial imaging platforms for identification of Huanglongbing-infected citrus trees. Comput. Electron. Agric. 2013, 91, 106–115. [Google Scholar] [CrossRef]
- Matese, A.; di Gennaro, S.F.; Berton, A. Assessment of a Canopy Height Model (CHM) in a Vineyard Using UAV-based Multispectral Imaging. Int. J. Remote Sens. 2017, 38, 2150–2160. [Google Scholar] [CrossRef]
- Wang, Q.; Nuske, S.; Bergerman, M.; Singh, S. Automated crop yield estimation for apple orchards. In Proceedings of the 13th Internation Symposium on Experimental Robotics, Québec City, QC, Canada, 17–22 June 2012. [Google Scholar]
- Payne, A.B.; Walsh, K.B.; Subedi, P.; Jarvis, D. Estimation of mango crop yield using image analysis–segmentation method. Comput. Electron. Agric. 2013, 91, 57–64. [Google Scholar] [CrossRef]
- Wijethunga, P.; Samarasinghe, S.; Kulasiri, D.; Woodhead, I.M. Digital image analysis based automated kiwifruit counting technique. In Proceedings of the 2008 23rd International Conference Image and Vision Computing New Zealand: IVCNZ, Christchurch, New Zealand, 26–28 November 2008; pp. 26–28. [Google Scholar]
- Nuske, S.; Achar, S.; Bates, T.; Narasimhan, S.; Singh, S. Yield estimation in vineyards by visual grape detection. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 2352–2358. [Google Scholar]
- Annamalai, P. Citrus Yield Mapping System Using Machine Vision. Master’s Thesis, University of Florida, Gainesville, FL, USA, 2004. [Google Scholar]
- Kurtulmus, F.; Lee, W.S.; Vardar, A. Green citrus detection using ‘eigenfruit’, color and circular Gabor texture features under natural outdoor conditions. Comput. Electron. Agric. 2011, 78, 140–149. [Google Scholar] [CrossRef]
- Silwal, A.; Gongal, A.; Karkee, M. Apple identification in field environment with over the row machine vision system. Agric. Eng. Int. CIGR J. 2014, 16, 66–75. [Google Scholar]
- Gnädinger, F.; Schmidhalter, U. Digital counts of maize plants by unmanned aerial vehicles (UAVs). Remote Sens. 2017, 9, 544. [Google Scholar] [CrossRef]
- Quirós, J.; Khot, L. Potential of low altitude multispectral imaging for in-field apple tree nursery inventory mapping. IFAC-PapersOnLine 2016, 49, 421–425. [Google Scholar] [CrossRef]
- Newman, S.E.; Davies, F.T. Influence of field bed position, ground surface color, mycorrhizal fungi, and high root-zone temperature in woody plant container production. Plant. Soil 1988, 112, 29–35. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Slaughter, D.C.; Hanson, B.D.; Barber, A.; Freitas, A.; Robles, D.; Whelan, E. Automated mobile system for accurate outdoor tree crop enumeration using an uncalibrated camera. Sensors 2015, 15, 18427–18442. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Zhao, X.; Zhang, J.; Feng, J. Greenness identification based on HSV decision tree. Inf. Process. Agric. 2015, 2, 149–160. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Chang, C.-C. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classification; Technical report; Department of Computer Science and Information Engineering, National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Roerdink, J.B.T.M.; Meijster, A. The watershed transform: Definitions, algorithms and parallelization strategies. Fundam. Inf. 2000, 41, 187–228. [Google Scholar]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef] [Green Version]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| False Negative | False Positive | Height (m) |
|---|---|---|
| 3/5000 | 0/5000 | 9 |
| 0/5000 | 0/5000 | 12 |
| 3/5000 | 0/5000 | 15 |
| 0/5000 | 0/5000 | 18 |
| False Negative | False Positive | Height (m) |
|---|---|---|
| 1/5000 | 0/5000 | 6 |
| 6/5000 | 0/5000 | 12 |
| 32/5000 | 0/5000 | 22 |
| Ground Count after Missing | 95% Confidential Interval |
|---|---|
| 80 | 75, 80 |
| 60 | 59, 62 |
| 40 | 37, 42 |
| 20 | 20, 20 |
| Level | Least Square Mean | ||
|---|---|---|---|
| 5 | A | 0.94 | |
| 0 | A | 0.93 | |
| −5 | B | 0.74 |
| Level | Least Square Mean | |||
|---|---|---|---|---|
| 5, Fabric | A | 0.98 | ||
| 0, Fabric | A | B | 0.94 | |
| 0, Gravel | B | 0.92 | ||
| 5, Gravel | B | 0.90 | ||
| −5, Gravel | C | 0.76 | ||
| −5, Fabric | C | 0.72 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
She, Y.; Ehsani, R.; Robbins, J.; Nahún Leiva, J.; Owen, J. Applications of High-Resolution Imaging for Open Field Container Nursery Counting. Remote Sens. 2018, 10, 2018. https://doi.org/10.3390/rs10122018
She Y, Ehsani R, Robbins J, Nahún Leiva J, Owen J. Applications of High-Resolution Imaging for Open Field Container Nursery Counting. Remote Sensing. 2018; 10(12):2018. https://doi.org/10.3390/rs10122018
Chicago/Turabian StyleShe, Ying, Reza Ehsani, James Robbins, Josué Nahún Leiva, and Jim Owen. 2018. "Applications of High-Resolution Imaging for Open Field Container Nursery Counting" Remote Sensing 10, no. 12: 2018. https://doi.org/10.3390/rs10122018
APA StyleShe, Y., Ehsani, R., Robbins, J., Nahún Leiva, J., & Owen, J. (2018). Applications of High-Resolution Imaging for Open Field Container Nursery Counting. Remote Sensing, 10(12), 2018. https://doi.org/10.3390/rs10122018