Improving Remote Sensing Scene Classification by Integrating Global-Context and Local-Object Features


Abstract
:
1. Introduction
- (1)
- Methods using low-level features. These methods mainly focus on designing various human-engineering either local or global features, such as spectral, color, texture, and shape information or their combination, which are the primary characteristics of a scene image. Some of these methods use local descriptors, for example, the scale invariant feature transform (SIFT) [6,7] for describing local variations of structures in scene images. For instance, Yang et al. [8] extracted SIFT and Gabor texture features for classifying remote-sensing images and demonstrated SIFT performs better. However, one limitation of the methods that use the local descriptors is a lack of the global distributions of spatial cues. In order to depict the spatial arrangements of images, Santos et al. [9] evaluated various global color descriptors and texture descriptors, for example, color histogram [10] and local binary patterns (LBPs) [11,12,13], for scene classification. To further improve the classification performance, Luo et al. [14] combined six different types of feature descriptors, including local and global descriptors, to form a multi-feature representation for describing remote-sensing images. However, in practical applications, the performance is largely limited by the hand-crafted descriptors, as these make it difficult to capture the rich semantic information contained in remote-sensing images.
- (2)
- Methods relying on mid-level representations. Because of the limited discrimination of hand-crafted features, these methods mainly attempt to develop a set of basis functions used for feature encoding. One of the most popular mid-level approaches is the bag-of-visual-words (BoVW) model [15,16,17,18,19,20]. The BoVW-based models firstly encode local invariant features from local image patches into a vocabulary of visual words and then use a histogram of visual-word occurrences to represent the image. However, the BoVW-based models may not fully exploit spital information which is essential for remote scene classification. To avoid this issue, many BoVW extensions have been proposed [21,22,23]. For instance, Yang et al. [21] proposed the spatial pyramid co-occurrence kernel (SPCK) to integrate the absolute and relative spatial information that is ignored in the standard BoVW model setting, motivated by the idea of spatial pyramid match kernel (SPM) [24] and spatial co-occurrence kernel (SCK) [15]. Additionally, topic models have been developed to generate semantic features. These models aim to represent the image scene as a finite random mixture of topics; examples are the Latent Dirichlet Allocation (LDA) [25,26] model and the probabilistic latent semantic analysis (pLSA) [27] model. Although these methods have made some achievements in remote scene image classification, they all demand prior knowledge in handcrafted feature extraction. Lacking the flexibility in discovering highly intricate structures, these methods carry little semantic meaning.
- (3)
- CNN-based methods. Recently, deep learning has achieved dramatic improvements in video processing [28,29] and many computer vision fields such as object classification [30,31,32], object detection [33,34], and scene recognition [35,36]. As a result of the outstanding performance in these fields, many researchers have been dedicated to using CNNs to extract high-level semantic features for remote sensing scene classification [37,38,39,40,41,42]. Most of them adopted pre-trained object classification models, which are available online such as AlexNet [30], VGGNet [31], and GoogLeNet [32], as discriminative feature extractors for scene classification. Nogueira et al. [43] directly used the CNN models to extract global features followed by a sophisticated classifier and demonstrated the effectiveness of transferring from the object classification models. Hu et al. [44] extracted features from multi-scale images and further fused them into a global feature space via the conventional BoVW and Fisher encoding algorithms. Chaib et al. [45] developed discriminant correlation analysis (DCA) method to fuse two features extracted from the first and second fully-connected layers of object classification model. Although current approaches can further improve the classification performance, one limitation of these methods is only the global-context features (GCFs) can be extracted and local-object-level features (LOFs), which would help to infer the semantic scene label for an image is ignored.
- (1)
- To address the issue that many previous CNN-based methods in scene classification justly extract the global feature from a single scene image and ignore LOFs that would help to infer the scene, we propose a novel two-branch, end-to-end CNN model to capture both GCFs and LOFs simultaneously.
- (2)
- Our network supports input of arbitrary size by using global average pooling layer and RoI pooling layer. Compared with methods that require fixed-size input images produced by resizing the scene image to a certain scale or cropping fixed-size patches from image, our method can extract more applicable features from the original-scale image.
- (3)
- By integrating GCFs and LOFs, our method can obtain superior performance compared with the state-of-the-art results from three challenging datasets.
2. Materials and Methods
2.1. Datasets
2.2. Methods
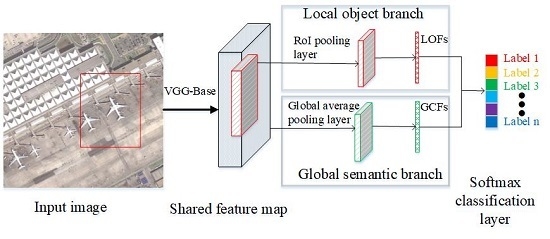
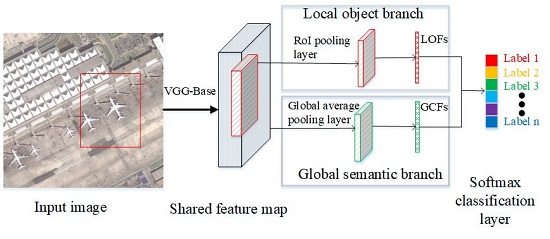
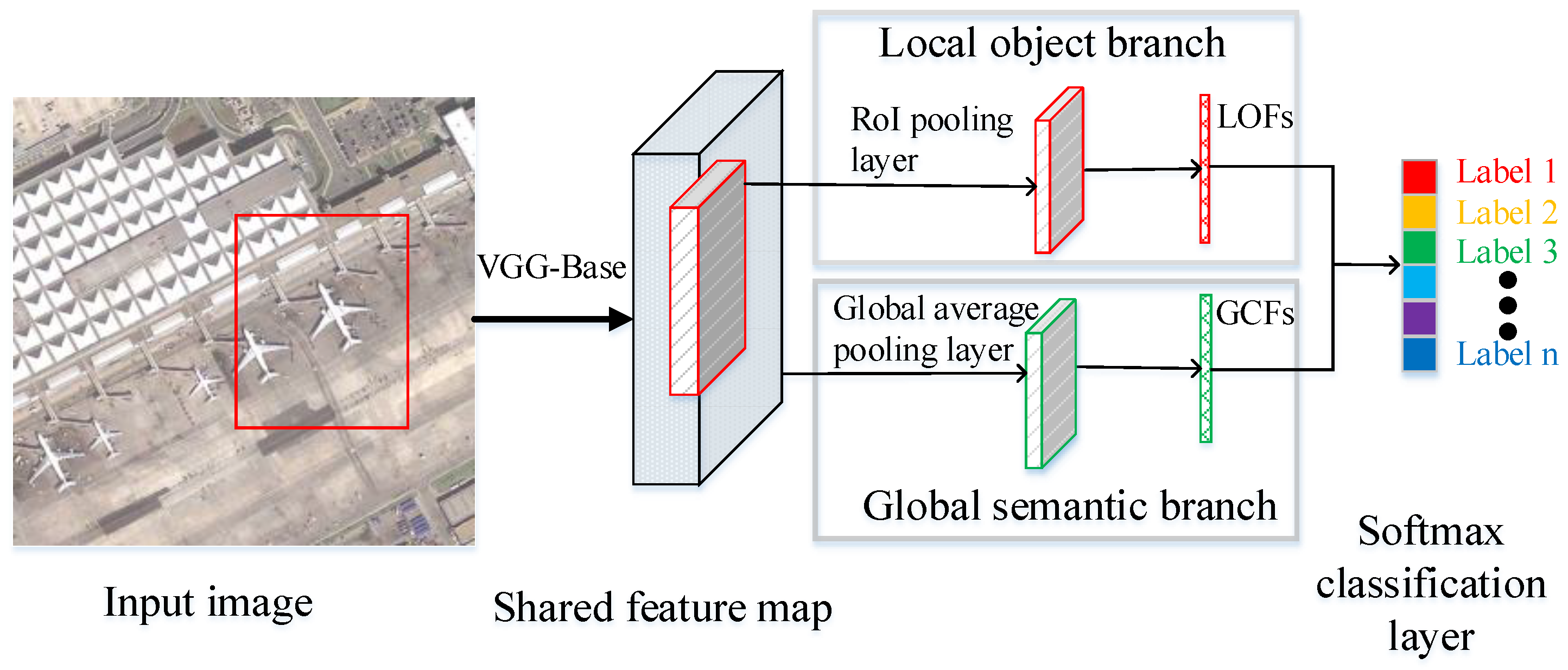
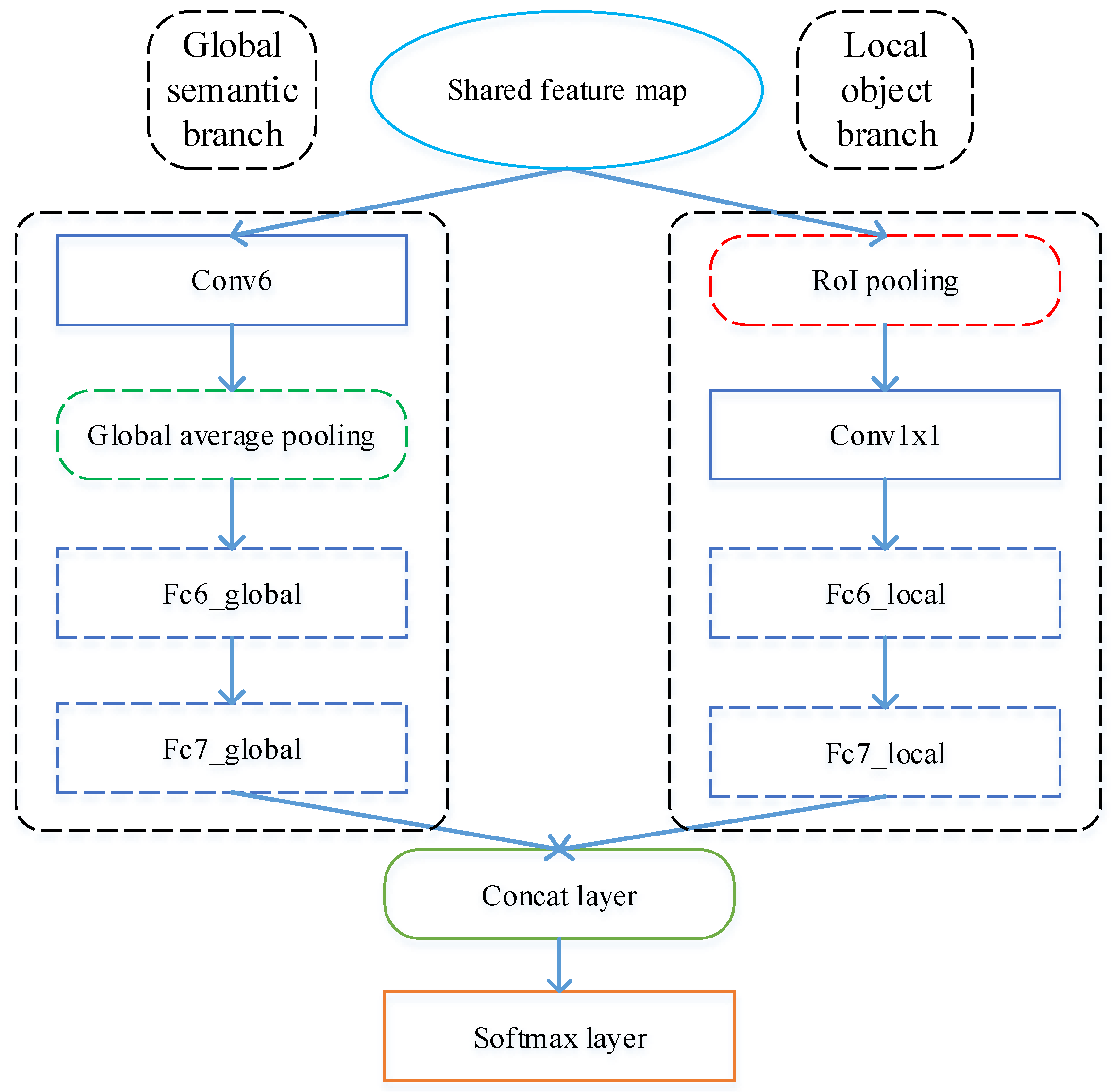
2.2.1. Overall Architecture
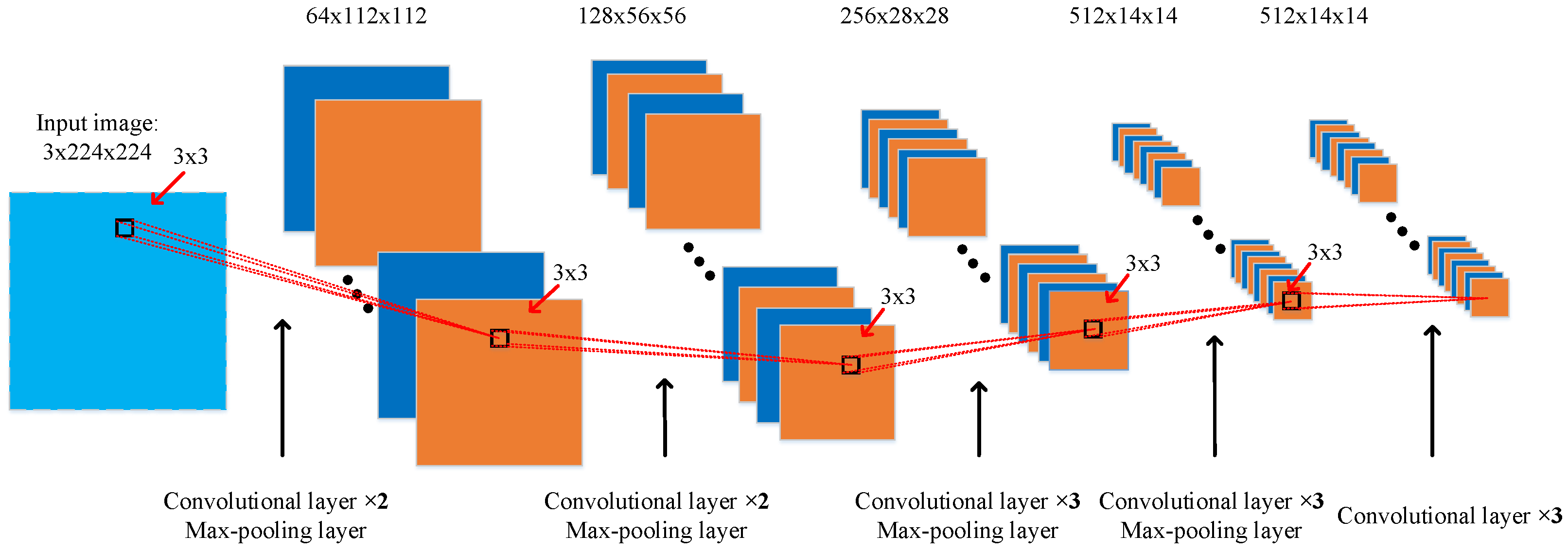
2.2.2. VGG-Base
2.2.3. Global Semantic Branch
2.2.4. Local-Object Branch
3. Results
3.1. Experimental Setup
3.1.1. Implementation Details
3.1.2. Evaluation Protocol
3.2. Experimental Results and Analysis
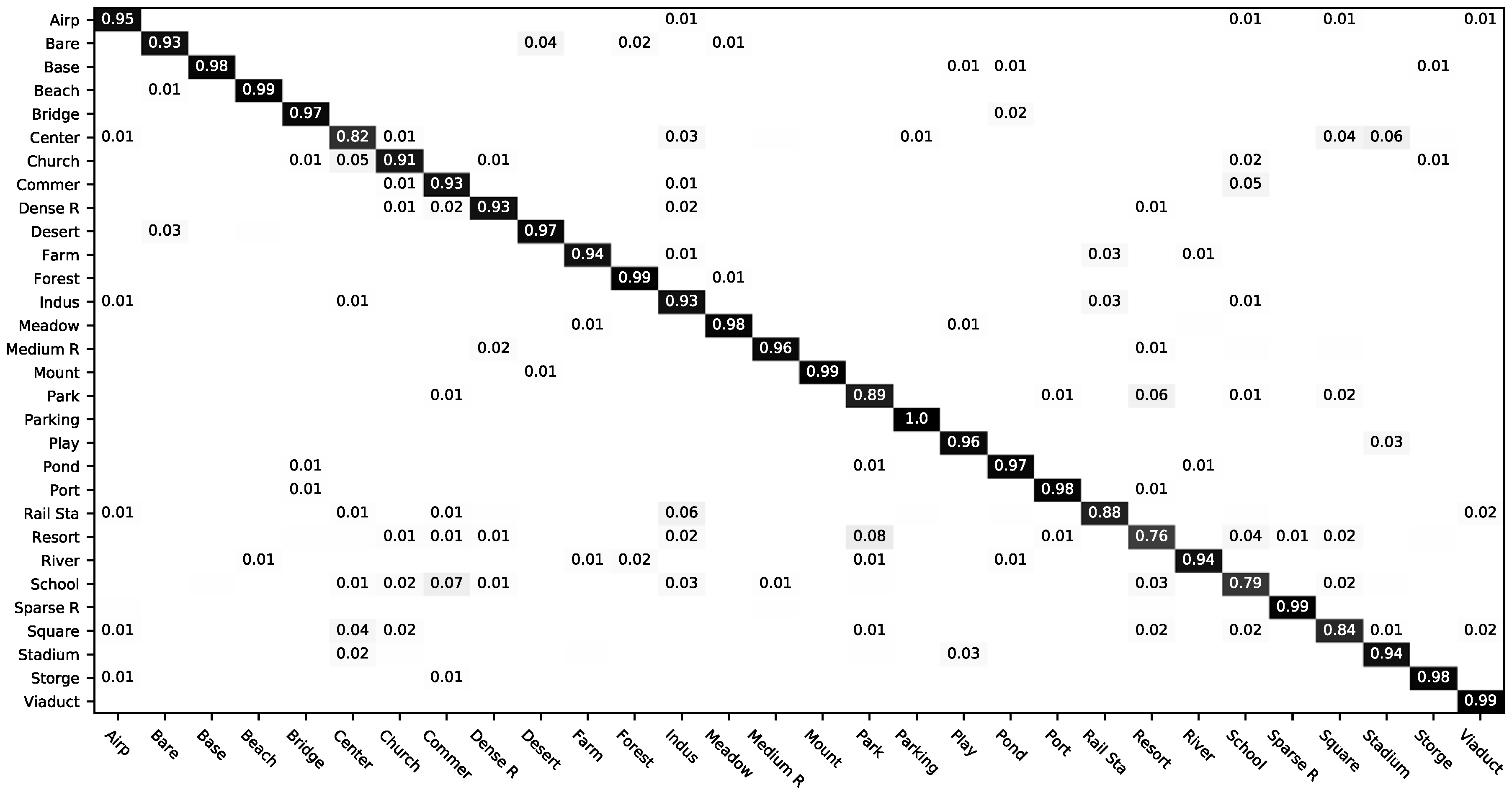
3.2.1. Classification of AID
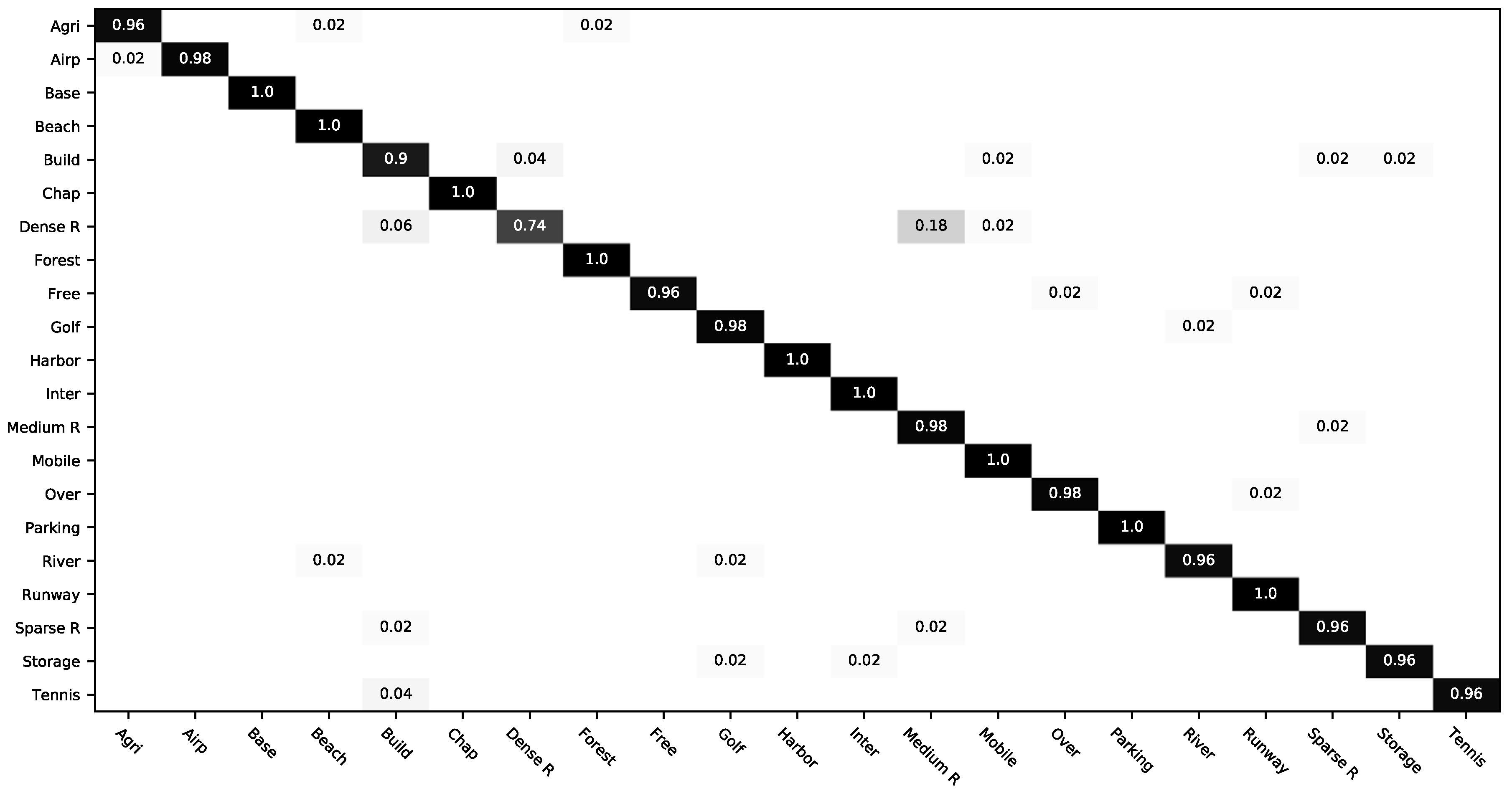
3.2.2. Classification of UC-Merced
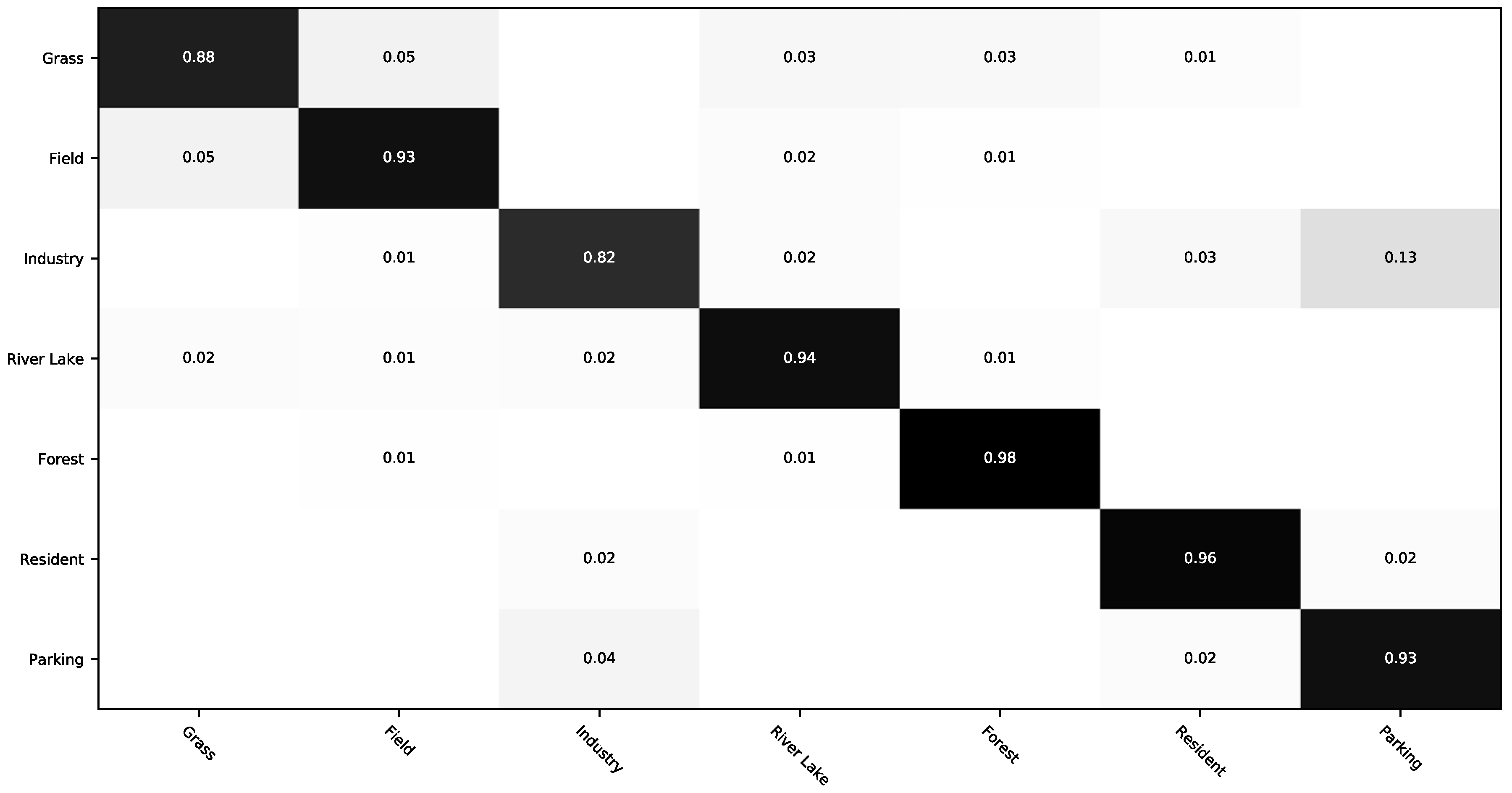
3.2.3. Classification of RSSCN7
3.3. Ablation Study
- (1)
- Results from LOB are the worst, which was because the LOB can only extract local-object features without paying attention to GCFs. It is not reliable for classifying a scene by only focusing on part of the image.
- (2)
- The method using only the GSB works better than the baseline method. We think there are two reasons. One is that our GSB architecture introduces a global average pooling layer and is more applicable than VGG16 to extract global features by taking the average of each feature map. Another reason is that the resize operation in the original VGG16 network makes the objects smaller and makes it harder to extract features.
- (3)
- Our proposed method achieved the best performance compared to only using one branch or baseline method, which was a result of combining both GCFs and LOFs. The LOB is designed to describe objects in RoIs, while the GSB focuses on extracting GCFs. Therefore, a collaborative representation of the fusion of GCFs and LOFs can generate superior performance.
4. Discussion
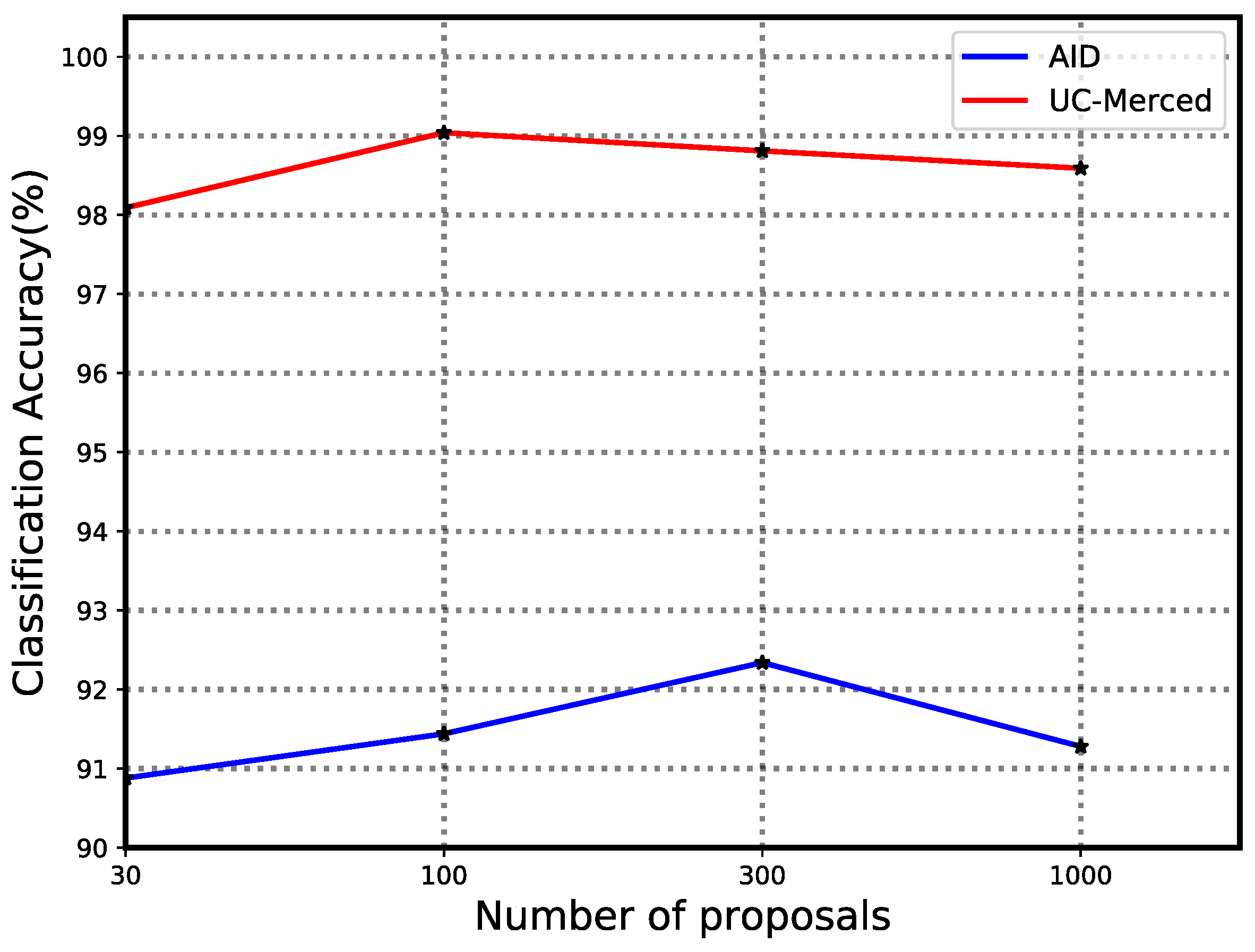
4.1. Evaluation of Number of Proposals
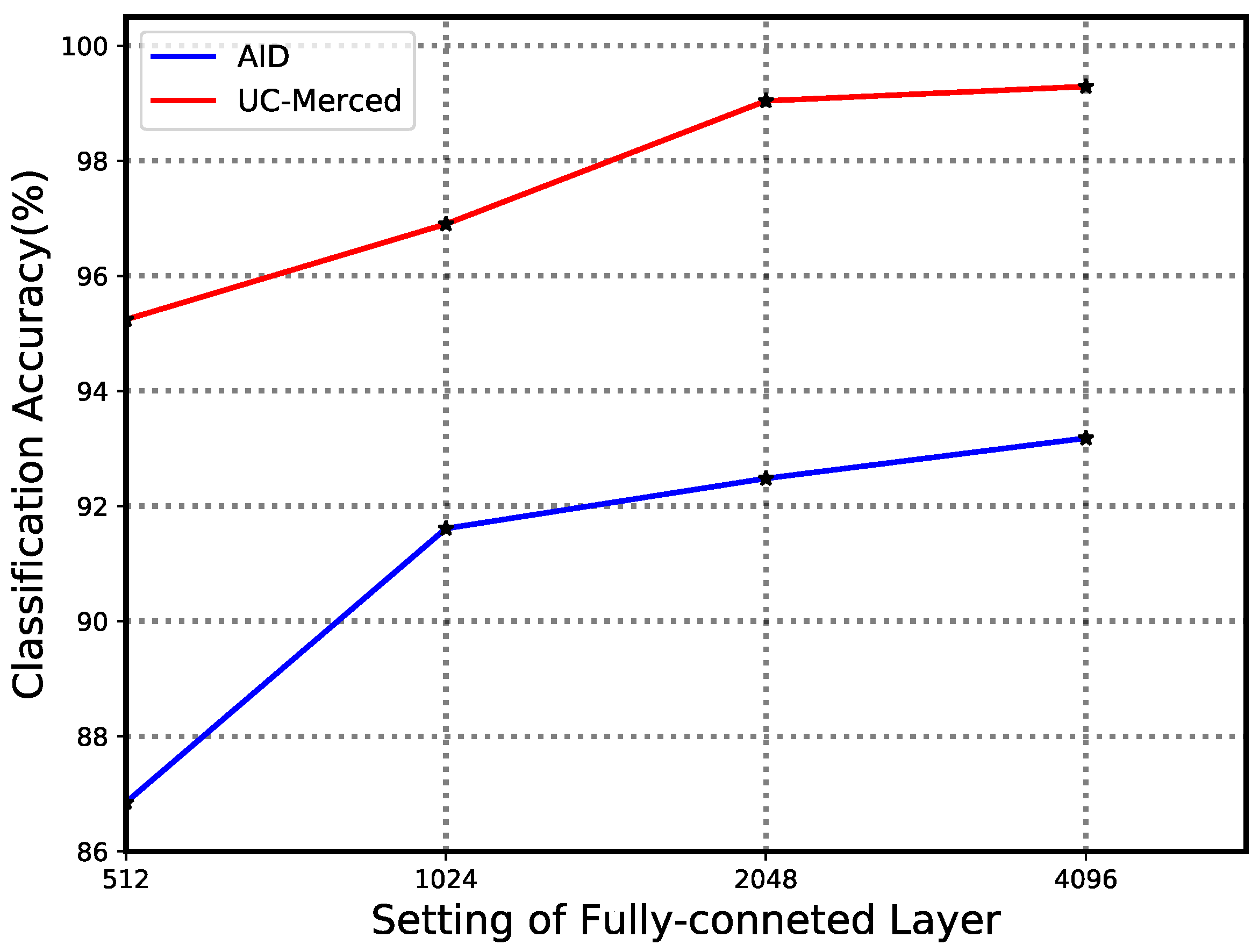
4.2. Evaluation of Number of Model Weights
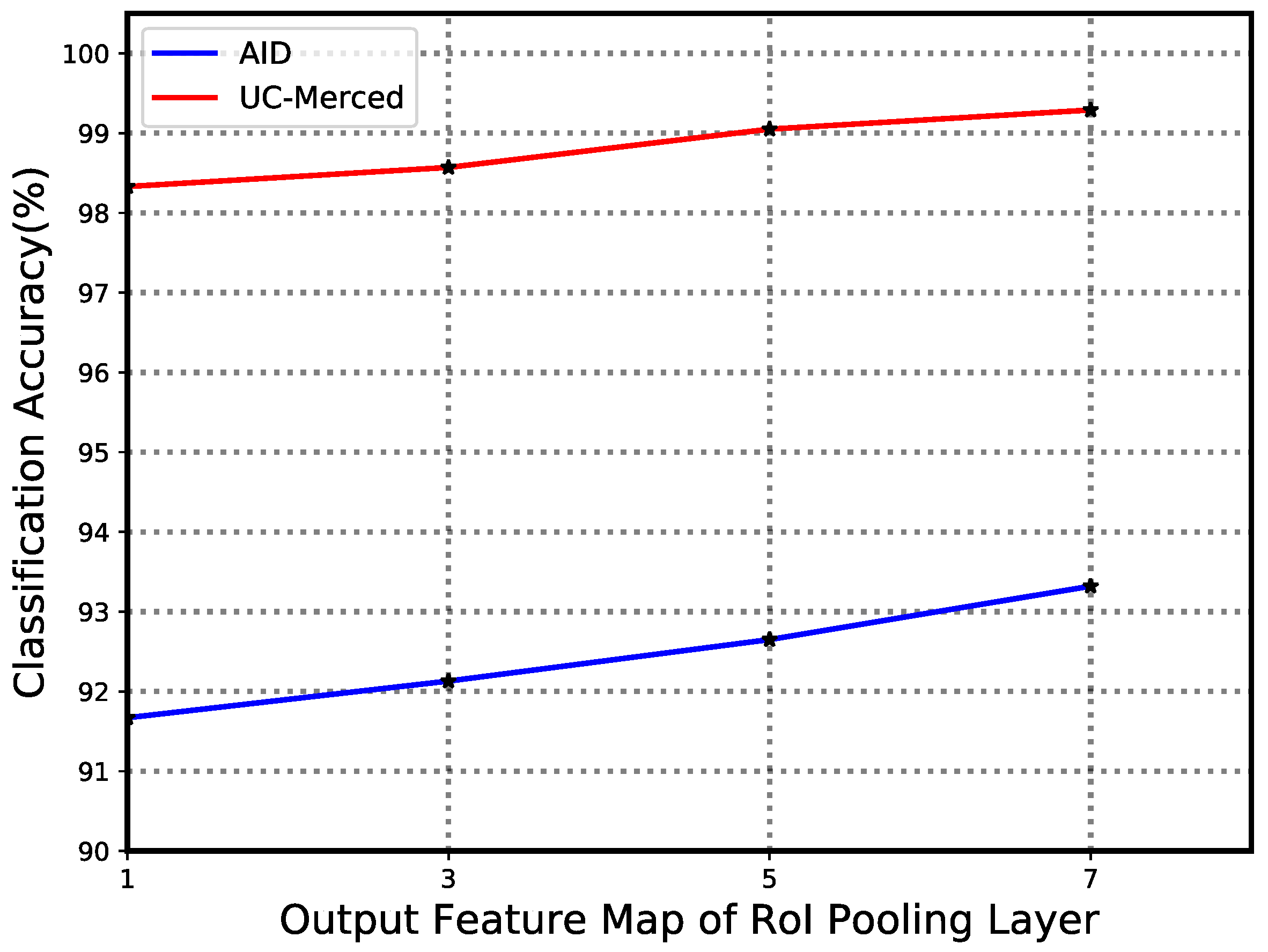
4.3. Evaluation of Scale of RoI Pooling Kernel
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Hu, Q.; Wu, W.; Xia, T.; Yu, Q.; Yang, P.; Li, Z.; Song, Q. Exploring the use of Google Earth imagery and object-based methods in land use/cover mapping. Remote Sens. 2013, 5, 6026–6042. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Yang, W.; Yin, X.; Xia, G.S. Learning high-level features for satellite image classification with limited labeled samples. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4472–4482. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.S. Extreme value theory-based calibration for the fusion of multiple features in high-resolution satellite scene classification. Int. J. Remote Sens. 2013, 34, 8588–8602. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.S.; Liu, G. A Hierarchical Scheme of Multiple Feature Fusion for High-Resolution Satellite Scene Categorization. In Proceedings of the International Conference on Computer Vision Systems, St. Petersburg, Russia, 16–18 July 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 324–333. [Google Scholar]
- Yang, Y.; Newsam, S. Comparing SIFT descriptors and Gabor texture features for classification of remote sensed imagery. In Proceedings of the 15th IEEE International Conference on Image Processing (ICIP), San Diego, CA, USA, 12–15 October 2008; pp. 1852–1855. [Google Scholar]
- Dos Santos, J.A.; Penatti, O.A.B.; da Silva Torres, R. Evaluating the Potential of Texture and Color Descriptors for Remote Sensing Image Retrieval and Classification. In Proceedings of the VISAPP, Angers, France, 17–21 May 2010; pp. 203–208. [Google Scholar]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2016, 10, 745–752. [Google Scholar] [CrossRef]
- Ren, J.; Jiang, X.; Yuan, J. Learning LBP structure by maximizing the conditional mutual information. Pattern Recognit. 2015, 48, 3180–3190. [Google Scholar] [CrossRef]
- Luo, B.; Jiang, S.; Zhang, L. Indexing of remote sensing images with different resolutions by multiple features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1899–1912. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar]
- Chen, S.; Tian, Y.L. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1947–1957. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, Z.; Hu, D. Scene classification using a multi-resolution bag-of-features model. Pattern Recognit. 2013, 46, 424–433. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Zhang, L.; Huang, B. The fisher kernel coding framework for high spatial resolution scene classification. Remote Sens. 2016, 8, 157. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Xia, G.S.; Zhang, L. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2108–2123. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Hierarchical coding vectors for scene level land-use classification. Remote Sens. 2016, 8, 436. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1465–1472. [Google Scholar]
- Zhao, L.; Tang, P.; Huo, L. A 2-D wavelet decomposition-based bag-of-visual-words model for land-use scene classification. Int. J. Remote Sens. 2014, 35, 2296–2310. [Google Scholar]
- Zhao, L.; Tang, P.; Huo, L. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Wang, Q.; Meng, Z.; Li, X. Locality adaptive discriminant analysis for spectral-spatial classification of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2077–2081. [Google Scholar] [CrossRef]
- Bosch, A.; Zisserman, A.; Munoz, X. Scene Classification via pLSA. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 517–530. [Google Scholar]
- Wang, Q.; Wan, J.; Yuan, Y. Deep metric learning for crowdedness regression. IEEE Trans. Circ. Syst. Video Technol. 2017. [Google Scholar] [CrossRef]
- Zhu, H.; Vial, R.; Lu, S.; Peng, X.; Fu, H.; Tian, Y.; Cao, X. YoTube: Searching Action Proposal via Recurrent and Static Regression Networks. IEEE Trans. Image Process. 2018, 27, 2609–2622. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NY, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 11–12 June 2015; pp. 1–9. [Google Scholar]
- Girshick, R. Fast r-cnn. arXiv, 2015; arXiv:1504.08083. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Swizerland, 2014; pp. 346–361. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. In Proceedings of Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 487–495.
- Herranz, L.; Jiang, S.; Li, X. Scene recognition with CNNs: Objects, scales and dataset bias. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 571–579. [Google Scholar]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing local and global features for high-resolution scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1793–1802. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Fei, F.; Zhu, Q.; Qin, Q. Scene Classification Based on a Deep Random-Scale Stretched Convolutional Neural Network. Remote Sens. 2018, 10, 444. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Deep filter banks for land-use scene classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1895–1899. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv, 2015; arXiv:1508.00092. [Google Scholar]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote. Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Dollar, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Swizerland, 2014; pp. 391–405. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Anwer, R.M.; Khan, F.S.; van de Weijer, J.; Monlinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. arXiv, 2017; arXiv:1706.01171. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. A Two-Stream Deep Fusion Framework for High-Resolution Aerial Scene Classification. Comput. Intell. Neurosci. 2018, 2018, 8639367. [Google Scholar] [CrossRef] [PubMed]
- Zou, J.; Li, W.; Chen, C.; Du, Q. Scene classification using local and global features with collaborative representation fusion. Inf. Sci. 2016, 348, 209–226. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Weights Shape | Bias Shape | Output Shape |
|---|---|---|---|
| Conv6 | 512 × 3 × 3 × 512 | 1 × 512 | ( + 1) × ( + 1) × 512 |
| Global average pooling | - | - | 1 × 1 × 512 |
| Fc6_global | 512 × 2048 | 1 × 2048 | 1 × 2048 |
| Fc7_global | 2048 × 2048 | 1 × 2048 | 1 × 2048 |
| Layer Name | Weights Shape | Bias Shape | Output Shape |
|---|---|---|---|
| RoI pooling | - | - | n × 7 × 7 × 512 |
| Conv1 × 1 | n × 1 × 1 × 512 | 1 × 512 | 7 × 7 × 12 |
| Fc6_local | 25,088 × 2048 | 1 × 2048 | 1 × 2048 |
| Fc7_local | 2048 × 2048 | 1 × 2048 | 1 × 2048 |
| Methods | 50% Training Set | 20% Trainging Set |
|---|---|---|
| CaffeNet [5] | 89.53 ± 0.31 | 86.86 ± 0.47 |
| GoogLeNet [5] | 86.39 ± 0.55 | 83.44 ± 0.40 |
| VGG16 [5] | 89.64 ± 0.36 | 86.59 ± 0.29 |
| salMLBP-CLM [37] | 89.76 ± 0.45 | 86.92 ± 0.35 |
| TEX-Net-LF [50] | 92.96 ± 0.18 | 90.87 ± 0.11 |
| Fusion by addition [45] | 91.87 ±0.36 | - |
| Two-Stream Fusion [51] | 94.58 ± 0.41 | 92.32 ± 0.41 |
| Ours | 96.85 ± 0.23 | 92.48 ± 0.38 |
| Methods | 80% Training Set | 50% Training Set |
|---|---|---|
| SCK [15] | 72.52 | - |
| SPCK [21] | 73.14 | - |
| BoVW [15] | 76.81 | - |
| BoVW + SCK [15] | 77.71 | - |
| SIFT + SC [38] | 81.67 | - |
| MCMI [13] | 88.20 | - |
| Unsupervised feature learning [38] | 81.67 ± 1.23 | - |
| Gradient boosting CNNs [39] | 94.53 | - |
| MS-CLBP + FV [12] | 93.00 ± 1.20 | 88.76 ± 0.79 |
| LGF [52] | 95.48 | - |
| SSF-AlexNet [40] | 92.43 | - |
| Multifeature concatenation [7] | 92.38 ± 0.62 | - |
| CaffeNet [5] | 95.02 ± 0.81 | 93.98 ± 0.67 |
| GoogLeNet [5] | 94.31 ± 0.89 | 92.70 ± 0.60 |
| VGG16 [5] | 95.21 ± 1.20 | 94.14 ± 0.69 |
| Fine-tuned GoogLeNet [42] | 97.10 | - |
| Deep CNN Transfer [44] | 98.49 | - |
| salMLBP-CLM [37] | 95.75 ± 0.80 | 94.21 ± 0.75 |
| TEX-Net-LF [50] | 96.62 ± 0.49 | 95.89 ± 0.37 |
| Fusion by addition [45] | 97.42 ± 1.79 | - |
| Two-Stream Fusion [51] | 98.02 ± 1.03 | 96.97 ± 0.75 |
| Ours | 99 ± 0.35 | 97.37 ± 0.44 |
| Methods | 50% Training Set | 20% Training Set |
|---|---|---|
| CaffeNet [5] | 88.25 ± 0.62 | 85.57 ± 0.95 |
| GoogLeNet [5] | 85.84 ± 0.92 | 82.55 ± 1.11 |
| VGG16 [5] | 87.18 ± 0.94 | 83.98 ± 0.87 |
| DBN [47] | 77 | - |
| HHCV [20] | 84.7 ± 0.7 | - |
| Deep Filter Banks [41] | 90.4 ± 0.6 | - |
| Ours | 95.59 ± 0.49 | 92.47 ± 0.29 |
| Methods | AID | UC-Merced | ||
|---|---|---|---|---|
| 50% Training Set | 20% Training Set | 80% Training Set | 50% Training Set | |
| Baseline | 94.08 | 91.25 | 96.90 | 95.33 |
| Local | 87.44 | 86.34 | 95.47 | 94.76 |
| Global | 95.04 | 92.25 | 98.09 | 96.28 |
| Global + Local | 96.85 | 92.48 | 99 | 97.37 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving Remote Sensing Scene Classification by Integrating Global-Context and Local-Object Features. Remote Sens. 2018, 10, 734. https://doi.org/10.3390/rs10050734
Zeng D, Chen S, Chen B, Li S. Improving Remote Sensing Scene Classification by Integrating Global-Context and Local-Object Features. Remote Sensing. 2018; 10(5):734. https://doi.org/10.3390/rs10050734
Chicago/Turabian StyleZeng, Dan, Shuaijun Chen, Boyang Chen, and Shuying Li. 2018. "Improving Remote Sensing Scene Classification by Integrating Global-Context and Local-Object Features" Remote Sensing 10, no. 5: 734. https://doi.org/10.3390/rs10050734
APA StyleZeng, D., Chen, S., Chen, B., & Li, S. (2018). Improving Remote Sensing Scene Classification by Integrating Global-Context and Local-Object Features. Remote Sensing, 10(5), 734. https://doi.org/10.3390/rs10050734